基于因子圖的不一致記錄對消歧方法
2020-01-09 03:48:32徐耀麗李戰懷王艷艷樊峰峰
計算機研究與發展 2020年1期
徐耀麗 李戰懷 陳 群 王艷艷 樊峰峰
(西北工業大學計算機學院 西安 710072) (大數據存儲與管理工業和信息化部重點實驗室(西北工業大學) 西安 710129)
大數據時代,信息化進程的迅猛發展促使各行各業都累積了大量的數據.但真實的數據存在各種各樣的數據質量問題如數據不完整、不一致、和不滿足實體同一性等,使得直接基于這些臟數據的分析和預測不能滿足應用場景的需求.為此,大量的研究工作針對這些問題提出一系列清洗算法.其中,針對數據無法滿足實體同一性現象,學術界和工業界研究了實體解析問題[1-3].實體解析也稱實體匹配,是通過識別出所有描述真實世界同一個實體的記錄對,來保證數據的實體同一性.它是數據集成或清洗系統的一個首要問題.
自實體解析問題第1次[4]被提出后,有大量實體解析方法被提出.部分實體解析方法[3,5-6]假設訓練數據事先給定.文獻[5-6]首先從訓練數據中學習實體匹配規則,然后用這些規則來解析記錄對是否匹配.文獻[3]首先使用embedding技術如fastText[7]將每個屬性的單詞序列轉換為相同維度的向量序列;然后訓練雙向序列模型Bi_RNN[8](bidirectional recurrent neural network)和序列比對模型來生成屬性摘要向量;接著用比較函數構建出記錄對的一系列特征;最后使用分類模型如多層感知器模型,訓練一個二分類模型,進而進行實體解析.然而,現實場景中,面臨一個新的實體解析任務時,事先標記好的數據集并不一定總是可用,而且某些領域數據需要由經驗豐富的專家來標記.考慮到依賴專家來標記數據集會帶來高昂的成本,本文所提的方法無需標注數據,因而具有更廣泛的應用場景.
一些學者[2,9]從數據統計角度分析匹配特征,提出了無監督的實體解析方法.如文獻[2]使用離群距離來估算記錄對的匹配可能性;文獻[9]使用機器學習的聚類算法,把具有類似特征的記錄劃分到匹配或不匹配組中.由于各種實體解析技術有特定的假設,以及解析任務的復雜性,對同一個實體解析任務處理的結果,存在大量的不一致記錄對.例如在文獻數據集Cora上,使用11種方法(如Rule,Distance,Cluster等)得到的解析結果中,一致匹配對的數目僅有1 013;而不一致記錄對的數目則高達44 909.所謂一致匹配對是指所有的方法一致認為該記錄對是匹配的;而不一致記錄對是指部分方法(如Rule)認為該記錄對是匹配的,而其余方法(如Distance)認為不匹配.本文的工作側重于解決這些不一致的記錄對.
對不一致記錄對進行消歧處理面臨很大挑戰.一方面,在沒有標簽數據情況下,直接選出所有方法中最好的是不現實的.另一方面,假設能夠選出綜合表現最好的方法,某些記錄對(如已選中的方法無法有效處理,而其他方法可以處理的匹配記錄對)的信息就不能夠得到充分利用.鑒于此,我們利用因子圖把各類匹配特征統一且有效地利用起來,并提出了基于因子圖的不一致記錄對消歧方法.
與記錄對是否匹配相關的信息大致可分為3類:1)記錄對自身匹配特征.例如使用字符串相似度,度量記錄對屬性值的相似程度.2)匹配傳遞特征.例如一個記錄對(r1,r2)匹配后,對其他記錄對(r1,r3)是否匹配的影響.3)外部匹配特征.例如個體方法的解析結果.為便于陳述,本文把現存的實體解析方法稱為個體方法.概率圖模型[10]的因子圖能夠利用因子函數靈活地為變量之間的關系建模.它首先把記錄對pi,j是否匹配視為待推斷變量m(pi,j),而把與m(pi,j)相關的其他匹配特征看成是已知變量,m(pi,j)為二元變量.當m(pi,j)=1時,表示ri和rj是匹配的;當m(pi,j)=0時,ri和rj是不匹配的.接著,使用核密度估計和圖的連通性來擬合出已知變量和未知變量之間的關系,并形式化為因子圖的因子函數.這樣,我們就能把不一致記錄對消歧問題,建模為一個隨機變量概率推斷問題,其中因子圖中因子的權重使用最大似然估計來推算.
本文的主要貢獻有3個方面:
1) 首次提出了一個基于因子圖的不一致記錄對消歧框架FG-RIP.該框架不依賴標記數據,能通過因子圖匯總各種異構匹配特征,如記錄對自身匹配特征、匹配傳遞特征和現存實體解析技術的外部匹配特征,來估算不一致記錄對的匹配可能性.
2) 設計并實現了基于最大似然估計的因子權重學習算法.該算法可以自動組合匹配特征的權重,并輸出最優的匹配特征權重組合.
3) 在真實的數據集上,大量的實驗結果表明該算法能明顯提升個體方法的解析效果.
1 不一致記錄對消歧問題
實體解析(entity resolution, ER)就是給定記錄集合D,識別出所有表示真實世界同一實體的記錄對p=(ri,rj),i≠j,其中,ri∈D且rj∈D.如表1所示,文獻數據集Cora包括記錄的唯一標識rID、論文的作者信息author、標題title和頁碼信息pages.實體解析就是找出所有表示同一個實體的記錄對如p2,3.給定一個實體解析方法M,它的輸入是候選記錄對的特征,輸出是所有預測為匹配的記錄對,記為P(M).為了與消歧算法相互區分,本文把現存的實體解析方法稱為個體方法.假定一系列個體方法的輸出結果如表2所示,pID是記錄對的唯一標識符,Mk列為第k個方法的預測結果,其中1≤k≤10,P(positive)(或N(negative))代表記錄對的預測狀態為匹配(或不匹配);GT(ground truth)列是記錄對的真實狀態.不一致記錄對pinc是只被部分個體方法預測為匹配的記錄對,如p2,3.一致記錄對pc是被個體方法統一預測為匹配的或者不匹配的記錄對.pc包括一致匹配對pcp如p4,5,和一致不匹配對pcn如p7,8.
