多核學習與用戶反饋結合的WMS圖層檢索方法
2019-10-29 08:55:58李牧閑桂志鵬成曉強吳華意
測繪學報 2019年10期
李牧閑,桂志鵬,,成曉強,吳華意,秦 昆
1. 武漢大學遙感信息工程學院,湖北 武漢 430079; 2. 武漢大學測繪遙感信息工程國家重點實驗室,湖北 武漢 430079; 3. 地球空間信息技術協同創新中心,湖北 武漢 430079; 4. 湖北大學資源環境學院,湖北 武漢 430062
WMS是開放式地理信息聯盟(open geospatial consortium,OGC)制定的在線動態制圖服務標準,是推動地理信息共享與互操作的重要里程碑。自2000年發布1.0版本標準以來得到業界廣泛運用,大量源自政府部門、國際組織和研究機構的地理空間數據以網絡地圖服務(web map service,WMS)形式涌現,目前全球公開在線的WMS數目眾多。有研究在互聯網中爬取超過4萬條可訪問WMS,通過分析發現所包含的30多萬張圖層空間覆蓋遍及全球,應用主題囊括氣候、地質、資源與生態等地理觀測組織(group on earth observations,GEO)定義的九大社會受益領域[1]。面對如此海量豐富的WMS數據資源,亟須一種高效準確的檢索方法幫助用戶從中發掘和定位興趣資源。
基于元數據字段的文本匹配和空間關系查詢是目前地理信息資源檢索的主要方式。Data.gov[2]、ESRI’s Geoportal server[3]、INSPIRE GeoPorta[4]、GEOSS Clearinghouse[5]、NOAA Data Catalog[6]和Spatineo Directory[7]等全球知名地理信息門戶通過提取WMS元數據中蘊含的圖層標題、關鍵字、服務提供者、發布時間和空間范圍等信息,運用文本匹配查詢實現對WMS資源的粗粒度檢索。由于資源提供者與不同領域用戶對地理資源元數據的表述方式存在差異,文本匹配無法實現精準查詢,引入地理本體和粗糙集理論優化圖層描述詞匯可實現語義層面的演繹推理[8];建立文本語義搜索規則,使用語義相似性評估來衡量搜索結果與用戶需求之間的相似性可提高檢索精度[9]。為提高檢索的命中率,學者們還提出多種檢索輔助策略,如依據圖層信息量豐富度生成一組代表不同尺度下典型地圖內容的高質量縮略圖[10],并設計圖層動態預覽功能以增強用戶體驗[9];通過連續監測WMS響應時間和主動收集用戶評價評估WMS質量作為篩選依據,并進行動態可視化[11-12]。上述策略利用語義優化文本檢索策略或引入其他輔助信息擴展檢索維度,一定程度上提升了WMS檢索的準確率與用戶體驗。然而大量在線WMS圖層元數據缺失、元數據缺乏明確的內容約束機制(如不少圖層命名為機構縮寫、圖層摘要為傳感器編號,關鍵字設定隨意)等,使得元數據無法具體表述圖層的內容構成、制圖方法等信息。地圖內容與元數據間的語義鴻溝使得基于文本的WMS檢索產生大量誤檢和漏檢結果,用戶雖可通過縮略圖預覽等輔助方式提升選擇效率,但仍無法直接基于地圖內容進行檢索。
