數(shù)據(jù)中心網(wǎng)絡(luò)傳輸協(xié)議綜述
2020-01-09 03:48:26曾高雄胡水海張駿雪
計算機研究與發(fā)展 2020年1期
關(guān)鍵詞:機制
曾高雄 胡水海 張駿雪 陳 凱
(香港科技大學(xué)計算機科學(xué)與工程系 香港 999077)
近10年來,網(wǎng)絡(luò)應(yīng)用(如搜索、在線零售和云計算等)飛速發(fā)展,對底層基礎(chǔ)設(shè)施在計算、存儲和網(wǎng)絡(luò)等方面提出了嚴苛的要求.在此驅(qū)動下,微軟、谷歌、亞馬遜、臉書、阿里巴巴等大型互聯(lián)網(wǎng)企業(yè)在全球范圍內(nèi)快速地建立起了高性能數(shù)據(jù)中心(data center, DC).這些數(shù)據(jù)中心通常采用商用器件,將服務(wù)器和交換機通過精心設(shè)計的網(wǎng)絡(luò)互聯(lián),從而以更經(jīng)濟更便捷的方式達到高速計算和海量存儲等需求.在支撐服務(wù)的各項技術(shù)中,數(shù)據(jù)中心網(wǎng)絡(luò)(data center network, DCN)是一個潛在且重要的性能瓶頸[1-3],因而引起了包括學(xué)術(shù)界和工業(yè)界的廣泛關(guān)注.
在這樣的背景下,本文調(diào)研了數(shù)據(jù)中心網(wǎng)絡(luò)的一個核心方面——傳輸層協(xié)議. 本文首先概述了數(shù)據(jù)中心網(wǎng)絡(luò)環(huán)境下傳輸層協(xié)議設(shè)計的機遇和挑戰(zhàn). 在這驅(qū)使下,一系列的傳輸協(xié)議被設(shè)計提出.隨后將早期(2010—2015年)數(shù)據(jù)中心網(wǎng)絡(luò)傳輸設(shè)計方面的工作進行分類,并對各自的優(yōu)缺點作了深入探討.最后分析了2015年以來數(shù)據(jù)中心網(wǎng)絡(luò)傳輸設(shè)計的研究趨勢.
1 數(shù)據(jù)中心網(wǎng)絡(luò)傳輸層協(xié)議概述
傳輸層協(xié)議旨在為應(yīng)用提供高吞吐、低延遲的網(wǎng)絡(luò)數(shù)據(jù)傳輸服務(wù).雖然傳輸協(xié)議在因特網(wǎng)上已經(jīng)有很長的歷史了,它卻直到2010年才在數(shù)據(jù)中心網(wǎng)絡(luò)環(huán)境下被系統(tǒng)性地探索.數(shù)據(jù)中心網(wǎng)絡(luò)有著和因特網(wǎng)不一樣的特點(如單一控制域和同構(gòu)網(wǎng)絡(luò)架構(gòu)).這給數(shù)據(jù)中心網(wǎng)絡(luò)上的傳輸協(xié)議設(shè)計同時帶來了機遇和挑戰(zhàn).本節(jié)將首先對因特網(wǎng)下的傳輸層協(xié)議作簡單介紹;之后,分析數(shù)據(jù)中心網(wǎng)絡(luò)的特點,并指出其對傳輸協(xié)議設(shè)計帶來的機遇和挑戰(zhàn).
1.1 因特網(wǎng)下的傳輸層協(xié)議簡介
傳輸層協(xié)議在因特網(wǎng)下已經(jīng)發(fā)展了幾十年.傳輸層協(xié)議包括:無連接的盡力傳輸協(xié)議,以用戶數(shù)據(jù)報協(xié)議(user datagram protocol, UDP[4])為代表;面向連接的可靠傳輸協(xié)議,以傳輸控制協(xié)議(transport control protocol, TCP[5-6])為代表.在大多數(shù)網(wǎng)絡(luò)場景(包括因特網(wǎng)和數(shù)據(jù)中心網(wǎng)絡(luò))中,應(yīng)用層使用的傳輸協(xié)議以面向連接的可靠傳輸協(xié)議為主.TCP傳輸層協(xié)議提供的服務(wù)包括可靠性、流量控制、擁塞避免、多路復(fù)用等.其中,擁塞控制方面的研究最為廣泛.
TCP最經(jīng)典的擁塞控制算法是由Jacobson[7]在1988年的SIGCOMM會議上提出的TCP Tahoe.該算法包括慢啟動(slow start)和擁塞避免(conges-tion avoidance)兩部分.新建立的連接首先進入慢啟動階段,每個來回通信時間(round-trip time, RTT)擁塞窗口(congestion window, CWND)漲1倍,直到通過計時器超時(timeout)發(fā)現(xiàn)丟包或者窗口達到慢啟動閾值(slow start threshold, ssthresh)進入擁塞避免階段.擁塞避免階段每個RTT擁塞窗口增加一個最大傳輸單元(maximum transmission unit, MTU),發(fā)現(xiàn)丟包則窗口降為初始值1并重新進入慢啟動階段.
TCP Tahoe算法為了避免網(wǎng)絡(luò)丟包后因為等待超時重傳而帶來的時間開銷,額外引入了快速重傳(fast retransmission)機制,發(fā)送方收到多個相同序列號的確認包(acknowledgement, ACK)后,即認為下一個序列號對應(yīng)的數(shù)據(jù)包已經(jīng)丟失,并開始丟包重傳.在此基礎(chǔ)上,TCP Reno[8]增加了快速恢復(fù)(fast recovery)機制,在快速重傳之初窗口降為當前值的一半,同時保持擁塞避免狀態(tài),避免了低效的初始化窗口和慢啟動過程.更進一步地,TCP New Reno[9]維護了快速恢復(fù)的狀態(tài),記錄快速恢復(fù)狀態(tài)之初已發(fā)送的數(shù)據(jù)包,直到這些數(shù)據(jù)都已被確認才退出這一狀態(tài),只在快速恢復(fù)初期進行1次窗口砍半,避免了因為連續(xù)丟包導(dǎo)致的連續(xù)砍窗口的問題.最后,TCP SACK[10]加入了選擇確認(selective ACK, SACK)與重傳機制,避免了累計確認(cumulative ACK)與重傳機制帶來的低效的回退N步(go-back-N)問題.