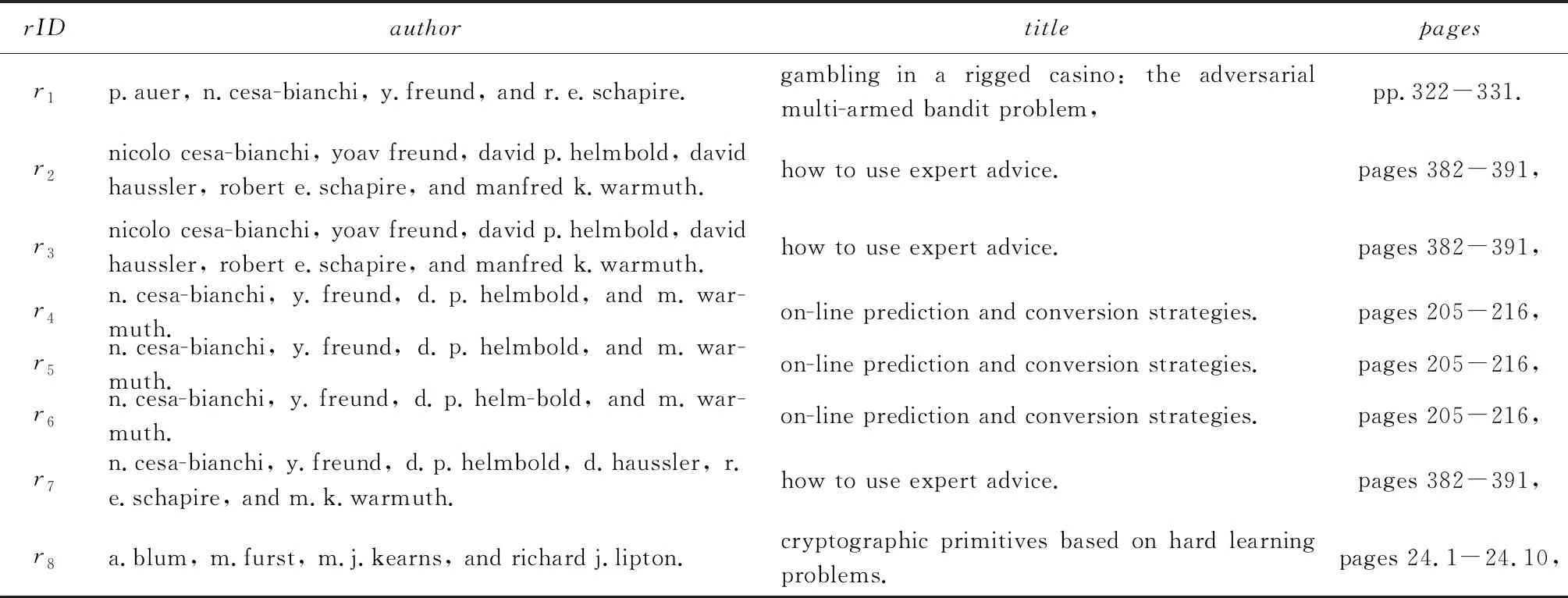
Table 1 Dataset表1 數據集
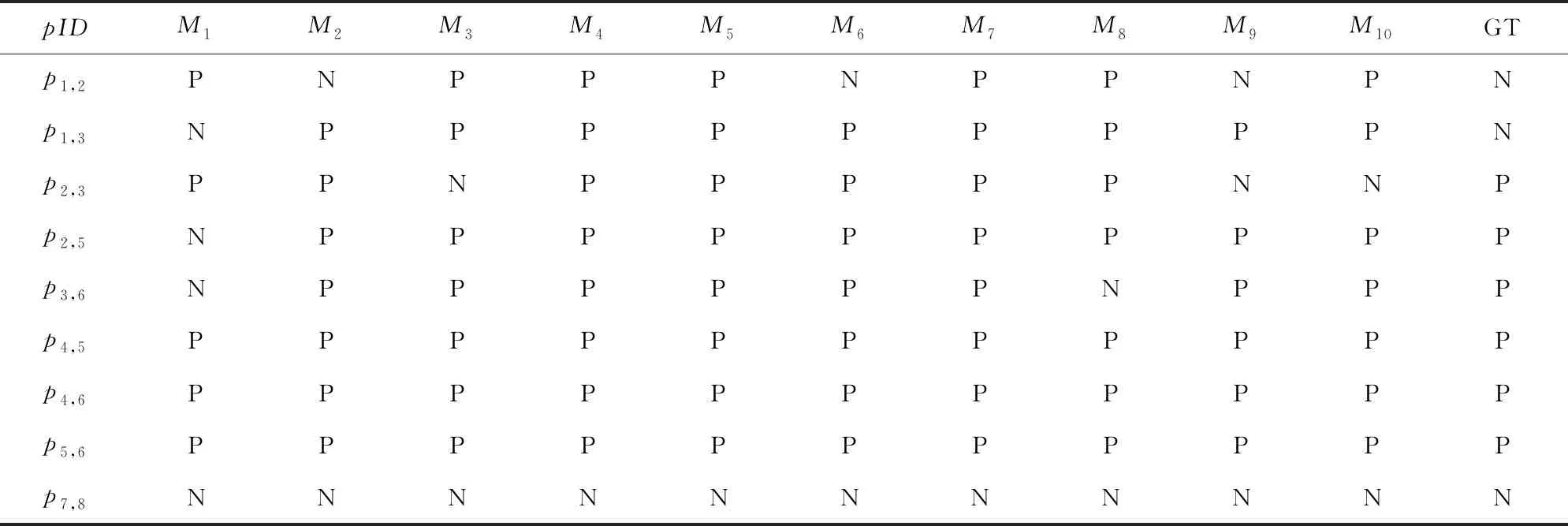
Table 2 Output of Individual Methods表2 個體方法的解析結果
Notes:Mk(k=1,2,…,10) represents the predicted label by thek-th method, GT represents the ground truth label of each record pair,N represents the predicated label of a pair is matching, P represents the predicated label of a pair is non-matching.
所謂不一致記錄對的消歧問題,就是給定一系列個體方法和一致記錄對集合Pc,推斷Pinc中不一致記錄對是否匹配.例如表2中不一致記錄對的消歧問題就是已知個體方法的解析結果M1,M2,…,M10和一致記錄對集合Pc={p4,5,p4,6,p5,6,p7,8},推斷Pinc={p1,2,p1,3,p2,3,p2,5,p3,6}中不一致記錄對的匹配狀態.
2 不一致記錄對消歧框架
本節首先概述基于因子圖的不一致記錄對消歧框架FG-RIP,接著詳細介紹它的2個關鍵模塊:基于因子圖的異構信息融合(heterogeneous informa-tion fusion based on factor graph)和基于最大似然估計的因子權重學習(learning factor weights based on maximum likelihood estimation).
FG-RIP的處理流程如圖1所示:
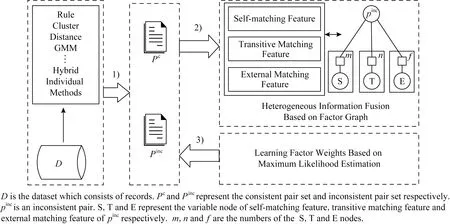
Fig. 1 A workflow for reconciling inconsistent pairs圖1 不一致記錄對消歧流程圖
1) 利用現存的個體方法(individual methods)解析數據集D,并得到Pc和Pinc.
2) 構建自身匹配特征(self-matching feature,縮寫為S),即計算記錄對的屬性值相似度和使用核密度估計來量化不一致記錄對的匹配可能性;利用圖的連通性構建一致匹配記錄對和不一致記錄對之間的匹配傳遞特征(transitive matching feature,縮寫為T);利用個體方法的解析結果構建外部匹配特征(external matching feature,縮寫為E),進而構建與不一致記錄對相關的因子圖.
3) 用最大似然估計方法計算因子圖中因子的權重.最后使用這些權重估計不一致記錄對的邊緣概率密度,并判斷不一致記錄對是否匹配.
2.1 基于因子圖的異構信息融合
在概率圖模型中,因子圖G=(V,E)類似于二部圖,其中V(vertices)是頂點集合,E(edges)是頂點之間邊的集合.它的頂點集合包括2類節點:因子節點f和變量節點v.邊只存在于因子節點和變量節點之間,而因子節點(或變量節點)之間沒有邊.因子節點定義了與它相連的變量節點的聯合概率分布.與二部圖的不同點是因子圖的因子節點定義了一個概率分布,而二部圖沒有概率分布的含義.
