一種基于關聯挖掘的服務一致化配置方法
2020-01-09 03:48:32劉紹華蘇林剛張文博
計算機研究與發展 2020年1期
王 燾 陳 偉 李 娟 劉紹華 蘇林剛 張文博
1(計算機科學國家重點實驗室(中國科學院軟件研究所) 北京 100190)2(中國科學院軟件研究所 北京 100190)3(北京工業大學 北京 100124)4(北京郵電大學 北京 100876)
服務化軟件系統通常由許多異構服務組件構成,每個服務組件都有許多配置項.例如,MySQL 5.6數據庫服務器有461個配置參數,Apache 2.4的所有模塊中有超過550多個配置參數[1].服務組件規模巨大以及多層軟件棧結構導致實際系統中通常包含成千上萬的配置項,使得系統正確配置困難且易于出錯.配置錯誤已經成為當今系統故障的主要原因之一[2].微軟、亞馬遜和Facebook等主要IT公司都經歷過配置錯誤所導致的宕機事件[3-5].在配置錯誤中,配置項關聯性(簡稱關聯性)引起的錯誤占很大比例.研究表明,12.2%~29.7%的錯誤與配置關聯性有關[6].
部分關聯性由服務組件之間的依賴關系引入.例如服務組件需要進行數據庫訪問,那么,服務的數據庫連接配置項需要與數據庫信息關聯,即服務與數據庫的數據庫名稱、用戶名和密碼等參數值必須保持一致.研究報告表明,開源軟件項目中有27%~51%的配置項和另一個項目存在關聯性[7].然而,分析配置項關聯性,特別是跨服務組件關聯性,非常困難.首先,關聯配置可能會跨多個服務組件,每個服務組件存在大量配置項,分析配置信息的工作量巨大;其次,眾多服務組件,尤其是開源軟件倉庫中的軟件,文檔可能與代碼不一致,甚至沒有文檔[8];最后,服務組件使用多種編程語言,因而難以使用程序分析方法[9].即便是領域專家也很難擁有跨多種服務組件和軟件的知識[10],而一旦忽略了一些配置項的關聯性,就可能會違反配置約束,從而導致系統錯誤.
本文提出了一種基于關聯挖掘的服務一致化配置方法.首先,從開源項目的代碼庫中爬取配置文件的樣本數據,將搜索范圍縮小到更改頻繁的配置項;然后,根據配置項名稱、取值比較和類型推斷計算每個配置項對的關聯系數,并且提供濾波器以確定可能關聯的配置項候選集合;最后,輸出配置項關聯性的排序列表,以便系統管理員重點關注一些配置項,并可以通過查詢操作檢查系統配置,從而減少配置錯誤所導致的系統錯誤.進而,挖掘配置項的關聯性,并且在召回率、準確率等方面對方法的有效性進行了實驗評估.實驗結果表明,所提出方法可以準確分析配置項的關聯性,討論了過濾器對最終結果的影響、關聯性配置的分布、產生錯誤的原因等問題.
本文的主要貢獻為:通過代碼倉庫挖掘與配置文件比較,評估配置項的關聯性,從而為實現大規模分布式軟件的自動化、智能化配置部署及錯誤診斷建立基礎.與文獻[7]相比,所提出方法無需掌握目標軟件的系統架構、軟件組件、交互行為、部署項含義等面向系統運維的用于部署配置的特定領域知識.可自動檢測配置項的關聯性,以有效減少系統配置并診斷配置錯誤的工作量.并且,搭建了典型的開源軟件系統,基于準確性與召回率對方法的有效性進行了實驗評價,分析討論了過濾器對最終結果的影響及相關性配置的分布,比較了現有工作,并結合實驗結果分析導致錯誤的問題原因.
1 研究動機
配置項關聯是指在跨服務組件的軟件系統中,某個服務組件的一個配置項依賴于其他配置項或環境對象[11].當一個配置項改變時,與之關聯的配置項都需要作出相應修改.例1中的MySQL和Tomcat的配置項具有關聯性,關聯語義約束了Tomcat可以使用的持久連接數量mysql.max_persistent不能大于MySQL提供的總量max_connections,違反約束就會發生過多連接錯誤;例2中的Web服務組件LogineService與EJB服務組件LoginEJB的配置項“jndi-name”關聯,關聯語義約束這2個配置項具有相同的值,否則應用程序將發生登錄失敗.
例1.MySQL和PHP的配置關聯.
MySQL配置文件:
max_connections=300.
PHP的配置文件:
mysql.max_persistent=400.
約束:在使用持久化連接的時候,PHP中mysql.max_persistent值應該不超過MySQL中max_connections的值.
影響:引發“too many connections”錯誤.
例2.應用組件間的配置關聯.
Web 服務LoginService的配置文件:
EJB組件LoginEJB配置文件:
約束:LoginService中的jndi必須和LoginEJB中的jndi-name保持一致.
影響:無法登錄應用,拋出異常.
檢測配置項關聯性以及約束條件,對于保障系統配置的正確性至關重要.在部署、遷移和更新系統時,違反約束就會出現配置項錯誤,從而導致系統故障.如果事先獲知配置項間的關聯性,當某個服務組件更新造成配置信息改變時,管理員就可以對其他服務組件的配置信息做相應修改,從而減少錯誤的發生.同時,當系統出現故障時,管理員可以重點關注關聯配置項,縮小配置錯誤檢查的范圍,從而降低系統故障風險并且減少人力投入.
為了確定跨服務組件配置項的關聯性,研究了有代表性的開源軟件,包括關系型數據庫MySQL(1)https://www.mysql.com、應用服務器Tomcat(2)http://tomcat.apache.org、內存數據庫Redis(3)http://redis.io等.通過對這些軟件特征的分析,發現了3種現象:
1) 如果2個服務組件相互依賴,可能存在跨服務組件的配置項關聯性.服務組件依賴通常以資源供給、函數調用、數據共享和數據傳輸等方式實現.例1是資源持久連接所產生的關聯性,例2是函數調用所產生的關聯性.
2) 配置項根據其鍵值對的語法可分為不同的類型.常見的3種配置項類型是數字、布爾值和字符串[8],可以根據配置項中鍵值對的語法模式推斷其語義.例如,“max_connections=300”是數字類型的配置項,可以根據推斷出其表示的是資源(即最大連接數)數量.最典型的是字符串類型的配置項,例如在MySQL中,“datadir=varlib”可以推斷為指定的文件路徑.
3) 盡管服務組件具有大量配置項,但只有小部分經常使用.文獻[1]研究表明,大多數用戶只設置了一小部分配置項(6.1%~16.7%),而高達54.1%的配置項使用默認值.還對開源軟件Redis進行具體研究,例如從Github(4)https://github.com中多個項目中抓取60個Redis的配置文件并分析其配置項值,發現在38個配置項中只有5個配置項(即13.2%)的值經常變化,而其他的配置項(即86.8%)只有5個以下不同的值.表1給出了Redis經常變化的配置項.
