一種整合語義對象特征的視覺注意力模型
2020-02-24 09:32:50趙歆波
哈爾濱工業(yè)大學學報 2020年5期
李 娜, 趙歆波
(1.西北工業(yè)大學 計算機學院,西安 710129; 2.陜西省語音與圖像信息處理重點實驗室,西安 710129)
視覺注意力機制是人類視覺快速掃描場景后獲取高度相關信息的大腦信號處理機制.視覺注意力模型是指計算機利用視覺搜索得到的各種特征,估計人類注意力顯著信息的技術.對于許多計算機視覺任務,人類視覺注意力建模是重要的科學問題.例如,對于視頻壓縮,人眼感興趣區(qū)域(Region of Interesting, RoI)是需要重點保留的關鍵信息.對人機交互和廣告設計來講,準確了解人眼在場景中哪些信息感興趣,可以更好設計出滿足用戶需求的產品.生物認知學為人類視覺注意機制研究提供了生物學基礎[1].當人眼觀察視覺信息時,經大腦特定部位選擇性地感知的信息會在人眼視網膜的黃斑上成像.例如,功能磁共振成像(Functional Magnetic Resonance Imaging, FMRI)顯示人類大腦的梭形面部區(qū)域感知面部信息[2],大腦的旁海馬區(qū)感知地方和建筑物[3-4]信息.受認知研究啟發(fā),本文記錄并分析了人眼在觀察場景時的眼動數據,得出語義對象區(qū)域為人類關注的高意識區(qū)域,這些語義對象特征會更吸引視覺注意力.
近年來,眾多科研工作者對人眼運動進行了研究,涌現出大量基于不同理論的視覺注意力模型.一些研究人員在低級注意力模型上取得了進展.其中最有影響力的是由Itti[5]等提出的基于特征整合理論[6]的自下而上注意力模型.該理論利用顏色,方向和強度等低級特征預測圖像中吸引人眼注意的顯著區(qū)域.基于神經反應去相關的思想,Diaz等[7]提出了自適應白化顯著性模型(Adaptive Whitening Saliency, AWS).Zhang等[8]提出了自然統(tǒng)計顯著模型(Saliency Using Natural statistics, SUN),該模型將視覺特征的自身信息作為自下而上的顯著性.Torralba[9]提出了一種用于視覺搜索的貝葉斯框架用于顯著性計算.Harel[10]等提出了基于圖論的顯著模型(Graph Based Visual Saliency, GBVS).Vig等[11]利用機器學習方法計算圖像區(qū)域的顯著性.Tavakoli等[12]利用無監(jiān)督模型提取的特征用于顯著性計算.盡管這些模型表現良好,但卻忽略了語義對象特征對人類視覺注意力的吸引.
Judd等[13]和趙等[14]將低級特征和語義特征整合到了學習框架中.Kummerer等[15]和Mahdi等[16]利用預訓練的深度學習模型提取低級特征及語義特征用于顯著性預測.但是,這些模型使用的語義特征比較有限,而實驗結果表明,視覺注意力模型的性能通過語義特征的引入獲得了極大地提高.雖然這些模型使用了語義特征作為自上而下的指導信息,但提取的語義信息類別很有限.
人類感知語義信息的過程涉及了大量大腦感知神經,其過程極其復雜.然而,深度學習在圖像語義分割領域成果斐然,涌現了各種性能優(yōu)良的網絡,如(FCN[17], DeepLab系列等[18-19]),深度學習網絡本質就是人腦的仿生結構,而圖像語義分割就是計算機自動從圖像中識別并分割出對象區(qū)域,這與本文提取出在人眼觀察場景時人腦感知的語義對象特征的目的不謀而合,因此,本文將性能優(yōu)異的語義分割網絡遷移到視覺注意力模型中,來提取語義對象特征,大大增多了語義信息的類別數量.
此外,除了由人類認知控制的自上而下的視覺注意外,還有一種潛意識的機制,即自下而上的視覺注意力,吸引人眼注意一些低級特征[6].因此,本文經過分析,提取了28個吸引人眼的低級特征,除RGB顏色,亮度,強度等常見的低級特征之外,由于Lab顏色模型是基于人對顏色的感覺,所以本文同時提取了Lab顏色空間的顯著性特征.
