一種變鄰域搜索與人耳掩蔽音樂生成方法
2020-02-24 09:11:30肖兆雄沙學軍
哈爾濱工業大學學報 2020年5期
關鍵詞:音樂
梅 林,肖兆雄,沙學軍
(哈爾濱工業大學 電子與信息工程學院,哈爾濱 150080)
音樂在日常生活中扮演著獨特角色,人們利用音樂或釋放壓力、表達情感、尋求共鳴,或盡情享受音樂帶來的美的體驗.隨著生活水平的不斷提高,只要稍加練習,普通人也能演唱或彈奏出優美的旋律,但相比之下作曲的門檻顯然更高.編寫一首樂曲往往分為旋律、風格、速度、調性與結構、和聲與樂器等部分[1],而且樂曲的各個部分不是完全正交,而是相互關聯的,例如一首歌的旋律往往決定了它的風格,而風格又在一定程度上影響了速度;樂句往往是小節的重復或變體等.因此在過去作曲屬于少數有天賦的人的工作,同時編寫一首好的樂曲也得益于作曲家的豐富經驗.
隨著計算機技術的發展,研究人員試圖從兩個角度利用計算機幫助作曲:一方面,協助有經驗的作曲家,完成一部分繁瑣的可重復性工作,使其專注于創造性的藝術;另一方面,使普通人也能夠從輕松譜寫簡單的樂曲開始,一步步培養人們作曲的能力與對音樂的興趣,使人們更加了解譜曲背后的原理,從而為作曲領域提供更多可能.本文著重研究的是無需或僅需少量專業知識的基于計算智能的音樂生成方法.伴隨著音樂市場的迅猛發展,作曲的專業方法與水平也在迅速攀升,基于變鄰域搜索與掩蔽效應的音樂生成方法能深度挖掘樂譜的潛能,通過人機交互充分調動音樂愛好者,尤其是青少年對音樂創作的積極性.
1 音樂生成領域研究概況
1.1 研究概況
從1959年Hiller與Isaacson首次在電子計算機上編寫音樂生成算法[2]開始,人們一直嘗試利用計算機代替或協助操作者完成作曲工作.音樂生成算法大致包含兩大類別:傳統算法與機器學習算法.傳統算法往往通過對音樂數據的特征提取建立數學模型將音樂參數化[3],或使用音樂編曲規則建立網絡結構并填充先驗知識庫進行建模[4];機器學習算法往往使用MIDI格式文件,通過構建神經網絡,如遞歸神經網絡(Recurrent Neural Network, RNN)、卷積神經網絡(Convolutional Neural Network, CNN)、長短時記憶(long Short Term Memory, LSTM)網絡等對音樂進行訓練[5-10],隨后通過隨機初始化參數的方法生成音樂.
盡管基于機器學習方法的音樂生成算法種類豐富,并且充分利用的模型或網絡的計算性能,但仍存在以下問題:
1)訓練樣本基本采用MIDI格式的音樂文件,該格式的音樂文件數據量小,易操作,但其音樂形式往往較為陳舊,無法體現音樂的流行性;
2)現有的基于機器學習的音樂生成系統網絡往往移植于在自然語言處理或圖像處理取得成效的網絡,幾乎不存在為音樂信號專門設計的神經網絡結構.因此無論是系統的輸入輸出還是參數調節都存在著一定的局限性;
3)絕大多數的音樂生成模型在生成階段采用的是白噪聲信號作為輸入,不符合一般的作曲規律;
4)生成出的音樂樣本往往在長時間范圍內不具備和諧性,且一般只有一種樂器,音樂形式較為單調.