針對現有檢索方法缺乏“感知”地圖內容,無法應對圖文描述不符的問題,本文借鑒基于內容的圖像檢索,將圖層間的視覺相似性作為檢索依據以提高檢索精度。基于內容的圖像檢索按照特征提取方式可分為人工設定特征和自動學習兩類方法。人工設定特征的檢索方法通常選用顏色、形狀、紋理、光譜特征和SIFT算子等視覺特征作為圖像內容描述[13-14],并依據特征向量間的相似度實現檢索。這類方法對樣本數量要求較低,但因為特征選取直接影響檢索結果,需設計多組對比試驗選取合適的特征。自動學習的特征由深度學習框架(如卷積神經網絡模型)對大量圖像樣本訓練獲得,通過低層特征組合形成抽象且包含一定語義信息的高層表示,極大提升了對圖像內容的描述能力[15]。但高維特征加大了海量圖像相似性度量的計算量,導致檢索速率低下。為此,有研究使用PCA或乘積量化對特征進行壓縮和降維加速相似度計算[16-17];或結合深度學習與哈希思想將高維特征映射為一串二進制編碼,通過計算漢明空間距離降低相似性計算復雜度[18]。盡管深度學習在眾多圖像檢索場景下性能優異,但并不適用于WMS檢索:①深度學習是數據饑渴型方法,需要大量樣本數據訓練模型,而目前WMS圖層尚未形成統一規范的關鍵詞體系,樣本規模較小且標簽信息匱乏、質量欠佳,無法支持基于深度學習的高層特征提取;②深度學習模型訓練與優化的時間成本較高,而不同用戶檢索差異化大(如空間范圍、專題類型、制圖風格等),難以根據用戶需求動態調整模型參數,從而無法滿足實時個性化檢索的需求。針對WMS圖層檢索,有研究通過對圖層分塊提取顏色空間分布特征,并結合SVM分類器對小樣本集進行學習實現檢索[19],但僅使用顏色特征,無法全面多角度地概括圖層內容,圖層檢索效果欠佳。因此,需要提取并融合多種特征,使各類特征信息能根據用戶差異化的檢索需求合理作用于分類模型的生成。
為此本文提出一種基于多特征多核學習的WMS圖層檢索方法,通過圖層的顏色、形狀和紋理特征表征圖層內容,利用多核學習自適應分配3種特征在分類模型中所占權重,實現WMS檢索與相似度排序。同時結合用戶對搜索結果的反饋精化分類模型和調整特征權重,并通過迭代檢索提高檢索精度,以支持基于圖層圖像內容的WMS個性化檢索與推薦。
1 結合多核學習和用戶反饋的圖層檢索算法
本文使用多特征多核學習分類方法,將WMS圖層分為匹配與非匹配兩類,算法流程如圖1所示。用戶首先使用文本關鍵詞觸發初始檢索,文本匹配的WMS圖層縮略圖分頁批量展示于檢索結果頁面;其次,用戶利用鼠標標記興趣圖層構建正樣本集,其余為負樣本,系統從特征文件中讀取上述圖層對應特征向量構成訓練集(所有WMS圖層特征向量通過對GetMap操作獲得的最大包圍盒地圖圖像預先提取生成,并以CSV文件格式存儲于服務器端);然后,系統利用多核學習訓練樣本構建分類模型并計算檢索結果;最后,按相似度排序輸出并更新檢索結果頁面。若結果不滿意,用戶可再次進行正樣本標記,并觸發分類模型精化訓練與二次分類。
