一種基于混沌理論和LSTM的GPS高程時間序列預測方法
2020-03-06 05:36:32李世璽孫憲坤張仕森
導航定位學報 2020年1期
李世璽,孫憲坤,尹 玲,張仕森
0 引言
利用全球定位系統(global position system,GPS)連續觀測高程數據進行噪聲分析或形變監測時,缺失數據的數量以及缺失數據的連續程度都會對分析
結果產生較大影響[1],因此需要提高缺失數據的補全或預測精度,滿足分析需求,從而保證分析的可靠性。基于神經網絡的預測方法與一些傳統方法相比,則具有很強的非線性特征學習能力[2-5]。如文獻[6]利用長短期記憶神經網絡(long short-term memory,LSTM)長時間的特征記憶能力對上海佘山站的高程坐標進行了預測,其30 d滾動預測結果的均方根誤差約為 2.4 mm,擬合趨勢也較為準確,但使用了缺失數據 2端所有的可用數據訓練模型,不符合實際應用中的預測要求,且缺乏對GPS時間序列自身特性的分析。而在時間序列預測問題中,采用結合了時間序列數據自身特點的混合預測模型,往往能夠取得更好的預測效果,而非某種預測模型的簡單應用[7-10]。
由于GPS高程時間序列是1種非平穩非線性的1維時間序列,它包含了確定的長期趨勢、周期性的震蕩模式,以及短期的非線性變化規律和噪聲[11],其中在我國境內噪聲通常為白噪聲(white noise,WN)加閃爍噪聲(flicker noise,FN)[12-13]。遍布于整個時間序列的噪聲,使模型的整體預測結果具有不確定性,不同頻率的信號相互交疊既掩蓋了序列原本的變化規律,同時也增加了重復的時間序列信息,它們都使模型學習序列特征更加困難。因此提高時間序列的預測精度,應先將噪聲分離,并從原始的1維序列中挖掘更多有效的特征模式用于預測。
混沌時間序列預測方法是著眼于分析時間序列自身特點的 1類非線性時間序列預測方法,它首先通過降噪減少序列的無用信息,再利用序列各時間節點間的相關性以及序列片段包含信息量的多少,將1維時間序列映射到高維相空間,從而恢復出時間序列系統特征,最后使用多特征序列進行預測。混沌預測方法在許多領域都已成功應用,如文獻[14]將 1維的徑流量時間序列進行相空間重構,恢復了復雜水文系統的時空特征,并將重構后的多維序列作為預測模型的輸入進行訓練,提高了長江徑流量預測的穩定性和準確性。文獻[15]通過求取嵌入維數與延遲時間,把人流量時間序列重構為多維度空間矢量,將有規律的混沌吸引子恢復出來后再進行預測。文獻[16]應用混沌理論,重構GPS衛星鐘差序列并進行了預測,取得了較好的短期預測效果。