本文利用深度學習網絡提取語義對象特征,將其與刺激人眼的低級特征通過支持向量機(Support Vector Machine, SVM)進行整合,訓練這些特征與眼動跟蹤技術獲取的真實注視點之間的映射關系,得到能預測人眼注視點的視覺注意力模型.
1 眼動數據采集與分析
為了研究普通人在觀看場景時的視覺行為,本文從用于語義分割的VOC2012數據庫[20]里帶有語義分割標簽的2 913張圖像里挑選出研究用的圖像.圖像選取時最主要的原則是圖像中語義對象尺寸不能過大,因為當語義對象尺寸占了圖像絕大部分面積時,統(tǒng)計出的眼動注視點落入語義對象區(qū)域的數量是沒有意義的.同時,兼顧數據庫語義對象的多樣性,盡可能地均衡了各類語義對象的數量,最終選擇了2 000張圖像進行研究.然后記錄人眼觀察這2 000張圖像時的眼動跟蹤數據,形成新的數據庫VOC2012-E.該數據庫用于對注視點的定量分析,并為顯著性模型的研究提供基準圖像.與其他公開語義對象分割的數據集相比,本文建立新數據集的主要動機是分析注視點信息.
本文利用Tobii TX300眼動儀記錄受試者的眼球運動,其可以進行高精度和高準確性的眼動追蹤.實驗中,為保證數據的有效性,每次只播放100張圖像,每張圖像播放5s,在播放下一張圖像前自動進行快速校準,每次采集大致進行10~15 min,共有10名受試者參與實驗.
如表1所示,本文統(tǒng)計了每張圖像的眼動注視點落入語義對象區(qū)域的總數,然后計算出落入語義對象區(qū)域的注視點占全部注視點的平均占比,數值超過83.53%,這表明語義對象特征吸引了受試者大部分的注意力.因此,為了提高視覺注意力模型預測的準確性,語義對象特征的引入意義重大.

表1 眼動注視點統(tǒng)計
