基于多源異構數據挖掘的“紅色記憶”知識圖譜構建
2020-07-04 12:32:11郭嘉欣
知識管理論壇 2020年1期

摘要:[目的/意義]中華民族與中國共產黨人對真理追求的過程形成紅色文化資源,對其進行知識組織和挖掘構建“紅色記憶”,不僅能夠提升民族自信與凝聚力,更是堅定文化自信的重要途徑。針對紅色文化資源所存在的分布廣、來源多、類型雜、內容有限、組織程度低等問題,構建基于多源異構數據挖掘的“紅色記憶”知識圖譜,以充分利用紅色文化資源。[方法/過程] 首先通過設計概念、關系及屬性構建紅色文化資源本體庫,完成 “紅色記憶”的知識建模工作;其次通過多渠道采集紅色文化資源,具體分析紅色文化資源的構成和特點,針對這些多源異構數據進行實體、屬性、關系識別采取;最后通過圖數據庫存儲構建“紅色記憶”知識圖譜。[結果/結論] 通過構建“紅色記憶”知識圖譜,能夠對多源異構的紅色文化資源數據進行深層關系挖掘,提升紅色文化資源的組織水平,為實現紅色文化智能化服務奠定基礎。
關鍵詞:紅色文化資源? 知識圖譜構建? 知識建模
分類號:G250
引用格式:郭嘉欣. 基于多源異構數據挖掘的“紅色記憶”知識圖譜構建[J/OL]. 知識管理論壇, 2020, 5(1): 59-68[引用日期]. http://www.kmf.ac.cn/p/200/.
1? 引言
紅色文化資源是中華民族與中國共產黨人在對真理追尋的過程中形成的,這使得其歷史發展的周期性較長,從而導致紅色文化資源在開發和利用的過程中存在著分布廣、來源多、類型雜、內容有限、組織程度低等問題,阻礙了用戶對紅色文化資源的深層次利用。2012年,谷歌公司首先提出知識圖譜的概念[1],意在從語義角度組織網絡數據,構建大型知識庫,進而提供智能搜索服務。國內外各公司和研究機構也紛紛開始構建知識圖譜,如德國馬普所的YAGO[2]、谷歌的Knowledge Vault[3]、復旦大學的CN-DBpedia[4]及清華大學的XLore[5]等。知識圖譜作為一種重要的知識表示方式,逐漸成為各行各業從網絡化向智能化轉型升級的重要一環,具有廣闊的發展前景[3]。
紅色文化資源作為中華優秀文化的重要構成部分,蘊涵著十分豐富的革命和歷史價值,是堅定文化自信的基礎支撐[6]。受電子技術迅速發展的影響,許多地區提出了建立紅色文資源數據庫,如四川特色文化資源數據庫[7]、西柏坡紅色教育資源基礎數據庫[8]等,這在一定程度上使得紅色文化資源的組織程度得到了提升,但也還僅僅停留在數據存儲的階段,其組織程度還不夠高。知識圖譜這一新的資源組織方式并沒有在紅色文化資源的研究利用中得到廣泛的應用。因此,筆者通過采集結構各異、來源不同的紅色文化資源數據,對其進行知識組織和挖掘,進而構建“紅色記憶”知識圖譜,提升紅色文化資源組織程度,把紅色文化資源以更直觀、動態、關聯的形式呈現給用戶。
