基于運動篩選和3D卷積的視頻早期煙霧檢測
2020-09-04 03:16:24高聯欣胡泳植馮宇浩
計算機工程與應用 2020年17期
高聯欣,魏 維,胡泳植,馮宇浩
成都信息工程大學 計算機學院,成都 610225
1 引言
森林是地球生態系統的主體,在調節氣候、涵養水源、防風固沙、改善土壤等方面起著重要的作用。而森林火災則是突發性強、破壞性大、難以控制的自然災害,一旦發生森林大火,就會造成大量的自然資源和人類財產的損失。在火災發生前期會產生偏白色的煙霧,它與云、水霧等自然景象有很大的相似性,檢測難度大,但是若能在早期檢測出這一顯著的視覺特征,就能提早預警,將火災扼殺在搖籃,從而將損失降到最低。
隨著計算機視覺技術的發展,相比于傳統使用煙霧報警器、瞭望臺、人工巡邏的方式來發現火災煙霧,基于視頻監控的方法更加高效和節約成本。Chen 等人[1]通過實驗發現煙霧的R、G、B 三個通道的值非常接近,灰度值的范圍在80到220之間,并提出了基于幀差法的運動分割后進行像素級分類煙霧的方法。Tian等人[2]將視頻每一幀分塊后,利用大氣散射模型推導出煙霧圖像的形成模型,然后提出一種雙重過完備字典的方法,將煙霧檢測轉為了凸優化求解的過程。Ma 等人[3]對視頻序列進行線性增強后,利用低秩矩陣恢復的方法獲取煙霧的顯著性,然后使用塊匹配算法消除干擾后輸入支持向量機進行煙霧識別。Russo等人[4]利用背景減法從視頻幀中提取前景,然后基于形狀獲取感興趣區域并計算局部二值模式的值和直方圖,形成特征向量,輸入Bhattacharyya 系數和支持向量機相結合的分類器中進行煙霧檢測。Yuan 等人[5]根據煙霧顏色設計了基于模糊邏輯的檢測規則,然后利用擴展卡爾曼濾波器對檢測規則的輸入和輸出進行重構。Wang 等人[6]通過手工設計煙霧的顏色、模糊、輪廓、主運動方向等特征輸入支持向量機進行檢測。Vijayalakshmi[7]使用模糊C均值的方法進行煙區定位檢測。
