基于非分類關(guān)系提取技術(shù)的知識(shí)圖譜構(gòu)建
2020-06-08 10:54:36韋韜王金華
工業(yè)技術(shù)創(chuàng)新 2020年2期
韋韜,王金華
(1.北京賽迪翻譯技術(shù)有限公司,北京 100048;2.中國電子科技集團(tuán)公司第三十二研究所,上海 201808)
引言
每時(shí)每刻信息的海量增長,為人們學(xué)習(xí)知識(shí)帶來便利,但是為人們進(jìn)行索取、識(shí)別、學(xué)習(xí)知識(shí)帶來提取和甄別困難[1]。對海量隱性知識(shí)進(jìn)行自動(dòng)關(guān)聯(lián)、快速進(jìn)行機(jī)器思考,而把這些海量知識(shí)有機(jī)組織起來的核心就是“神經(jīng)網(wǎng)絡(luò)”[2]。
為構(gòu)建滿足以上業(yè)務(wù)需求的“神經(jīng)網(wǎng)絡(luò)”,知識(shí)圖譜的構(gòu)建是一個(gè)解決方案。知識(shí)圖譜包括目標(biāo)融合與識(shí)別知識(shí)圖譜、全維度關(guān)聯(lián)分析知識(shí)圖譜等[3-4]。這些知識(shí)圖譜其實(shí)是由圖上的實(shí)體和語義描述、實(shí)體間的關(guān)聯(lián)關(guān)系和語義描述等要素所組成的,要從海量互聯(lián)網(wǎng)信息、衛(wèi)星遙感數(shù)據(jù)中發(fā)現(xiàn)實(shí)體,就已經(jīng)是個(gè)巨大的難題[5],而發(fā)現(xiàn)實(shí)體間的關(guān)聯(lián)關(guān)系,并將這些海量的實(shí)體關(guān)聯(lián)關(guān)系進(jìn)行記錄、存儲(chǔ),乃至對這些知識(shí)圖譜進(jìn)行全語義空間的快速檢索,并不是現(xiàn)有信息系統(tǒng)能夠勝任的。
由于人們所掌握的提取知識(shí)已經(jīng)難以覆蓋現(xiàn)有海量信息,因此如何在信息系統(tǒng)中,為全維度的信息構(gòu)建一個(gè)相互關(guān)聯(lián)、智能搜索、快速定位、易于維護(hù)的網(wǎng)絡(luò)化數(shù)據(jù)模型,并在該模型上進(jìn)行知識(shí)決策,成為一個(gè)關(guān)鍵的問題。本文從自動(dòng)化、持續(xù)化的知識(shí)圖譜構(gòu)建機(jī)制進(jìn)行研究,分析了多源、異構(gòu)知識(shí)圖譜建模、融合、管理等現(xiàn)實(shí)需求,應(yīng)用非分類提取技術(shù),提出了知識(shí)圖譜的自動(dòng)化構(gòu)建實(shí)踐路徑和模型。
1 問題的提出
1.1 研究背景
互聯(lián)網(wǎng)大力發(fā)展的這些年是一個(gè)數(shù)據(jù)爆炸的時(shí)代,數(shù)據(jù)量每年保持著50%左右的增長速度,為了處理這些海量的數(shù)據(jù),挖掘這些數(shù)據(jù)的潛在意義,提高數(shù)據(jù)檢索質(zhì)量和效率,全球各大研究機(jī)構(gòu)和搜索引擎公司都絞盡腦汁。隨著Linking Open Data 等項(xiàng)目的全面展開,語義Web數(shù)據(jù)源的數(shù)量激增,大量資源描述框架(Resource Description Framework,RDF)數(shù)據(jù)被發(fā)布。互聯(lián)網(wǎng)正從僅包含網(wǎng)頁和網(wǎng)頁之間超鏈接的文檔萬維網(wǎng)(Document Web)轉(zhuǎn)變成包含描述各種實(shí)體和實(shí)體之間豐富關(guān)系的數(shù)據(jù)萬維網(wǎng)(Data Web)。