遙感影像目標的尺度特征卷積神經網絡識別法
2019-10-30 01:01:54董志鵬李德仁王艷麗張致齊
測繪學報 2019年10期
董志鵬,王 密,2,李德仁,2,王艷麗,張致齊
1. 武漢大學測繪遙感信息工程國家重點實驗室,湖北 武漢 430079; 2. 地球空間信息協同創新中心,湖北 武漢 430079
隨著地對地觀測技術的發展,高分辨率遙感影像的數據獲取量越來越大,且已被廣泛用于城市規劃、災害監測、農業管理和軍事偵察等方面[1-3]。在大數據條件下,如何自動化、智能化地實現高分辨率遙感影像目標檢測與識別,對高分辨率遙感影像應用價值的發揮具有重要影響[4]。為此,國內外學者開展了大量的研究,其中許多研究方法主要使用人工設計的影像目標特征進行目標檢測與識別,如梯度直方圖(histogram of oriented gradient,HOG)[5]、局部二值模式(local binary patterns,LBP)[6]、尺度不變特征變換(scale-invariant feature transform,SIFT)[7]和Gabor[8]等特征,然后將這些特征以特征量的形式輸入到傳統的分類器,如支持向量機(support vector machine,SVM)[5,7]、AdaBoost[9]、決策樹[10]等進行分類,在特定的目標識別任務中取得了較好的效果。但由于遙感衛星復雜多變的拍攝條件,傳統的目標檢測與識別算法難以適應不同情況下的遙感影像,算法的穩健性、普適性較差[11-12]。
近年來,卷積神經網絡(convolutional neural networks,CNN)作為最熱門的深度學習模型算法,其不需要人為設計目標特征,且會根據海量數據和標注自行進行有效特征提取和學習[13-14]。在訓練數據充足的情況下,模型具有良好的泛化能力,能夠在復雜多變的條件下依然保持良好的穩健性[15-16]。因此,卷積神經網絡模型已被廣泛應用于圖像目標檢測與識別領域。如文獻[17]提出regional CNN(RCNN)算法,該算法將候選區域提取算法與CNN相結合,首先使用selective search算法提取圖像的候選區域,然后通過CNN對候選區域進行特征提取,最后根據特征使用SVM進行區域分類,實現圖像的目標檢測與識別。文獻[18]為了減少文獻[17]中CNN對重疊候選區域的重復計算,提出spatial pyramid pooling net(SPPNet)算法。該算法只對CNN最后一層卷積層特定區域進行一次池化操作,輸出候選區域的特征用于分類實現目標檢測與識別,極大提高了模型的訓練和測試速度。