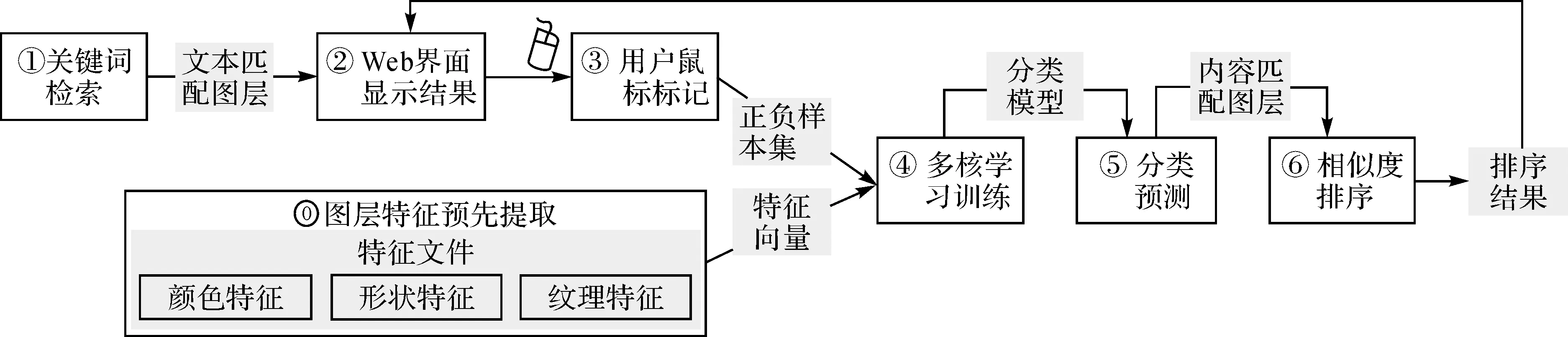
圖1 結合多核學習與用戶反饋的WMS圖層檢索算法流程Fig.1 WMS layer retrieval workflow combined with multiple kernel learning and user feedback
1.1 WMS圖層圖像的特征提取
WMS檢索需要設計有效的視覺特征來描述圖層圖像內容。作為反映客觀世界的符號模型及空間信息的載體[20],通過WMS發布的地圖在類型與表達形式上豐富多樣,既包括由點線面等矢量數據通過符號化渲染得到的矢量地圖也包括影像地圖,其中矢量地圖(包括普通地圖與針對某類地理要素的專題地圖)的表達形式與自然影像和遙感影像存在顯著差異(圖2)。自然影像和遙感影像中的場景與對象較為具象,組件構成相對穩定。如自然影像中的街道由道路、行人和建筑等構成,遙感影像中機場包含飛機和航站樓等對象,而飛機有機身、機翼等組件構成,視覺特征顯著。因此,可使用物體濾波器響應、詞袋模型等方法構建高層語義特征向量,判斷影像中對象構成及其分布情況來對圖像內容進行描述[21-22]。而矢量地圖中對象表達與比例尺、制圖風格等因素密切相關,往往較為抽象與多樣(如大比例尺下水體表達為面對象,在小比例尺下為點或線對象;等高線和暈渲圖均可用于表達地形信息),無穩定的組合形式,人為設計一種普適的高層語義特征難度大。圖像領域常用的視覺特征包括顏色、形狀、紋理、空間關系特征、SIFT和HOG等,其中形狀、顏色、紋理特征適用性較優而被廣泛運用于圖像檢索,而空間關系特征對旋轉、反轉、尺度敏感[23],HOG維度過高[24],SIFT對低對比度圖像檢索效率較低[25],應用范圍較前三者小。通過對WMS圖層內容的分析,本文認為顏色、形狀和紋理3種底層特征為一定程度上描述地圖內容提供了可行方案:①WMS圖層渲染與地理要素屬性的空間分布有關,顏色風格鮮明且表現出顯著的空間分布特性;②WMS圖層對象形狀輪廓清晰,可明顯觀察到區域輪廓,有效傳達區位信息;③隨著要素空間分布密集度的變化,WMS圖層可能具有多尺度或方向上的紋理。因此,本文選取顏色、形狀和紋理作為WMS圖層檢索的視覺特征。
本文在HSV(hue,saturation,value)空間內統計分塊顏色直方圖作為顏色特征。常用的顏色特征中,顏色矩由于僅利用低階矩概括顏色分布,使得圖像區分能力較弱[26];而顏色聚合向量為引入空間分布信息,通過設定閾值劃分顏色聚合與不聚合區域,容易出現因閾值選取不當導致的空間信息丟失問題[27]。分塊顏色直方圖通過圖像幾何分割提取顏色空間分布信息,并可根據WMS渲染特點量化各分塊內的顏色,從而能夠更好地刻畫地理要素的空間分布與屬性變化。為此,本文結合地圖利用顏色變化代表不同地理屬性及其等級這一特點,對應將色調、飽和度和明度分別劃分為3、8和12個等級。同時,考慮到人眼對圖層中心區域的重點關注,結合空間金字塔匹配[28]原理,使用橢圓(長短軸等于WMS縮略圖長寬的一半)和4條基線將圖像分為5部分。最后分別計算各分塊的顏色直方圖,并組成形成該圖層的顏色特征,共(3+8+12)×5=115維。