本文利用因子圖把與記錄對是否匹配相關的異構信息綜合起來,以便量化記錄對匹配的概率和不匹配的概率.與不一致記錄對是否匹配相關的異構特征有3類:記錄對的自身匹配特征、匹配傳遞特征和外部匹配特征.因子圖模型首先把不一致記錄對是否匹配,以及與不一致記錄對是否匹配的相關特征看成是隨機變量,然后構建這些隨機變量的聯合概率分布.它的處理過程是:1)把不一致記錄對(如pi,j)是否匹配m(pi,j)看成是一個二元隨機變量,把與m(pi,j)相關的3類特征看成是隨機變量集合V,這些隨機變量構成因子圖的變量節點或因子節點;2)使用指數函數exp(·)來構建V中變量與m(pi,j)之間的函數關系,并作為因子節點的因子函數;3)借鑒最大似然估計的思想計算出各個因子的權重;4)計算pi,j匹配的概率p(m(pi,j)=1|V)和pi,j不匹配的概率p(m(pi,j)=0|V).如果p(m(pi,j)=1|V)大于p(m(pi,j)=0|V),那么pi,j匹配,反之不匹配.為減少不必要的計算,本文所指的概率分布都是未經歸一化的概率分布,因為對于某不一致記錄對pinc而言,pinc的匹配狀態只取決于匹配概率和不匹配概率的相對大小.對未歸一化的pinc匹配概率和不匹配概率而言,它們的歸一化因子是相同的,使用未歸一化的概率值不影響匹配狀態的預測結果.
2.1.1 自身匹配特征
記錄對的自身匹配特征,主要考慮:1)不一致記錄對pinc中相應屬性值之間的相似度sim(pinc,nattr);2)使用核密度估計擬合出屬性值的相似度sim(pinc,nattr)與記錄對是否匹配m(pinc)之間的概率分布.nattr(attribute name)是屬性名,sim(·)可以是任意相似度度量.本文使用Jaccard相似系數來度量2個屬性值的相似度.
我們把屬性值相似度建模為因子節點.該類因子節點的因子函數fS,是m(pinc)與sim(pinc,nattr)之間的分布律,具體數學描述為
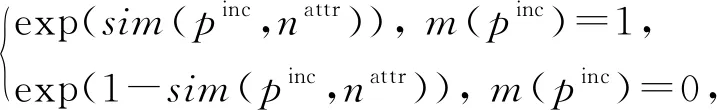
(1)
其中,S(self-matching)代表基于相似度的自身匹配特征;nattr是屬性名;sim(pinc,nattr)是pinc的nattr屬性值相似度;exp(·)是指數函數;m(pinc)是一個布爾變量,如果m(pinc)=1,那么pinc匹配,否則m(pinc)=0,pinc不匹配.例如表2中p2,3的title屬性,有sim(p2,3,title)=1,那么p2,3的因子圖包含一個因子節點,且該因子節點的因子函數定義為
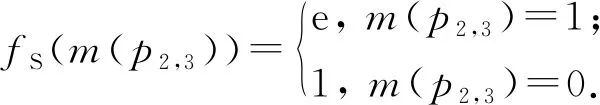
(2)
核密度估計(kernel density estimation, KDE)是一種無參數的密度估計技術,它能夠依據樣本擬合出屬性值相似度和記錄對是否匹配之間的概率密度函數.對每個屬性nattr,我們使用了所有的一致匹配對集合Pcp和一致不匹配對集合Pcn的子集(也就是在nattr上與Pinc相似的)作為核密度估計的輸入樣本.對于任意pinc和nattr,依據擬合出的密度函數和屬性值相似度sim(pinc,nattr),我們就可以計算pinc匹配不匹配的概率值.匹配的概率值越高,表明pinc匹配的可能性越大.
本文使用scikit-learn提供的核密度估計算法KernelDensity[11].它的核心思想是以給定的一系列樣本值作為觀察值集合,以一個非線性函數作為核函數,對于某待判斷的樣本xq,它的概率密度值由觀察值集合X的樣本與xq的差值決定,具體計算為
(3)
其中,N是樣本的數目;n(·)是一個歸一化函數,保證p(xq)∈[0,1].h是一個平滑因子,用來權衡偏差和方差.h越大,密度函數p(xq)具有高的偏差,也越光滑;反之,h越小,p(x)具有高的方差,即越不光滑.為了避免核密度估計遇到不連續性問題,本文采用平滑的高斯函數作為核函數:
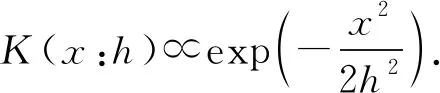
(4)
類似屬性值相似度特征,我們把由KDE擬合的記錄匹配特征看成是另一種自身匹配特征.這類因子節點的因子函數fSKDE定義為
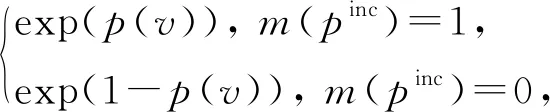
(5)
p(v)=p(sim(pinc,nattr)).
(6)
式(6)是把sim(pinc,nattr)作為式(3)的輸入得到的,SKDE(self-matching KDE)代表基于核密度估計的自身匹配特征.
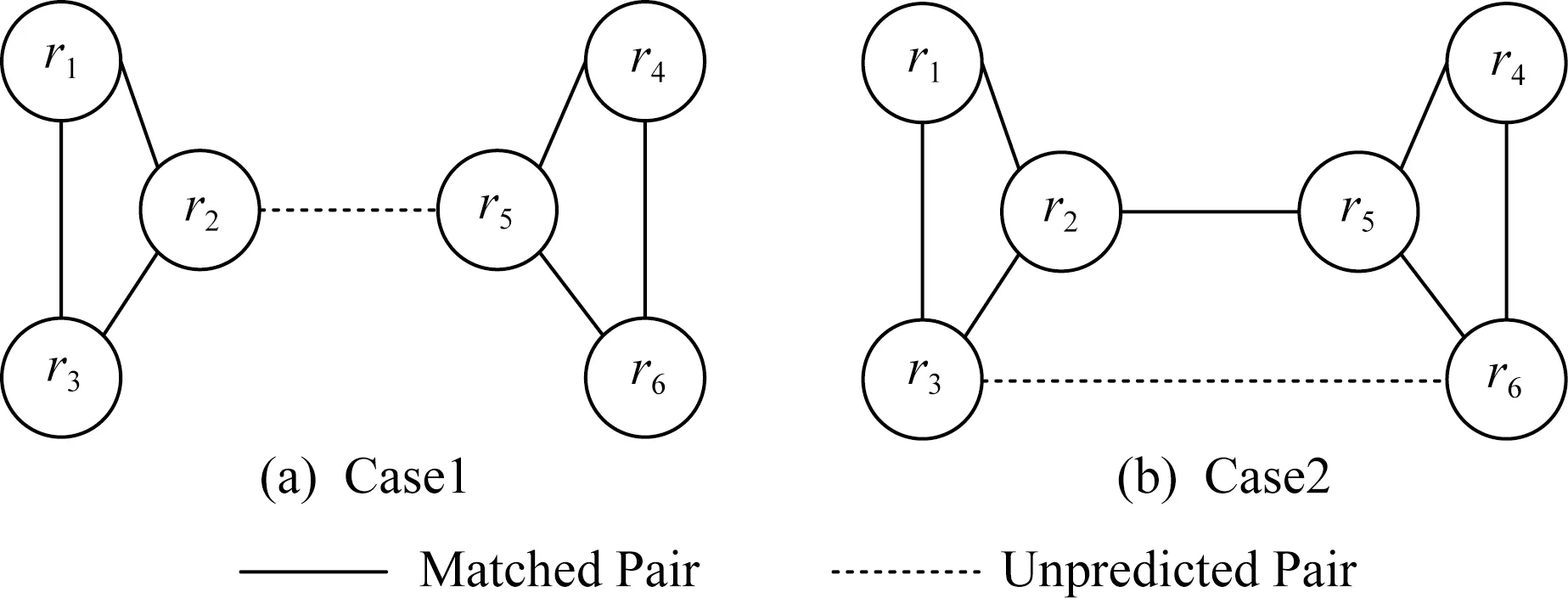
Fig. 2 Relationships among matched pairs and unpredicted pairs圖2 匹配的記錄對與待預測的記錄對之間的關系
2.1.2 匹配傳遞特征
假設把每個記錄看成是無向圖的頂點,如果某個記錄對被預測為匹配,那么相關的記錄之間存在1條實線邊,如圖2(a)中r1和r2所示.對于待判斷記錄對如p2,5,該記錄對的相關記錄之間存在1條虛線邊,表示待預測狀態.在消歧過程中,處于待預測狀態的記錄對pi,j可分為2種情況:
情況1.ri和rj分別屬于不同的連通圖,記為c=1,如圖2(a)的r2和r5,c表示記錄對所屬情況.
