靜態軟件缺陷預測研究進展*
2019-10-24 07:45:06吳方君
計算機與生活 2019年10期
吳方君
1.江西財經大學 信息管理學院,南昌330013
2.江西財經大學 數據與知識工程江西省高校重點實驗室,南昌330013
+通訊作者E-mail:wufangjun@jxufe.edu.cn
1 引言
軟件缺陷(fault),又稱為錯誤(error)、故障(defect)、失效(failure)、bug、問題(problem)等[1-5],是軟件如影隨形的特有成分。雖然無法完全杜絕缺陷,但可以對其進行分析與監測,以盡量減少缺陷[1-5]。軟件缺陷預測是一種能夠有效地挖掘軟件中可能還遺留而尚未被發現的潛在缺陷及其分布情況的技術。通常利用數據挖掘、機器學習和統計學習等通過對軟件產品屬性、過程屬性和已經發現的缺陷數據等各種歷史數據進行綜合挖掘和分析,從而預測軟件系統中存在的缺陷模式。在提高軟件質量、開發過程的可控性和用戶需求的滿足程度,降低軟件開發成本和開發過程的風險,改進軟件開發過程等方面起著非常重要的作用,是近年軟件數據挖掘領域的研究熱點之一[6-15]。軟件缺陷預測從20 世紀70 年代發展至今,一直受到來自軟件產業界和學術界兩方面的關注。
在產業界,項目經理和軟件工程師發現隨著軟件系統的規模越來越大,系統的復雜程度也越來越高,相應地花費在軟件缺陷修正上的費用也越來越昂貴,消耗的時間也越來越多。既然完全消除缺陷是不可能的,那么借助于缺陷預測對其進行預測分析以盡量減少也是不錯的選擇。產業界的項目經理和軟件工程師早已意識到軟件缺陷預測在改善系統質量方面起著重要作用,也迫切希望將其作為軟件項目開發管理的重要環節,運用到軟件工程實踐活動中。在學術界,學者們提出了眾多軟件缺陷預測方法,進行了一系列實證,取得了斐然的成績[6-33],尤其是基于軟件度量的軟件缺陷預測成果豐碩。
為了對現有的軟件缺陷預測研究進行深入細致的分析對比和總結,在中國知網、Elsevier、Wiley、Springer、ACM、IEEE 等數據庫中,以中文關鍵詞“軟件缺陷預測”和英文關鍵詞“software defect prediction”進行檢索,截止到2019 年4 月17 日,檢索結果如表1所示。由于相關文獻太多,因此選擇了其中一些經典的文獻(側重于國內的研究工作)進行論述。

Table 1 Search results表1 檢索結果
本文從靜態軟件缺陷預測的四個關鍵要素,即軟件度量指標的篩選、測評數據資源庫、缺陷預測模型的構建和缺陷預測模型的評價,綜述了現有的研究工作;指出了靜態軟件缺陷預測面臨的挑戰和新問題,展望了進一步的研究方向。
雖然近年來有同類的工作[10,15,21],但本文的側重點與它們有所不同。(1)在軟件度量指標方面,文獻[10,15,21]側重于從代碼復雜度、程序模塊間依賴性、軟件開發過程、開發人員經驗和項目團隊組織架構等多個角度總結已有的度量指標;而本文認同度量指標存在冗余的觀點,因此更側重于度量指標的篩選(即特征選擇)。