然而,基于傳統計算機視覺的煙霧檢測非常依賴人工設計的特征,這可能導致煙霧圖像的內在特征被忽略掉。隨著深度學習的發展,卷積神經網絡在圖像識別上獲得了巨大的成功。它的最大特點是不需要手工設計健壯的特征,而是從輸入數據中自動地進行特征學習。在眾多的圖像比賽中,如ImageNet,卷積神經網絡獲取的特征對圖像的識別率要遠遠高于人工設計的特征。
Hu 等人[8]提出了一種基于時空卷積神經網絡的煙霧檢測方法,將相鄰幀的煙霧光流圖輸入時間流網絡獲取煙霧運動信息,將單幀煙霧圖片輸入空間網絡獲取靜態特征,然后融合獲取的兩部分特征輸入支持向量機進行分類,該方法基于相鄰幀提取光流,若煙霧運動緩慢則光流效果較差。Luo等人[9]通過背景動態更新和暗通道先驗算法檢測可疑區域,再將可疑區域輸入五層神經網絡進行識別。Yuan 等人[10]受 GoogleNet Inception 模塊的啟發,提出了DMCNN 網絡來檢測煙霧,相比于ZF-Net、VGG16、Inception-v3,獲取了更好的效果。然而Luo 和Yuan 的方法沒有考慮煙霧的時間信息。Yin等人[11]設計了獨立的兩個網絡分別學習煙霧空間特征和運動特征,之后輸入RNN 網絡以循環的方式融合來進行檢測識別煙霧,該方法網絡過多,計算量大。Hu等人[12]將卷積神經網絡和循環神經網絡相融合,將煙霧和其對應的光流圖輸入網絡進行檢測,該方法進行了光流的計算,開銷較大。Zeng等人[13]通過對現有目標檢測算法Faster-RCNN、SSD、R-FCN的特征提取部分進行修改從而適應煙霧的檢測。該方法針對中后期擁有顯著顏色特征的煙霧效果較好,但是對早期顏色特征不顯著的煙霧效果不好。
針對上述問題,本文提出了基于運動篩選獲取疑似煙霧塊,并使用單獨一個多尺度3D 卷積神經網絡同時獲取煙霧的空間信息和時間信息的早期煙霧檢測方法。該方法能夠較好地檢測出早期煙霧,極大降低誤報率。
2 算法設計與實現
為了能適應復雜環境下的早期煙霧檢測,算法流程如圖1所示。
