基于《同義詞詞林》深度的詞義相似度計算研究
2020-09-04 03:15:42孫玉泉
計算機工程與應用 2020年17期
楊 泉,孫玉泉
1.北京師范大學 漢語文化學院,北京 100875
2.北京航空航天大學 數學科學學院,北京 100191
1 引言
詞語間的語義相似度(本文簡稱詞義相似度)計算是自然語言處理中文本數據處理的基礎,隨著人工智能時代的到來,詞義相似度計算越來越多地應用到機器翻譯、人機問答、情感計算、信息抽取、生物醫學等不同領域。
目前詞義相似度的計算方法基本上可以分為兩類:一類是根據某種已有知識本體(Ontology)或分類體系(Taxonomy)進行計算;另一類是在大規模語料庫的基礎上直接統計和計算[1]。基于語料庫的方法需要在大規模精確標注語料的基礎上進行,對語料的依賴性較大,可解釋性也較差。而基于知識本體的方法依據人類的世界知識,對詞語之間的語義相似程度進行計算,具有較強的理論依據。
國外很多詞義相似度測量方法是使用WordNet 作為底層參考知識本體來實現和評估的[2]。例如Resnik等在WordNet 的“IS-A”分類體系基礎上提出了一種基于共享信息內容概念的詞義相似性計算方法。對同義詞表組內的名詞詞義分配置信值,利用分類相似性解決語義歧義問題[3]。Taieb 等提出了一種基于WordNet 層次結構深度分布的相關概念下位詞子圖量化法。該方法對WordNet 中兩個待比較詞的下位詞和深度參數比組成的子圖進行量化,并利用與“IS-A”分類體系相關的拓撲參數,計算兩個詞語的語義相似度[4]。WordNet 是目前世界上計算英語詞義相似度的主要知識本體依據。
國內中文詞義相似度計算也有采用知網作為分類詞典的方法,劉群、李素建等在知網的基礎上給出了判定詞義相似度的計算模型[1,5]。但是知網的構造者董振東指出知網的結構與WordNet 是有很大區別的,最大不同在于它不是一部義類詞典,而是一個描述概念與概念之間關系以及概念的屬性與屬性之間關系的知識系統[6-7]。《同義詞詞林》是梅家駒等人于1983 年編撰的可計算漢語詞庫,經哈爾濱工業大學研究人員擴展成為《哈工大信息檢索研究室同義詞詞林擴展版》(本文簡稱《詞林》),其內部結構與WordNet 的分類體系較為相似,因此近年來越來越多地被應用于詞義相似度計算中。
田久樂等利用《詞林》的編碼及結構特點,結合詞語的相似性和相關性,實現了一種基于路徑和深度的詞語相似度計算方法,對于兩個詞語義項s1和s2,其相似度計算公式如下:
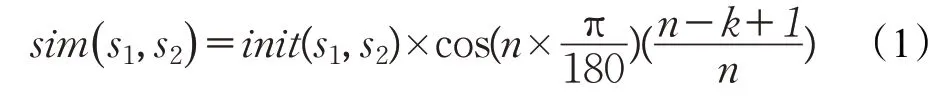
其中,init(s1,s2)是相似度初值函數是相似度初值調節參數,n是分支層結點總數,k是兩個義項在最近公共父結點中的分支距離[8-9]。
朱新華等根據詞語的分布情況,為《詞林》提出的詞語相似度計算公式如下:
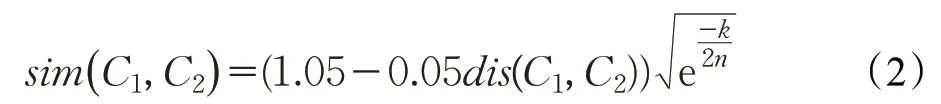
其中,分支結點數n和分支間隔數k為調節參數,dis(C1,C2)是詞語編碼C1和C2在樹狀結構中的距離函數。該文為知網也提出了改進的義原相似度計算,最后綜合考慮知網與《詞林》的動態加權策略來計算最終的詞語語義相似度[10]。
陳宏朝等提出了一種基于路徑與深度的《詞林》詞語語義相似度計算方法。該方法通過兩個詞語義項之間的最短路徑及其最近公共父結點在層次樹中的深度計算兩個詞語義項的相似度。并提出在語義詞典中任意兩個義項s1和s2的相似度計算公式如下:Depth(LCP(s1,s2))表示兩個義項s1和s2最近公共父結點的深度距離,Path(s1,s2)表示兩個義項之間的最短路徑;α為深度調節參數,β為路徑調節參數[9]。
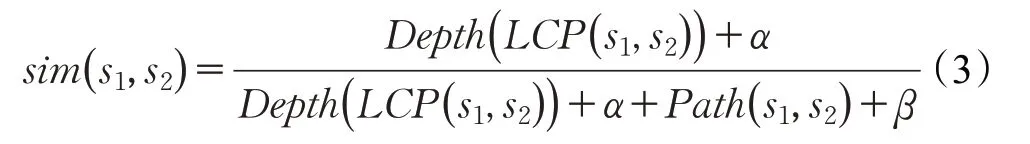
王松松等提出了一種基于路徑與《詞林》編碼相結合的詞語語義相似度計算方法,該方法使用局部敏感哈希算法將兩個詞語在《詞林》中的編碼轉換成兩個二進制,再使用海明距離來計算兩個二進制之間的距離,具體計算公式如下:
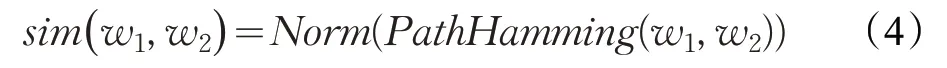
其中,Norm表示對海明距離計算結果進行歸一化處理,PathHamming(w1,w2)表示詞語w1和w2之間的海明距離[11]。
綜上,研究者設計《詞林》詞義相似度計算模型時具有以下兩個特點:(1)進一步挖掘知識體系中的相關信息,并將這些信息作為計算詞義相似度的關鍵因素;(2)進一步完善詞義相似度的計算模型,建立詞義相似度與關鍵因素之間更為合理的關系表達式。從而使得相似度計算結果更接近人工判定值,但相關算法和模型仍有需要完善的地方。
2 《同義詞詞林》組織架構分析
經哈工大擴展后的《詞林》目前共收錄詞語77 456條,分為 12 個大類,95 個中類,1 428 個小類,小類下方進一步劃分為4 026 個詞群和17 817 個原子詞群兩級。每個原子詞群對應一個義項編碼,也對應著一組同義詞條目,其中只有一個義項的詞語有68 645 個,兩個或兩個以上義項的詞語有8 811個。
《詞林》體系中將詞語分為五個層級,第一層級是大類,用1 位大寫英文字母表示;第二層級是中類,用1 位小寫英文字母表示;第三層級是小類,用2 位十進制整數表示;第四層級是詞群,用1位大寫英文字母表示;第五層級是原子詞群,用2位十進制整數表示。在這個五層級分類體系中用7 位編碼確定后就可以唯一表示一組原子詞群。第8位編碼有三種情況:“=”表示原子詞群中的詞語屬于同義詞語;“#”表示原子詞群中的詞語屬于相關詞語;“@”表示原子詞群中只有一個詞語,這個詞語在《詞林》中既沒有同義詞語,也沒有相關詞語。表1詳細展示了《詞林》中的五層、8位義項編碼情況(參見《哈工大同義詞詞林擴展版》網站:http://www.ltpcloud.com/download)。

