應用深度強化學習的壓邊力優化控制
2020-06-24 02:58:30張新艷余建波
哈爾濱工業大學學報 2020年7期
張新艷, 郭 鵬, 余建波
(同濟大學 機械與能源工程學院, 上海 201804)
板材拉深成形作為一種基礎零部件制造工藝,被廣泛應用于汽車、機電、輕工和航空航天等諸多領域. 拉深成形通過壓邊力(blank holder force,BHF)來控制金屬材料的流動,從而影響最終成品的成形質量. 在拉深過程中采用恒定的壓邊力容易導致起皺與破裂等質量缺陷,因此在拉深過程中合理地控制壓邊力參數就成為防止起皺、破裂和提高成品質量的重要手段之一.
在壓邊力控制領域,最優化理論與有限元模擬相結合是一類常用的方法. Ghouati等[1]提出了網格法與單純形法相結合的優化方法,其計算效率高,能夠有效減少有限元仿真次數,但無法保證所求的解在可行域內. 包友霞等[2]在Ghouati提出的優化方法的基礎上進行改進,使得優化過程中各變量點始終保持在可行域內,保證了解的可行性. 孫成智等[3]提出了一種集成了有限元模擬與自適應響應面法(adaptive response surface method,ARSM)的優化設計方法,并且應用信賴域模型管理來調節設計空間的變化,保證優化過程的收斂. Hillmann等[4]將成形極限圖上各點到成形極限和起皺極限距離的加權和作為目標函數,以壓邊力作為設計變量,在有限元仿真環境下采用BFGS優化方法對壓邊力進行優化. Scott等[5]以極限應變作為目標函數,以壓邊力作為設計變量,在ABAQUS仿真環境下利用靈敏度分析方法對盒形件進行優化. 以上方法準確性較高,但數值模擬速度無法滿足優化迭代要求,限制了方法的使用,并且最佳壓邊力搜索方向也難以確定.
神經網絡被廣泛應用于處理壓邊力控制問題中的非線性關系. Senn等[6]采用近似動態規劃方法來進行壓邊力控制,利用神經網絡來擬合系統動力學以及價值函數. 黃玉萍等[7]通過建立徑向基網絡,以應力、應變和減薄率作為輸入,壓邊力曲線作為輸出,構建了壓邊力優化模型. Qian等[8]和Manabe等[9]利用神經網絡進行材料參數和工藝參數的在線識別,并結合彈塑性理論預測壓邊力大小. 汪銳等[10]通過將模糊控制技術與神經網絡相結合,構建模糊神經網絡專家系統來進行壓邊力的智能控制.
傳統的壓邊力控制方法往往需要對拉深過程進行建模或依賴一些先驗知識. Dornheim等[11]提出了一種無模型的壓邊力控制方法,避免了系統模型的擬合. 該方法將神經擬合Q迭代(neural fittedQiteration, NFQ)算法與有限元仿真相結合,為每個控制步長建立一個Q值網絡. 然而NFQ是一種基于價值的強化學習算法,只能用于離散動作空間的控制問題,無法用于連續動作空間的控制問題. 綜合以上分析,目前壓邊力控制領域還存在難以獲得精確動力學模型以及壓邊力控制效果無法達到最優化的問題.
本文提出了一種基于深度強化學習的壓邊力優化控制模型,提高了壓邊力的控制效果;引入一種新的策略網絡結構,進一步提高了深度強化學習在壓邊力控制任務中的控制效果;將壓邊力理論知識引入網絡訓練中,用理論壓邊力公式進行回放經驗池的初始化,提高了壓邊力策略的學習效率;以一個圓筒件的拉深成形過程為分析對象,通過有限元仿真驗證了本文提出的壓邊力優化控制模型的有效性.
1 理論背景
1.1 馬爾科夫決策過程
強化學習(reinforcement learning,RL)問題一般由馬爾科夫決策過程(Markov decision process,MDP)進行建模[12]. 通常將MDP定義成一個四元組(S,A,r,p),其中:1)S為所有系統狀態集合,st∈S表示智能體(agent)在時刻t的系統狀態;2)A為動作集合,at∈A表示agent在時刻t所采取的動作;3)r為回報函數,r(st,at)表示在狀態st下采取動作at后的獎勵值;4)p為狀態轉移概率分布函數.p(st+1|st,at)表示在狀態st下采取動作at后轉移到下一狀態st+1的概率.
在強化學習中,定義策略π:S→A為狀態空間到動作空間的一個映射. 在每個離散步長t,agent在當前狀態st下根據策略π采取動作at,接收到回報值r(st,at)并轉移到下一狀態st+1. 定義Rt為從t時刻開始到T時刻情節(episode)結束時的累積回報值:
式中:γ∈[0,1]為折扣率,用來確定短期回報的優先程度.
1.2 強化學習
強化學習的目標是尋找到一個最優策略πφ(參數為φ)來最大化期望回報值J(φ)=Esi~pπ,ai~π[R0][13]. 在行動者-評論家(actor-critic)框架中,策略網絡(actor)通過確定性策略梯度[14](deterministic policy gradient,DPG)進行網絡更新:
φJ(φ)=Es~pπ[aQπ(s,a)|a=π(s)φπφ(s)],
式中:Qπ(s,a)=Esi~pπ,ai~π[Rt|s,a]為動作值函數(critic),表示在遵循策略π情況下,在狀態s采取動作a后的期望回報值.
Q學習(Q-learning)使用時間差分算法進行動作值函數的學習,通過迭代貝爾曼方程求解Q函數:
Qπ(st,at)=r(st,at)+γEst+1,at+1[Qπ(st+1,at+1)],at+1~π(st+1).