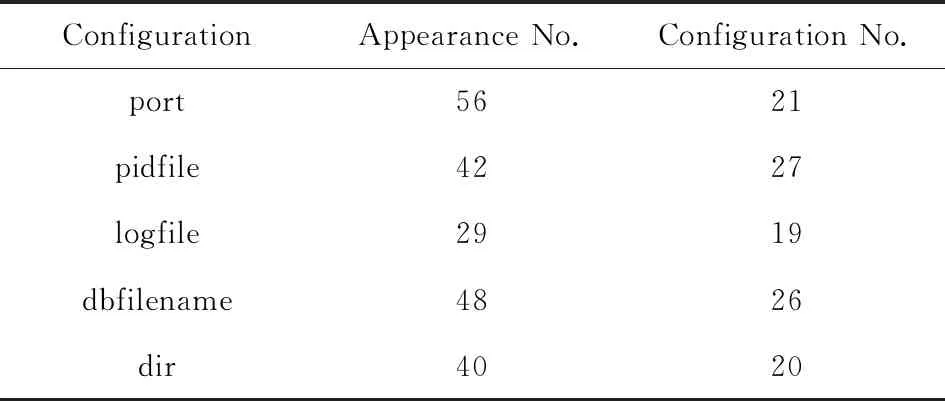
Table 1 Configuration Change List表1 配置項數量列表
基于觀察發現:1)通過分析配置項的鍵和值信息,可以推斷語義信息;2)通過分析配置項類型,可以推斷其表示的對象與特征.因此,根據對配置項鍵、值和類型的分析,提出基于關聯挖掘的服務一致化配置方法.
2 服務一致化配置方法
2.1 方法概述
方法技術路線如圖1所示,主要包括配置項過濾、配置項類型推斷、關聯系數計算、過濾配置關聯性、配置項關聯性排序等5個步驟.
1) 配置項過濾.通過互聯網使用爬蟲技術從代碼倉庫(如Github)中抓取開源軟件(如Redis)的配置文件作為樣本數據,過濾掉幾乎沒有變化的配置項以縮小搜索范圍,并關注那些頻繁修改的配置項.在相同配置項的多個例集合里,通過配置值變化數量的絕對值和比例值來判斷,比如少于5個不同值、少于5%.
2) 配置項類型推斷.將配置項的鍵值對與定義的正則表達式及關鍵字相匹配,可以推斷其類型.
3) 關聯系數計算.根據配置項的關鍵字、值和類型等特征,計算不同服務組件的每對配置項的關聯系數.
4) 過濾配置關聯性.基于關聯系數過濾非關聯配置對,將過濾結果作為確定關聯性的依據.
5) 配置項關聯性排序.將根據關聯系數排序的關聯配置項對的列表提供給用戶,以供參考檢查或修改系統配置.
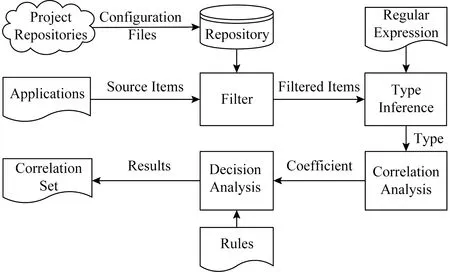
Fig. 1 Approach overview圖1 技術路線
2.2 配置庫構建
從在線技術論壇和代碼托管網站,包括Server-Fault(5)http://serverfault.com,StackOverflow(6)http://stackoverflow.com,Database Administrators(7)http://dba.stackexchange.com,Github中,抓取流行開源項目(例如Web服務器、數據庫、消息中間件)的配置文件例.
方法針對具有大量配置項的系統軟件作為目標軟件,找到經常會發生變化的常用配置項.以Github為代表的開源軟件倉庫積累了大量軟件項目,其中很多軟件需要使用諸如數據庫、消息隊列等類型的系統軟件,存在眾多配置文件,從而能夠支持方法對常用、常變配置項的識別.方法能夠適用于以配置文件進行設置的系統軟件.當然,方法的適用性受能夠收集到的配置使用信息影響,因此對于廣泛使用的常用軟件具有更好的適用性.
建立配置庫以檢測配置項關聯性包括3個步驟:1)確定目標系統及相關軟件以限定分析對象(如數據庫、消息中間件等).2)從Github庫的項目中搜索相應的軟件配置文件.3)檢測相關組件配置文件中配置項的關聯關系.以典型的3層架構企業應用為例:1)目標系統為企業應用,包括表現層、業務邏輯層、數據訪問層.2)從Github庫的項目中搜索表現層和業務邏輯層、業務邏輯層和數據訪問層的相關軟件.表現層典型軟件為Apache,Lighttpd,Nginx;業務邏輯層典型軟件為Tomcat,Jetty,JBOSS;數據訪問層典型軟件為MySQL,PostgreSQL,InterBase.3)基于同類型軟件集合建立配置倉庫,挖掘不同類型軟件組件間的關聯關系.
基于同類型軟件集合重點分析以擴充配置倉庫,重點分析開源軟件倉庫中相關軟件的配置文件,可以提升方法的針對性與應用效果.同時,構建配置項庫過程中,每個軟件和工具的配置項例數量是一個逐漸累積的過程,且數量越多,對于發現經常修改的配置項集合以及常用取值,尤其是系統軟件的數值型配置項,起到促進作用.例如,從Github上找到了超過100個Redis的配置文件來構建實驗所用的Redis相關配置項庫.
對樣本數據進行統計分析,獲取每個配置項的例值,提出2個過濾規則以獲取配置項的頻繁項集.
1) 多值過濾.如果配置項例在樣本數據集中的值有較大差異,則該配置項為頻繁項.例如表1中的端口為Redis的監控端口,不同服務組件的端口值通常不同,收集了56個端口配置項例,其中的21個具有不同的值.
2) 異值過濾.如果樣本數據中沒有出現目標系統中的配置項例值,則該配置項為頻繁項.這是由于在特定服務組件中,某些配置項可能配置為樣本數據中未出現的特定值,例如配置項中設置文件路徑、用戶名和密碼.
2.3 配置項類型推斷
配置項類型通常包括數值型、布爾型和字符串型,每種類型可能具有多個子類型.例如Redis的“pidfile”表示文件路徑,“bind” 表示IP地址,二者都是字符串類型配置項.推斷配置項類型有助于獲取其語義.配置項值與每個正則表達式匹配,遵循3個規則:
1) 如果配置項類型是數字或布爾類型,則配置項的值幾乎沒有語義信息.例如Redis的“port”表示監聽端口號,“timeout”表示超時的時間,二者都是數字類型配置項.如果僅僅根據配置項的值,則沒有屬性及特征信息,配置項名稱需要用其他正則表達式和關鍵字表示.
2) 如果配置項類型和子類型都被推斷出來,則使用更具體的類型來描述配置項.例如“IP Address”(服務器的IP地址)既是定義的IP類型,又是字符串類型,那么將該配置項設置為IP類型.
3) 使用關鍵詞可以推斷出多個子類型.例如“jdbc.pool.maxIdle”表示數據庫連接資源上限,是數字類型配置項.配置項名稱中“jdbc.pool”可以推斷為Resource類型,而“maxIdle”可以推斷為Size類型.
每個配置項的推斷類型以類型向量表示:Tentry=(t1,t2,…,tm),其中,ti(1≤i≤m)表示一種配置項類型,當配置項屬于此類型時,ti=1,否則ti=0;m表示配置項類型數量,向量長度固定.由于一個配置項可以同時具有多種推斷類型,向量中可能有多個元素的值為1.表2給出了典型配置項類型描述,同時配置項類型是可擴展的以適應新的類型、正則表達式和關鍵字.