文獻[19]提出Fast-RCNN算法,采用region of interest pooling(ROI pooling)層對CNN卷積層的特定區域進行池化,并引入多任務訓練函數,使模型的訓練和測試變得更加方便,且具有較高的目標檢測與識別精度。文獻[20]對Fast-RCNN算法進行進一步加速,提出Faster-RCNN算法,用region proposal network(RPN)網絡代替selective search候選區域提取算法;RPN負責提取數量更少準確率更高的候選區域,并與Fast-RCNN提取特征的網絡共享卷積層,進一步減少計算量,檢測速度更快,且目標檢測與識別精度優于RCNN、Fast-RCNN算法。但上述卷積神經網絡算法均是針對自然圖像設計的模型算法,相對于自然圖像,高分辨率遙感影像存在背景更加復雜、目標區域范圍更小和同類目標尺度變化更大等特點[21-22]。因此,上述卷積神經網絡算法難以良好地學習與耦合高分辨率遙感影像目標特征信息,對遙感影像目標檢測與識別精度不高。
針對上述問題,本文提出基于高分辨率遙感影像目標尺度特征的卷積神經網絡檢測與識別方法。首先通過統計遙感影像目標的尺度范圍,獲得卷積神經網絡訓練與測試過程中目標感興趣區域合適的尺度大小。然后根據目標感興趣區域合適的尺度,提出基于高分辨率遙感影像目標尺度特征的卷積神經網絡檢測與識別架構。最后通過定性對比試驗和定量評價驗證本文卷積神經網絡架構的有效性。
1 本文方法概述
本文方法主要分為兩個步驟:①統計高分辨率遙感影像目標的尺度范圍,獲得遙感影像目標感興趣區域尺度大小;②根據目標感興趣區域尺度,設計高分辨率遙感影像目標檢測與識別卷積神經網絡架構。
1.1 目標感興趣區域尺度范圍
高分辨率遙感衛星通常在近地軌道對地球表面進行成像,且成像過程中受光照、氣象條件等影響,生成的遙感影像存在影像內容復雜、目標尺度范圍較小,且不同時間段生成的遙感影像輻射差異較大等特點。在遙感衛星特殊的成像條件下,為了充分統計影像典型目標感興趣區域的尺度范圍,本文建立了一個包含飛機、儲存罐和船只的遙感影像目標檢測與識別數據集WHU-RSone。該數據集中包含2460幅高分辨率遙感影像,影像大小為600×600像素~1372×1024像素。2460幅遙感影像中包含22 191個目標,其中7732個飛機(plane)目標、10 572個儲存罐(storage-tank)目標和3887個船只(ship)目標,具體信息如表1所示。
表1 WHU-RSone數據集目標類別與數目
Tab.1 The category and number of objects in WHU-RSone data set

目標類型目標個數飛機7732存儲罐10572船只3887總計22191
