基于Python的自動代理Web漏洞掃描器的設計與實現
2020-07-30 14:03:27孟清路賀俊劉對高雨
科技視界 2020年17期
孟清 路賀俊 劉對 高雨


摘 要
Web掃描器是提高網站安全性,讓滲透效率快速提升不可或缺的一部分,現有的優(yōu)秀掃描器的掃描功能都很強大,但是代理功能卻并不強。本文開發(fā)了一款基于Python的自動代理Web漏洞掃描器,利用爬蟲和asyncio技術維護一個動態(tài)的免費代理池,通過隨機調用代理池里的有效代理進行Web掃描。因為測試全程可以使用隨機代理,所以即使出現多個代理被安全設備發(fā)現的情況下也能繼續(xù)進行有效的測試,這將大大提高授權情況下的黑盒測試下的效率。同時爬蟲還使用了多進程,布爾去重,廣度優(yōu)先爬取等技術進一步減少測試所需要的時間。
關鍵詞
代理掃描;滲透測試;Web安全;爬蟲
中圖分類號: TP393.08 ? ? ? ? ? ? ? ? 文獻標識碼: A
DOI:10.19694/j.cnki.issn2095-2457 . 2020 . 17 . 14
Abstract
Web scanners are an integral part of Web site security and penetration efficiency, and the best existing scanners have powerful scanning capabilities, but not as powerful proxies.This paper develops a python-based automated proxy Web vulnerability scanner, which USES crawler and asyncio technology to maintain a dynamic free proxy pool, and randomly invokes effective proxies in the proxy pool for Web scanning.Because random agents can be used throughout the testing process, effective testing can continue even if multiple agents are discovered by security devices, which will greatly improve the efficiency of black box testing under authorization.The crawler also USES multi-process, Boolean de-weighting, breadth-first crawling and other techniques to further reduce the time required for testing.
Key Words
Proxy scanner; Penetration testing; Crawler
0 引言
互聯網的不斷發(fā)展,日新月異的計算機技術使得Web產品的不斷發(fā)展,各個領域對于互聯網的需求也突顯了出來。自十八大以來,習總書記對我國的網絡安全問題十分看重[1]隨著在2016年《中華人民共和國網絡安全法》法案正式通過,并且該法案將于次年6月起開始施行[2],社會各界對于網絡安全也重視了起來,可如何保障Web產品的安全已經成了一大難題。
在網絡安全測試中滲透測試是一個十分重要的測試方法,這項技術已經存在數十年[3]。現如今雖然市面上有了幾款較為成熟的漏洞掃描檢查工具可以幫助開發(fā)人員和網站維護人員完成大部分的安全防護工作,但是幾乎所有的工具的Web代理功能都非常的弱,甚至有些都沒有代理功能。這就導致大部分掃描器對于防護弱的網站時可以肆無忌憚的亂掃,但是面對安全防護不錯的網站就無能為力了,為了保護好測試者,降低測試者在授權的黑盒測試中被現有的安全防護措施和設備所發(fā)現的概率,一款可以自動代理的Web掃描器就非常重要了。