如圖1(b)所示,匯總實驗中記錄的所有受試者的真實眼動注視點,疊加到原圖1(a)上,得到眼動點的分布情況.圖1(c)重點突出語義對象與眼動點分布的關系,經過進一步分析,無論目標較大的圖像(第8列圖像牛),還是目標較小的圖像(第9列圖像羊),語義對象都吸引了受試者大部分的注意力.圖d為將真實眼動注視點進行高斯濾波得到的基準圖像,用于第4節(jié)的注意力模型的訓練.
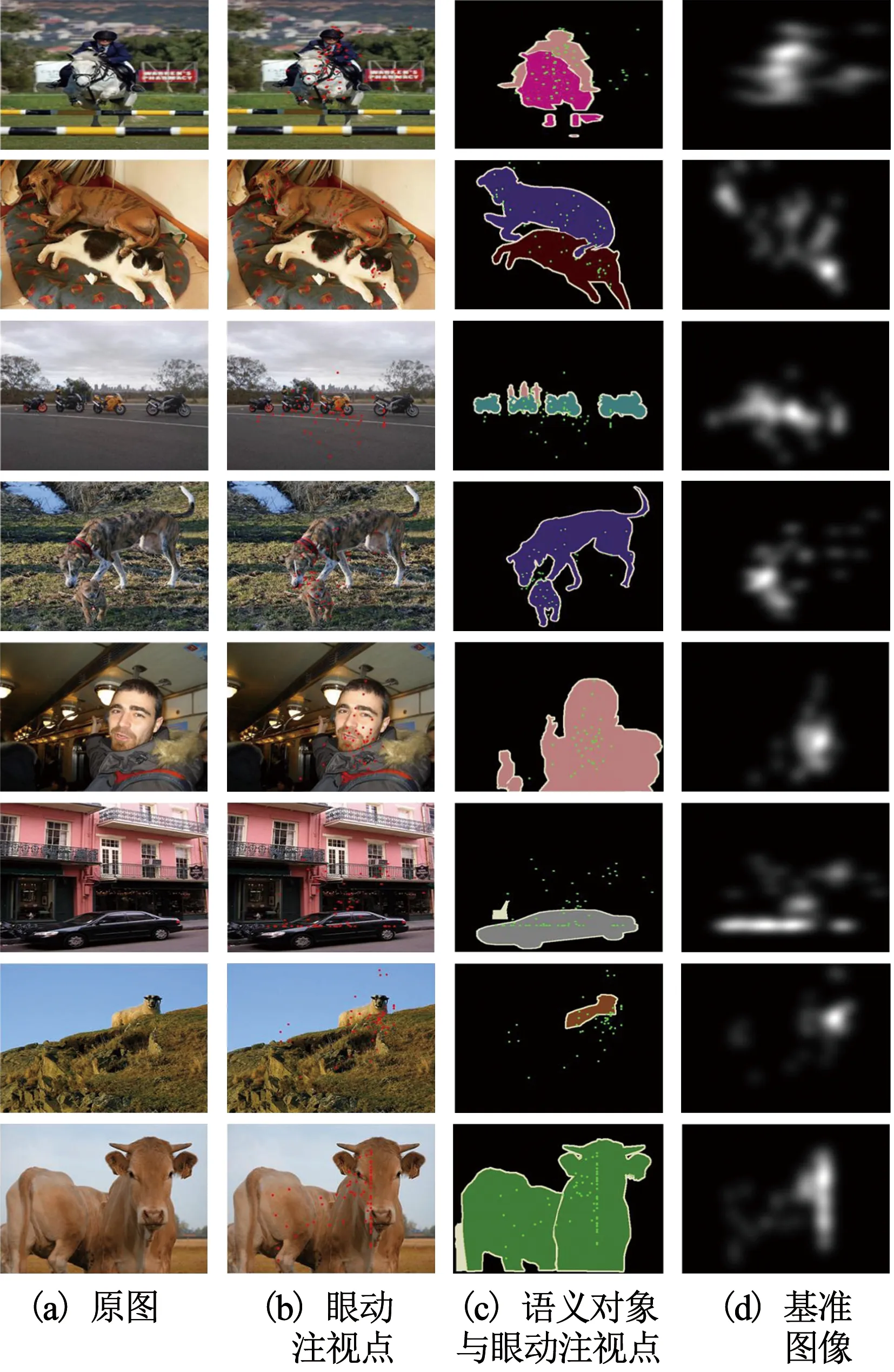
圖1 眼動跟蹤實驗
2 語義對象特征的提取
根據實驗分析得出的語義特征提取的必要性,利用FCN網絡從圖像語義分割的角度出發(fā)提取圖像的語義對象特征.與語義分割任務不同,本文提取的語義對象特征是否具有精確邊緣,并不影響視覺注意力模型的預測人的注視點,但特征提取的時間和硬件成本卻對視覺注意力模型的訓練至關重要.因此,綜合比較了常見語義分割模型,本文利用綜合性能最好的FCN-8s網絡提取語義特征,同時為了保證特征提取的魯棒性和有效性,對其進行了改進:采用了參數線性整流(Parametric Rectified Linear Unit, PReLu)函數取代了線性整流函數(Rectified Linear Unit, Relu);使用適應性矩估計(Adaptive monent estimation, Adam)優(yōu)化網絡的學習率.
圖2為本文利用的FCN-8s的網絡結構.在本文使用的網絡結構中,在卷積之后不再使用Relu激活函數.雖然Relu激活函數由于自身只有線性關系,收斂速度很快,但是當輸入為負數時,Relu的輸出被設為0,導致對應權重無法更新,即該神經元壞死,將會對任何數據都無法響應.為解決這一問題,本文采用PReLu激活函數,其計算公式如下
(1)
式中:a的取值是在0~1之間變化的數,i為不同的通道.如式(1)所示,與Relu函數不同的是,當PReLu的輸入為負數時,它的輸出非0,從而避免了神經元壞死,而且PReLu只增加了很少的參數,所以只增加了很少的網絡的計算量.