WHU-RSone數據集中包含不同輻射亮度、不同尺度大小的目標影像數據,可以用于充分統計不同成像條件下遙感影像典型目標感興趣區域的尺度范圍,圖1為WHU-RSone數據集中部分樣例目標數據。在Faster-RCNN架構中RPN網絡使用3種尺度(128、256和512)和3種比例(1∶2、1∶1和2∶1)生成9種目標感興趣區域。9種目標感興趣區域大小如圖2左側矩形框內所示,9種目標感興趣區域能覆蓋的區域范圍如圖3面積較大多邊形區域所示。

圖1 WHU-RSone目標樣例數據Fig.1 Object sample data in WHU-RSone data set
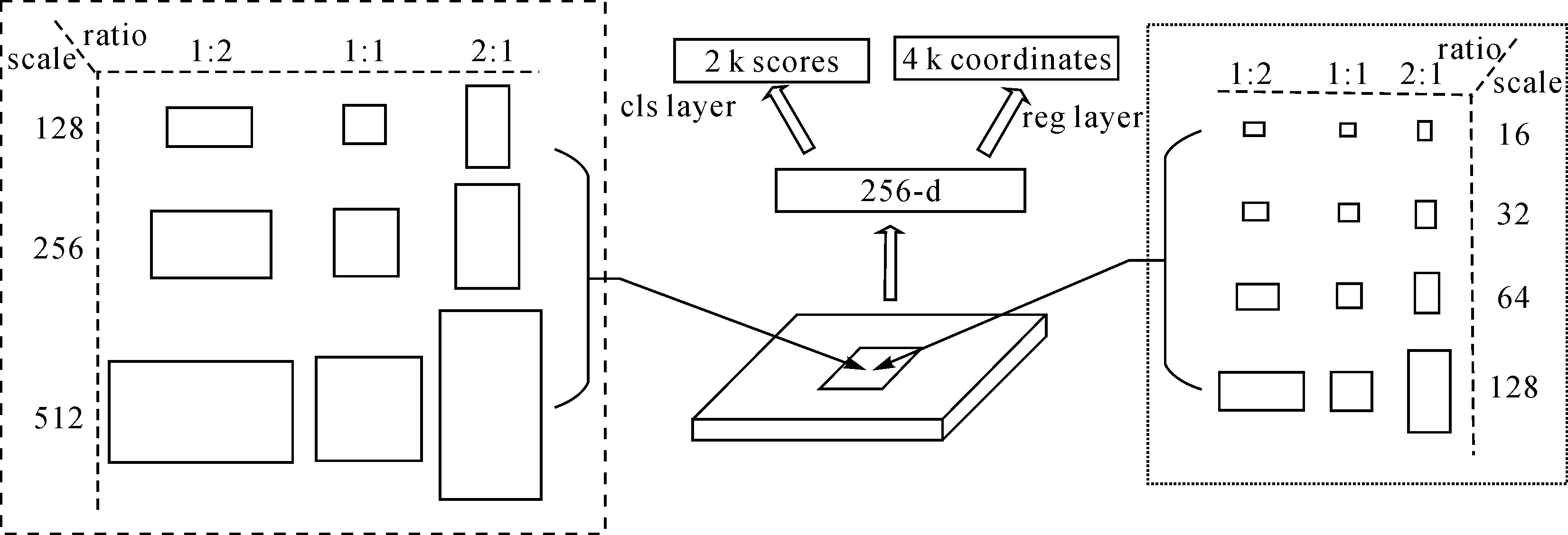
圖2 目標感興趣區域提取網絡Fig.2 Object region of interest extraction network
對WHU-RSone數據集中22 191個目標尺寸進行統計,統計信息如圖4所示。在圖4中,WHU-RSone數據集中僅有6.95%的目標尺寸處于中RPN網絡生成的9種目標感興趣區域覆蓋的區域范圍內,RPN網絡生成的9種目標感興趣區域難以有效耦合遙感影像典型目標的尺寸大小。由于高分辨率遙感影像中典型目標的尺度通常較小,需要對RPN網絡生成的感興趣區域尺度進行改進,設置4種尺度(16、32、64和128)與3種比例(1∶2、1∶1和2∶1)獲得12種目標感興趣區域。12種目標感興趣區域大小如圖2右側矩形框內所示,12種目標感興趣區域能覆蓋的區域范圍大小如圖3面積較小多邊形區域所示。在圖4中,WHU-RSone數據集中有95.65%的目標尺寸處于改進后RPN網絡生成的12種目標感興趣區域覆蓋的區域范圍內,幾乎所有的目標尺寸均處于改進后RPN網絡生成的12種目標感興趣區域覆蓋的范圍內。統計結果表明,設置的4種尺度(16、32、64和128)和3種比例(1∶2、1∶1和2∶1)生成的目標感興趣區域能有效耦合遙感影像中典型目標的尺度范圍。據此,在本文卷積神經網絡架構設計中,RPN網絡利用4種尺度(16、32、64和128)和3種比例(1∶2、1∶1和2∶1)生成卷積神經網絡架構訓練與測試過程中目標感興趣區域大小。

圖3 目標感興趣區域覆蓋范圍Fig.3 Coverage area of object region of interest
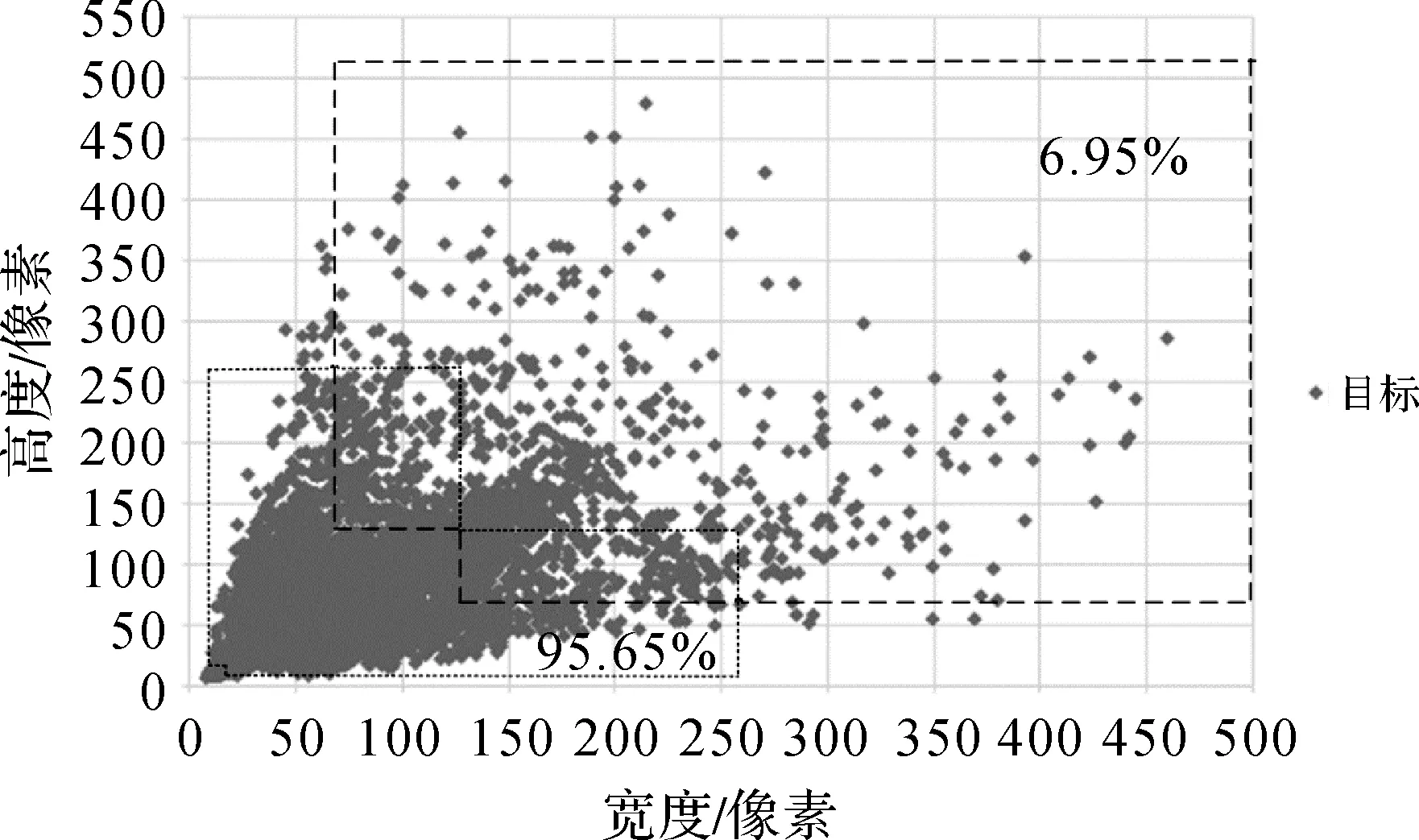
圖4 目標尺度分布范圍Fig.4 Object scale distribution range
1.2 目標檢測與識別卷積神經網絡架構