1.2 本文所采用的方法流程
本文設計以下結構用作音樂生成,如圖1所示.輸入階段為時域音樂波形,經過基于音高顯著度的旋律提取與基于人耳掩蔽效應的時域音符分塊后映射到音符域以便人為調整,隨后輸入訓練模型中獲得動態范圍、二次折疊基音等訓練數據.在生成階段使用基于變鄰域搜索的音樂生成算法迭代生成樂譜,最后從樂器庫中選擇樂器完成音樂片段的制作.整個過程從輸入到輸出都可以生成樂譜與時域波形文件以便人工增刪與標注,人機交互的思想貫穿其中,有助于充分調動操作者的積極性.下面分為訓練階段、生成階段與樂音模擬三個部分對整個系統做介紹.

圖1 本文音樂生成系統結構
2 訓練階段
2.1 訓練輸入與預處理
輸入音樂訓練階段的輸入x(t),它以4個小節為單位,可以是一段樂器的獨奏,也可以是一段人聲哼唱.在后續的處理中將對x(t)重新定位,音符起始位置位于t=0處.
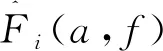
為調動操作者的積極性與創造力,本文所述方法有意對頻譜進行模糊處理.降低部分基頻提取算法的復雜度,并采用余弦加權算法,幀內加權算法為
(1)
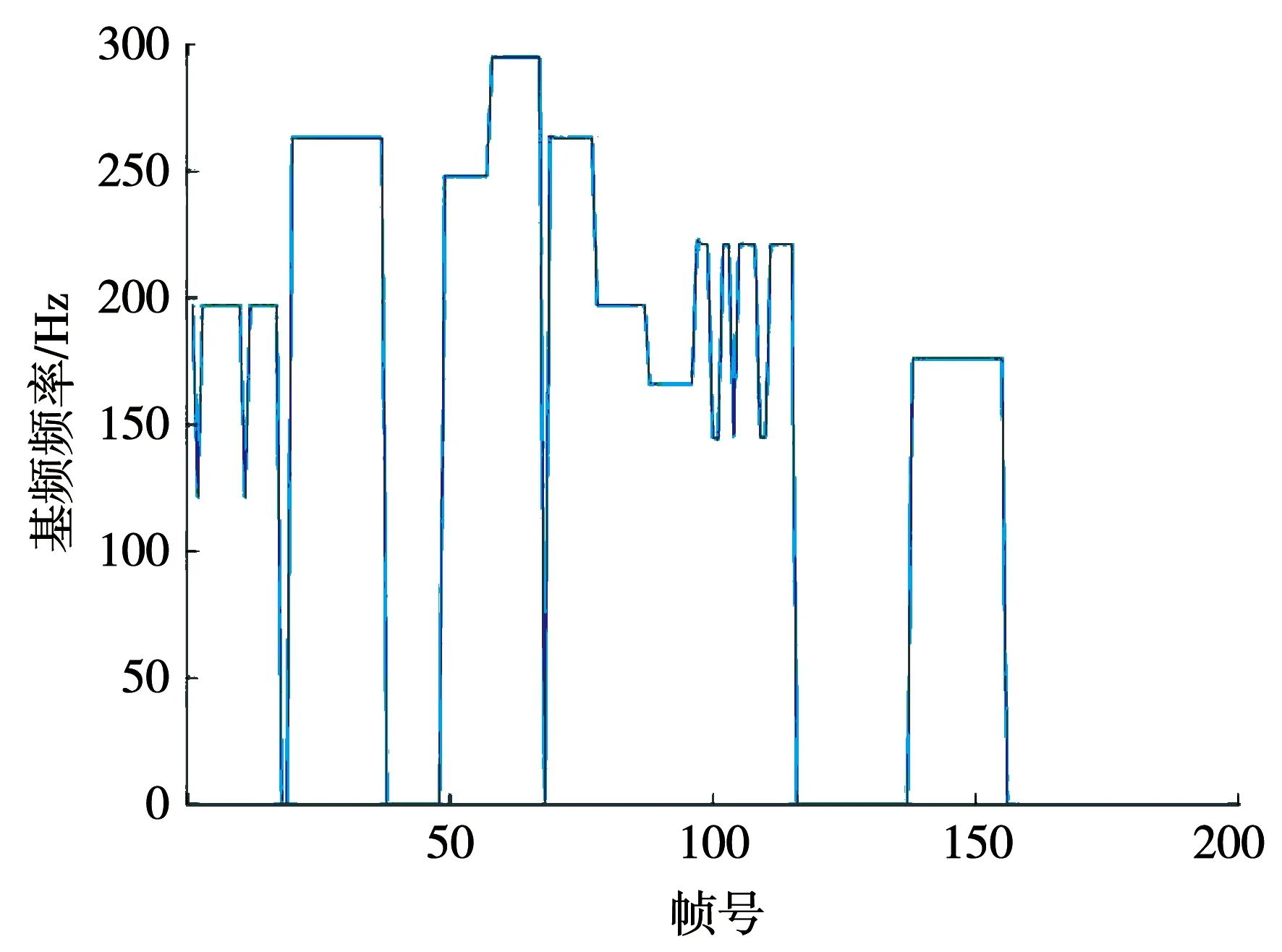
圖2 基于音高顯著度的旋律檢測示意
由圖可知該算法基本可準確檢測旋律線,但會偶爾出現旋律過低的情況,可用簡單的算法解決.但使用本文的預先加權算法將會有意使其中兩個音符的高度降低,通過譜表可視化與試聽即可手動在譜表中調整音高,達到培養操作者的樂感的目的.
2.2 訓練參數
基于現有的樂理知識,本文將訓練參數設置為式(2)所示,式中第1項為記數符,用于標示已訓練樣本的數量,前3列為專業樂譜參數,后4列為將樂譜進行兩次折疊后獲得的基本樂譜參數,用于描述樂譜在較長時間內的連貫性與變化.將頻譜折疊后處理屬于本文的試驗性操作,初步選取4個基本樂譜參數進行分析,不至于使系統過于復雜.具體參數名如表1所示.