圖2 自然圖像、遙感影像與WMS圖層圖像示例Fig.2 Examples of natural image, remote sensing image and WMS layer image
本文使用Hu矩[29]對地圖對象形狀進行描述。Hu矩是一種計算量和冗余度較小的形狀區域描述符,有效避免了傅里葉描述符和鏈碼等形狀輪廓描述符因前后景分割復雜情況導致的輪廓提取問題[30],如部分WMS圖層存在前后景定義不清晰的現象。本文通過計算圖層灰度圖像的中心矩,并使用零階矩對其進行歸一化,生成一系列可描述區域輪廓旋轉半徑、圖像橢圓、主軸方向角等形狀屬性的低階矩。然后,對上述矩進行非線性組合,構造出7個具有旋轉、平移和尺寸不變性的Hu矩。
本文使用Gabor紋理特征對WMS圖層的紋理分布進行描述。常用紋理特征包括灰度共生矩陣、LBP、Gabor特征等。其中灰度共生矩陣和LBP均基于灰度的空間相關特性,尺度描述較為單一,難以應對WMS圖層紋理在尺度和方向上的多樣性;Gabor紋理特征通過對基小波的旋轉和尺度變換,得到一組自相似但方向和尺度各不相同的濾波器,能夠更加有效刻畫地圖中不同尺度和方向的紋理信息[31]。本文參考文獻[32]選取5個尺度和8個方向,得到共40個濾波器,計算濾波結果的均值和標準方差作為紋理特征,特征維度為40×2=80。
1.2 基于多核學習的WMS圖層分類模型構建
本文選用的3種圖像特征在維度、數量級上存在較大差異,對此使用一種多核學習的方法對特征進行融合并實現WMS分類。核方法通過非線性映射將低維線性不可分問題轉化為高維空間中線性可分的問題,并用核函數替換高維空間中復雜的內積問題,降低運算復雜度。傳統單核方法將所有向量映射到同一高維空間,對不同維度和數量級特征構成的異構數據分類效果不佳。針對這種現象,文獻[33—34]提出多核學習(multiple kernel learning,MKL),采用多個核函數的凸組合代替單個核函數,將異構數據的不同特征分量分別輸入對應的核函數進行映射,使數據在新的特征空間中得到更好的表達。多核學習通過與SVM相結合在多個領域得到了廣泛運用,如圖像分類、目標檢測與識別和模式回歸等[35]。多核學習模型如式(1)所示
(1)
式中,km(x,xi)為基核;qm為基核對應的權重;K(x,xi)表示合成核,通過兩個向量的內積實現特征隱式的非線性映射。使用SVM分類器,多核學習的核權重計算和優化可通過求解式(2)的凸規劃優化來實現
(2)
式中,C為規則化參數;ξi為松弛變量;αi和b為可通過樣本學習到的系數。使用Lagrangian函數結合對偶理論等計算得到決策函數(式(3)),其中只有權重非零的核函數在分類中有效