借鑒Faster-RCNN架構設計,本文卷積神經網絡架構包括RPN網絡和目標識別網絡。其中RPN網絡用于生成影像中的目標感興趣區域,目標識別網絡用于對RPN網絡中生成的目標感興趣區域進行識別分類及目標區域坐標回歸。卷積神經網絡架構示意圖如圖5所示。
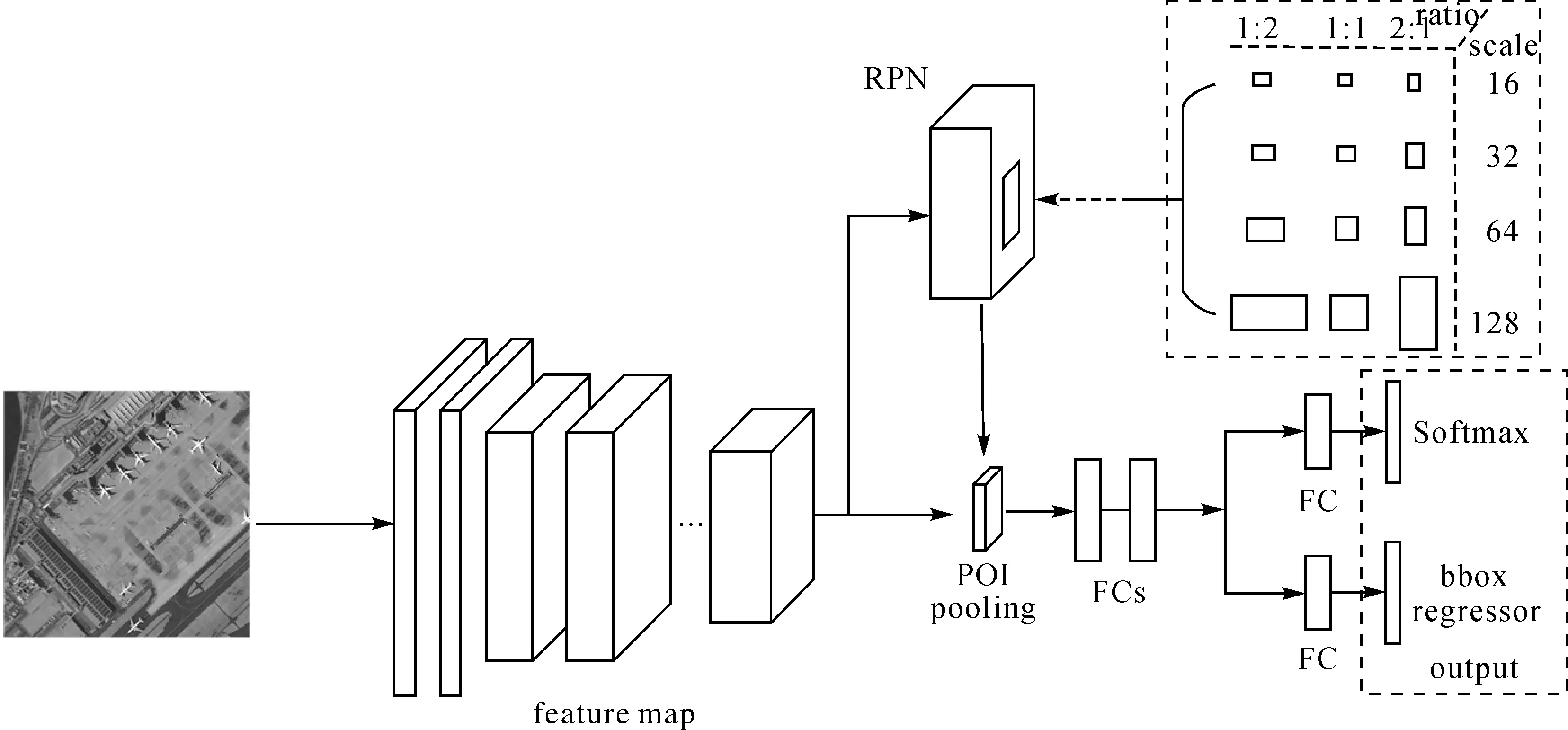
圖5 本文卷積神經網路架構Fig.5 The proposed convolution neural network framework
1.2.1 RPN網絡
本文中RPN網絡用于提取目標感興趣區域,生成的目標感興趣區域用于架構的目標檢測與識別的訓練與測試。本文架構的RPN網絡采用4種尺度(16、32、64和128)和3種比例(1∶2、1∶1和2∶1)生成12種錨點用于得到卷積神經網絡架構的目標感興趣區域,錨點示意圖如圖5矩形框內所示。RPN網絡在最后一層特征圖上根據錨點生成目標感興趣區域,對目標感興趣區域進行前景與背景的二分類及目標感興趣區域坐標回歸訓練,使RPN網絡中的權重學習到預測目標區域的能力。二分類與目標區域坐標回歸訓練的損失函數L(p,t)的計算如下所示
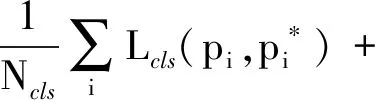
(1)
(2)
(3)
(4)
(5)
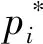
1.2.2 目標識別網絡
目標識別網絡使用卷積層(convolution layer)、激活層(relu layer)和池化層(pooling layer)獲得影像特征圖(feature map)。本文分別使用Zeiler and Fergus(ZF)模型[23]和visual geometry group(VGG)模型[24]兩種經典網絡模型獲得卷積神經網絡架構的特征圖,通過兩種不同的模型驗證卷積神經網絡架構的有效性。RPN網絡將生成的目標區域信息傳遞給目標識別網絡,目標識別網絡結合目標區域信息和網絡中最后一層特征圖,獲得目標區域在特征圖上特征向量信息,將特征向量信息傳遞至ROI pooling層,獲得指定大小的特征向量信息。特征向量被傳遞至全連接層(fully-connected layer,FC)用于目標識別分類和區域坐標回歸訓練和測試。目標識別分類和區域坐標回歸訓練的損失函數L(p,k*,t,t*)計算如下所示
(6)
(7)
(8)
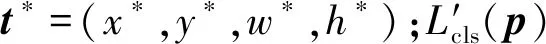
1.2.3 架構訓練與測試