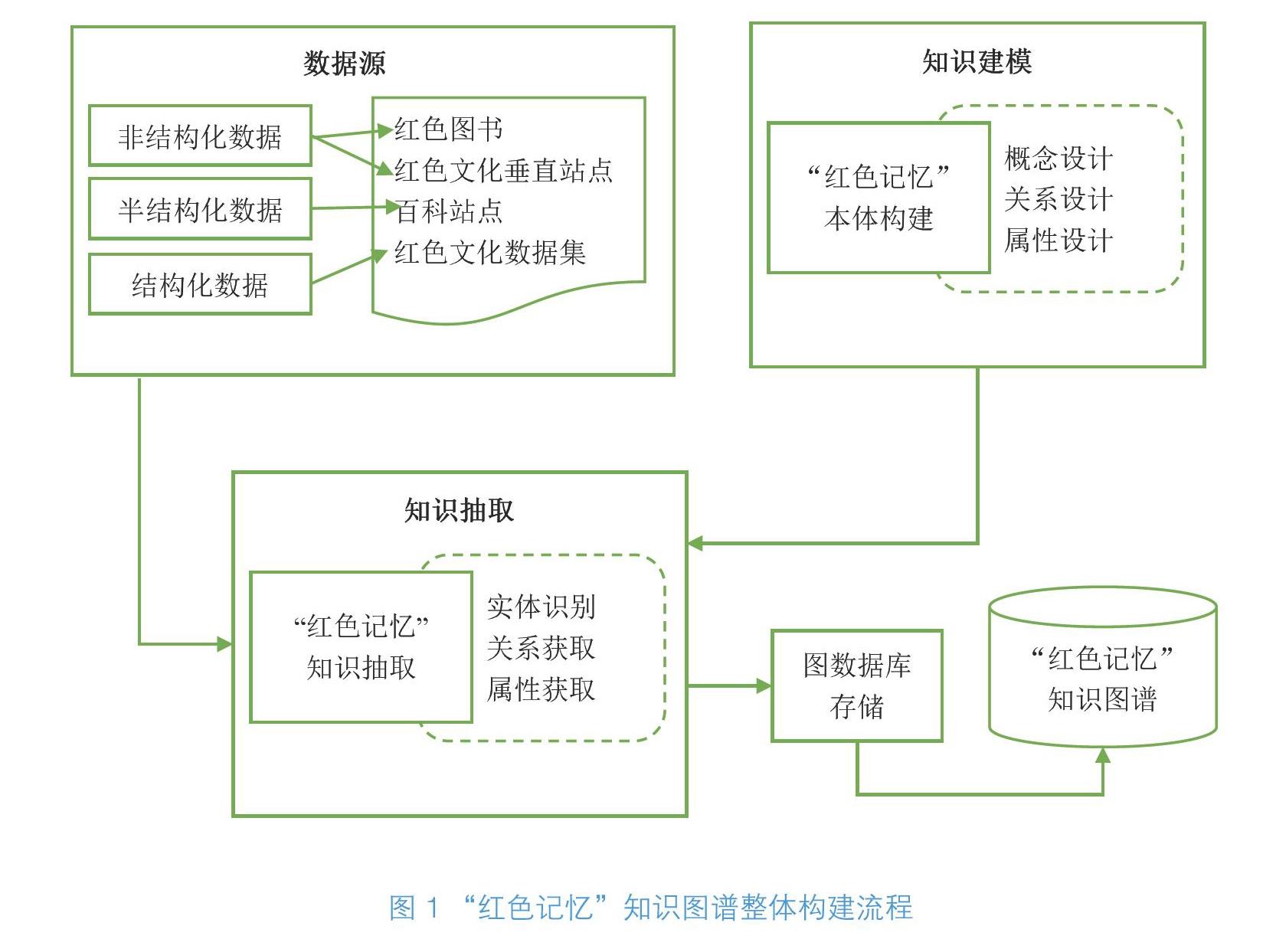
2 “紅色記憶”知識圖譜的構建流程
紅色文化資源是中國共產黨領導的革命和建設中所形成的崇高精神及其物質載體的總稱[9],它不僅存在于過去,而且發展于當下,其內涵將伴隨歷史進程和實踐需要而不斷深化。對紅色文化資源進行組織和挖掘,可以重現蘊涵在其中的“紅色記憶”。知識圖譜本質上是結構化、語義化的知識庫,它以圖的結構表示現實世界中的實體、屬性及其關聯,其中圖的節點代表實體,而實體之間存在的語義關聯則用圖中的邊來描述 [10]。構建知識圖譜的方式主要有以下兩種:自頂向下和自底向上 [11]。自頂向下的方式是指事先細化概念及概念之間的關系,完成本體庫設計,形成知識圖譜的Schema層,然后將實體匹配填充到預定義好的本體Schema層中。自底向上的方法則是先從語料庫或數據集中抽取出實體、屬性和關系,并把同類型的實體重新進行組織,將其抽象為概念,最后構建得到Schema層。
筆者將綜合應用自頂向下和自底向上這兩種不同的方式來構建“紅色記憶”知識圖譜。首先,通過觀察比較紅色文化資源的各個數據源,確定“紅色記憶”知識圖譜所需要的具體數據,通過編寫網絡爬蟲、手動采集等方式從紅色圖書、網站、開放數據集、百科等多種數據源中獲取構建“紅色記憶”知識圖譜所需要的數據,其中,開放數據集是結構化數據的主要來源,百科是半結構化數據的來源,從紅色圖書和紅色文化垂直站點獲取的則是非結構化文本;其次,通過剖析紅色文化資源數據的構成及特征來設計概念、關系及屬性,運用工具Protégé構建紅色文化資源本體庫,從而完成“紅色記憶”知識建模;然后,基于設計好的本體庫,根據所獲取的不同形式的數據采取不同的方法進行實體、關系、屬性的抽取;最后,將識別得到的紅色文化資源知識進行整合處理,并將其存入圖數據庫Neo4j中,通過Neo4j 完成知識的可視化呈現,實現“紅色記憶”知識圖譜的構建,整體過程如圖1所示。
3? 基于“紅色記憶”本體構建的知識建模
知識建模是知識圖譜構建的一項重要任務,它是對知識進行邏輯化和體系化的過程。通過本體構建來進行知識建模能夠充分描述知識圖譜中所涉及到事物的屬性及聯系。本體作為一種抽象化的表示模型,可以清楚明了地定義和描述概念及概念之間的關系,確定知識圖譜的數據形態,說明知識圖譜中存在哪些數據,例如實體的類別、不同實體所擁有的屬性、實體與實體之間的關聯[12]。本體的構建過程較為復雜,為了確保規范性,構建本體時必須要遵循相應的原則。目前被廣泛認同的本體建模規范是T. R. Gruber提出的5條準則:明確性、一致性、可擴展性、最小編碼偏差和最小本體承諾[13]。對于本體構建方法而言,目前已有一些較為成熟的方式,如IDEF-5法、Methontology法、七步法和基于敘詞表構建本體法等,其中,七步法相比其他方法而言具有一定的通用性[14],所以筆者選用七步法,并綜合考慮紅色文化資源自身的特點,構建“紅色記憶”本體庫。
