應用近紅外光譜法結合波長篩選快速測定煙草綠原酸、莨菪亭和蕓香苷含量
2020-01-02 02:15:20周文忠張峻松高占勇楊盼盼
江西農業學報 2019年12期
關鍵詞:模型
周文忠,張峻松,鄒 悅,劉 靜,高占勇,楊盼盼*
(1.鄭州輕工業大學 食品與生物工程學院,河南 鄭州 450002;2.云南同創檢測技術股份有限公司,云南 昆明 650106;3.紅云紅河煙草(集團)有限責任公司,云南 昆明 650231)
煙草中多酚類物質主要包含:綠原酸、蕓香苷和莨菪亭,其中綠原酸占總多酚含量的75%~90%[1]。多酚在煙草的生長發育、調制特性、煙葉色澤、煙氣香吃味和煙氣生理強度等方面起著重要作用,是衡量煙草品質的一個重要因素[2]。因此,煙草中多酚類物質含量的檢測顯得尤為重要。目前,有文獻[3]報道的煙草中綠原酸、蕓香苷和莨菪亭含量的測定方法主要有高效液相色譜法(HPLC)、紫外可見分光光度法等,這些方法存在檢測成本高、前處理復雜、難以實現快速檢測等問題。
近紅外光譜法[4-5]作為一種快速、綠色、環保的光譜分析方法,已廣泛應用于農業、煙草、食品、制藥和石化等各個行業。近紅外分析技術也被應用于煙草中的多酚含量的快速測定,吳玉萍等[5]挑選244個樣品建立了煙草中總多酚含量的近紅外校正模型,外部驗證集20個樣品的預測值與實測值之間的平均標準偏差為0.10,且近紅外預測值與化學法測定值之間不存在顯著性差異。章平泉等[6]基于36份煙葉樣品的近紅外光譜,對比評價了不同光譜預處理方式和不同建模波段的建模效果。