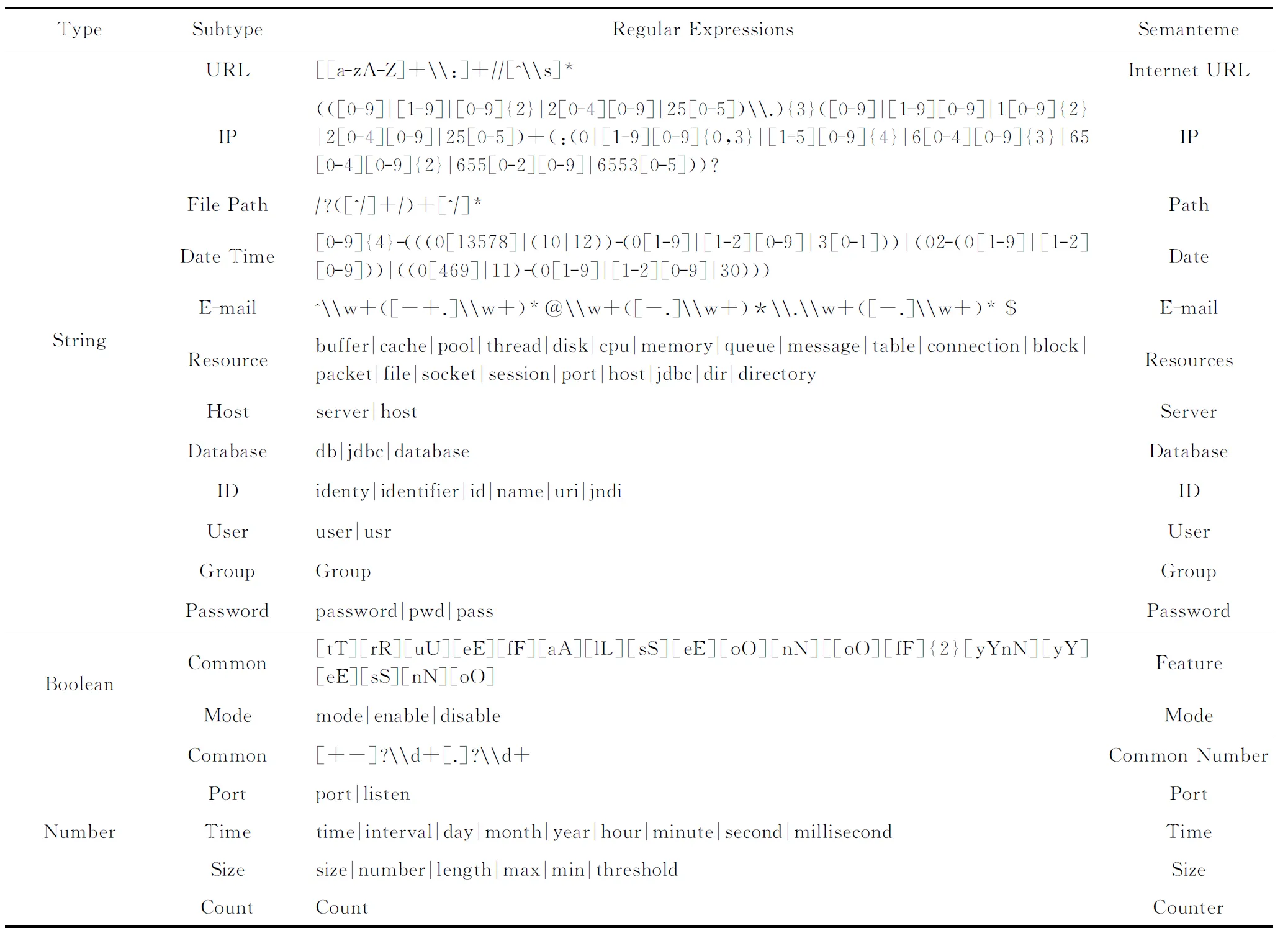
Table 2 Configuration Type Description表2 配置類型定義
2.4 關聯系數計算
將配置項關聯性分為一致關聯性和類型關聯性.
1) 一致關聯性
一對配置項具有相同值,或者一個值是另一個值的子串,在配置項關聯性中最為常見,可以用一致關聯性系數衡量.2個配置項之間的一致關聯性系數基于關鍵字、值和類型計算.這是由于如果2個配置項關聯,其值相同或者相似.同時,由于配置項具有相似語義,關鍵字和類型也相似.
一致性關聯是通過取值來推測2個配置項可能描述的是同一個對象,由于關注的配置項都是采用key,value形式存儲,很難主動識別參數值的數據類型.例如,密碼可能是“123456”,也可能是“qwe123”等,因此,統一作為字符串類型處理具有更好的通用性.所提出方法根據表2將值抽象化為正則表達式,正則表達式能夠表達值的數據結構和類型,因此計算最長公共子串用來衡量值的數據類型和類型的相似度.
給定配置項ei=ki,vi,Ti,其中,ki為配置項ei的關鍵字,vi為ei的取值,Ti為類型向量.計算關鍵字、取值和類型之間的相似性,然后將這些相似性的平均值作為一致關聯性系數.
基于“最長公共子串”方法計算配置項ei與ej的鍵和值的相似度為
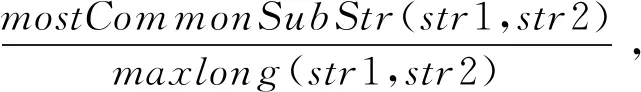
(1)
其中,函數mostCommonSubStr(str1,str2)表示字符串str1和str2的公共子串,maxlong(str1,str2)表示字符串str1和str2的較長字符串長度值.
基于余弦計算類型向量Ti和Tj相似度為
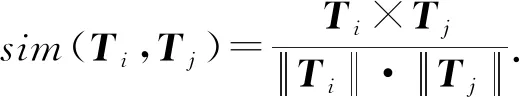
(2)
將配置項對ei與ej的鍵、值、類型相似度平均值作為一致關聯性系數:
consis(ei,ej)=α×sim(ki,kj)+β×sim(vi,vj)+γ×sim(Ti,Tj).
(3)
相似度取值范圍為[0,1],分數越高,配置項對存在一致性的可能性越高.對開源軟件的例分析,發現以上3個相似度對最終結果的影響差別不大,因此采用均值計算總的關聯系數.在未來的工作中,將進一步研究是否采用加權均值方式可以改進方法的效果.
2) 類型關聯性
如果一個配置項的值改變了,另一個配置項應該變為相應的值,而不一定是相同的值,在大多情況下,可以從配置項類型中推斷出來.例如Resource類型配置項與Size類型的配置項關聯,即后者設置了前者所表示資源的數量.再如URL和IP這2種類型通常相互關聯.
“一致關聯性”是不同配置項在表示同一個對象時,取值要保持相同或部分相同;而“類型關聯性”是不同配置項存在語義關聯,當一個發生變化,另一個也需要隨之改變.例如用戶名和密碼就是關聯類型.“一致關聯性”中的“類型”是字段的數據類型,如數字型、布爾型、字符串等;“類型關聯性”是某配置項的值隨其他配置項做相應變化.
定義了配置項類型之間的共性關系,其中每種關系都隱含著2種實體之間的語義.通用類型關聯以系統部署和運維管理的領域知識為基礎,描述配置項之間的語義關聯,類型關聯包括:1)用戶信息,包括用戶名密碼郵件地址;2)主機信息,包括IP地址端口URL主機名;3)文件信息,包括文件名稱用戶組別訪問權限.例如,對于數據庫系統,數據庫名稱和數據庫IP地址以及用戶名和密碼是類型相關的,當數據庫變化,對應的IP地址和用戶名密碼也可能發生變化.再如,FilePath,User表示這2種類型的配置項因權限而關聯,而Host,IP表示主機配置項具有此IP地址.另外,用戶也可根據領域知識自行設置類型關聯規則.
類型關聯分數correl(ei,ej)用于評估配置項類型關聯性,首先計算2個配置項(ei,ej)的類型向量(ti,tj)之間的各類型關聯的數量,而后將值歸一化為范圍為0到1之間:

(4)
當ti與tj關聯時,corrVal(ti,tj)=1,否則為0.配置項對(ei,ej)的一致關聯性和類型關聯性是配置項對的2種不同的相似性ei和ej,當consis(ei,ej)增加,那么correl(ei,ej)則隨之減少,反之亦然.
2.5 配置項關聯性確定
根據2.4節的方法,可以檢測到眾多配置項對之間存在著關聯性,為了保證結果的正確性,本節提出多個過濾規則以去除錯誤的關聯性結果.
