基于循環一致性對抗網絡的室內火焰圖像場景遷移
2020-04-11 02:00:22楊植凱卜樂平歐陽繼能
光學精密工程 2020年3期
楊植凱,卜樂平,王 騰,歐陽繼能
(海軍工程大學 電氣工程學院,湖北 武漢 430033)
1 引 言
隨著深度學習的發展,基于深度卷積神經網絡(Deep Convolutional Neural Networks,DCNN)的火災識別方法得到大量應用。而深度學習的方法依賴于訓練集的樣本的數量和質量。正樣本(火災視頻)與負樣本(背景干擾)不均衡會影響到深度神經網絡識別的準確率[1]。由于受到安全限制,很多場景下,如廠房、倉庫、辦公室等場所無法直接點火采集火災視頻數據或測試火災監控模型。而由固定的試驗場所采集的數據則存在背景、干擾情況單一的缺陷。以上限制造成數據集中正樣本(不同背景下的火災視頻)數量偏少,正負樣本不平衡,限制了深度學習火災識別算法的作用和效果。
為解決數據不平衡的問題,Kisantal等設計了多次復制小目標圖像的數據增廣(Data Argument, DA)方法以增加數據集中小目標圖像的數量[2]。與常見的目標檢測數據集不同,火焰沒有明顯的分割邊緣。并且當火焰燃燒時自身產生的煙霧以及周圍物體的顏色都會發生相應變化,這些因素都限制了火焰在場景中的提取與復制,同時限制了對火焰圖像的增廣。基于此,本文提出一種將火焰與場景相融合的方法。該模型滿足火焰數據增廣的三個要求:第一是火焰的多樣性即生成的火焰形狀、顏色等特征多樣。第二是生成圖像應盡量具備視覺真實性,即火焰的顏色、產生的煙霧及其附近物體的反光等,應符合該場景條件下的經驗值。第三是添加火焰的區域與整體場景的拼接處應平滑地過渡。
由于生成對抗網絡的應用(Generative Adversarial Network, GAN)[3]的應用,圖像轉換領域快速發展并取得了良好效果,本文任務由圖像轉換(Image-to-Image translation, I2I)完成。雖然目前已有多種不同功能的圖像轉換網絡結構。比如,超分辨率重建[4-5], 語意合成[6-7], 圖像增強[8-9]及 圖像編輯[10-12]等。但以上應用中并沒有適用于解決本文問題的方法。一方面,傳統I2I方法的一個常見的限制是它們的確定性輸出[5,7]。受到Gaty[13]的啟發,文獻[14-16]將圖像信息分解為兩部分:內容信息和風格信息。其中內容信息包含了圖像潛在的空間結構、形狀等在圖像轉換過程中需要保留的信息。而風格信息包含了紋理、顏色以及其他在轉換中需要改變的信息等。但對同一個輸入,這類方法只能得到一個固定的輸出,無法滿足在同一場景下火焰多樣性的要求。