表1 《詞林》義項編碼表
在《詞林》的編碼體系中,前面四層結點都代表抽象的類別,只有第五層的葉子結點才是具體的詞語,同一個詞語可能有多個不同的義項,即同一詞語可能在不同的原子詞群中同時存在。其中第一層級的大類代碼含義如表2所示。

表2 《詞林》大類代碼含義表
表2 中A、B、C 類多為名詞,D 類多為數詞和量詞,E 類多為形容詞,F、G、H、I、J 類多為動詞,K 類多為虛詞,L 類是難以被分到上述類別中的一些詞語[12]。大類和中類的排序遵照從具體到抽象的原則,如E 大類下面又分為五個中類,從“外形”到“境況”,如表3所示。

表3 《詞林》E大類分支義項代碼含義表
下面將《詞林》體系做形式化表示:
(1)為將不同大類的層級體系整合在一起,本文在《詞林》體系第一層級“大類”上面再增加一個根結點R,這樣《詞林》體系中的詞語根據其編碼就構成一個完整的六層結點、五層邊的樹形結構圖。
(2)在《詞林》體系中,所有詞語都在第五層的葉子結點上,將詞語集合記為S={s1,s2,…,sn},對于任意兩個葉子結點上的詞語(s1,s2),其詞義相似度值表示為S(s1,s2)。
根據以上形式化表示方式,可以把《詞林》的義項編碼轉化為如圖1的樹形結構圖。
(4)在圖1的樹形結構中,深度是指某個結點(葉子結點或父結點)到根結點的距離,用D表示;路徑是指兩個葉子結點分別到其最近父結點的邊的總和,用P表示。例如圖1 中,s1和s4的最近父結點是F31,那么s1到s4的路徑就是s1到F31的邊總數與s4到F31的邊總數之和。s1到F31的邊總數為2,s4到F31的邊總數為2,那么s1到s4的路徑P=4。結點F31的深度是其到根結點R的邊的總數,因此F31的深度D=3。

圖1 《詞林》樹形結構圖
通過上文對《詞林》的整體架構的分析,可以得出以下結論:
(1)知識本體對于詞義相似度計算起決定性作用。基于義項編碼的《詞林》樹形圖中,不同葉子結點間的路徑信息里面隱含著《詞林》中的詞義相似度信息,這些信息實際是作者在編著《同義詞詞林》時就已融入其中的世界知識。在計算詞義相似度時如果能精確解析蘊含其中的豐富信息,并將其形式化后轉化為計算機可執行算法,就可以計算出基于《詞林》的兩個詞語之間的詞義相似度數值。不同知識本體中蘊含著不同的分類體系和世界知識,實際上是其構建者對于世界知識和詞語體系認識的不同。如果用不同的知識本體做基礎去計算詞語之間的詞義相似度,即使使用相同的算法也會得出不同的結論。因此知識本體首先是影響詞義相似度計算結果的決定性因素。