因此,本文嘗試將混沌理論與 LSTM相結合,提出1種新的預測模型。首先對時間序列進行經驗模態分解(empirical mode decomposition,EMD)并降噪,去除序列包含的白噪聲部分,然后求取時間序列的延遲時間,嵌入維數以及李雅普諾夫指數,證明GPS高程站心坐標時間序列具有混沌特性,并重構序列相空間。最后,將相空間每1維特征向量作為LSTM的時間步輸入網絡進行訓練。本文方法將預測結果的均方根誤差(root mean square error,RMSE)與平均絕對值百分比(mean absolute percentage error,MAPE)與常用的 LSTM 和 LSTM+卷積神經網絡(convolutional neural networks,CNN)的方法,以及文獻[6,10]提及的方法相比較,希翼通過著重對GPS高程時間序列特性進行分析,可彌補簡單應用神經網絡可解釋性較差的缺點,對于時間序列變化趨勢的預測會更為顯著與準確,以用于GPS高程時間序列的趨勢預測或補全工作。
1 GPS高程時間序列預測方法
本文預測方法的網絡結構如圖1所示,主要由時間序列降噪、混沌特性分析,以及LSTM預測網絡幾部分組成。其中,實驗數據來源于國際全球衛星導航定位系統服務組織(The International Global Navigation Satellite Systems(GNSS) Service,IGS)基準站上海佘山站(SHAO)的2 380 d站心坐標系高程數據,將其作為原始時間序列。
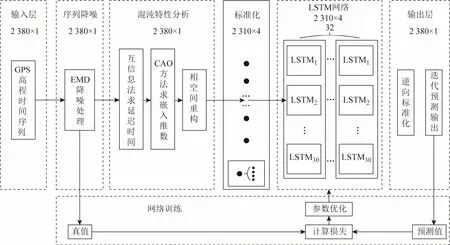
圖1 GPS高程時間序列預測模型
1.1 序列降噪
EMD方法是1種數據驅動的降噪方法,認為瞬時頻率如果有意義,函數必須是對稱的,局部均值為零,并且具有相同的過零點和極值點,由此可將原始時間序列分解為若干個包含不同時間尺度的本征模函數(intrinsic mode function,IMF),如圖2所示。其中包括高頻噪聲項、周期項、以及趨勢項等[17-18],再通過計算各IMF與原序列的相關性重構降噪后的時間序列,去除高頻噪聲,各IMF與原始時間序列的相關系數如表1所示,實現對GPS時間序列的降噪后,得到的序列尺寸應為2 380×1,即降噪后時間序列共有2 380 d數據,每1天數據包含1個特征維度。