作為一種特別的文化資源,紅色文化資源不僅具有資源的屬性也具有文化的屬性,還具有二者深度融合所衍生出來的特殊屬性[15],這也導致了其分類標準的多樣性。根據渠長根等[16]的歸納,目前學術界針對紅色文化資源所采用的最基本的分類法是將其劃分為物質和精神兩大類,除此之外,有的學者將紅色文化資源劃分為動態和靜態兩種類型,或是根據一般、特殊的兩分法來對紅色文化資源進行分類。在實際的研究中,除了將紅色文化資源按照簡單的二分法標準來劃分外,通常還會根據不同的學科需要來進行進一步的調整劃分,張泰城[17]依據“以主題分類為主、兼顧學科的原則”,并遵循中文的語言習慣將紅色文化資源劃分為紅色舊址、器物、文獻、人物、事件、文藝、建筑、精神、研究、創作10個大類;張克偉[18]按照國家旅游資源的分類方法首先把紅色文化資源細分為三大主類:遺址遺跡、建筑和設施、人文活動,再將其細分為10種基本類型,其中遺址遺跡包含歷史事件的發生地、軍事遺址與古戰場兩類,建筑和設施分為文化活動場所、展示演示的場館、碑碣(林)、名人故居和歷史紀念建筑、陵區陵園5類,人文活動包含人物、事件和文藝作品3類。
構建“紅色記憶”本體庫通常需要對概念、屬性及關系等多個方面進行設計考量。對于“紅色記憶”來說,其核心是人,因此首先確定的是“人物”這一重要概念,與之密切聯系的必然是人物所經歷或參與的事件,因此也加入“事件”概念。根據“人物”和“事件”這兩個主題概念對“紅色記憶”相關的信息進行瀏覽,發現人物所加入的組織與人物和事件的聯系也非常密切,故將“組織”加入本體列表。除此之外,人物故居、紀念館、陵園等信息也是比較重要的概念,而這些信息都可以看作是建筑,因此,新增“建筑”這一概念。針對“紅色記憶”,其所具有的文化屬性也必然會涉及到紅色文學藝術作品,所以增加“資源”這一概念。這5個概念確定之后,參考前文提到的分類標準以及實際搜集到的數據來輔助劃分子概念。其中,人物作為獨立概念不再進行劃分;由于搜集到的事件相關數據基本為會議和戰爭兩類,所以將事件劃分為會議、戰爭及其他3類,同樣地將組織劃分為學校、軍團、政黨和其他,將建筑分為名人故居、紀念館、紀念碑、紀念塔、遺址(舊址)、陵園、陵墓;資源則按照載體形態的不同分為書籍、電影、畫作、詩詞和歌曲。綜合考慮以上幾個概念,發現事件、建筑、組織的細分概念存在一些模糊的邊界問題難以確定,并且直接使用子類概念進行構建會降低本體的可擴展性,所以將事件、建筑、組織的子類概念取消,轉而新增“類型”這一概念,并將類型劃分為事件類型、建筑類型和組織類型3類,并在各類型中添加“其他”這一選項,從而保證了所構建本體的全面性、準確性和可擴展性。
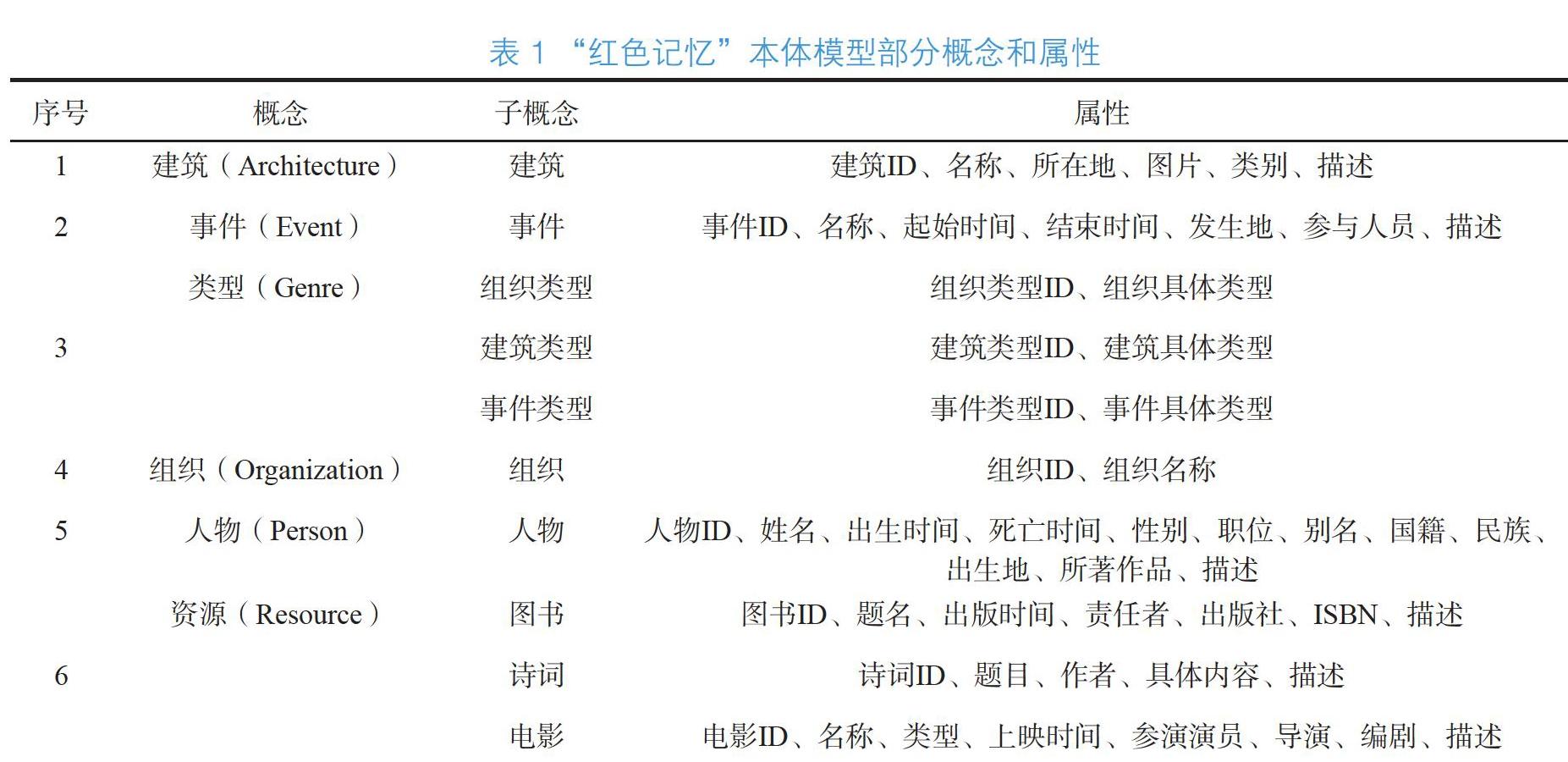