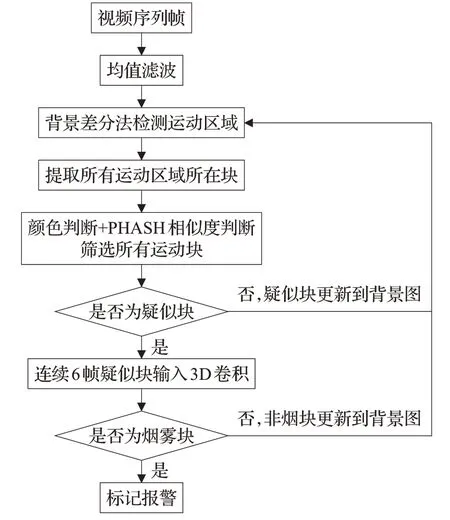
圖1 基于運動篩選和多尺度3D卷積的視頻早期煙霧檢測算法流程圖
2.1 運動篩選
2.1.1 視頻序列預處理
算法首先將視頻序列標準化為320×240的尺寸,然后對視頻幀進行了均值濾波的操作來減輕視頻幀中的噪聲對后續背景差分法的影響。均值濾波算法公式如下所示:
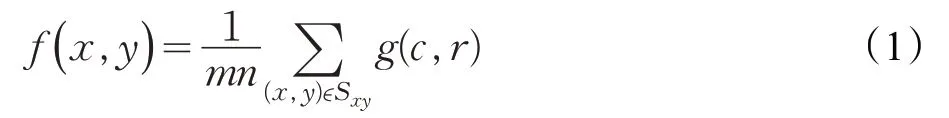
其中,g(c,r)表示原始圖像,f(x,y)表示均值濾波后得到的圖像,并令Sxy表示中心點在(x,y)處,大小為m×n的濾波窗口。
2.1.2 背景差分檢測運動區域
常用的運動檢測方法有幀差法、混合高斯模型和背景差分法三種算法。幀差法適用于具有一定運動速度的物體,由于煙霧可能存在運動緩慢的狀態,幀差法將很難捕捉到該條件下煙霧的運動;混合高斯模型需要對背景像素進行建模,容易將緩慢運動的煙霧判為背景;背景差分法則可以通過對視頻第一幀或者前幾幀進行背景幀的建模,將之后獲取到的視頻幀與該背景幀進行比較,從而很好地檢測到細微的運動。算法將輸入視頻進行濾波后的首幀作為背景圖,之后對其進行動態更新。背景差分算法如公式(2)、(3)所示:
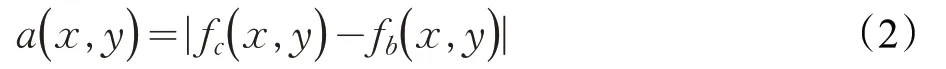
其中,fc(x,y)、fb(x,y)分別代表當前幀和背景幀,a(x,y)代表當前幀和背景幀對應像素的差值的絕對值的差值圖。
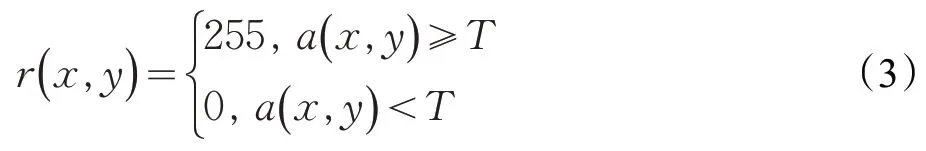
由于背景像素會存在微小變化,并且還存在噪聲的影響,故對差值圖a(x,y)進行二值化操作得到r(x,y),將大于等于閾值T的像素值設置為255作為運動像素,小于T的設置為0 代表背景,在實驗當中將T值取10 可以得到較好的結果。