(2)父結點深度與路徑具有等價關系。在引入了根結點R的情況下,《詞林》有六層結點,五層邊,所有的詞語都位于層級體系最下面的葉子結點上,因此它們與根結點R的距離(即葉子結點深度)都相同,數值為5。而對于父結點深度只有4種取值情況,D=1,2,3,4。顯然一個葉子結點的深度應該是它到其任何父結點的距離與該父結點深度之和。對于任意兩個葉子結點,它們到最近父結點的距離相等,因此兩個詞語間的路徑是它們到最近父結點距離的2倍。例如,s1和s4的父結點是F31,s1到s4的路徑P=4 ,F31的深度D為3,s1和s4到F31的邊數均為,因此父結點深度和路徑有如下關系:
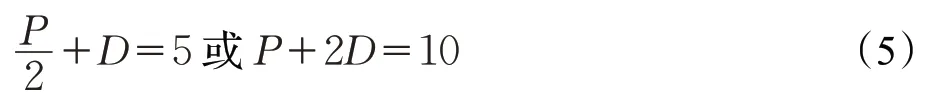
該結論說明路徑和父結點深度是兩個能夠相互表示的量,因此在計算相似度時兩者能夠互相替代,從而簡化算法。
(3)在同一個知識本體中,最近父結點F的深度對于兩個詞語的詞義相似度起決定性作用。從《詞林》體系中可以直觀地看出來,F在《詞林》體系中所處層級位置越高,D的取值越小,則s1與s2的相似度越低;相反F在《詞林》中所處層級位置越低,D的取值越大,其在《詞林》中所處層級位置越低,則s1和s2的相似度越高。因此D的取值與S成正比關系,而F的位置與S成反比關系。這從語言學角度也很容易理解,當兩個詞語所處的分支層的父結點越低,說明這兩個詞語所在的類別距離越近,兩個詞語的語義相似程度就越高,相反當兩個詞語所處的分支層的父結點越高,說明這兩個詞語所在的類別距離越遠,兩個詞語的語義相似程度就越低。詞義相似度計算問題就是將已有知識體系中的信息進行量化表達的過程,因此對知識體系中信息提取得越充分,使用得越合理,就能得到更好的計算結果。為此本文對《詞林》中與詞義相似度相關的信息進行了詳細的統計和分析。
①分析葉子結點中詞語的分布情況。在《詞林》中每個葉子結點對應一個義項編碼,且唯一代表一個原子詞群,根據義項編碼末位(即第8 位編碼)判斷,原子詞群中的詞語有三類關系:同義、相關或獨立。“獨立”的意思是該原子詞群內部僅包含一個詞語,最大的原子詞群包含572個詞,是縣名的集合。原子詞群中不同詞語數量分布情況如圖2所示。
對照組患者圍手術期低血糖發生率為15.00%,觀察組為3.33%,兩組對比差異有統計學意義(P<0.05);對照組患者圍手術期傷口感染率為18.33%,觀察組為5.00%,兩組對比差異有統計學意義(P<0.05)。見表1。
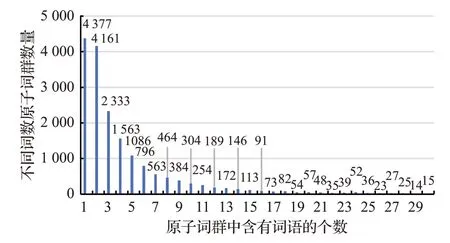
圖2 不同詞語數量原子詞群分布圖
從圖2 中可以看出,原子詞群的分布符合冪率分布。包含詞語個數越少的原子詞群在《詞林》中所占的比例越高。例如僅包含一個詞語的原子詞群數量最多有4 377 個,占比25.6%;包含兩個詞語的原子詞群有4 161個,占比23.3%;而包含30個詞語的原子詞群只有15個。