情況2.ri和rj屬于同一個連通圖,記為c=2,如圖2(b)的r3和r6.
情況1如圖2(a)所示.假設已知記錄對p1,2,p1,3,p2,3,p4,5,p4,6,p5,6處于匹配狀態,那么記錄對p2,5是否匹配的信息可以從r2和r5各自所在的連通圖中得到.由實體解析的定義可知,處于匹配狀態的記錄對p2,3,表明r2和r3是現實世界中同一個實體erec的2個不同描述.對某個屬性nattr來說,r2[nattr]和r3[nattr]是erec[nattr]的近似描述.當判斷r2和r5是否匹配時,可以用sim(r3[nattr],r5[nattr])作為匹配傳遞特征.傳遞特征的因子函數定義與自身匹配特征的因子函數定義類似.
情況2如圖2(b)所示.由于p2,5處于匹配狀態,待預測記錄對p3,6的r3和r6處于同一個連通圖.我們在因子圖中添加傳遞變量節點vT和傳遞因子節點fT.fT的因子函數為
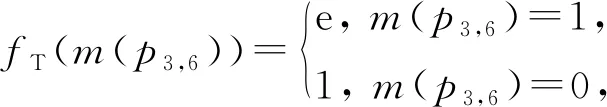
(7)
其中,m(p3,6)是待預測的變量節點,且m(p3,6)=1表示p3,6匹配,而m(p3,6)=0表示p3,6不匹配.為便于陳述,本文把與匹配傳遞特征相關的節點稱為傳遞變量節點或傳遞因子節點,并用T(transitive)表示匹配傳遞特征.
綜上所述,對于匹配傳遞特征,我們按照算法1構建與pinc相關的傳遞變量節點和傳遞因子節點.
算法1.匹配傳遞特征的因子節點和變量節點的構建.
輸入:不一致記錄對pinc和一致匹配對集合Pcp;
輸出:pinc的變量節點、傳遞變量節點集VT和傳遞因子節點集FT.
① 根據Pcp構建無向圖.
② 對于待預測狀態的記錄對pinc,利用圖的連通性,判斷pinc是屬于情況1還是情況2.
③ 若pinc屬于情況1,首先構建一個待預測變量節點m(pinc),并為它的每個屬性nattr構建一個傳遞變量節點vT∈VT和一個傳遞因子節點fT∈FT.考慮到某些待預測狀態的記錄對,會產生較多的匹配傳遞特征.例如在圖2(a)中,p2,5的nattr屬性的匹配傳遞特征包括sim(r3[nattr],r5[nattr]),sim(r1[nattr],r5[nattr]),sim(r2[nattr],r4[nattr]),sim(r2[nattr],r6[nattr]).鑒于此,對于每個屬性nattr,本文只選擇這些匹配特征中sim(·)最小的,記為ms(pinc,nattr),作為pinc在nattr上傳遞變量節點vT的變量值.fT的因子函數定義為
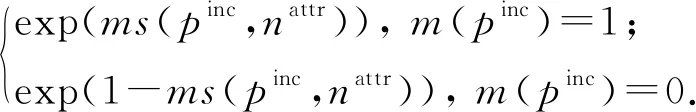
(8)
④ 若pinc屬于情況2,首先構建變量節點m(pinc),并為它的每個屬性構建一個傳遞變量節點vT∈VT和一個傳遞因子節點fT∈FT,其中fT的因子函數定義為
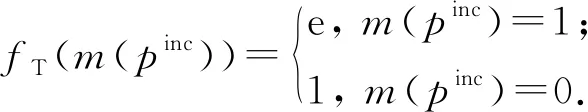
(9)
2.1.3 外部匹配特征
與傳統的實體解析方法不同,本文的消歧方法是對傳統實體解析方法的結果中不一致記錄對進行預測.這些不一致記錄對具有個體方法的投票信息.本文把這些投票信息歸類為外部匹配特征,并用E(external)表示外部匹配特征.pinc的外部匹配特征包括:1)pinc獲得的投票比例;2)個體方法關于pinc的投票信息.
依據pinc獲得的投票比例,可構建與源自投票比例的外部匹配特征相關的因子節點和變量節點.假設使用k(k>1)個不同的個體方法,且有Npinc個方法預測pinc為匹配的,那么在因子圖中添加因子節點fE、變量節點vE和待預測變量節點m(pinc).其中vE=Npinck,fE(m(pinc),vE)是fE的因子函數,其數學形式為
fE(m(pinc),Npinck)=
(10)
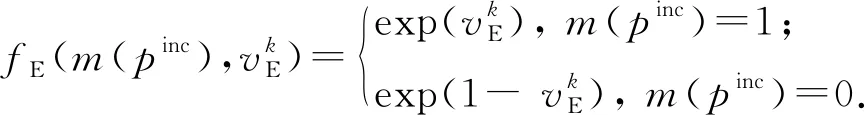
(11)
2.2 基于最大似然估計的因子權重學習
對于某不一致記錄對pinc,假設已經得到與它相關的所有因子函數如f1,f2,…,fl,其中l是因子節點的數目,那么pinc是否匹配的變量m(pinc)與所有相關的變量V={v1,v2,…,vl}之間的聯合概率密度可定義為
p(m(pinc),v1,v2,…,vl;w1,w2,…,wl)= exp(w1)×f1×exp(w2)×f2×…× exp(wl)×fl,
(12)
其中wi是因子fi的權重.