1) 閾值過濾.為配置項一致關聯性設定閾值Hc,為配置項類型關聯設定閾值Ht,當關聯性系數小于閾值,則2個配置項之間的關聯關系較弱,過濾掉該配置項對.
2) 冗余過濾.觀察發現,一個服務組件的配置項ei很少會與另一個服務組件的多個配置項關聯.因此,如果1個配置項在由2個服務組件組成的配置項對中出現了3次以上,僅將關聯系數最高的3個配置項對作為關聯配置項,過濾掉其他配置項對.
3) Top-K過濾.根據配置項對的關聯性系數按降序排序,得到一致關聯性和類型關聯性2個關聯性排序列表,將2個列表中的前K個配置項對作為關聯配置項對.
使用以上3個過濾規則,將關聯性較低的配置項對過濾掉后,可以得到配置項一致關聯性列表和類型關聯性列表的并集作為最終候選列表.
3 實驗評價
3.1 實驗環境
使用服務化Java應用系統Adventure和基于云的存儲服務CloudShare(8)http://www.aliyun.com等2個典型的開源軟件系統以評估所提出方法,表3給出了2個實驗系統的服務組件.
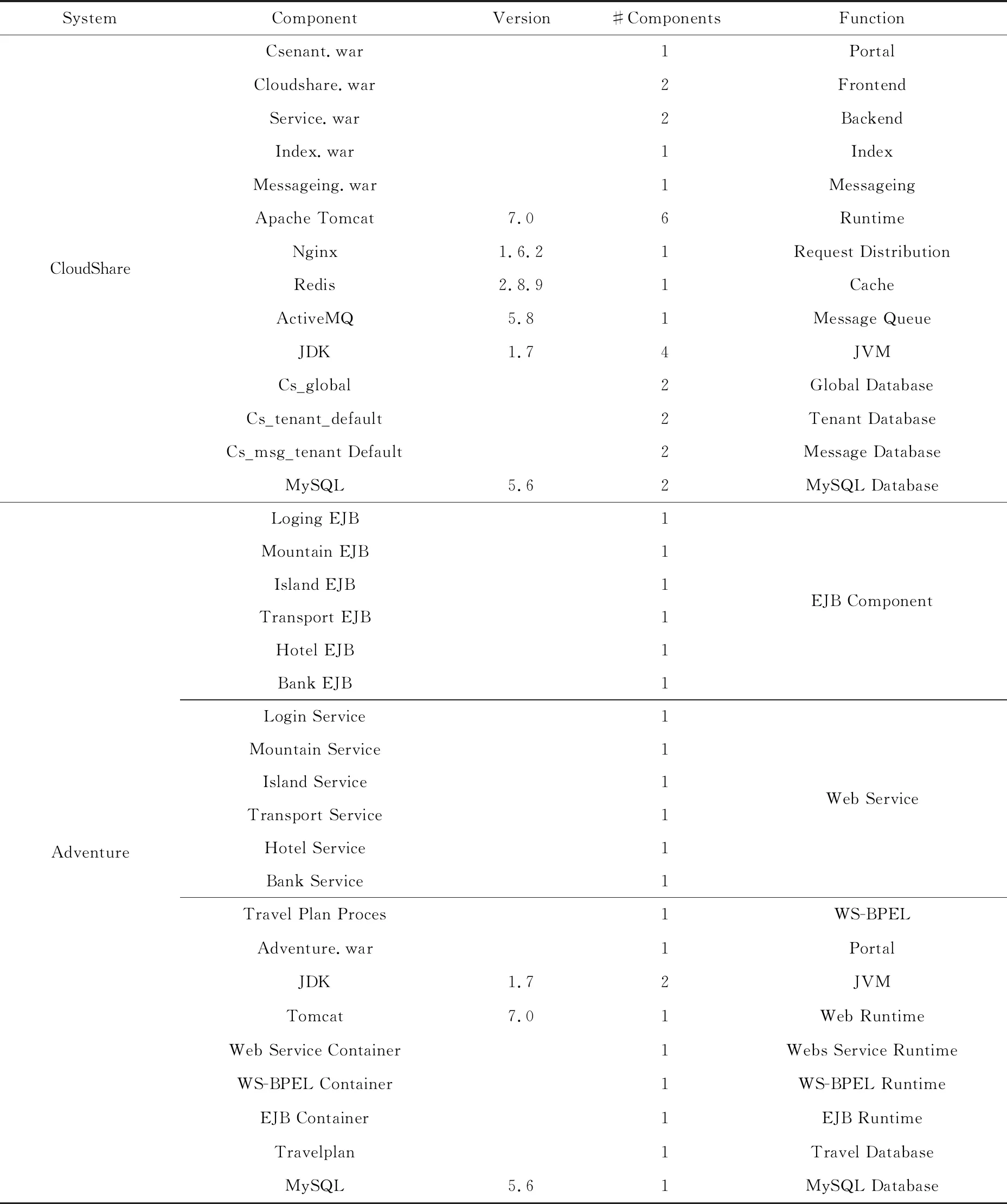
Table 3 Experimental Service Components表3 實驗系統服務組件
Adventure是提供旅游安排服務的應用,采用SOA(service oriented architecture)框架,具有Web services, WS-BPEL(Web services-business process execution language),EJB(enterprise Java beans)和其他服務組件.在3個服務器上總共部署22個服務組件,包括應用的服務組件和系統軟件(如Tomcat,MySQL).
CloudShare提供文件存儲與共享、工作協同和即時消息等眾多服務.將該系統部署在阿里云①環境中,其中的28個服務組件分布在5臺云主機上,配置為Intel?CoreTMi7,3.4 GHz CPU,4 GB RAM,CentOS 6.5操作系統.
服務一致化配置方法檢測關聯配置項對列表,當管理員進行系統部署、升級或遷移時,以該列表作為參考以輔助檢查系統配置正確性,避免違反關聯性約束條件.
3.2 實驗步驟及結果
服務一致化配置方法的具體實現步驟包括:1)使用Scrapy爬取Github上目標系統的配置文件,解析Key,Value為類型配置項保存在Redis數據庫;2)定義正則表達式用以判定配置項的語義類型;3)依據規則計算配置項之間的一致性和類型關聯性;4)使用過濾器算法把得到的備選集合進一步過濾.
實驗分為配置項過濾、配置項類型推斷、關聯系數計算及結果過濾4個步驟.方法涉及的參數包括:一致性關聯的閾值(Hc)與類型關聯的閾值(Ht),Top-K排序過濾的閾值(K).根據實踐經驗,實驗前兩者設置為0.6,K則設置為5.這3個參數都是閾值型參數,用以確定是否將備選的配置關聯作為最終結果返回,Hc主要用于一致性關聯,Ht用于類型關聯,K用于確定選取過濾的對象數量.
1) 配置項過濾
由于互聯網上具有大量開源軟件的配置文件樣本數據,配置項過濾可以很大程度上減少需要分析的配置項數量.如圖2所示,CloudShare比Adventure的配置項過濾效果要好,這是由于前者使用眾多的開源服務組件來構件系統,大部分配置項都被過濾掉了,例如CloudShare過濾掉了50%以上Nginx的配置項和80%以上Redis的配置項.