結果表明,綠原酸、新綠原酸和蕓香苷近紅外數學模型外部驗證的平均相對誤差和變異系數(RSD)均在5%以內。冷紅瓊等[7]采集200個樣品的近紅外光譜,使用偏最小二乘法(PLS),選擇7500~4000 cm-1譜段,采用二階導數和Norris濾波法(段長5,段間距3)進行光譜預處理,建立了煙草中綠原酸、蕓香苷、莨菪亭及總多酚的近紅外預測模型。結果表明:近紅外光譜技術與常規標準檢測方法測定值在顯著水平0.05時,不存在顯著性差異。侯英等[8]采用隨機蛙跳算法對建模波長進行了篩選。因此,近紅外光譜技術用于定量分析煙草中綠原酸、蕓香苷、莨菪亭及總多酚具有較強的可行性。
進行近紅外定量分析時,波長選擇是十分必要的[9]。在增加建模樣本量的基礎上,本研究擬采用不同波長篩選算法:7500~4000 cm-1波長范圍[7]、隨機蛙跳算法[8](Random Frog)和間隔隨機蛙跳算法[10](Interval Random Frog),基于模型內部評價參數和外部驗證結果,優選出最佳的波長篩選算法,并用于建立煙草中綠原酸、蕓香苷、莨菪亭近紅外校正模型,以期進一步提高近紅外校正模型的穩定性和預測的準確性。
1 材料與方法
1.1 儀器及材料
近紅外光譜儀:Nicolet Antaris Ⅱ型(美國Thermo Fisher 公司);光譜采集及數據分析軟件:RSULTTM集成軟件和TQ Analyst 8.6(美國Thermo Fisher 公司);光譜數據處理及建模軟件;MATLAB R2010a軟件;樣品旋風磨(美國FOSS公司)。600個陳化煙樣品由云南中煙工業有限責任公司技術中心提供,隨機挑選500個作為校正集樣品,余下100個作為外部驗證集樣。