最大似然估計是一種估計總體分布中未知參數的方法,它的核心思想是概率最大的事件最有可能出現.由于因子節點的權重是未知的,為了估計這些權重,我們采用最大似然估計的思想,極大化觀察數據,也就是最大化變量V關于參數W的對數似然函數:
(13)
其中V={v1,v2,…,vl}是除了m(pinc)以外的所有變量集合;W={w1,w2,…,wl}是所有權重的集合;n是待消歧的不一致記錄對的數目|Pinc|.
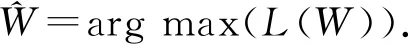
我們使用scipy提供的信任區域約束算法(trust region constrained algorithm)[12]求解有約束的最優化問題.
3 實驗與結果
本節概述了實驗的運行環境,并在真實數據集Cora和Song上驗證算法的有效性.所有實驗的運行環境配置為 Intel?CoreTMi7-4710MQ 2.50 GHz處理器、16 GB內存和Ubuntu 16.04 64位的操作系統.編程語言是Python 3.服務器端數據庫是MongoDB.
3.1 度量標準
本文采用實體解析文獻[5,13-14]廣泛使用的查準率、查全率和F1來評價算法的有效性.由于個體方法是從候選記錄對開始處理,所以,在與個體方法的對比中,使用的是全部候選記錄對的查全率、查準率和F1,而其他實驗使用不一致記錄對集合的查全率、查準率和F1.所謂查準率是指預測為匹配且真正匹配的記錄對數目,與預測為匹配的記錄對數目的比值,記為Ppre.查全率是指預測為匹配且真正匹配的記錄對數目,與所有真正匹配的記錄對數目的比值,記為Rrec.F1是查準率和查全率的調和平均值,具體定義為

(14)
3.2 數據集
本文在Cora和Song數據集上測試提出的方法.下面我們從數據集特點和記錄對方面介紹這2個數據集.
數據集Cora[15]是一個文獻數據.它包含1 295個記錄,而這些記錄隸屬于112個實體的某一個.每個記錄由12個屬性描述如文獻的作者列表和標題等.我們將這些記錄對兩兩比較,得到的候選記錄對數目為837 865.本文處理的對象是不一致記錄對.對Cora數據而言,不一致記錄對的數目為44 909,一致匹配對的數目是1 013,而一致不匹配對的數目是791 943.
數據集Song[16]是一個歌曲數據.它包含100 000個記錄,每個記錄由7個屬性描述,例如歌曲的專輯名和發布時間等.我們抽取了其中的20 744個記錄進行實驗.這些記錄對經過blocking技術過濾后,得到的候選記錄對的數目是260 181,其中不一致記錄對的數目為115 258,一致匹配對的數目為651,一致不匹配對的數目為144 272.
3.3 對比方法概述
本文采用的個體方法總共有11個,包括:1)5個無監督的解析方法,分別是基于RR規則[6]的方法Rule、基于離群距離的方法Distance[2]、基于k-means的Cluster[9]、基于高斯混合模型的GMM[10]、基于狄利克雷過程的變分貝葉斯高斯混合模型DPBGM[17];2)6個基于學習的解析方法,分別是基于支持向量機的SVM[18]、基于決策樹模型的CART[19]、基于隨機森林的ERT[20]、基于高斯樸素貝葉斯模型的GNB[11]、基于多層感知器的MLP[8]和基于深度學習技術的Hybrid[3].
各個無監督方法的解析過程逐一概述為:Rule方法是使用事先給定的匹配規則來判斷記錄對是否匹配,其規則形式與文獻[6]提出的RR規則相同.Distance方法[2]首先計算離群距離,然后依據離群距離和匹配約束來判斷記錄對是否匹配.Cluster方法是使用開源的機器學習庫scikit-learn來復現文獻[9]中提到的k-means聚類解析方法.GMM和DPBGM方法是把實體解析問題等價于將候選記錄對劃分為匹配組和不匹配組的聚類問題.GMM即高斯混合模型[10],假設匹配記錄對和不匹配記錄對分別服從2個參數未知的高斯分布,而觀測數據來自這2個高斯分布的混合模型.GMM通過EM算法[18]學習該模型的未知參數,進而使用訓練好的模型將記錄對劃分為匹配組和不匹配組.DPBGM是高斯混合模型的一種變體,即高斯混合的變分貝葉斯估計模型.DPBGM與GMM的不同點是,DPBGM使用變分推斷估計模型的參數.
基于學習的解析方法SVM,CART,ERT,GNB,MLP是機器學習領域的分類模型.這些模型的主要思想是構建樣本特征,訓練二分類模型,并預測記錄對是否匹配,其中樣本的特征是記錄對的相應屬性值的相似度構成的向量.這些模型的不同點在于模型構建原理.本實驗的SVM是非線性支持向量機,其模型構建原理是在特征空間中搜索一個超平面,用來把記錄對集合劃分為匹配組和不匹配組.CART的模型構建原理是使用特征和閾值構建二叉樹,其中每個樹節點都具有最大的信息收益.ERT的模型構建原理是首先使用訓練集的子樣本構建一系列隨機決策樹,然后使用這些決策樹的解析結果均值來進行最終的判斷.GNB算法與樸素貝葉斯算法的相同點是基于貝葉斯定理和類條件獨立性假設;兩者的不同點是GNB假設在給定類標簽后,每個特征服從高斯分布.MLP模型是一個二分類的前饋神經網絡,本實驗中MLP的輸入層是記錄對的屬性相似度特征,輸出層是記錄對的匹配狀態.隱藏層包括2層:第1層的神經元數目是5;第2層的神經元數目是2.它的損失函數是交叉熵損失函數,優化算法是擬牛頓方法L-BFGS.本實驗調用scikit-learn庫中這些算法的API實現接口[11].本實驗的Hybrid算法,首先使用預訓練的embedding模型把每個屬性的單詞序列轉換為固定維度的向量序列;然后訓練并融合雙向序列模型Bi_RNN和序列比對模型來構建屬性摘要向量;接著用比較函數計算記錄對的屬性相似度描述向量;最后多層感知器以訓練集的屬性相似度描述向量為輸入,訓練出二分類模型進行實體解析.所有監督或無監督的現存實體解析方法,都可以作為消歧框架的個體方法,但必須有至少2個不依賴標簽數據,且有差異的個體方法.這樣基于學習的解析方法就可以用有差異的無監督方法的輸出結果中的一致的部分作為訓練集.有差異的無監督個體方法越多,訓練集的純度越高.所謂訓練集的純度是指訓練集中標簽正確的記錄對所占的比例.
消歧方法GL-RF[21]是針對Clean-Clean ER場景[22]下消歧算法.本文將該算法的匹配約束去掉,修改為可以處理Dirty-Dirty ER場景下的消歧算法,并進行了對比實驗.
3.4 實驗和結果
本節中,我們進行4組實驗來驗證FG-RIP的有效性.
實驗1.與個體方法進行了對比,驗證了FG-RIP算法能自動組合出在F1指標上最好的方法.這些個體方法的實驗結果如表3,4所示,最大值已用黑體標出.
Note: The maximum values are in bold.