對于巨大的狀態空間,通常使用一個可微的函數近似器Qθ(s,a)估計動作值,其參數為θ. 深度Q學習[15](DeepQ-learning,DQN)算法采用了“目標網絡”技術,在更新過程中使用另一個網絡Qθ′(s,a)計算目標值:
yt=r(st,at)+γQθ′(st+1,at+1),at+1~πφ′(st+1).
式中動作at+1根據目標策略網絡πφ′進行選擇. 獲得目標值后,DQN通過最小化損失函數L(θ)進行動作值網絡參數的更新:
L(θ)=Est,at,r(st,at),st+1[(yt-Qθ(st,at))2].
2 基于深度強化學習的壓邊力控制策略優化算法
通過將雙延遲深度確定性策略梯度[16](twin delayed deep deterministic policy gradient,TD3)與結構化控制網絡[17](structured control network,SCN)相結合,本文提出了SCN-TD3算法用于壓邊力控制策略的學習.
2.1 雙延遲深度確定性策略梯度
TD3是一種actor-critic框架的深度強化學習算法,在深度確定性策略梯度[18](deep deterministic policy gradient,DDPG)的基礎上拓展而來. 為了解決actor-critic框架算法中的Q值過估計問題,TD3采用3個關鍵技術提高算法的穩定性和性能.
1)actor-critic框架下的剪裁雙Q學習.受深度雙Q學習[19](double deepQ-learning,DDQN)啟發,TD3使用當前actor網絡選擇最優動作,使用目標critic網絡評估策略:
yt=r(st,at)+γQθ′(st+1,πφ(st+1)).
在actor-critic框架中,目標actor與目標critic網絡采用的“軟更新”[18]方式使得當前網絡與目標網絡過于相似,無法有效分離動作選擇與策略評估. 因此,算法保持了一對actor網絡(πφ1,πφ2)和一對critic網絡(Qθ1,Qθ2). 其中,πφ1根據Qθ1進行優化,πφ2根據Qθ2進行優化:
(1)
如果critic網絡Qθ1與Qθ2相互獨立,那么根據式(1)能有效避免由于策略更新所導致的偏差. 然而Qθ1與Qθ2在計算目標值時互相使用,并且基于相同的回放經驗進行更新,因此兩者并不互相獨立. 為了進一步減小偏差,TD3使用了剪裁雙Q學習(Clipped DoubleQ-learning)算法計算目標值:
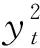
2)策略延遲更新.在深度強化學習算法中,目標網絡被用于提供一個穩定學習目標. 通過多步更新,critic網絡能逐漸減小與目標Q值之間的誤差;然而,在critic網絡高誤差情況下,進行actor網絡的更新會導致策略的離散行為. 因此,actor網絡的更新頻率應低于critic網絡的更新頻率,保證actor網絡能在Q值誤差較低的情況下進行更新,提高actor網絡的更新效率. TD3在critic網絡每進行d次更新后,進行一次actor網絡的更新.
3)目標策略平滑正則化.由于TD3中采用的是確定性策略,進行critic更新時目標值很容易受函數近似誤差的影響,導致目標值不準確. 因此TD3引入了一個正則化方法來減少目標值的方差,通過自舉相似狀態動作對的估計值進行Q值估計平滑化:
yt=r(st,at)+Εε[Qθ′(st+1,πφ′(st+1)+ε)].
TD3通過向目標策略添加一個隨機噪聲,并且在mini-batches上取平均的方法實現平滑正則化:
ε~clip(N(0,σ),-c,c).
2.2 結構化控制網絡
受傳統非線性控制理論啟發,文獻[17]提出了結構化控制網絡(structured control network,SCN),將actor-critic框架中的策略網絡分為非線性部分與線性部分兩個部分. 將上述兩個部分的動作值相加得到最終動作:
πφ(s)=πn(s)+πl(s).
式中:線性項πl(s)=K·s+b,K與b為線性控制增益矩陣與偏置項. 非線性項πn(s)為一個全連接多層神經網絡,并去除輸出層的偏置項. 這種簡單的結構變化能夠有效地提升深度強化學習的性能,在機器人控制以及視頻游戲等領域均取得了比原網絡結構更加優異的表現.
2.3 理論壓邊力知識
在壓邊力控制領域,研究人員通過板材成形理論以及對拉深過程的簡化假設,推導了圓筒件拉深過程的有效壓邊力區間. 通過預先確定有效壓邊力區間,能夠得到相對合理的壓邊力曲線.
如圖1所示,板材拉深過程的有效壓邊力范圍由上限壓邊力Qrup與下限壓邊力Qfwr組成.Qrup表示在拉深過程中保證工件不產生破裂缺陷的最大壓邊力,Qfwr表示在拉深過程中保證工件法蘭邊不產生起皺缺陷的最小壓邊力. 其中,

[1-μK1(α)]-2ωI(α)-J(α)}.
式中:μ為拉深過程中毛坯與模具間的摩擦因數,n為材料的硬化指數,σb為材料的抗拉強度,r為材料的厚向異性系數.RB、RC、F(α)、K1(α)、ω、I(α)與J(α)是隨著拉深過程變化的變量,具體物理意義與計算方式參見文獻[20].
式中:t0為板材厚度,B為材料的強度系數,y0為單波的最大撓度,r0為法蘭內半徑,m為拉深系數,F(n,m,ρ)與Fm(λm)為隨拉深過程變化的兩個變量,具體物理意義與計算方式參見文獻[21].
圖1中位于上限壓邊力與下限壓邊力之間的3條壓邊力曲線是由3種深度強化學習算法優化學習得到的. 可以看出,它們在整個拉深過程中始終保持在Qrup與Qfwr之間,保證了最終成品不產生質量缺陷.