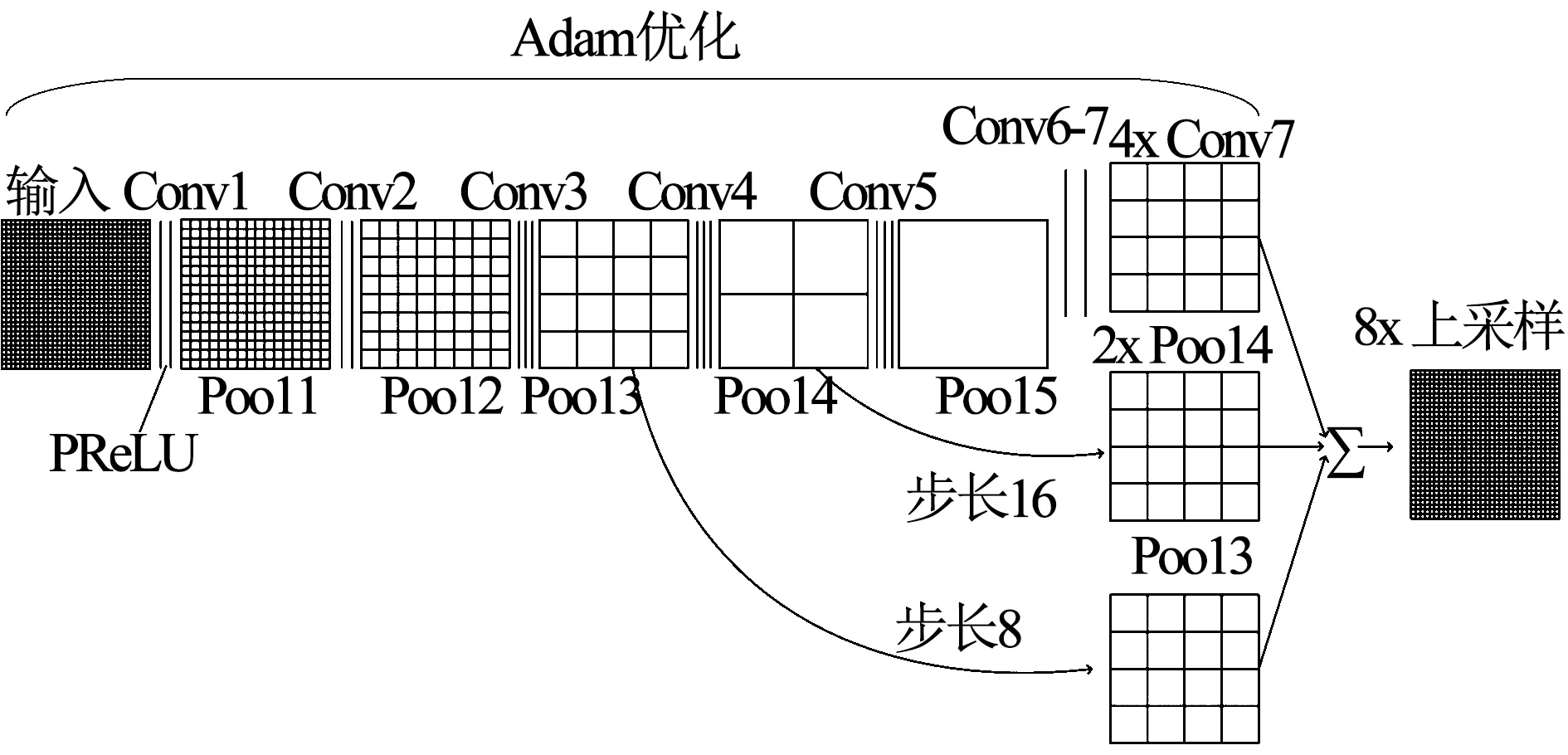
圖2 本文使用的FCN-8s網絡結構
此外,在網絡的訓練過程中,本文不再采用梯度下降優(yōu)化算法,而是利用Adam優(yōu)化算法調整網絡更新權重和偏差參數.梯度下降法雖然是最常用的優(yōu)化算法,但是為其選擇合適的學習率比較難,學習率太小會導致網絡收斂過于緩慢,而學習率太大可能會影響網絡收斂.而且不同特征應采用不同的更新率,比如,出現頻率較小的特征,應有更大的更新率,但是梯度下降法的學習率是固定的.而Adam優(yōu)化算法可以為每個特征計算自適應學習率,同時改進了梯度下降法的缺點,如學習率消失、收斂過慢等.在本文提取語義特征的實際過程中,Adam優(yōu)化算法效果良好,收斂速度比梯度下降法更快,使特征提取更為有效.圖3為本文改進后的FCN-8s架構提取的語義對象特征FS示例.圖3(a)為原圖,圖3(b)為提取的語義對象特征,圖3(c)為人工標記的語義對象.
