分布式NameNode在云存儲平臺中的應用
2019-12-10 09:48:22丘剛瑋黃欣
電腦知識與技術 2019年28期
丘剛瑋 黃欣

摘要:為了解決HDFS單一NameNode處理大批量并發訪問的瓶頸問題,論文提出了一種基于MongoDB數據庫的分布式NameNode節點架構,增強節點的處理能力,進一步提高了HDFS集群的性能。實驗結果表明:基于MongoDB數據庫的分布式NameNode節點架構方案不僅有效擴展了HDFS的命名空間,同時提高了HDFS集群的并發讀寫能力。
關鍵詞:MongoDB;分布式存儲;單一NameNode節點;HDFS
中圖分類號:TP393? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2019)28-0040-03
Abstract: Aiming at the bottleneck of concurrent access of HDFS single NameNode, a distributed NameNode architecture based on MongoDB database is proposed. It improves the processing capacity of nodes and the performance of HDFS cluster. The experimental results show that the approach of MongoDB and distributed NameNode not only extends the namespace of HDFS effectively, but also improves the concurrent reading and writing ability of HDFS cluster.
Key words: MongoDB; distributed storage; single NameNode; HDF
HDFS(Hadoop Distributed File System)是Google GFS開源的Hadoop分布式文件系統,可存儲海量大數據,由于其具有高可靠性、高可用性、高伸縮性等特性,目前已經成功應用于航空安全QAR(Quick access recorder)數據分析[1]、醫學影像存儲[2]、預測模型[3]、云儲存系統平臺實現[4]等多個領域。由于單一NameNode限制導致的性能問題,HDFS在實際應用過程中漸漸暴露不足之處。眾多學者針對此問題進行多方面的改進,文獻[5]的改進方法是在DataNode 節點中存儲小文件的元數據信息;文獻[6]采用元數據壓縮打包方式來減少元數據的大小;文獻[7]在另一臺服務器存放元數據塊到Datanode的映射信息,以降低NameNode的壓力。這些改進有效地減少了NameNode節點的讀寫請求,在一定程度上減緩了單一NameNode性能問題。但是這些改進方法的本質不變,還是由一個主節點NameNode控制訪問交互[8]。隨著文件數量級增長,大批量并發訪問,單一NameNode節點的連接數和處理能力將受到極大的挑戰,導致整個HDFS集群性能瓶頸。為了從本質上解決單一NameNode限制問題,基于MongoDB數據庫對其架構進行優化,以便能夠支持多NameNode節點。
1 單一NameNode的HDFS分析
現有HDFS使用的是主/從架構,一個HDFS集群包括了單一NameNode節點及大量DataNode節點。NameNode節點管理和維護所有的命名空間和元數據信息。當Client訪問HDFS集群時,由NameNode控制訪問交互,再執行實際數據操作,可以說整個HDFS集群僅僅一個入口點。所以,NameNode節點相當于是整個集群的核心和關鍵。此外,DataNode節點還可以與Client及另外的DataNode節點進行交互。為了避免單一NameNode節點限制問題,HDFS盡可能減少了Client對NameNode節點的操作。