另一方面,雖然BicycleGAN[17]等多模態I2I提出在輸出和隱空間之間使用雙射變換,將圖像的風格信息回歸為白噪聲,通過改變白噪聲改變轉換圖像的風格,對同一圖像的轉換具有多樣性的輸出。然而噪聲形式的解纏繞表達雖然可以增加輸出的多樣性,但無法確定生成圖像的風格。類似地,Multimodal Unsupervised Image-to-Image Translation(MUNIT)[18]將圖像的內容信息與風格信息分別解纏繞為隱編碼的形式,通過改變代表風格的隱編碼得到多樣性的輸出。但這種方法生成的圖像清晰度低,而且通過編碼器自動習得的隱編碼沒有明確的含義,可解釋性差。在通過編碼器抽取圖像信息的同時,文獻[19-20]通過顯式編碼控制圖像生成。這些編碼有明確意義,可解釋性強。AgeGAN[19]采用了與InfoGAN[21]類似的方法,從由編碼向量生成的圖像中解纏繞出向量自身以初始化編碼器。這個向量由白噪聲以及表示年齡的條件編碼c組成,通過c在轉換階段控制所生成人臉的年齡。Ganimation[20]則使用了表示人臉表情的17維向量控制生成人臉的表情。這種由編碼形式的解纏繞表示所生成的圖像有一個明顯的缺陷,即圖像信息就壓縮至編碼的過程中會造成信息的大量丟失,由編碼重建圖像時,引起失真問題。由于以上多模態I2I方法[18-20]主要在保留人臉發色、膚色的基礎上重構五官,五官形狀和背景顏色的改變是被允許的。但并不適合本文問題中保持背景細節的要求。
與編碼形式的輸入相比,可解釋性更強的方法是使用圖像輸入。文獻[22]將圖像中解糾纏出的人臉編碼與圖像形式的五官輪廓結合,以重組人臉表情。文獻[23]則使用了梯度意義的線條。Progressive Image Reconstruction Network with Edge and Color Domain(PI-REC)[24]使用色塊與五官邊緣,重建人臉。因為線條與色塊比編碼包含的信息更為準確具體,使用這種圖像作為條件輸入所獲得的結果更加明確,可控性更強。
受到這種圖像形式的顯式表示方法的啟發,從信息的保留與傳遞考慮,本文設計了以火焰圖像作為條件輸入的場景遷移模型,在保證轉換圖像背景細節質量的同時增強火焰的多樣性、可控性。同時為了便于數據集制作,本文設計了基于CycleGAN的場景遷移模型以解除非匹配數據對于模型訓練的限制。
2 問題描述
2.1 火焰場景融合
本文目的是尋求無火場景In在火焰形態c條件下到有火場景Iyc的映射:M:(In|c)→Iyc,通過改變c達到增加火焰多樣性的目的。
由于編碼形式的信息高度抽象,因此無法包含足夠具體的信息準確描述火焰的形態、位置及其與背景的關系。通過編碼器將條件c或風格信息映射到隱編碼空間的方式會導致c的意義不明確,影響火焰形態的可控性。此外,以編碼形式作為生成火焰的控制條件會引起圖像其他位置的扭曲、變色,背景的細節將難以保持。
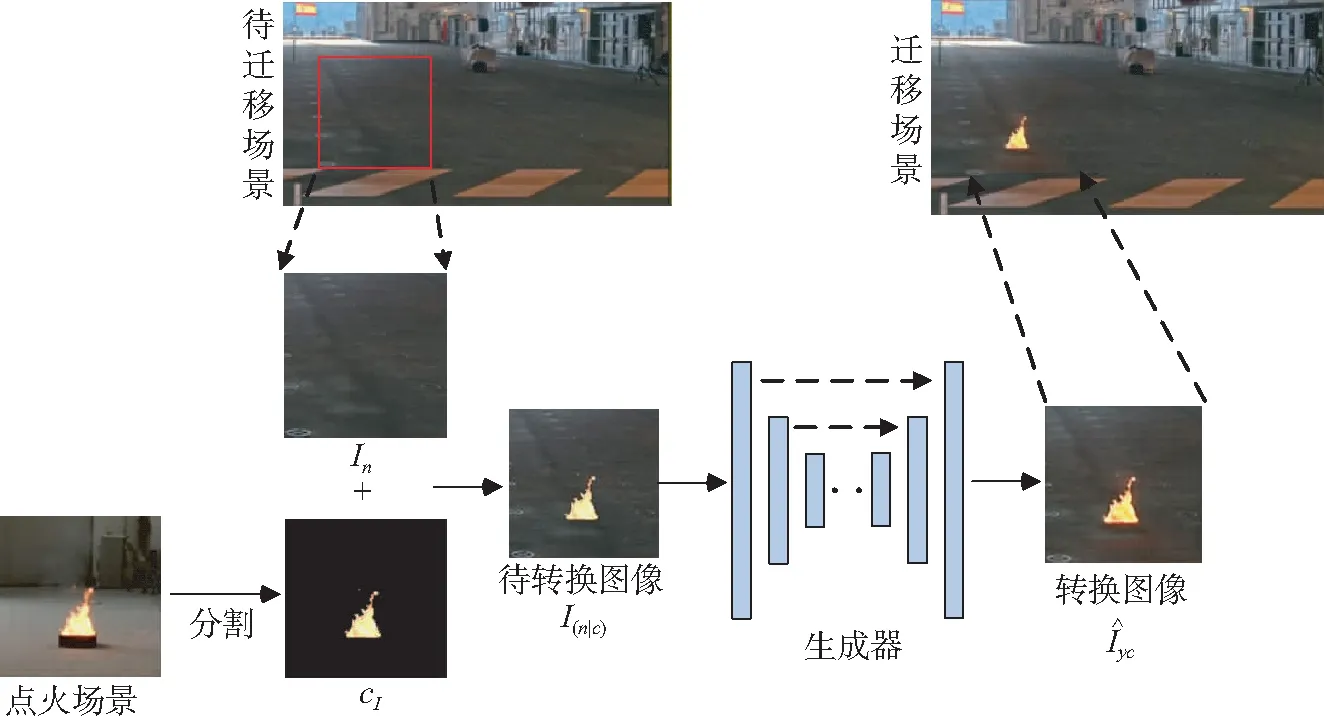
圖1 火焰場景融合示意Fig.1 Model architecture of scene and flame fusing

圖2 復雜場景下火焰分割缺陷示意Fig.2 Defect of flame segmentation in complex scenarios