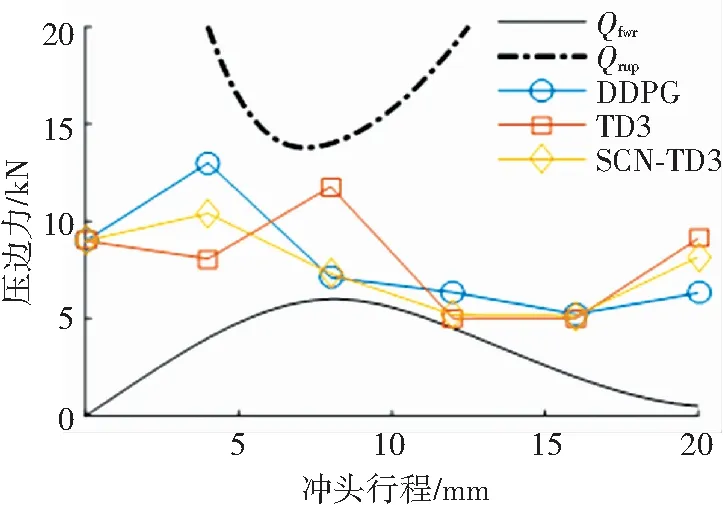
圖1 有效壓邊力Fig.1 Effective blank holder force
2.4 算法描述
本文將SCN-TD3與有限元仿真相結合,構建了基于深度強化學習的壓邊力控制策略優化算法, 算法描述如下.
輸入:有限元模型
輸出:actor網絡πφ
第1步:初始化critic網絡Qθ1與Qθ2的參數θ1與θ2,以及actor網絡的參數φ
第2步:初始化目標網絡參數:θ1′←θ1,θ2′←θ2,φ′←φ
第3步:初始化回放經驗B
第4步:For episode = 1,Mdo
第5步:初始化有限元模型狀態s1
第6步:Fort= 1,Tdo
第7步:選擇動作at,
at←πφ(st)+ε,ε~N(0,σ)
第8步:在有限元模型中執行at,輸出st+1與rt
第9步:將轉移經驗存儲到回放經驗中,(st,at,r(st,at),st+1)→B
第11步:利用目標網絡得到動作
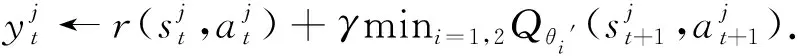
第13步:根據梯度
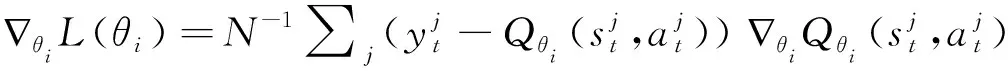
第14步:Iftmoddthen
第15步:根據梯度
第16步:更新目標網絡
θi′←τθi+(1-τ)θi′,φ′←τφ+(1-τ)φ′
第17步:End if
第18步:End for
第19步:End for
3 基于深度強化學習的拉深控制模型
3.1 問題描述
本文針對板材拉深過程進行壓邊力控制優化,得到成形質量合格的成品件. 如圖2所示,板材拉深裝置主要由毛坯、沖頭、壓邊圈和凹模4部分組成. 毛坯被放置在壓邊圈與凹模法蘭之間,由壓邊圈夾緊. 整個加工過程被分為5個控制步長,每個控制步長內壓邊力的大小相等,沖頭以恒定速度向下沖壓,將毛坯壓入凹模腔體. 本文將板材拉深控制過程建模成離散時間的馬爾科夫決策過程,以板材內部的Mises應力分布作為系統狀態s,每個控制步長內的壓邊力大小作為系統動作a. 由于本文所建立的有限元模型被劃分為527個單元,使用全體單元的Mises應力分布作為系統狀態會使得狀態空間過于龐大,不利于問題的有效求解. 因此,本文采用圖2標記的部分有限元的Mises應力作為系統狀態,在反應系統狀態特征的同時將系統狀態縮小為27維.
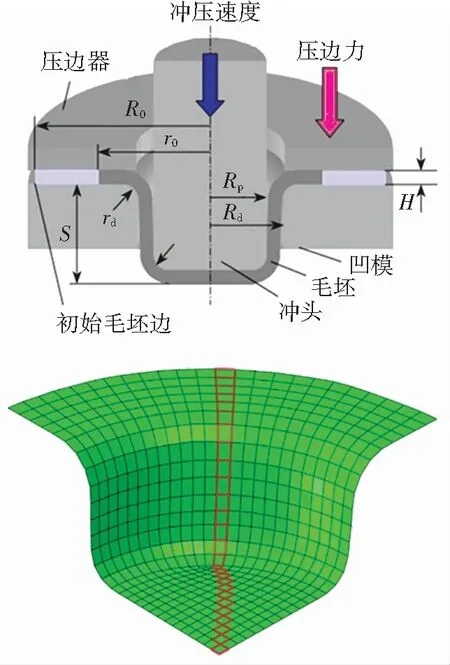
圖2 拉深模型Fig.2 Deep drawing finite element model
3.2 壓邊力控制模型
壓邊力控制模型如圖3所示,主要由環境與智能體兩部分組成. 其中,環境由有限元模型與成本函數組成;智能體由兩個價值網絡以及一個策略網絡組成. 環境接受到動作a,根據前一時刻環境狀態得到當前的回報r與觀察值s并將其輸入智能體,智能體輸出下一步長動作,開始下一次交互. 智能體在與環境進行交互的過程中利用深度強化學習算法不斷地更新網絡參數,最終學習到一個最優的壓邊力控制策略.
