基于循環自動編碼器的間歇過程故障監測
2020-07-21 07:15:08高學金劉騰飛徐子東高慧慧于涌川
化工學報 2020年7期
高學金,劉騰飛,徐子東,高慧慧,于涌川
(1 北京工業大學信息學部,北京100124; 2 數字社區教育部工程研究中心,北京100124; 3 城市軌道交通北京實驗室,北京100124; 4 計算智能與智能系統北京市重點實驗室,北京100124)
引 言
間歇過程因其小批量、可操作性強、產品附加值高等特點,在化工生產中被廣泛應用[1]。多向主成分分析[2](multiway principal component analysis,MPCA)和多向偏最小二乘[3](multiway partical least squares, MPLS)最早被提出用于間歇過程的故障監測,已得到了較大發展[4-7]。間歇過程本身反應復雜多變,通常具有較強的非線性和動態性,增加了故障監測的難度[8-9]。
傳統方法中通常使用核方法解決過程非線性,取得了較好的效果[10-12]。進一步,為同時處理間歇過程中的非線性和動態性,Wang 等[13]提出了雙向動態核PCA(two-dimensional dynamic kernel PCA, 2DDKPCA)方法,通過構造支持域(region of support,ROS)捕捉批次內和批次間兩個方向的動態性,但支持域難以確定。Jia 等[14]提出了批動態核PCA(batch dynamic kernel PCA, BDKPCA)方法,通過增廣時滯數據的方式處理動態性,而后使用所有批次數據的平均核矩陣進行PCA 建模。但增廣時滯數據并不能有效提取過程數據間的時序關聯關系,對動態性的處理仍有不足。Zhang 等[15]提出了遞歸核PCA 方法,在核空間遞歸更新樣本協方差矩陣的特征值分解,考慮了歷史信息對當前時刻的影響。Zhang 等[16]提出了全局保持核慢特征分析方法,在處理非線性和動態性的同時考慮了全局數據結構信息。然而,核空間不可知,在線更新困難,當訓練數據增加時,核矩陣所需的計算和存儲需求都急劇增大,這些缺陷使同時處理過程動態性的難度大大增加。
自動編碼器(autoencoder,AE)是一種用于無監督特征提取的神經網絡,因深度學習的熱潮而備受關注[17]。Yan等[18]將自動編碼器應用于過程監測,在解決非線性問題的同時考慮了過程監控的魯棒性。但AE 同樣假設過程變量是獨立同分布的,忽略了過程數據的時序相關性,容易導致較高的漏報率和誤報率。
循環神經網絡(recurrent neural network, RNN)對處理非線性時間序列有著較強的適用性,能較好地學習和利用時序樣本間的動態關聯信息。長短時記憶(long short-term memory, LSTM)網絡是RNN的一種典型改進形式[19],改善了RNN 的梯度消失問題,在學習新信息的同時能夠動態記憶長時間的歷史信息[20]。然而在過程監測領域,LSTM 還少有應用。基于此,本文提出一種基于循環自動編碼器(recurrent autoencoder,RAE)的間歇過程故障監測方法。首先,利用AT[21]展開方法將間歇過程數據展開成二維,通過滑動窗采樣得到模型輸入序列;之后采用LSTM 網絡構建自動編碼器,將輸入序列作為期望輸出進行網絡訓練,通過隱藏層的循環連接提取過程數據的動態關聯信息。最后,通過青霉素發酵過程和實際的工業過程驗證了所提算法優越性和有效性。
1 循環自動編碼器
1.1 傳統自動編碼器
傳統自動編碼器是一個三層前饋神經網絡,它由編碼器和解碼器兩部分構成,通過最小化重構誤差學習到原始數據的特征表達[22]。編碼器f(x)將輸入x∈Rn映射到隱含層特征h∈Rm,可表示為
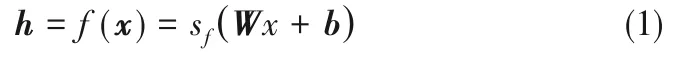
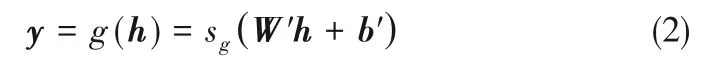
式中,W'∈Rn×Rm與b'∈Rn分別為解碼器的權重矩陣和偏置向量;sg為解碼器激活函數。重構誤差L(x,y)為輸入x與重構y之間的差異,可表示為