考慮到以上因素,本文提出將映射M:(In|c)→Iyc中編碼形式的條件c改為圖像形式的條件cI。同時,將火焰也看作待轉換圖像的內容信息,將cI植入場景中,覆蓋相應位置的背景像素。其中cI來自于已有視頻中相似場景下的火焰,I(n|cI)與Iyc的差異表現在煙霧、物體的反光等火焰燃燒時對場景圖像的紋理和顏色所造成的改變等方面,這些可以看作風格信息。I(n|cI)則以圖像形式完整包含了著火場景中的內容信息如火焰的位置、形態和背景等,以明確的內容信息為基礎進行圖像轉換,將遷移的火焰與場景相融合,從而避免因修改內容信息而引起生成圖像失真。最終本文火焰場景融合方法的數學表示為映射M:I(n|cI)→Iyc,其流程如圖1所示。
2.2 循環一致性對抗網絡與非匹配數據集

圖3 匹配與非匹配數據集Fig.3 Paired and unpaired datasets
一般情況下,樣本的多樣性越高,訓練的網絡模型處理復雜情況的穩定性越好。但數據集的制作難度隨著場景的復雜程度增長:當火焰附近存在與火顏色相近的物體時;或在低光照條件下,光滑表面反射的火光與火焰顏色相似,都將難以從場景中分割出火焰(如圖2紅圈所示,彩圖見期刊電子版)。如圖4所示,為了降低數據制作的難度,本文在制作數據集時,將相同光照條件下由簡單場景下分割出的火焰cI移植到復雜場景中作為I(n|cI);而將復雜場景中真實的火焰燃燒圖像作為Iyc,通過CycleGAN結構訓練圖像轉換網絡。

圖4 復雜場景下數據集制作示意Fig.4 Dataset production in complex scenarios
3 基于CycleGAN的場景遷移網絡結構
3.1 模型整體結構
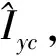
圖5 網絡整體結構Fig.5 Overall structure of network
由于循環一致性對抗網絡形成了鏈狀的映射結構,訓練中無法清晰地界定G與F的映射關系。為了G與F學習到準確的映射關系,本文引入了同一映射損失,即當G與F各自將目標圖像域中的圖像仍然映射至各自的目標圖像域中時,目標圖像在轉換后應與轉換前保持一致。
3.2 生成器
本文的兩個生成器G與F都使用了相同的結構,其結構如圖6所示。為了避免背景在轉換過程中產生形變采用了U-net[25]結構。U-net在編碼器和解碼器層與層之間具有跳躍連接,可以很好地避免輸出圖像模糊和扭曲。除此之外,注意力機制也被引入,用以提升火焰與場景融合的效果。
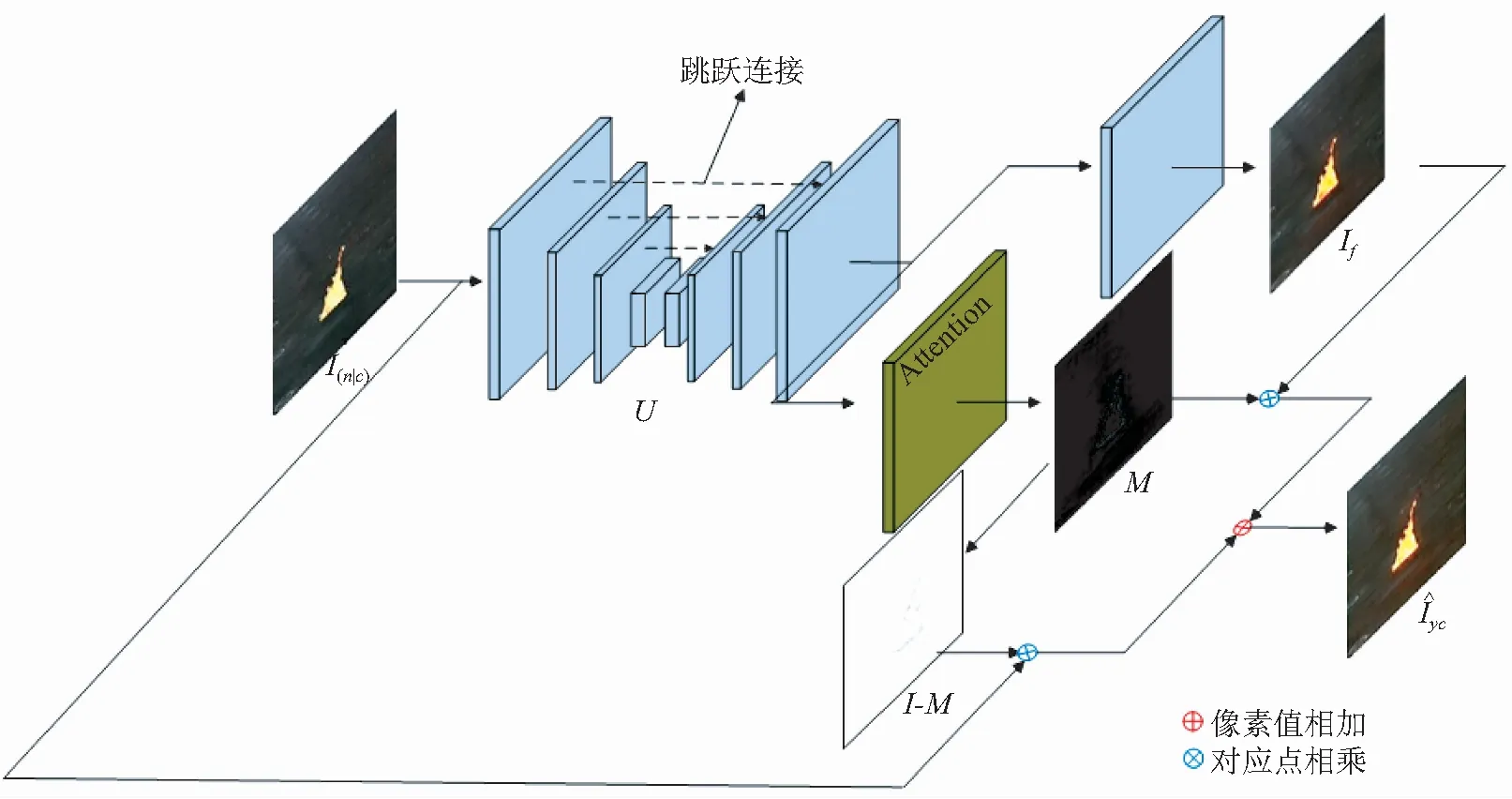
圖6 生成器模型結構
Fig.6 Model structure of generator
3.3 注意力機制
不同于常見的圖像轉換任務,火焰場景遷移只需要對火焰及其周圍進行相應轉換。通過訓練,注意力機制可以對感興趣區域產生高度響應,從而有針對性地提升生成圖像的質量。目前注意力機制可以根據情況和自身功能加載在生成器的前端[26]、中間[27]和末端[20]。為使最終生成的圖像與場景的拼接可以更加自然,本文采用了圖像遮罩[28]的方式融合轉換前圖像I(n|cI)與轉換后圖像If,并采用GANimagtion[20]中的方式訓練注意力層。