背景差分法能夠檢測到細微的運動但無法隨著時間動態地更新背景,在光照變化劇烈或存在較多運動物體的場景下會檢測出大量的干擾目標,為了減少后續算法的運算量,還需要對背景差分所檢測出的所有運動塊進行篩選,選擇煙霧可能性較大的塊進行檢測,同時將不符合條件的塊更新到背景幀,從而實現動態的背景更新。算法將視頻幀劃分為10×10 共計100 個區域塊,并按照2.2節方法計算背景差分獲取的運動區域所對應的塊。基于以上分析,本文提出了基于RGB 顏色空間和均值HASH算法的兩步運動區域篩選的算法。
2.1.3 RGB顏色判斷與均值HASH算法
通過實驗發現,當煙霧慢慢出現,煙霧所在塊的RGB 圖像中B 通道的像素值呈現逐漸上升的趨勢。故對運動塊取B 通道的像素值與背景塊的B 通道像素值相減后求和,若大于0則送入下一步檢測,若小于0則將這一個運動塊判為背景更新到背景圖。
然后采用均值HASH算法對基于RGB顏色空間篩選后的運動塊進行二次篩選,其目的是為了篩選出與背景區分度較大的運動塊。
均值HASH算法首先將32×24的運動塊縮放到8×8的大小,以去除圖像的高頻和細節信息,然后將圖像轉化為灰度圖,計算所有64個像素的灰度平均值,之后將圖像的每一個灰度值和平均值相比較,大于等于平均值則記作1,小于平均值則記作0,這樣就得到了64位由0和1組成的能代表這張圖像的特征的一串hash編碼,其流程如圖2所示。
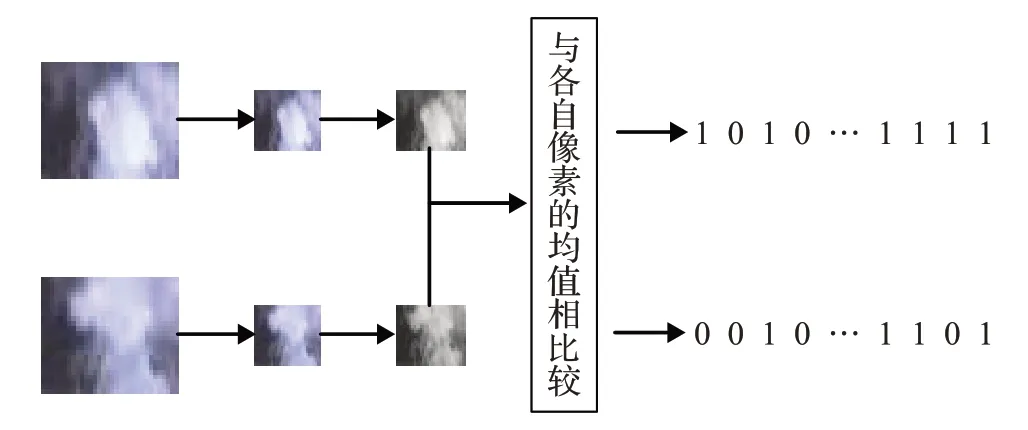
圖2 均值HASH算法流程圖
通過比較背景塊和運動塊的64位hash編碼的漢明距離是否大于閾值D就可以進行相似度的判斷,從而對運動區域進行篩選,不符合條件的塊更新到背景圖,實驗中D設置為3。
RGB 顏色判斷和均值HASH 算法組合篩選運動塊的效果如圖3 所示。其中紅色方框代表顏色判斷所篩選的運動區域,黃色橫線代表均值HASH算法在顏色判斷的基礎上進一步篩選后的結果。

圖3 顏色判斷和均值HASH算法篩選運動區域
實驗結果顯示,經過提出的兩步篩選算法,能夠很好地將無關塊去掉,從而得到疑似煙霧塊。
2.2 背景動態更新