Client在讀寫數據時,首先向NameNode節點獲知元數據信息,然后根據這些信息直接與DataNode節點交互,進行讀寫數據。雖然盡可能使NameNode輕量級,但元數據信息仍然占文件系統超過一半以上。隨著HDFS運行的任務數量的增加,NameNode的負荷變得越來越重,必定影響文件系統整體性能。Client對HDFS的操作都必須先向NameNode節點請求,雖然客戶端只需獲知較少的元數據信息,但如果同一時間有非常多的請求,NameNode的負荷非常重,有些Client的操作就無法及時響應,這就是HDFS關于單一NameNode的性能問題核心所在。
2 可擴展的多NameNode節點優化原理
2.1 優化難點分析
在現有的HDFS架構中單一NameNode節點是HDFS的主要服務器,負責管理管理和維護整個文件系統的命名空間和元數據信息,分工明確。Client對HDFS集群發送請求時都必須先和NameNode交互才能與相應的DataNode節點進行實際的數據操作。即把單一NaneNode架構優化為多NameNode節點的架構關鍵之處主要有以下三點:如何命名分布式NameNode,當單一NameNode節點變為到多NameNode節點時,多NameNode節點該如何命名以及分布;如何定位有關文件元數據信息的位置,當Client發起讀某一文件請求時,如何快速定位NameNode節點并獲取其元數據信息,進一步獲取DataNode節點信息讀取相關文件;數據一致性問題,當Client與某一個NameNode節點的對其元數據信息進行更改操作,其他的NameNode節點如何實時獲取同樣的更改并作出一樣的更改操作。
2.2 基于MongoDB的解決方案
Mongodb是一種分布式NoSQL數據庫,基于C++語言,可支持關系型數據庫的絕大多數操作,可存儲多種格式的數據類型[9]。MongoDB數據庫兼具存儲性能高、易部署、易于使用、功能豐富、支持索引等優點。非關系型數據庫可在HDFS上部署,相對于傳統關系型數據庫,NoSQL數據庫部署在分布式集群上,增加了可存儲的數據量,可以維護更多的DataNode,擴展性更強,并減少了對單個節點的通信壓力。
引入MongoDB的優化方案,把整個文件系統的命名空間以及元數據信息的控制由NameNode轉化為MongoDB數據庫中,采用星型狀將多個NameNode節點與MongoDB連接,每個NameNode節點相當于只是負責整個文件系統一部分命名空間,所有NameNode的元數據信息的集合才是整個文件系統的命名空間和元數據信息。當啟動HDFS集群時,將重構有關數據塊和DataNode節點間的映射信息,并將其記錄到MongoD數據庫。規定某個指定的Client只能和某個指定的NameNode進行交互,各個NameNode間沒有交互,保證文件系統的一致性。其架構如圖1所示:
當Client發起請求時,先與其中一個NameNode節點連接,根據命名空間查看是否存在所需的元數據信息,如果無,則對MongoDB數據庫進行查詢,獲取相應文件名的元數據信息(文件名和數據塊間映射,數據塊和DataNode節點間映射),將其加載到NameNode節點內存中。當Client下次訪問該文件的時,可直接在NameNode節點獲取相關的元數據信息,就不用再對MongoDB進行訪問,即“一次加載,多次讀取”,相當于原始的單一NameNode節點同Client和DataNode節點進行交互。
在寫數據時,實時更新當前NameNode的元數據信息,利用延遲寫的策略將系統更改后的元數據信息寫入MongoDB數據庫中,以便有效減少地寫數據庫造成的延時。
3 MongoDB和分布式NameNode節點優化
設計每一個NameNode的元數據信息一開始都是空的,實際整個文件的命名看空間和元數據信息都在MongoDB數據庫中,每個NameNode在首次使用時先在MongoDB數據庫中加載所需信息,在元數據發生變化時,該數據實時更新到數據庫中,并通知其他NameNode節點。
