基于YOLOv3 的車輛多目標檢測
2020-03-12 07:43:52王萍萍仇潤鶴
科技與創新 2020年3期
王萍萍,仇潤鶴
(東華大學 信息科學與技術學院,上海201620;數字化紡織服裝技術教育部工程研究中心,上海201620)
交通出行與人們的日常生活緊密地連接在一起,因此道路交通問題成為人們研究與解決的重點問題之一。隨著智慧城市、智慧交通等理念的提出與發展,目前智慧交通系統已成為深度學習研究的熱點,其中車輛目標檢測技術是智慧交通系統數據前端采集研究的重要內容之一[1]。
傳統的目標檢測技術主要有幀差法、背景差分法、光流法以及方向梯度直方圖(HOG)檢測器等方法,具體檢測過程分為四步:圖像預處理、區域選擇、特征提取以及分類器分類[2]。
由于計算量過大和檢測步驟煩瑣,傳統的目標檢測技術很難達到高精度檢測并且泛化能力很差[3]。隨著深度學習在圖像領域的不斷發展,基于深度學習的目標檢測技術的研究取得了巨大的進步。
基于深度學習的目標檢測技術主要分為兩類:①基于區域建議的目標檢測方法[4],利用神經網絡(CNN)代替傳統的特征提取,選擇性搜索方法生成多個候選框,主要有R-CNN、Fast R-CNN、Faster R-CNN、FPN 等檢測算法;②基于回歸的目標檢測方法[4],充分利用了回歸的思想,實現了端到端的檢測[5],直接在原始圖像的多個位置上回歸,標出目標位置邊框以及目標類別,主要有YOLO(You Only Look Once)系列和SSD 目標檢測算法。
由于監控場景下存在光線、車輛種類、交通擁堵遮擋等多重問題,從而導致精確檢測難度高,小目標檢測困難。針對這些問題,本文采用YOLOv3 目標檢測算法對道路交通場景下的各類車輛、行人進行多目標檢測,利用基于Mxnet深度學習框架的YOLOv3 的目標檢測算法,加入Darknet-53網絡結構訓練自制的VOC 數據集,通過調參得到適合道路交通場景下的多目標檢測模型,實現高精度的車輛多目標檢測,最后結合細分類系統完成車輛各屬性的識別。
1 車輛多目標檢測系統設計
本文的車輛多目標檢測系統的設計源于車輛二次識別系統的需求,車輛二次識別系統用于識別車輛品牌、車款、年份、顏色、年檢標、安全帶等屬性信息,便于實現車輛的檢索和車輛以圖搜圖的功能。車輛二次識別系統主要由圖像數據采集、車輛多目標檢測和車輛細分類等模塊組成,實現了各類車輛的快速查找以及其各屬性的可視化。本文主要針對該系統中目標檢測系統的研究與實現,是車輛二次識別系統的重要組成部分。通過道路邊上的卡口攝像頭獲取交通場景車輛圖像數據,然后再對其進行數據預處理。考慮到交通場景下不同的光線和復雜的路況,車輛的目標檢測技術精度存在很大的挑戰。需要選擇識別速度快、精度高的目標檢測技術,以在光線較暗、遮擋嚴重的場景下盡可能地實現車輛種類的識別與定位。
研究發現YOLOv3 目標檢測算法具有速度快、精度高等優點,滿足檢測算法的要求。YOLOv3 目標檢測是一種端到端的檢測算法[6],主要是以Darknet-53 網絡為網絡基礎,利用殘差基本單元解決特征提取的深層問題[7],大量減少了每次卷積的通道,并且采用多尺度預測對輸入圖像的3 個尺度的特征圖進行預測[8]。
車輛多目標檢測過程如圖1 所示。
首先利用YOLOv3 檢測算法對已經完成預處理的圖像數據進行模型訓練,得到適合該場景數據的最優模型并保存。測試檢測目標時將輸入圖片放入對應于YOLOv3 檢測算法的測試腳本,并將其通過保存的最優訓練模型,對其進行多目標預測。由于本實驗的檢測對象為交通場景下的多種目標,具體為汽車、卡車、公交車、三輪車、摩托車、自行車、行人,基本包含了交通場景下可能出現的車輛種類,所以得到的訓練模型僅包含這7 種類別。輸入圖像加入訓練模型后,對網絡結構最深的3 層特征提取進行預測,選擇置信度最高的邊界框輸出。
2 車輛多目標檢測系統的實現
2.1 數據集的制作
車輛多目標檢測時,需獲取數據以及預處理數據,采集的實驗數據需要滿足高清、多場景的要求,本文通過卡口攝像機獲取監控視頻下道路交通場景圖片,通過解碼JPG 圖片后,獲取不同時間、不同地點和不同角度的圖片數據。由于獲取圖片的時間間隔較短,需要先對圖像進行去重,以減少重復樣本,去重后獲得大約18 000 張車輛圖片數據。參考公開的Pascal VOC 數據集格式制作適用于檢測環境的數據集,首先對采集的圖像進行數據標注,使用LabelImg 軟件對數據集進行圖像標注,標注后生成對應的XML 文件。由于本實驗需檢測道路上的各種車輛類型,本文將車輛劃分為6 個種類以及行人,因此XML 文件中共7 個目標,分別為car、truck、bus、tricycle、moto、bike、pedestrian。LabelImg標注樣本如圖2 所示。本文采用的檢測算法不能識別空目標文件,因此數據標注結束后,編寫python 腳本批量刪除空目標的XML 文件及其對應的JPG 圖片。最后利用剩下的13 000 張左右數據圖片制作VOC 數據集,將數據按9∶1分成訓練集和測試集兩部分,使訓練集為11 708 張圖片,測試集為1 000 張圖片。
