基于微博關注網絡的轉發預測算法研究
2020-08-21 09:09:32劉超姚耿楊宏雨
數字技術與應用 2020年7期
劉超 姚耿 楊宏雨

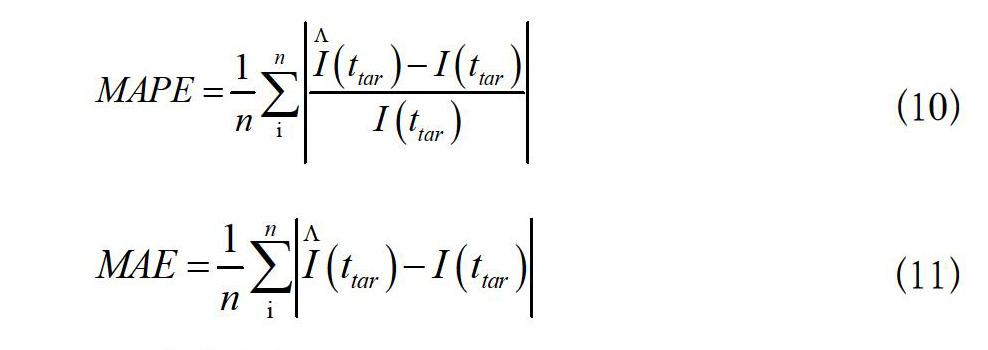
摘要:針對目前研究轉發預測的方法忽視了微博傳播過程中用戶關注網絡的問題,基于微博信息的轉發機制,結合傳染病建模理論,提出一種基于微博關注網絡的轉發預測模型。首先建立微博轉發者與其被關注粉絲之間的數量關系,然后建立微博傳播者預測模型。微博數據集上的實驗結果表明,與基準模型相比,該模型能夠取得更好的預測效果。
關鍵詞:微博;預測模型;信息傳播
中圖分類號:TP391.9 文獻標識碼:A 文章編號:1007-9416(2020)07-0121-04
0 引言
在線社交媒體和社交網絡已成為人類生活中不可替代的重要部分,例如新浪微博作為國內最活躍的社交網絡之一,在2018年其月活躍用戶達4.62億,連續三年增長數量超過7000萬[1]。在線社交網絡已經成為互聯網時代最重要的人際交互平臺,使得虛擬網絡成為當今社會熱點話題和輿情傳播的主要渠道。在此背景下,預測用戶生成內容的受歡迎程度,其在眾多應用中的實用價值而引起了廣泛關注[2],因此預測信息傳播的流行程度已成為了在線社交網絡研究的重要內容。
微博作為中國最具影響力的社交媒體平臺之一,對微博流行度的預測已經成為當前的研究熱點。由于微博的轉發數據較為容易獲取,并且微博轉發量能夠反映微博在一段時間內的熱度,因此一般采用微博的轉發量作為微博流行度的量化指標,從而將對微博的流行度預測轉化為對微博發布后對轉發數量的預測,根據其早期的轉發動態來預測其最終的轉發量[3]。
目前對微博轉發量的預測有基于時間序列、基于回歸模型、基于傳染病模型等多種預測方法。基于時間序列的方法是對微博轉發量進行時間序列建模,研究微博轉發量在一段時間內的變化規律[4],這種方法不考慮微博傳播過程中的個體差異,通常只適用于研究微博傳播的一般情況[3]。基于回歸的方法是通過挖掘影響微博傳播中的關鍵因素,一般包括發布時間、文本內容、評論數量等,利用這些特征建立回歸模型,從而預測微博最終轉發量[5]。這種方法的困難在于不易選擇合適的特征,并且需要較多的歷史數據訓練模型[3]。最后,基于流行病模型的預測方法是以傳染病學和傳播學的理論研究基礎,構建新的傳播規則和模型,建模思路清晰可靠,已成為微博轉發預測的一種重要方法。本文選擇基于傳染病模型,對微博轉發量進行預測。