1.2 LSTM循環神經網絡
LSTM 網絡是由Hochreiter 等[23]提出的一種改進RNN。傳統RNN 雖然適用于處理非線性時間序列,但其存在梯度消失問題,即無法學習到較為久遠的序列信息。因此,LSTM 網絡將RNN 的隱含層改進為存儲單元,以提升其保持長期歷史信息的能力。圖1所示為LSTM存儲單元結構。

圖1 存儲單元結構Fig.1 Structure of memory cell
存儲單元中使用記憶細胞保存信息,通過輸入門、遺忘門和輸出門來控制細胞狀態。其中,輸入門控制信息流對細胞狀態的更新,遺忘門決定從細胞狀態中丟棄的信息,而輸出門最終確定存儲單元的輸出。存儲單元的計算流程可以由以下復合函數表示[20]
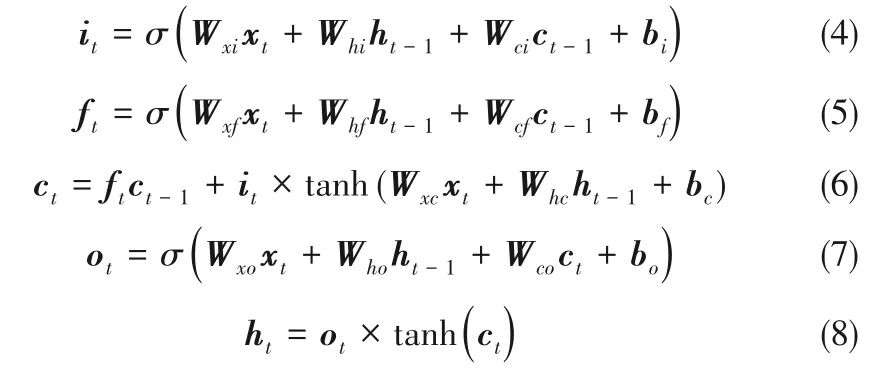
式中,it、ft、ot、ct分別為t時刻的輸入門、遺忘門、輸出門和細胞狀態,W和b分別為其對應的權重矩陣和偏置向量;ht為t時刻存儲單元的輸出;σ為sigmoid函數。
LSTM 網絡輸出的計算方式與傳統RNN 相同,可表示為

式中,yt為t時刻LSTM 網絡的輸出,Why和by為隱含層到輸出層的權重矩陣和偏置向量;由此,給定一個輸入序列,LSTM 網絡可得到同樣長度的輸出序列。
2006年博湖縣建立了“非遺”保護中心,確定了博湖縣文化館為開展“非物質文化遺產保護工作”具體實施單位,近年來,縣委、縣政府團結和帶領全縣各族人民,大力實施“水陸并進”戰略,但博湖縣非遺資源的有效利用方面存在以下問題:
1.3 循環自動編碼器
針對間歇過程數據的非線性和動態性特征,將傳統AE 使用LSTM 網絡擴展為RAE,即將LSTM 網絡替換為傳統AE 的隱含層,LSTM 將輸入序列輸出為重構序列,以此來計算重構誤差。克服了LSTM只能用于分類,無法進行監測的問題,并使其在處理時序數據中性能較好的優勢引入間歇過程中,其展開結構如圖2所示。網絡中隱含層特征不僅傳遞到了輸出層,同時傳遞到了下一時刻的隱含層。因此,RAE 有效考慮了歷史序列對當前狀態的影響,并且LSTM 賦予了模型保留長期時序信息的能力。此外,隱含層的循環連接使RAE 可以表達出一個過程狀態到另一個過程狀態的轉移關系,從而提取時序樣本間的動態關聯信息。