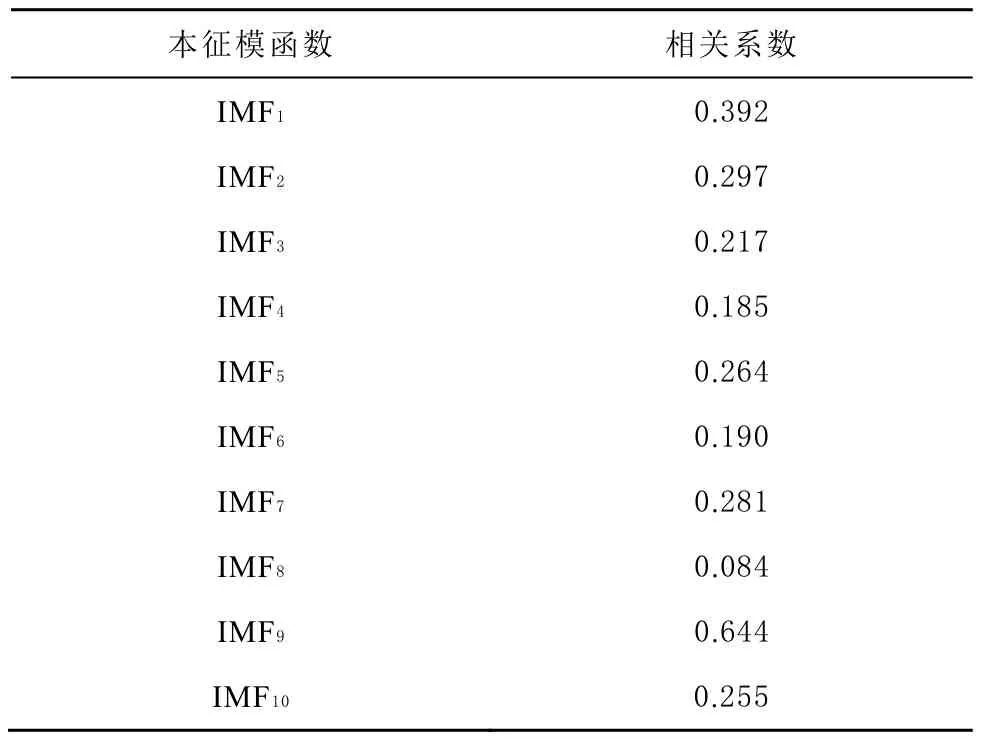
表1 各本征模函數與原序列的相關系數
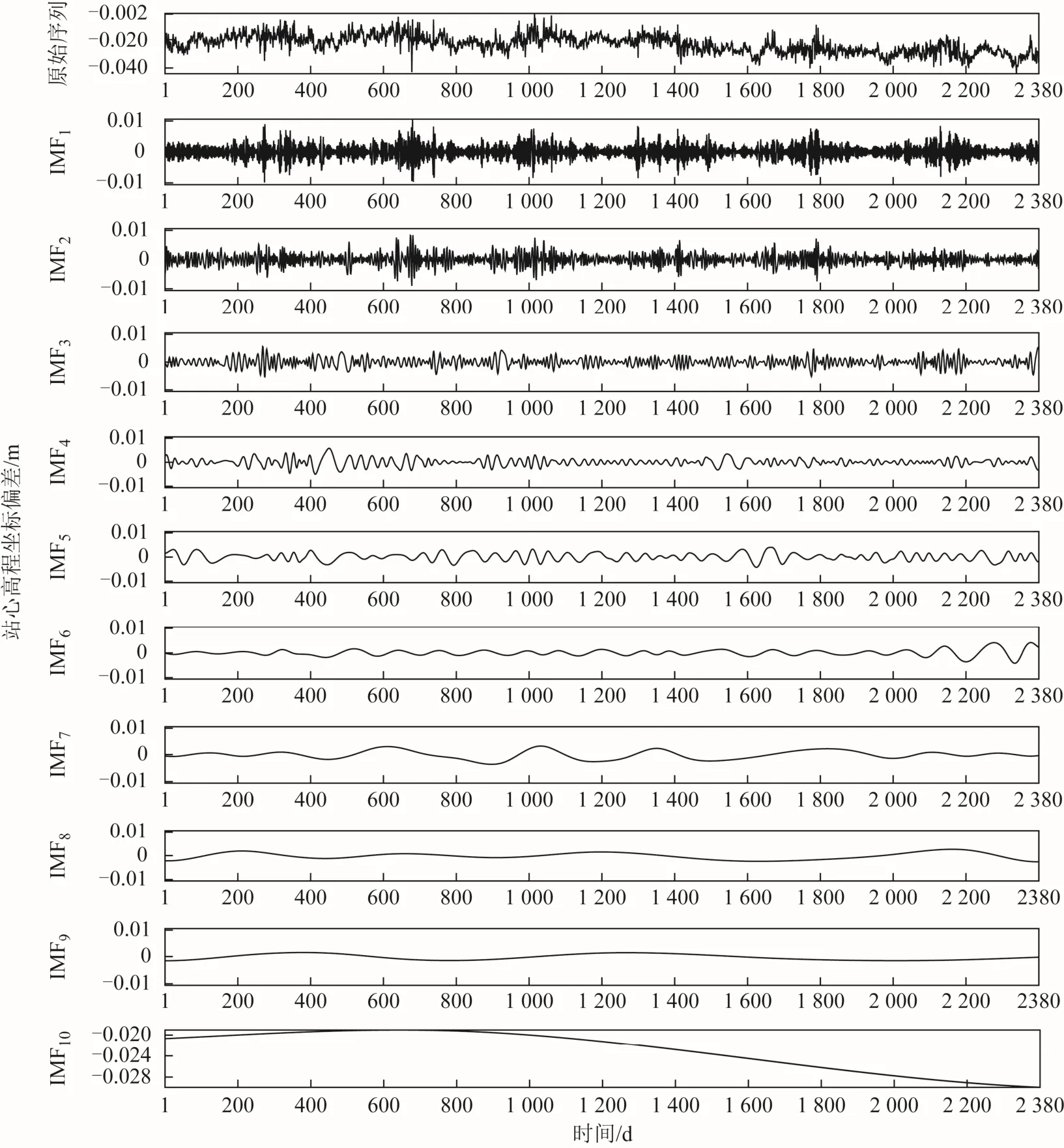
圖2 原始時間序列與經EMD分解后的各本征模函數
由圖2可知,原始時間序列經EMD分解得到 了10個不同時間尺度的本征模函數,頻率依次降低,其中IMF10頻率最低且具有明顯的趨勢項特征。而由表1可知第1個相關系數極小值對應的IMF為IMF4,說明此時IMF序列與原序列相關性最低,可知IMF1~IMF4代表了高頻噪聲[17-18];所以將它們歸為噪聲序列,IMF5~IMF10則重構為降噪后時間序列,序列降噪前后對比如圖3所示。
由圖3可知,降噪后的時間序列較好地保留了它的周期項特征與趨勢項特征,時間序列的變化情況更為清晰。
1.2 混沌特性分析
降噪后的時間序列仍為1維的時間序列,此時序列的特征并不明顯,需要對序列進行合適的采樣,拓展特征維數,故采用互信息法求取合適的延遲時間,CAO方法求取嵌入維數,最終得到李雅普諾夫指數,驗證序列具有混沌特性并將降噪后的時間序列重構為包含 4個維度特征的多特征時間序列,重構后的序列尺寸應為2 340×4,即重構后的序列包含2 340 d數據,每1天的數據包含4個特征維度。
1)延遲時間的求取。互信息法是1種成熟的確定延遲時間的方法,它能夠描述序列具有的非線性特征,最大化時間序列包含的信息量,其計算公式可表示為
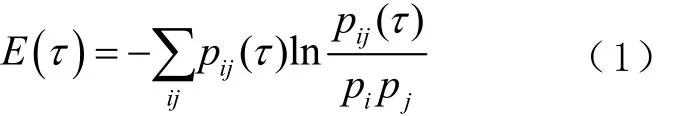
式中:E(τ)表示時間序列平均信息熵;pi與 pj分別表示時間序列在區間i、j內的概率;pij(τ)為其聯合概率;τ為延遲時間。由式(1)可知,隨著τ的增大,時間序列 x(t)與 x(t+τ)的 E(τ)會逐漸降低,直到某個臨界點,它們將不再關聯,而這個臨界點通常取第1個極小值點。針對降噪后序列應用互信息法求得的不同延遲時間下的平均信息熵如圖 4所示。
