基于DBM的電力投訴工單分類的應用研究
2020-10-20 05:34:01楊恒顏宏文
計算技術與自動化 2020年3期
楊恒 顏宏文


摘? ?要:提出了基于深度玻爾茲曼機的電力投訴工單識別分類模型。首先對投訴工單數據進行數據清洗,對處理后的數據使用結巴分詞算法進行分詞并制作字典,再使用詞袋模型對所分詞向量化處理提取文本特征。進一步地,通過TF-IDF算法找出關鍵詞以及余弦相似度計算訓練、測試文檔間的相似度;最后使用深度玻爾茲曼機對投訴工單進行分類。實驗證明,分類的準確度達到80%,有效地緩解電力部門的工作壓力,提高工作效率。
關鍵字:投訴;TF-IDF;DBM;文本分類;
中圖分類號:TP391.1? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?文獻標識碼:A
Application Research on Classification of Power
Complaint Work Order Based on DBM
YANG Heng?,YAN Hong-wen
(School of Computer and Communication Engineering,Changsha University of Science
& Technology,Changsha,Hunan 410114,China)
Abstract:A classification model based on the deep Boltzmann machines for power complaint work order identification is proposed. Firstly,the data of the complaint work order data is cleaned and use the Jieba algorithm to segment the processed data,and create a dictionary. Then the BoW model is used to extract the text feature from the segmentation vectorization process. Further,the TF-IDF algorithm is used to find keywords and cosine similarity calculations to calculate the similarity between training and test documents.Finally,the deep Boltzmann machine is used to classify the complaint work orders. The experiment proves that the accuracy of the classification reaches 80%,effectively alleviating the work pressure of the power sector and improving work efficiency.
Key words:complaint;TF-IDF;deep Boltzmann machine;text classification
當前,用戶投訴成為電力企業一項重點關注的問題,如何有效地減少用戶的投訴量,提供更好的電力服務從而提升用戶的滿意度成為供電企業關注的焦點[1]。近年來,隨著供電企業管理水平的不斷提高,優質服務的落地要求也越來越高。目前,95598目前對投訴的分類依然采取人工分類的方法,效率低下且存在主觀偏差[2]。因此,利用自動化手段實現95598投訴工單分類以替代人工進行分類顯得尤為重要與迫切。
國內外眾多學者對分類問題進行了大量細致的研究。在數據的預處理上,文獻[3]利用Word2Vec模型緩解了短文本中數據特征稀疏的問題;文獻[4]使用BOW-HOG的改進模型用于圖像分類;文獻[5]使用中科院分詞系統ictclas并對其進行了優化,有效識別出新詞并實現分詞結果的優化。在文本分類模型算法方面,文獻[6]將L21范數與極限學習機結合,提出L21規范最小化極限學習機,有利于群體稀疏性并減少學習模式的復雜性;文獻[7]提出一種利用語義相似度的支持向量機用于Web文檔分類,在公共數據集上提高了F1值5%;文獻[8]提出了基于極限學習機的中文文本分類方法,有效地提高了平衡分類精度;針對多標簽文本分類的概念歧義和底層語意結構問題,文獻[9]提出了將隨機森林(RF)算法和隱性語義索引(LSI)結合的集成分類算法;文獻[10]提出基于K中心點和粗糙集的KNN分類方法,降低了計算規模,提高了文本數據的分類效率。以上方法所涉及的算法模型均為淺層的機器學習方法,雖然能夠解決在簡單情況或有多重限制條件下的問題,但當面對的是復雜的實際問題時,例如多類別的分類問題,淺層的機器學習方法的泛化能力將受到較大限制,于是尋求更深層次的機器學習方法成為關鍵。