1.2 數(shù)據(jù)中心網(wǎng)絡(luò)的特點、機遇與挑戰(zhàn)
相對于因特網(wǎng)這類復(fù)雜多變且不完全可控的異構(gòu)網(wǎng)絡(luò),數(shù)據(jù)中心網(wǎng)絡(luò)是一個單一自治域(admini-strative domain)下的同構(gòu)網(wǎng)絡(luò)環(huán)境.單一自治域意味著端主機(endhost)及其使用的協(xié)議、網(wǎng)絡(luò)設(shè)備及配置,甚至應(yīng)用對網(wǎng)絡(luò)服務(wù)的需求(如延遲敏感還是帶寬敏感等)等都相對可控可預(yù)測.同構(gòu)性體現(xiàn)在固定有規(guī)律的拓撲,如Fat-tree[1],VL2[11]等;相同的網(wǎng)絡(luò)設(shè)備及配置,如顯式擁塞通告(explicit congestion notification, ECN[12]),相對一致的緩存大小和鏈路帶寬;有限的路由條數(shù)以及可預(yù)測的RTT等.
數(shù)據(jù)中心網(wǎng)絡(luò)的這些特點給傳輸協(xié)議設(shè)計帶來了許多機遇,列舉如下:
1) 數(shù)據(jù)中心網(wǎng)絡(luò)下可以協(xié)調(diào)端主機協(xié)議和網(wǎng)絡(luò)設(shè)備設(shè)置,存在更多性能優(yōu)化空間.傳統(tǒng)因特網(wǎng)因為網(wǎng)絡(luò)不可控,只能使用丟包信息作為擁塞反饋信號,不可避免地帶來了高延遲和高丟包率等問題.即使網(wǎng)絡(luò)設(shè)備使用了一些復(fù)雜的網(wǎng)絡(luò)優(yōu)化機制,端主機上的協(xié)議也很可能沒能充分配合使用.數(shù)據(jù)中心網(wǎng)絡(luò)則可以協(xié)調(diào)兩者,如網(wǎng)絡(luò)側(cè)采用主動隊列管理(active queue management, AQM[13])在擁塞早期標記ECN信號,接收端收到信號通過ACK反饋給發(fā)送端,發(fā)送端得以及時調(diào)整發(fā)送窗口或速率實現(xiàn)高效擁塞控制等.
2) 數(shù)據(jù)中心網(wǎng)絡(luò)下的傳輸協(xié)議不受公平性的約束.因特網(wǎng)不是單一自治域,存在多種不同協(xié)議之間的競爭,因而公平性是一個重要指標,給網(wǎng)絡(luò)性能方面的優(yōu)化帶來了約束.數(shù)據(jù)中心網(wǎng)絡(luò)作為單一自治域,一方面可以協(xié)調(diào)內(nèi)部不同應(yīng)用使用不同的網(wǎng)絡(luò)優(yōu)先級隊列,例如,區(qū)別對待延遲敏感和帶寬敏感的應(yīng)用,可以優(yōu)化兩者各自不同的目標;另一方面可以統(tǒng)一全局采用相同協(xié)議和網(wǎng)絡(luò)配置,避免不同協(xié)議間的競爭.
3) 同構(gòu)的數(shù)據(jù)中心網(wǎng)絡(luò)更有利于協(xié)議和網(wǎng)絡(luò)設(shè)備的參數(shù)設(shè)置.例如,相對穩(wěn)定的RTT可以幫助設(shè)置最小重傳計時器(retransmission timeout, RTO);相對穩(wěn)定的網(wǎng)絡(luò)鏈路帶寬和RTT意味著可預(yù)測的網(wǎng)絡(luò)帶寬時延乘積(bandwidth delay product, BDP),可以幫助設(shè)置初始擁塞窗口大小和ECN標記的閾值等.
與此同時,數(shù)據(jù)中心網(wǎng)絡(luò)面對著更加復(fù)雜嚴苛的應(yīng)用要求,給傳輸協(xié)議設(shè)計帶來了巨大的挑戰(zhàn),列舉如下:
1) 應(yīng)用要求嚴苛.一個典型的應(yīng)用設(shè)計模式(網(wǎng)頁搜索、廣告篩選等的基礎(chǔ))是分割聚合(partitionaggregate[2]).上層應(yīng)用需求被分割成多個小的任務(wù)給多個底層工作機器(worker),底層機器完成任務(wù)后將結(jié)果返回給應(yīng)用匯聚層得到最終結(jié)果.為了滿足服務(wù)級協(xié)議(service-level agreement, SLA),每一輪迭代(包括計算和網(wǎng)絡(luò)傳輸)都需要在10 ms量級的期限內(nèi)完成.99.9%的尾部時延仍然會對用戶帶來巨大的影響(要么返回不準確的結(jié)果,要么造成長等待時間).
2) 應(yīng)用需求多樣.不同的應(yīng)用通常會有不同的網(wǎng)絡(luò)傳輸需求.有些應(yīng)用要求短時間內(nèi)的低時延,比如面向用戶請求的短流量響應(yīng).有些應(yīng)用要求長時間的穩(wěn)定吞吐量,比如數(shù)據(jù)中心內(nèi)部定期的海量數(shù)據(jù)更新.有些應(yīng)用有限定完成期限,在期限內(nèi)完成的數(shù)據(jù)才有效,快于期限完成的數(shù)據(jù)并不一定會帶來更大的應(yīng)用價值.
2 早期研究
基于第1節(jié)對數(shù)據(jù)中心網(wǎng)絡(luò)的觀察,工業(yè)界和學(xué)術(shù)界開始了對數(shù)據(jù)中心網(wǎng)絡(luò)環(huán)境下傳輸協(xié)議設(shè)計的研究.本節(jié)將早期(2010—2015年)數(shù)據(jù)中心網(wǎng)絡(luò)傳輸設(shè)計方面的工作分成3類——基于端主機的擁塞控制、網(wǎng)絡(luò)仲裁機制和交換機優(yōu)先級調(diào)度,并分別對這3類工作的優(yōu)缺點作深入討論.表1概括了本節(jié)介紹的3類工作及其相應(yīng)的優(yōu)缺點.

Table 1 Comparison Between Early (2010—2015) Work on DCN Transport Protocol表1 數(shù)據(jù)中心網(wǎng)絡(luò)傳輸層協(xié)議早期(2010—2015年)工作的比較
2.1 基于端主機的擁塞控制
數(shù)據(jù)中心網(wǎng)絡(luò)最經(jīng)典的傳輸層擁塞控制算法是由斯坦福大學(xué)和微軟的研究人員在2010年的SIGCOMM會議上提出的數(shù)據(jù)中心傳輸協(xié)議(datacenter transmission control protocol, DCTCP)[2].DCTCP是一種基于端主機的擁塞控制算法,主要包括2部分:交換機端的ECN標記和主機端的速率控制.DCTCP在這2部分與基于ECN的TCP協(xié)議都有明顯不同.一方面,DCTCP使用了基于交換機瞬時隊列長度的單一閾值標記算法.基于瞬時隊列的標記可以對突發(fā)流帶來的網(wǎng)絡(luò)擁塞作出快速響應(yīng),使得算法有更好的突發(fā)容忍性.此外,單一閾值標記配置使用更簡單,這也是基于DCN內(nèi)較穩(wěn)定的基礎(chǔ)RTT的條件.另一方面,DCTCP將單個位的ECN序列轉(zhuǎn)化為多個位的擁塞程度并依此調(diào)整窗口,而不像TCP那樣簡單粗暴地窗口砍半.這樣既避免了輕微擁塞下過度響應(yīng)導(dǎo)致的帶寬浪費,又防止了嚴重擁塞下響應(yīng)不足導(dǎo)致的高延遲和高丟包率.
