2011—2017年基于百度搜索指數的全國手足口病預測研究
2020-07-27 05:32:52紀煥林張燕婷羅淦豐
汕頭大學醫學院學報 2020年2期
紀煥林,張燕婷,羅淦豐,李 克
(1.汕頭大學醫學院公共衛生與預防醫學教研室,廣東 汕頭 515041;2.中山大學公共衛生學院醫學統計與流行病學系,廣東廣州 510080;3.中山大學公共衛生學院(深圳),廣東 深圳 518107)
手足口病是以多種腸道病毒為病原體的傳染病,目前已成為全國傳染病報告發病率排名前五的丙類傳染病[1],對5歲以下的兒童造成了嚴重的疾病負擔[2]。傳統的疾病監測系統是通過逐層上報的形式,數據發布上有延遲。近年來,已有不少研究通過挖掘互聯網搜索數據,建立數學模型對傳染病進行預測[3-4],證明了網絡搜索數據對傳染病疫情有一定的預測能力。本研究旨在建立一個結合百度關鍵詞搜索指數和全國手足口病發病數的自回歸移動平均模型(autoregressive integrated moving average,ARIMA),對手足口病的發病進行監測和預測。
1 資料與方法
1.1 數據來源
2011—2017年手足口病的發病數據來源于中國疾病預防與控制中心公布的數據(http://www.phsciencedata.cn/Share/),其中2011年1月—2016年12月數據用于模型擬合,2017年1—12月的數據用于模型驗證。對應時間的百度關鍵詞搜索指數數據從百度指數官網(http://index.baidu.com)上以月為單位進行收集。
1.2 研究內容與方法
1.2.1 構建綜合百度搜索指數 從手足口病的疾病名稱、癥狀、治療和預防4個維度入手,結合相關領域文獻,參考百度關鍵詞挖掘工具(http://tool.chinaz.com/baidu/words.aspx)選擇關鍵詞并擴展,初步獲取了240個與手足口病相關的基礎關鍵詞,計算每個關鍵詞的搜索指數與手足口病發病數的Spearman相關系數,按照相關系數r>7且有統計學意義(P<0.05)的原則,篩選出最終納入分析的關鍵詞。然后構建綜合百度搜索指數,即計算每個關鍵詞的搜索指數與發病數的相關系數在所有相關系數之和中的權重系數,再將該權重系數與對應的關鍵詞的搜索指數相乘,最后求和得到。最后計算綜合百度搜索指數與全國發病數據的Spearman相關系數,確定相關性的大小。相關公式如下:
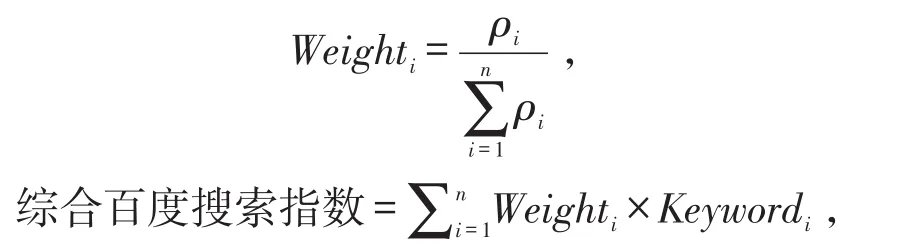
式中,ρi為第i個關鍵詞的搜索指數與發病數的相關系數;Weighti為第i個關鍵詞的權重系數;Keywordi為第i個關鍵詞的搜索指數。
1.2.2 模型擬合 ARIMA模型是一種將ARMA模型與差分運算組合的時間序列預測方法,即建立一個由因變量和隨機誤差對平穩時間序列的滯后值影響的模型,公式為ARIMA(p,d,q)×(P,D,Q)s,該模型應用的前提條件是所要預測數列的個體值需相對穩定[5]。本研究通過時序圖及單位根檢驗來判斷時間序列的平穩性,采用差分處理將不平穩的序列轉換為平穩序列,用極大似然法估計模型參數。模型殘差通過Ljung-Box方法判斷是否為隨機序列。根據赤池信息準則來判斷模型的擬合優度,AIC值最小時為最優模型。以上方法通過R軟件中的“tseries”和“forecast”包實現。
1.2.3 模型預測 模型的預測效果使用均方根誤差百分比(root mean squared percent error,RMSPE)和平均絕對百分比誤差(mean absolute percent error,MAPE)來評價[6],其值越小,說明模型預測性能越好。計算公式如下:
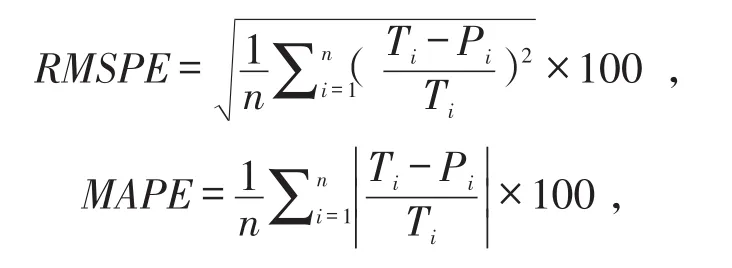
式中,Ti表示第i個真實值;Pi表示第i個預測值。
1.3 統計學方法
模型的分析及作圖使用軟件R 3.4.1,檢驗水準均為a=0.05,P<0.05認為差異有統計學意義。
2 結果
2.1 2011—2017年全國手足口病發病概況
2011—2017年全國共計發病達14 787 625人,月平均發病數176 043人,年平均發病率約154/10萬。
2.2 關鍵詞的篩選與綜合百度搜索指數的構建
分別對240個百度關鍵詞搜索指數和全國手足口病發病數進行相關分析,按r>0.7,P<0.05的條件,篩選出19個關鍵詞,見表1。根據19個關鍵詞的百度搜索指數及其與全國手足口病發病數的相關系數進行加權來構建綜合百度搜索指數。全國手足口病發病數與綜合百度搜索指數的相關系數r=0.94,P<0.05。
2.3 模型擬合