在這個(gè)背景下,Google、百度和搜狗等搜索引擎公司紛紛以此為基礎(chǔ)構(gòu)建知識(shí)圖譜,即Knowledge Graph、百度知心和搜狗知立方等,來改進(jìn)搜索質(zhì)量,從而拉開了語義搜索的序幕。同時(shí),面對海量、復(fù)雜、異構(gòu)的網(wǎng)絡(luò)信息,我們需要具備能夠?qū)ζ溥M(jìn)行快速分析挖掘與關(guān)聯(lián)的能力,也就是能夠快速挖掘分析出對象實(shí)體,并將實(shí)體關(guān)聯(lián)到龐大的知識(shí)圖譜中的能力。同時(shí),數(shù)據(jù)處理環(huán)境也要在數(shù)據(jù)處理量、反饋時(shí)效等方面具備很強(qiáng)的能力。想要擁有這些能力,如何構(gòu)建一張完整、高質(zhì)量的知識(shí)圖譜,是不得不考慮的關(guān)鍵問題。
世界各個(gè)國家和地區(qū)均已開展系統(tǒng)構(gòu)建或技術(shù)研發(fā),為大數(shù)據(jù)的有效收集、融合、管理和分析提供支持,并從中獲得有價(jià)值的信息。例如,Palantir公司通過其完善的數(shù)據(jù)庫和強(qiáng)大的數(shù)據(jù)關(guān)聯(lián)分析技術(shù),從技術(shù)上開展了以下重點(diǎn)工作:1)構(gòu)建大規(guī)模數(shù)據(jù)庫的體系結(jié)構(gòu);2)探索以現(xiàn)有資源填充數(shù)據(jù)庫的新方法,并創(chuàng)造新的來源,以及創(chuàng)造新的挖掘、融合和提煉算法;3)為了分析和關(guān)聯(lián)數(shù)據(jù)庫信息,采用知識(shí)圖譜的新模型,從而獲得可操作的技術(shù)。
相比之下,我國對知識(shí)圖譜構(gòu)建技術(shù)的利用和研究還需深入。面對涉及到各個(gè)領(lǐng)域的、海量紛繁復(fù)雜的數(shù)據(jù),我們急需一種方法對其進(jìn)行清洗處理,使其變成有高利用價(jià)值的知識(shí)圖譜。知識(shí)圖譜的構(gòu)建步驟一般是數(shù)據(jù)抽取、中文分詞、實(shí)體識(shí)別、關(guān)系識(shí)別。而關(guān)系識(shí)別是目前是最難以解決的問題,其主要工作是:實(shí)體共現(xiàn)、關(guān)系標(biāo)注,而現(xiàn)有方法無法做到關(guān)系標(biāo)注的持續(xù)改進(jìn),或者只能強(qiáng)烈依賴外部知識(shí)輸入和人工干預(yù)。
1.2 本研究解決的問題
本研究探索解決的問題有:
(1)通過收集信息,實(shí)現(xiàn)自動(dòng)/半自動(dòng)化構(gòu)建知識(shí)圖譜的技術(shù),其中涉及的主要技術(shù)包括:文本分詞、詞性標(biāo)注、術(shù)語分析、命名實(shí)體識(shí)別、語法分析、語義分析、實(shí)體關(guān)系提取;
(2)滿足對來源多、流量大、高密集度數(shù)據(jù)進(jìn)行可靠記錄、高效分析的要求;
(3)快速挖掘分析出研究對象實(shí)體,并將實(shí)體關(guān)聯(lián)到龐大的知識(shí)圖譜中;
(4)對海量、復(fù)雜、異構(gòu)的網(wǎng)絡(luò)信息進(jìn)行快速分析挖掘與關(guān)聯(lián),實(shí)現(xiàn)知識(shí)圖譜的半自動(dòng)化構(gòu)建;
(5)集成、整合現(xiàn)有信息系統(tǒng)中所有結(jié)構(gòu)良好的數(shù)據(jù)資源,對信息系統(tǒng)運(yùn)行過程中產(chǎn)生的信息資源進(jìn)行實(shí)時(shí)整合,并對接外部信息資源,從而實(shí)現(xiàn)知識(shí)圖譜信息的完整性、準(zhǔn)確性、時(shí)效性。