在《詞林》的構建過程中,將同一原子詞群中詞語的相似度定義為1,或者說原子詞群是《詞林》中詞義相似度計算的最小單元。因此基于《詞林》的詞義相似度計算實際上是原子詞群之間的相似度計算。僅使用《詞林》的知識無法進一步比較原子詞群內部詞語間的相似度,特別是相關性詞語的相似度無法進行進一步判斷,需要借助更多知識。
②分析不同深度上結點的數量及其分支的分布情況。
從圖3中可以看出,第一層中各結點包含的分支數存在較大差異,其中包含分支數最多的是結點B 類(物類),共有4 568個分支(具體分支情況見圖4);包含分數支最少的結點是L類(敬語類),僅有28個分支。
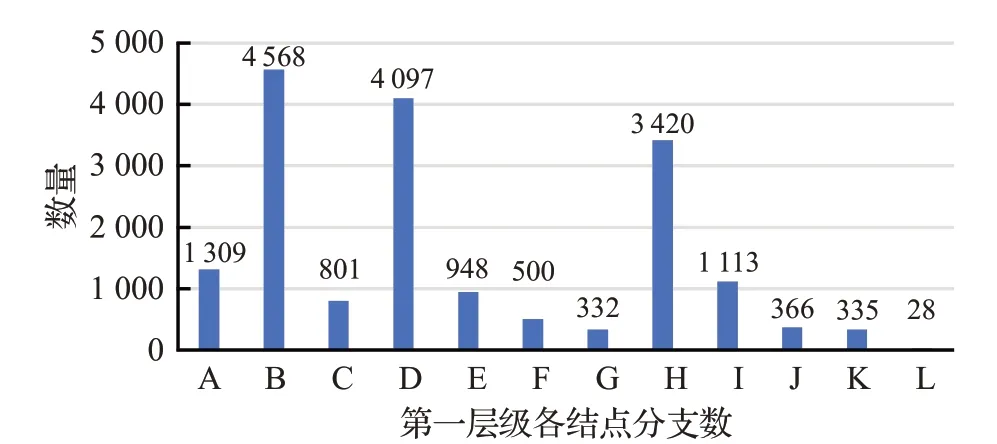
圖3 《詞林》第一層級各結點分支數量圖

圖4 B大類各結點分支數量分布圖
進一步分析第一層結點的分支情況,其中A結點包含從a到n共14個不同分支,分支中包含結點最多的有291 個,最少的有19 個(具體分支情況見圖5)。結點A的子結點Ae包含18個分支(詳見圖6)。對這些結點中的每一個結點還可以繼續分析其分支數量,直到得到每一個結點所包含的原子詞群中詞語的數量。
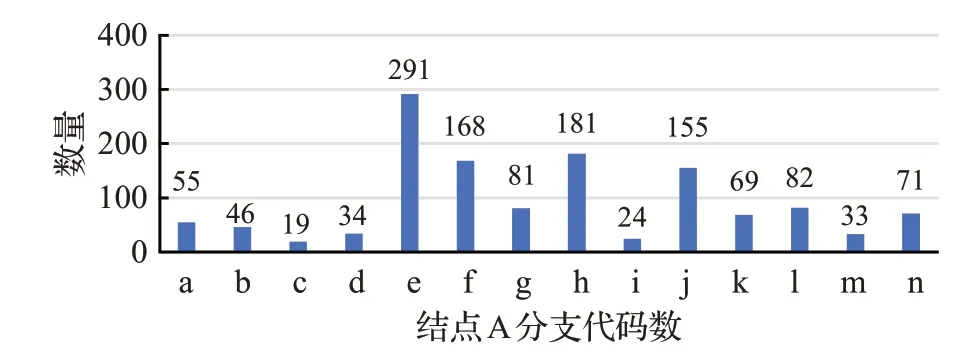
圖5 A大類各結點分支數量分布圖
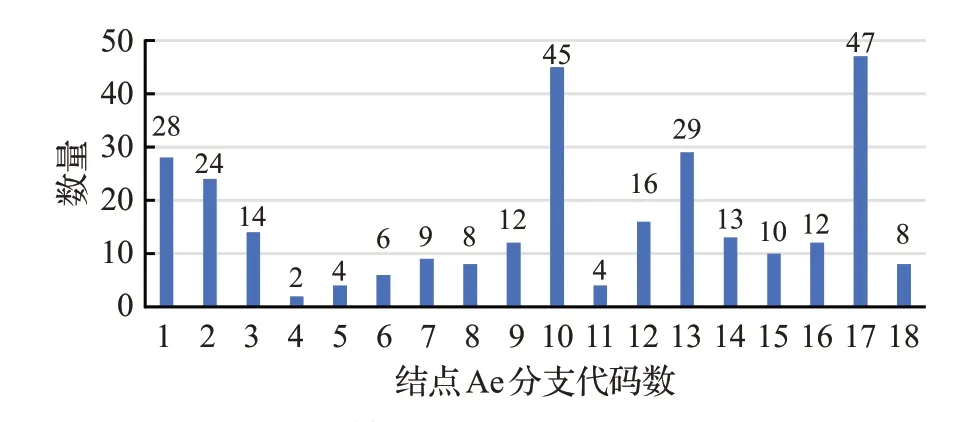
圖6 結點Ae分支數量分布圖
3 基于父結點深度和父結點深度與其分支信息相結合的詞義相似度計算模型
在基于知識本體的詞語相似度算法中,使用路徑和深度計算詞語相似度是非常重要的一類方法。如前所述在基于WordNet的英語詞語相似度計算方法中,研究者提出了各種簡單或復雜的基于路徑和深度的計算方法,這些方法又可進一步劃分為僅基于路徑的方法、基于路徑和深度的方法以及包含信息內容的方法等[4]。因為《詞林》也具有清晰的詞語路徑和深度信息,所以這些基于路徑和深度的方法都可以直接用于基于《詞林》的詞義相似度計算中。但由于WordNet 與《詞林》的組織架構不同,在WordNet 中不同的詞可能具有不同深度,這種葉子結點深度不均勻,義項遍布所有結點的組織方式與《詞林》是截然不同的。
《詞林》中所有詞語都在葉子結點上,因此都具有相同深度,如果直接使用基于WordNet 的計算公式,就會出現得到的相似度只能取到幾個有限值的情況,無法體現不同詞對之間的差異。但在《詞林》體系中這種取值也具有一定的合理性,在《詞林》體系中,詞語按照類別逐級細分,例如“人類”的語義代碼為Aa01A02=,“兄弟”的語義代碼為Aa02A07=“,森林”的語義代碼為Bh01A03=。“人類”與“兄弟”的語義類別在同一個大類A 中,而“人類”與“森林”的語義類別不同,分別在A 大類和B 大類中,因此前兩者的詞義相似度一定高于后兩者。如果用圖1的樹形結構來描述,“人類”與“兄弟”的最近父結點為處于第三層的a,其深度為2。“人類”與“森林”的父結點為R,其深度為0。所以最近父結點深度不同的兩個詞對所對應的詞義相似度必然不同。