DCTCP具體算法為:
1) 交換機基于瞬時隊列長度以單一閾值對經(jīng)過的數(shù)據(jù)包標記ECN.
2) 接收端將收到的數(shù)據(jù)包中的ECN信息通過ACK中的ECN-Echo反饋回發(fā)送方.
3) 發(fā)送方統(tǒng)計收到ACK中ECN-Echo比例的指數(shù)加權(quán)滑動平均值α.當沒有ECN-Echo時,每個ACK窗口增加1WCWND;當遇到ECN-Echo時,每個RTT窗口乘性砍α2.
在這之后,一系列的基于ECN的擁塞控制算法被設(shè)計出來.D2TCP[15]以降低期限錯失率(deadline miss rate)為目標,在DCTCP的基礎(chǔ)上引入了流的完成期限D(zhuǎn),并以此計算期限緊急程度e=TD,其中T為預(yù)期完成時間;當數(shù)據(jù)發(fā)送方收到ECN-Echo時,每個RTT窗口乘性砍αe2,使得期限更緊急的流可以更快地完成.類似地,L2DCT[16]則以降低流的完成時間(flow completion time, FCT)為目標,在DCTCP的基礎(chǔ)上引入了與發(fā)送數(shù)據(jù)量反相關(guān)的流的權(quán)值函數(shù)f;當數(shù)據(jù)發(fā)送方收到ECN-Echo時,每個RTT窗口乘性砍αf2,使得更小的流可以更快地完成,從而逼近在流大小信息不可知下理論最優(yōu)的最少獲得服務(wù)優(yōu)先(least attained service, LAS)[23]調(diào)度算法.此外,有一些工作(如ECN[24])認為只需優(yōu)化調(diào)整交換機ECN機制,采用順時出隊列的方式標記,即可以在不改動端主機TCP協(xié)議的情況下達到和DCTCP相近的性能.
基于端主機的擁塞控制機制只需要改動端主機上的軟件協(xié)議棧,交換機上配置簡單的ECN標記,因而具有配置簡單和易于實現(xiàn)部署的優(yōu)點.不足的是,因為沒有很好地結(jié)合更多的交換機支持,基于端主機的擁塞控制機制在性能上通常與理論最優(yōu)存在較大差距.例如,DCTCP沒有區(qū)分大小流,使得大小流同時存在于單一隊列中,小流的完成時間會受到大流的排隊延遲影響而變得很長.與此同時,基于端主機的擁塞控制機制需要較長的時間周期去收斂到穩(wěn)定狀態(tài).
2.2 網(wǎng)絡(luò)仲裁機制
為了克服基于端主機的擁塞控制收斂時間長等缺陷,網(wǎng)絡(luò)仲裁機制得到了廣泛關(guān)注.網(wǎng)絡(luò)仲裁機制借助于網(wǎng)絡(luò)中交換設(shè)備等可以觀察到經(jīng)過流量的需求,從而基于一定的算法計算發(fā)送窗口或速率或調(diào)整方向,通過數(shù)據(jù)包頭和接收端ACK反饋回發(fā)送端,從而實現(xiàn)擁塞控制和流量調(diào)度.
最早的代表性工作是由微軟的研究人員在2011年的SIGCOMM會議上提出的期限驅(qū)動傳輸控制協(xié)議(deadline-driven delivery control protocol, D3)[17].D3以降低期限錯失率為目標,假設(shè)上層應(yīng)用可以將數(shù)據(jù)流大小和規(guī)定期限信息傳給傳輸層.基于這些信息,D3設(shè)計了網(wǎng)絡(luò)仲裁機制,讓交換機根據(jù)全局流信息分配帶寬,優(yōu)先分配數(shù)據(jù)流在規(guī)定期限內(nèi)完成所需的最小帶寬,即r=sD,其中s為流的大小,D為流的完成期限;最后將剩余的帶寬平均分配給所有的流.
不足的是,D3需要交換機來記錄流狀態(tài)并分配帶寬,這樣復(fù)雜的功能遠遠超出了目前商用交換機的支持功能范圍.此外,D3采用了貪婪式的先到先服務(wù)的帶寬分配方案,先到達的流一旦被分配帶寬,將占用帶寬直至最終完成,而不允許中途釋放帶寬給新流,即不允許搶占.這導(dǎo)致了非最優(yōu)的流調(diào)度,如圖1(b)所示,由于一個接近完成期限的流(fA)可能會為了等待一個先到達的完成期限較遠的流(fB)而被阻滯,進而錯過了規(guī)定的完成期限.
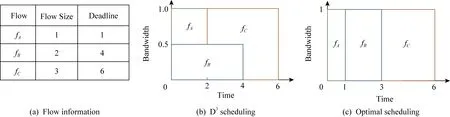
Fig. 1 Illustration to show the suboptimal performance of D3 without preemption圖1 實例說明D3在沒有搶占機制下的非最優(yōu)調(diào)度性能
針對D3的缺點,伊利諾伊大學(xué)香檳分校的研究人員在2012年的SIGCOMM會議上提出了搶占式分布快速控制協(xié)議(preemptive distributed quick control protocol, PDQ)[18].與D3類似,PDQ假設(shè)上層應(yīng)用可以將數(shù)據(jù)流大小和規(guī)定期限等信息暴露給傳輸層.利用這些信息,PDQ同樣也設(shè)計了顯式速率控制的實現(xiàn)機制,逼近不同的調(diào)度算法.例如:1)最短任務(wù)優(yōu)先(shortest job first, SJF)[25]調(diào)度算法.數(shù)據(jù)量越小的流將會被優(yōu)先分配帶寬.2)最近期限優(yōu)先(earliest deadline first,EDF)[26].越接近完成期限的流將會被優(yōu)先分配帶寬.與D3不同的是,PDQ采用了搶占式的帶寬分配方案,可以根據(jù)流的緊急程度將已分配的帶寬重新分配,從而解決了D3非最優(yōu)調(diào)度的問題(圖1(c)中最優(yōu)調(diào)度與PDQ相同).