本文第2章對知識(shí)圖譜構(gòu)建技術(shù)進(jìn)行了系統(tǒng)架構(gòu)設(shè)計(jì),第3章闡述了知識(shí)圖譜構(gòu)建的關(guān)鍵技術(shù),第4章進(jìn)行了總結(jié)并提出建議。
2 系統(tǒng)架構(gòu)設(shè)計(jì)
2.1 模塊設(shè)計(jì)
本文設(shè)計(jì)的知識(shí)圖譜構(gòu)建框架包含的技術(shù)包括數(shù)據(jù)采集、命名實(shí)體識(shí)別、語法語義分析、實(shí)體關(guān)系提取四大模塊,其中最核心的技術(shù)是命名實(shí)體識(shí)別和實(shí)體關(guān)系提取,如圖1所示。
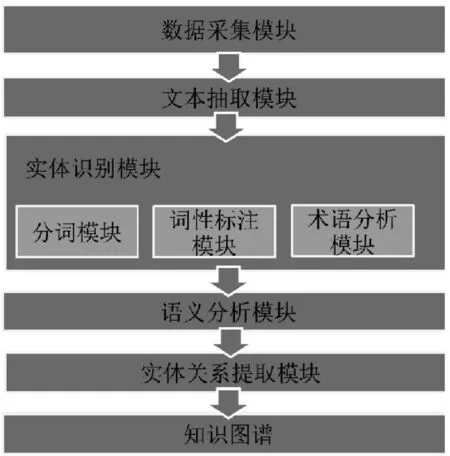
圖1 系統(tǒng)架構(gòu)
2.1.1 數(shù)據(jù)采集
我們是通過采用數(shù)據(jù)爬蟲系統(tǒng)來實(shí)現(xiàn)初始數(shù)據(jù)積累的,和一般性的以廣度為目標(biāo)的數(shù)據(jù)爬蟲系統(tǒng)相比,我們進(jìn)行了改進(jìn)優(yōu)化,使其成為可以圍繞某一特定目標(biāo)進(jìn)行針對性的爬取的、面向網(wǎng)絡(luò)信息大數(shù)據(jù)的爬蟲系統(tǒng)。對爬取到的數(shù)據(jù)進(jìn)行清洗和簡單的預(yù)處理之后,就把數(shù)據(jù)輸出到命名實(shí)體識(shí)別模塊。
2.1.2 命名實(shí)體識(shí)別
我們通過命名實(shí)體識(shí)別模塊來實(shí)現(xiàn)對文本信息中主要實(shí)體對象的識(shí)別,其主要功能包括:分詞模塊、詞性標(biāo)注模塊、術(shù)語分析模塊。
其中分詞和詞性標(biāo)注可以放在一起進(jìn)行,在分詞的時(shí)候就標(biāo)注好詞性。基本的分詞和詞性標(biāo)注操作依賴于分詞規(guī)則庫以及詞典與詞性的一個(gè)關(guān)系庫。然而事實(shí)上,這對歧義詞和新詞的識(shí)別率較低。尤其是在中文分詞中,一詞多義、歧義以及各種網(wǎng)絡(luò)名詞的出現(xiàn),使我們需要不斷地?cái)U(kuò)充分詞庫。為了應(yīng)對詞典統(tǒng)計(jì)分詞的不足,我們采用了基于CRF機(jī)器學(xué)習(xí)算法的分詞技術(shù),并且不僅考慮了詞語出現(xiàn)的頻率信息,同時(shí)還增加了對上下文語境的考慮,這使得模塊對歧義詞和新詞有較好的學(xué)習(xí)能力。我們結(jié)合不斷擴(kuò)充的分詞庫,采用比較成熟的分詞技術(shù),通過分詞庫和詞性庫就可以完成分詞和詞性標(biāo)注,不僅更加準(zhǔn)確,并且效率很高,當(dāng)遇到歧義詞、新詞,分詞庫和詞性庫不能解決的時(shí)候,再結(jié)合CRF完成工作,兼以擴(kuò)充我們的分詞庫和詞性庫。在分詞和詞性標(biāo)注后,將術(shù)語輸出到術(shù)語分析模塊。
術(shù)語分析通常是指從術(shù)語詞典中提取出術(shù)語到術(shù)語庫。我們需要根據(jù)不同的領(lǐng)域劃分并維護(hù)這個(gè)術(shù)語庫。術(shù)語分析后將信息輸出到語法語義分析模塊。
2.1.3 語法語義分析模塊
結(jié)合本體集成,提取出語法庫和本體庫。結(jié)合語法、語義規(guī)范以及語法、語義的學(xué)習(xí)算法,生成信息提取的一個(gè)規(guī)則庫。依賴這個(gè)過程生成的語法庫、本體庫以及信息提取規(guī)則庫,通過語法、語義分析,提取出本體間的關(guān)系,再通過本體構(gòu)建工具生成語義元數(shù)據(jù)模型,然后將模型輸出到實(shí)體關(guān)系提取模塊。
2.1.4 實(shí)體關(guān)系提取