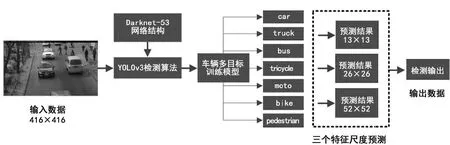
圖1 YOLOv3 多目標檢測過程

圖2 LabelImg 標注樣本
2.2 模型訓練
車輛數據集制作完成后,利用目標檢測算法對自制的VOC 數據集進行模型訓練。本實驗采用的硬件配置是服務器為NVIDA 1080iT 的GPU,軟件環境選擇pycharm 腳本編輯器、MobaXterm 遠程連接軟件、Mxnet 深度學習框架和YOLOv3 目標檢測算法。使用Darknet-53 網絡結構時,首先根據需要檢測的對象對算法進行分類與檢測修改,將檢測的類別按檢測所需改為7 種。然后將Darknet-53 網絡加入到YOLOv3 檢測算法,學習率初始值設置為0.001,根據GPU實際使用的性能情況,將模型訓練的batch size 定為4[9],然后對訓練集進行模型訓練,訓練過程中自動保存訓練日志、訓練模型以及最優訓練模型。在訓練過程中需要調節參數優化訓練過程,首先考慮學習率對預測精度的影響,將學習率由初始的0.001 調至0.000 01;其次考慮動量對訓練過程的影響,當訓練達到瓶頸時,修改動量以提高預測精度。對訓練集進行180 次訓練迭代后獲得最優訓練模型,訓練過程如圖3 所示。
圖3 訓練過程
本實驗采用416×416 大小的圖像輸入,因此不同特征對應的尺度是13×13、26×26、52×52,即每個網格會輸出3個預測框,預測種類數為7,則輸出的維度為3×(1+4+7)=36。這樣可以在不影響檢測結果的前期下,有效減少網絡的運算量,同時提高檢測精度和檢測的速度。
2.3 測試結果
對道路交通場景下的圖像數據進行測試主要考慮車輛種類的覆蓋、不同光線、不同角度以及道路擁堵等問題。本文采用的測試場景多樣化,涵蓋了城市和鄉鎮的十字路口、單向道路和雙向道路等多種場景,以保證該多目標檢測適用于監控下的實時檢測。本文選擇包括汽車、卡車、公交車、三輪車、摩托車、自行車和行人7 種類型全覆蓋、不同光線強度、不同道路的圖像數據,如圖4 所示。
在制作VOC 數據集時,制作了1 000 張測試集未進行預處理,對其進行預訓練的模型測試,從測試結果可以看出該算法對車輛多目標檢測的處理速度達到47.5 bit/s,平均每張圖片的檢測速度達到0.021 s。測試結果如圖5 所示,多種目標檢測的平均精度達到81.65%,其中包括汽車、卡車、公交車、三輪車、摩托車、自行車和行人的檢測精度,由于現在道路場景下使用三輪車和卡車較少,訓練模型中對這兩類的檢測精度較低。由于交通場景中卡口攝像頭拍攝角度、道路擁堵等實際問題,導致在模型訓練中各個檢測精度并沒有和單目標檢測一樣達到95%以上,但是對于該數據集的應用已經獲得很好的檢測效果。

圖4 各類車輛及行人目標檢測圖像
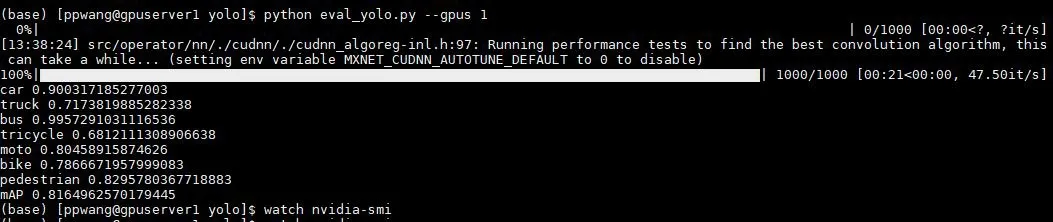
圖5 測試結果
在模型訓練結束后,自動保存適合該數據集的最優預訓練模型,同時保存損失函數以及平均測試精度的變化。平均檢測精度是評價多目標檢測效果的重要指標,當訓練迭代次數到達100 次后,平均檢測精度漸趨平緩,最后達到81.65%左右不再增加,所以可以得到0.816 5 的平均檢測精度。
3 結語
本文介紹了基于Mxnet 深度學習框架的YOLOv3 目標檢測算法的道路交通場景下車輛多目標檢測方法,包括檢測系統的架構、數據集制作、模型訓練、調參優化、檢測結果和結果分析。實驗表明,基于YOLOv3 的目標檢測算法在交通場景下檢測精度上取得了良好的效果,7 種類別下的平均檢測精度達到81.56%,能準確地檢測出6 種車輛以及行人。由于目前實際道路交通場景中三輪車和卡車出現的情況并不多,這兩類的樣本數量稀少以及監控攝像頭受環境的影響產生清晰度的問題,導致三輪車和卡車的檢測沒有達到很高的精度。對此問題,需要進一步深入研究,改進檢測算法,使其對少樣本的訓練模型達到較高的檢測精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