PDQ離理想的SJF和EDF仍有較大的差距.這是因為在PDQ系統(tǒng)里,暫停或者啟動一個流都需要至少一個RTT來與路徑上所有的交換機協(xié)調(diào).這一個RTT的額外開銷對于數(shù)據(jù)中心內(nèi)大量小流來說是不可接受的負擔.此外.精確地計算出一個流的發(fā)送速率并不是一個簡單的事情,比如一個流的發(fā)送瓶頸可能不是在網(wǎng)絡(luò)里,而是在端主機的磁盤上.
與此同時,網(wǎng)絡(luò)仲裁機制中還包括一類利用服務(wù)器做集中式擁塞控制調(diào)度的設(shè)計.代表性工作是由麻省理工學(xué)院的研究人員在2014年的SIGCOMM會議上提出的FastPass[19].這類工作在發(fā)送數(shù)據(jù)前,發(fā)送端會向集中控制器發(fā)送請求,集中控制器結(jié)合請求信息和網(wǎng)絡(luò)狀況作出相應(yīng)的調(diào)度指令,包括發(fā)送數(shù)據(jù)的時間、速率和路徑等.這種集中式調(diào)度優(yōu)點明顯,因為可以獲取網(wǎng)絡(luò)全局信息,理論上可以達到最優(yōu)的調(diào)度,但是也存在明顯缺點,系統(tǒng)實現(xiàn)上需要額外一個RTT開銷去獲取調(diào)度決策,因而對數(shù)據(jù)中心下小流的完成時間有較大的負面影響.
2.3 交換機優(yōu)先級調(diào)度
為了克服網(wǎng)絡(luò)仲裁機制不可實現(xiàn)等缺陷,斯坦福大學(xué)的研究人員在2013年的SIGCOMM會議上提出了基于交換機優(yōu)先級調(diào)度的pFabric[20].pFabric既不要求交換機配置大量內(nèi)存以維持所有流的狀態(tài)信息,也不要求交換機實現(xiàn)復(fù)雜的調(diào)度算法以計算反饋信息.pFabric的核心思想是將流調(diào)度從速率控制中分離開來.pFabric的設(shè)計包含2部分:1)端上的速率控制協(xié)議.新流以線速發(fā)出,去除任何快速丟包重傳機制,直到連續(xù)多次超時才進入探索模式,定期發(fā)送最小數(shù)據(jù)包并在接收到確認時重新進入慢啟動.2)交換機上的優(yōu)先級調(diào)度和優(yōu)先級丟包.交換機上優(yōu)先調(diào)度最高優(yōu)先級的數(shù)據(jù)包;當緩沖已滿時,優(yōu)先丟棄低優(yōu)先級的數(shù)據(jù)包.
與網(wǎng)絡(luò)仲裁機制相比,pFabric設(shè)計更簡單,同時保證了接近理論最優(yōu)的性能.但是,pFabric仍然無法在已有的商用交換機上實現(xiàn).一方面,商用交換機芯片支持的優(yōu)先級隊列數(shù)量非常有限(大約8個);另一方面,商用交換機芯片并未廣泛支持優(yōu)先級丟包機制,一旦一個數(shù)據(jù)包進入了交換機的緩沖區(qū),它就不會被新到來的包“擠出去”.后續(xù)工作EPN嘗試使用2個優(yōu)先級隊列逼近pFabric的性能,然而需要對交換機做更多復(fù)雜的改動,因而同樣無法在商用交換機上實現(xiàn).
pFabric等工作都假設(shè)我們可以從應(yīng)用獲得流的信息,比如流的大小.事實上,雖然數(shù)據(jù)中心是一個單獨管理域,應(yīng)用的流信息仍然很難獲得.主要原因有2個:1)很多應(yīng)用是一邊計算一邊傳輸?shù)模援攽?yīng)用開始傳一個流時,它自己也不知道這個流總共要傳多少字節(jié).2)對于許多可以獲得流大小的應(yīng)用,管理員仍然需要去修改其網(wǎng)絡(luò)通信模塊獲得流大小,并將這個信息通過合適的接口傳遞給協(xié)議棧.考慮到數(shù)據(jù)中心有大量的應(yīng)用,逐一修改這些應(yīng)用獲得流信息對于管理員來說無疑是巨大的負擔.
基于上述觀察,無信息感知的流調(diào)度工作應(yīng)運而生.香港科技大學(xué)的研究人員在2015年的NSDI會議上提出了實際的無信息感知的流調(diào)度機制 (practical information-agnostic flow scheduling, PIAS)[21].PIAS采用多級反饋隊列作為其調(diào)度策略.在多級反饋隊列里面,所有流一開始都屬于最高優(yōu)先級,當一個流已經(jīng)發(fā)送的字節(jié)數(shù)超過一個閾值時,這個流就被降入下一個優(yōu)先級.根據(jù)多級反饋隊列策略,小流會在較高優(yōu)先級內(nèi)完成,而大流會在較低優(yōu)先級內(nèi)完成.多級反饋隊列可以在長尾分布下有效地近似理想的最短剩余時間優(yōu)先,降低流的整體平均完成時間以及小流的完成時間.PIAS利用端主機來記錄每個流已經(jīng)發(fā)送的字節(jié)數(shù)并標記數(shù)據(jù)包的優(yōu)先級,而在交換機里只需要配置普通的優(yōu)先級隊列.因此,PIAS可以在普通的商用交換機和標準的TCPIP協(xié)議棧上實現(xiàn),容易在生產(chǎn)環(huán)境里部署.
在PIAS系統(tǒng)里,一個關(guān)鍵的部分就是多級反饋隊列的閾值.閾值決定了如何將不同大小的流隔離在不同優(yōu)先級里.如果閾值設(shè)置得不好,大小流可能某個時刻全部混雜在一個優(yōu)先級里面,嚴重拖長小流的完成時間.簡單的理論分析發(fā)現(xiàn),理想的閾值跟每條鏈路的流大小分布和平均利用率都有關(guān)系.在真實的數(shù)據(jù)中心環(huán)境里,流的大小分布和平均利用率是在時間和空間2個維度上同時變化的.在這種條件下,閾值和流量的錯配幾乎是無法避免的.對此,PIAS搜集數(shù)據(jù)中心全局的流量信息來統(tǒng)一計算閾值,并利用交換機的顯式擁塞通知機制來減輕錯配的影響.在2018年的SIGCOMM會議上,香港科技大學(xué)的研究人員進一步提出了AuTO[27],其中一個機制就是通過深度強化學(xué)習(xí)來自動優(yōu)化多級反饋隊列的閾值.