圖像遮罩可以表示為式(1):
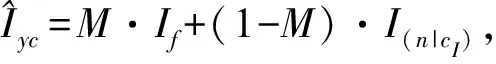
(1)
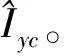
注意力損失函數為:
(2)
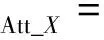
(3)
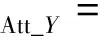
(4)
其中:A=G(I(n|cI)),B=F(Iyc),Ai,j,Bi,j表示圖像矩陣A或B中第i行第j列的元素值。
3.4 判別器
由于圖像的轉換區域集中在火焰附近,因此本文的兩個判別器DC和DF都使用了PatchGAN[6,29]的判別器結構。這種結構不是對圖像的整體進行真實性評價,而是將整體圖像分為N×N的小區域,分別判斷每個區域的真實性。除了最后一層卷積層,每層卷積層之后都伴隨有Leaky ReLU[30]激活層。通過Sigmoid函數將最后的輸出歸一化。判別器的結構如圖7所示。
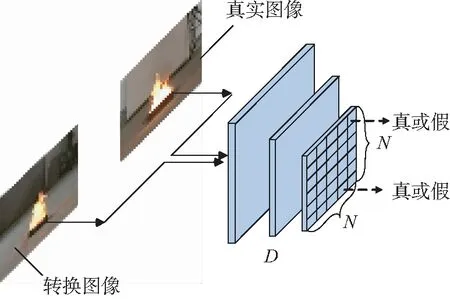
圖7 判別器模型結構Fig.7 Structure of discriminator
3.5 損失函數
循環一致性損失:
(5)
其中:
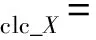
(6)
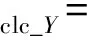
(7)
同一映射損失:
(8)
其中:
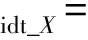
(9)
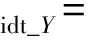
(10)
對于生成器G與判別器D,本文使用了訓練過程相對穩定的Least Squares GAN(LSGAN)[31]作為對抗性損失。對于生成器的輸入z與目標圖像x,有:
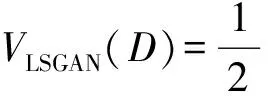
(11)
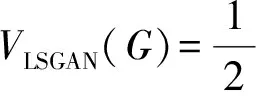
(12)
本文采用常用設置:a=0,c=1,b=1。
因此生成器G與判別器DG的損失函數分別為:
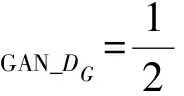
(13)
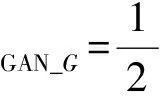
(14)
而生成器F與判別器DF的損失函數分別為:
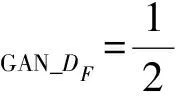
(15)
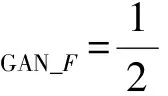
(16)
最終對抗性損失為:
(17)
訓練整個網絡的聯合損失函數為:
(18)
本文設置λ1=5,λ2=0.5,λ3=1,λ4=10-5。
4 實驗與結果分析