前期文獻中的普遍結論是假設兩個詞語義項s1和s2的相似度S與它們最近父結點的深度D存在確定的函數關系,根據本文描述《詞林》結構的樹形結構圖,S與D成正比關系,即D越大時S的取值越大,反之越小,且S的取值應介于[0,1]之間,為此本文給出如下簡潔公式:

其中,λ1、λ2、λ3、λ4為調節參數。該式僅通過父結點深度D來計算兩個詞語的詞義相似度S的大小,且能很好地體現D與S的關系。
公式(3)使用了距離、路徑以及動態參數,當動態參數β取常數時,本文所提出的公式(6)實際與公式(3)是等價的。因為在公式(3)中Depth和Path分別是加權后的深度和路徑,且每層只有一個權值,若將公式(5)代入公式(3)所得結果實質上與公式(6)結果等價。因為在《詞林》中路徑的深度層次有限,所以詞對間相對位置的情況是有限的,因此使用公式(6)只能得到幾種有限詞義相似度取值。也就是說公式(6)對應函數的定義域為{0,1,2,3,4},因此函數的值也是有限的,根據函數值與D成正比的關系,該函數是一個階梯函數。根據上面的分析,在《詞林》體系中不同階梯會對應不同層級的詞語,從語言學角度來看這樣的結果具有一定的合理性。為使得詞語語義相似性得到更好的描述,可以通過調整函數表達式或者加入更多語言學信息來進一步計算出更合理的詞義相似度結果。公式(3)通過使用隨詞對變化而變化的動態調節參數β來實現相似度值的變化,其目的是為了克服只有幾個有限值的不足,但是用這種做法所調節的幅度及目標值卻都是不可控的,而且從語言學角度的可解釋性不強。上述深度是表示兩個義項分類差異的結果,在調整基于父結點深度相似度階梯取值時,最好不要改變其相似度階梯,因此應在階梯取值基礎上進行微調。根據這一思想,本文使用任意兩個義項s1和s2最近父結點的分支信息構建微調項,對公式(6)進行微調后給出如下微調結果:
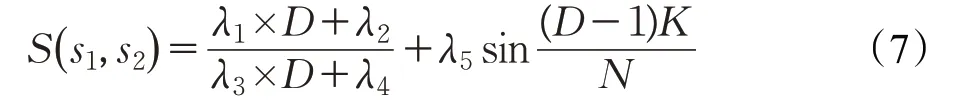
其中,D為最近父結點深度,N為其最近父結點所包含的分支總數,K為兩個義項所在分支的間距。根據公式(6)中函數取值的特點及其對最大值和最小值擬合不足的問題,通過設置調整參數(D-1)來改進端點處的擬合情況,為避免微調項改變和否定父結點深度確定的相似度層級問題,引入正弦函數進行調節。
4 實驗與分析
Rubenstein 等讓51 名被試對65 個詞對(簡稱為RG65)進行“同義判斷”,這65個詞對的語義從“高度相似”到“語義無關”不等,被試需要根據對這些詞對的語義相似性判斷,在0.0~4.0 范圍內給詞對打分[13]。后來Miller 等從 RG65 中提取了30 個詞對(簡稱為MC30),這30對樣本中有10對詞語的語義具有高相似性,有10對詞語的語義具有中相似性,還有10 對詞語的語義具有低相似性,然后從被試樣本中抽取38 份樣本作為MC30的人工語義相似性判斷結果[14]。本文也以此作為判斷標準。