本文在RGB 顏色判斷、均值HASH 算法中對非疑似塊以及下文的3D卷積中判斷為非煙霧塊的區域進行背景動態更新的算法如算法1所示。
算法1

其中x,y,w,h為待更新區域的起始x,y軸坐標與寬w和高h,通過算法獲得的xl,xr,yu,yd為待更新區域所對應塊分別在x軸和y軸的起始塊和結束塊。最后判斷塊是否滿足外部算法(顏色判斷/均值HASH/3D卷積)條件,若不滿足則將當前幀所對應的塊替換掉背景幀的相應塊,從而實現背景的動態更新。
2.3 多尺度3D卷積神經網絡
3D 卷積神經網絡的輸入是多幀圖片組合成的塊,每一個塊中包含了所對應目標的空間特征和該時間段的運動時間特征,2D 卷積神經網絡的輸入則只是單幀的圖片,如圖4 所示。不同于2D 卷積只能提取數據的空間特征,3D 卷積可以從多幀圖片中同時提取數據的時間和空間特征,例如文獻[14]使用3D卷積來捕捉視頻流的空間和運動信息,從而實現動作識別。
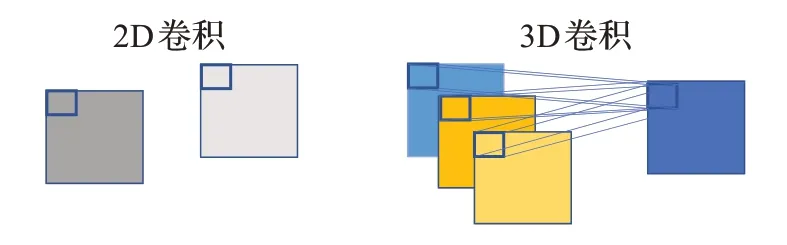
圖4 2D卷積與3D卷積
在視頻序列中,由于煙霧存在運動狀態,有隨時間變化的顏色、紋理和形狀等特征,為了捕捉連續視頻幀中的這些特征信息并讓特征多樣化,使用3D 卷積從不同尺度去提取煙霧的特征是非常適合的,于是設計了如圖5所示的多尺度3D卷積結構。
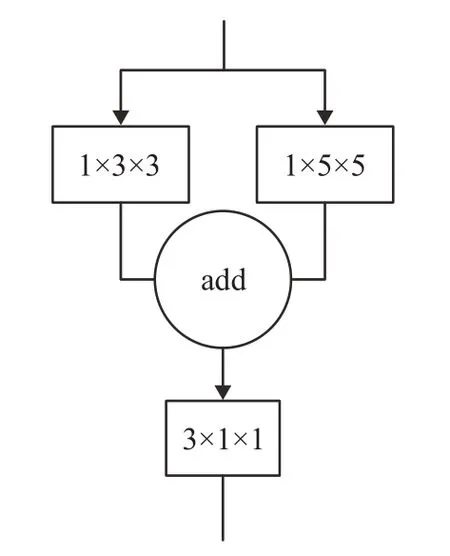
圖5 多尺度3D卷積結構
圖5中1×3×3和1×5×5卷積用于提取煙霧圖像的不同尺度的空間信息,之后將其融合在一起,保持多尺度特征的共存,最后使用3×1×1的卷積進行多幀之間的時間采樣。最終將這樣的3D 模塊進行堆疊,就得到了多尺度3D卷積網絡(6M3DC)。結構圖如圖6所示。