PIAS把所有流都簡單視為不能預(yù)先知道大小且沒有截止完成時間限制的流.事實上,在數(shù)據(jù)中心里面,多種類型的流是共存的.第1類流是有規(guī)定期限的流.對于這種流,流的大小往往也可以預(yù)先知道或者估計出來.第2類流是沒有規(guī)定期限的限制,也無法預(yù)先知道大小的流.對于這種流,PIAS的優(yōu)化效果是最好的.第3類流是沒有規(guī)定期限的限制,但是可以預(yù)先知道大小的流.對于這種流,使用少量優(yōu)先級的pFabric近似方案優(yōu)化效果是最好的.為了解決上述“混合流”(mix-flows)的調(diào)度問題,香港科技大學(xué)的研究人員在2016年的SIGCOMM會議上提出了Karuna[22].嚴格來說,Karuna并不是一個純粹的無信息感知的方案,它只是不知道第2類流的信息.Karuna把有規(guī)定期限的流(第1類)固定在最高優(yōu)先級,以降低期限錯失率.但是為了降低第1類流對于另外2類流的影響,Karuna使用了一種叫作MCP[28]的傳輸層協(xié)議,讓第1類流以較低的吞吐量“恰好”在規(guī)定期限內(nèi)完成.對于沒有規(guī)定期限的限制,也無法預(yù)先知道大小的流(第2類),Karuna采用了多級反饋隊列來調(diào)度,讓一個流在傳輸過程中優(yōu)先級不斷降低.對于沒有規(guī)定期限的限制,但是可以預(yù)先知道大小的流(第3類),Karuna根據(jù)流的大小,賦予它們一個固定的優(yōu)先級,一個流越大,得到的優(yōu)先級就越低.通過對3類流的區(qū)分處理,Karuna可以同時降低流的期限錯失率和平均完成時間.
2.4 其 他
2.1~2.3節(jié)介紹的工作要么側(cè)重基于端主機的擁塞控制,要么側(cè)重基于交換機的仲裁機制,要么側(cè)重網(wǎng)絡(luò)的優(yōu)先級調(diào)度,密歇根州立大學(xué)的研究人員在2014年的SIGCOMM會議上提出了PASE[29],認為這3個機制應(yīng)該結(jié)合起來.PASE同時使用了仲裁、優(yōu)先級隊列和基于ECN的速率控制協(xié)議.與D3和PDQ那樣利用網(wǎng)絡(luò)仲裁每個流的速率不同,PASE把仲裁機制實現(xiàn)在端主機或者交換機的CPU上,計算出每個流在網(wǎng)絡(luò)里的優(yōu)先級和粗粒度的參考速率,再利用基于端主機的速率控制對速率做細粒度控制.因此,PASE不需要對交換機芯片進行修改,而且不用擔心流的發(fā)送速率計算不夠準確的問題.PASE依靠商用交換機上有限的優(yōu)先級隊列來調(diào)度流,并且利用基于ECN的速率控制協(xié)議來充分利用鏈路帶寬.因此,跟D3, PDQ,pFabric相比,PASE不僅更容易部署,而且在許多場景下甚至可以取得更好的性能.
3 趨勢與展望
隨著數(shù)據(jù)中心網(wǎng)絡(luò)的升級換代(如帶寬從1 Gbps增加到10 Gbps再到40 Gbps100 Gbps,基礎(chǔ)往返延遲從幾百微秒降低到幾微秒),傳統(tǒng)的TCP傳輸層協(xié)議及其變型逐漸難以達到預(yù)期的網(wǎng)絡(luò)傳輸性能.一方面,TCP協(xié)議采用了反應(yīng)式的擁塞控制算法,無法勝任流量突發(fā)性更強(大多數(shù)流在幾個RTT內(nèi)就完成了)的高速網(wǎng)絡(luò)傳輸;另一方面,TCPIP協(xié)議棧基于系統(tǒng)內(nèi)核軟件,造成了高CPU消耗和高網(wǎng)絡(luò)協(xié)議棧延遲.針對這2個問題,2015年以來的科研工作分別嘗試采用了接收端驅(qū)動的主動擁塞控制和RDMA網(wǎng)絡(luò)傳輸?shù)姆绞郊右越鉀Q.本節(jié)將分別討論分析這2類工作.表2和表3分別對這2類工作做了比較分析.
3.1 接收端驅(qū)動的主動擁塞控制
數(shù)據(jù)中心網(wǎng)絡(luò)下接收端驅(qū)動的主動擁塞控制(proactive congestion control, PCC)的雛形是由加州大學(xué)伯克利分校的研究人員在2015年的CoNEXT會議上提出的pHost[30].pHost的設(shè)計初衷是以一種可實現(xiàn)的方式達到與pFabric(性能上被認為是當時最優(yōu)的設(shè)計)相近的性能.一種可實現(xiàn)的做法是使用集中式控制器,帶來的問題是調(diào)度時間開銷很大,通常導(dǎo)致小流的完成時間遠遠差于pFabric.另辟奇徑地,pHost將流調(diào)度的任務(wù)放到了數(shù)據(jù)接收端:數(shù)據(jù)發(fā)送方發(fā)送數(shù)據(jù)前請求發(fā)送(request to send, RTS),可以包含相關(guān)調(diào)度信息(如流大小等);數(shù)據(jù)接收方根據(jù)收到的所有請求按照一定的調(diào)度算法分配發(fā)送許可(token或credit或grant或pull);數(shù)據(jù)發(fā)送方按照接收到的發(fā)送許可發(fā)送相應(yīng)數(shù)量的數(shù)據(jù).這樣既保證了商用設(shè)備可實現(xiàn),又達到了可擴展的流調(diào)度,實驗驗證可以達到pFabric相近的性能.