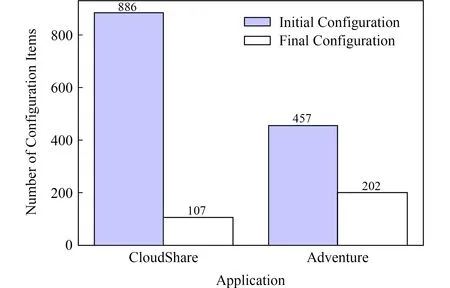
Fig. 2 Filtering Results圖2 配置項過濾結果
2) 配置項類型推斷
對于系統中的每個服務組件,建立頻繁配置項集,并推斷配置項類型.表4展示了配置項類型推斷的結果,通過人工比對,大多數配置項的類型推斷都是正確的.表4中的配置項總數為202項,比圖2中的配置項總數要多,這是由于很多配置項有多種類型.例如“db.default.USER=app”用于設置數據庫用戶名,可以根據鍵中的關鍵字來推斷數據庫和用戶類型.配置推斷錯誤與錯誤率如表5所示,在CloudShare的202個類型推斷中有11個錯誤,錯誤率為5.45%.例如“mail.username=noreply@cloudshare.im”根據正則表達式推斷為電子郵件類型,但是這個配置項實際上是一個用電子郵件設置的用戶名.再如“server_id=1”為數字類型的配置項,實際上用來作為服務器ID.在Adventure的212個類型推斷中有17個錯誤,錯誤率為8.02%.
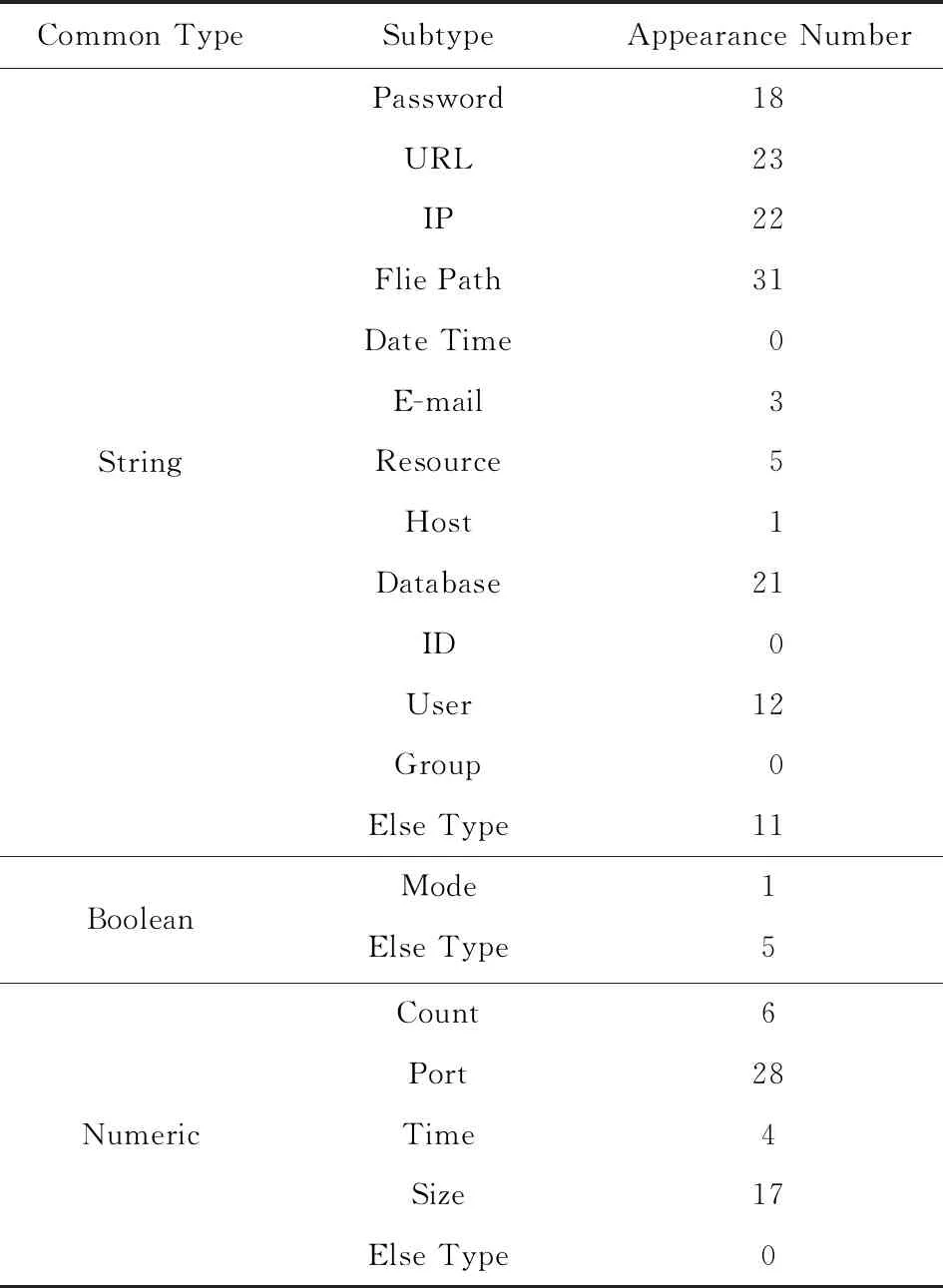
Table 4 Configuration Type Distribution of CloudShare表4 CloudShare配置類型分布

Table 5 Fault Rate of Configuration Inference表5 配置推斷錯誤率
3) 關聯系數計算及結果過濾
基于第2節所提出的配置項關聯性檢測方法,為配置項對生成一致關聯系數和類型關聯系數.通過人工手動判斷找到的關聯性是否正確,使用準確率(precision,P)與召回率(recall,R)評價所提出方法的效果:
(5)
其中,TP(true positive)表示正確發現的關聯數量,FP(false positive)表示錯誤判斷的關聯數量,FN(false negative)表示存在關聯但被判斷為無關聯的數量.
通過對CloudShare和Adventure的配置項做逐條深入分析,人工在CloudShare中發現91個配置項關聯關系,在Adventure中發現84個配置項關聯關系,以之作為基準進行評價.根據所提出的方法,在CloudShare中發現了65個正確關聯關系,在Adventure中發現了69個正確關聯關系.因此,CloudShare的召回率為6591=71.43%,Adventure的召回率為6984=82.14%.

Fig. 3 Experimental results of filters in CloudShare圖3 CloudShare過濾結果
使用閾值過濾器、冗余過濾器和Top-K過濾器對1)2)步驟檢測的關聯配置項對進行過濾操作,以輸出關聯配置項對的最終候選集合.根據經驗,設置閾值的默認值為0.6,k的默認值為5.對于準確率,不同過濾規則的組合會對最終結果有著不同的影響,分別進行評價.圖3和圖4中T表示實驗過程中使用閾值過濾器,R表示實驗過程中使用冗余過濾器,Top-K表示實驗過程中使用Top-K過濾器,T+R表示同時使用閾值過濾器和冗余過濾器,T+Top-K表示同時使用閾值過濾器和Top-K過濾器,T+R+Top-K表示同時使用所有過濾器.實驗結果如圖5所示,對于CloudShare,只使用閾值過濾器(T)的精度是最低的,約為65140=46.43%,這是由于存在很多假陽性結果.進而,通過與其他不同的過濾器組合來減少假陽性結果以提高精度,最高能夠達到約6597=67.01%.Adventure與CloudShare的結果類似,當只使用閾值過濾器(T)時,精度最低,約為69132=52.27%.然后,精度增加到53.91%,這是由于冗余濾波器去除了一些假陽性結果.Adventure中T+Top-K和T+R+Top-K的2個實驗的最終準確度相同,約為78.41%,這是由于大多數假陽性結果都被Top-K過濾器過濾掉了,不存在多余的候選配置項關聯,因此,當進一步使用冗余濾波器時,冗余濾波器對最終結果沒有影響.