(2)

表1 訓練用樂譜參數
以數個表中基本參數為例,基音為樂譜的第一個音,動態為音符的整體變化程度,豐富度為音符出現的數量,速度為音符間平均間隔.
以其中一個二次折疊參數為例,二次折疊動態1如式(3)所示:
Ndyna4N,1=∑(|diff(E4(1,i))|).
(3)
式中E4(1,i)為將樂譜E(i)二次折疊后的樂譜第一行,求導操作將跳過E(i)=0的非音符點.在獲取上述參數后,可繼續添加訓練樣本.理論上添加風格不同的音樂會使訓練用樂譜參數趨于二者平均值,因此可對訓練結果進行加權,使整體的訓練結果偏向一特定風格.此外上述參數也可作為評價標準對后續生成的音樂片段進行打分.
3 生成階段
3.1 變鄰域搜索算法
變鄰域搜索算法屬于具有通用算法構架的元啟發式算法,這類算法一般用于求解NP-難問題.變鄰域搜索算法在尋找局部最優解的迭代過程中不斷改變鄰域,算法的核心在于鄰域結構的定義.變鄰域搜索算法在音樂生成領域的相關研究極少,但由于變鄰域搜索算法的步驟與作曲工作中旋律的確定十分相似,且迭代終止條件可以與人工判別相結合,因此本文選擇變鄰域搜索算法作為音樂生成迭代算法.
在介紹變鄰域搜索算法前,首先對優化問題及其相關定理進行說明.優化問題如下式定義:
min{fi(x)}
s.t.hj(x)≤bj
(4)
式中:x∈F,F?S;i=1,2,…,m;j=1,2,…,n;S為解空間;F為解集;x為可行解;fi為目標函數;hj為約束條件函數.在音樂生成問題中,x為音符位置,S為有限空間,則音樂生成問題為組合優化問題.