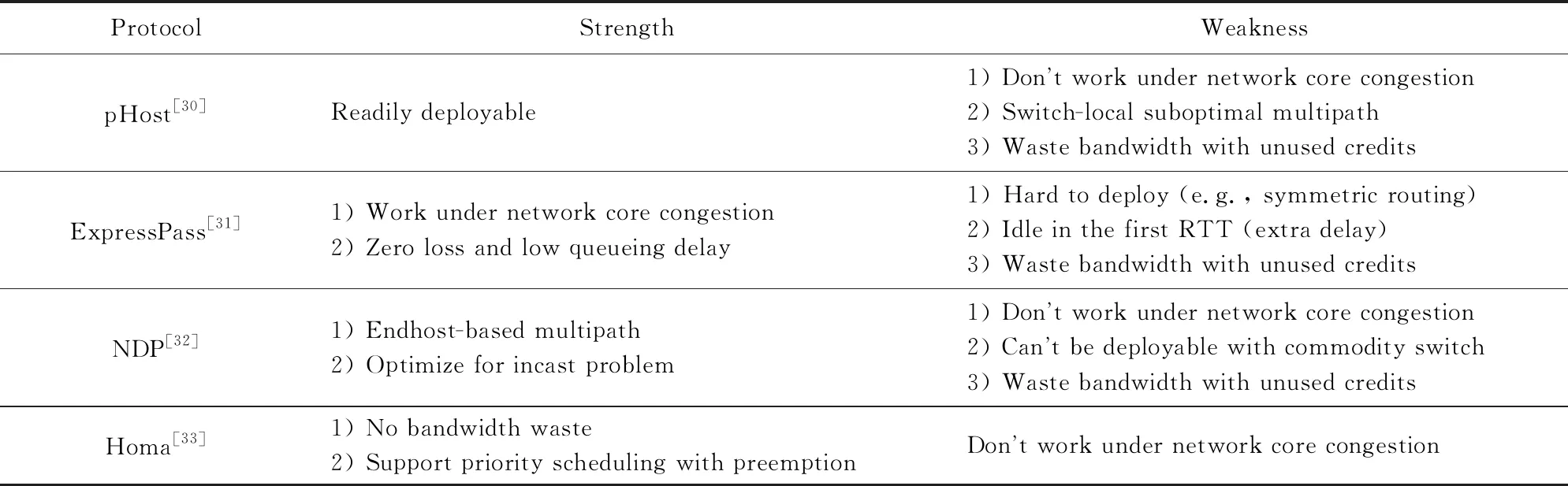
Table 2 Comparison Between Existing Work on Proactive Congestion Control表2 主動擁塞控制的現(xiàn)有工作的比較

Table 3 Comparison Between Existing Work on RDMA Congestion Control表3 RDMA擁塞控制的現(xiàn)有工作的比較
接收端驅(qū)動的主動擁塞控制因為其接近零排隊時延和快速收斂等優(yōu)點被學(xué)術(shù)界和工業(yè)界廣泛關(guān)注.然而,現(xiàn)有的主動擁塞控制設(shè)計仍然存在一些問題.例如,pHost只能解決網(wǎng)絡(luò)擁塞發(fā)生在網(wǎng)絡(luò)邊緣,即發(fā)送端網(wǎng)絡(luò)入口鏈路及接收端網(wǎng)絡(luò)出口鏈路處的情形.它假設(shè)數(shù)據(jù)中心網(wǎng)絡(luò)采用全雙向(full bisection)帶寬和交換機逐包分撒(packet spray[38])鏈路負載衡以達到網(wǎng)絡(luò)內(nèi)部無擁塞.對于網(wǎng)絡(luò)入口處的擁塞,在發(fā)送端上可以解決;對于網(wǎng)絡(luò)出口處的擁塞,則由接收端調(diào)度完美解決.然而,實際數(shù)據(jù)中心網(wǎng)絡(luò)中這一假設(shè)并不一定成立,例如,在發(fā)生鏈路故障導(dǎo)致網(wǎng)絡(luò)不對稱時,網(wǎng)絡(luò)內(nèi)部仍然會發(fā)生擁塞,pHost在這時候?qū)o法發(fā)揮作用.
為了彌補pHost的不足,韓國先進科學(xué)技術(shù)研究院和谷歌的研究人員在2017年的SIGCOMM會議上提出了ExpressPass[31],是一種能夠解決網(wǎng)絡(luò)任意節(jié)點擁塞的主動擁塞控制算法.ExpressPass的數(shù)據(jù)發(fā)送方發(fā)送數(shù)據(jù)前請求發(fā)送;數(shù)據(jù)接收端發(fā)送credit在網(wǎng)絡(luò)中通過獨立的隊列及限速反向模擬數(shù)據(jù)發(fā)送過程,在credit輕微排隊時即丟包;數(shù)據(jù)發(fā)送方按照接收到的發(fā)送許可發(fā)送相應(yīng)數(shù)量的數(shù)據(jù).ExpressPass利用了credit的反向模擬獲取網(wǎng)絡(luò)狀態(tài),限制了隊列深度,避免了真實數(shù)據(jù)包的丟失,同時credit的控制回路可以做得更加激進,從而實現(xiàn)快速收斂.
與此同時,歐洲的研究人員也在2017年的SIGCOMM會議上提出了另一種主動擁塞控制算法NDP[32].NDP在pHost的基礎(chǔ)上使用基于端主機的逐包多路負載均衡機制替代網(wǎng)絡(luò)交換機本地的逐包分撒機制,可以避免因為鏈路故障等原因?qū)е碌木W(wǎng)絡(luò)內(nèi)部的擁塞(但仍然無法解決網(wǎng)絡(luò)拓撲不對稱或核心帶寬不足等導(dǎo)致的網(wǎng)絡(luò)內(nèi)部擁塞問題);同時加入砍去有效載荷(cutting payload, CP)[39]的機制,可以避免在incast等極度擁塞狀況下的長尾部時延.NDP雖然性能上比pHost優(yōu)越,但是卻因為引入CP而失去了商用設(shè)備可實現(xiàn)的優(yōu)點.
斯坦福大學(xué)和麻省理工學(xué)院的研究人員在2018年SIGCOMM會議上提出了Homa[33],對pHost作了進一步的改進.Homa的創(chuàng)新之處有2點:1)它發(fā)現(xiàn)了當pHost發(fā)送端與多個接收端通信并同時收到發(fā)送許可時,部分發(fā)送許可及相應(yīng)的帶寬會浪費的問題.對此,Homa引入了過度承諾(overcommit-ment)的機制,發(fā)送超過網(wǎng)絡(luò)容量的發(fā)送許可來保證網(wǎng)絡(luò)帶寬不被浪費.2)它發(fā)現(xiàn)了pHost在新流到達時不能及時搶占,需要等待一個RTT才能調(diào)整調(diào)度策略的問題.對此,Homa使用了網(wǎng)絡(luò)多優(yōu)先級隊列的機制,從而達到第1個RTT快速搶占,這同時也解決了過度承諾超發(fā)導(dǎo)致的擁塞丟包問題.
現(xiàn)有的基于接收端的主動擁塞控制存在的另一問題是往返時延不同的流共存時發(fā)送許可觸發(fā)的數(shù)據(jù)報文不協(xié)調(diào).原來以計算好的時間間隔發(fā)送的發(fā)送許可,觸發(fā)的數(shù)據(jù)報文可能因為時延不同而同時到達同一條鏈路,產(chǎn)生意外的擁塞.另外,如何將這類設(shè)計應(yīng)用到RDMA和廣域網(wǎng)的場景下也是一個有挑戰(zhàn)的課題,上述因時延不同導(dǎo)致的問題在這些場景下會更加突出.