2.3.1 時間序列平穩化 用2011年1月—2016年12月的發病數據構建時間序列,繪制時序圖,發現序列為非平穩序列,需進行差分處理。差分后通過單位根檢驗得DF=-4.176 5,P<0.05,說明該序列已經平穩,d與D取值為1。序列的季節周期為12個月,故s=12。
2.3.2 模型的定階 繪制自相關圖和偏自相關圖后發現自相關系數拖尾,q可取值0。偏自相關系數2階后截尾,p可取值1或2。P,Q值一般不會超過2,分別對P,Q值取0、1逐個嘗試,結合AIC值判斷,最終確定的模型為ARIMA(2,1,0)(0,1,1)12,此模型的AIC值最小。
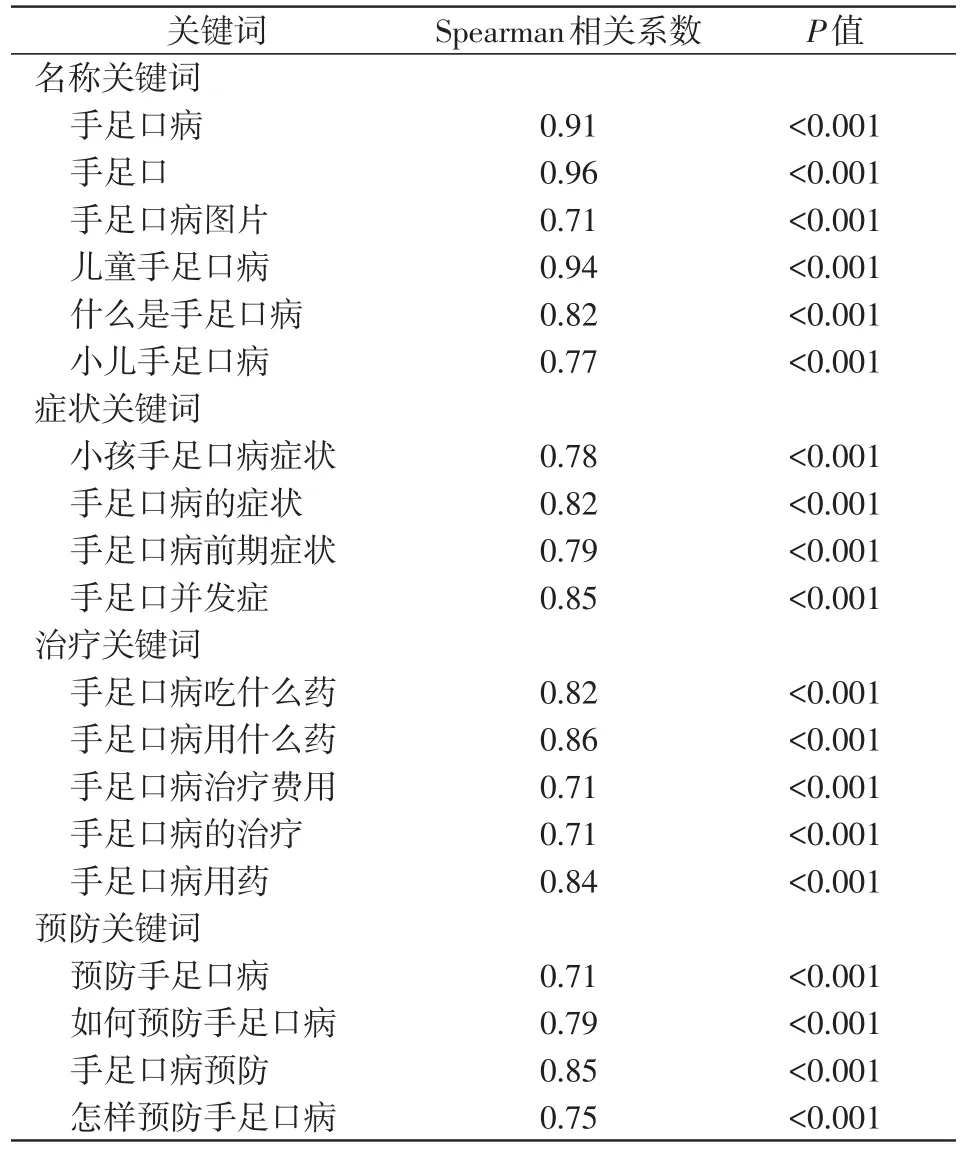
表1 19個百度關鍵詞與手足口病發病數的相關性
2.3.3 模型驗證 對此模型殘差進行白噪聲檢驗,Ljung-Box統計量Q=0.165,P=0.684,未通過顯著性檢驗,殘差是隨機序列,證明該模型已充分提取原序列信息,可進行預測。
2.4 模型預測效果比較
2017年1—12月手足口病實際發病數與模型預測發病數見表2,進一步計算模型的預測效果指標,得到基于百度指數的模型的MAPE=24.86%,RMAPE=29.86%;單獨利用發病歷史數據的模型的MAPE=27.58%,RMAPE=35.50%,說明前者的預測準確度要更好。基于百度搜索指數建立的ARIMA模型與單獨利用發病歷史數據建立的ARIMA模型的預測效果見圖1、圖2。
3 討論
百度指數是大數據時代重要的統計分析數據,客觀地記錄了各個關鍵詞每日的搜索量。網絡搜索詞量的動態變化一定程度上反映了該地區相關疾病流行情況和人群中發病及求醫的信息[7]。ARIMA模型是應用于傳染病預測最常用的方法之一[8-9],其綜合考慮了傳染病的周期性、季節性、隨機性等可能影響序列平穩性的因素,提高了模型的預測和擬合效果。利用網絡搜索數據進行傳染病的預測已成為研究熱點之一,國外研究基于“谷歌”搜索引擎已有登革熱[10]、流行性感冒[11]谷歌趨勢預測,國內更多的研究是挖掘百度搜索指數,進行不同數學模型預測,如流行性感冒[12]、登革熱[13]、紅斑性肢痛癥[14]等,也有對清遠市做基于百度指數的手足口病不同數學模型的預測研究[15-16],但目前尚無基于百度搜索指數的全國手足口病ARIMA發病預測模型研究。
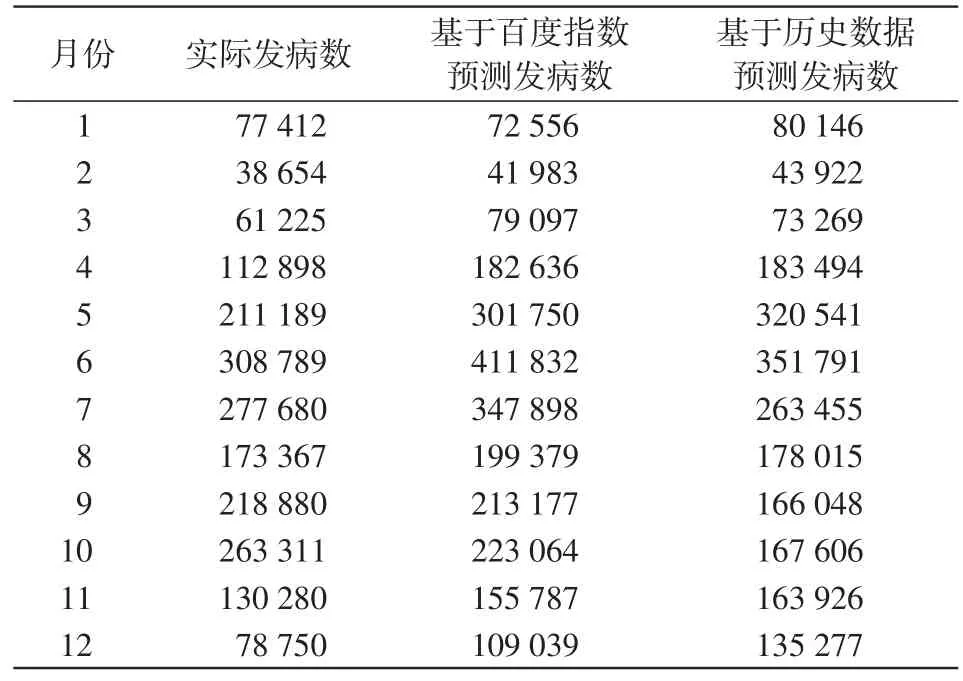