圖2 RAE展開結構Fig.2 Unfold structure of RAE
給定輸入序列X =(x1,…,xT),其與輸出序列Y =(y1,…,yT)間的誤差為所有時間步誤差之和,可以表示為
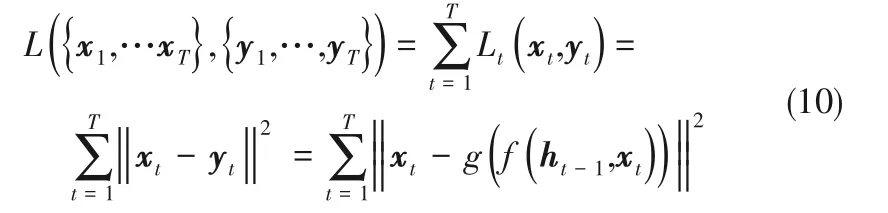
式中,Lt為t時刻的重構誤差,f(·)為編碼器,如式(5)~式(8)所示;g(·)為解碼器,如式(9)所示。
2 基于RAE的過程監測策略
2.1 數據預處理
間歇過程原始數據可表示為X(I×J×K),其中I為批次個數,J為變量個數,K為采樣點個數。由于LSTM 需要輸入為時間序列,所以使用批次展開和變量展開結合的AT[21]方法將三維過程數據展開成二維,然后對每批次數據以窗寬為d的滑動窗進行連續采樣,提取出時間序列。數據展開采樣過程如圖3所示。
首先,按批次方向將歷史數據X(I×J×K)展開成二維矩陣X(I×KJ)進行標準化處理,降低了過程變量的非線性。接著將數據重新排列成三維形式,然后按變量方向展開成二維矩陣X(IK×J)。最后,對展開后的每個批次數據采用滑動窗將其采樣為序列形式,其中第i個批次第k個時刻滑動窗采樣得到的序列為
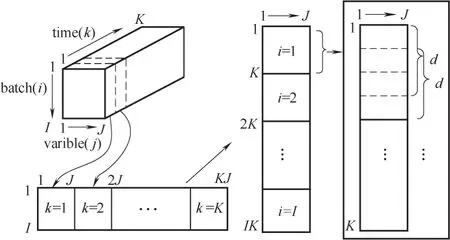
圖3 數據預處理Fig.3 Data preprocessing

2.2 故障監測指標
為監控過程變化,在殘差空間中構建SPE 統計量。基于RAE 的重構誤差,其SPE 統計量計算方式為

其中,d為采樣滑動窗的窗寬,e是一個時刻的輸入與輸出間的誤差。由于難以確定SPE統計量的數學分布,因此采用核密度估計[24]方法獲取統計量控制限,其形式[25]為
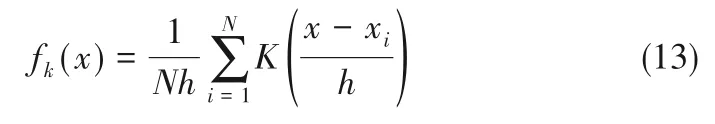
式中,fk(x)為概率密度,x為觀測樣本,K為核函數,h為窗寬,N為觀測樣本數目。
2.3 離線建模
(1)將正常間歇過程的三維歷史數據X(I×J×K)按照2.1 節所述方式展開標準化并使用窗寬為d的滑動窗對各批次進行連續采樣,得到訓練所用的樣本序列。
(2)使用基于時間的反向傳播算法訓練RAE,直到模型收斂。
(3)根據式(12)求取全部建模序列的SPE 統計量。
(4)根據式(13)使用核密度估計方法計算得到SPE統計量的控制限[26-29]。
2.4 在線監測

(2)計算輸入序列的SPE 統計量,通過判斷其是否超過控制限來確定生產過程是否發生故障。
3 青霉素發酵過程仿真研究
青霉素(penicillin)是一種常見的臨床抗菌藥品,其生產制備過程是典型的間歇過程,具有較強的非線性和動態性。本文使用Birol 等[30]研究開發的青霉素發酵基準仿真平臺Pensim2.0 進行在線監控仿真研究。設定每批次發酵時間為400 h,采樣間隔為1 h。共產生40 批次正常工況數據,每個批次的初始條件均在允許的范圍內稍加改變。選取10個過程變量用于建模和監控,如表1 所示。為較好模擬實際生產狀況,對訓練樣本加入一定量的高斯噪聲干擾。