1 軟件設計
1.1 軟件需求分析
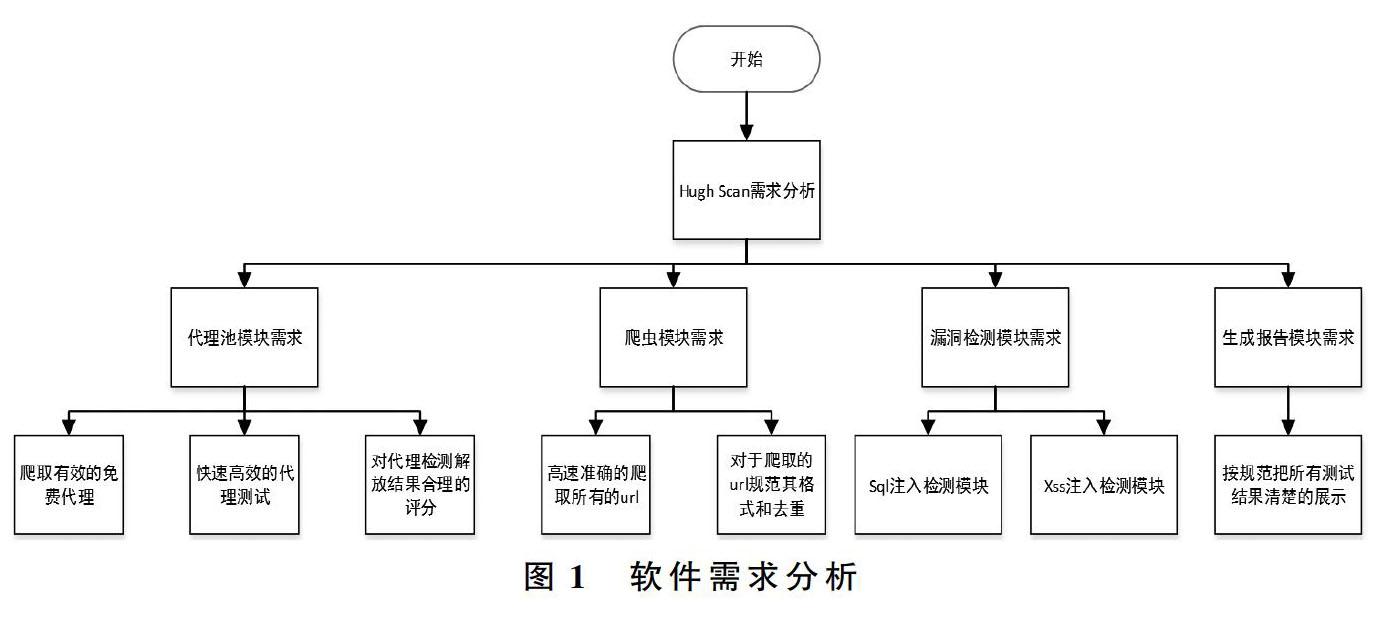
此次要設計的漏洞掃描器是一個可以自動代理的Web掃描器,掃描器要實現自動代理功能一個可自行維護的Web代理池就非常重要,其次作為一款掃描器基本的Web掃描功能是產品的核心,最后要實現對掃描的信息進行有效的存儲和輸出。需求分析流程圖如圖1。
1.1.1 代理池模塊需求分析
在互聯網高度發(fā)達的今天,網絡爬蟲已經成為在重復采集數據中不可或缺的一部分[4]。代理池的作用也就越來越大了,為了維護一個可用的高質量的代理池一般需要大量的時間和金錢,如果把錢花在維護代理池,這對于大部分的滲透測試來說可謂是本末倒置,所以本軟件所設想的是一個可積累,免費,實用的代理池模。要實現這些功能就需要從互聯網上的免費代理網站爬取代理并進行測試、打分,最后存儲起來,下一次使用時可以在原來的基礎上進行再次的測試從而提高代理池的效率,當然為了使用這一模塊用戶在滲透測試之前都必須花一定的時間進行代理池的維護。
1.1.2 自動爬取需求分析
有了一個可用的代理池之后自動爬取功能的實現也就非常簡單了,只需要在每次爬取時獲取一個隨機的代理并在爬取時使用即可。爬蟲爬取目標網站時使用的是廣度優(yōu)先爬取,這樣在爬取網站時就可以設置要爬取的網站最大深度。當然為了提高爬取的效率,多進程是必不可少的,爬取時要對爬取出來的url進行規(guī)范化和去重處理這樣就可以減少大量非必要的測試。
1.1.3 漏洞檢測功能需求分析
Web漏洞種類繁多,本掃描器暫時只支持最常見的漏洞:Sql注入漏洞和Xss注入漏洞。Sql注入是在Web前端同后臺數據庫之間發(fā)生數據交互時產生的安全漏洞[5]。Xss攻擊指攻擊者將惡意腳本寫入到Web網頁當中,通常這些腳本能夠利用用戶的瀏覽器中的Javascript來執(zhí)行惡意代碼,來獲取用戶的隱私信息以及其他一-些惡意操作[6]。不同的漏洞通過調用不同的漏洞檢測模塊,模塊之間不存在相互調度關系,在檢測過程中Sql和Xss注入漏洞都是通過自動填充表單并提交的方法獲取對應的含注入點的url。
1.1.4 報告生成需求分析
對于掃描的結果一定要有一個清晰明確的輸出,不然掃描等于沒有掃描,對于不方便直接顯示的數據也要指明文件輸出的詳細位置,提供多種輸出格式。
2 系統實現
經過軟件的需求分析我們可以得知Web掃描器應該分為四個大模塊,分別是代理池模塊,自動爬取模塊,漏洞檢測模塊和生成報告模塊。
2.1 代理池模塊實現
代理池通過proxy_pool_run.py進行代理池的運行和控制包括獲取要爬取的有效免費ip數量,并判斷現有的IP數量是否滿足,從而控制爬蟲的爬取。爬取時通過crawalers文件下的daili66.py,ip3366.py,kuaidaili.py和xici.py爬取網站的免費代理,每次爬取時都會隨即產生隨機值填充到要爬取的網站url中防止重復爬取,對爬取的代理進行布爾去重后存儲到指定的文件,存儲初時默認代理的分數為0。在proxy_test.py中進行代理的檢測,每次成功后代理分數加一,滿9分后分數不再上升但是依然要檢測,對于檢測失敗的代理將從代理池中刪除。代理測試時為提高測試效率使用異步協程的方式,每次測試100個代理,當然本項目也支持你在代理池存儲文件中按規(guī)范添加自己的代理。代理池模塊流程圖如圖2。
2.2 爬蟲模塊實現
爬蟲模塊是本項目的核心,如何從用戶提交的一個有效url中高效的爬取出url是最重要的。爬蟲模塊的文件在Scan目錄下的,Craw.py將對爬取的url鏈接進行判斷除去空鏈接,如果不是規(guī)范的url則會利用urllib庫的parse模塊獲取絕對路徑的地址,在使用pybloom_live庫的BloomFilter模塊對爬取的url進行布爾去重。