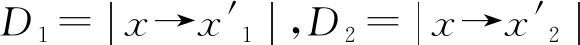
將變鄰域搜索算法移植到音樂生成系統中,需要改進的有以下部分:1)鄰域結構D(x)需要根據樂理知識事先進行規定,效果近似于常規作曲時對樂譜的修改;2)在迭代過程中,鄰域結構D(x)可人為進行改變,保證數個音符不發生變化;3)目標函數的值取最小并不意味著旋律最動聽,因此需要根據人耳試聽輔助判斷任意解x是否為局部最優解,或人工調整解的形式.
基于以上問題,本文提出的基于樂理知識的變鄰域搜索算法做出了以下改進:1)根據基本作曲知識將鄰域結構轉化為變鄰域搜索操作,包含變調、刪減音符與增加新音符三種;2)在迭代過程中可人為鎖定部分音符,改變鄰域結構;3)迭代停止條件由目標函數的計算與人工試聽進行聯合判決.
變鄰域搜索算法流程如下:
1)規定目標函數fi,根據樂理知識設計x的鄰域D(x),規定最大迭代次數km與每次迭代搜索操作;
2)隨機生成或人工輸入初始值x;
3) 隨機選取D(x)內的s個點x1,x2,xs,令滿足fi(x)最小點為中心,并可以人為固定部分音符值,從而生成新的D(x);
4)重復上述操作直至達到最大迭代次數或人工停止.
本文提出的基于樂理知識的變鄰域搜索操作包含變調、刪減音符與增加新音符三種,算法流程見圖3.每次迭代首先隨機生成搜索長度RrandL=2n,n=0,1,2、搜索起始位置RrandP∈[1,64-randL+1],與搜索操作RrandO=1,2,3,其中RrandL,RrandP共同表示鄰域區間,RrandO=1,2,3分別對應變調、刪減音符與增加新音符3種操作.當任意待處理位置有Ccell(1,i)=′1′,即被鎖定時,重新生成以上參數,隨后依照訓練參數表與RrandO對音樂片段進行處理,并計算參數矩陣KdataG4×7通過預先設定好的代價函數矩陣KdataC4×7計算得分:
SScore=∑(|KdataG-KdataN|·KdataC).
計算樂譜的變化程度后,對樂譜進行綜合打分.例如動態越高說明音符更富于變化,代價函數得分越低說明與訓練數據越接近.若此次搜索的結果在門限外,則再次重新生成RrandL,RrandP,RrandO并重復以上操作直到滿足條件為止.
樂譜的得分并不能完全反映音樂片段是否動聽,只能從一定程度上約束樂譜的生成規律.例如一個樂譜動態范圍很大,可能是旋律緊湊動人,也可能是音符雜亂無章的排列.若要保證每次迭代的代價函數得分變低,結果往往是一個或一段音符持續時間的刪減.經過多次測試后,本文設計了一個得分門限(20%),雖然迭代后的樂譜可能代價函數得分變高,但如果在門限內則保留樂譜,即保證了樂譜不至于出現過多刪減,同時也不會出現過于不和諧的音符.

圖3 變鄰域搜索算法流程圖
迭代后的樂譜通過GUI界面進行可視化顯示,操作者可通過試聽判斷樂譜中動聽的部分并進行音符的增刪與標記Ccell(n,i)=′1′,若Ccell(n,i)=′1′則在接下來的迭代中將跳過被標記的音符,隨后重復上述步驟對樂譜進行迭代,計算機迭代與人工評價與處理交互進行,直至生成令人滿意的樂譜G(i).
3.2 后期處理
生成音樂片段可保存為wav格式文件或表格文件,可用于后續的音樂生成或添加伴奏、修飾與調節速度等后期處理操作.本文提供一種根據所生成樂譜的二次折疊信息G4(j,i),i=1,…,16,j=1,…,4添加伴奏與鼓點的方法.首先根據G4(1,i),i=1,3,5,…,15確定伴奏的音符起始位置與音高,再根據G4(j,i)的二次折疊動態參數對音高進行變調,最后根據Bbpm與G4(j,i)中音符出現的位置添加鼓點.文中的主旋律、伴奏與鼓點均通過樂音模擬方法生成和選取.