由圖 4可知,平均信息熵在延遲時間為 14 d的時候,達到第1個極小值,說明此時序列片段間關聯性達到最低,故選擇延遲時間為14 d。
2)嵌入維數的求取。CAO方法求取嵌入維數,能夠使重構后的時間序列相空間不存在信息折疊,在混沌時間序列分析時廣泛使用[19],算法步驟如下:
步驟1:從較小的嵌入維數m開始,分別重構出m維與m+1維的相空間,計算相空間中鄰近點對間的歐式距離比值(),rim,可表示為

步驟3:計算E(m)與E(m+1)的變化比Em,可表示為
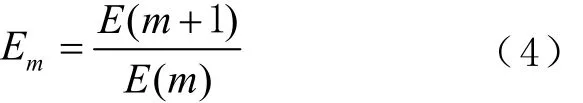
步驟4:重復步驟1~步驟3直到Em穩定。
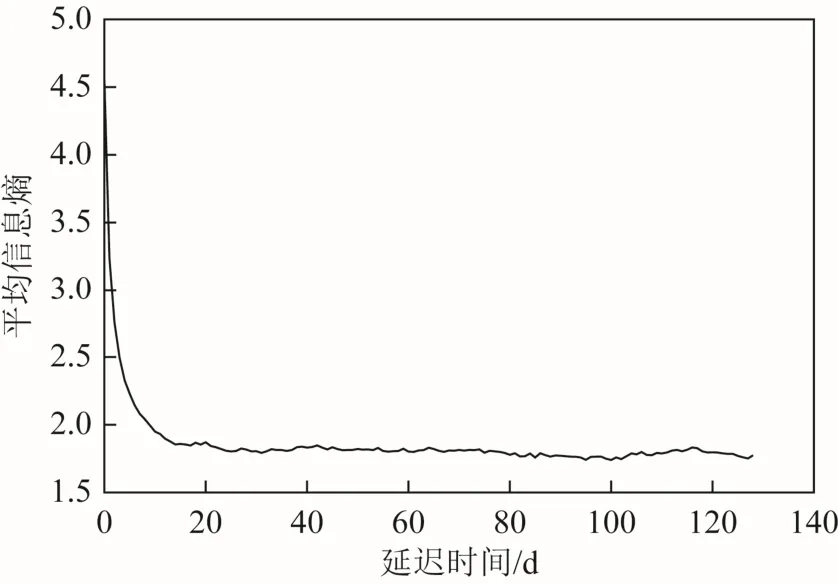
圖4 不同延遲時間下的平均信息熵
若序列存在混沌特性,那么當 m增加到某個值時,Em會收斂于1,表明此時時間序列的吸引子在相空間已完全打開,嵌入維數的增加不會再使特征序列包含的信息量變多,所以將 m+1作為嵌入維數最合適,根據CAO方法求得的各維數下Em的變化情況如圖5所示。
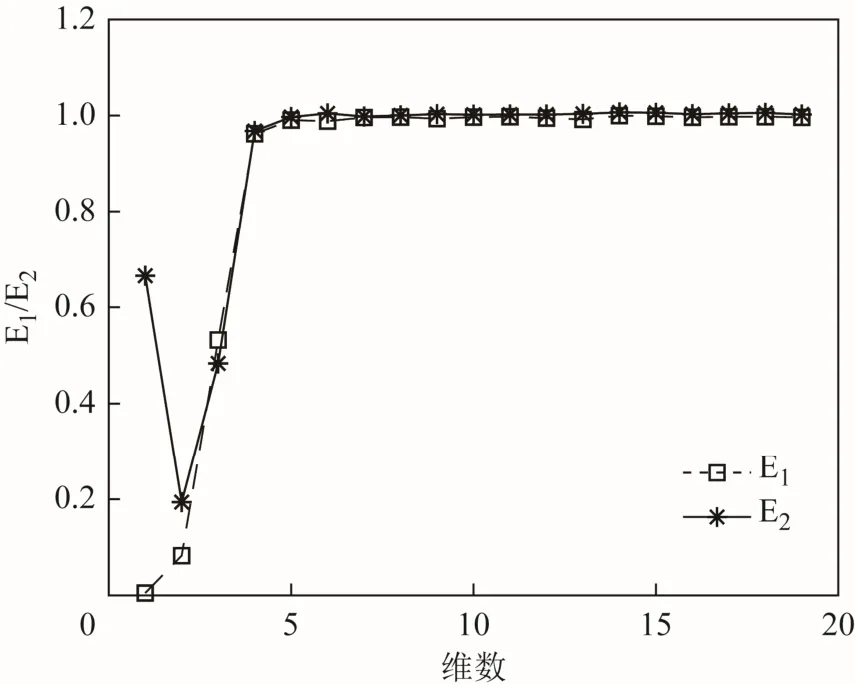
圖5 最小嵌入維數
由圖5可知,維數達到4以后,變化比在小范圍內逐漸穩定,可以認為在該維度上重構時間序列能夠很好地展開11維時間序列,近似反映原系統相空間的變化規律,因此嵌入維數選擇為4。
3)GPS時間序列的混沌性判別。混沌性判別是混沌時間序列相空間重構的可行性保證,常用方法是通過求取延遲時間和嵌入維數來確定最大李雅普諾夫指數,進而判斷時間序列是否具有混沌特性。
李雅普諾夫指數反映了混沌吸引子中鄰近軌道的分離速度,而最大李雅普諾夫指數決定了相空間相鄰軌道是否穩定,若其大于 0,則序列變化會以指數增長,直到無法預測。根據求得的延遲時間與嵌入維數計算李雅普諾夫指數,具體步驟如下:
步驟 1:對降噪時間序列做快速傅里葉變換,并通過周期-功率譜圖估算序列平均周期;
步驟2:利用延遲時間τ,嵌入維數m重構時間序列,序列x(n)經過重構后可表示為
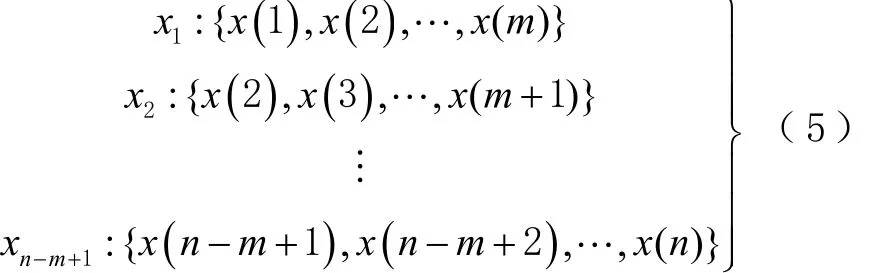
式中: xn?m+1表示重構后的第 n-m+1維時間序列;x(n ?m+1)表示原始序列第n-m+1個值。