綜上所述,“紅色記憶”本體中的概念主要分為以下6個類別:建筑(Architecture)、事件(Event)、類型(Genre)、組織(Organization)、人物(Person)、資源(Resource),其中類型與資源兩個概念下又劃分了多個子概念,類別分為建筑類型、事件類型和組織類型。對每個類別的數據進行分析發現每個概念具有的特征不同,故根據不同類別的特征對屬性進行定義,這里選取了“紅色記憶”本體模型部分概念和屬性進行展示,如表1所示:
上述所設計的本體庫中,概念和子概念之間是上下位關系,子概念具有不同的屬性,子概念所包含的實體和實體之間則存在不同的語義關聯,如人物與人物之間存在“配偶”、“子女”等多種關系,建筑與人物/事件之間存在“紀念”關系,基于前文所述概念設計,最終確定“紅色記憶”中所涉及的部分關系。通過本體構建工具Protégé添加“紅色記憶”定義好的概念及關系,完成“紅色記憶”知識建模,設計的部分本體概念如圖2所示:
4 “紅色記憶”數據源與知識獲取
紅色文化資源見證了我們黨從成立之初到逐漸發展壯大的整個過程[19],其歷史發展的周期較長,所以其資源采集、處理和存儲方式也不盡相同,這也使得與紅色文化資源有關的數據也呈現出明顯的多源異構性。全國各地的圖書館、檔案館、博物館及各類紀念館、陳列館、紅色旅游景點等都是獲取紅色文化資源的來源,除此外,大數據時代的到來也使得各種Web資源變成獲取紅色文化資源的重要來源。所以,從這些來源采集到的結構化數據、半結構化數據和非結構化數據就是構建“紅色記憶”知識圖譜的數據基礎。
結構化數據能夠用數字或文字來描述或表達,具有相同的層次或網絡結構,通常存儲在關系型數據庫中。“紅色記憶”的結構化數據主要來源于開放數據集,具體方法是利用API接口將數據下載到本地并存儲為關系型數據。“紅色記憶”知識圖譜的構建便是基于結構化數據,并搜集其他不同來源、不同結構的數據進行補充。
非結構化數據通常是利用自然語言形式保存的文本資源[20],是最豐富的知識來源,在紅色文化網頁、紅色旅游網頁、圖書等非結構化的數據源中均存在大量文本。實體識別作為自然語言文本處理的基礎[21],是知識圖譜構建的重要步驟。實體識別即命名實體識別,是指從語料中抽取出具有特定含義的命名性指稱項,如人名、地名及機構名等[22]。對“紅色記憶”知識圖譜而言,要識別的實體即是在模式層的“紅色記憶”本體模型中所定義的概念。對于實體識別,目前最常用的方法是通過機器學習來實現,可以利用網絡爬蟲等相關工具從網頁中獲取“紅色記憶”語料,再利用分詞工具對語料進行分詞、標注等預處理工作,之后將標注好的語料進行詞向量轉換。最后選取訓練集語料,并通過機器學習訓練出抽取模型[23],利用實體識別模型來從文本中提取出“紅色記憶”的實體。實體識別完成后,可繼續進行屬性獲取。