實(shí)體關(guān)系提取包括分類關(guān)系提取、非分類關(guān)系提取。其中已經(jīng)有分類體系的關(guān)系提取不存在太大技術(shù)障礙,難點(diǎn)就是非分類關(guān)系提取。非分類關(guān)系提取可分為兩個(gè)不同的問題:1)發(fā)現(xiàn)一對概念間存在的關(guān)系;2)根據(jù)語義標(biāo)記這種關(guān)系。本研究采用兩種方法來提取非分類關(guān)系。本文認(rèn)為實(shí)體關(guān)系的抽取比單純的實(shí)體抽取難度更高,準(zhǔn)確性、成熟度更低,因此將在第3章對實(shí)體關(guān)系提取功能進(jìn)行詳細(xì)、深化的技術(shù)設(shè)計(jì)與探討。
2.2 系統(tǒng)總體流程設(shè)計(jì)
從大規(guī)模文本集合中自動(dòng)提取語義元數(shù)據(jù)是構(gòu)建知識(shí)圖譜和知識(shí)庫的核心步驟,圖2以流程的方式將如何從文本數(shù)據(jù)中對知識(shí)圖譜元素進(jìn)行抽取識(shí)別所需要采用的方法、領(lǐng)域資源、所采用的技術(shù)按先后次序依次列出,而這也正是進(jìn)行語義分析的基礎(chǔ)。
如圖2所示,本系統(tǒng)的流程包括文本信息采集、數(shù)據(jù)清洗和過濾、命名實(shí)體識(shí)別、分詞、詞性標(biāo)注、術(shù)語分析、語法分析、語義分析、語義關(guān)系識(shí)別和提取等步驟。其中,命名實(shí)體識(shí)別是通過機(jī)器學(xué)習(xí)和傳統(tǒng)詞典相集成的方法實(shí)現(xiàn)的;術(shù)語分析是通過術(shù)語的提取和術(shù)語詞典集成的方式實(shí)現(xiàn)的;語法分析與語義分析是通過本體學(xué)習(xí)與本體集成的方式實(shí)現(xiàn)的;語義關(guān)系識(shí)別和提取是通過語義關(guān)系學(xué)習(xí)與聲明規(guī)范相結(jié)合來實(shí)現(xiàn)的。
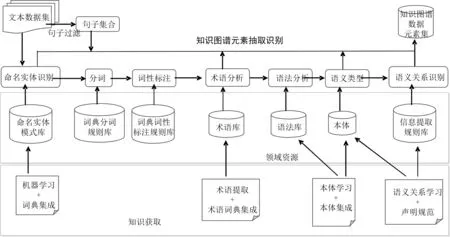
圖2 知識(shí)圖譜元素抽取識(shí)別流程
3 實(shí)體關(guān)系提取關(guān)鍵技術(shù)
3.1 討論
知識(shí)圖譜的人工構(gòu)建被視為一種耗時(shí)、耗力、枯燥、易錯(cuò)的任務(wù),再者由于缺乏對現(xiàn)有知識(shí)圖譜進(jìn)行集成或重復(fù)使用的標(biāo)準(zhǔn),以及缺乏完全自動(dòng)化的知識(shí)獲取方法,知識(shí)圖譜甚至本體的構(gòu)建進(jìn)一步受到阻礙。
因此,本研究將精力集中在知識(shí)圖譜的自動(dòng)構(gòu)建技術(shù)上。使用機(jī)器學(xué)習(xí)和文本挖掘方法,從領(lǐng)域文本中獲取知識(shí)圖譜和本體要素,已逐漸成為一種有利于本體工程的方法。在此背景下,本體學(xué)習(xí)被認(rèn)為能幫助知識(shí)工程師以及終端用戶進(jìn)行本體構(gòu)建,其集成了多個(gè)領(lǐng)域,如本體工程、機(jī)器學(xué)習(xí)和自然語言學(xué)習(xí)領(lǐng)域的技術(shù)。這些技術(shù)被用于三個(gè)主要階段,即實(shí)體識(shí)別、分類關(guān)系提取、非分類關(guān)系提取。這三個(gè)階段能幫助構(gòu)建本體或豐富現(xiàn)存本體,而本體學(xué)習(xí)是構(gòu)建知識(shí)圖譜的支撐。
本體學(xué)習(xí)中涉及到提取非分類關(guān)系的方法,被視為是一個(gè)困難而又容易被忽視的問題。非分類關(guān)系包括兩方面:一是概念間關(guān)系的發(fā)現(xiàn);二是基于語義的關(guān)系標(biāo)記。解決這種賦予關(guān)系標(biāo)記的問題也是十分不易的,因?yàn)橥活愅ㄓ玫母拍顚?shí)例通常存在多種關(guān)系,而且即使語義是清晰的,在幾個(gè)相似的標(biāo)記中選取符合上下文的標(biāo)記也是十分困難的。