6M3DC 網絡的每一個輸入為連續6 幀圖像所組成的塊,每一個塊里面包含了某一時刻目標對應的運動狀態和空間特征,網絡的目的為通過學習每一個塊中目標空間特征和運動特征,從而獲得目標的空間與時間特征。網絡的每一個Block 結構都如圖3 所示,一共7 個Block。除了第一個Block,每一個Block 前面都接上了BN層(Batch Normalization),在提高訓練速度的同時可以防止隨著網絡加深而產生的梯度擴散的問題,最后使用Global Average Pooling 3D 來增強特征圖內的響應并且不會增加網絡的參數量,最后接上兩個神經元的Fully Connected Layer進行分類。若6M3DC判斷塊為非煙霧,則按照2.2 節方法將塊更新到背景圖;為煙霧,則進行標記預警。各模型網絡參數如表1所示。
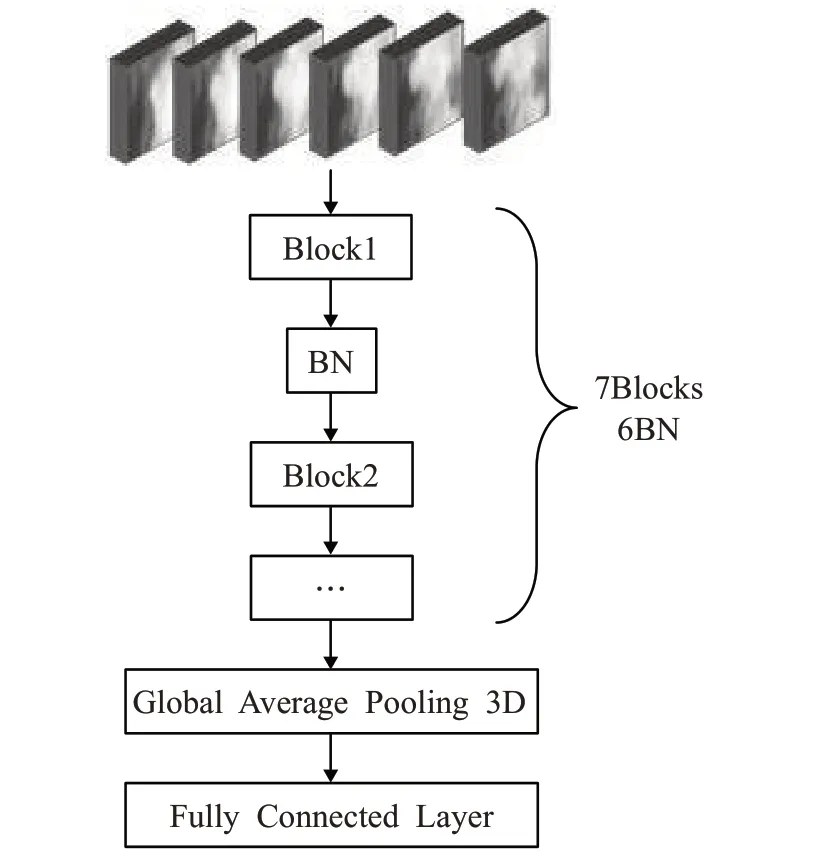
圖6 6M3DC網絡結構圖
3 實驗分析與結論
實驗基于Keras 來構建和訓練所提出的3D 卷積網絡,所有實驗均在配備Inter?Core? i5-8400 CPU @2.80 GHz 2.81 GHz和NVIDIATeslaM40GPU的PC上運行的Win10和Ubuntu16.04操作系統中進行的。
由于煙霧視頻沒有統一完善的公開數據集,本文的煙霧數據集來自土耳其比爾肯大學、內華達大學和中國科學技術大學的公開煙霧數據庫。訓練集從部分煙霧視頻中進行裁剪,并對其進行水平翻轉的數據增強后得到,如圖7所示。
訓練集包含正樣本10 296組,負樣本10 068組的6×32×24×3的煙霧塊。測試視頻如圖8所示,其中Video1~Video3 為中近距離快速運動的煙霧,Video4~Video6 為遠距離緩慢運動煙霧。
3.1 評定標準
視頻煙霧的檢測主要從精確率、召回率和F-Measure三個方面來進行算法的評測,精確率是指預測為正的樣本中有多少是對的,包括把煙霧預測為煙霧(TP)和把非煙霧預測為煙霧(FP);召回率是指樣本中的正例有多少被預測正確了,包括把煙霧預測為煙霧和把煙霧預測為了非煙霧(FN);為了防止精確率和召回率出現矛盾的情況,使用F-Measure來綜合考慮。公式如式(4)~(6)所示:
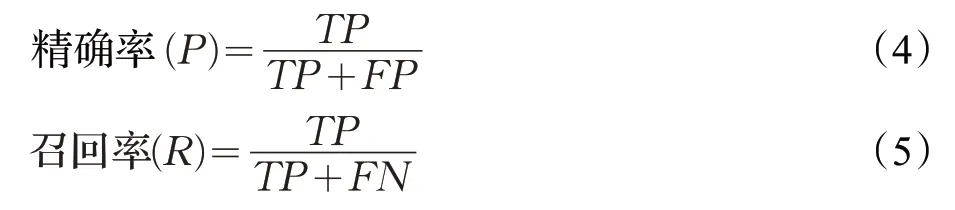
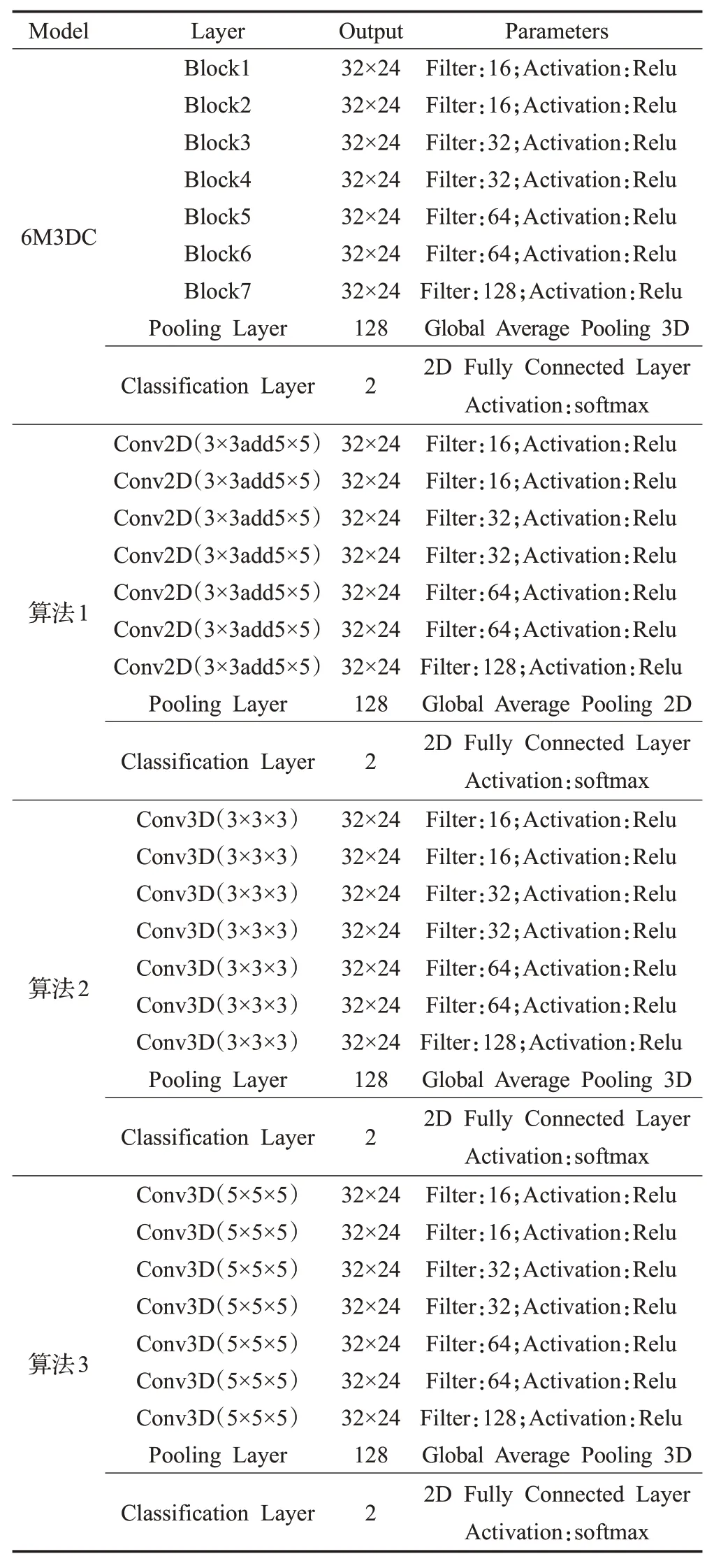
表1 各模型網絡參數
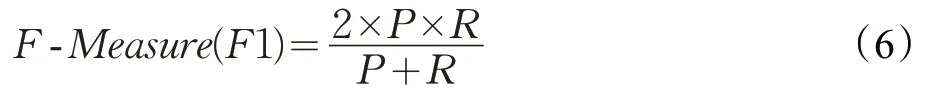
3.2 背景建模有效性驗證
為了驗證背景建模的有效性,將本文算法分為是否更新背景模型的兩組對照實驗,實驗結果如表2所示。
實驗結果顯示,在精確率方面,未進行背景更新時,煙霧識別的平均準確率遠小于進行背景更新時,并且在環境較為復雜的V3 和V5 視頻中出現了大量的誤檢。在召回率方面,是否進行背景更新差異不大。綜上所述,對背景進行建模,能夠更加穩定地檢測各種環境下的煙霧。

圖7 部分煙霧訓練數據集

圖8 煙霧測試視頻
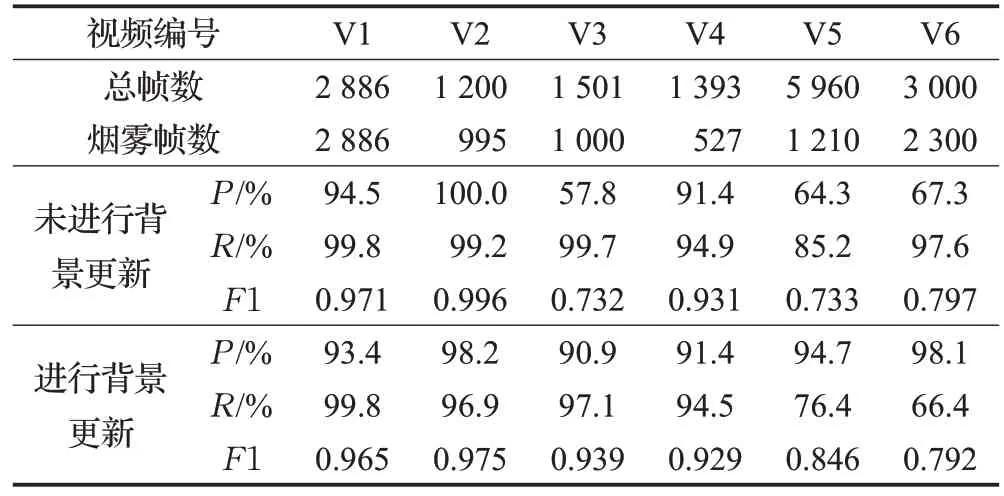
表2 背景建模對照試驗
3.3 與2D卷積相比較
為了驗證本文提出的3D 卷積網絡效果好于2D 卷積網絡。在相同條件下,將圖4 的3D 卷積結構去掉了最后的3×1×1 卷積,將1×3×3 和1×5×5 卷積修改為3×3和5×5 的2D 多尺度卷積,將其作為算法1,并與同樣為2D卷積的Yuan[10]的算法進行實驗對比,如表3所示。
實驗結果顯示,2D 卷積在對煙霧視頻進行檢測時擁有較低精確率和較高的召回率,但非常不穩定,對不同環境下的煙霧檢測差異較大,究其原因是在檢測中存在與煙霧空間特征相似的干擾物,從而產生了誤報。而3D 卷積除了從空間特征的角度,還會在時間角度上進行檢測判斷,從而大大提高了精確率和穩定性。
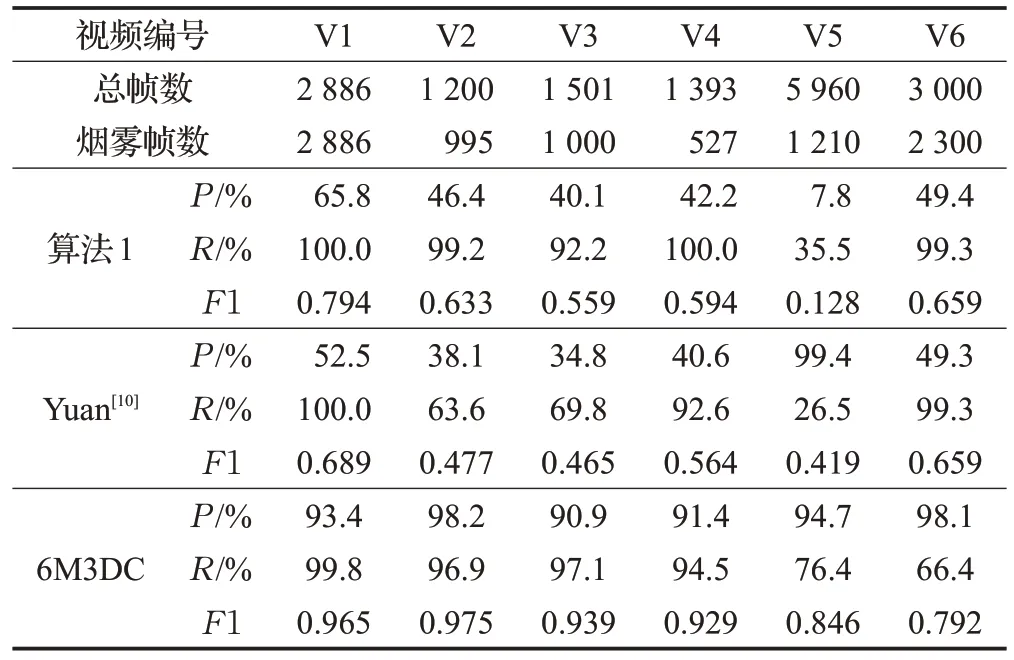
表3 6M3DC與2D卷積相比較
3.4 與3D卷積相比較
為了驗證本文提出的3D 卷積的有效性,將圖4 的卷積結構分別替換為單一的3×3×3和5×5×5的的3D卷積作為算法2和算法3,并與同樣為3D卷積的薛繼光[15]的算法進行比較,如表4所示。