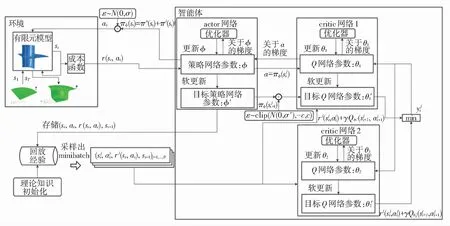
圖3 壓邊力控制模型Fig.3 Blank holder force control model
3.2.1 有限元模型
本文建立的板材拉深仿真模型如圖4所示. 通過假設模型對稱性與材料各向同性,建立了1/4的板材拉深三維模型,并將拉深過程劃分為6個離散的時間步長. 其中前5個為控制步長,完成向下拉深過程,最后1個步長為卸載步長,沖頭恢復到原始位置同時將壓邊力卸載. 模型根據上一步長的狀態與輸入的壓邊力值,計算出下一步長的狀態.
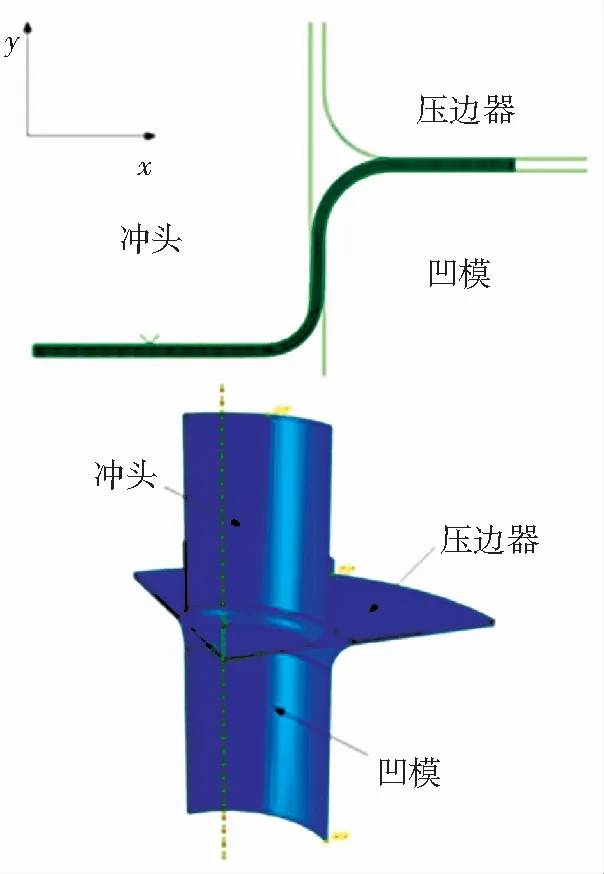
圖4 有限元模型Fig.4 Finite element model
有限元模型由3個剛體部件與1個可變形毛坯組成. 剛體部件分別為沖頭、凹模和壓邊圈. 沖頭半徑Rp為25 mm,沖頭圓角半徑rp為4 mm,凹模內徑Rd為26.2 mm,凹模圓角半徑rd為6 mm. 圓形毛坯厚度H為1 mm,半徑R0為50 mm. 毛坯材料屬性為彈塑性材料,材料為08F低碳鋼[22]. 材料的彈性模型為線彈性模型,塑性模型為符合Mises屈服準則的各向同性模型. 毛坯的有限元單元類型為可變形的4節點4邊形殼單元(S4R).
沖頭以恒定速度4 mm/s向下沖壓,將毛坯壓入凹模腔中,拉深深度S為20 mm. 壓邊力在每個控制步長開始時給出,在每個控制步長內壓邊力保持不變,均勻施加在壓邊圈上. 壓邊力變化范圍為5 000~13 000 N.
本文用ABAQUS進行有限元模型的搭建. 在線優化控制環境中,智能體基于當前得到的系統狀態來設置動作. 為了符合在線優化控制環境的要求,保證有限元模型的有效性與可重用性,使用了ABAQUS腳本與分析重啟動技術.
3.2.2 回報函數
回報函數僅由終止狀態產生的回報值組成. 控制目標為生產出的工件內部應力低,材料厚度充足,并且材料利用率低. 針對以上3個目標,分別建立評價指標函數并通過三者的加權和得出總的質量評價函數[11].
有限元模型由527個單元組成. 根據有限元仿真輸出的Mises應力分布云圖、厚度分布云圖與U1位移分布云圖,可以得到最終成品每個單元的Mises應力值mi(i=1,2,...,527)、單元厚度hi(i=1,2,...,527)以及毛坯邊在x軸方向上的位移d. 根據以上的數據,建立成本函數:
Cb(sT)=-minhi,
Cc(sT)=-d.
最后,本文以加權調和平均的形式給出總的質量評價函數:
式中權重值wi用于控制各個成本項的重要性,本文中權重wi均為1.
4 實驗與結果分析
受硬件因素影響,實際實驗驗證十分困難. 本文參考文獻[11]的壓邊力控制仿真實驗設計,利用圓筒件拉深成形的有限元仿真進行實驗.
4.1 訓練過程分析
在SCN-TD3中,策略網絡與價值網絡的結構均為4層神經網絡,隱藏層節點為300. DDPG與TD3的網絡結構與SCN-TD3一致. SCN-TD3算法中,學習率為0.000 1,探索率σ為0.1,目標動作噪聲方差σ'為0.2,目標動作截斷值c為0.2,策略網絡更新間隔d為2. DDPG和TD3的參數與SCN-TD3一致. 訓練過程中,算法在每個訓練步長進行10次網絡更新.