“紅色記憶”知識圖譜實體屬性獲取的來源是各類百科網站詞條的infobox,infbox中的信息通常為半結構化數據,這些數據具有較高的一致性和完整性,這使得在獲取“紅色記憶”中人物信息時,只需利用爬蟲爬取百科詞條中相應的infobox標簽即可獲取關于人物的一些基本信息。例如圖3展示的是“楊至成”這一人物詞條的360百科的infobox信息,選取其中的中文名稱、外文名稱、別名、國籍4個屬性,通過瀏覽網頁源代碼可以得到這些屬性的信息(見圖4)。通過解析網頁源代碼,發現根據“class”標簽找到人物所對應的屬性,那么可以利用python的BeautifulSoup 庫來對html元素進行操作,從而獲取“楊至成”的屬性信息,得到<實體,屬性,屬性值>三元組。
實體間關系的識別抽取則與實體識別的原理類似,再獲取得到“紅色記憶”實體后,結合所獲得的“紅色記憶”實體,選取含實體對象較多的語句,對其進行實體關系的抽取。通過對實體、屬性、關系的識別抽取,最終獲取到構建“紅色記憶”知識圖譜所需要的實體、屬性和關系。最后,把從不同來源獲取的數據進行整理歸類,并將其存儲在關系數據庫中,部分數據示例如圖5所示:
5 “紅色記憶”知識存儲
目前,知識圖譜的存儲工作主要是通過圖數據庫完成的。通過圖數據庫存儲知識圖譜,能夠實現圖數據的可視化,并能通過圖數據庫所提供的各種工具對知識圖譜進行集成管理,能高效迅速地滿足用戶的各類需求。當前,Neo4j以其優良的性能和簡單的操作等優點,在各種圖數據庫中使用最為廣泛。筆者將“紅色記憶”知識圖譜存儲在Neo4j中,Neo4j中的標簽代表“紅色記憶”中的概念,節點代表了“紅色記憶”中的實體,而邊則描述的是關系。Neo4j通過執行Cypher命令能夠管理和操作知識圖譜中的數據。由于Cypher命令提供批量導入CSV格式數據的Load語句,所以將關系型數據庫中的“紅色記憶”知識轉化為CSV格式的文件進行存儲,并按照以下語句批量導入。
批量導入概念/實體(以導入“建筑”為例):
LOAD CSV WITH HEADERS? FROM “file:///Architecture.csv” AS line
MERGE(p:Architecture{ArchID:line.ArchID,nameS:line.nameS,address:line.address,place:line.place,firstImg:line.firstImg,type:line.type,desc:line.desc})
批量導入關系(以導入人物與事件之間的關系“ParticiPateIn”為例):
LOAD CSV WITH HEADERS FROM “file:///PersonToEvent.csv” AS line
Match(from:Person{PersonID:line.PersonID}),(to:Event{EventID:line.EventID})