(3)
本文使用SimpleMKL[36]對WMS進行圖層分類。由于SimpleMKL引入了L2正則化公式約束權重以促進稀疏核的組合,并使用簡化梯度算法實現迭代優化,相比其他多核學習算法具有收斂性好、求解效率高的優點。本文選用局部性強、適用性高且求解參數少的高斯核函數構建多核模型。尺度參數σ是高斯核函數最重要的參數,當σ趨近于0時所有樣本都屬于同一類;當σ趨于無窮時任意樣本都屬于不同類。對于各特征,在0至無窮大之間都存在一個最優尺度參數使樣本在映射后的高維空間中實現最優區分。針對所選取的顏色、形狀、紋理特征,本文為每種特征分別構建一組尺度不同高斯核(如圖3)。結合文獻[36]和圖層參數尋優試驗,設置每組高斯核由十個核組成,各核尺度參數σ∈[0.03,1,2,5,7,10,12,15,17,20]。
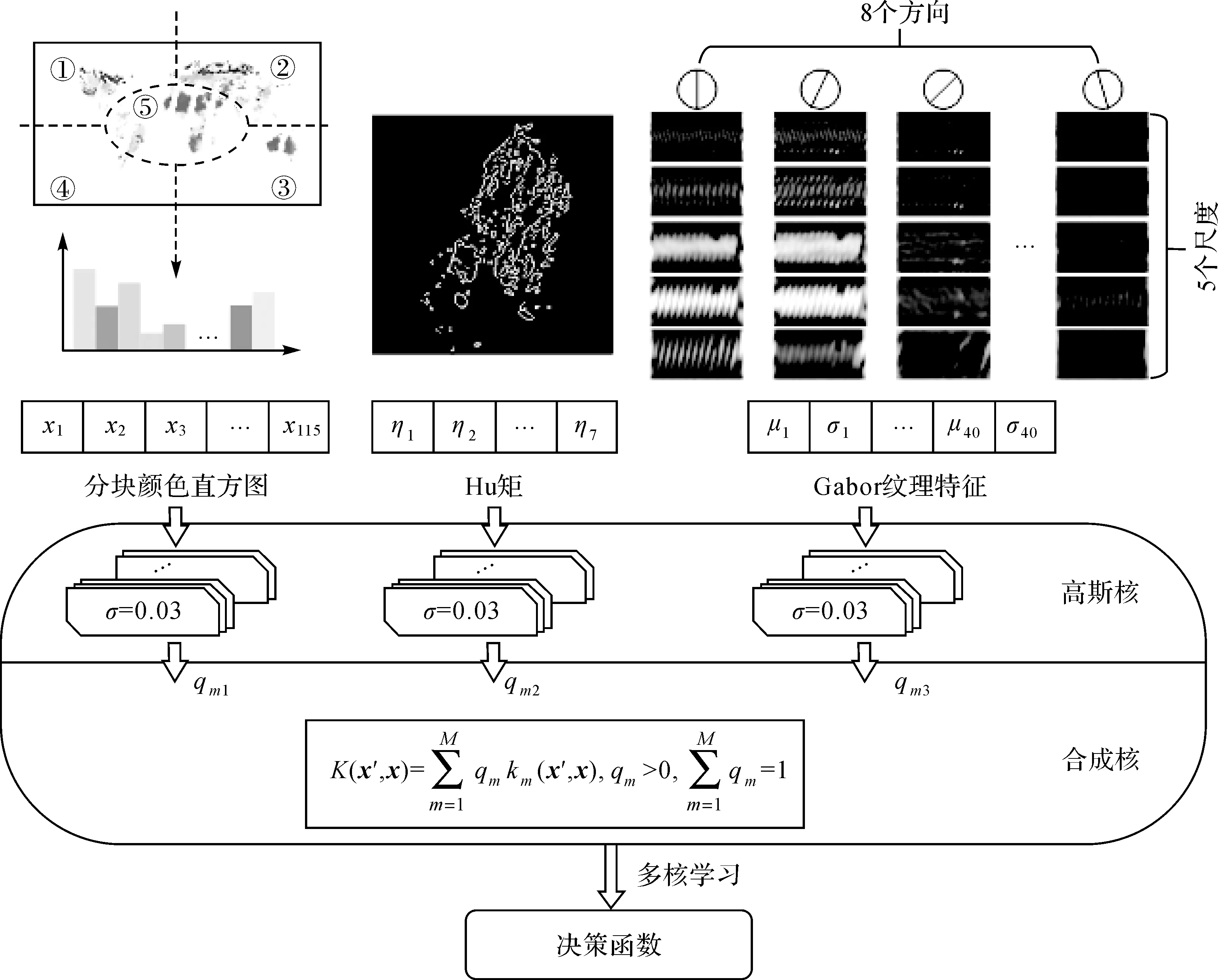
圖3 融合3種圖像特征的多核構造方法Fig.3 Multiple kernel construction method for fusing three types of image features
對本文構建的多核模型進行訓練求解,可根據WMS圖層樣本內容自適應地調整特征權重并為每個特征選擇恰當的核參數,以滿足用戶差異化的檢索需求。如圖4中Blue Marble影像和西班牙氣溫專題圖的顏色空間分布或形狀輪廓相似性較高,則訓練后分類模型中顏色或形狀特征權重較大,有效提高了決策函數的可解釋性和預測性能等。
1.3 結合用戶Web端反饋的檢索優化
由于選取的3種底層特征均不具備高級語義信息,本文引入用戶反饋機制。通過用戶興趣樣本補充,調整多核模型中各核權重,以期縮小檢索中的語義鴻溝,實現分類模型精化,滿足用戶個性化檢索需求。
用戶反饋于開發的基于Web的WMS圖層檢索系統原型實現,用戶通過鼠標點擊行為標記當前檢索結果頁面中所有正確檢索結果,如圖5所示,檢索結果中紅框標心的圖層縮略圖為人工標記的正確檢索圖層,系統將其與前次檢索使用的正樣本合并去重作為新正樣本集。當前頁面中未被選中圖層為負樣本,與前次檢索使用的負樣本合并后,從中選擇與新正樣本數量相當的圖層作為新負樣本集,以保證正負樣本數目均衡。對補充后的樣本集重新訓練得到新的分類模型,再次計算檢索結果并排序輸出顯示。
2 試驗結果與分析
本文從檢索準確性、檢索高效性和用戶反饋有效性3個方面開展試驗分析,綜合驗證本文方法的可行性:①結合對比試驗驗證多特征融合對各類WMS檢索準確性的提升;②探討檢索用時的影響因素及實時檢索的可能性;③分析反饋機制對檢索精度的提升效果,驗證其有效性。
2.1 試驗數據
本文使用的試驗數據來自全球653條WMS,共包含11 689張可訪問圖層,涵蓋全球溫度、云量、風速、土壤和土地利用等多種專題類型地圖,也包括道路網圖、地名地址等基礎設施分布地圖等。試驗中所有圖層縮略圖統一存儲為3通道的JPEG格式。