大多數(shù)對于從文本源中進(jìn)行非分類關(guān)系提取的研究要結(jié)合不同層次的統(tǒng)計(jì)和語言分析技術(shù)。在此背景下,關(guān)聯(lián)法則被用來從文本中獲取語義(非預(yù)先定義的)關(guān)系,如可以通過使用關(guān)聯(lián)法則發(fā)現(xiàn)一對詞語共同出現(xiàn)的概率,來判斷這對詞語合適的關(guān)系。雖然通過這類方法可以發(fā)現(xiàn)語義關(guān)系,但是并沒有解決標(biāo)記的問題。
其他研究者采用正規(guī)表達(dá)式來獲取語義關(guān)系。這類方法需要完全地檢測文本,而語義關(guān)系的識(shí)別則是根據(jù)文本中一系列詞語是否匹配預(yù)定義的模式來決定的。許多算法和此類方法相關(guān),被應(yīng)用于尋找上下位關(guān)系。然而這些算法需要預(yù)先生成符合關(guān)系模式的規(guī)則,這樣就需要終端用戶具有大量的領(lǐng)域知識(shí)。相關(guān)的研究以同樣的方式,通過使用外部語義詞典,如WordNet,根據(jù)預(yù)先定義的少量語義結(jié)構(gòu)自動(dòng)分配語義關(guān)系。同樣地,這種方式也并不能提取更多的語義關(guān)系。
由于上述方法的缺陷,越來越多的研究者注重于使用自然語言處理技術(shù),從領(lǐng)域文本集中提取語法結(jié)構(gòu),以幫助語義關(guān)系的提取。比如有研究通過選擇和一對概念頻繁出現(xiàn)在一起的動(dòng)詞作為語義關(guān)系的標(biāo)記。在此研究中,概念之間的關(guān)聯(lián)是由一對概念基于動(dòng)詞的條件概率來衡量的。RelExt系統(tǒng)根據(jù)術(shù)語在領(lǐng)域文本中被觀察的頻率,使用基于相關(guān)度的統(tǒng)計(jì)測量來過濾術(shù)語,然后根據(jù)動(dòng)詞和名詞概念共同出現(xiàn)的測量值,選取排序高者作為關(guān)系。然而有研究表明,與一對概念共同出現(xiàn)的動(dòng)詞,往往并不一定能成為該對概念之間的關(guān)系動(dòng)詞。
綜上所述,現(xiàn)有的非分類關(guān)系的提取方法還不完善,即只能提取一小部分語義關(guān)系,而且為了提高關(guān)系提取的正確率,特別需要領(lǐng)域知識(shí)的輸入。與現(xiàn)存方法相比較,本研究采用了兩種關(guān)鍵技術(shù)實(shí)現(xiàn)非分類關(guān)系提取。
3.2 基于關(guān)聯(lián)法則和語義關(guān)系的非分類關(guān)系提取技術(shù)
本研究提出基于關(guān)聯(lián)法則和語義關(guān)系的方法,來測量一對概念和動(dòng)詞的相關(guān)性的強(qiáng)度(此強(qiáng)度是由所提取的關(guān)聯(lián)規(guī)則的confidence 來定義的),作為已確認(rèn)存在語義關(guān)系的概念對的候選標(biāo)記。同時(shí)本研究還提出,在領(lǐng)域文本集中,通過概念間的依存和句法結(jié)構(gòu)分析,可以發(fā)現(xiàn)概念之間的語義關(guān)系,而概念之間的語義關(guān)系通常又是由動(dòng)詞來表達(dá)與連接的。該方法的流程如圖3所示。其中,通過句法分析選擇概念候選集后,由關(guān)聯(lián)法則對其進(jìn)行挖掘,確認(rèn)合適的關(guān)系集,最后通過領(lǐng)域?qū)<业姆答仯峁┳詈线m的知識(shí)圖譜關(guān)系集合。該方法不僅可以用于自動(dòng)發(fā)現(xiàn)概念間的關(guān)系,也可為這些關(guān)系賦予合適的標(biāo)記,極大減輕了知識(shí)工程師在知識(shí)圖譜和領(lǐng)域本體構(gòu)建時(shí)的負(fù)擔(dān)。