3 低級特征的提取
人類的早期視覺通路會利用視網膜及初級視覺皮層提取如強度,顏色和方向等若干低級特征.因此為提高視覺注意力模型的性能,本節(jié)經過反復實驗及結果比較,選取了包含了28個低層特征的特征集FL={f1,f2,…,f28}:圖4中(1)~(13)圖為13個亮度特征,其通過金字塔濾波器對3尺度的多分辨率亮度圖像進行4方向的濾波得到;圖4中(14)~(16)圖為利用ITTI[5]模型計算得到的顏色,強度,方向3個特征;由于Lab顏色模型是基于人對顏色

圖3 本文利用改進的FCN-8s提取的語義對象特征

圖4 28個低級特征
的感覺,因此本文利用FT[21]模型提取Lab色彩空間特征(圖4中(17)圖);圖4中(18)~(23)圖為計算紅、綠、藍三顏色通道值及概率值,分別得到的3個色度特征及3個色度概率特征;圖4中(24)~(28)圖為利用中值濾波器對6尺度的彩色圖像進行濾波,并計算三維色度直方圖而得到的5個色度直方圖特征.
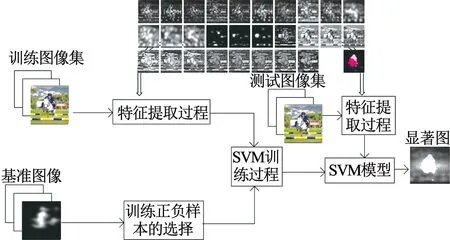
圖5 視覺注意力模型訓練過程
4 視覺注意力模型的訓練
提取語義對象特征FS和低級特征集合FL之后,得到本文提取的特征集合F={FS,FL}.為獲取提取的特征集F與本文構建的VOC2012-E數據庫里記錄的眼動追蹤數據的映射關系,本文引入機器學習理論,利用非線性分類器模擬人腦神經系統(tǒng)的非線性映射.在統(tǒng)計學習理論中發(fā)展起來的SVM方法是一種通用學習方法,其在非線性分類應用中有非常好的表現.因此,本文利用SVM理論,訓練得到每個特征與視覺注意力之間的關系,并在訓練過程中,本文基于特征整合理論對特征集合F里的特征進行并行處理[5],最后利用訓練得到的映射關系生成視覺顯著圖.
具體地,訓練過程中,取樣本集S?T,T為基準圖像的訓練集.樣本s∈S.令
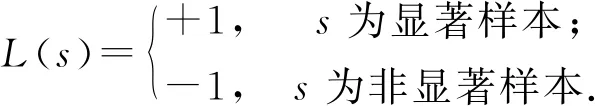
設P為基準圖像的像素集,P={p1,p2,…,pN},N為基準圖像中像素的個數.O(pi)表示像素的顯著度,i=1,2,…,N. 對像素集P進行排序得到有序集合Po={po1,po2,…,poN},其中O(po1)≥O(po2)≥…≥O(poN).在利用SVM模型進行訓練時,本文選擇Sp?S作為正樣本,Sn?S作為負樣本,其中Sp={po1,po2,…,pom},m=0.05N,Sn={pol,pol,…,poN},N-l=0.3N,最終預測出顯著圖,訓練過程的流程圖如圖5所示.
5 實驗及結果分析
為評測本文視覺注意力模型的性能,將其與8種經典的視覺注意力模型在VOC2012-E數據庫上進行比較,這8種模型分別是AIM[22],AWS[7],Judd[13],ITTI[5],GBVS[10],SUN[8],STB[23]和Torralba[9],然后在MIT300測試數據集上在線測試性能, 除以上8種模型之外,本文模型同時與4種先進的視覺注意力模型在MIT300數據庫上相比較,這4種模型分別是eDN[11],UID[12], Deep Gaze2[15], DeepFeat[16].評價函數選取受試者工作特征曲線下面積(Area Uner Curve, AUC),線性相關系數(Correlation Coefficient, CC)及歸一化掃描路徑顯著性(Normalized Scan Path Saliency,NSS). AUC是度量視覺注意力模型預測出的顯著圖與基準圖像的差異的一個評價函數,通常,AUC的值介于0.5~1.0之間,AUC越大,模型的表現與基準圖像更相近.CC用來衡量視覺注意力模型預測的顯著圖與基準圖像的線性相關性. NSS為人眼凝視位置在模型輸出顯著圖上的歸一化顯著值為
(2)
(3)
式中:S為模型的輸出顯著圖,σs和μs為模型輸出顯著圖上的均值與標準差.
圖6為9種模型預測顯著圖的實驗結果圖的示例,輸入圖片來自于VOC2012-E數據庫.從實驗結果可以看出,與其他8種模型相比,本文預測的顯著圖中語義對象特征是高顯著性的,這說明本文提出的視覺注意力模型顯然更接近于人類視覺認知.