2.2 多特征多核學習的查準率對比
本文使用查準率作為檢索精度衡量指標,分析該方法相比現有基于顏色直方圖和SVM的檢索方法[19]在檢索精度上的優勢。考慮到點、線、面要素和遙感影像4類圖層視覺差異大,且顏色、形狀和紋理特征相似程度不同,本文從4類圖層中分別選擇多組圖層進行人工標簽標注開展無反饋檢索對比試驗,驗證多特征融合在WMS檢索中的必要性。各組圖層中正負樣本總數為30個。圖4為部分圖層訓練樣本與檢索結果示例,圖6為對應的查準率。
由圖6可知,本文方法融合多種特征能有效地提升查準率,但不同類型圖層的查準率仍存在較大差異。①面要素圖層的顏色分布和對象輪廓描述了地理要素在特定區域的空間分布。如圖4所示的西班牙溫度分布圖和愛荷華州魚群分布圖,顏色分布細節存在差異,但區域輪廓一致,通過訓練可提高形狀特征對應權重,達到提高查準率的目的。②盡管Blue Marble風格影像的藍色系配色風格易與其他同色系圖層混淆(如全球卷云反射率等),但由于類內圖層內容在顏色、形狀和紋理上相似性高,綜合使用3種特征能有效提高查準率。③通常點線要素圖層的要素空間排布形態與緊湊度受到多種因素影響。如圖4中的全球生物量圖和道路網,隨著統計目標和道路級別的不同,點線及其顏色分布產生差異,并引起內部紋理和輪廓變化。特別是點要素圖層輪廓細碎,類內配色風格差異大,視覺相似度低,僅使用顏色特征無法有效概括類內圖層內容的相似性。盡管本文方法綜合利用3種特征使得查準率有所提升,但整體精度仍較低。
2.3 多特征多核學習效率分析
為驗證本文方法能否支持WMS圖層實時檢索,本文統計分析不同樣本規模下不同有效核數目對應的平均檢索用時。為保證圖層縮略圖的清晰展現,限定每頁檢索結果頁面可容納的縮略圖數量為80張,同時考慮到實際系統交互的用戶體驗,用戶反饋標記操作多集中在第1—2頁,樣本數目至多160個,本試驗設置10、50、100、150和200共5個樣本數量級。對各樣本數量下5000組不同正負樣本構成的訓練集進行學習并解算核權重,統計每組權重非零的有效核數目和10次重復試驗的平均檢索用時。試驗環境為單臺臺式機,硬件配置為intel i5四核處理器(主頻3.00 GHz)和16 GB內存,操作系統為Windows 10,算法基于MATLAB實現。
統計各樣本數量下有效核數目出現頻次,如圖7所示有效核數目最大為18,但主要集中于10以內,且最大檢索用時未超過2.5 s。為此本文進一步分析有效核數目為1~9時檢索用時變化規律(圖8)。本文將檢索用時劃分為訓練用時和其余用時(包括樣本數據讀入、多核模型預設、預測分類和相似性排序用時等)兩部分,并以樣本數量10為基準分析不同樣本數量和有效核數目下訓練用時和其余用時的變化率,計算公式如式(4),tn,k為樣本數為n,有效核數目為k時的訓練用時或其余用時
時間變化率=(tn,k-t10,k)/t10,k
(4)