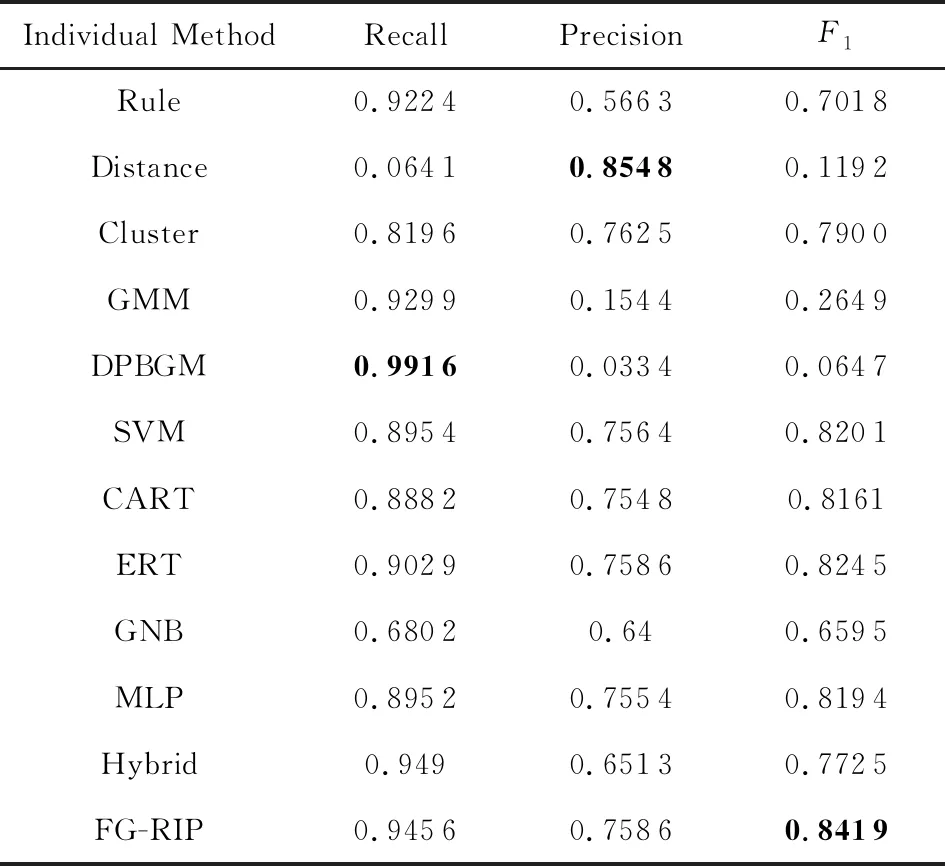
Table 4 Comparison with Individual Methods on Cora表4 Cora數據集上與個體方法的對比
Note: The maximum values are in bold.
由表3,4可以得出:
1) 在相同的數據集上,個體方法各有所長.①對Song數據而言,在所有的個體方法中,Rule具有最高的查全率和相對較高的查準率,這說明了基于屬性值相似度和閾值的領域規則能夠有效識別出記錄對,但存在準確率欠缺的不足.這也表明,查全率高而查準率低的個體方法如Rule,GMM等,有助于過濾掉不匹配的記錄對,同時保障真正匹配的記錄對以較高的概率落入不一致記錄對集合中.另外,盡管GNB具有最高的查準率,但查全率較低.這表明被GNB預測為匹配的記錄對,具有較高的可信性.這也表明對于查準率高而查全率低的方法如GNB,可有效保證真正匹配記錄對以較高概率落入一致匹配記錄對集合中.CART和MLP算法的查準率、查全率和F1均達到90%以上.這表明屬性值相似度特征和較少的模型參數就能夠為Song數據集訓練較好的解析模型.②對Cora數據而言,Distance具有最高的查準率和極低的查全率.這是由于樊峰峰等人[2]提出了一個基于主成分分析的離群距離.對某個記錄ri,該離群距離能夠找到與該記錄匹配概率最高的記錄對rj,其中i≠j.對于數據集中某實體erec,假設只有2個記錄ri和ri描述該實體erec,那么Distance的解析結果較好.而Cora數據集中erec對應多個記錄,使得Distance識別為匹配的記錄對,有較高概率是真正匹配的.而其他匹配的記錄對被解析為不匹配的,導致了極低的查全率.DPBGM具有最高的查全率,且GMM具有較高的查全率.這些說明在沒有標簽數據的情況下,選擇一個適合所有數據集的方法具有很大的挑戰.
2) 在不同的數據集上,大部分個體方法的查準率、查全率和F1有差異.例如SVM在Cora數據上F1值與最高的F1值相差2.18%,卻在Song數據上相差43.98%.這是由于SVM模型依賴于來自數據集的支持向量,若這些支持向量無法有效分類樣本,則模型的分類效果較差.Hybrid在Cora數據上有較高的查全率,而在Song數據集上有較高的查準率.這是由于文獻[3]融合了embedding技術、雙向序列模型、序列比對模型和多層感知器來訓練出一個二分類模型.由于該模型的參數多(如在Song和Cora數據集上,需要訓練的參數數目分別為9 210 006和26 545 814),但訓練樣本集合(即一致記錄對集合)有限,且訓練樣本集合(一致記錄對集合)和測試樣本集合(不一致記錄對集合)屬于不同的分布,導致訓練的模型過擬合即在訓練數據集上查準率、查全率和F1高達90%以上,而在Song數據集的測試集合上,僅查準率較高;而在Cora數據集上,僅查全率最高.另外,某些個體方法不受數據集差異的影響.比如GMM在Cora和Song數據上均有高達90%以上的查全率和較低的查準率,這說明混合高斯模型對數據的差異不敏感,具有較好的健壯性.
3) 平均來看,監督模型的解析效果優于無監督的.例如對Song數據而言,6個監督模型的平均查全率、查準率和F1,依次為0.674 7,0.911 9,0.756 9;而5個無監督模型的平均查全率、查準率和F1依次為0.735 3,0.367 3,0.423 8.對Cora數據而言,6個監督模型的平均查全率、查準率和F1依次為0.868 5,0.719 4,0.785 4;而5個無監督模型的平均查全率、查準率和F1依次為0.745 5,0.474 3,0.388 1.這表明,盡管在消歧問題上,訓練集(一致記錄對集合)和測試集(不一致記錄對集合)不滿足獨立同分布,且在理論上,當訓練樣本和測試樣本是獨立同分布時,監督模型才有最好的效果,但由于部分監督模型如CART和MLP,具有較好的健壯性,能在非獨立同分布場景下,訓練出較好的二分類模型.如在Song數據的消歧問題上,CART和MLP的查準率、查全率和F1高達90%.這也表明通過分析一致記錄對的特征有助于更好地預測不一致記錄對的匹配狀態.
4) FG-RIP 能夠更準確地解析出更多的匹配記錄,具有最好的綜合指標F1.由表3,4可知,與其他個體方法相比,FG-RIP具有較高的查準率和查全率.這是由于FG-RIP把個體方法的解析結果作為外部匹配特征,并綜合記錄對的自身匹配特征和匹配傳遞特征來進行消歧.在Cora數據集上,雖然FG-RIP的查準率沒有Distance高,但它具有最好的綜合指標F1.類似地,在Song數據集上,FG-RIP也具有最高的F1值.這些表明,基于因子圖的消歧算法FG-RIP能自動組合各類特征,獲得最優的綜合指標.