步驟3:找到每個點 x (t)的最近鄰點x(t?),同時限制短暫分離,計算鄰近點對的距離初值 xt(0),可表示為
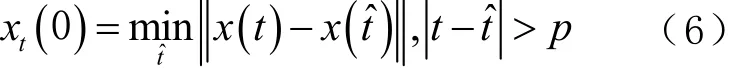
式中:p 為平均周期;t=1,2,…,n-m+1。
步驟 4:計算每個點χ(t)在 i個延遲后相應鄰近點對的距離χt(i),即
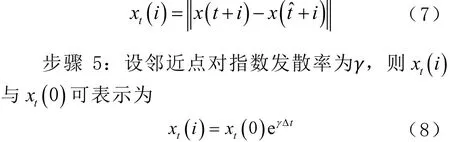
式中:t?=1,2,… ,m,且 t≠t?;i=1,2,… ,min(m-t,m-t?)。對每個 i求取所有 t的χt(i),并求其平均χ(i),在χ(i)與i有線性關系的區域用最小二乘法擬合直線,該直線斜率即為最大李雅普諾夫指數。
根據上述步驟求取時間序列的平均周期,時間序列周期功率譜如圖6所示。
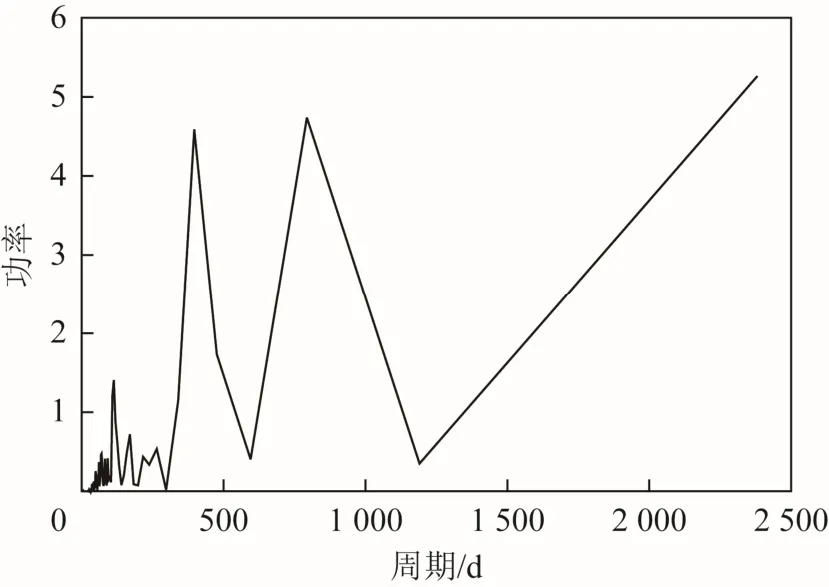
圖6 周期功率譜(即序列長度時)
由圖6可知,序列周期圖為2 380 d時,功率達到最大點,其次為平均周期取793 d時,故取793 d為序列平均周期,結合延遲時間與嵌入維數求取最大李雅普諾夫指數的結果如圖7所示。
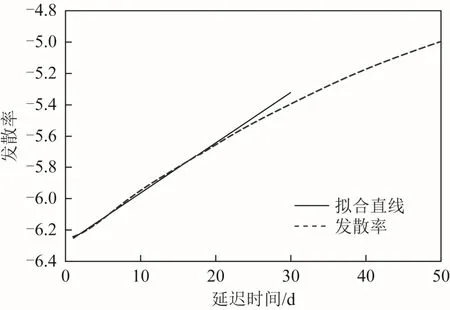
圖7 時間序列最大李雅普諾夫指數
根據圖7可知,實線為擬合的直線,其斜率為0.033 4,即最大李雅普諾夫指數大于0,證明實驗所用高程時間序列具有混沌特性,可以采用混沌理論重構GPS高程時間序列相空間并進行預測。
1.3 LSTM預測模型
LSTM是1種特殊的循環神經網絡,有著與循環神經網絡相似的單元結構,能夠通過前向與反饋傳播有效記憶時間序列時間節點間的變化特征。除此之外,LSTM增加了遺忘門、輸入門和輸出門。其中遺忘門能夠限制上一時間節點輸出的信息量,輸入門可以選擇性地獲取新的輸入信息,輸出門則能根據新輸入的信息與上一時刻輸出的信息計算出當前時刻的輸出;3個門結構相互作用,通過反復訓練獲得網絡權值,它能夠充分學習到不同時間步之間短期或長期的時間特征。
為加快網絡權值的收斂,故先對重構的時間序列進行數據標準化處理,再輸入 LSTM預測模型進行學習,并計算網絡輸出的迭代預測值與真值的損失(loss),使用 ADAM(adaptive moment estimation)方法對網絡權重值不斷優化改正,最終得到預測模型。
1.4 評價指標