1.2 方法
1.2.1 多酚含量的測定 參照標準方法[11]測定600個樣品中綠原酸、莨菪亭和蕓香苷含量,作為建立近紅外校正模型的基礎數據。
1.2.2 樣品前處理及近紅外光譜的采集 參照標準方法[12]對樣品進行預處理。設置儀器參數,采集樣品近紅外光譜。
1.2.3 異常樣品的挑選及光譜數據預處理 采用TQ Analyst 8.6軟件對樣品近紅外光譜進行預處理,預處理方法:多元散射校正(MSC)+二階求導+Norris(5,3)平滑[13];基于蒙特卡羅采樣的奇異樣本回歸診斷[14],采用MATLAB R2010a軟件對校正集樣本中奇異樣本進行挑選。
1.2.4 特征波長變量的篩選及變量數的確定 采用間隔隨機蛙跳算法、隨機蛙跳算法篩選建立煙草中多酚成分(綠原酸、莨菪亭和蕓香苷)近紅外校正模型的特征波長。間隔隨機蛙跳算法和隨機蛙跳(Random Frog)算法[15]參數為迭代次數N=10000;開始運算的變量數Q=40。利用最小的交叉驗證均方差(RMSECV)確定較優的波長變量數[16]。
1.2.5 校正模型的建立及評價 基于間隔隨機蛙跳算法、隨機蛙跳算法篩選的特征波長和7500~4000 cm-1范圍波長,分別采用偏最小二乘法(Partial Least Squares, PLS)建立煙草中綠原酸、莨菪亭和蕓香苷的近紅外校正模型。由交互驗證的均方差(Root Mean Square Error of Cross Validation, RMSECV)最小值決定偏最小二乘法(PLS)適宜主因子數。