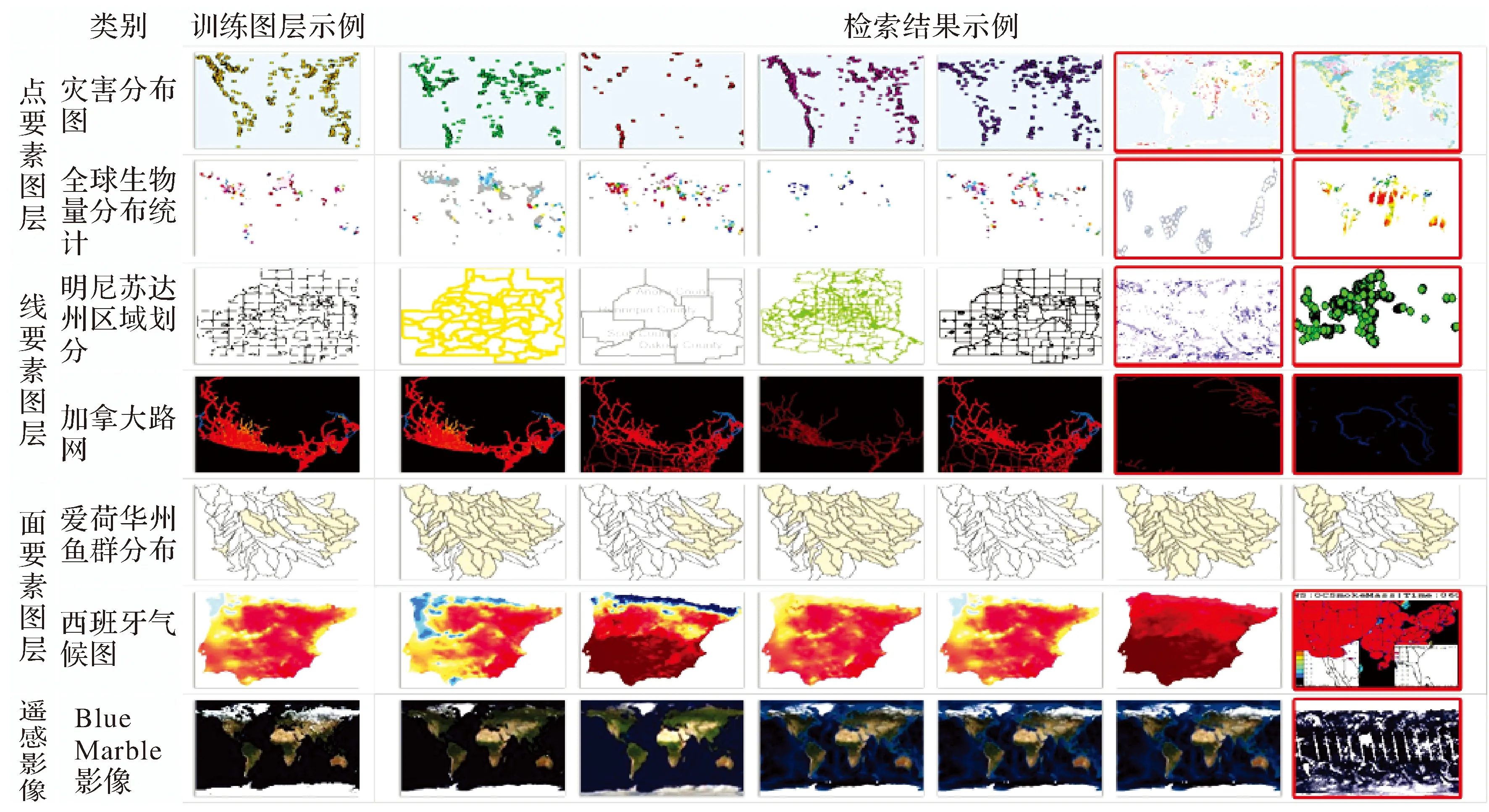
圖4 部分圖層訓練樣本與檢索結果示例(帶紅框圖層為檢索錯誤結果)Fig.4 Examples of training set and results (wrongly retrieved images are marked with red rectangle borders)
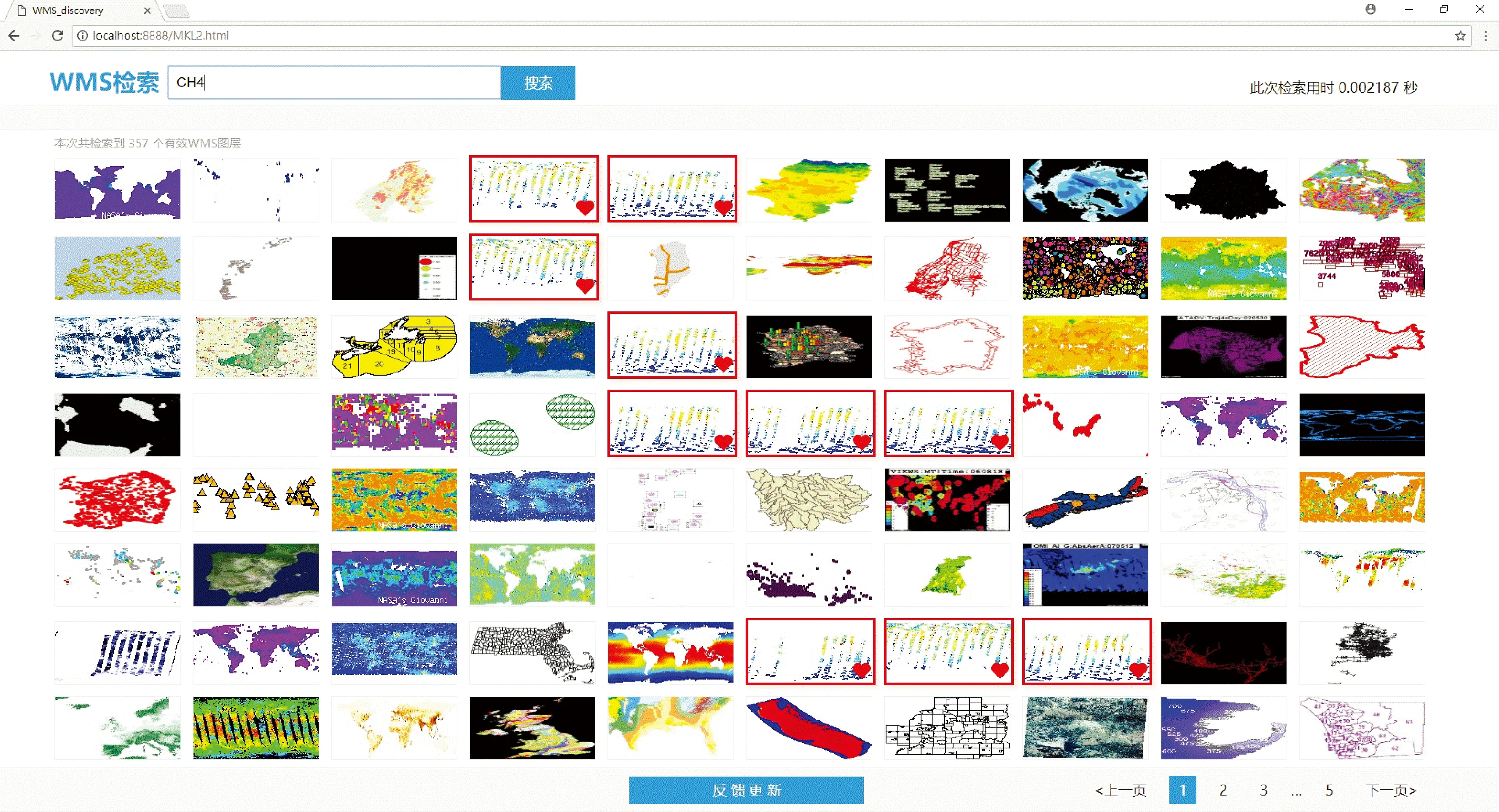
圖5 WMS圖層檢索結果展示界面及用戶反饋示例(以全球甲烷(CH4)分布圖為例)Fig.5 The GUI of WMS layer retrieval result exhibition page and user feedback demonstration (taking global CH4 distribution map for example)
由圖8可知,檢索用時隨樣本數量和有效核數目的增加而增加,不同樣本數量和有效核數下的平均檢索用時為0.1~1.6 s,基本能夠滿足用戶實時檢索的需求。其中訓練用時隨樣本數量和有效核數目增加呈增長趨勢,有效核數目與檢索所需特征類數高度相關。當檢索對象為使用單一特征可有效區分的WMS圖層,分類模型復雜度低有效核數目較少(多為1~2個),訓練用時較短。其余用時不受核數目變化的影響但隨樣本數量的增加呈線性增長。其中樣本數據讀入時間受樣本數量影響最大,而多核模型預設、預測分類和相似性排序用時所占比重小,受樣本數量影響較小,其變化對其余用時影響有限。同時,對比圖8訓練用時和其余用時變化率曲線,訓練用時隨樣本數量增長速度略高于其余用時,可從算法優化和數據讀取并行等角度進一步加速檢索速率。
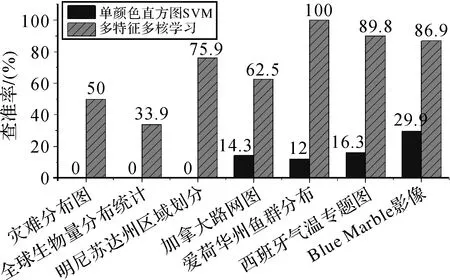
圖6 單顏色直方圖SVM與多特征多核檢索算法的查準率對比Fig.6 The precision comparison of SVM with blocking color histogram as the single feature and the proposed multiple kernel learning with three selected features
2.4 反饋機制的有效性驗證
本文分別選取點、線、面要素地圖和遙感影像中的多組代表圖層開展反饋有效性驗證試驗。試驗選用查準率和查全率評估反饋對檢索精度的提升,使用平均準確率(average precision,AP)評估反饋對正確檢索結果位序的影響,綜合評判反饋能否輔助用戶快速獲取有效信息。各指標計算如式(5),其中Q為檢索結果總數,r為位序,P(r)為當前位置的查準率。迭代反饋中各項指標變化情況如圖9所示。
(5)

圖7 不同樣本數量下有效核數目的頻次分布Fig.7 The frequency distribution of kernel number in different training sample sizes