3.3 基于規(guī)則和機(jī)器學(xué)習(xí)的非分類關(guān)系提取技術(shù)
采用基于規(guī)則和機(jī)器學(xué)習(xí)相結(jié)合的混合方法從領(lǐng)域文本中提取非分類關(guān)系的流程如圖4所示。

圖3 基于關(guān)聯(lián)法則和語義關(guān)系的非分類關(guān)系提取流程
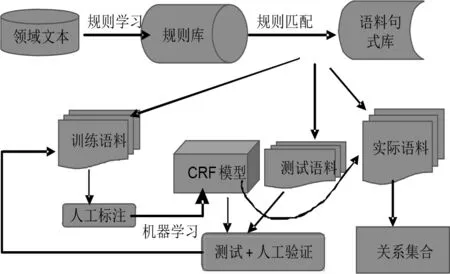
圖4 基于規(guī)則和機(jī)器學(xué)習(xí)的非分類關(guān)系提取流程
提取流程具體為:
(1)對領(lǐng)域文本進(jìn)行人工的規(guī)則學(xué)習(xí),形成規(guī)則庫;
(2)使用所學(xué)習(xí)的規(guī)則對其他語料文本進(jìn)行匹配,形成語料句式庫;
(3)利用語料句式庫,對訓(xùn)練語料進(jìn)行人工標(biāo)注,然后用CRF機(jī)器學(xué)習(xí)算法進(jìn)行訓(xùn)練,生成訓(xùn)練模型;
(4)使用測試語料和訓(xùn)練模型,進(jìn)行測試和人工驗(yàn)證,根據(jù)測試結(jié)果,對訓(xùn)練語料進(jìn)行補(bǔ)充和調(diào)整,重新訓(xùn)練,直到訓(xùn)練模型的準(zhǔn)確率和召回率達(dá)到一定的水平;
(5)利用調(diào)整過的訓(xùn)練模型,結(jié)合規(guī)則匹配結(jié)果,從實(shí)際語料中提取非分類實(shí)體關(guān)系。
以上流程有效提高了從術(shù)語集合中獲取非分類關(guān)系的效果,受到人工幫助的CRF算法還可以提取更多的術(shù)語,有效地補(bǔ)充現(xiàn)有的術(shù)語集合。
4 結(jié)論與建議
本文圍繞多源、異構(gòu)知識(shí)圖譜,提出了建模、融合、管理、分析等現(xiàn)實(shí)需求;特別是針對人工構(gòu)建知識(shí)圖譜存在的問題,探討了知識(shí)圖譜的自動(dòng)化構(gòu)建技術(shù),明確了實(shí)體關(guān)系提取中的非分類提取技術(shù)是關(guān)鍵技術(shù)。
本文研究探討的技術(shù),可用于網(wǎng)絡(luò)中心、數(shù)據(jù)中心等平臺(tái),在相關(guān)業(yè)務(wù)中接入了偵察、預(yù)警、探測等多源情報(bào)后,可以實(shí)現(xiàn)知識(shí)圖譜的自動(dòng)化構(gòu)建,并通過知識(shí)圖譜實(shí)現(xiàn)關(guān)聯(lián)印證、綜合處理等功能,最終形成情況態(tài)勢圖。
由于數(shù)據(jù)往往具有保密性,本文強(qiáng)烈建議提升知識(shí)圖譜在系統(tǒng)運(yùn)行狀態(tài)進(jìn)行自動(dòng)化、持續(xù)化構(gòu)建的能力,從而使得數(shù)據(jù)即使在沒有知識(shí)庫基礎(chǔ)的環(huán)境下,也能成長為完整、可用、與時(shí)俱進(jìn)的知識(shí)圖譜體系,從而更好地為各種業(yè)務(wù)提供知識(shí)支撐。
猜你喜歡
當(dāng)代陜西(2021年17期)2021-11-06 03:21:36
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
學(xué)苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
語文知識(shí)(2014年1期)2014-02-28 21:59:13