圖5為不同算法回報值隨訓練步長數的變化情況. 本文將各控制步長下壓邊力的相鄰訓練步長的差作為算法收斂的判斷依據. 當連續100個訓練步長下,各壓邊力相鄰訓練步長的差均<1 000 N時,認為算法收斂. 在SCN-TD3控制下,回報值大約在第1 500個步長收斂,而在DDPG與TD3控制下,回報值大約在第1 800與第1 700個步長收斂. 從回報值的整體變化趨勢上看,SCN-TD3控制下的回報值收斂最快,并且最終收斂到的回報值水平高于TD3. TD3控制下的回報值收斂略快于DDPG,并且最終收斂到的回報值水平高于DDPG. 這主要是由于1)TD3算法中采用的剪裁雙Q學習、延遲策略更新和目標策略平滑正則化這3種技術,有效地緩解了價值網絡的過估計問題以及過估計問題給策略網絡更新所帶來的影響; 2)策略網絡的非線性結構與線性結構能夠同時結合全局控制與局部控制的優點. 各算法的優勢對比如表1所示.
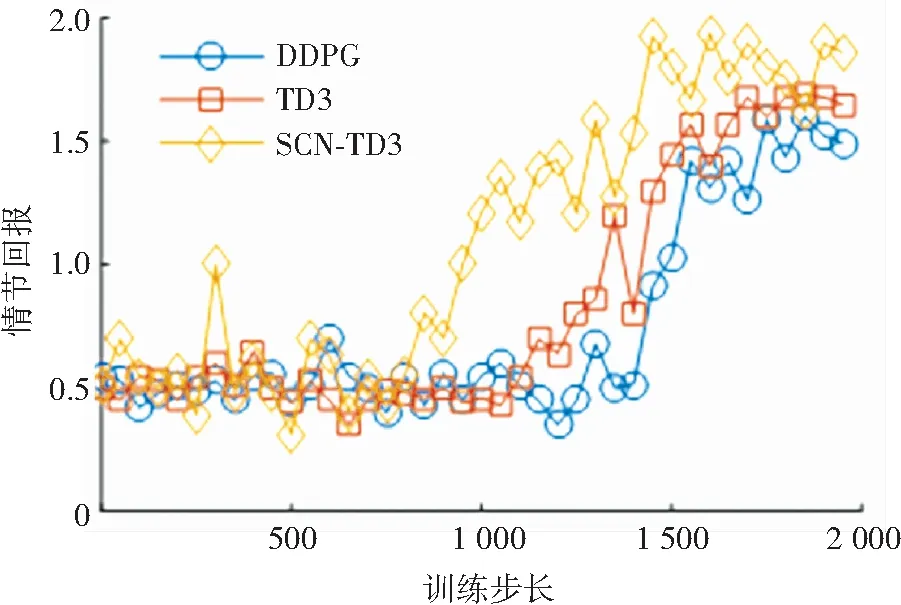
圖5 回報值隨訓練步長變化Fig.5 Variation of episode reward with step

表1 算法優勢對比Tab.1 Comparison of different algorithms
在訓練過程中,每5個訓練episode結束后,利用當前的策略網絡進行10次拉深仿真控制,取平均值作為驗證回報值. SCN-TD3得到的最優驗證回報值為1.928 8,而DDPG與TD3控制下的最優驗證回報值分別為1.602 9與1.690 8. 各算法最優驗證回報值所對應的壓邊力控制策略如表2所示.
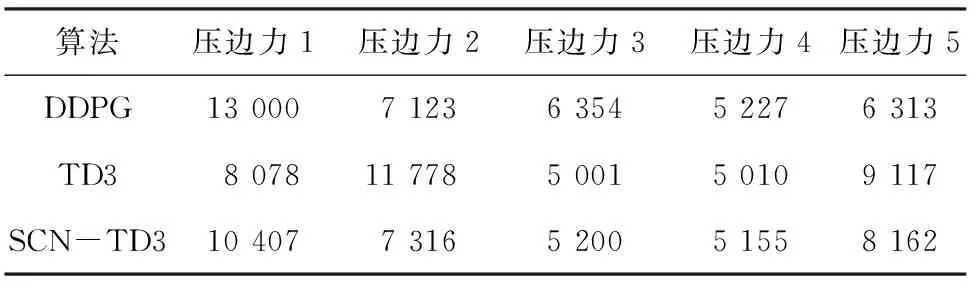
表2 最優控制策略Tab.2 Optimal control policy N
4.2 訓練過程壓邊力變化分析
為了探究壓邊力在訓練過程中的變化情況,本文給出了DDPG、TD3與SCN-TD3控制下各控制步長的壓邊力隨訓練步長的變化情況(見圖6). 由圖6可知,在訓練的早期,步長2到步長5的壓邊力聚集在最小值5 000附近,3種算法均陷入局部最優. 隨著訓練的進行,算法逐漸跳出局部最優點,最終收斂于一定的壓邊力水平. SCN-TD3控制下各步長壓邊力收斂速度均快于其他兩者,體現了SCN-TD3在性能上的優勢.