校正模型的評價參數[17]:模型的決定系數(R2);校正均方根誤差(Root Mean Square Error of Calibration, RMSEC);交叉驗證均方差(Root Mean Square Error of Cross Validation, RMSECV);外部驗證采用預測平均相對誤差參數進行評價,以上過程均采用MATLAB R2010a軟件完成。
2 結果與討論
2.1 光譜預處理及異常樣品的挑選
在建立校正模型之前對數據進行奇異值檢測,剔除異常樣品可以提高模型的穩健性[18]。模群迭代奇異樣本診斷[14]是一種基于奇異樣本點對預測殘差和預測誤差很敏感的原理,采用預測誤差的分布為依據的診斷方法。光譜預測誤差的均值-方差分布如圖1所示(以綠原酸為例)。由圖1可知,異常樣本(outlier)個數為5個(樣品編號:9、123、124、215和270),剔除異常樣品后剩下的樣本集樣品595個(校正集樣品:495個,驗證集樣品:100個)。采用上述方法對莨菪亭和蕓香苷的異常樣品進行剔除,莨菪亭和蕓香苷樣品均剔除異常樣品4個,剔除異常樣品后剩下的樣本集樣品596個(校正集樣品:496個,驗證集樣品:100個)。建模集樣品中綠原酸、莨菪亭和蕓香苷含量范圍分別為6.70%~28.71%、0.08%~0.71%和4.42%~17.07%。