傳染病建模的基本建模思路是把微博網絡中的用戶節點劃分為多個倉室,通常有未知者S、傳播者I和免疫者R。對于某條微博,未知者S表示沒有接觸過這條微博的用戶,傳播者I表示接觸過并且會以一定概率轉發該微博的用戶。免疫者R表示接觸過微博后不會進行傳播的用戶。微博的轉發擴散就表示為用戶節點在不同倉室之間的轉移[6]。在經典SIR模型的基礎上,Xiong等[7]增加了接觸信息者C,建立了基于轉發機制的信息傳播模型,接觸信息者C表示閱讀了這條微博,但還沒有決定是否要轉發。Zang等[8]在SI模型的基礎上提出了一種網絡增長模型,將信息在社交網絡上的傳播過程轉化為網絡的增長,實現了對社交網絡中用戶數量變化的預測。他們建立的這種模型將早期指數增長網絡放緩至中后期的冪律增長,更加精確地描述了網絡的變化過程。
本文基于對微博傳播過程的分析,建立了一種基于關注網絡的微博轉發量預測模型,考慮了微博在傳播過程中潛在關注者數量的變化,并根據這一動態變化的指標預測未來轉發量。在開源數據集上進行的實驗結果表明,本文建立的模型相比基準模型,能夠實現更好的預測效果。
1 模型建立
在微博網站上,當某個用戶發出一條微博時,只有這個用戶的粉絲可以收到這條信息,并考慮該信息是否值得轉發。如果一些用戶決定轉發它,那么這些用戶的粉絲就有機會閱讀和傳播這條微博。這些粉絲的轉發又會帶來新的用戶去閱讀和傳播。這樣這條微博信息的影響就超出了發布者的局部網絡,并且有機會在微博網絡上擴散到更大范圍。
基于上述的信息傳播機制,我們的模型以下列方式定義。在每個時間步里,轉發者和其他用戶之間的交互行為有以下規則:
(1)定義轉發者為I,每個轉發者的粉絲會收到微博信息,因此,這個轉發者的粉絲會成為這條微博的潛在關注者。
(2)全部的潛在關注者構成一個倉室S,并且會有的概率轉發這條微博,即以的速度轉變為轉發者。當該S倉室內的用戶轉變為轉發者后,這個用戶的粉絲會在下一個時刻加入到倉室S中。
可以看出,在該模型中,存在兩種狀態,分別是轉發者I,以及潛在關注者S。這個模型的一個重要特征就是S并不是一個定值,而是根據初始微博傳播的數據,建立S和I之間的數量關系:。我們將分別定義為在t時刻潛在關注者和轉發者的數量。因此在的時間段內,新增I的數量可計算為:
通過對微博傳播數據的分析,發現潛在關注者數量S與微博傳播初期的轉發者數量I,以及初期轉發者的平均粉絲數相關,其中S和I之間存在較為明顯的函數關系。當轉發數量較小時,微博處在一個快速傳播的階段, 此階段轉發數會大幅增加,在這個階段,平均粉絲數較大,反映了在傳播初期,參與傳播的用戶多為活躍用戶,微博影響力較大。此時,每個參與轉發的用戶會帶來較多的潛在關注者,因此總的S數量相對I數量呈現出更加快速的增長。
隨著時間的增加, 轉發快速增長階段結束后,總轉發次數在慢慢趨于平穩,這個階段轉發率下降到一個較低程度。此時,主要參與轉發的是數量相對較多的普通用戶,他們擁有較小的粉絲數,但是由于整體的轉發數量較多,因此也會使潛在關注者的數量在短時間內有明顯的增長。之后隨著轉發率和單位時間內轉發數的進一步下降,新接受到信息的潛在關注者較少,因此信息較少發生傳播,總轉發量在較長時間上維持穩定。