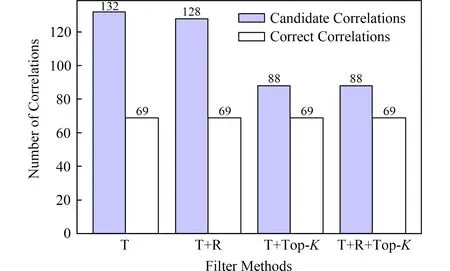
Fig. 4 Experimental results of filters in Adventure圖4 Adventure過濾結果
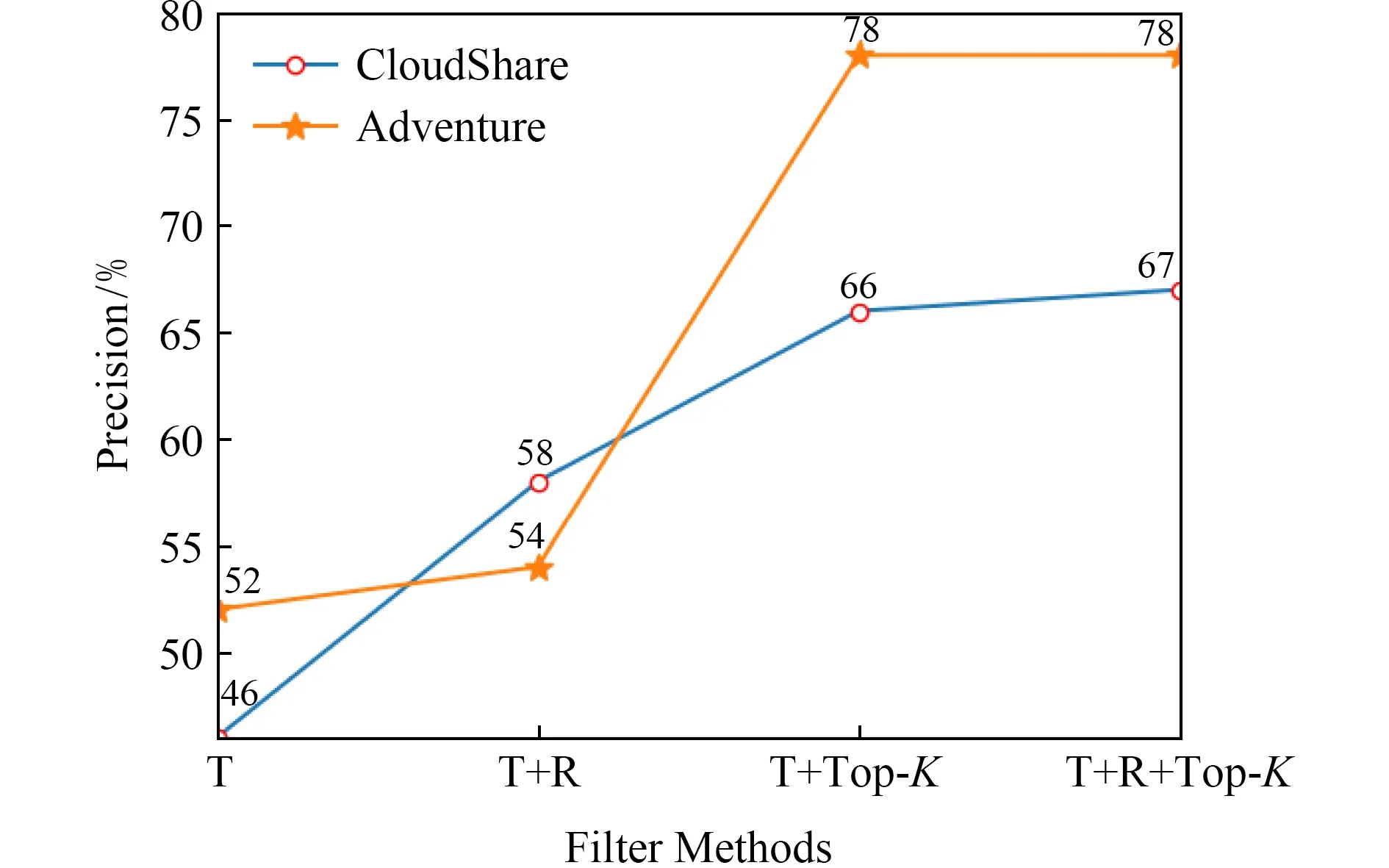
Fig. 5 Precision comparison of filters圖5 過濾準確率比較
進一步分析發現關聯性排序前5名(即K=5)的正確配置項對的數量.如圖6所示,排名第1的數量分別為45和54,分別占69.23%和78.26%,實驗結果表明關聯性排序可以準確表現配置項的關聯程度.
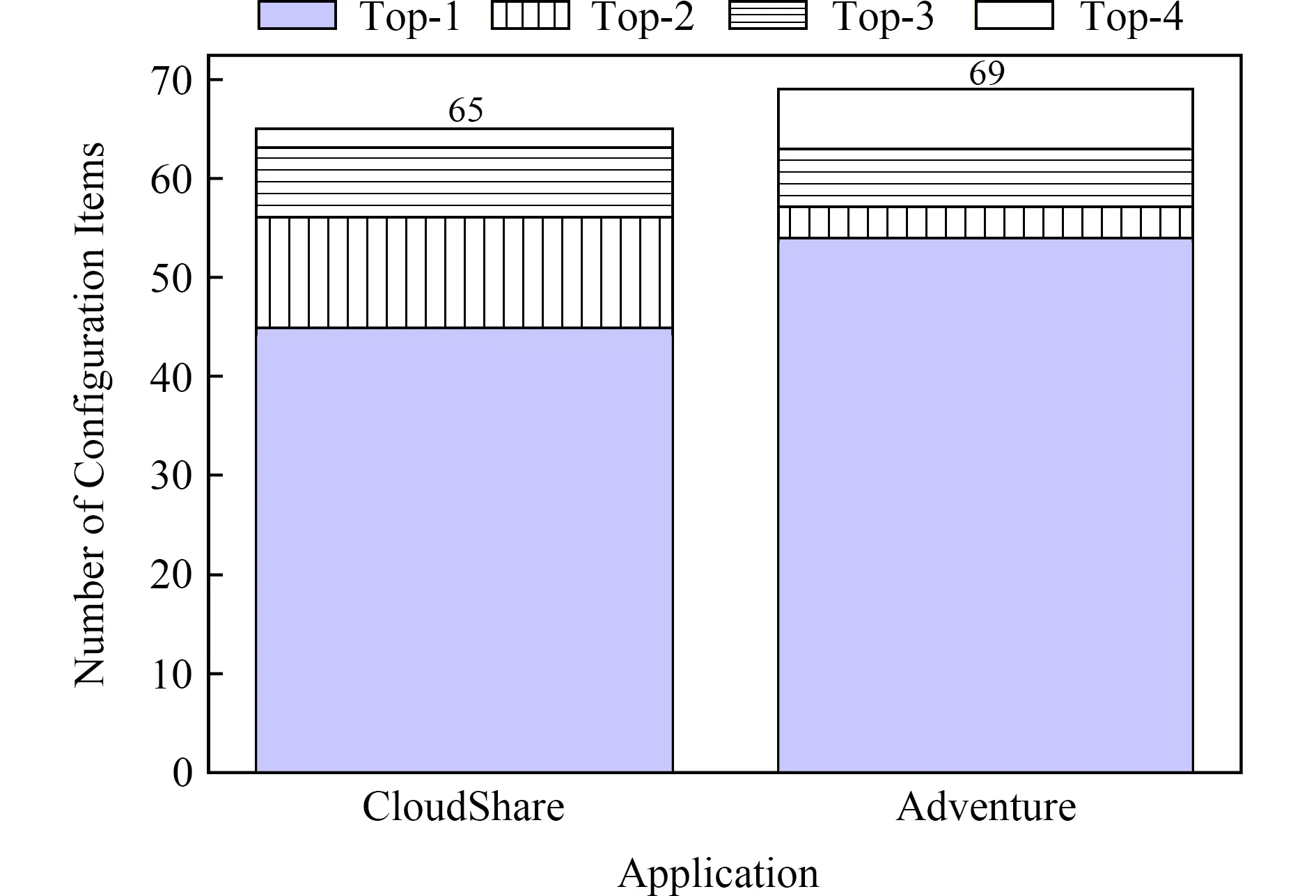
Fig. 6 Rank of configuration association圖6 配置項關聯排序
3.3 方法比較
文獻[11]提出一種配置參數關聯分析方法,當配置文件中參數值是相同字符串或者一個值是另一個值的子串,則檢測為配置關聯.在實驗中,將所提出方法與該方法進行比較.如圖7和圖8所示, CloudShare和Adventure表示所提出方法的效果,而CloudShare_N和Adventure_N表示文獻[11]所提出方法的效果.實驗結果表明這2種方法的召回率相近,但是所提出方法的準確率卻遠高于已有工作.例3和例4描述了錯誤檢測的配置關聯性,如例3,
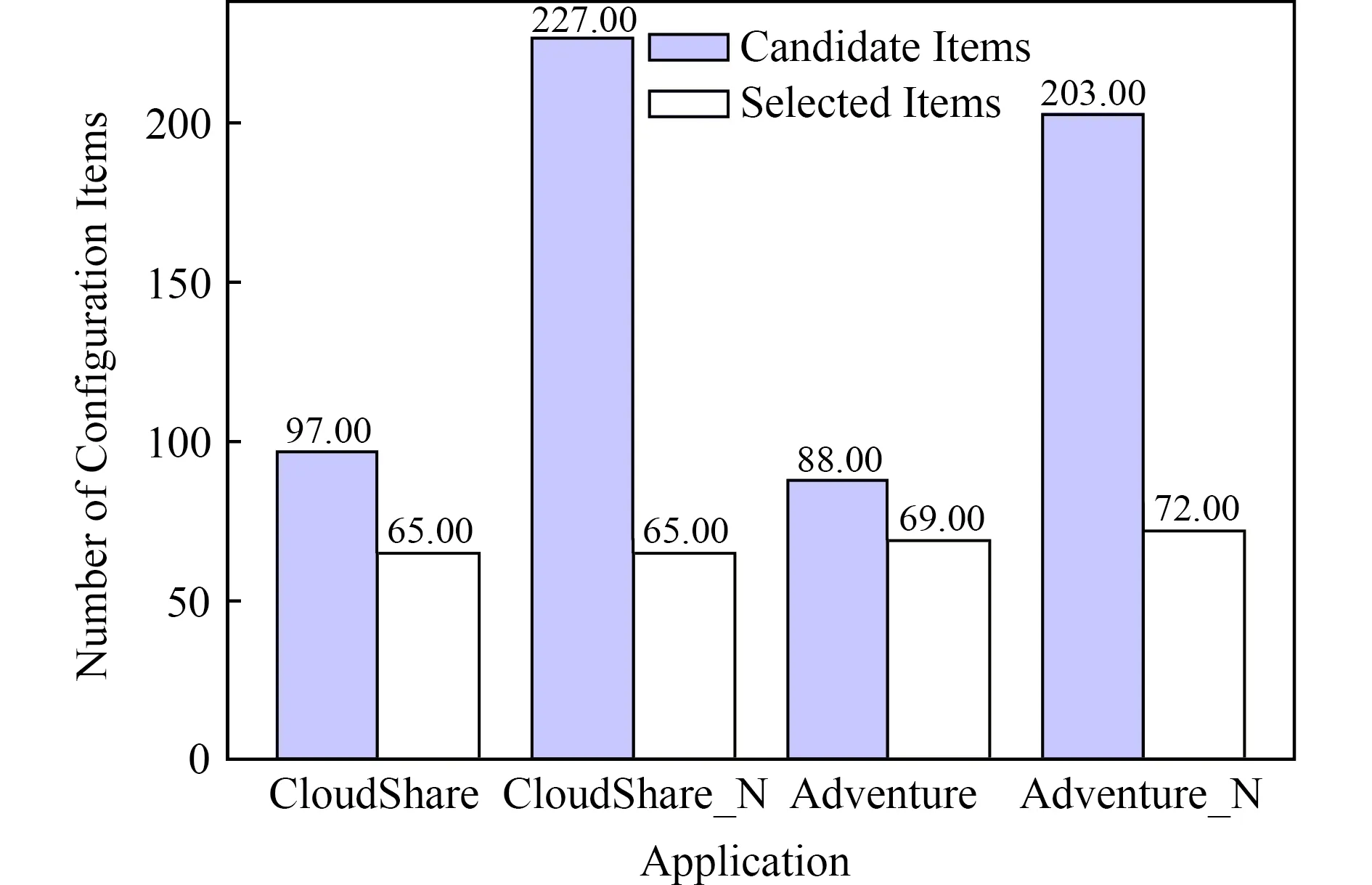
Fig. 7 Comparison of experimental results圖7 實驗結果比較
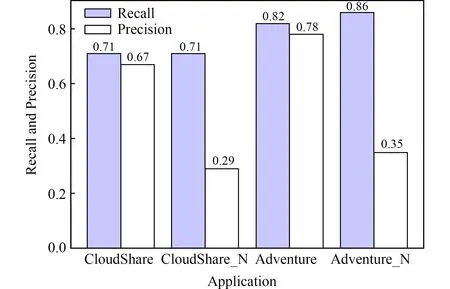
Fig. 8 Comparison of precision and recall圖8 準確率和召回率比較
已有方法僅比較配置項的取值,所以存在許多假陽性結果.另一方面,如例4,2個類型關聯的配置項會由于取值不同而被忽略,從而造成假陰性結果.
例3.Nginx和服務組件的錯誤關聯.
Nginx配置文件:
upstream.msg.server=133.133.134.174:8082.
服務配置文件:
redis.host=133.133.134.174.
約束:前者設置消息服務的負載均衡器,后者設
置Redis的IP地址,二者值相似但意義不同.
例4.索引服務和數據庫的遺漏關聯.
Index的配置:
jdbc.username=index-app.
數據庫的配置:
password=pwd.app.
約束:2個配置相關聯,如果前者的值改變,后者的值相應改成該用戶在數據庫中對應的密碼.
3.4 實驗結果討論
1) 假陰性錯誤
通過分析實驗結果,發現大多數遺漏的關聯關系涉及2個以上配置項.
例5.配置項1對多關聯關系.
Nginx配置項:
upstream.msg.server=133.133.134.174:8082.
Node2配置項:
redis.host=133.133.134.174.
Tomcat配置項:
Connector.port=8082.
例6.配置項間關聯關系.
MySQL配置項:
database.name=cs_global.cs_tenant_default.port=3306.
service.war配置項:
jdbc.url=jdbc:mysql:133.133.134.175:3306cs_tenant_default.
Node5配置項:
node.host=133.133.134.175.
例5顯示了1對多的關聯關系,其中Nginx的配置項與服務器節點2的IP地址和Tomcat的端口關聯.例6涉及到4個配置項,其中,jdbc.url與MySQL、服務器的其他3個配置項關聯.所提出的方法只關注1對1的關聯關系,僅發現了upstream.msg.server和IP的關系,這是由于差異較大的字符串導致最終的關聯性系數很低.
2) 關聯性分布
將系統的服務組件具體分為2類.
① 應用服務組件(圖9中表示為App).提供業務相關的功能和服務,例如CloudShare中的Web模塊(即WAR包)和Adventure系統中的Web服務、EJB和WS-BPEL流程等;

Fig. 9 Configuration association圖9 配置項關聯
② 實例通用服務組件(圖9中表示為Com).提供公共服務的服務組件以支持多種業務應用,如Nginx,Redis,Tomcat,ActiveMQ,MySQL.