剔除異常樣品后,樣品原始近紅外漫反射光譜經多元散射校正(MSC)+二階求導+Norris(5,3)平滑預處理后的光譜如圖2所示。由圖2b可知,經預處理后的近紅外光譜在10000~9000 cm-1存在高頻噪聲,在進行近紅外校正模型建立時應將此波段排除在外,因此選擇9000~4000 cm-1波數范圍內的光譜數據進行特征波長或波段的篩選。
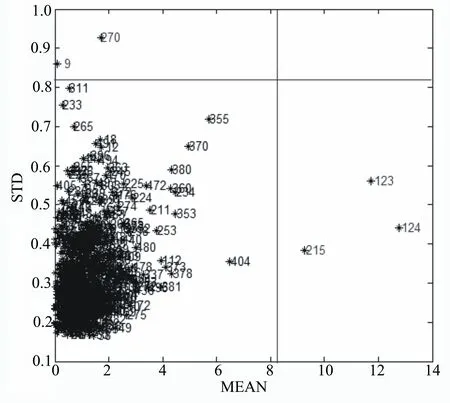
圖1 綠原酸近紅外校正模型模群迭代奇異樣本診斷圖
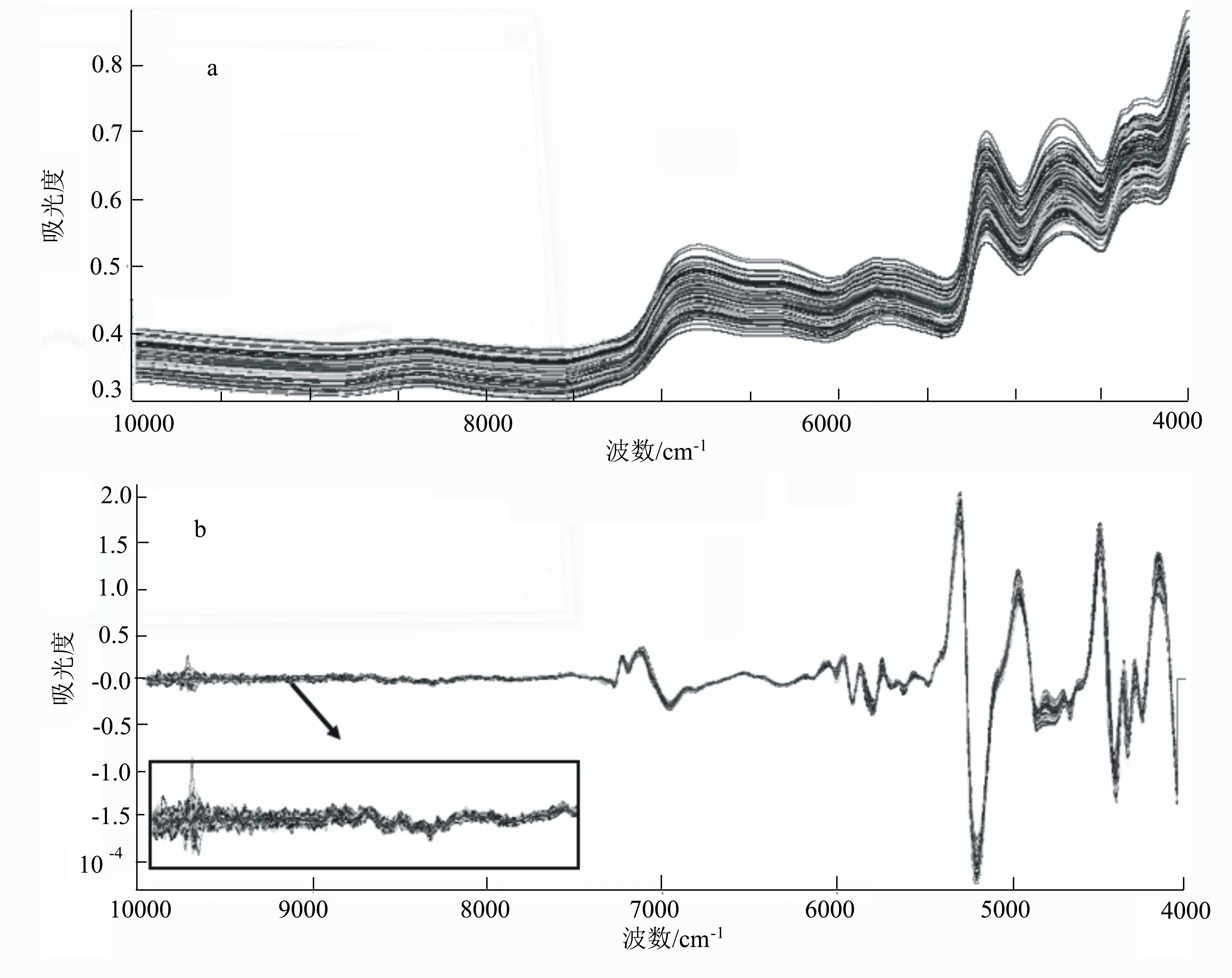
圖2 代表性樣品近紅外漫反射光譜(a)和經預處理后(b)的光譜圖
2.2 特征波長變量的篩選
隨機蛙跳算法能夠利用少量的變量迭代進行建模,是一種非常有效的高維數據變量選擇方法。間隔隨機蛙跳算法是一種基于隨機蛙跳算法,性能更加優越的波長變量篩選算法。兩種方法通過輸出每個變量選擇可能性,根據變量重要性進行波長選擇。采用隨機蛙跳和間隔隨機蛙跳算法分別對煙草中綠原酸、莨菪亭和蕓香苷近紅外校正模型的特征波長點進行提取,不同的波長點有不同的選擇概率。以莨菪亭為例,不同波長點被選取的概率如圖3所示。
由圖3可知,間隔隨機蛙跳波長篩選算法較隨機蛙跳算法篩選出被選擇概率大的波長點分布更為集中。通過模型交叉驗證均方差(RMSECV)隨變量數增加的變化情況,在RMSECV取得最小值時確定為較優的變量數。以綠原酸為例,RMSECV隨波長變量數增加變化的趨勢如圖4所示。