Queue_manager.py會獲取和判斷用戶要求爬取的網站深度,再使用廣度優(yōu)先爬取的技術進行爬取。如果你要使用本項目的自動代理功能,則會調用crawlers目錄下的proxy_pool_run.py文件中的getproxy_url()函數從代理池中隨機選取一個代理進行使用,通過多進程的方式來大幅提高爬蟲模塊的執(zhí)行效率。之所以選擇多進程而不是多線程是因為“在多核下, 如果想做并行執(zhí)行提升程序效率, 比較常用有效的方法是使用多進程[7]。”爬蟲模塊流程圖如圖3。
2.3 漏洞檢測模塊實現
漏洞檢測模塊在Attack目錄下,每個模塊之間功能分離不重復。
2.3.1 Sql注入檢測模塊實現
Sql注入的自動化判斷難在如何獲取注入點,本掃描器通過提煉網頁中的form表單并進行自動填充提交在獲取對應的url從而獲得可能存在注入點的url。Url測試時craw_url()函數對爬取的頁面進行form表單的自動填充并拼接上我們所測試的多個playload。 _craw()函數從隊列中獲取要測試的url,先提交一個含有單個單引號的playload的url看是否存在報錯,如果不報錯則說明可能使用了雙引號,則進行雙引號的字符型Sql注入測試和搜索型的Sql注入測試;如果報錯則再提交一個含有單個雙引號playload的url看是否報錯,如果在報錯則可能是數字型的Sql注入漏洞,則利用對應的playload進行測試,如果提交一個含有單個雙引號playload的url不報錯則可能是單引號的字符型Sql注入測試和搜索型的Sql注入;如果按對應的playload測試后不報錯,則可能含有Sql注入漏洞,將對應的url存儲起來然后判斷是否測試完所有的url,有則取出下一個url,沒有模塊結束。Sql檢測模塊流程圖如圖4。
2.3.2 Xss漏洞檢測模塊實現
Xss和Sql注入一樣注入點都是通過自動提交form表單的形式獲取可能含有注入點的url,Xss漏洞檢測時先檢測是否存在dom型Xss,再檢測是否存在反射型或存儲型Xss注入。
Dom型的Xss檢測時會根據正則表達式去掉含有playload的響應包中的內容,接著在剩余的內容中查找注入點,如果存在相吻合的數據,則可能存在dom型Xss注入。
反射型Xss和存儲型Xss是通過九個核心的正則表達式(正則表達式常用來按用戶所定義的規(guī)則來檢索或替換符合的文本,從而達到用戶所預期的一串特殊字符[8]。)檢測時首先是發(fā)送一個設定好的特殊payload,在確定pladload在url中的輸出點所對應的dom結點的位置,比如:注釋內、雙引號內、<>內……其次再看這個輸出點對應核心正則表達式中所描述的哪個位置。找到pladload所在的位置后就需要查看在這個位置要利用成功有哪些字符不能被轉義,然后在看響應中的payload,從此時顯示payload的表現形式判斷那些‘不可被轉義的特殊字符前要被加上轉義符重新發(fā)送修改后的playload,直到每個不可被轉義的字符都成功的繞過一次才會認為存在Xss漏洞。當然不同的dom位置的攻擊方法也不同。Xss注入漏洞檢測模塊流程圖如5。
2.4 報告生成模塊實現
報告生成模塊實現的腳本是Output文件下的out_web.py,此腳本有add_list()函數以列表的形式添加到對應的字典中,在通過build_html()函數進行輸出,一般情況下add_list()函數所獲取的列表全部來源于掃描出來的各類.txt文件,最后把這些數據全部整合起來輸出為一個頁面。
3 項目展示
3.1 項目主界面展示
本軟件是使用的是pyhton3.7版本,啟動時直接在命令行下運行主程序即可。程序啟動的提示中會顯示是否要使用免費代理功能,如果輸入No,則會顯示出本軟件的命令行參數,如果選擇Yes,則會先進行代理池的初始化,初始化結束后會顯示本軟件的命令行參數。
3.2 基礎功能演示
3.2.1 代理池功能演示
在直接運行主程序Hugh.py,即輸入“python Hugh.py”都會提醒是否使用免費代理功能如果需要在命令行中輸入Yes即可。
3.2.2 網頁爬取功能演示