本文卷積神經網絡架構利用Caffe框架實現,采用端到端的訓練方式對RPN網絡和目標識別網絡進行訓練。將RPN網絡損失和目標識別網絡損失相加,利用隨機梯度下降法進行反向傳播。訓練過程中,使用ImageNet上訓練好的模型初始化本文網絡模型參數。本文RPN網絡的batch大小為256,目標識別網絡的batch大小為2000,網絡訓練的動量為0.9,衰減因子為0.000 5,基礎學習速率為0.001,學習速率變化比率為0.1,每迭代50 000次變化學習速率,最大訓練迭代次數為75 000。
在卷積神經網絡架構測試階段,將一幅遙感影像輸入卷積神經網絡架構,利用RPN網絡生成6000個目標區域,對目標區域進行非極大值抑制,非極大值抑制的intersection over union(IoU)閾值為0.7。然后選取置信度排名前300的目標區域傳遞至目標識別網絡,目標識別網絡對300個目標區域進行分類識別及區域坐標回歸,輸出目標類別和區域坐標。
2 試驗結果與分析
大規模的學習樣本是支撐深度學習發揮高性能的基礎。為此,本文建立了一個包含2460幅遙感影像的目標檢測與識別數據集WHU-RSone。數據集中包含22 191個目標,其中7732個飛機目標、10 572個存儲罐目標和3887個船只目標,數據集具體信息如表1所示。
為了充分驗證本文卷積神經網絡架構的有效性,將本文卷積神經網絡架構與Faster-RCNN架構進行定性與定量對比評價。在試驗中使用ZF和VGG兩種網絡模型獲得本文架構與Faster-RCNN架構的特征圖,通過兩種不同的模型充分對比驗證兩種架構的性能。在2460幅遙感影像中隨機選出1476幅影像作為訓練數據,492幅影像作為驗證數據,492幅影像作為測試數據。通過訓練和驗證數據對本文架構與Faster-RCNN架構進行訓練,利用測試數據對訓練后的兩種架構進行對比測試。
2.1 訓練損失值(loss)對比
圖6為兩種架構基于ZF模型和VGG-16模型訓練loss走勢圖。圖6(a)中藍色曲線和紅色曲線分別為Faster-RCNN ZF和本文架構ZF模型訓練loss曲線。相對于Faster-RCNN ZF模型loss曲線,本文架構ZF模型的loss更易趨于收斂,且收斂后的loss值小于Faster-RCNN ZF模型。圖6(b)中的藍色曲線和紅色曲線分別為Faster-RCNN VGG-16和本文架構VGG-16模型訓練loss曲線。同樣,相對于Faster-RCNN VGG-16模型loss曲線,本文架構VGG-16模型的loss更易趨于收斂,且收斂后的loss值小于Faster-RCNN VGG-16模型。
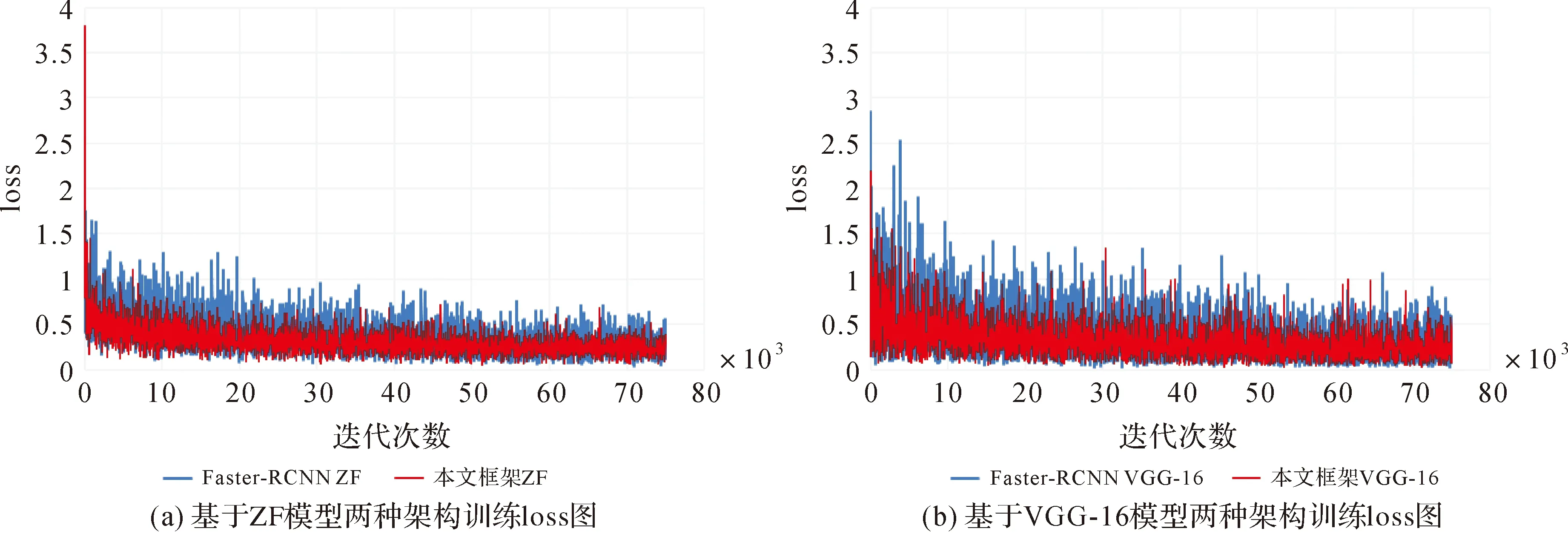