實驗2.與已存在的消歧方法GL-RF進行了對比.我們分別從Song和Cora數據集的不一致記錄對集合中抽取了1 000個和2 000個進行對比實驗.如表5,6所示:
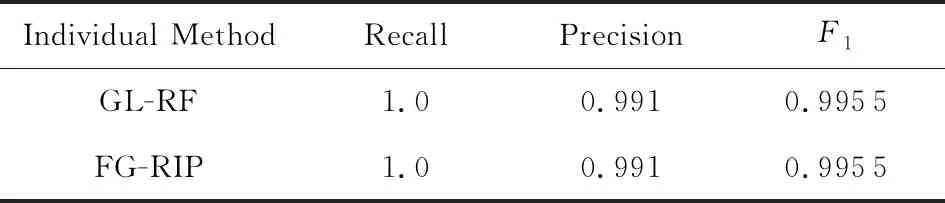
Table 5 Comparison with GL-RF on Song表5 Song數據集上與GL-RF的對比
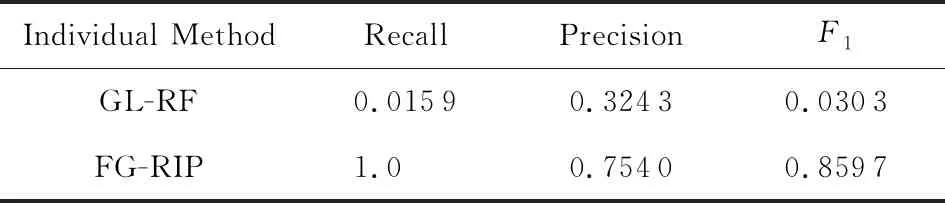
Table 6 Comparison with GL-RF on Cora表6 Cora數據集上與GL-RF的對比
表5,6所示的實驗對比結果可得出:
1) 改造后的GL-RF可以有效處理部分Dirty-Dirty ER場景下的不一致記錄對消歧問題.由表5可知,在Song數據集上,GL-RF和FG-RIP的實驗結果相同.這是由于雖然Song數據屬于Dirty-Dirty ER場景,但Song的不一致記錄對集中匹配記錄對與Clean-Clean ER場景的大體吻合.具體來說,在Clean-Clean ER場景下,某個記錄最多有1個與之相匹配的記錄.Song數據上,92.81%的記錄最多有1個與之匹配的記錄;7.19%的記錄與2個以上的其他記錄相匹配,因而GL-RF能有效地處理這類消歧問題.
2) FG-RIP算法在Cora數據集上優于GL-RF.這是由于:①從數據集的角度看,Cora的不一致記錄對集中匹配記錄對與Clean-Clean ER場景差異較大.具體來說,Cora數據中,僅6.88%的記錄最多有1個與之匹配的記錄;93.12%的記錄與2個以上的記錄相匹配;有的記錄甚至有83個與之匹配的記錄.這導致改進后的GL-RF在Cora數據中消歧效果有限.②從方法的角度看,GL-RF只考慮了一致記錄對和不一致記錄對之間的距離關系,適合識別與某個記錄最匹配的記錄.而FG-RIP把各類匹配特征建模為特征因子,自動組合最優消歧模型,因而能更準確地識別匹配記錄對.
實驗3.本文使用查準率、查全率和F1指標,分析了不同的因子特征對Cora和Song數據的消歧結果的影響.在圖3(a)(b)中,如第2節所述,S,T,E分別代表記錄對自身匹配特征、匹配傳遞特征、外部匹配特征.我們可以觀察到:1)匹配傳遞特征T在2個數據集上均具有較高的查全率.這表明特征T有助于識別更多的匹配記錄對.2)記錄對自身匹配特征S消歧效果表現不穩定.在Cora數據上,S具有較高的F1,而在Song數據上具有較低的F1.3)外部匹配特征E具有較好的消歧效果.如E的查全率在Cora數據上最高,且F1值高于記錄對自身匹配特征S和匹配傳遞特征T.這表明融合個體方法的特征能有效地發揮個體方法識別匹配記錄對的能力.4)所有特征表現穩定,在所有數據集上均能取得較好的效果.以F1指標為例,所有特征的解析效果在Song和Cora數據上達到最高.
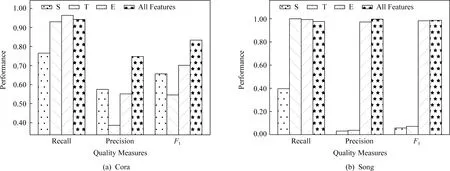
Fig. 3 Performance comparison on different factors圖3 不同因子的消歧效果對比
實驗4.分析基于相似度的核密度估計技術對FG-RIP方法的影響.如圖4所示,KDE代表FG-RIP算法只使用基于相似度的核密度估計特征;-KDE代表FG-RIP算法使用去掉核密度估計特征后所有其他特征.本質上,在相似度值的基礎上,用核密度估計技術計算概率值,相當于把原來的相似度特征從線性空間變換到非線性空間.變化后的特征對非線性可分的數據集有效,而對線性可分的數據集效果不明顯.由圖4的實驗結果可知:1)當變化后的特征空間能有效劃分候選記錄對集合的匹配記錄對和不匹配記錄對時,基于核密度估計技術的特征可獲得較好的消歧效果.如對于Cora而言,與-KDE相比,變化后的特征空間(KDE)有較高的查全率、查準率和F1值,即能提供更好的分類效果;而對于Song而言,原有特征空間(-KDE)的消歧質量指標均高于KDE的消歧質量.2)基于全部特征的消歧算法具有一定的魯棒性.在核密度估計特征有效時,它的消歧效果略低于核密度估計特征的效果;在核密度估計特征無效時,它受其消歧效果的影響小.①當變化后的特征空間能有效區分匹配對和不匹配對時,僅僅使用基于相似度的核密度估計特征,FG-RIP就能獲得最好的消歧效果,甚至在某些質量指標上略高于所有特征.如在Cora數據集上,KDE的查全率和F1值最高.所有特征的查全率和F1值低于KDE的相應值,表明在Cora數據中增加非KDE特征后,質量指標有所下降,但降低的幅度不大,如所有特征的F1值僅減低了0.49%.②當變化后的特征空間不能有效地區分匹配對和不匹配對時,KDE的消歧效果較差.如在Song數據集上,KDE的所有質量指標最低.但所有特征的消歧質量受KDE特征的影響小.由于缺少標簽數據,事先評估KDE的消歧效果不可行.鑒于此,在實際應用場景中,建議使用全部的特征,以便消歧算法具有較好的魯棒性.