表1 青霉素發酵過程主要變量Table 1 The main variables of penicillin fermentation process
為驗證所提方法用于過程監控的有效性,本文選取了三組故障批次樣本進行測試驗證,如表2所示。

表2 故障批次設置情況Table 2 Fault batch settings
RAE 模型需要設定的主要參數有隱含層節點數目和采樣時間窗口大小,本文采用網格搜索法對兩個參數進行交替尋優確定。其中RAE 模型的序列平均重構誤差-L作為參數選擇標準,計算方式如式(14)所示

式中,d為滑動窗寬,Li為序列中第i個時刻的重構誤差,xi和yi分別為模型第i個時刻的輸入和重構向量。序列隱含層節點數選擇16、32、64、128,采樣窗寬d選擇2、4、8、16、32,共計20 組參數進行搜索尋優,得到模型的序列平均重構誤差值如表3所示,重構誤差值越小,模型越精確。最終選擇隱含層節點數目為64,采樣窗寬為8。為進一步表明本文方法的優越性,本文將所提方法與傳統方法進行了對比分析,對比方法選擇BDKPCA[14]、AE 以及增廣時滯數據的滑動窗AE(move window AE,MWAE)方法。為進行更合理的分析對比,將BDKPCA 的T2和SPE統計量進行融合得到C統計量,如式(15)所示


表3 不同參數下模型的平均重構誤差值Table 3 Mean reconstruction error values of models with different parameters
圖4 所示分別為BDKPCA、AE、MWAE 與本文所提RAE 方法對故障1 的在線監測圖,虛線為99%的控制限。可以看出故障發生后,所有方法的監測統計量指標均立刻超出控制限,但BDKPCA 仍存在一定的漏報警現象。從圖4(a)~(c)的對比可以看出,AE 方法誤報率最高,BDKPCA 和MWAE 由于考慮了過程動態性,誤報警有所減少。相比之下,RAE 方法誤報警最少且故障幅度上升更為明顯,監測到的故障工況與正常工況間的數據分布差異更大。
圖5 分別為BDKPCA、AE、MWAE 與RAE 方法對故障2的監測結果。BDKPCA 的C統計量在218 h監測到故障。AE對故障的檢測存在一定的延遲,在221 h監測到故障,且存在較多誤報警。MWAE相比AE 誤報警較少,且可以在215 h 監測到故障。從圖5(d)中可以看出,本文所提RAE 方法沒有誤報警,且在208 h 監測到故障,故障檢測的實時性有了明顯提高。