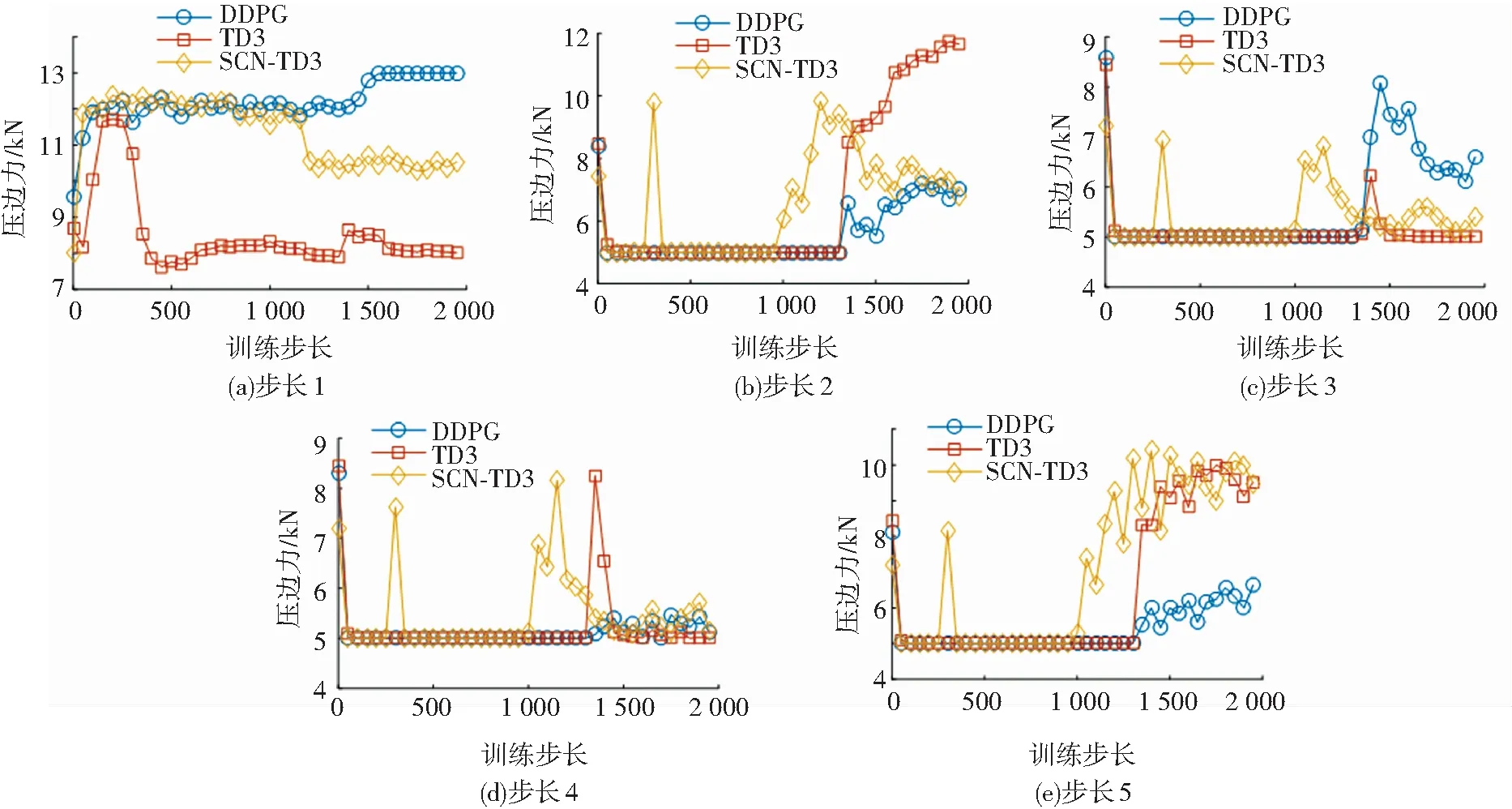
圖6 各控制步長壓邊力變化Fig.6 Variation of blank holder force with each control step
4.3 成品質量分析
根據DDPG、TD3以及SCN-TD3學習到的最優壓邊力控制策略,在ABAQUS中分別進行板材仿真拉深. 根據仿真結果輸出的Mises應力分布云圖、厚度分布云圖與U1位移分布云圖,進行成品質量分析. Mises應力分布云圖展示了成品各有限元單元的Mises應力分布情況. 根據圖7~9,可以得到三者的內部應力項指標分別為4 221、4 475以及3 708. 從總體分布上看,TD3控制下的成品的內部應力和最小,DDPG控制下的成品的內部應力和最大.
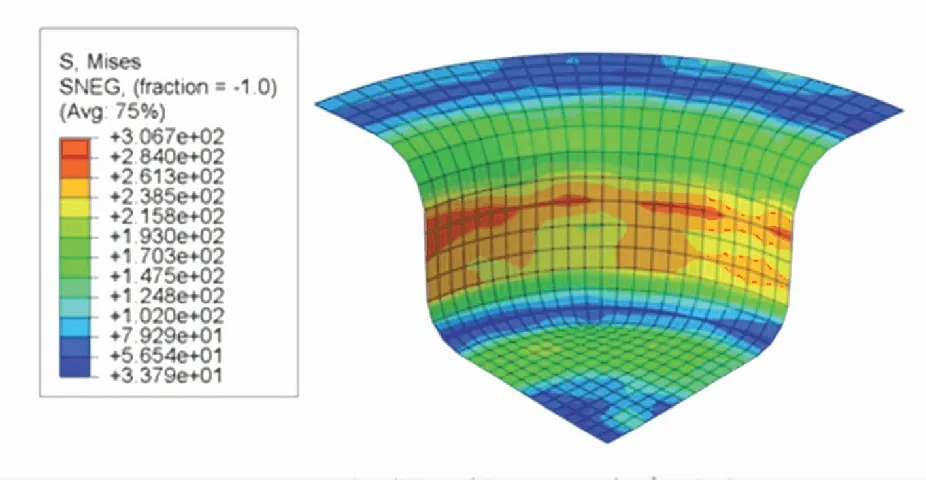
圖7 SCN-TD3控制下的Mises應力分布云圖Fig.7 Mises stress distribution under SCN-TD3
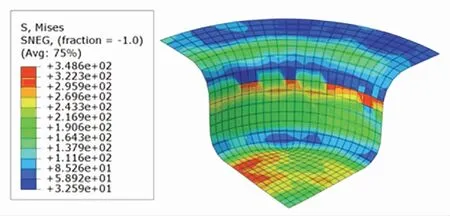
圖8 DDPG控制下的Mises應力分布云圖Fig.8 Mises stress distribution under DDPG