4 樂音模擬
4.1 常見樂器的分析與分類
一種樂器的樂音一般由聲源經過共振腔,再經過外部環境到達人耳.本文對幾種常見樂音模擬算法(基于物理模型的弦振動仿真、基于電聲類比的共振腔模擬[11]與基于二維數字波導的樂音合成[12]等)進行分析與總結,以基于物理模型的弦振動仿真為例,可以用一個偏微分方程及其邊界條件來描述音樂信號的時間序列:
(4)
式中:t與x為時空坐標,y(x,t)為振動偏移量,E為彈性模量,T0為弦兩端的標稱張力,ρ為材料密度,A為弦的橫截面積,I為慣性矩,d1為與時間相關的阻尼,d3為與頻率相關的阻尼.式(3)的邊界條件為
y(0,t)=0,y(L,t)=0,
(5)
(6)
忽略變換求解過程,其結果為基頻與諧波的疊加.以吉他尼龍弦為例,對模型進行仿真,仿真結果的時域信號幅值較小且呈指數衰減,與實際情況類似;其頻域結果在基頻與諧波出現了較為明顯的峰值.基于電聲類比的共振腔模擬與基于二維數字波導的樂音合成等研究結果與上述結果類似,輸出結果為頻域共振峰圖.通過對常見樂器的頻域幅值與時域包絡的試聽與分析,并結合上文的研究結果,將樂器分類為弦樂器、體樂器和混合樂器3種.
4.2 樂音參數化與模擬生成
本文將樂器的發聲模式簡化為圖4所示結構.
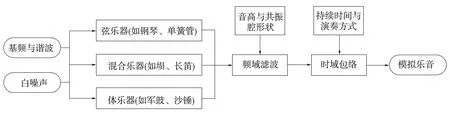
圖4 模擬樂器發聲結構
將樂音模擬分為激勵源S、頻譜F(a,f)與時域包絡A(b,t)三部分.其中若激勵源為白噪聲(對應體樂器),頻譜F(a,f)可用多個帶通濾波器組表示,若激勵源為弦振動(對應弦樂器),頻譜F(a,f)可與激勵源加權混合表示.通過根據需求確定相關參數(音高、持續時間等),并生成與現有樂器類似,或全新音色的樂音.
樂器音色模擬一個簡單的方法是通過手繪幅頻曲線對弦各次諧波振動進行加權,再通過一個表示演奏方式(如彈弦、拉弦等,或通過手繪)的時域包絡即可模擬部分弦樂器(鋼琴、雙簧管等)的音色.本文設計了一種通過跟蹤鼠標拖動路線初步確定頻率曲線,并根據不同頻率的聲波在自由聲場中的衰減(基于將聲波分解為球諧函數疊加的思想)對曲線進行加權的弦樂音生成方法,例如見圖5所示的模擬樂音鋼琴.添加的時域包絡為指數衰減的形式,對應琴弦的彈撥.也可通過高斯白噪聲加一階低通濾波器或二階帶通濾波器可模擬部分體樂器(如沙錘、軍鼓等).該過程的模型可用于接下來的樂音試聽、旋律添加樂器、伴奏和鼓點等操作,例如圖6所示的模擬樂音沙錘,帶通頻率為1 500~2 000 Hz,衰減頻率為16 Hz,18 000 Hz,阻帶衰減為10 dB,時域包絡為指數上升與指數衰減生成的模擬樂音既可表示大部分傳統樂器,用少量參數即可模擬昂貴的專業樂器,也可生成全新的時域波形,營造截然不同的聽音體驗.本小節生成的模擬樂音將用于整個音樂訓練與生成系統,隨時聽取音樂片段并進行后期處理.