圖4 故障1的監測結果Fig.4 Monitoring results of fault 1
圖6 分別為四種方法對故障3 的監測結果。BDKPCA 的C統 計 量 在189 h 監 測 到 故 障。AE 在195 h 監測到故障,而MWAE 在184 h 監測到故障。圖6(d)中,RAE 方 法 在175 h 監 測 到 故 障,比BDKPCA 和MWAE 方法分別提前了14 h 和9 h。相比其他三種方法,本文所提方法對于該幅值較小的緩變故障更為敏感,表現出更好的監控效果。
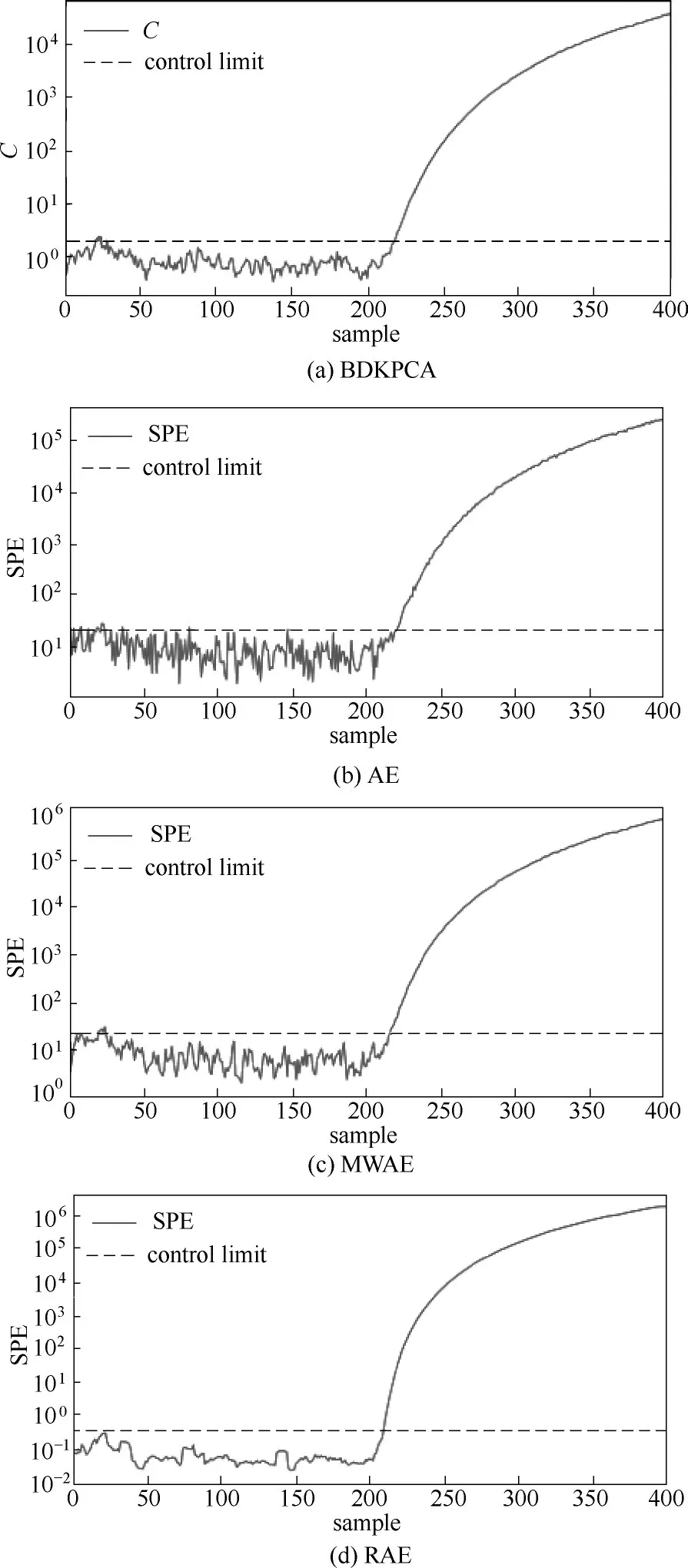
圖5 故障2的監測結果Fig.5 Monitoring results of fault 2
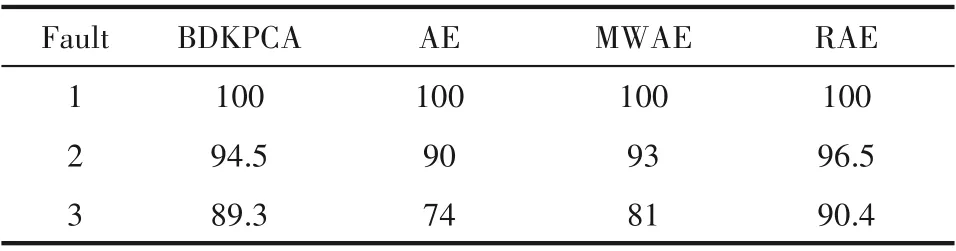
表4 四種方法的故障檢測率Table 4 Fault detection rate of four methods/%

圖6 故障3的監測結果Fig.6 Monitoring results of fault 3
四種方法對三個故障批次的詳細故障檢測率和誤警率分別如表4 和表5 所示。由故障檢測率和誤警率的對比可知,BDKPCA 和MWAE 比AE 方法具有更強的故障檢出能力以及更低的誤警率,說明處理過程動態性是必要的。而RAE 相比于其他三種方法故障檢測率最高,且誤警率明顯降低,可靠性較好。RAE 使用LSTM 網絡建立基于時間序列的AE,具有較好的非線性表達能力,且能動態記憶歷史信息,有利于故障監測。綜上可知,對于非線性和動態性較強的間歇過程,本文所提出的基于RAE的監測方法是有效的。