merge(from)-[r:participateIn{PersonID:line.PersonID,EventID:line.EventID}]->(to))
將存儲在關系型數據庫中的“紅色記憶”知識批量導入Neo4j后形成“紅色記憶”知識圖譜,結果如圖6所示,藍色的圓點表示人物,綠色的圓點表示組織,紅色圓點表示建筑,棕色圓點表示紅色資源,橙色原點代表事件,通過箭頭指示它們之間的關系。由于知識圖譜所具有的開放互聯的特性,后續還可運用Cypher命令增加新的數據[24],形成大規模“紅色記憶”知識圖譜,從而實現紅色文化智能搜索、知識問答、知識推理等應用,為實現紅色文化資源的智能化服務奠定基礎。
6? 結語
將知識圖譜這一新的組織技術應用于紅色文化資源的開發研究,是紅色文化資源學科發展的必然抉擇,也是數字化、智能化的時代要求。筆者通過定義概念、屬性、關系設計了“紅色記憶”本體庫,完成“紅色記憶”知識建模,并從結構不同、來源各異的紅色文化數據源獲取數據,基于這些數據進行命名實體的識別、關系及屬性抽取來獲取知識,進而得到“紅色記憶”三元組,并將其存儲于Neo4j中,構建了“紅色記憶”知識圖譜,從而更進一步地提升紅色文化資源的組織程度,將紅色文化資源以更直觀、更現代的方式呈現出來,使得分布于各處的碎片化紅色文化資源得到了重組[25],重現了蘊涵在書籍、歌曲、遺址中的“紅色記憶”。在后續的工作中,筆者將進一步對“紅色記憶”知識圖譜的智能問答、知識推理等應用進行研究,滿足用戶對于紅色文化的智能化服務的需求,更大程度上發揮紅色文化資源中所蘊含的價值。
參考文獻:
[1] SINGHA A. Introducing the knowledge graph: things, not strings[EB/OL]. [2019-04-10]. http://googleblog.blogspot.co.uk/2012/05/introducing-knowledge-graph-things-not.html.
[2] SUCHANEK F M, KASNECI G, WEIKUM G. Yago: a core of semantic knowledge[C]//Proceedings of the 16th international conference on World Wide Web. New York: ACM, 2007: 697-706.
[3] DONG X, GABRILOVICH E, HEITZ G, et al. Knowledge vault: a web-scale approach to probabilistic knowledge fusion[C] //International conference on knowledge discovery and data mining. New York: ACM, 2014: 601-610.