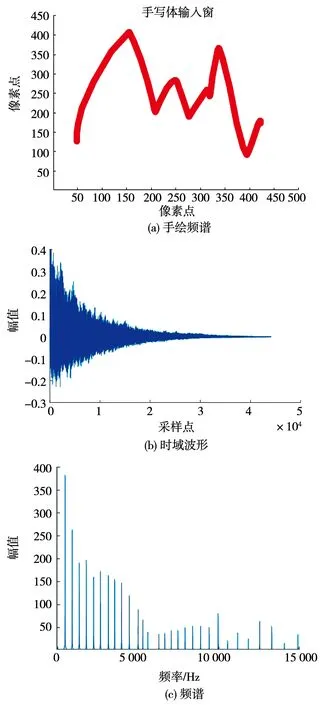
圖5 模擬樂音鋼琴特征分析

圖6 模擬樂音沙錘特征分析
Fig.6 Characteristics analysis of the simulated sand hammer sound
5 音樂生成系統測試
本次通過哼唱《致愛麗絲》的部分小節作為訓練數據,以《小星星》的前7個音符作為輸入,經過迭代與人工刪改后生成的譜表如圖7所示.圖8是上述樂譜添加模擬樂音后的時域波形圖,動態上升了18,速度不變,音符豐富度上升1,雖然代價函數得分上升了12.63%,但仍在設置的門限范圍內.該音頻已具備一定藝術性,與《小星星》的聽感完全不同.圖9是上述樂譜基于樂譜二次折疊參數添加伴奏與鼓點后的時域波形圖,相較于上述音頻更加悅耳動聽.

圖7 一次生成測試的樂譜可視化結果

圖8 樂譜添加模擬樂音后的時域波形
Fig.8 Time-domain waveform after adding simulated instrument to the music score
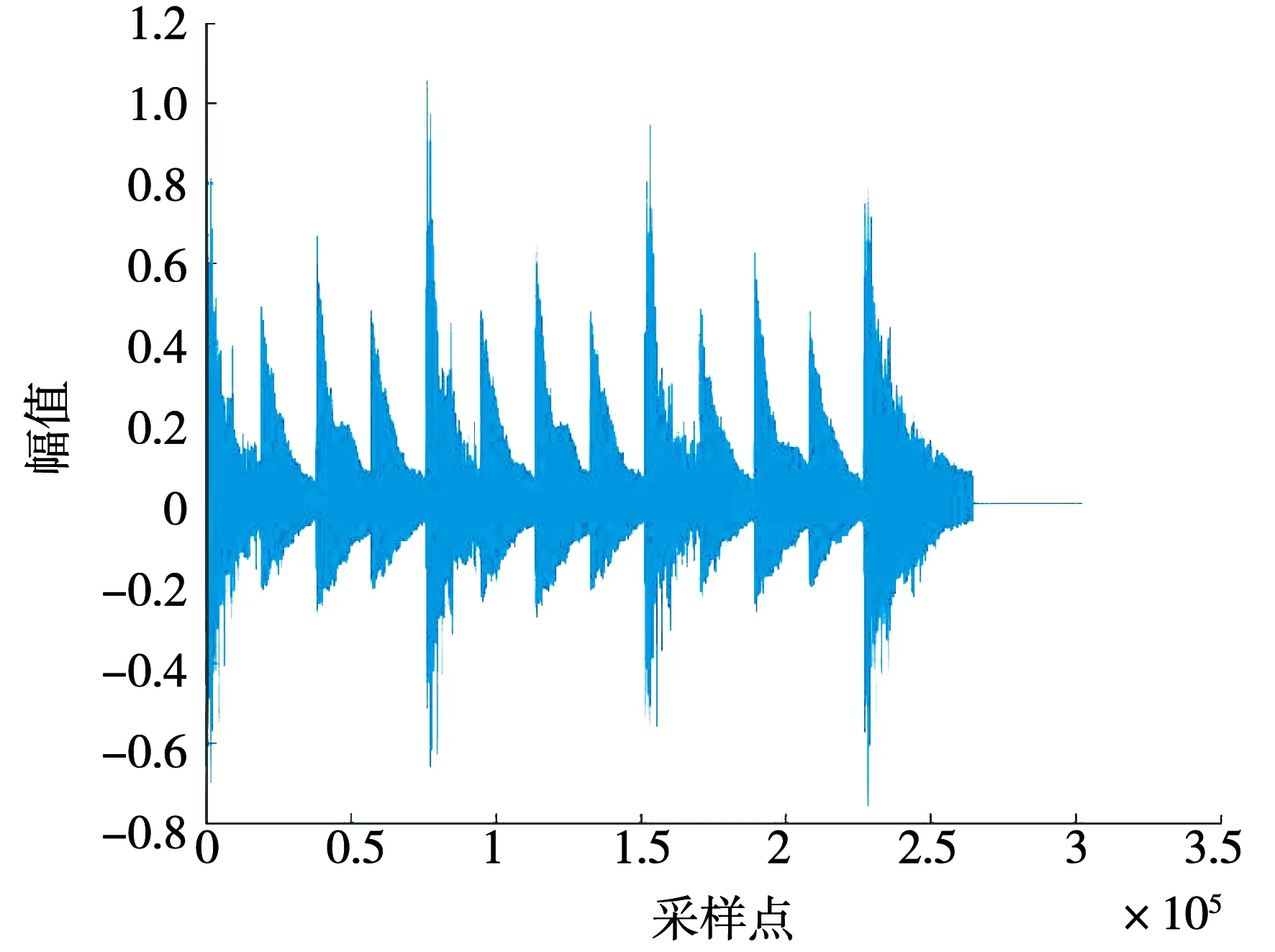
圖9 樂譜添加伴奏與鼓點后的時域波形
Fig.9 Time-domain waveform after adding accompaniment and drums to the music score
與傳統組合優化問題不同,由于生成的音樂片段具有一定藝術性,客觀評價指標只能作為音樂生成的指導,客觀評價指標得分高并不代表音樂片段悅耳動聽,因此不能完全使用客觀評價指標對生成結果進行評價,主觀聽感應作為音樂片段好壞的主要評價標準.通過對近年來提出音樂生成方法所提供的部分片段進行試聽比較[13-21],得益于生成階段的人機交互,本文提供的方法所生成片段更為動聽,此外訓練與生成過程也更為直觀新穎,便于操作.