表5 四種方法的誤警率Table 5 False alarm rate of four methods/%
4 算法實際驗證
實驗數據來源于北京某生物制藥公司,該公司主要以基因重組大腸桿菌外源蛋白質表達制備白介素-2。該公司提供了30 批正常工況大腸桿菌發酵生產歷史數據,選取用于進行監測的7 個主要過程變量如表6所示。本次實驗中的發酵批次持續時間6~7 h。數據從菌體接種入罐開始采集,每5 min采樣一次,30個批次三維數據集為X(30×7×72)。
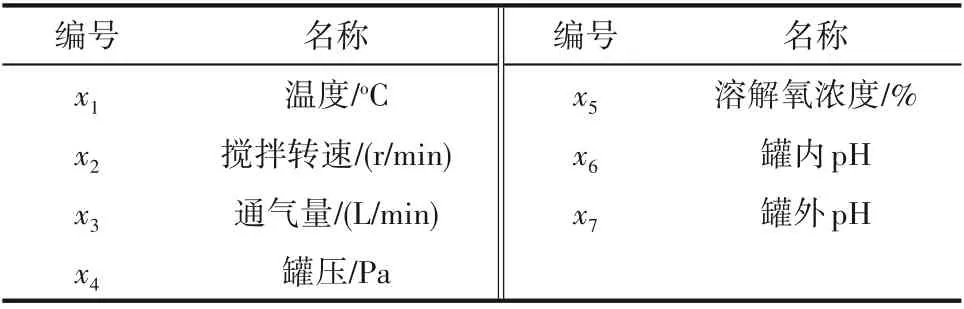
表6 大腸桿菌發酵過程主要變量Table 6 The main variables of recombinant Escherichia coli fermentation process
故障批次為,在第38 個采樣時刻引起的,表現為斜率2%的斜坡故障。圖7 分別為AE 和RAE 對故障批次的監測結果。傳統AE 方法在發酵開始階段出現了誤報警,SPE 統計量在第42 個采樣時刻超過控制限,存在一定延遲。RAE 方法的監測統計在第40 個采樣時刻超出控制限,不存在故障的漏報警和誤報警現象。通過以上分析,監測方法可以有效檢測出生產過程中的故障,具有較大的實用價值。
5 結 論
本文針對間歇過程的非線性和動態性問題,提出了基于RAE 的過程監測方法。該方法利用LSTM循環神經網絡構建自動編碼器,解決過程非線性的同時可以有效學習時序樣本間的動態關聯信息。青霉素發酵仿真和重組大腸桿菌實際生產過程案例研究表明,相比傳統方法,RAE 能更及時地檢測到過程故障,誤警率較低,具有一定應用價值。
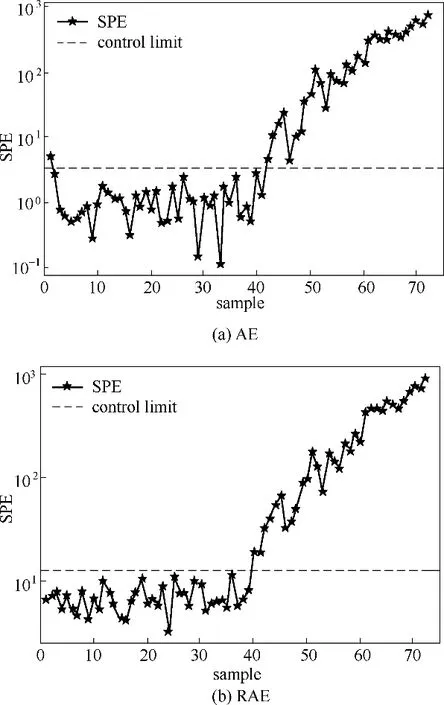
圖7 故障監測結果Fig.7 Monitoring results of fault
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
兒童故事畫報(2019年5期)2019-05-26 14:26:14
汽車維護與修理(2016年10期)2016-07-10 08:17:41
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
汽車維修與保養(2015年12期)2015-04-18 07:51:49
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維修與保養(2015年2期)2015-04-17 01:30:34