圖6 Faster-RCNN架構與本文架構訓練loss對比圖Fig.6 Comparison of Faster-RCNN and the proposed CNN framework training loss
Faster-RCNN架構通過設置3種尺度(128、256和512)和3種比例(1∶2、1∶1和2∶1)生成9種目標感興趣區域對架構進行訓練。本文架構通過設置4種尺度(16、32、64和128)和3種比例(1∶2、1∶1和2∶1)生成12種目標感興趣區域對架構進行訓練。兩種架構在其他結構相似的情況下,試驗結果表明本文架構設置的4種尺度(16、32、64和128)和3種比例(1∶2、1∶1和2∶1)生成12種目標感興趣區域更有利于高分辨率遙感影像目標檢測與識別訓練,可以獲得更好的模型訓練結果。
2.2 目標檢測與識別定量評價
本文使用492幅遙感影像對訓練后的Faster-RCNN架構和本文架構進行對比評價。通過mAP(mean average precision)[25]對兩種架構的目標檢測與識別精度進行定量評價。mAP值越大說明網絡架構的目標檢測與識別精度越高,反之亦然。在計算mAP時,當檢測結果的坐標與目標真值坐標的IoU大于等于0.5時,認為檢測結果正確,反之為錯誤檢測結果。mAP的計算如式(9)所示
(9)
式中,n為目標類別數;i為類別標簽;APi為標簽i類別的平均精度,APi的大小為標簽i類別的P-R曲線下包含的面積,如圖7所示。
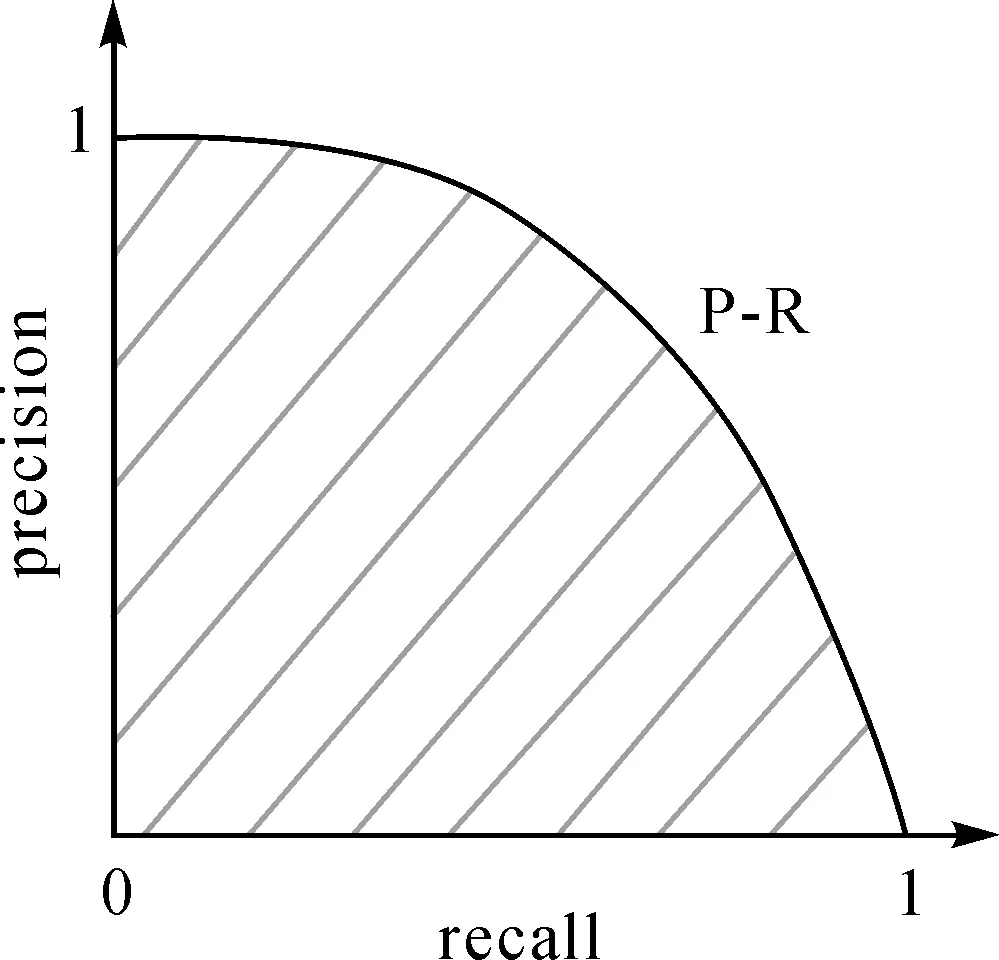
圖7 P-R曲線Fig.7 P-R curve diagram
圖8為兩種架構基于ZF模型和VGG-16模型的mAP走勢圖,圖8(a)中實線和虛線分別為本文架構ZF模型和Faster-RCNN ZF模型的mAP曲線,圖8(b)中實線和虛線分別為本文架構VGG-16模型和Faster-RCNN VGG-16模型的mAP曲線。圖8(a)、(b)中,本文架構的mAP曲線均高于Faster-RCNN架構的mAP曲線,表明本文架構的目標檢測與識別精度優于Faster-RCNN架構。
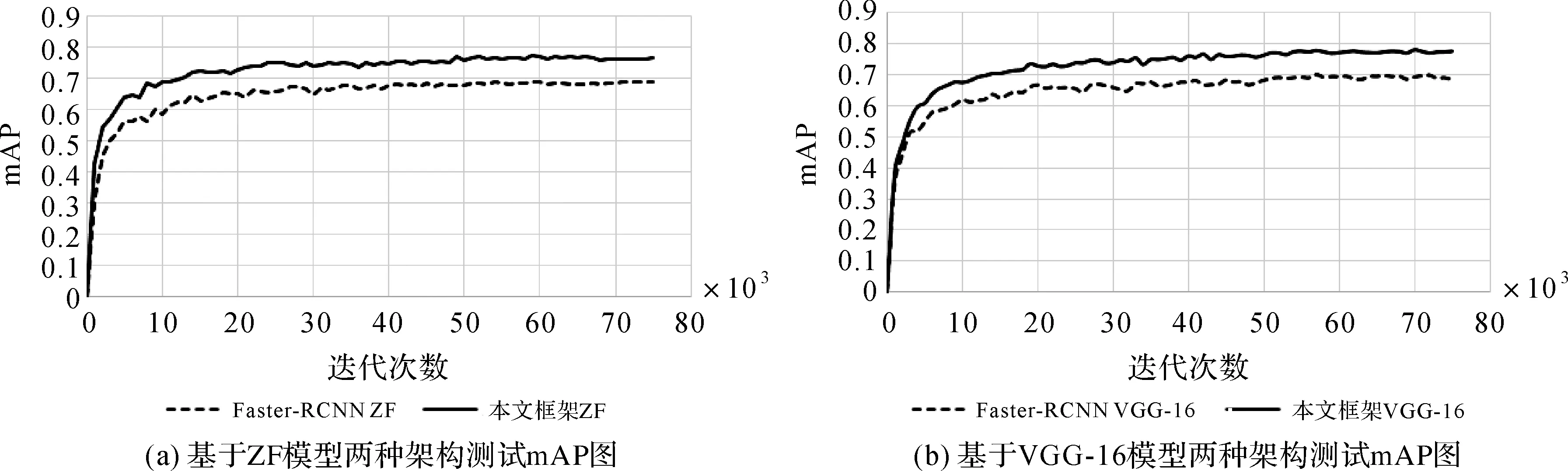
圖8 Faster-RCNN架構與本文架構測試mAP對比圖Fig.8 The mAP comparison of Faster-RCNN and the proposed CNN framework test