服務組件之間的依賴關系分為3類: App與App,App與Com,Com與Com.根據3種類型的服務組件依賴關系對關聯關系進行分組,分布情況如圖9所示,發現大多數關聯存在于App與App之間以及App與Com之間.這是由于應用的服務組件依賴于系統軟件所提供的服務,造成許多配置項互相關聯.例如,service.war依賴于Redis的緩存服務,因此它們之間有3個配置項關聯,即端口號、IP地址和密碼.另外,應用的服務組件之間的數據通信和功能依賴也產生了許多App與App的配置項關聯.例如,Web服務HotelService和HotelEJB之間有4個關聯,即jndi-name,jndi-provider,URL,以及其他一些參數.因此,大多數配置項關聯都是應用在程序與其他軟件之間.
4 相關工作
在配置錯誤檢測方面,通常采用程序分析方法,主要包括靜態分析與動態分析.基于靜態數據流的方法剖析軟件源代碼并分析數據執行流,預先計算可能出現的配置錯誤[12].ConfAid動態注入程序執行的源碼以跟蹤程序執行流程,檢測錯誤的根本原因[13].ConfDiagnoser將靜態分析與動態分析相結合,基于統計分析技術將不希望的行為與特定的配置項聯系起來[14].CODE基于統計分析技術設定在特定背景下訪問配置項的規則,通過檢測訪問配置的行為自動發現軟件配置錯誤[15].基于簽名的方法提取與特定錯誤配置相關聯的程序行為,將其定義為簽名,從而診斷配置錯誤類型[16-17].基于重放的方法(如Chronus[18],AutoBash[19],Traight[20])在沙箱中嘗試可能的配置變化以修復配置錯誤.基于比較的方法(如Strider[21],PeerPressure[22])將錯誤配置與正確配置相比較,根據差別檢測配置錯誤原因.在簡化系統配置方面,當前工作可以降低錯誤配置率的方式有:提供自動化的部署和配置;最小化配置項數量并找出頻繁設置的配置項;設置用戶友好的配置約束.文獻[1]通過實例研究在配置項設計方面提供給軟件架構師和開發人員有益經驗以供借鑒.ConfValley是由聲明性語言、推理機和檢查器組成的通用配置驗證框架,以易于軟件系統配置[23].
在配置錯誤修復方面,當前工作通過拒絕錯誤的配置和打印有用的日志信息來查明錯誤.Conferr是用來測試和評估軟件系統對人為造成配置錯誤的恢復能力[24].文獻設置要改變的配置項,并給出這些值的建議取值范圍,從而修復配置錯誤[25].ConfDiagDetector在測試階段注入配置錯誤,并觀察輸出信息,運行時基于配置變異與自然語言處理檢測配置錯誤[26].文獻[27]提出了一種數據量感知的內存集群自動配置方法,可有效識別程序的高維配置,通過分層方式組合了多個獨立子模型以構建性能模型,采用遺傳算法搜索最優配置,從而在給定集群上實現最佳性能.文獻[28]用歸納方法調研了運營商對安全配置錯誤的看法,探討這類安全問題中的人為因素,定性研究如何達到目標群體并檢測錯誤配置,為減少錯誤配置的頻率和影響提供了建議.文獻[29]對5種廣泛使用的開源軟件源代碼的配置約束及變化進行例研究,發現配置數據總體的統計、特定類型約束的特征以及配置約束提取的障礙3種情況,進而提出建議以自動提取配置約束.MisconfDoctor通過錯誤配置測試,提取每個錯誤配置的日志特征,并構建特征數據庫,通過計算新異常日志與特征數據庫的相似性來發現潛在的錯誤配置[30].PCHECK幫助軟件系統早期檢測隱性配置錯誤,分析源代碼并自動生成配置檢查代碼,使用配置值模仿后期執行以捕獲錯誤表現[31].
一些工作關注于配置關聯性檢測.Rabkin將配置項分為數字、模式、標識符和其他等4種類型,基于靜態程序分析學習程序使用配置項的模式以推斷配置項類型[8].SPEX根據軟件源碼分析控制流圖以推斷配置項間的控制依賴,并比較語句以推斷配置項值的關系,沿著參數的整個數據流路徑學習配置模式以確定其語義[32].Encore使用數據的語法模式和系統的環境信息推斷配置項類型,基于機器學習以模板的形式給出配置項關聯性[7].與SPEX和Encore不同,所提出方法僅基于配置文件而不是分析源代碼來確定配置項關聯,因此與編程語言無關.此外,用一組預定義的正則表達式推斷配置項可能的多種類型,而不是僅表示單一的類型信息,具有更強的表達能力.文獻[11]基于配置項值的相似性計算其關聯概率,同時提出了一些過濾器,例如異值過濾器、非頻繁值過濾器和歸一化Google距離過濾器.然而,這些過濾器在實際應用中受到限制而不能使用.異值過濾器和非頻繁值過濾器要求多個服務組件例,在只有一個例的情況下無法應用.另外,標準化Google距離過濾器利用Google搜索結果中2個配置項的出現頻率作為過濾度量.然而如果至少有一個是特定應用軟件的配置項,則很難找到配置項對的出現.所提出方法分析了配置項的鍵、值和類型,并且過濾檢測不需要額信息,具有準確性與實用性.
5 討 論
采用例研究方法系統調研了3層架構企業應用,提取了表2典型配置的數據類型的正則表達式形式,分析了通用類型關聯規則,實驗結果及系統實踐表明,能夠較好解決3層架構企業應用的配置關聯性檢測問題.同時,配置的數據類型和配置類型的關聯性規則具有可擴展性,面向不同的應用系統可以在實際運行過程中增量式添加新的正則表達式和類型關聯規則.由于難以窮舉配置文件中所有數據類型,因此在今后工作中,計劃應用自然語言處理或語義分析技術更好理解配置項中的關鍵字.
方法粗粒度定義了一些通用類型關聯規則,覆蓋面較窄,因此在今后工作中,計劃面向具體應用領域廣泛分析更多的開源軟件系統,以定義更多領域相關的類型關聯規則.方法難以發現2個以上配置項之間的關聯性,且服務組件之間還可能存在關聯性的傳遞[32],因此在今后工作中,計劃應用統計學習和推斷技術更準確地發現這類關聯性.所提出方法無法發現在程序中被硬編碼為常量或變量,而不出現在配置文件中的配置項,因此在今后工作中,計劃引入程序分析技術以更全面發現配置信息.
所提出方法設計多個參數設置,如一致關聯性中的α,β,γ,以及閾值過濾中的閾值等.這些參數根據經驗設置,實踐過程及實驗結果表明,能夠得到較好效果.分布式系統的多參數設置是一個重要的研究方向,目前已有較多研究成果[33-34],因此未對該方向開展深入研究.在未來工作中,將嘗試采用已有基于智能搜索的參數設置方法(如爬山算法)以合理、高效配置參數.
6 結 論
分布式軟件系統在部署、更新或遷移過程中,由于服務組件配置項之間存在著關聯性,配置項設置不一致會引發配置錯誤.人工手動確定配置項的關聯性需要跨多個軟件的領域知識,既耗時又繁瑣.針對該問題,提出了一種基于關聯挖掘的服務一致化配置方法,以自動發現服務組件之間配置項的關聯性,并基于2個典型開源軟件系統對其效果進行了評估.
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
學苑創造·A版(2018年11期)2018-02-01 06:29:20
商周刊(2017年9期)2017-08-22 02:57:56
讀者(2017年5期)2017-02-15 18:04:18
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