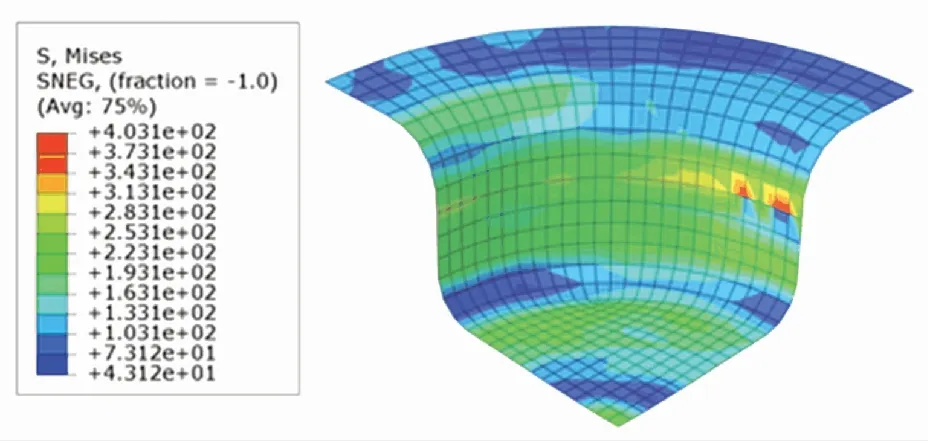
圖9 TD3控制下的Mises應力分布云圖Fig.9 Mises stress distribution under TD3
厚度分布云圖體現了成品各處厚度的分布情況. 根據圖10~12,SCN-TD3控制下成品的最小厚度為0.858 4 mm,DDPG控制下成品的最小厚度為0.853 3 mm,TD3控制下成品的最小厚度為0.850 3 mm. SCN-TD3控制下的成品厚度最為充足,TD3控制下的成品厚度最薄.
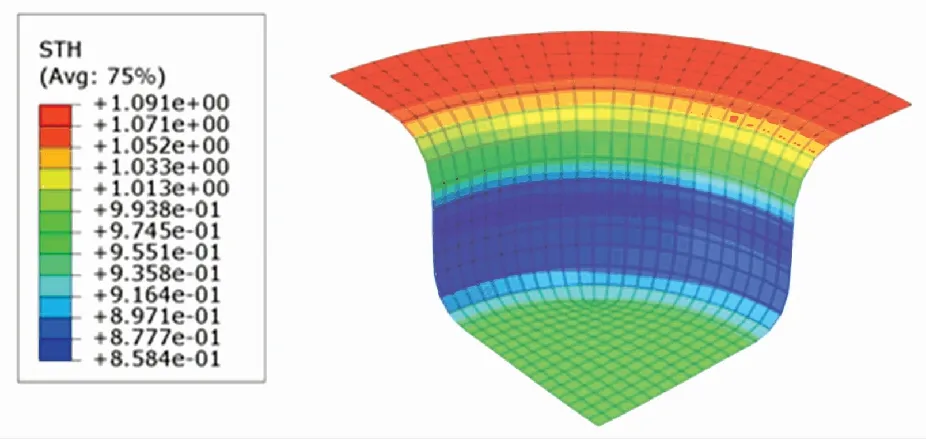
圖10 SCN-TD3控制下的厚度分布云圖Fig.10 Thickness distribution under SCN-TD3
U1位移分布云圖表示成品的每個有限元單元在x軸向上的位移. 根據圖13~15可知,SCN-TD3控制下成品的法蘭邊位移為7.781 7 mm,DDPG控制下成品的法蘭邊位移為8.0837 mm,TD3控制下成品的法蘭邊位移為7.944 6 mm. 表明SCN-TD3控制下的材料消耗比DDPG與TD3都要小.