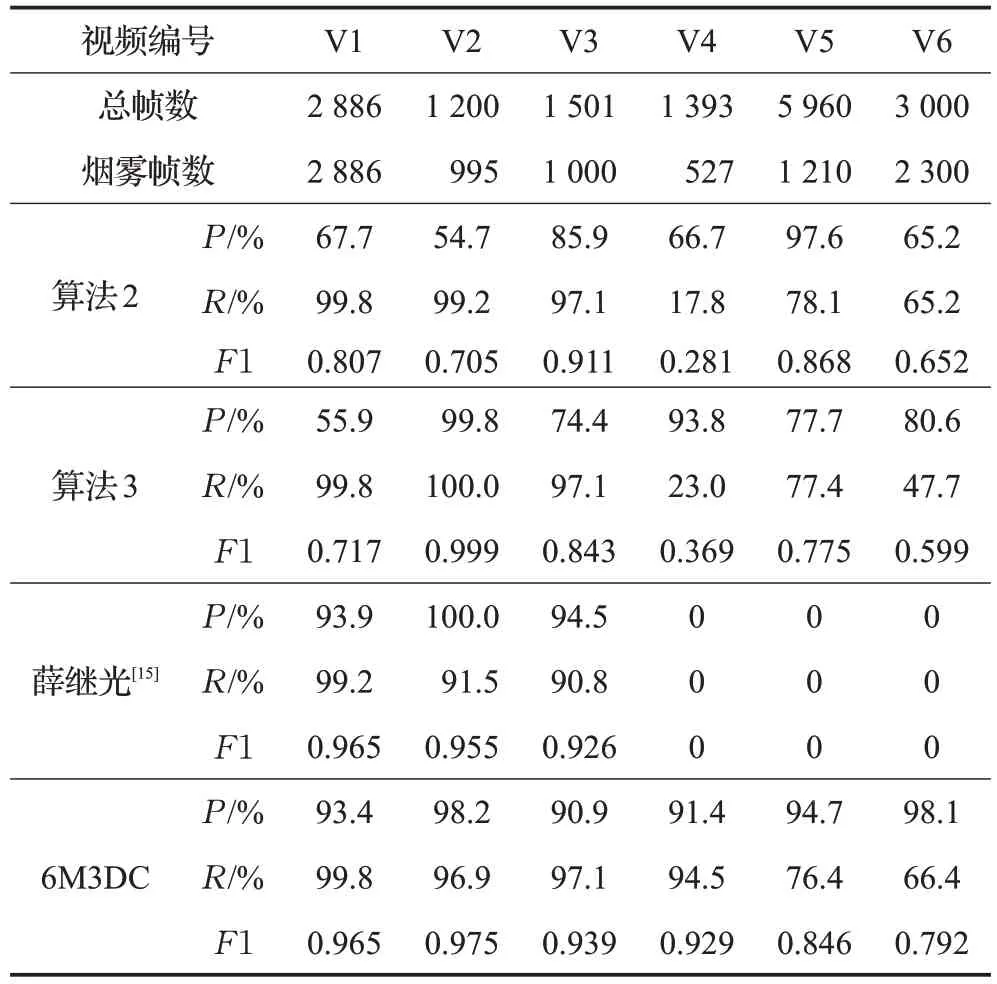
表4 6M3DC與其他3D卷積相比較
實驗結果顯示,對于V1~V3的中近距離的煙霧,所有3D 算法都擁有著較高的平均召回率,但是精確率存在著較大的差異,薛繼光[15]和6M3DC 的平均準確率遠遠高于算法2和算法3;對于V4~V6遠距離的煙霧,由于距離遠,存在著運動不顯著的問題,所以相比于中近距離煙霧,整體召回率有較大的下降,但6M3DC的平均召回率和平均準確率都要遠遠優于其他算法。薛繼光的算法無法對遠距離煙霧進行檢測的原因是其在運動處理時采用了幀差法,無法檢測到緩慢運動的煙霧,致使其后續網絡無法進行檢測。
3.5 實驗結果可視化
為了驗證本文算法的有效性,將算法1、算法2、算法3和本文算法進行了可視化,如表5所示,可見本文算法在不同環境下能夠較為精確地覆蓋所有煙霧區域。

表5 實驗結果可視化
4 結束語
本文設計的運動篩選和6M3DC網絡相結合的視頻早期煙霧檢測算法,利用RGB顏色判斷、均值HASH算法和多尺度3D 卷積神經網絡,對中近距離的煙霧的平均召回率達97.9%,平均準確率達94.2%;對遠距離煙霧的平均召回率達79.1%,平均準確率達94.7%,能夠較好地適應不同場景下的煙霧檢測。未來的工作計劃是對運動區域的篩選進行進一步研究,并構建更為有效的卷積神經網絡以適應緩慢運動的煙霧的檢測。
猜你喜歡
汽車工程師(2021年12期)2022-01-17 02:29:54
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
當代陜西(2020年14期)2021-01-08 09:30:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
海峽科技與產業(2016年3期)2016-05-17 04:32:12