3.2 RDMA網(wǎng)絡(luò)擁塞控制
為了解決3.1節(jié)的高速低延遲數(shù)據(jù)中心網(wǎng)絡(luò)發(fā)展的問題,特別是TCPIP內(nèi)核軟件協(xié)議棧帶來的性能瓶頸,遠程直接內(nèi)存訪問(remote direct memory access, RDMA)[40]開始被引入到DCN中.RDMA可以將數(shù)據(jù)直接從一臺計算機的內(nèi)存?zhèn)鬏數(shù)搅硪慌_計算機,無需雙方操作系統(tǒng)的介入,因而具有極高的性能.
雖然RDMA技術(shù)已經(jīng)廣泛應(yīng)用于高性能計算(high performance computing, HPC)領(lǐng)域,在DCN中大規(guī)模部署仍然存在一些挑戰(zhàn).一個核心的問題是如何將網(wǎng)絡(luò)傳輸機制集成到RDMA硬件設(shè)備(包括網(wǎng)卡和交換機)中,目前存在3類解決方案:1)IB(InfiniBand)[41].IB使用專用網(wǎng)卡和交換機等硬件實現(xiàn)無損網(wǎng)絡(luò)(即網(wǎng)絡(luò)不丟包),與傳統(tǒng)以太網(wǎng)絡(luò)不兼容.目前廣泛應(yīng)用于HPC領(lǐng)域,難以部署于廣泛基于IP和以太網(wǎng)技術(shù)的DCN.2)iWARP[42].網(wǎng)卡硬件實現(xiàn)了完整的TCP傳輸協(xié)議,支持傳統(tǒng)以太網(wǎng)絡(luò).受限于復(fù)雜的網(wǎng)卡實現(xiàn),基本性能(延遲、吞吐量)被普遍認為弱于RoCE.3)RoCE[43].網(wǎng)卡硬件實現(xiàn)了簡單的傳輸協(xié)議,支持傳統(tǒng)以太網(wǎng)絡(luò),普遍被認為在有損網(wǎng)絡(luò)下性能不佳,通常配合基于優(yōu)先級的流量控制(priority flow control, PFC)使用.然而,使用PFC存在線頭阻塞和死鎖等問題.
數(shù)據(jù)中心網(wǎng)絡(luò)RDMA擁塞控制最早的代表性工作是由微軟、邁絡(luò)思和加州大學(xué)圣塔芭芭拉分校的研究人員在2015年的SIGCOMM會議上提出的DCQCN[34].這也是目前工業(yè)界采用最廣的RDMA擁塞控制算法,已經(jīng)被集成到邁絡(luò)思ConnectX系列網(wǎng)卡上.DCQCN為了支持以太網(wǎng)采用了RoCEv2技術(shù),配合使用了PFC流量控制技術(shù)以保證無損網(wǎng)絡(luò).為了避免頻繁觸發(fā)PFC帶來線頭阻塞和死鎖等問題,DCQCN采用了其核心擁塞控制算法,包括3部分:1)擁塞點(congestion point, CP),即交換機,采用基于RED[44]和瞬時隊列長度的ECN標記算法.2)通告點(notification point, NP),即數(shù)據(jù)接收端,根據(jù)收到數(shù)據(jù)包含的ECN信息返回擁塞通告包(congestion notification packet, CNP).受當時硬件限制,CNP生成間隔(默認為N=50s)只能達到微秒級別,因而很難做到逐包反饋.3)反應(yīng)點(reaction point, RP),即數(shù)據(jù)發(fā)送端,與DCTCP類似,維護了ECN比例的指數(shù)加權(quán)滑動平均值α.每收到CNP則乘性砍α2;每隔K=55s內(nèi)若沒有收到CNP則增加發(fā)送速率.DCQCN擁塞控制算法與DCTCP非常相似,但受硬件條件約束,有2點明顯的不同:一是直接控制發(fā)送速率而非擁塞窗口;二是基于計時器調(diào)整速率而非逐包調(diào)整.這些硬件限制導(dǎo)致的差異給DCQCN的設(shè)計與參數(shù)配置帶來了極大的挑戰(zhàn),該工作在理論上給出了指導(dǎo)原則與證明,但是在實際部署中仍然存在許多問題.
與此同時,谷歌、加州大學(xué)伯克利分校和微軟的研究人員也在2015年的SIGCOMM會議上提出了一套擁塞控制方案TIMELY[35],并圍繞RDMA環(huán)境作了詳細分析與評估.TIMELY是第1個在數(shù)據(jù)中心內(nèi)部采用RTT作為擁塞反饋信號的傳輸控制協(xié)議.TIMELY發(fā)現(xiàn)當前網(wǎng)卡技術(shù)支持精確的RTT測量,并且RTT可以有效反映網(wǎng)絡(luò)擁塞隊列深度.基于這一觀察,TIMELY通過RTT與Tlow和Thigh兩個參數(shù)比較,將核心算法劃分為3部分:1)當RTT小于Tlow時,增加發(fā)送速率;2)當RTT大于Thigh時,減小發(fā)送速率;3)當RTT介于兩者間時,根據(jù)RTT的梯度變化動態(tài)調(diào)整速率.當RTT梯度為正時,說明延遲及擁塞仍在增加,應(yīng)該減小發(fā)送速率;當RTT梯度為負時,說明延遲及擁塞在減小,應(yīng)該增加發(fā)送速率.TIMELY主體部分采用基于RTT梯度的速率調(diào)整算法在性能上廣受爭議,普遍被人認為在動態(tài)網(wǎng)絡(luò)下沒有唯一的收斂點,即有可能在一個很高延遲的范圍內(nèi)收斂[45].