本文將在《詞林》的基礎上,參考MC30人工判別結果,使用魚群算法建立描述詞義相似度的關系模型,以期突破根據先驗經驗建立函數模型的局限性。人工魚群算法是李曉磊等人于2002年提出的一類基于動物行為的群體智能優化算法。該算法是通過模擬魚類的覓食、聚群追尾、隨機等行為在搜索域中進行尋優,是群體智能思想的一個具體應用[15]。由此本文對公式(6)和(7)中的系數分別表示為4維和5維向量Λ1,Λ2,這樣可以把待優化的參數看作人工魚個體,通過構建魚群分別尋找最優參數。首先使用魚群算法對公式(6)中的系數進行尋優,最后得到的系數分別為:λ1=0.981 1,λ2=0.497 7,λ3=0.124 4,λ4=4.461 2 。
再使用魚群算法對公式(7)中的系數進行尋優,最后得到的系數分別為:
λ1=0.836 6,λ2=0.443 1,λ3=0.167 7
λ4=3.779 3,λ5=0.098 7
將第一組系數代入公式(6)得到基于父結點深度的詞義相似度計算方法,將第二組系數代入公式(7)得到基于父結點深度與其分支信息相結合的詞義相似度計算方法。使用這兩個方法分別對MC30 進行詞義相似度計算,計算結果如表4所示。
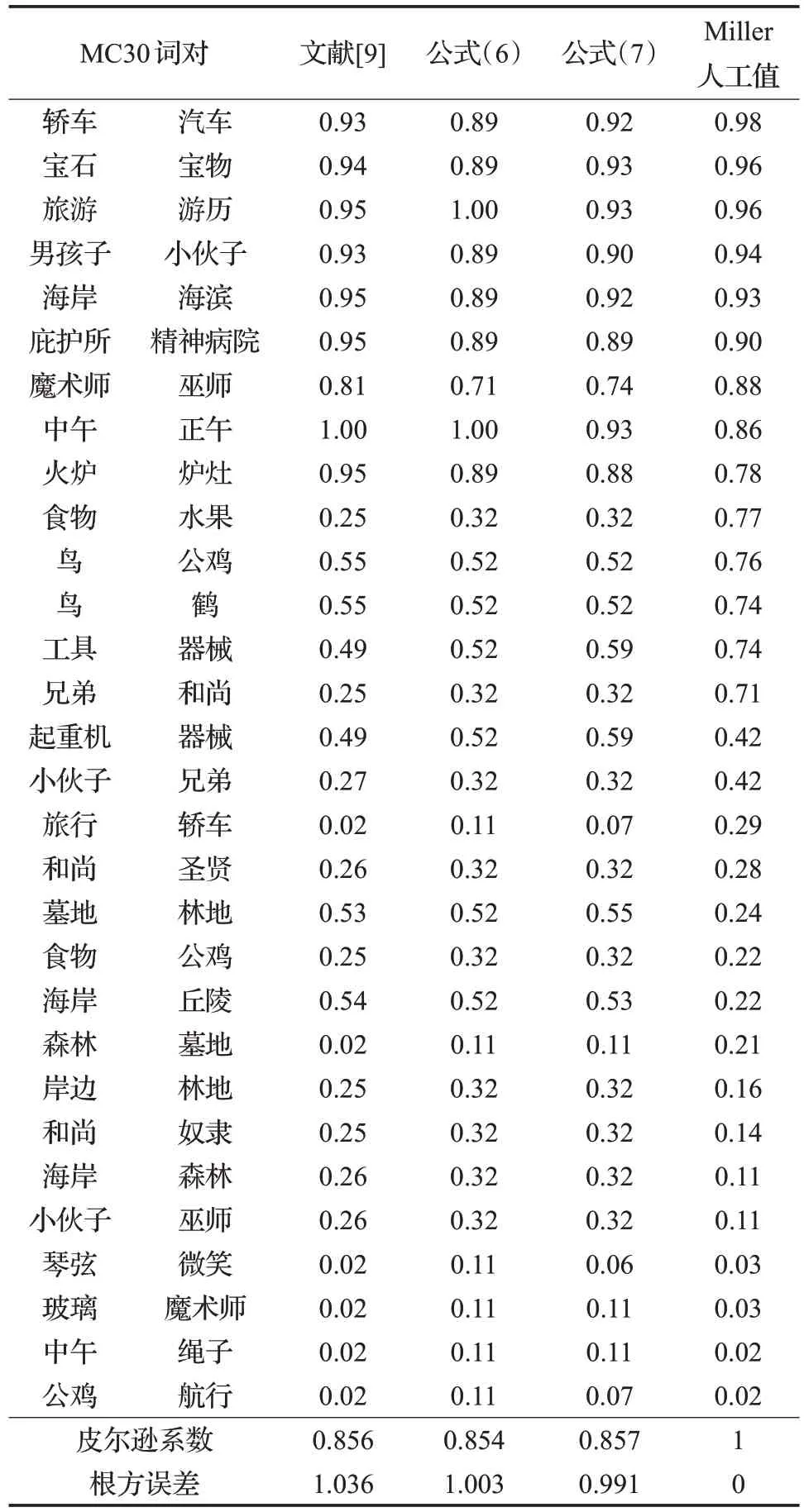
表4 MC30詞對實驗結果對比表
表4 中分別列出了公式(6)和公式(7)的相似度計算結果,以及文獻[9]的結果,從中可以看出,公式(6)雖然僅使用父結點深度信息,但仍能得到較好的計算結果,其結果與人工值間的皮爾遜系數為0.854,與文獻[9]的結果0.856 僅有微小差異,均優于該文獻中列出的其他方法,這說明在《詞林》的框架體系中,父結點深度對相似度起到決定性作用。此外還計算了根方誤差,該值是使用不同算法計算MC30 詞義相似度結果與人工值之差的平方和再開根號,顯然該值較文獻[9]相應結果更小。公式(7)不僅使用了父結點深度信息,還將兩個詞最近父結點的分支信息結合了進來,因此計算結果得到了進一步提升。具有最高的皮爾遜系數和最小的根方誤差。
顯然在各種方法的計算結果中均存在與人工值差別較大的義項,例如“食物”和“水果”這一組詞對,其人工判定值較高而《詞林》中計算的值都很低。在《詞林》中兩個詞語的編碼分別為Br03A01=和Bh07A01=,并且被分在“物品”和“植物”兩個不同的中類里面,因此其相似度較低。這種差異實際上是《詞林》和人工判別方法所使用的知識體系之間存在的差異,而本文算法能較好地刻畫《詞林》體系中所蘊含的詞義相似度信息。