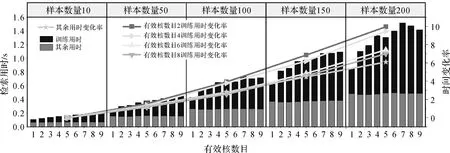
圖8 多核學習訓練用時與其余用時隨樣本數量及核數目的變化趨勢Fig.8 The increasing of training time and other computing time with the increased training sample sizes and kernel numbers
由圖9可知反饋對查全率貢獻小,但能有效提高查準率和平均準確率。查全率在反饋中保持不變或僅有小幅度提升。其中點、線圖層中要素分布模式多樣、視覺差異大,檢索結果與正樣本視覺相似性高,用戶在此基礎上反饋無法補充其他分布模式的點線要素圖層信息,因此不能有效提高該類圖層的查全率。隨著反饋迭代大量錯誤檢索結果被剔除,查準率提升迅速。多次反饋后仍被誤檢的圖層與正樣本在地理要素或屬性空間分布、配色風格或區域輪廓上差異有限、視覺相似度高,將這些圖層作為負樣本補充后會干擾訓練,使分類模型向錯誤方向調整,造成查準率波動。通過反饋檢索平均準確率到達了較高水平,說明反饋能夠有效剔除錯誤結果,并有效改善正確結果的相似度排序。同時試驗表明,經過1—2次反饋后,樣本規模已足夠輔助模型捕捉到圖層間的相似性,并將各核權重調節至合理區間,此后查全率、查準率和平均準確率等指標基本保持穩定。綜上所述,用戶通過少數次反饋能有效篩除錯誤干擾項,提高正確檢索結果位序,快速找到匹配的圖層。
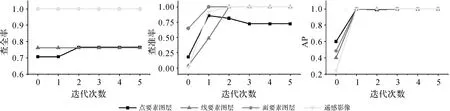
圖9 不同類型圖層的用戶反饋有效性試驗結果Fig.9 Results of user feedback validity experiment for different types of layers
3 總結與展望
本文將基于內容圖像檢索應用于WMS圖層檢索,設計了一種基于多特征多核學習的檢索策略,并結合用戶反饋機制提升檢索精度。試驗結果表明該算法能夠實時準確滿足用戶多樣化的檢索需求。相比現有WMS檢索方法,本文方法考慮了圖層的視覺相似性,融合顏色、形狀、紋理3種特征對圖層內容進行描述;通過多核學習實現特征的高效組合和核函數參數選擇;結合用戶反饋,動態調整與優化分類模型,適應了用戶檢索差異化大的需要。
本文算法對面要素圖層和遙感影像效果較好,而點線要素圖層需進一步優選特征或結合深度學習框架提取圖層高級語義特征,以提高檢索精度。目前本文方法假定反饋過程中所有檢索正確結果均被用戶手動標記,可借鑒半監督學習或弱監督學習的思想,通過少量標記圖層篩選檢索結果中其他興趣圖層,減輕用戶反饋標記負擔。同時,為應對檢索用時隨樣本數目快速增長的現象和大量用戶并發檢索的需求,需設計合理的并行計算方案,提升用戶體驗。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