由上述分析,可以根據某微博在t時刻的轉發數量I,計算得到對應的未感染者數量,如公式(4):
由上述公式,可以得到任意時刻I的數量。首先利用LM算法,在微博傳播的初始階段進行擬合,最小化誤差和,得到參數。再將參數帶入到公式中,計算得到下一時間點的I的數量。為了使I的預測值更加準確,也為了方便計算,需要讓計算時間間隔較小,保證條件成立。
2 實驗分析
2.1 數據預處理與評價指標
本文的實驗數據來自Jing Zhang等[9]采集的微博轉發數據集。該數據集采集了170萬用戶的微博數據,并構建了這170萬用戶之間的關注關系網絡。為了準確評價實驗結果,使用絕對誤差MAPE,以及平均絕對誤差MAE,其計算公式為分別為公式(10)、公式(11)。
2.2 實驗分析
2.2.1 微博熱度對模型預測效果的影響
首先,在實驗數據集上用本文提出的模型進行實驗,以每條微博發布后4h的數據為訓練集,對未來24h的微博轉發量進行預測。模型對不同熱度的微博預測結果如圖1。根據實驗結果可以看出,本文提出的轉發量預測模型能夠較為準確的對微博的未來轉發量進行預測。特別是對于微博轉發量較大、熱度較高的微博,預測效果較好。
2.2.2 預測時間對模型預測效果的影響
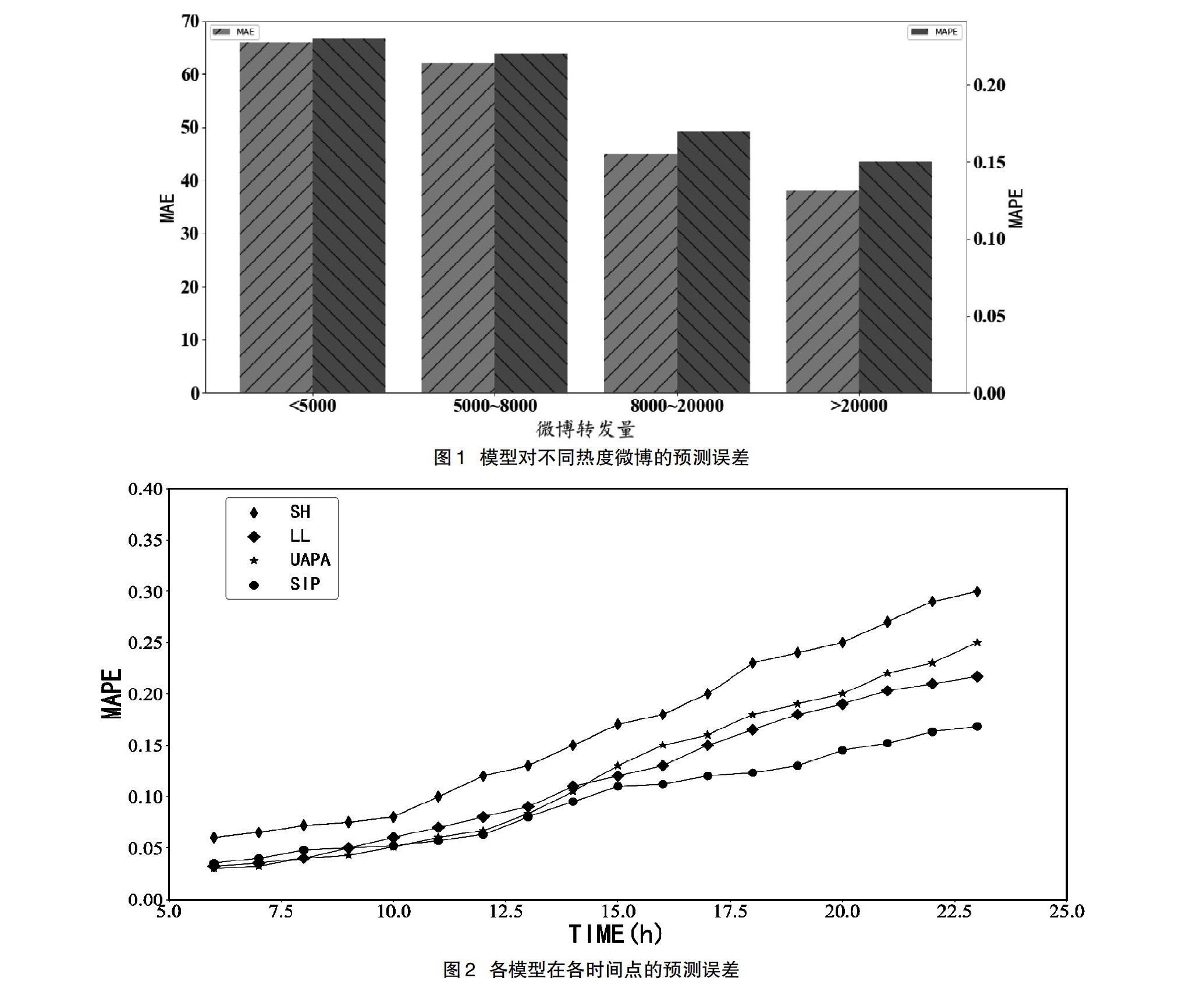
選擇數據集中轉發量超過20000的微博數據,用本文提出的模型以及對比的模型進行測試,對比模型分別采用SH[10]、LL[11]、UAPA[12]。計算模型在微博發布后的各個時間節點上的預測誤差,結果如圖2所示。根據實驗結果可知,隨著預測時間的增大,模型的誤差也會增大。從總體上看,本文提出的模型(SIP)在各時間段內,均有較低的預測誤差,同時相比其他模型,準確率也更高。
3 結語
本文基于微博轉發的實際規律,結合傳染病建模理論,建立了一個針對微博轉發量的預測模型。首先用參與傳播者的粉絲作為微博的關注者,代替傳染病模型固定數量的初始未感染者,并建立了微博關注者與轉發者數量關系方程,利用已知數據擬合其中的參數,然后又建立了轉發者數量的預測模型。將本文建立的模型在真實數據集上進行實驗,證明該模型有較好的預測效果。
參考文獻
[1] 2018微博用戶發展報告[R].北京:新浪微博數據中心,2019.
[2] 胡長軍,許文文,胡穎,等.在線社交網絡信息傳播研究綜述[J].電子與信息學報,2017,39(4):794-804.
[3] 吳越,陳曉亮,蔣忠遠.微博信息流行度預測研究綜述[J].西華大學學報,2017,36(1):1-6.
[4] Yang J,Leskovec J.Patterns of temporal variation in online media[C]//Proceedings of the fourth ACM international conference on Web search and data mining.ACM,2011:177-186.