隨機蛙跳算法和間隔隨機蛙跳算法選出的莨菪亭近紅外校正模型最優變量數分別為273和147。隨機蛙跳算法和間隔隨機蛙跳算法選出的綠原酸和蕓香苷近紅外校正模型較優的變量個數依次為:262、198和283、175。依據變量重要性分別選擇最優建模波長數作為校正模型輸入變量。
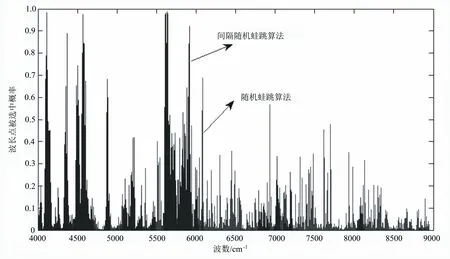
圖3 采用蛙跳算法和間隔蛙跳算法計算出的不同波長點變量的選擇概率
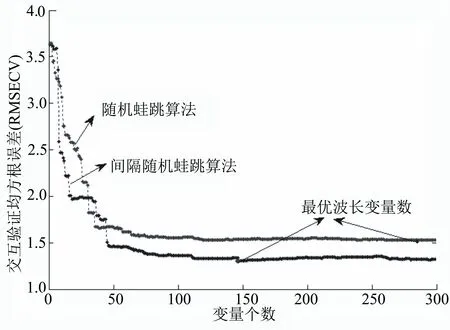
圖4 交叉驗證均方差(RMSECV)隨變量數的變化
2.3 校正模型的建立及評價
為評價不同波長(波長點)變量條件下建立的煙草多酚校正模型的精度。本研究選擇7500~4000 cm-1波長變量及通過隨機蛙跳算法和間隔隨機蛙跳算法篩選出波長點變量,分別采用偏最小二乘法(PLS)建立煙草中多酚類化合物綠原酸、莨菪亭和蕓香苷的近紅外校正模型。
以綠原酸校正模型為示例,隨機蛙跳和間隔隨機蛙跳算法篩選波長變量建立校正模型中交互驗證均方差(RMSECV)隨主成分數的變化見圖5。由圖5可知,隨著主成分數的增加,兩種算法篩選波長變量建立近紅外校正模型的RMSECV逐漸降低,取得RMSECV最小值時對應的主成分數為最優的建模主成分數。隨機蛙跳算法和間隔隨機蛙跳算法最優的主成分數分別為11和12。
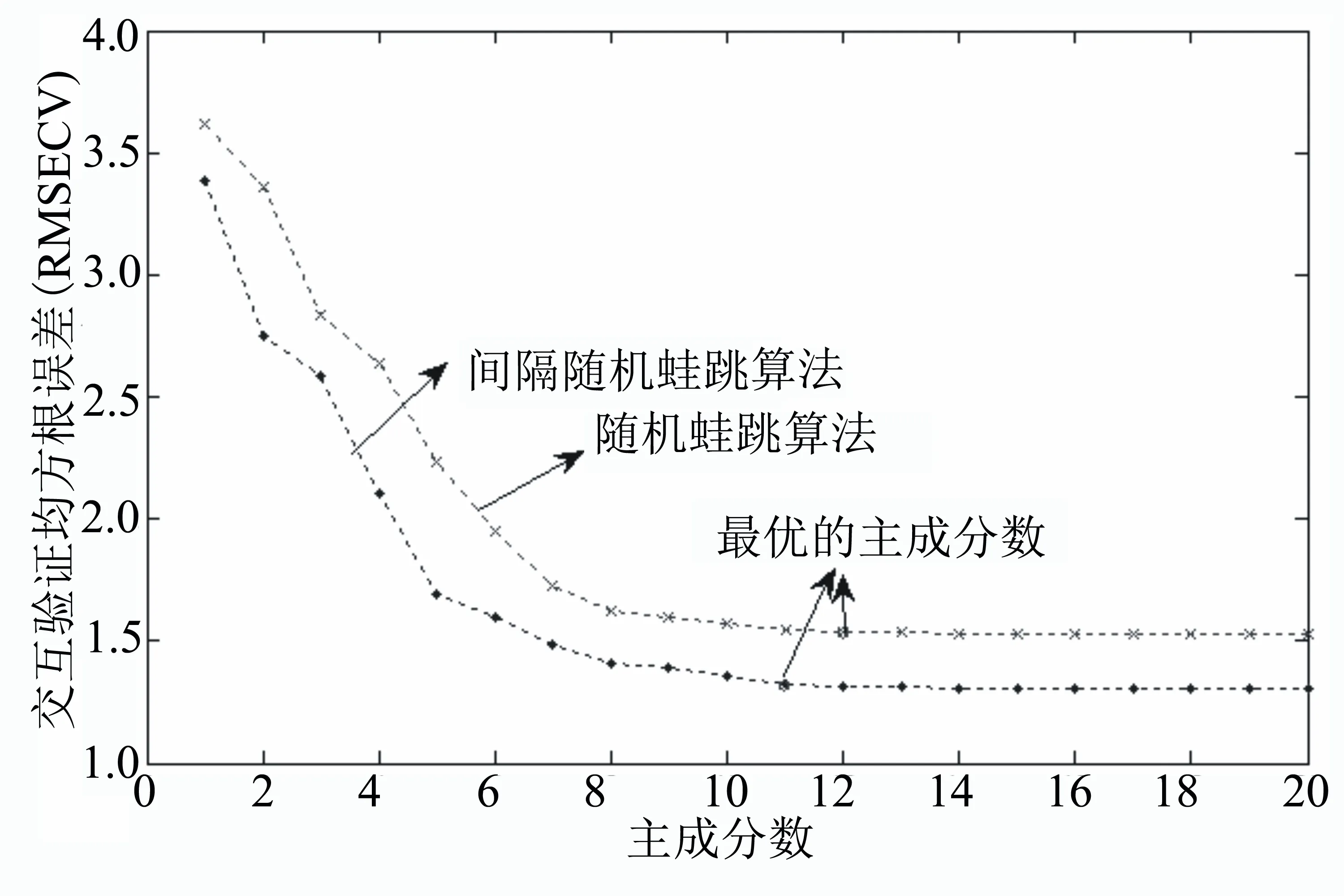
圖5 煙草中綠原酸的近紅外校正模型交互驗證均方差(RMSECV)隨主因子的變化