DCQCN依賴于PFC保證網(wǎng)絡(luò)無損,因而存在PFC帶來的各種問題,包括線頭阻塞和死鎖等.對此,許多工作[46-47]嘗試去逐個解決這些問題.2018年在SIGCOMM會議上由加州大學(xué)伯克利分校等的研究人員提出的IRN[36]則反其道而行之,認為網(wǎng)絡(luò)無損或PFC對于以太網(wǎng)上支持RDMA不是根本上不可或缺的.IRN結(jié)合了iWarp和RoCE各自的優(yōu)勢,一方面類似于iWarp,將網(wǎng)絡(luò)可靠性建立在端傳輸協(xié)議而非無損網(wǎng)絡(luò)上;另一方面類似于RoCE,在網(wǎng)卡上實現(xiàn)盡可能簡化的協(xié)議機制.IRN設(shè)計上有2個主要部分:1)高效的丟包恢復(fù),使用選擇重傳取代低效的回退N步(go-back-N)機制,同時采用雙超時重傳定時器減小尾部丟包等問題的影響.2)簡單的流速控制,將發(fā)送數(shù)據(jù)量限制在一個BDP內(nèi),在不浪費帶寬的前提下盡可能地避免擁塞.IRN在仿真器上做了大量實驗證明其在沒有PFC的支持下能夠達到甚至超過使用PFC的DCQCN和TIMELY的性能.然而,IRN目前并未集成到商用網(wǎng)卡中.數(shù)據(jù)中心RDMA網(wǎng)絡(luò)應(yīng)該向無損網(wǎng)絡(luò)還是有損網(wǎng)絡(luò)方向發(fā)展仍然是一個熱門話題.
更進一步地,哈佛大學(xué)和阿里巴巴的研究人員在2019年的SIGCOMM會議上提出了全新的RDMA擁塞控制方案HPCC[37].HPCC發(fā)現(xiàn)RDMA擁塞控制方案存在許多參數(shù),這些參數(shù)的調(diào)整涉及到網(wǎng)絡(luò)吞吐量、延遲和穩(wěn)定性(是否頻繁觸發(fā)PFC等)等性能指標相互之間的利益權(quán)衡.文獻[37]認為這種非此即彼的利益權(quán)衡是由以前的硬件約束(如基于計時器的速率調(diào)整等)導(dǎo)致的,現(xiàn)有硬件技術(shù)的發(fā)展可以打破這種尷尬局面,具體表現(xiàn)在2個方面:一方面,現(xiàn)有網(wǎng)卡有更強大的計算能力和資源,可以支持更精確快速的逐包確認和響應(yīng);另一方面,網(wǎng)絡(luò)交換機有了更開放可自定義的數(shù)據(jù)平面(data plane),比如,可以支持網(wǎng)絡(luò)內(nèi)部自動測量(in-network telemetry, INT),交換機在每個經(jīng)過的數(shù)據(jù)包包頭加入當前時間、隊列長度、歷史發(fā)送數(shù)據(jù)量等信息,幫助端主機作出更精確的擁塞控制響應(yīng).
HPCC擁塞控制主要由2部分組成:1)交換機采用了INT反饋機制,在每個經(jīng)過的數(shù)據(jù)包的包頭加入當前時間、隊列長度、歷史發(fā)送數(shù)據(jù)量等信息;2)端主機擁塞控制同時限制發(fā)送速率R和窗口CWND,速率調(diào)整算法包含加性和乘性調(diào)整2部分.加性部分每個RTT增加固定的發(fā)送速率aiRate,這樣類似于TCP可以保證小流不被餓死,即保證了流競爭的公平性.乘性部分首先基于INT反饋信息計算出網(wǎng)絡(luò)逐跳的鏈路利用率Ui,再根據(jù)逐跳最大的瓶頸利用率maxi(Ui)與設(shè)定的目標利用率Utarget的比值乘性地調(diào)整發(fā)送速率R.為了避免對單一擁塞事件的多次重復(fù)響應(yīng),HPCC還結(jié)合了逐包和逐RTT的速率調(diào)整機制.逐RTT的速率調(diào)整會在每個RTT開始時設(shè)定一個參考速率Rc,逐包的速率調(diào)整則根據(jù)INT反饋圍繞當前RTT下的Rc上下波動調(diào)整速率.這樣在保證快速響應(yīng)的同時,可以避免觸發(fā)不必要的降速和帶寬浪費.
RDMA下的傳輸層設(shè)計仍然有很大的探索空間.如何設(shè)計RDMA傳輸層使得網(wǎng)絡(luò)可以擴展到廣域網(wǎng)中?如何設(shè)計RDMA網(wǎng)絡(luò)下的負載均衡機制?能否在RDMA網(wǎng)絡(luò)卡中使用基于接收端的主動擁塞控制取代傳統(tǒng)的被動擁塞控制?如何處理好傳統(tǒng)TCPIP流量和RDMA流量共存的場景?這些問題的探索和解決將會是未來的研究趨勢.
4 總 結(jié)
近10年來,在盛行的網(wǎng)絡(luò)應(yīng)用(如搜索、在線零售和云計算等)的需求驅(qū)動下,數(shù)據(jù)中心在全球范圍內(nèi)以前所未有的速度和規(guī)模發(fā)展建立起來.特別地,數(shù)據(jù)中心網(wǎng)絡(luò)引起了包括學(xué)術(shù)界和工業(yè)界的廣泛關(guān)注.在此背景下,本文圍繞數(shù)據(jù)中心網(wǎng)絡(luò)中的傳輸層協(xié)議設(shè)計作了詳細的總結(jié)和未來的展望.首先,本文回顧了傳輸層協(xié)議在因特網(wǎng)上的發(fā)展,探討了數(shù)據(jù)中心網(wǎng)絡(luò)和因特網(wǎng)不一樣的特點,以及這些特點給傳輸層協(xié)議設(shè)計帶來的機遇和挑戰(zhàn).隨后,本文探討了早期(2010—2015年)數(shù)據(jù)中心網(wǎng)絡(luò)傳輸設(shè)計方面的工作,主要包括3類——基于端主機的擁塞控制、網(wǎng)絡(luò)仲裁機制和交換機優(yōu)先級調(diào)度.這3類工作在可實現(xiàn)性和性能等方面各有優(yōu)缺點,在各自方向上都有了相當成熟和完善的研究.最后,本文分析了2015年以來數(shù)據(jù)中心網(wǎng)絡(luò)傳輸設(shè)計的研究方向,主要包括2類——接收端驅(qū)動的主動擁塞控制和RDMA傳輸協(xié)議設(shè)計.這2類工作在理論和系統(tǒng)實現(xiàn)上至今仍存在著許多尚未解決的問題,將會成為數(shù)據(jù)中心網(wǎng)絡(luò)傳輸協(xié)議研究的未來趨勢.
猜你喜歡
四川勞動保障(2021年9期)2022-01-18 05:11:08
文苑(2018年21期)2018-11-09 01:23:06
當代陜西(2018年9期)2018-08-29 01:21:00
當代陜西(2017年12期)2018-01-19 01:42:33
暨南學(xué)報(哲學(xué)社會科學(xué)版)(2016年9期)2017-01-15 13:52:00
中國衛(wèi)生(2016年9期)2016-11-12 13:28:08
中國衛(wèi)生(2015年9期)2015-11-10 03:11:12
醫(yī)學(xué)研究雜志(2015年12期)2015-06-10 06:57:46
中國衛(wèi)生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