[4] XU B, XU Y, LIANG J, et al. CN-DBpedia: a never-ending Chinese knowledge extraction system[C]//International conference on industrial, engineering and other applications of applied intelligent systems. Berlin: Springer, 2017: 428-438.
[5] WANG Z, LI J, WANG Z, et al. XLore: a large-scale English-Chinese bilingual knowledge graph[C]//International semantic Web conference. New York: ACM, 2013: 121-124.
[6] 胡果, 張榮秀.中華紅色文化的主要特質及時代價值[J]. 山西廣播電視大學學報, 2017(1): 103-105.
[7] 王茂春.特色文化資源與高新技術融合的路徑探索[J]. 中華文化論壇, 2015(6): 128-133.
[8] 王玉平, 張同樂, 張志永.西柏坡紅色文化資源數據庫建設熱議[J]. 河北師范大學學報(哲學社會科學版), 2014, 37(1): 140-145.
[9] 李實.準確認識“紅色資源”的豐富內涵[J]. 政工學刊, 2005(12): 23.
[10] 漆桂林, 高桓, 吳天星.知識圖譜研究進展[J]. 情報工程, 2017, 3(1): 4-25.
[11] 劉嶠, 李楊, 段宏, 等.知識圖譜構建技術綜述[J]. 計算機研究與發展, 2016, 53(3): 582-600.
[12] 馬燦.面向“智慧法院”的知識圖譜構建方法與研究[D]. 貴州: 貴州大學, 2019.
[13] GRUBER T R. Toward principles for the design of ontologies used for knowledge sharing?[J]. International journal of human-computer studies, 1995, 43(5/6): 907-928.
[14] 岳麗欣, 劉文云.國內外領域本體構建方法的比較研究[J]. 情報理論與實踐, 2016, 39(8): 119-125.
[15] 張泰城.論紅色文化資源[J]. 紅色文化資源研究, 2015, 1(1): 1-11.
[16] 渠長根, 聞潔璐.紅色文化資源研究綜述[J]. 浙江理工大學學報(社會科學版), 2019, 42(2): 179-187.
[17] 張泰城.論紅色文化資源的分類[J]. 中國井岡山干部學院學報, 2017, 10(4): 137-144.
[18] 張克偉.沂蒙紅色文化資源產業化研究[D]. 濟南: 山東大學, 2010.
[19] 許慶領.人文地理信息整合及可視化關鍵技術研究[D]. 阜新: 遼寧工程技術大學, 2012.
[20] 郭文龍.中醫方劑知識圖譜構建研究與實現[D]. 蘭州: 蘭州大學, 2019.
[21] 張曉艷, 王挺, 陳火旺.命名實體識別研究[J]. 計算機科學, 2005(4): 44-48.
[22] 王良萸.基于web數據的碳交易領域知識圖譜構建研究[D]. 馬鞍山: 安徽工業大學, 2018.
[23] 蔣秉川, 萬剛, 許劍, 等.多源異構數據的大規模地理知識圖譜構建[J]. 測繪學報, 2018, 47(8): 1051-1061.
[24] 吳雪峰, 趙志凱, 王莉, 等.煤礦巷道支護領域知識圖譜構建[J]. 工礦自動化, 2019, 45(6): 42-46.
Abstract: [Purpose/significance] Red cultural resources are produced in the process of the Chinese nation and the Chinese Communists pursuit of truth. Constructing “red memory” by organizing and mining knowledge of red cultural resources can not only enhance national self-confidence and cohesiveness, but also be an important part of cultural self-confidence. There may be many problems when using red cultural resources, such as wide distribution, multiple sources and types, limited content and low degree of organization. In order to make full use of red cultural resources, this paper constructs a “red memory” knowledge graph based on multi-source heterogeneous data. [Method/process] Firstly, this paper constructed a red cultural resource ontology library for knowledge modeling of “red memory”. Secondly, it analyzed the composition and characteristics of red cultural resources collected through multiple channels and extract entities, attributes, relationships. Finally, the “red memory” knowledge graph was constructed through knowledge fusion and storage. [Result/conclusion] By constructing the “red memory” knowledge graph, it is possible to mine deep relationship on multi-source heterogeneous red cultural resource data, improve the organization degree of red cultural resources, and realize of intelligent services of red cultural resources.
Keywords: red cultural resources? ? knowledge graph construction? ? knowledge modeling