4.1 數據集和訓練細節
本文在倉庫場景下錄制了20段視頻,并記錄了光照強度。本文實驗參考倉庫的照度標準,絕大多數視頻的環境光照強度在50~400 Lux之間。以此為基礎,分別制作了火焰圖像數據集cI以及燃燒場景數據集Iy。
最終從16段視頻中分別選用800張I(n|cI)和Iy圖像用于訓練。從另外4段視頻中選取100對用于測試。對于難以分割火焰圖像的復雜場景,本文從相同光照條件下的簡單場景中分割出火焰cI植入復雜場景相同位置作為I(n|cI),而將實際錄制的復雜場景中的燃燒圖像作為Iyc。對于簡單場景,則使用不同時刻的I(n|cI)與Iyc。因此,I(n|cI)與Iyc是非匹配的。
本文實驗均使用Pytorch0.4.1深度學習框架,在英偉達GPU(泰坦Pascal X)進行訓練。BicycleGAN,MUNIT以及本文模型都使用Adam優化的隨機梯度下降法(Stochastic Gradient Descent,SGD)更新網絡參數(β1= 0.5,β2= 0.999),學習率lr分別為0.000 2,0.000 2,0.000 1, Batchsize=1,本文模型訓練200Epoch, BicycleGAN訓練200Epoch, MUNIT訓練400Epoch分別達到穩定的結果。
AgeGAN使用Adam優化的SGD(β1= 0.5,β2= 0.999), 學習率lr=0.001, Batchsize=32,訓練200Epoch達到穩定的結果。
4.2 評價方式
本文通過消融實驗對模型結構進行評價及分析;通過與BicycleGAN、MUNIT等相關模型的比較對火焰遷移模型進行定性評價;通過FID(Fréchet Inception Distance)[32-33]和Learned Perceptual Image Patch Similarity(LPIPS)[34]兩個接近人類視覺的評價指標對圖像質量進行定量評價。
Fréchet距離用于衡量兩個高斯分布的差異,FID計算兩個圖片集在InceptionNet[35]各層間響應的Fréchet距離衡量兩組圖像的差異。
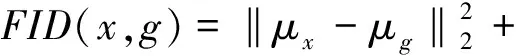
(19)
對不斷增加的干擾而言,FID的測試結果與人類的判斷相一致。與IS[36]相比,FID對噪聲的抵抗能力較強,對模型坍塌更加敏感。較低的FID意味著較高的圖片質量和多樣性。
LPIPS 通過計算生成圖像與實際圖像映射在預訓練的DCNN特征空間的距離評價生成圖像與實際圖像的相似度。LPIPS也展示出了與人類視覺相似的評價體系,與傳統的圖像相似度度量方法不同[37],感知相似度對噪聲更不敏感,對模糊更敏感。LPIPS值越小,生成圖像在人類感知上越接近真實圖像。LPIPS可以表示為:
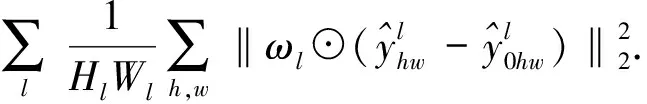
(20)
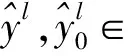
本文取測試圖像的均值:
(21)