(2)在缺陷預測模型構建方面,文獻[10]將缺陷預測分成傾向預測、數量/密度預測和嚴重等級預測,相應的方法有統計方法(如K最近鄰、線性回歸)、有監督方法(如隨機森林、模糊方法、信念網絡、支持向量機)、半監督方法(如最大期望法)和無監督方法(如模糊聚類、K均值);文獻[15]將缺陷預測分成傾向預測和數量/密度預測,相應的方法有機器學習方法和基于緩存的方法;文獻[21]側重考察跨項目軟件缺陷預測,相應的方法有基方法(如樸素貝葉斯、邏輯斯蒂回歸)、優化方法(如裝袋、提升、遺傳算法)和復合方法;本文將缺陷預測分成傾向性預測、數量/密度預測和模塊排序,除了總結機器學習方法之外,也總結了復雜網絡、多目標優化和深度學習等方法。此外,本文還就缺陷預測模型的評價方面進行了總結,從如何將缺陷預測模型運用到產業界角度出發,重點考慮了缺陷的嚴重等級。
2 軟件缺陷預測的分類
軟件缺陷預測的研究與應用,自1971 年Akiyama[1]提出至今,受到了學術界和軟件產業界的高度重視,取得了可喜的成就[6-33]。
根據數據來源不同,軟件缺陷預測可分為[19-20]:(1)版本內缺陷預測,只使用軟件系統的某個特定版本的數據進行缺陷預測;(2)跨版本缺陷預測,使用軟件系統的幾個不同版本的數據進行缺陷預測;(3)跨項目缺陷預測,使用一個軟件系統的數據預測另外一個軟件系統的缺陷;(4)混合項目缺陷預測,借助于輔助軟件系統的大量數據,再結合目標軟件系統的少量數據,預測目標軟件系統的缺陷。跨項目缺陷預測和混合項目缺陷預測主要采用遷移技術[19-33],如吳方君[19]將遷移學習方法TrAdaBoost(transfer Ada-Boost)和代價敏感AdaC2 相結合,提出了AdaC2Tr-AdaBoost 方法;Limsettho 等[22]指出數據分布不均衡和源數據集與目標數據集的分布不一致是造成跨項目缺陷預測效率低下的原因;戴翔等[23]在Burak過濾法和SMOTE(synthetic minority over-sampling technique)法的基礎上用投票方式來集成七種分類方法的預測結果;Chen 等[24]提出了DTB(double transfer Boosting),使用數據引力法重塑了源數據集的整體分布,使之與目標數據集的分布相匹配,在部分已標記的目標數據的基礎上借助遷移增強方法來消除源數據中起消極作用的數據;Xia 等[25]提出了HYDRA(hybrid model reconstruction approach)方法,遺傳算法階段利用遺傳算法為多個分類器分配權重,進而生成一個組合遺傳分類器,集成學習階段利用AdaBoost 從多個遺傳分類器生成最終的分類器;毛發貴等[26]基于TrAdaBoost 提出了MergeTrAdaBoost和MultiTrAdaBoost 法,用遷移學習和自適應增強技術,尋找源數據集中與目標數據集關聯性高的數據;程銘等[27]提出了加權貝葉斯遷移學習法,使用數據引力法將源數據集與目標數據集間的差異轉化為訓練數據的權重,在此基礎上建立分類器;何吉元等[28]提出了半監督集成跨項目軟件缺陷預測方法S3EL(search based semi-supervised ensemble learning),該方法依據每個特征的均值將源數據集劃分成兩部分來構建多個樸素貝葉斯弱分類器,再借助于遺傳算法來組合上述弱分類器,進而構建出最終的分類器;李一露等[29]先利用版本級訓練數據選擇方法rTDS(release-level