此外造成這種結果的原因還可能來自于不同語言間的差異,因為人工判定值是基于英語詞匯進行的,而上述算法都是翻譯為對應的漢語詞匯后基于《詞林》進行的。這種現象從索緒爾結構主義語言學的基本觀點來看就很容易理解,語言是由能指和所指構成:能指是指語言的音響和形象,即語言的讀音和書寫形式;所指是指語言的概念和內容。語言是一個符號系統,具有任意性,這種任意性的關系又叫約定性,即符號的形式和意義的結合是由社會“約定俗成”的,而不是它們之間有什么必然、本質的聯系。因此不同符號體系、不同語言系統中的所指對應的能指可能不盡相同,而不同語言體系中能指所要表示的所指可能也會存在一定差異。因此不同語言體系的人在表達同一個所指時,因為能指的不同可能就會存在一定的理解差異,這樣就造成了在不同語言體系中,所指相同的情況下,能指之間的詞義相似度判斷也會存在一定的差異。
5 結語
(1)本文指出在《詞林》中父結點深度和路徑是一對等價概念,基于父結點深度的詞語的詞義相似度計算方法利用簡單的計算公式就能得到較為理想的計算結果。算法簡潔便于其在相關工作中的使用,如短語結構相似度或句子相似度的計算。算法簡潔使得算法更能體現詞義相似度計算所需的核心知識,在《詞林》體系中父結點深度是詞義相似度的決定性因素,而不是分支信息,分支信息對詞義相似度的計算只能起到微調作用。給分支信息賦予過高的權重從語言學角度來看也很難解釋。此外,使用核心知識可以避免過擬合現象的發生,使得算法具有更好的泛化能力和適應性。
(2)在實驗過程中發現有些詞語的相似度與人工標注值存在較大差異,除進一步改善計算方法外,英漢兩種語言在語言符號的音義表達系統中存在差異這一現象是客觀存在的,因此英語詞語之間的詞義相似度與其在漢語中對應的詞語之間的詞義相似度可能總會存在一定的差異。因此本文在相關系數達到實用性要求的條件下,主要關注提高算法易用性和分析算法所體現的語言學原理。
(3)不同知識本體建立者因為對世界知識理解的不同,其構建的知識本體也會存在較大差異,因此《詞林》和WordNet對詞語相似度的體現也必然存在差異,這對基于兩個知識本體分別判斷詞語之間的詞義相似度會有較大影響。
(4)由于《詞林》框架設計原因,目前基于《詞林》的詞義相似度算法都是針對不同原子詞群間的詞語進行的,相同原子詞群內部詞語間的相似度或相關度判別需要進一步借助其他知識本體,如知網中的信息才能進行,這是下一步需要研究和關注的內容。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
開放教育研究(2020年2期)2020-03-31 01:54:14
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
現代語文(2016年21期)2016-05-25 13:13:44
新聞傳播(2015年10期)2015-07-18 11:05:40
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