假如我們僅需要爬取的網站是“http://192.168.111.141:8081/”在命令行輸入命令“python Hugh.py -u http://192.168.111.141:8081/”就可以進行網頁爬取,爬取時默認爬取深度為 3,如果需要更改爬取深度請在命令中加入depth選項,假設要修改的深度為4,則此時完整的的命令為“python Hugh.py -u http://192.168.111.141:8081/ --depth=4”。
3.2.3 漏洞檢測模塊功能演示
(1)Sql注入檢測模塊演示
如果我們要對爬取的網站進行Sql注入檢測時,假設要爬取的網站是“http://192.168.111.141:8081/”,默認爬取深度,則爬取的命令是“python Hugh.py -u http://192.168.111.141:8081/--sql=1”,即可對整個網站進行Sql注入檢測。
(2)Xss注入檢測模塊演示
如果我們要對爬取的網站進行Xss注入檢測時,假設要爬取的網站是“http://192.168.111.141:8081/”,默認爬取深度,則爬取的命令是“python Hugh.py -u http://192.168.111.141:8081/--xss=1”,即可對整個網站進行Xss注入檢檢測。
(3)Sql注入和Xss注入同時檢測模塊演示
如果我們要對爬取的網站進行Xss和Sql注入檢測時,假設要爬取的網站是“http://192.168.111.141:8081/”,默認爬取深度,則爬取的命令是“python Hugh.py -u http://192.168.111.141:8081/--xss=1 ?--sql=1”,即可對整個網站進行檢測,如圖6。
3.2.4 掃描報告結果展示
在爬取網站后打開掃描結果所在的文件夾即可看到各種掃描結果,其中.html文件就是所有掃描結果的匯總,如圖7所示。如果要修改輸出文件的位置,請在lib.config.py中更改。
4 結束語
本項目實現了一個基于Python的自動代理Web漏洞掃描器,成功維護了一個簡易的代理池,讓自動化代理功能成功地加入到了Web掃描器中,而且能成功檢測出網站的安全漏洞,讓黑盒測試有了更大的隱蔽性,具有一定的實用價值。當然本掃描器還是有許多不足之處,比如支持檢測的漏洞不夠多,支持的代理協議不夠多,掃描報告頁面相對簡陋等,需要繼續(xù)改進。
參考文獻
[1]張?zhí)N昭.中國特色治網之道: 理念與成就——十八大以來我國網絡空間治理的回顧與思考[J].中國行政管理,2019,1:28.
[2]鄧若伊.以法制保障網絡空間安全構筑網絡強國—— 《網絡安全法》和《國家網絡空間安全戰(zhàn)略》解讀[J].電子政務,2017,2:2-35.
[3]牛詠梅.面向Web應用的漏洞掃描器的設計與實現[J].南陽理工學院學報,2018,10(06):66-69.
[4]王佳鵬,徐海蛟,許培宇,何佳蕾,林冠成.面向網絡爬蟲的高可用動態(tài)池系統設計與實現[J].福建電腦,2019,35(06):8-11.
[5]李鑫.基于Web滲透測試的SQL注入研究[J].信息與電腦(理論版),2020,32(03):164-166.
[6]谷家騰. 基于動態(tài)分析的XSS漏洞檢測方法研究[D].北京郵電大學,2019.
[7]唐琳,董依萌,何天宇.基于Python的網絡爬蟲技術的關鍵性問題探索[J].電子世界,2018(14):32-33.
[8]苻玲美.正則表達式在python爬蟲中的應用[J].電腦知識與技術,2019,15(25):253-254.
猜你喜歡
中華詩詞(2022年6期)2022-12-31 06:41:24
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中國科技論壇(2017年7期)2017-07-25 08:49:53
媽媽寶寶(2017年2期)2017-02-21 01:21:24
國際漢語學報(2016年1期)2017-01-20 08:21:20
海峽科技與產業(yè)(2016年3期)2016-05-17 04:32:12