對于整個系統的元數據信息存儲在MongoDB數據庫,分析MongoDB和分布式NameNode節點優化方案的讀寫過程。
3.1 讀文件操作
基于MongoDB數據庫和HDFS優化方案有關讀文件操作過程如下:
(1) Client發送讀請求,通過open()函數打開文件,并創建Distributed File System對象。
(2) Client創建讀取相應文件數據信息的FSData Input Stream對象,利用read()函數來向FSData Input Stream對象傳遞用戶的請求信息。
(3) HDFS的FSData Input Stream對象接收用戶請求后與NameNode節點交互,獲取該用戶的數據塊地址信息。
(4) NameNode根據FSData Input Stream對象傳送過來的請求信息判斷該用戶的數據塊的信息是否存在,如果存在,則向Client端的FSData Input Stream對象返回該用戶的數據塊的信息;如果不存在,NameNode節點就去Mongo DB數據庫中讀取所需的數據塊信息,并將此信息保存在NameNode中,然后再向Client端的FSData Input Stream對象返回該用戶的信息。
(5) FSData Input Stream對象接收返回的數據塊文件的地址信息后向該用戶的DataNode節點發出read()請求,讀取用戶所需要的元數據信息,并呈現給用戶,此時利用close()函數關閉讀取數據流,HDFS讀操作完成。
3.2 寫文件操作
基于MongoDB數據庫和HDFS優化方案有關寫文件操作過程如下:
(1) Client發起寫請求,利用open()函數來打開文件,并建立Distributed File System對象。
(2) 利用create()方法創建文件上傳的FSData Output Stream數據流對象。
(3) 向特定的NameNode發送新建文件目錄的請求,該文件條目下是空的。優化后的方案存在多個NameNode,必須事先指定不同的NameNode。
(4) NameNode節點接收請求信息后根據Client身份判斷是否有操作權限,再判斷所需文件條目是否存在,若有則不創建;若無則創建。
(5) 把用戶數據與DataNode數據節點對應,并依次寫入相應的數據塊文件。
(6) 當DataNode節點存儲完成后向FSData Output Stream對象返回確認。
(7) Client的FSData Output Stream對象將文件名和數據塊間映射,數據塊和DataNode節點間映射等元數據信息存入相應的NameNode節點,NameNode節點再將該元數據信息持久化到MongoDB數據庫中。
(8) 待需要上傳的文件完成后,Client會執行close()函數關閉寫操作流,HDFS寫操作完成。
4 實驗結果與分析
4.1 實驗環境配置
在單一NameNode節點限制優化測試方案中,選用兩臺物理機上架構HDFS系統,即NameNode的配置為Inter(R) Xeon(R) CPU E5-1620 v3 @3.5 GHz,內存為512M,分別命名為NameNode1和NameNode2,MongDB所在服務器的配置為Inter(R) Xeon(R) CPU E5-1620 v3 @3.5 GHz,MEM為2.0GB。
4.2 實驗參數設置
針對并發訪問處理的實驗設計,對于改進前的方案,模擬12個Client進程,對HDFS并發讀寫操作;對于改進后的方案,模擬6個Client進程訪問NameNode1,6個Client進程訪問NameNode2。設定文件讀寫規模為1000、3000、5000、10000、15000,每個Client進程分別對改進前后的系統并發讀寫,并分別其記錄寫入時間。
4.3 結果分析
4.3.1 并發讀寫文件速度對比
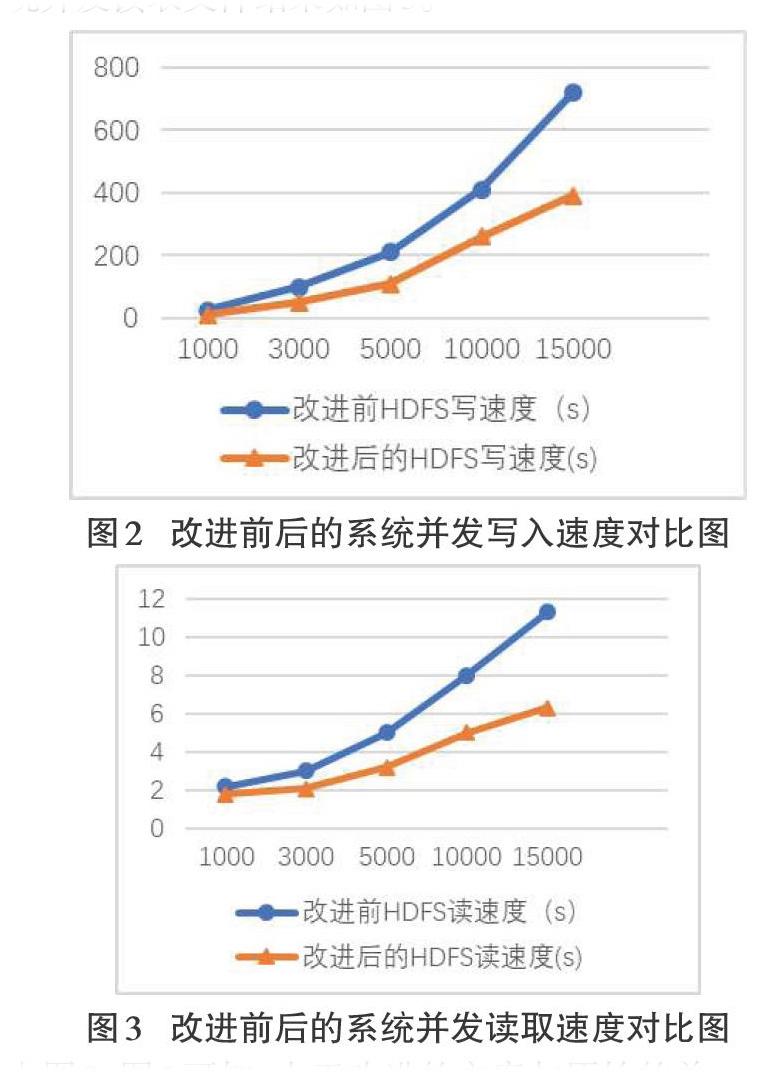
改進前后的系統并發寫入文件結果如圖2所示,改進前后的系統并發讀取文件結果如圖3。