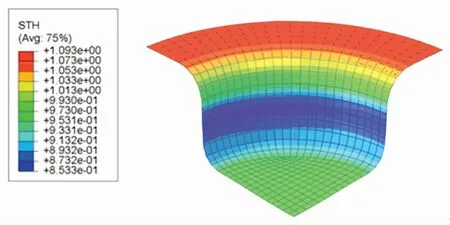
圖11 DDPG控制下的厚度分布云圖Fig.11 Thickness distribution under DDPG
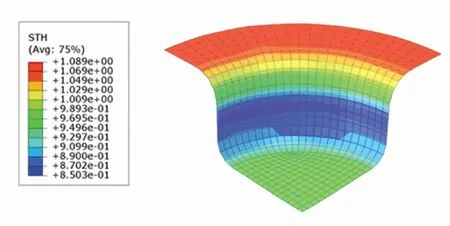
圖12 TD3控制下的厚度分布云圖Fig.12 Thickness distribution under TD3
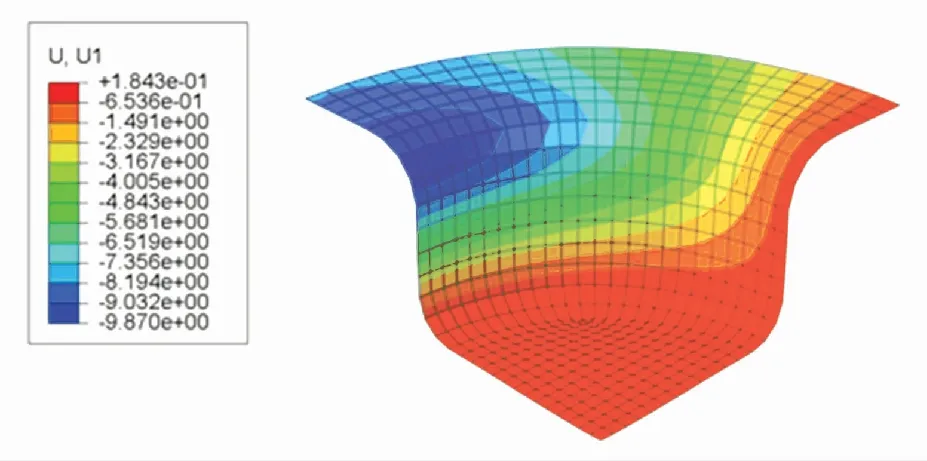
圖14 DDPG控制下的U1位移分布云圖Fig.14 U1 displacement distribution under DDPG
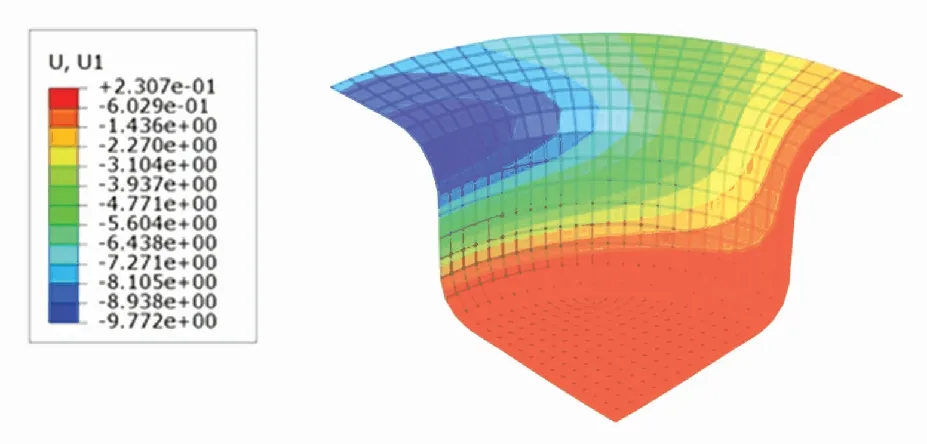
圖15 TD3控制下的U1位移分布云圖Fig.15 U1 displacement distribution under TD3
由于成本函數的組成為內部應力項、最小厚度項與材料消耗項的調和平均,因此盡管SCN-TD3在內部應力和指標上的表現不如TD3,但是其在3個成本項中的綜合表現最優. 綜合以上分析可知,相較于DDPG與TD3,SCN-TD3控制下成品的內部應力和較小,材料最小厚度充足,材料消耗程度最低,總體質量最優.
4.4 理論知識對于訓練過程的影響
根據圖1的理論有效壓邊力區間產生多條可行的壓邊力軌跡以及轉移經驗. 將有效壓邊力產生的轉移經驗加入初始經驗回放池,達到將理論知識引入壓邊力策略優化過程的目的.
通過對各控制步長所對應拉深行程下的有效壓邊力區間進行隨機采樣,得到了1 000條有效壓邊力軌跡及5 000個有效轉移經驗. 為了探究理論知識對于訓練過程的影響,控制初始轉移經驗中有效壓邊力轉移經驗所占比例分別為0%、25%、50%、75%和100%,輸出所對應的回報值隨訓練步長的變化情況,如圖16所示.
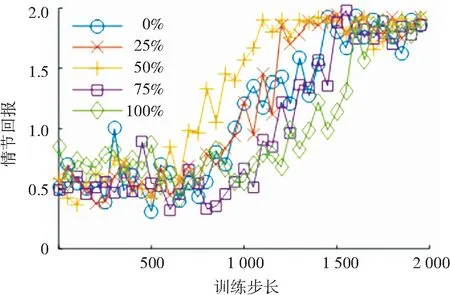
圖16 不同比例有效轉移經驗下的回報值變化
Fig.16 Variation of episode reward with different percentages of efficient transition experience
由圖16可知,隨著有效轉移經驗所占比例的增加,訓練過程中回報值的收斂越來越迅速,在50%達到最快收斂速度,隨后收斂速度隨有效轉移經驗所占比例的增加開始下降. 這表明,在初始經驗回放中添加適量的有效轉移經驗能夠為網絡的訓練提供一個良好的初始訓練數據,讓策略網絡的參數更快地往回報值高的參數空間進行梯度下降. 然而當初始回放經驗中的有效轉移經驗過多時,由于缺少低回報值的轉移經驗,策略網絡的更新無法有效地遠離低回報值的參數空間,反而使得回報值收斂速度下降. 根據以上分析可知,在初始經驗回放池中保持經驗樣本的多樣性有助于策略網絡的訓練.
5 結 論
1)本文將深度強化學習與有限元仿真進行集成,建立了板材拉深過程壓邊力控制模型,避免了系統動態的擬合.
2)對策略網絡的結構進行改進,并將壓邊力理論知識引入網絡訓練中,建立了一個更加有效的深度強化學習算法,提高了成品的成形質量.
3)有限元仿真實驗驗證了本文所提出的SCN-TD3算法的有效性,并與DDPG與TD3算法進行了壓邊力控制效果比較. 實驗表明,SCN-TD3控制下成品的內部應力和較小,材料最小厚度充足,材料消耗程度最低,總體質量最優.
猜你喜歡
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學大世界(2018年1期)2018-04-12 05:39:14
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
機械工程師(2015年10期)2015-02-02 01:14:03
時代英語·高三(2014年5期)2014-08-26 02:49:51
機電產品開發與創新(2014年4期)2014-03-11 16:42:24