為解決電力投訴工單的智能識別分類問題,提出了一種基于深度玻爾茲曼機(Deep Boltzmann Machine,DBM)的電力投訴工單識別分類方法。該方法將95598電力投訴工單與自然語言處理中的文本分類問題結合,對電力投訴工單進行預處理,運用基于深度學習的電力投訴工單分類技術,有效優化質量監督管理工作,強化服務問題防控,減輕基層投訴壓力,提高員工工作效率。
1? ?算法概述
1.1? ?DBM算法
為了使得學習具有多個隱藏層和數百萬個參數的玻爾茲曼機(Boltzmann Machine,BM)變得切實可行,Salakhutdinov和Hinton為玻爾茲曼機提出了一種新的學習算法DBM[11]。DBM是一種具有多層隱藏隨機變量的二元成對馬爾科夫隨機場(無向概率圖模型),它使用變分近似法估計數據相關的期望,并且使用持久性馬爾可夫鏈來近似數據獨立期望。通過使用逐層“預訓練”階段可以使學習更有效,該階段允許通過單個自下而上的傳遞來初始化變分推斷。深度玻爾茲曼機是一種深度生成模型,它是一個完全無向的模型,每一層內的每個變量是相互獨立的,并且條件于相鄰層中的變量。深度玻爾茲曼機已經被應用于各種任務,包括文檔建模,文本分類等。
深度玻爾茲曼機包含一組可見單元v∈{0,1}D
和多層隱藏單元h(1)
}為模型參數,表示可見層到隱藏層以及隱藏層之間的交互[12]。在DBM中,所有層都是對稱且無向的,模型結構如圖1所示。
1.2? ?TF-IDF[13]算法
TF-IDF(term frequency-inverse document frequency)是一種用于信息檢索與文本挖掘的常用加權技術,旨在反映單詞對集合或語料庫中文檔的重要性。在研究詞的重要程度的時候往往會看一個詞的詞頻,也就是這個詞在文檔里面的出現次數,當然也有些常用的詞,雖然出現的次數比較多,但是在每個類別里面出現的次數,都很多,這部分的詞匯對于分類來說是沒有什么作用的。TF-IDF文檔-逆文檔詞頻法是一種較優秀的特征提取的方法。數字圖書館中83%的基于文本的推薦系統使用TF-IDF。
在一份給定的文檔里,詞頻(term frequency,TF)指的是某一個給定的詞語在該文檔中出現的頻率。對于給定文檔d中的詞語t,其重要性tf(t,d)可以表示為:
其中,ft,d表示詞語t在文檔d中出現的次數,ft′,d表示文檔d的字詞數。
逆向文檔頻率(inverse document frequency,IDF)是一個詞語普遍重要性的度量,通過將文檔總數除以包含該項的文檔數,然后取該商的對數得到,即:
其中,N表示語料庫中的文檔總數,d∈D:t∈d表示詞語t在文檔D中出現的次數。通常我們調整為1+d∈D:t∈d以防止詞語t在文檔D中未出現而導致分母為0的情況。
則TF-IDF的計算公式為:
通過在給定文檔中,高頻率詞語在整個文檔集合中的低文檔頻率,產生高權重的TF-IDF。因此,TF-IDF傾向于過濾掉常見的詞語,保留重要的詞語。
2? ?基于DBM的電力投訴工單分類模型
2.1? ?模型描述
目前,每年95598電力投訴工單中數量規模較大,人工分類效率低下,并且工單內容是以非結構化的文本形式記錄存儲的,然而深度學習神經網絡模型識別的模式是通過向量中的數值形式體現。因此,針對以上問題,本文采用先對訓練文檔進行清洗,包括檢查數據一致性、處理無效值和缺失值以及去停用詞等;對清洗后的數據使用Jieba分詞[14]并制作字典,如圖2所示。進一步地,運用BoW[15]模型進行向量化特征提取。通過使用TF-IDF算法對訓練文檔和測試文檔的文本特征向量進行相似度比較,獲得相似度后使用DBM模型進行訓練并根據權重預測分類,如圖3所示。
2.2? ?DBM訓練步驟
由于隨機初始化后使用最大似然法訓練DBM會導致訓練經常失敗,于是采取了貪心逐層預訓練的方法。通過該方法,將DBM的每一層看作一個單獨的RBM(Restricted Boltzmann machine,RBM)。于是對第一層進行建模,對輸入對象進行訓練。后一層的RBM的訓練建模使用前一層RBM的后驗分布樣本輸入。通過貪心逐層預訓練的方式訓練了所有的RBM后,將所有的RBM組合成DBM。下一步使用對比散度(ContrastiveDivergence,CD)訓練DBM。訓練步驟如下:
1)使用CD近似最大化log P(v)來訓練RBM。
2)訓練第二個RBM,使用CD-k近似最大化 log P(h(1)
,y)來建模h(1)
和目標類y,其中h(1)
采自第一個RBM條件于數據的后驗。在學習期間將k從1增加到20。
3)將兩個RBM組合為DBM。使用k = 5的隨機最大似然訓練,近似最大化log P(v,y)。