4.3 消融實驗
4.3.1 模型作用評估
在第1節中討論了圖像形式的條件cI在圖像轉換上的不同影響。圖8(f)展示出本文的方法具有保持背景圖像質量和增強火焰真實性的優點,這一優勢同樣在圖8(e)和圖8(g)中有所體現。圖8(f)給出了本文模型的轉換結果,它對移植了火焰的場景進行轉換(圖8(d))。圖8(a)給出了相同結構下,使用場景進行轉換得到的結果,可以看出它只會生硬地添加火焰圖像。
另一方面,直接對圖像進行轉換而不是通過編碼重建圖像的方式也便于選擇帶有跳躍連接的生成器以維持背景圖像的清晰度。與圖8(f)相比,通過編碼器-解碼器(Encoder-Decoder)[14]方式生成的圖像(圖8(g))背景顏色改變較大,說明U-net在維持背景方面具有優勢。

圖8 消融實驗結果對比Fig.8 Result comparison of ablation experiment
4.3.2 注意力機制評估
在沒有注意力結構的情況下,本文的模型采用了圖像翻譯過程中最簡單的方法,即接近一致地改變輸入背景的顏色(圖8(e))。而采用注意力結構的生成器將背景顏色的改變限制在火焰的附近(圖8(f)),使結果更加真實。可以相信,隨著數據集的擴充和訓練的進行,這種能力會得到更大提升。

圖9 場景光照強度對注意力的影響Fig.9 Scene illumination intensity effects on attention mechanism
4.4 遷移圖像與環境的關系
4.4.1 光照強度對遷移效果的影響
本文將不同光照強度下拍攝的火焰遷移至同一場景中以分析火焰顏色特征對轉換效果的影響。圖11中火焰內核圖像取自于圖10所示場景。圖10中場景光照強度從左到右分別為78、140、180、400、1 500 Lux。而圖11中3個場景的光照強度分別為186、50、32 Lux。

圖10 火焰內核來源,圖像下方為場景光照強度Fig.10 Sources of fire kernel, labels below each figure is illumination intensity of the scene

圖11 不同光照強度下火焰的遷移結果(火焰內核來自于圖9)Fig.11 Migration results of flame recorded at different illumination intensity(fire kernels taken from Fig.9)
可以看出,火焰在地面的反射光幾乎不受遷移場景光照強度的影響,而是與火焰內核的顏色相關。火焰亮度越高,遷移進場景地面反射光越強烈。并且,由于32 Lux的場景中地面的灰度值最低,轉換圖像的地面反光是這3個場景中最強的。當場景光照強度達到400 Lux時,無論是真實圖像還是轉換圖像,火焰附近都難以看到地面的反光。從圖11可以看出,在同樣的場景中,火焰面積越大,地面的反光越強,這說明除了火焰顏色,火焰面積也是控制轉換結果的一個條件因素。因此可以推斷出本文的模型主要是根據火焰的顏色特征和火焰附近背景的灰度值而補充相應的反射和火焰的邊緣。這是符合常識和預期的,因為攝像機的光圈會自動調整曝光以適應不同的光照強度,因此場景圖像不會因為光照強度變化顯示出非常大的區別。而火焰的明度通常在一個固定的區間內,因此不同曝光下的火焰圖像呈現出不同的顏色特征。