表2中為圖8中Faster-RCNN架構和本文架構的mAP曲線平穩時,各類目標的AP值,及所有目標類別的mAP值。表2中,本文架構ZF模型的飛機、存儲罐和船只的AP值均高于Faster-RCNN ZF模型,說明本文架構ZF模型對各類目標的檢測與識別精度均優于Faster-RCNN ZF模型;本文架構ZF模型和Faster-RCNN ZF模型的mAP值分別為0.772 7和0.691 0,本文架構ZF模型的mAP值比Faster-RCNN ZF模型提高了8.17%。表2中本文架構VGG-16模型的飛機、存儲罐和船只的AP值均高于Faster-RCNN VGG-16模型,表明本文架構VGG-16模型對各類目標的檢測與識別精度均優于Faster-RCNN VGG-16模型;本文架構VGG-16模型和Faster-RCNN VGG-16模型的mAP值分別為0.779 0和0.695 9,本文架構VGG-16模型的mAP值比Faster-RCNN VGG-16模型提高了8.31%。試驗結果表明本文架構的mAP值比Faster-RCNN架構有了較大的提升,本文架構的目標檢測與識別精度優于Faster-RCNN架構。
2.3 目標檢測與識別目視判別
表2中Faster-RCNN架構與本文架構基于VGG-16模型的mAP值分別高于兩種架構基于ZF模型的mAP值,則對mAP值更高的Faster-RCNN VGG-16模型與本文架構VGG-16模型的檢測與識別結果進行目視對比評價。兩種架構目標檢測與識別的置信度閾值設為0.8,圖9(a1)、(b1)、(c1)、(d1)和(e1)為Faster-RCNN VGG-16模型的測試樣例結果,圖9(a2)、(b2)、(c2)、(d2)和(e2)為本文架構VGG-16模型的測試樣例結果。
表2 目標檢測與識別定量評價結果
Tab.2 Quantitative evaluation results of object detection and recognition
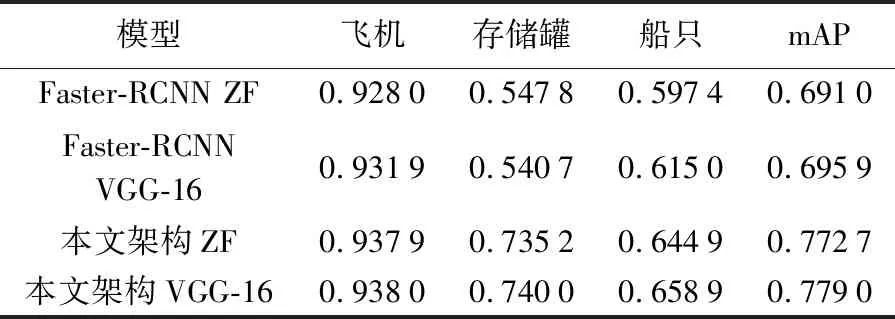
模型飛機存儲罐船只mAPFaster-RCNN ZF0.92800.54780.59740.6910Faster-RCNN VGG-160.93190.54070.61500.6959本文架構ZF0.93790.73520.64490.7727本文架構VGG-160.93800.74000.65890.7790
在圖9(a1)、(a2)中黃色箭頭所指的區域,Faster-RCNN VGG-16模型難以檢測與識別出尺度較小的飛機目標,而本文架構VGG-16模型可以準確檢測與識別出尺度較小的飛機目標。
在圖9(b1)、(b2)中黃色箭頭所指的區域,Faster-RCNN VGG-16模型難以檢測與識別出尺度較小的飛機目標,而本文架構VGG-16模型可以準確檢測與識別出尺度較小的飛機目標。