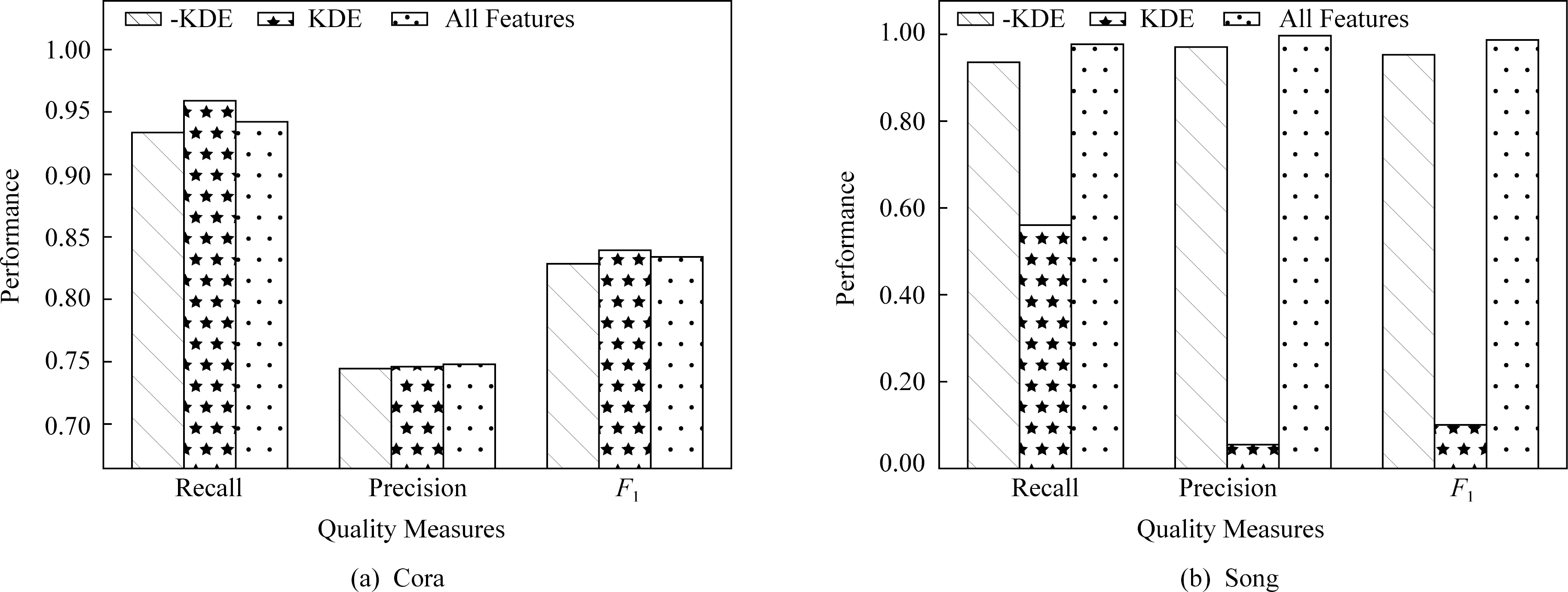
Fig. 4 Performance comparison on kernel density estimation圖4 核密度估計的消歧效果對比
4 相關工作
由于實體解析問題是數據集成和清洗系統的核心基礎問題,且在很多領域有廣泛的應用,領域專家和學者提出了一系列的解析技術.這些相關的工作可劃分為三大類:基于學習的[3,5-6]、基于統計的[2,9,23-25]、和基于人機配合的[26-27].
基于學習的實體解析方法[3,5-6]首先使用訓練數據集來學習實體匹配的模式或者規則,接著用訓練好的模式或規則判定記錄對是否匹配.文獻[3]提出了4種屬性級摘要表示方法(分別是聚合模型(SIF)、基于循環神經網絡的序列模型(RNN)、注意力模型(Attention)和基于序列和注意力的混合模型(Hybrid)),并使用神經網絡來訓練實體解析模型.文獻[6]從已知的匹配(和不匹配)記錄對集合中學習屬性級別的匹配規則集(ARs),并組合這些規則成一系列記錄級別的規則集(RRs).文獻[5]提出了一種描述記錄和實體之間匹配關系的規則(ER-rule),并設計了從訓練集中自動學習ER-rule的算法和高效的在線實體解析算法.這些方法都依賴標簽數據,且不能解決不一致記錄對消歧問題,而我們的方法假設標簽數據不存在,側重于標簽數據缺失場景下消歧問題.
基于統計的實體解析方法[2,9,23-25]是通過統計分析記錄對的匹配特征,并形式化為某個合適度量,進而選取合適的閾值來將記錄對劃分為匹配的或者不匹配的.比如文獻[23]分別從單詞的簡寫和全寫,前綴關系和字符近似匹配方面提出了3種字段匹配度量算法.文獻[24]提出了Footrule Distance,用來輸出與給定元組最相關的topk個記錄值.針對大多數算法未體現關鍵屬性重要性的不足,文獻[25]利用信息增益或統計概率的方法計算屬性權重,并提出了基于這些屬性權重的最終相似度來提升實體解析的準確率.文獻[2]提出了離群距離,并證明了離群距離與記錄對匹配的可能性是正相關的.這類方法的優點是不需要訓練數據集和額外的訓練過程,只需要估算出合適的匹配度量和閾值.但由于實體解析應用場景的復雜性,匹配度量和閾值的確定很難做到適用于所有的場景.文獻[9]使用統計機器學習的聚類算法如k-means方法,把候選記錄對分成兩組:匹配組和不匹配組.這類不依賴標簽數據的方法都可以作為消歧框架的個體方法,用來對數據集進行預先處理,以得到一致或不一致記錄對.
針對全自動的實體解析方法不能徹底解決實體解析問題,基于人機配合的實體解析方法[26-27]提出借用用戶的知識以人機配合的方式進行解析.文獻[26]將實體解析過程分為設計階段和執行階段.設計階段就是用戶在樣本數據上使用現成的工具靈活地構建出一個實體解析工作流;在執行階段,用戶可調用支持大數據處理的工具來執行設計好的工作流.文獻[27]提出了基于規則的候選記錄對生成階段和基于crowd細化匹配記錄對2個階段.這2個階段都有人和自動算法的共同參與,這類方法需要人的參與,無法自動完成不一致記錄對的消歧處理.
與本文的消歧算法最相關的是GL-RF[21].該算法的核心思想是首先基于TF.IDF計算記錄對的向量表示;接著分析與每個不一致記錄對距離最近的前k個一致匹配對和一致不匹配對,對于該不一致記錄對的影響;最后當前k個一致匹配對的影響大于前k個一致不匹配對時,該不一致記錄對為匹配,反之為不匹配.文獻[22]依據數據集是否存在重復記錄,把實體識別問題區分為3種場景:Clean-Clean ER,Dirty-Clean ER,Dirty-Dirty ER.其中Clean-Clean ER是指左數據源和右數據源都沒有重復記錄.FG-RIP與GL-RF的區別有2點:1)GL-RF是針對Clean-Clean ER場景,而FG-RIP則是針對Dirty-Dirty ER場景;2)GL-RF沒有考慮個體方法的解析結果的可信程度,而FG-RIP使用因子權重來區分個體方法的解析結果.
5 總結和展望
本文研究了在沒有標簽數據場景下不一致記錄對消歧問題,并首次提出了基于因子圖的不一致記錄對消歧框架.該框架利用因子圖融合與不一致記錄對相關的特征(包括自身匹配特征、匹配傳遞特征和外部匹配特征),并使用最大似然估計計算因子圖中因子的權重.實驗結果表明:該算法能夠有效地學習到合適的權重,并自動組合出最優的消歧方案.在沒有標簽的場景下,自動估計不同特征的解析效果很有挑戰性,也具有深遠的現實意義.因為自動估計不同特征的解析結果,并選擇最優的特征組合,可進一步提升解析的效果.比如在Cora數據集上只使用記錄對的基于相似度的核密度估計特征就能獲得更好的解析效果.鑒于此,我們把無標簽場景下,不同特征消歧結果的質量估計問題作為將來的研究問題.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