4)將y從模型中刪除。定義新的一組特征h(1)
和h(2)
,可在缺少y的模型中運行均勻場推斷后獲得。使用這些特征作為多層感知機(Multi-Layer Perception,MLP)的輸入,其結構與均勻場的額外輪相同,并且具有用于估計y的額外輸出層。初始化MLP的權重與DBM的權重相同。使用隨機梯度下降和Dropout訓練MLP近似最大化log P(y | v)。
2.3? ?本模型分類具體步驟
基于DBM的電力投訴工單分類的具體實現如下所示:
2.3.1? ?訓練文檔預處理
1)取樣本集(X,Y),其中X = (x1,x2,…,xl)表示輸入的文檔,Y = (y1,y2,…,ym)表示實際的m類文檔類別。
2)對X進行預處理,包括建立停用詞表,對X進行Jieba分詞、去停用詞、詞性過濾,得到若干關鍵詞W = (w1,w2,…,wn),同時制作字典,n為關鍵詞wn 的字典序號。
3)對X使用BoW模型進行文本特征向量化,生成的特征向量為[(1,z1),(22,z2),…,(n,zk)],其中(n,zk)代表在X中序號為n的關鍵詞出現了zk次。
2.3.2? ?分類測試文檔
1)選取訓練文檔D = (D1,D2,…,DL),其中Dc = {D1c,D2c,…}為第c類文檔集合(1≤c≤L)和測試文檔集合T = (T1,T2,…,Tj);
2)對T和D兩類文本進行文本特征向量的
TF-IDF計算并進行相似度比較,獲得M個相似度。
3)將M個相似度導入DBM模型,訓練其所分配的權重,進而預測T類別。
算法偽代碼如下:
輸入:訓練文檔Train = (D1,D2,…,Dl)
測試文檔Test = (T1,T2,…,Tj)
文檔類別Y =? (y1,y2,…,ym)
輸出:測試文檔分類類別
Class =? (c1,c2,…,cl)
1. W = Jieba(Train,Test);//Jieba分詞文檔
2. dct = Dictionary(W);//制作字典
3. BoW(Train,Test),D = [(1,z1),(22,z2),…,(n,zk)],T = [(1,z1),(22,z2),…,(n,zk)];//BoW模型詞向量化
4. M = TF - IDF(D,T);//TF-IDF獲得關鍵詞向量
5. N = COSINE(MD,MT);//余弦相似度計算文檔相似度
6. DBM_train(Train);//DBM訓練相似度
7. Class = DBM_classify(N);//分類測試文檔
3? ?實驗分析
3.1? ?實驗環境與數據集
實驗硬件環境為Intel Core i5 8400 2.8 GHz的CPU,內存為32 G RAM,軟件環境為Windows 10操作系統以及Pycharm Professional Edition搭載Python 3.6集成開發環境。
實驗選取的數據集為2009年10月4日至2017年3月29日某省電網下發的33000張投訴工單,其中訓練文檔數量為5個類別共計10000個,測試文檔數量為23000個。
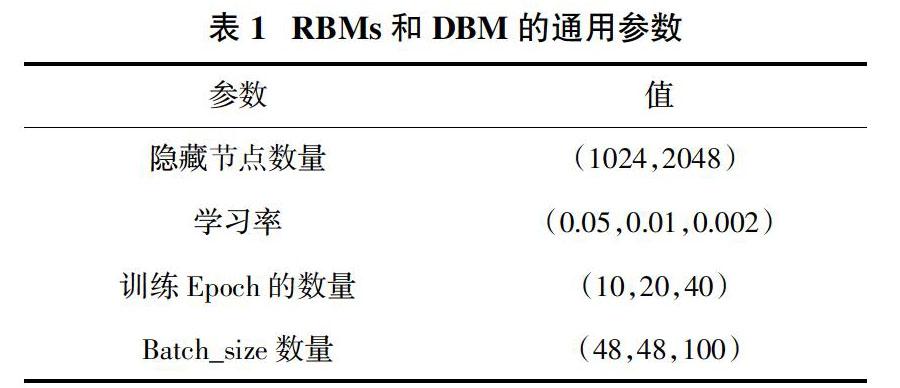
模型訓練中,部分參數值如表1、表2所示。
3.2? ?實驗結果與分析
從精確率(Precision)、召回率(Recall)以及F1得分三項指標對模型進行評價,并分別對比使用,Word2Vec向量,字典向量,TF-IDF向量,和TF-IDF 相似度向量輸入,實驗結果如表所示。
通過對比試驗可以看出,同時使用DBM作為訓練模型的情況下,所提出的數據預處理方法在三項指標上均優于其他三種方法。
使用TF-IDF 相似度向量,預處理方法對電力投訴工單進行一級分類,結果如表4所示。
通過使用改進后的DBM模型對電力投訴工單進行分類預測,準確率達到了80%。使用TF-IDF向量相似度的預處理方法,能夠很好地表示文本與類別之間的相關性,再結合DBM的分類能力,分類的結果相較于其他的處理方式,有了很大的提升。也說明了使用機器學習,加DBM這種深度學習方法的混合模型,效果更佳。
從表4可以看到,對于大部分的類別來說,具有良好的分類效果。'服務投訴'類別存在準確率偏低但是召回率較高的情況,說明模型找到了大部分'服務投訴'的類別,但是預測的結果中存在其他類別較多的情況。造成這個問題的主要原因是,'服務投訴'這個類別下面的子分類的數量要遠遠大于其他分類,并且涉及到更廣的范圍。跟其他分類的詞匯有更多的交集,造成模型的錯誤分類。
測試數據里面一共有2210個‘服務投訴類別數據,1916個‘營業投訴類別數據,531個‘停送電投訴類別數據587個‘供電質量類別數據,1179個‘電網建設類別數據,總計6423個。可以得知每個類別的數據量不是均衡的,這也是影響模型效果的一個點,某個類別的數據量不足,就會導致這個類別的權重比別的類別要低,對應的召回率就會比較低,也就是有較多屬于這個類別的樣本沒有被挖掘出來。比如‘停送電投訴這個類別的數據量是最少的,相應的召回率也就越低,只有0.34,說明該類別的樣本只有34%被成功的找出來。