以綠原酸校正模型為例,分別采用7500~4000 cm-1光譜波長變量+PLS、Random Frog+ PLS和Interval Random Frog+PLS所建立校正模型的效果如圖6~圖8所示。莨菪亭、綠原酸和蕓香苷依照上述步驟方法建立近紅外校正模型的內部評價參數(表1)和用100個外部驗證集預測的相對標準偏差(表2)。
由圖6~圖8和表1~表2可知,在光譜預處理方式、校正集樣本、驗證集樣本和建模參數一致的條件下,以綠原酸為例,對比3種不同波長或波長篩選算法:7500~4000 cm-1、Random Frog和Interval Random Frog,決定系數由0.9462增加至0.9721;校正集的均方估計殘差由1.1458降低到0.7741;交互驗證均方差由1.1254降低到0.8210。100個外部驗證集預測平均相對誤差由8.337%降低到7.025%。3種波長或波長篩選算法建立的煙草莨菪亭和蕓香苷近紅外校正模型建模效果對比與綠原酸相似。以上結果表明,采用Interval Random Frog+PLS建立的近紅外校正模型的內部評價參數(決定系數、均方估計殘差RMSEC和交互驗證均方差RMSECV)優于Random Frog+ PLS方法,后者又優于7500~4000 cm-1光譜波長變量+PLS。100個外部驗證集樣品驗證結果表明Interval Random Frog+PLS優于Random Frog+ PLS方法,后者又優于7500~4000 cm-1光譜波長變量+PLS。