本系統可以從易獲得的時域音頻文件出發,通過較少的操作和較短的時間獲得具有藝術感的音樂片段,能夠直觀地體驗音樂的創作過程,利于充分調動音樂愛好者,特別是青少年的對音樂的熱情,并能夠通過預先設定的參數與樂器選擇,進一步豐富音樂片段.但每次生成的持續時間較短,一般為4~10 s.
6 結 論
傳統的作曲由于需要大量樂理知識與聽音經驗,普通的音樂愛好者很難參與其中.本文所述方法克服了傳統作曲門檻過高、可重復工作量大等缺點,以及難以獲得大量專業樂器音色的缺陷,提供了一種基于變鄰域搜索與掩蔽效應的音樂生成方法,即讓普通的音樂愛好者也能參與到作曲中,同時也能通過人機交互的方式充分調動音樂愛好者,尤其是青少年對音樂的積極性,并使其投入其中.此外,基于頻域幅值與時域包絡的樂音模擬算法也克服了大量樂器難以獲得的缺陷,反之也可為樂器設計與校準提供參考.
猜你喜歡
瘋狂英語·新悅讀(2022年8期)2022-09-20 01:32:14
小天使·一年級語數英綜合(2020年3期)2020-12-16 02:56:12
文苑(2020年6期)2020-06-22 08:41:40
海峽姐妹(2019年6期)2019-06-26 00:52:50
電影(2018年8期)2018-09-21 08:00:00
藝術啟蒙(2018年7期)2018-08-23 09:14:16
兒童繪本(2017年24期)2018-01-07 15:51:37
華人時刊(2017年13期)2017-11-09 05:39:13
西部大開發(2017年8期)2017-06-26 03:16:14
東方藝術·大家(2016年6期)2016-09-05 07:30:56