由圖2、圖3可知,由于改進的方案與原始的單一NameNode方案不同,采用了基于MongDB數據庫的NameNode1和NameNode2多個NameNode,使得系統能夠在處理進行并發讀寫請求,尤其是文件數據量比較多的情況下,分布式NameNode節點的處理能力優勢比較明顯。
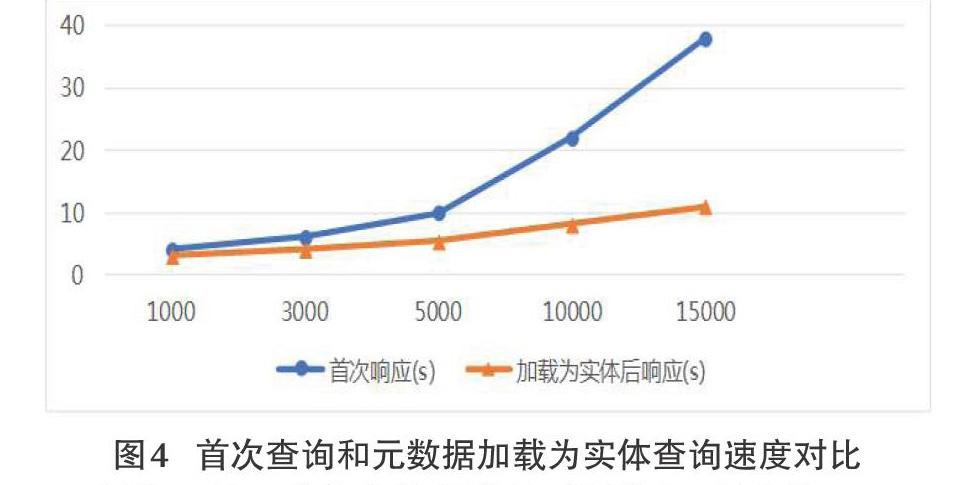
4.3.2 首次響應和元數據加載為實體響應
上述實驗是基于所有的元數據都存在NameNode中的并發讀時間,由于NameNode進行首次查詢元數據的時候,先查詢MongDB數據庫的信息。所以,需要測試首次響應和元數據加載為實體后響應延遲時間,文件規模同上。實驗結果如圖4。
由圖4可知,隨著文件規模的不斷增大,首次從MongoDB里加載元數據信息延遲比較嚴重。但是,由于元數據信息在首次加載后,之后的操作就不必去查詢數據庫,所以,即可以“一次加載,多次讀取”,在實際應用中這些延遲基本是可以忽略不計的。
綜上,在大規模文件數據下,分布式存儲的優勢比較明顯,分布式NameNode+MongoDB方式響應時間最快,并使得HDFS的命名空間得到擴展。
5 結束語
HDFS分布式文件存儲由單一NameNode節點控制多個DataNode節點的存儲方式容易在單一NameNode節點出現瓶頸問題。分布式NameNode+MongoDB方案的核心思想將HDFS集群中由原來的一個NameNode節點控制的架構優化成多個NameNode控制。該方式既保證了整個集群數據信息的完整性又有效地減輕了單一NameNode節點的負荷,進一步擴展了HDFS的命名空間,同時提高了HDFS集群的并發讀寫能力。
在以后的工作中,將對改進HDFS進行更深入的研究,如解決分布式NameNode負載均衡的問題。
參考文獻:
[1] 馮興杰, 吳稀鈺. HDFS可視化及其在QAR數據中的應用研究[J]. 中國民航大學學報,2017,35(01):56-59.
[2] 方勝吉, 李憶昕, 周姍姍. 探析HDFS在區域醫學影像存儲上的應用[J]. 電腦編程技巧與維護, 2017(22):89-90.
[3] 于磊春, 陳健美, 劉響, 等. 基于預測模型的HDFS集群負載均衡優化與研究[J]. 計算機應用與軟件, 2018 (05):155-162.
[4] 陳虎. 基于HDFS的云存儲平臺的優化與實現[D]. 華南理工大學, 2012.
[5] Jiang L , Li B , Song M . THE optimization of HDFS based on small files[C]// IEEE International Conference on Broadband Network & Multimedia Technology. IEEE, 2011.
[6] Mackey G , Sehrish S , Wang J . Improving metadata management for small files in HDFS[C]// IEEE International Conference on Cluster Computing & Workshops. IEEE, 2009.
[7] 欒亞建. 分布式文件系統元數據管理研究與優化[D]. 華南理工大學, 2010.
[8] 高考數據分布式存儲優化的設計與實現[D]. 山東師范大學,? 2017.
[9] 曾強, 繆力, 秦拯, 等. 面向大數據處理的Hadoop與MongoDB整合技術研究[J]. 計算機應用與軟件, 2016(2): 21-24.
【通聯編輯:代影】
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中華手工(2017年2期)2017-06-06 23:00:31
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中外會展(2014年4期)2014-11-27 07:46:46