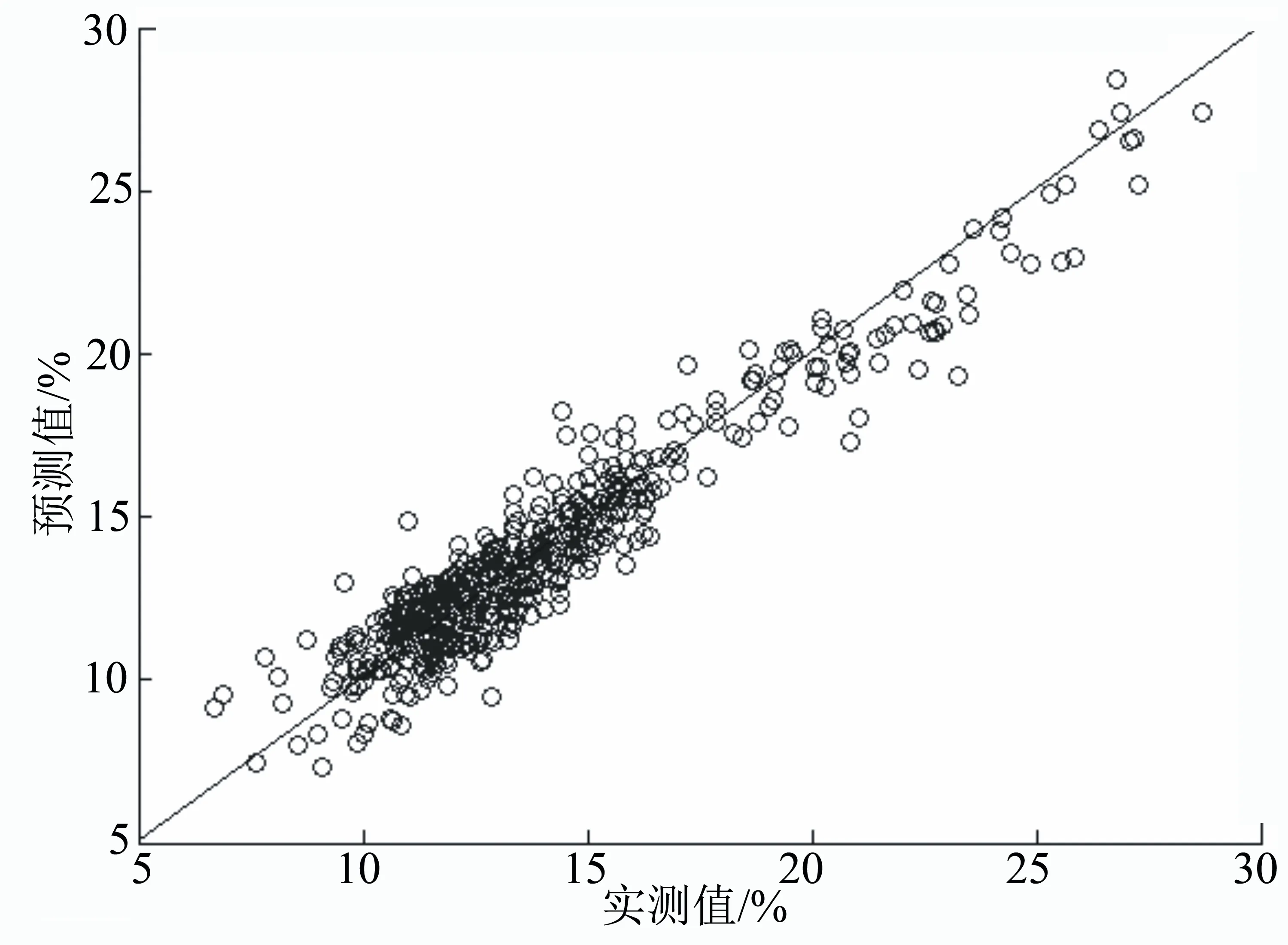
圖6 煙草中綠原酸近紅外校正模型效果圖(7500~4000 cm-1+PLS)
3 結論
基于相同光譜預處理和建模方法,相同的校正集和驗證集樣品光譜分別通過7500~4000 cm-1、隨機蛙跳算法篩選和間隔隨機蛙跳算法篩選波長點變量建立煙草中綠原酸、莨菪亭和蕓香苷的近紅外校正模型,并對建模效果進行內外部評價。結果表明采用間隔蛙跳篩選輸入變量時,模型的穩定性和預測準確性最優。通過波長優選進一步提升了煙草綠原酸、莨菪亭和蕓香苷近紅外校正模型的穩定性和準確性,為該方法的推廣應用奠定了基礎。
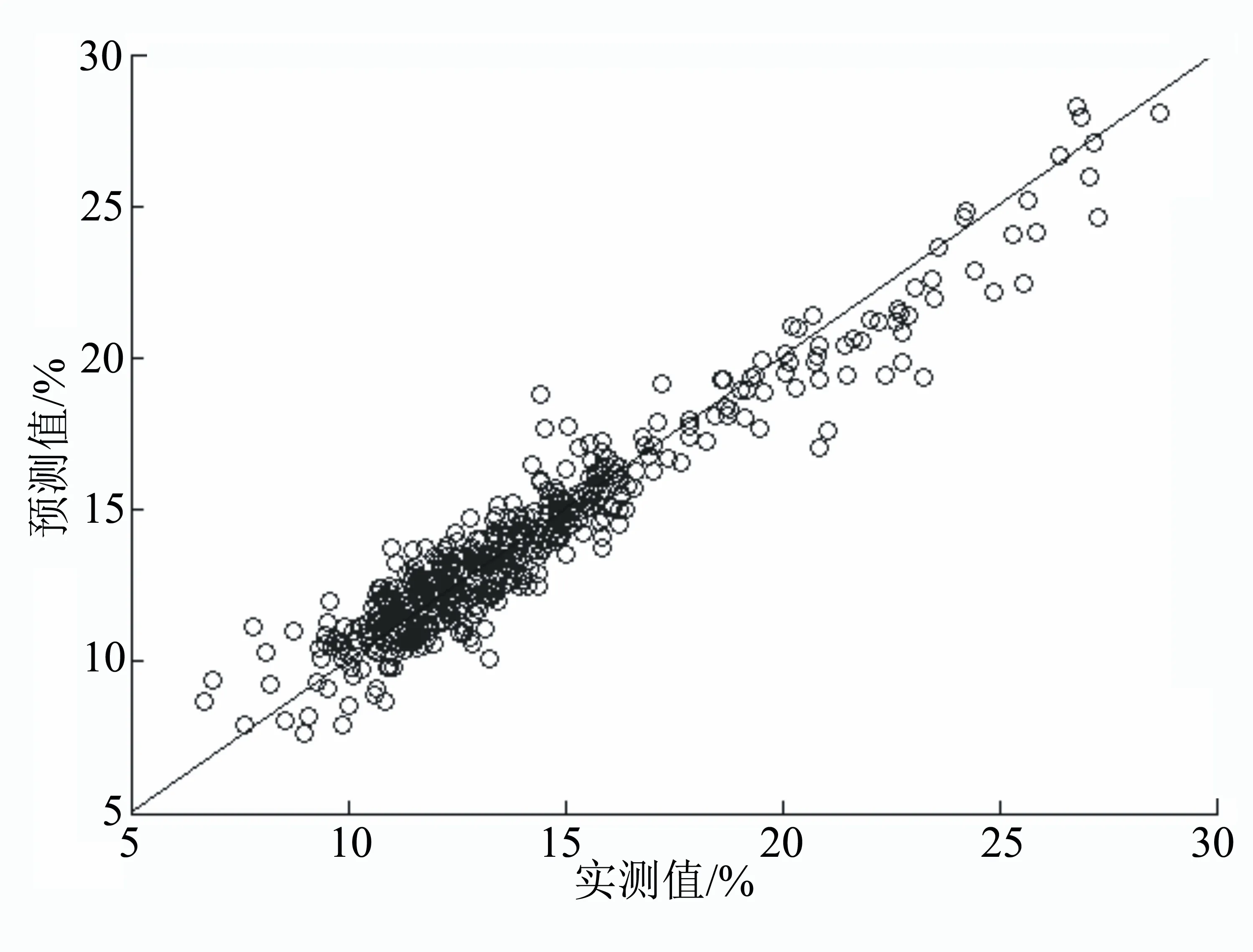
圖7 煙草中綠原酸近紅外校正模型效果圖(Random Frog+PLS)
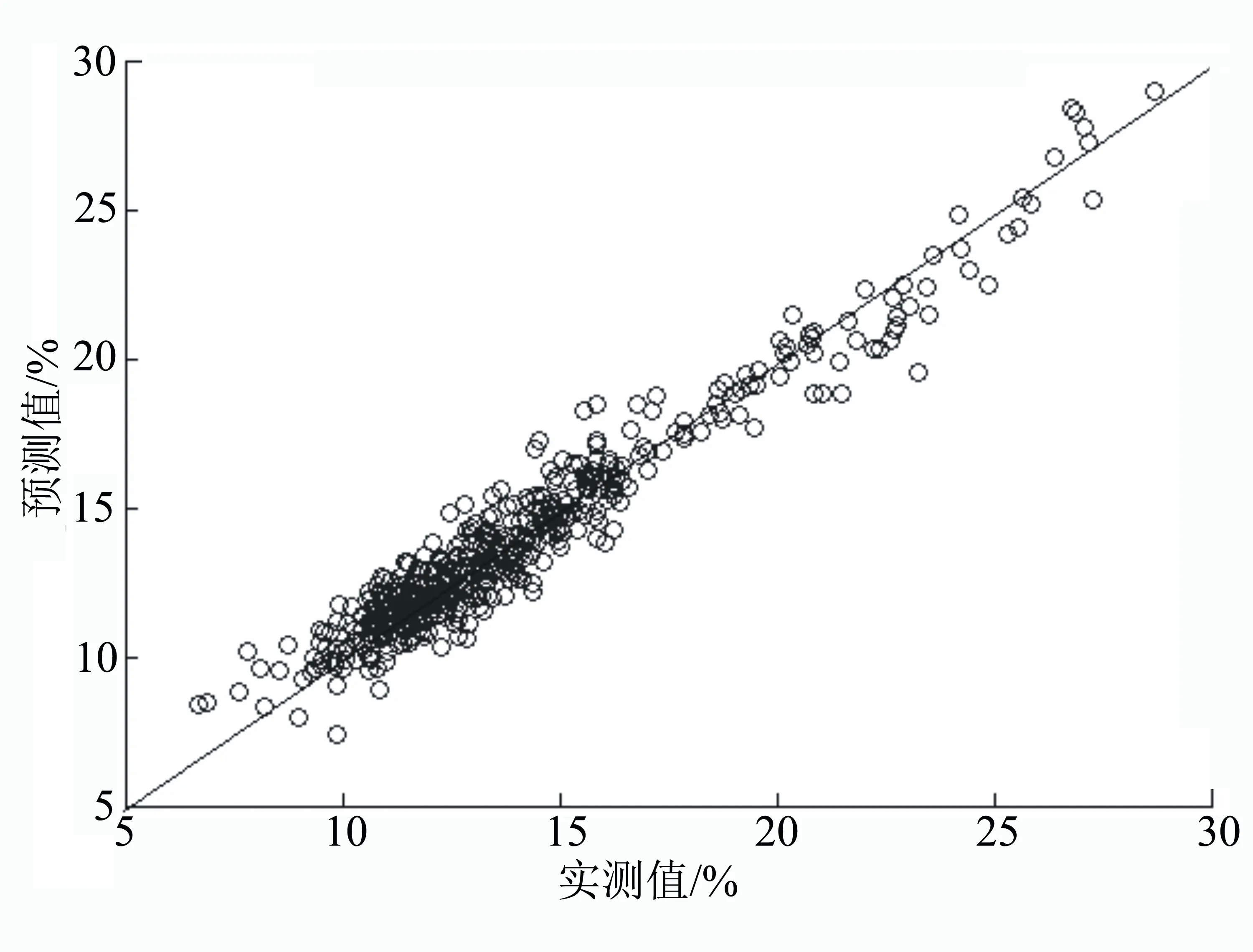
圖8 煙草中綠原酸的近紅外校正模型效果圖(Interval Random Frog+ PLS)
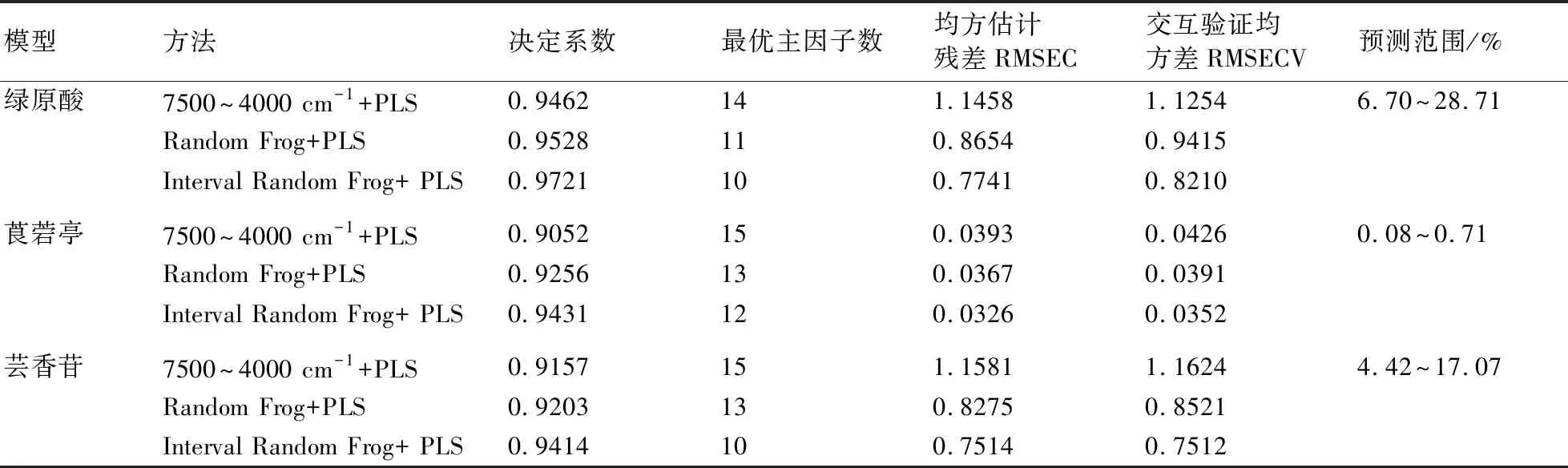
表1 不同建模輸入變量條件下建立的煙草中綠原酸、莨菪亭和蕓香苷近紅外預測模型評價指標的比較

表2 不同建模輸入變量條件下建立的煙草中綠原酸、莨菪亭和蕓香苷近紅外預測模型外部驗證評價指標的比較
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