表2 2017年1—12月的實際發病數與模型預測發病數(人)
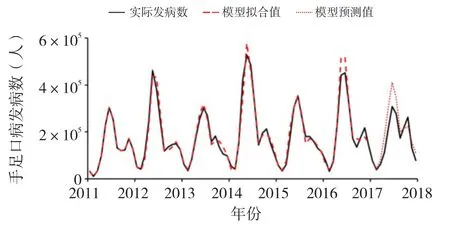
圖1 基于百度搜索指數的ARIMA模型預測效果圖
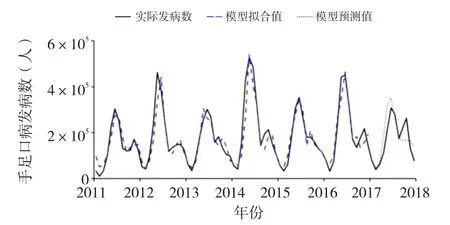
圖2 基于發病歷史數據的ARIMA模型預測效果圖
本研究利用關鍵詞挖掘工具,從240個百度關鍵詞最終篩選出19個相關系數大于0.7的關鍵詞,然后加權構建綜合百度搜索指數,提高了預測的精確度。綜合百度搜索指數與手足口病發病數的相關性為0.94,同時,兩者變化的趨勢較為一致,說明使用百度指數進行手足口病發病的預測是合理且可靠的。利用建立的ARIMA模型進行預測,發現用結合百度搜索指數建立的ARIMA模型相對于只基于手足口病發病數建立的ARIMA模型,前者的MAPE值以及RMSPE值都比較低,說明使用百度搜索指數可以更好地提升ARIMA模型的預測性能。
本研究也存在一定局限性,百度關鍵詞受到網民文化教育水平、個體健康需求等的影響,導致關鍵詞范圍寬泛;另一方面,人們也可能受媒體報道的影響,使百度指數存在媒體效應,造成百度指數的虛浮。盡管如此,挖掘互聯網大數據對傳染病進行發病預測的方法,為傳染病的監測和防控提供了一個新思路。隨著大數據時代的來臨,百度指數作為一個方便、免費、易得的數據來源,應用前景廣泛,未來可以使用不同的數學模型,結合全國或不同地區的傳染病發病數據,建立預測性能更優的傳染病監測系統。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
Defence Technology(2020年4期)2020-07-02 03:16:58
數學物理學報(2020年2期)2020-06-02 11:29:24
青年與社會(2018年2期)2018-01-25 15:37:06
光學精密工程(2016年6期)2016-11-07 09:07:19
學周刊(2016年26期)2016-09-08 09:02:52
IT時代周刊(2015年8期)2015-11-11 05:50:22
核科學與工程(2015年4期)2015-09-26 11:59:03
中國醫學人文(2015年6期)2015-06-08 06:00:48