精確率和召回率各有優劣勢,F1得分可以看作精確率和召回率的加權平均,同時考慮了分類模型的精確率和召回率,更加具有參考意義。最佳的得分是‘電網建設的F1得分為0.86,最低的是‘服務投訴的0.77,均值也是0.77。可以看到對于不同的類別結果仍有一定的差距。對于較差的類別還有繼續優化的空間。
據不完全統計,正常情況下僅依靠人工處理2萬張投訴工單至少需要花費4人連續工作1周時間。若將此項技術運用到實際生產應用中,僅需花費1人1-2小時即可完成處理。
4? ?結? ?論
隨著生活水平的不斷提高,用戶對供電服務的要求和維權意識也不斷提升,因此電力公司的投訴數量也呈現激增趨勢。針對人工分類效率低下的問題,提出了基于DBM的電力投訴工單分類模型。通過運用BoW模型對語料進行向量化特征提取并使用TF-IDF算法對訓練文檔和測試文檔的文本特征向量進行相似度計算,有效地解決了特征頻率差異的問題。通過對比實驗證明本文所涉及模型在多項指標上具有較大提升。
參考文獻
[1]? ? 周文杰,嚴建峰,楊璐. 基于深度學習的用戶投訴預測模型研究[J]. 計算機應用研究,2017,34(05):1428-1432.
[2]? ? 朱龍珠,徐宏,劉莉莉. 基于深度學習的95598重大服務事件識別研究[J]. 電力信息與通信技術,2018,16(11):19-23.
[3]? ? 汪靜,羅浪,王德強. 基于Word2Vec的中文短文本分類問題研究[J]. 計算機系統應用,2018,27(05):209-215.
[4]? ? 鄒北驥,郭建京,朱承璋,等. BOW-HOG特征圖像分類[J]. 浙江大學學報(工學版),2017,51(12):2311-2319.
[5]? ? 楊陽,魏曉,秦成磊. 基于Web知識的中文分詞結果優化[J].計算機應用與軟件,2015,32(12):55-58.
[6]? ? JIANG M,PAN Z,LI N. Multi-label text categorization using L21-norm minimization extreme learning machine[J]. Neurocomputing,2017,261:4-10.
[7]? ? CHINNIYAN K,GANGADHARAN S,SABANAIKAM K. Semantic similarity based web document classification using support vector machine[J]. Int. Arab J. Inf. Technol.,2017,14(3),285-292.
[8]? ? 程東生,范廣璐,俞雯靜,等. 基于極限學習機的中文文本分類方法[J]. 重慶理工大學學報(自然科學),2018,32(08):156-164.
[9]? ? 龔靜,黃欣陽. 基于隱性語義索引的多標簽文本分類集成方法[J]. 計算機工程與設計,2017,38(09):2556-2561.
[10]? 文武,李培強. 基于K中心點和粗糙集的KNN分類算法[J].計算機工程與設計,2018,39(11):3389-3394.
[11]? SALAKHUTDINOV R,HINTON G. Deep Boltzmann machines[C]//Artificial Intelligence and Statistics. 2009:448-455.
[12]? HINTON G E,SALAKHUTDINOV R R. A better way to pretrain deep Boltzmann machines[C]//Advances in Neural Information Processing Systems. 2012:2447-2455.
[13]? LESKOVEC J,RAJARAMAN A,ULLMAN J D. Mining of massive datasets[M]. London:Cambridge University Press,2014.
[14]? SUN J. JiebaChinese word segmentation tool[J].https://github.com/fxsjy/jieba,2012.
[15]? MCTEAR M F,CALLEJAS Z,GRIOL D. The conversational interface[M]. Cham:Springer,2016.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