預測結果的評價指標采用 RMSE和 MAPE,其中:RMSE對異常點較敏感,本文用它刻畫真實值與預測值的偏差,當預測時出現的不合理點越少,RMSE也會越小;MAPE則考慮了誤差與真實值之間的比例,用它來反映預測值與真實值的相對誤差,它們的計算公式可分別表示為

式中:n 為序列長度;true[i]與 predict[i]分別代表序列第i個真實值和預測值。
本文還將預測點與真實值的趨勢擬合情況作為評價指標之一,并且分析了本文方法應用在其他站點數據上的泛化能力。
2 實驗與結果分析
本文的實驗數據來源于中國地震局全球衛星導航定位系統(global navigation satellite systems,GNSS)數據產品服務平臺,共設計了2組實驗用于驗證本文提出的預測模型的有效性。第1組實驗基于IGS基準站上海佘山站(SHAO)的2 380 d站心坐標系高程數據,對比方法為目前常用的LSTM和 LSTM+CNN方法、文獻[6]和文獻[10]使用的變分模態分解(variational mode decomposition,VMD)以及廣義回歸神經網絡(generalized regression neural network,GRNN)的預測方法。第 2 組實驗針對SHAO、武漢站(WUHN)、拉薩站(LHAS)、新疆鄯善站(XJSS)和北京房山站(BJFS)等5個不同區域站點的各2 380 d站心坐標系高程數據,分別使用不同方法進行預測實驗,旨在驗證本文預測模型的泛化能力。實驗中數據預處理以及混沌特性分析部分的實驗是基于MATLAB2014完成的,預測模型的搭建與實驗是基于 Python3.7與Tensorflow1.9完成的。
2.1 預測模型的訓練
綜合前文的分析,結合圖1可知,重構后的時間序列共有2 340 d,每1天的數據有4個維度,實驗選取了前2 310 d數據作為訓練數據,剩余部分作為測試數據,并且通過網格搜索法選取預測模型超參數,最終選定隱層數量為32層,每1隱層中的LSTM神經元為30個,訓練輪數為500輪,學習率為0.001,批尺寸為64個。模型的輸入為重構后序列的第1~2 309 d數據,與之對應的輸出標簽為原始時間序列中第2~2 310 d數據,訓練過程中各方法的損失函數收斂情況如圖8所示。