4.4.2 風對遷移效果的影響
當環境中有風時,火焰受風的影響幾何中心發生偏移。相應地,火焰在地面反光的中心也會隨之偏移。圖12選取了3張因風吹而偏移中心位置的火焰(圖12(a)),將其遷移至4個不同場景之中(圖12(b)~圖12(e))。可以看出,4個場景的火焰遷移結果都體現出這一改變。因為訓練集中絕大部分圖像火焰下方位置是盛放燃油的油盤,而遷移場景在該位置缺少油盤,圖像轉換網絡無法對該區域做出合理轉換,因此圖12(d)和圖12(e)效果略差。

圖12 風對室內火焰場景遷移的影響
Fig.12 Wind effects on scene migration of indoor flame
4.5 與其他方法的比較
在圖13中,本文將MUNIT,AgeGAN,BicycleGAN以及本文方法用于火焰與場景融合的效果進行了定性比較。其中,對MUNIT和BicycleGAN分別使用了場景(bg)和移植了火焰的場景(ip)兩種圖像作為待轉換圖像進行訓練。本文的模型在火焰真實性和背景分辨率保持方面都優于最先進的方法。總體來說,MUNIT,AgeGAN及BicycleGAN顯示出了使用隱式編碼表示圖像的缺陷,而且使用移植了火焰的場景(ip)作為待轉換圖像所得結果優于將場景(bg)作為輸入。在僅用場景作為輸入的結果中,BicycleGAN(圖13(a))只能生硬地向場景圖像中添加火焰,而MUNIT(圖13(b))及AgeGAN(圖13(c))則無法描述火焰位置。并且這種生硬的映射改變了圖像的內容信息,導致轉換圖像背景的大面積失真。
盡管通過向場景移植火焰以完善待轉換圖像的內容信息,但是BicycleGAN中固定長度為8的樣式向量不能包含足夠的信息來完美地表示圖像風格,最終導致圖像中出現不均勻的色塊(圖13(e))。同樣, MUNIT提取的固定長度風格及內容向量不能包含足夠的信息保證重建圖像的分辨率(圖13(d))。簡單地增加向量的長度對于背景分辨率的保持是徒勞的。在這一點上,本文的模型不僅輸入具有明確的內容空間,可以準確地描述畫面結構,而且生成器中的跳躍連接可以將圖像的背景的分辨率保持在較高質量(圖9(b))。各主要相關方法的關鍵差異見表1。
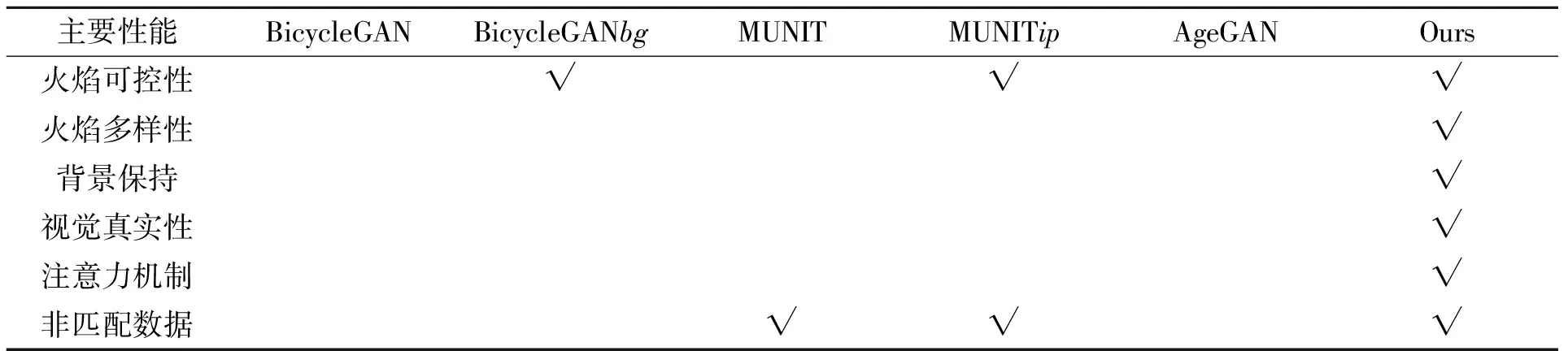
表1 本文及相關方法的主要性能比較
圖13 AgeGAN、MUNIT及BicycleGAN用于火焰遷移的結果比較
Fig.13 Comparison between AgeGAN, MUNIT and BicycleGAN used for fire migration
4.6 質量評價