[5] Jamali S,Rangwala H.Digging digg:Comment mining, popularity prediction,and social network analysis[C]//2009 International Conference on Web Information Systems and Mining.IEEE,2009:32-38.
[6] 李洋,陳毅恒,劉挺.微博信息傳播預測研究綜述[J].軟件學報,2016,27(2):247-263.
[7] Xiong F,Liu Y,Zhang Z,et al.An information diffusion model based on retweeting mechanism for online social media[J]. Physics Letters A,2012,376(30-31):2103-2108.
[8] Zang C,Cui P,Faloutsos C.Beyond sigmoids:The nettide model for social network growth,and its applications[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2016:2015-2024.
[9] Zhang J,Tang J,Li J,et al. Who influenced you? predicting retweet via social influence locality[J].ACM Transactions on Knowledge Discovery from Data (TKDD),2015,9(3):25.
[10] Szabo G,Huberman B A.Predicting the Popularity of Online Content[J].Communications of the ACM,2010,53(8):80-88.
[11] Shen H,Wang D,Song C,et al.Modeling and predicting popularity dynamics via reinforced poisson processes[C]//Twenty-eighth AAAI conference on artificial intelligence.2014.
[12] 朱海龍,云曉春,韓志帥.基于傳播加速度的微博流行度預測方法[J].計算機研究與發展,2018,55(6):1282-1293.