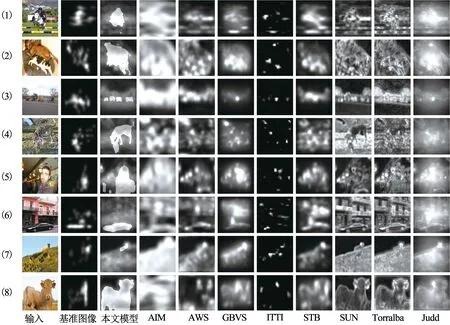
圖6 視覺注意力模型預測的顯著圖對比
表2為9種模型在VOC2012-E數據庫上的評價函數結果比較.從表2可以明顯看出,三種評價函數AUC,NSS和CC評價結果都表明本文模型性能優(yōu)于其他模型.本文模型的AUC值最高(0.823),其次是Judd(0.822)和GBVS(0.810),而ITTI模型的AUC值僅為0.531,這意味著本文算法與其他模型相比,更接近于基準圖像.本文模型的NSS值為1.360,其次是GBVS (1.263)和Judd (1.242),而STB模型的NSS值只有0.399,在9種模型中最低,僅為本文模型的1/4.本文模型的CC值(0.557)也最大,而CC值越高,注意力模型預測的顯著圖與注視點之間的相關性越高.因此,本文模型預測的顯著圖更接近于人眼注視點,這是因為本文模型的提出是受人類自由觀察自然場景的感知過程的啟發(fā),在模型訓練過程中融合了語義對象特征和典型的低級特征.
此外,為了進一步評估本文提出的模型,本文在公開數據庫MIT300進行評測,該數據庫包含了9個受試者觀察300張自然圖像時人眼注視點的基準數據,評測結果如表3所示,除了前文比較的8種模型之外,同時比較了4種先進的模型:Deep Gaze2及Deep feat同樣整合了高級特征與低級特征;eDN同樣利用SVM整合特征;及無監(jiān)督模型UID.
根據表3結果,AUC最高值為Deep Gaze2模型(0.84),而本文模型的AUC值與GBVS,Judd, eDN及DeepFeat模型的AUC值相近,但是本文模型的NSS值(1.27)在12種模型中最高,而且本文模型的CC值與DeepFeat模型的CC值并列最高(0.49).其中,整合了同樣高級特征與低級特征的Deep Gaze2模型與Deep feat模型與本文模型總體表現最優(yōu),而本文模型略勝一籌,這說明了本文整合語義特征的先進性.雖然同樣利用SVM整合特征的eDN模型的NSS值較低(1.14),但其AUC值與本文相同,CC值也較高,說明了本文利用SVM整合特征的有效性.因此本文模型在MIT300數據庫上性能表現良好,可以有效地預測人眼注視點.

表2 9種模型在VOC2012-E數據庫上的實驗結果比較

表3 12種模型在MIT300數據庫上的實驗結果比較
6 結 論
本文提出了一種整合了語義對象特征的視覺注意力模型.通過建立眼動跟蹤數據庫VOC2012-E,研究并記錄普通人在觀察自然場景時的眼動數據,經過分析得出語義對象特征在吸引人們的注意力時有重要作用.然后,受語義分割啟發(fā),利用深度學習網絡FCN-8s提取語義對象特征,同時用激活函數PReLu,優(yōu)化函數Adam改進網絡使其更有效地提取的語義對象特征.接著,提取在人類潛意識層吸引人注意力的如方向,顏色,強度特征等28個低級特征.最后訓練機器學習分類器SVM將之前提取的語義對象特征及低級特征映射到人類視覺空間,訓練后的模型可以預測自然場景的人眼視覺顯著圖.經過在VOC2012-E及MIT300數據庫的測試,與其他8種經典模型及4種先進模型相比,本文提出的視覺注意力模型性能更好,更符合人類觀察圖像時的視覺習慣,即語義對象高顯著.
猜你喜歡
汽車實用技術(2022年7期)2022-04-20 11:44:42
載人航天(2021年5期)2021-11-20 06:04:32
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
外語學刊(2016年4期)2016-01-23 02:34:15
大連民族大學學報(2015年2期)2015-02-27 08:28:11
出版與印刷(2014年4期)2014-12-19 13:10:39