本文對比了MUNIT,BicycleGAN,AgeGAN以及本文模型在重建的場景圖像與實際場景圖像間的FID與LPIPS值。其中,MUNIT和BicycleGAN分別使用了單純的背景(bg)和植入了火焰的背景(ip)作為待轉換圖像。從表2可知,單純的背景輸入(BicycleGANbg,MUNITbg,AgeGAN)所得結果在FID與LPIPS值上與植入火焰的背景(BicycleGANtp,MUNITtp,Ours)差距明顯,側面反映了圖像形式的條件輸入在處理本文問題上所具有的優勢。與BicycleGANtp和MUNITtp相比,用本文模型重建的圖像的FID與LPIPS值是最小的,分別為119.6和0.134 2,說明同樣以植入了火焰的背景作為輸入的情況下,本文模型火焰場景遷移問題上仍然優于BicycleGAN與MUNIT。
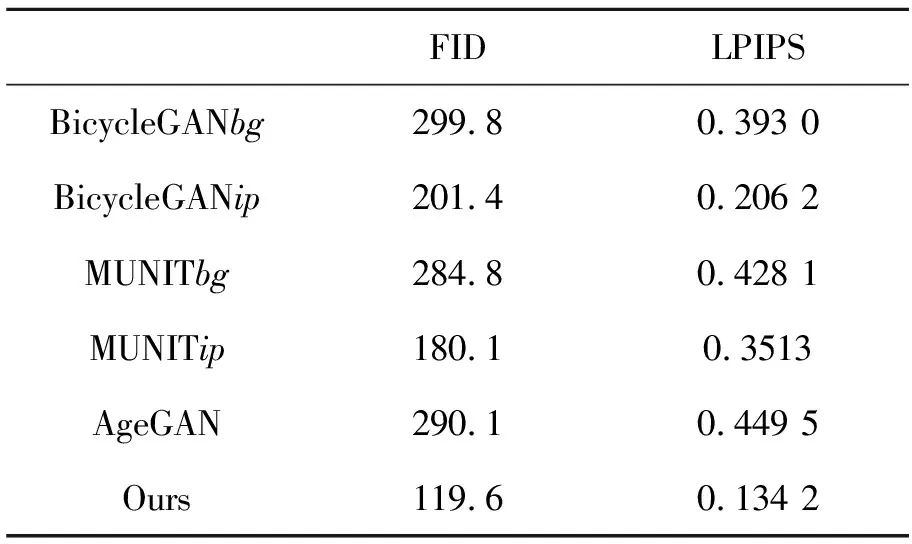
表2 不同模型的FID與LPIPS
4.6 討 論
不同于常見的圖像轉換,本文問題聚焦于火焰周圍圖像而不是整體圖像的風格變化。因此本文選擇添加注意力層以限制圖像轉換的區域。雖然注意力結構的使用提升了火焰場景融合的效果,可以更加準確地在火焰附近的地面添加火光倒影,但無法完全達到人類經驗和邏輯水平。一定程度上,由于火焰根部的儲油盤是黑色的,吸收了大量的可見光,無法顯示出I(n|cI)與Iyc的差異,影響了學習的效果。另外由于存在拍攝距離、角度、背景亮度和火焰大小等干擾因素,相同光照強度下所拍攝火焰的亮度以及地面反光存在差異。總體而言,場景環境中光照強度高,火焰圖像顏色偏黃,地面的火焰反射光越淡;光照強度低,火焰圖像顏色偏青,地面的火焰反光越明顯。轉換模型能夠根據經驗,依據火焰顏色、面積以及場景的顏色向圖像中添加火焰虛化的邊緣和地面的反光。
5 結 論
本文提出了一種新的室內火焰燃燒圖像的場景遷移方法。該方法基于循環一致性生成對抗網絡并添加了注意力結構以提升效果,通過遷移其它視頻中的火焰圖像在未點火場景中生成火焰,目前該領域尚未有人做出相關研究。從信息的保留與傳遞考慮,該方法以顯式的圖像形式取代隱式的編碼以表示火焰形態,在改善火焰的可控性和生成圖像的真實性,以及維持轉換圖像高質量的背景細節方面取得了良好的表現。實驗表明,與BicycleGAN、MUNIT以及AgeGAN等采用編碼方式控制圖像生成的方法相比,本文方法改善了控制條件的可解釋性從而提升了火焰形態的可控性,并且取得了相對逼真的效果。通過在測試集上使用FID和LPIPS兩個接近人類視覺的評價方式對轉換結果的打分顯示,本文方法所得結果最為真實,其分值分別為119.6和0.134 2。在一定程度上,這項工作可以用來制作和增廣危險場合下的火焰燃燒圖像及訓練集。
猜你喜歡
汽車工程師(2021年12期)2022-01-17 02:29:54
當代陜西(2020年14期)2021-01-08 09:30:42
中華手工(2017年2期)2017-06-06 23:00:31
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