在圖9(c1)、(c2)中黃色箭頭所指的區域,Faster-RCNN VGG-16模型難以檢測與識別出尺度較小的存儲罐目標,而本文架構VGG-16模型可以準確檢測與識別出尺度較小的存儲罐目標。
在圖9(d1)、(d2)中黃色箭頭所指的區域,Faster-RCNN VGG-16模型難以檢測與識別出尺度較小的存儲罐目標,而本文架構VGG-16模型可以準確檢測與識別出尺度較小的存儲罐目標。


圖9 測試樣例檢測與識別結果Fig.9 Test sample detection and recognition results
在圖9(e1)、(e2)中黃色箭頭所指的區域,Faster-RCNN VGG-16模型將長條形狀的碼頭區域識別為船只,而本文架構VGG-16模型可正確識別長條形狀的碼頭區域。
試驗結果表明,對于遙感影像中尺度較小的目標,本文架構VGG-16模型的檢測與識別結果優于Faster-RCNN VGG-16模型,本文架構VGG-16模型可獲得良好的影像檢測與識別結果。
為了進一步驗證本文框架的適用性與穩健性,將本文框架VGG16模型用于6幅高分二號全色影像目標檢測與識別。目標檢測與識別的置信度閾值設為0.8,試驗結果如圖10所示。
通過目視判讀試驗結果,本文框架VGG-16模型可有效檢測與識別出影像中的飛機、存儲罐和船只等典型地物。試驗結果表明本文卷積神經網絡架構可有效應用于高分二號影像的目標檢測與識別,本文卷積神經網路架構具有良好的普適性與穩健性。
3 結 論
針對傳統影像目標檢測與識別算法中人工設計特征穩健性、普適性差的問題,本文提出基于高分辨率遙感影像目標尺度特征的卷積神經網絡檢測與識別。由于高分辨率遙感影像存在背景復雜、目標區域范圍較小和同類目標尺度變化較大的特點,對此本文通過統計遙感影像目標的尺度范圍,獲得卷積神經網絡訓練與檢測過程中目標感興趣區域合適的尺度大小。試驗統計分析得出設置4種尺度(16、32、64和128)和3種比例(1∶2、1∶1和2∶1)生成的12種目標感興趣區域能有效耦合遙感影像中飛機、存儲罐和船只等典型目標的尺度范圍。根據合適的目標感興趣區域尺度,提出基于高分辨率遙感影像目標尺度特征的卷積神經網絡檢測與識別架構。通過WHU-RSone數據集測試驗證,結果表明本文架構ZF模型和本文架構VGG-16模型的mAP值分別比Faster-RCNN ZF模型和Faster-RCNN VGG-16模型提高了8.17%和8.31%,本文架構可以更好地檢測出影像中尺度較小的目標,獲得良好的目標檢測與識別效果。下一步將在遙感影像目標檢測與識別的基礎上,對目標方向預測進行研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