由圖8可知,在訓練集上,所有方法的loss收斂都很快。其中LSTM方法的loss最大,收斂后有一定的波動,LSTM+CNN的loss較之更低,且較穩定。本文方法與文獻[10]方法的 loss大小明顯小于前 2種方法,說明在訓練集上更容易學到序列的變化模式,效果優于前2種方法;不同在于本文方法loss波動較大,但總體看來 loss略低于文獻[10]的方法,說明本文方法在訓練集上表現最優,同時也印證了模型超參數的選擇是較為合理的。
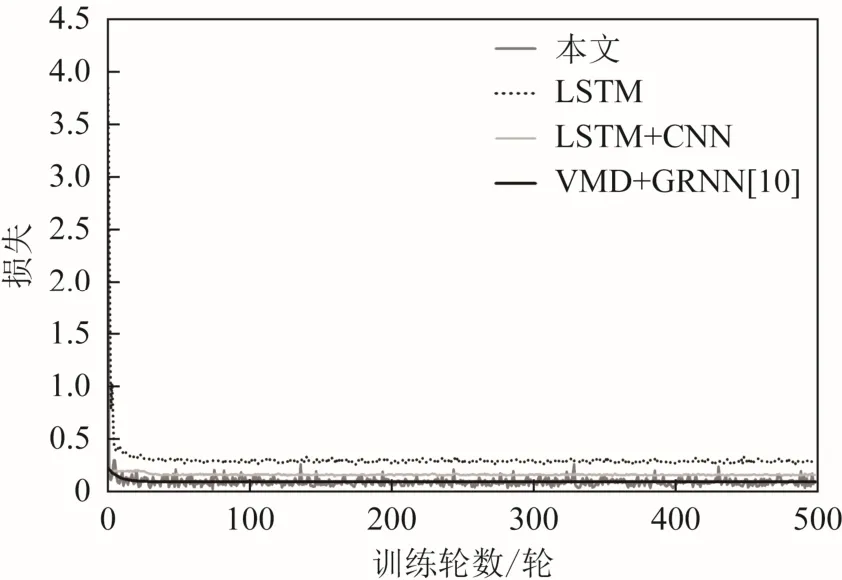
圖8 損失函數收斂
2.2 SHAO站預測結果對比
考慮到迭代預測的結果存在一定的不確定性,所以本文基于4種方法分別訓練了20次模型,并分別統計了預測結果的評價指標,見圖9、圖10,各方法最優結果的評價指標如表2所示。
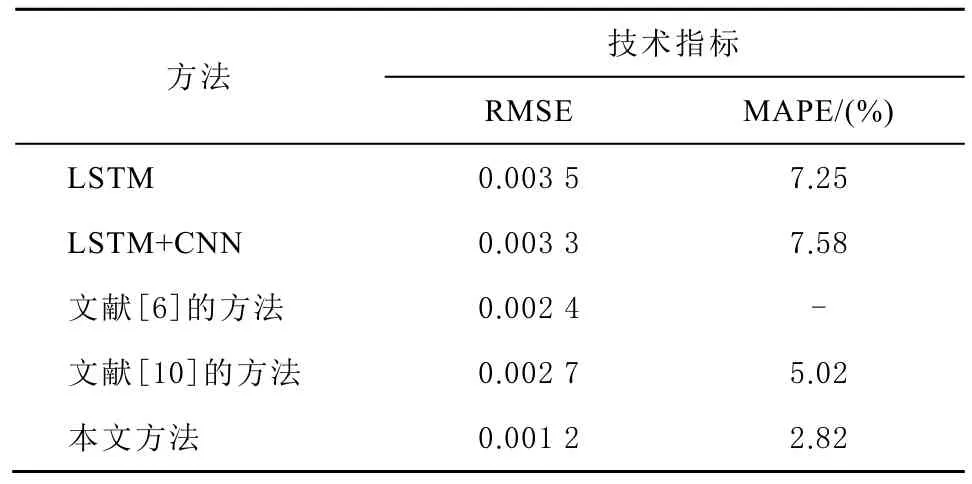
表2 各方法評價指標對比
綜合圖9、圖10與表2可知,所有方法的預測結果都在一定的范圍內浮動,是相對穩定的。其中,文獻[6]由于通過 Lag Feature方式重構時間序列,并進行了網絡超參數優選,因此 RMSE相較前2種方法有明顯提高。文獻[10]則結合了混沌理論重構的多特征時間序列和 GRNN方法,同時提高了RMSE和MAPE,說明了多特征預測的有效性。本文方法同樣利用混沌理論構建多特征,但采用了 LSTM進行預測:得到的 MAPE為2.82 %,說明預測值與真值相對誤差小;而RMSE僅為0.001 2,說明預測結果中異常點較少,其對應的觀測值物理意義為站心坐標預測值與真值間的平均誤差為 1.2 mm,這能夠滿足 GPS靜態數據后處理的精度要求、在所列方法中,預測效果為最佳。各方法對 SHAO站 30 d最佳的滾動預測效果圖見圖11。
由圖 11可知:LSTM方法和 LSTM+CNN方法預測點擬合的整體趨勢較為平緩,對于序列的局部變化難以及時做出調整進行預測;而文獻[10]和本文方法由于使用了多特征,使得預測結果對于單調性以及凹凸性發生變化的點更為敏感,預測的趨勢更為準確。這也說明了為什么本文方法在訓練時,雖然誤差總體較小,但波動較大。
2.3 模型的泛化能力分析
為說明本文提出的預測方法具有較好的泛化能力,本文針對WUHN站、LHAS站、BJFS站、XJSS站分別做了4種方法的預測實驗,預測效果如圖12所示。
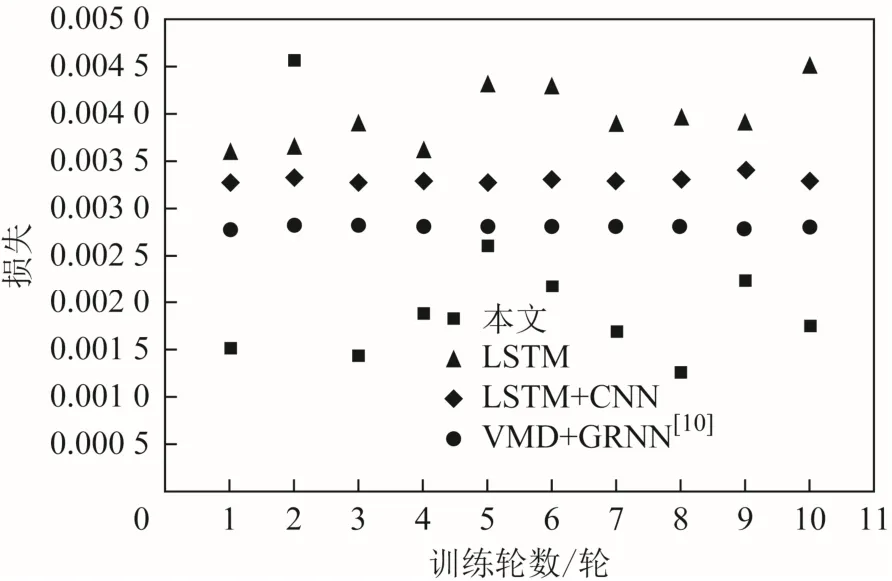
圖9 均方根誤差(RMSE)對比
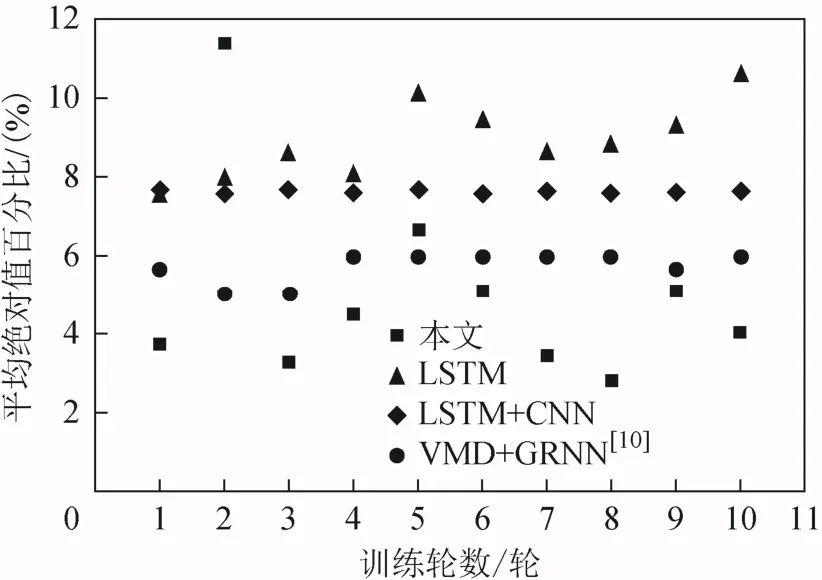
圖10 平均絕對值百分比(MAPE)對比圖
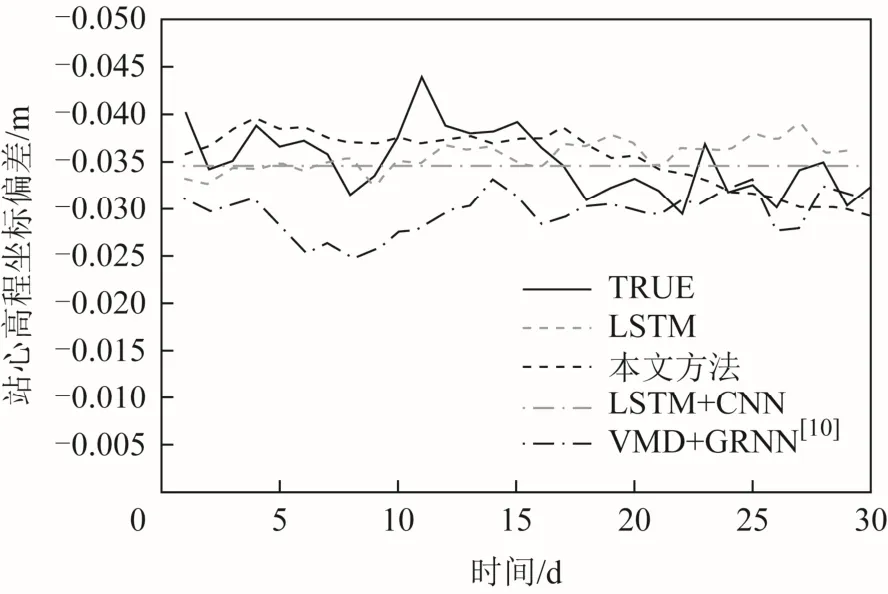
圖 11 SHAO 站 30 d 預測效果
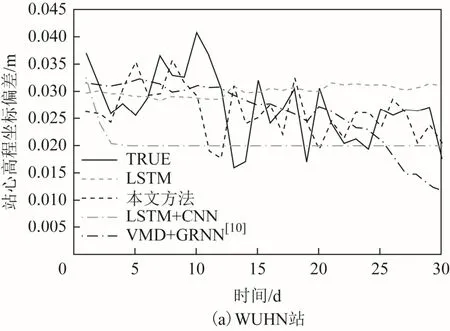

圖12 各站30 d的預測效果圖
由圖12可知,針對不同地區的高程觀測數據,各站點的預測結果與 SHAO站大致相同,LSTM、LSTM+CNN的預測測結果較為平緩,能夠反映一定的整體趨勢,而本文的方法不僅能準確反映序列整體的變化趨勢,局部點的變化趨勢也更為顯著,說明該預測模型具有一定的泛化能力,同時也說明了混沌分析,用多特征變量進行預測以及建立混合模型的有效性。
基于上述實驗結果,可以得出以下結論:
1)單變量特征的預測方法在精度和預測曲線形態的擬合上要略差于多變量特征預測方法;
2)基于混沌理論將單一維度時間序列重構為多特征時間序列,是1種有效的拓展或恢復特征的方法,能夠有效提高預測的效果;
3)結合對時間序列自身特性分析與預測模型的混合模型預測方法要優于某一預測網絡模型的簡單應用。
3 結束語
針對GPS高程時間序列的特點,將混沌理論與LSTM相結合,本文提出了1種新的混合預測模型。首先對時間序列進行EMD降噪,去除白噪聲等無關信息;然后驗證了GPS高程時間序列具有混沌特性;并將1維時間序列在高維展開,增加了特征維度,最大化序列包含信息;再作為LSTM的時間步輸入模型進行訓練。通過 2組實驗數據計算結果表明,本文方法的預測結果中,RMSE最低可達 0.001 2,而 MAPE僅為2.9 %,能夠滿足GPS后處理的精度要求,提高了對高程時間序列的預測精度以及變化趨勢的準確性,同時具有一定的泛化能力,是深度學習在GPS數據分析領域的 1次應用,可用于今后的實際工程中的預測或補全應用。接下來的研究方向會針對訓練時不穩定的現象進行模型改進,同時探索深度學習在GPS領域的其他應用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