training data selection)從候選的跨項目訓練數據集中選擇與目標數據集距離近的源數據集,然后再利用實例級訓練數據選擇方法iTDS(instance-level training data selection)為目標數據集中的每個目標實例返回k個最近的實例,從而構成多粒度數據選擇方法mTDS(multi-granularity training data selection);楊杰等[30]通過多個源項目分別對目標項目進行預測,然后加權得到最終的預測結果,權重同時考慮預測準確度以及源項目與目標項目間的KL散度;Chen 等[32]提出了一種多角度遷移的軟件缺陷預測方法MTDP(multiview transfer learning for software defect prediction),首先構建異構遷移模型,然后通過遷移異構實例來生成模擬實例,再通過協同訓練來標記模擬實例,進而擴展訓練集,最后構建分類器;陳翔等[20]對跨項目軟件缺陷預測進行了綜述;Herbold 等[31]不僅對跨項目軟件缺陷預測進行了綜述,而且開發出了跨項目軟件缺陷預測實驗平臺Cross-Pare(https://crosspare.informatik.uni-goettingen.de/)。有關混合項目缺陷預測更詳細的總結煩請參考文獻[20-21,31]。
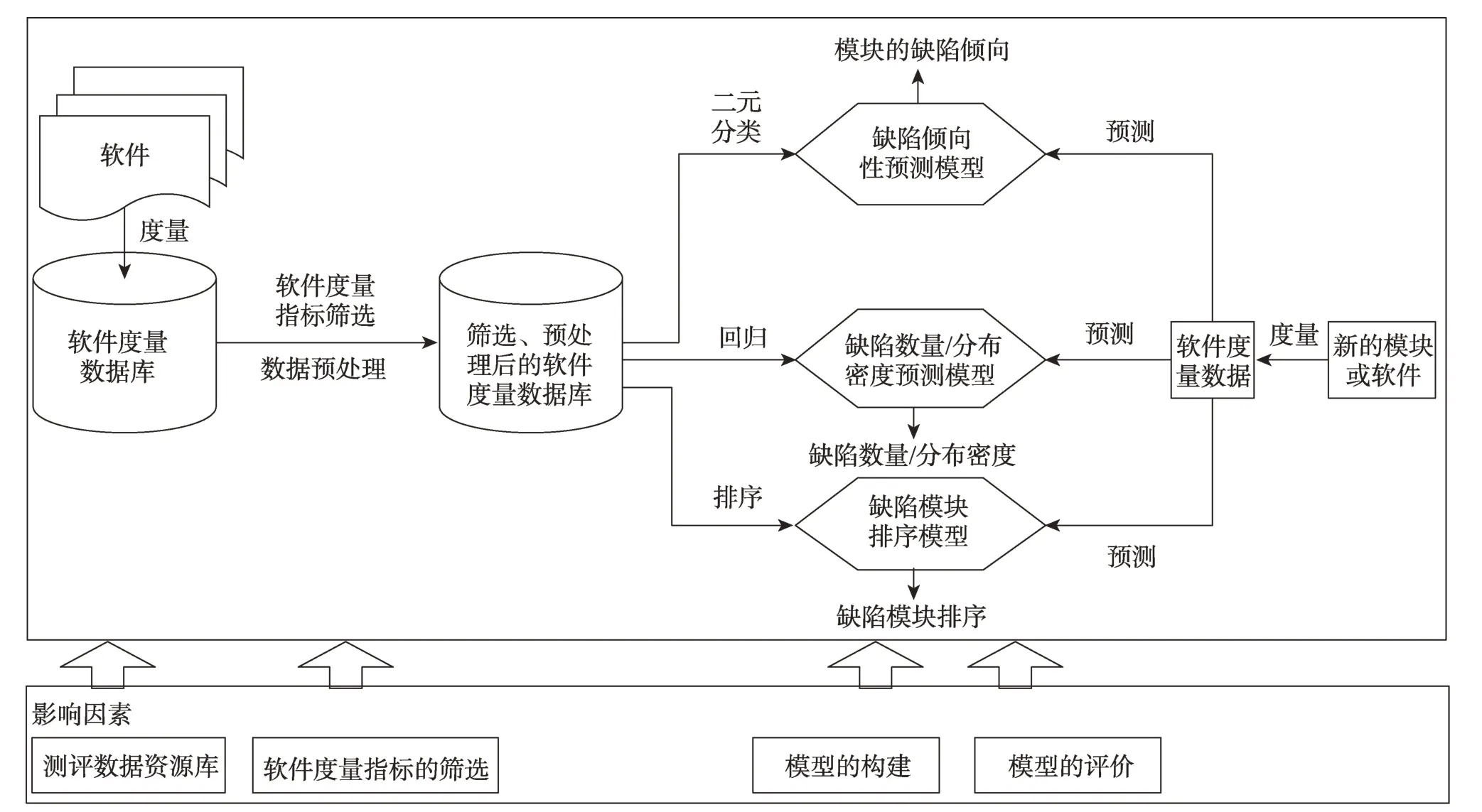
Fig.1 Research framework of static software defect prediction圖1 靜態軟件缺陷預測研究框架
根據是否與軟件生命周期有關,缺陷預測可分為靜態預測和動態預測,后者預測缺陷分布隨軟件生命周期的變化情況,如Rayleigh 分布模型、以Littlewood模型為代表的指數分布模型和S曲線分布模型等。
根據預測目標的不同,靜態缺陷預測又可細分為:(1)缺陷傾向性預測,即預測模塊是否含有缺陷,是一個二元分類問題;(2)缺陷的數量/分布密度預測,即預測模塊中含有的缺陷數量/密度,是一個回歸分析問題;(3)缺陷模塊排序預測,即先預測模塊中含有的缺陷數量或缺陷傾向性概率,然后降序排列,將排名前K(Top-K)的模塊推薦給開發人員進行審查/測試,是一個排序問題。后者介于前兩者之間,適用于測試資源未知的情況。如果人力和物力資源有限,則只審查/測試Top-K模塊;如果人力和物力資源充足,則可以審查/測試全部模塊。研究框架如圖1所示。
根據預測粒度不同,軟件缺陷預測可分為[34]:(1)模塊級預測,即預測模塊含有的缺陷;(2)文件級預測,即預測文件含有的缺陷;(3)變更級缺陷預測,也稱即時缺陷預測,當開發者每次提交變更代碼時,預測其是否存在缺陷,由Kamei等[35]首次提出此概念。
目前,基于軟件度量的靜態軟件缺陷預測是比較成熟和流行的技術,包含四個關鍵要素[15,19]:軟件度量指標的篩選、測評數據資源庫、缺陷預測模型的構建和缺陷預測模型的評價。因此,本文第3~6章將分別綜述上述四方面的現有工作。
3 軟件度量指標的篩選
3.1 軟件度量指標篩選的研究現狀
軟件度量指標主要包括刻畫軟件產品屬性的指標和刻畫軟件開發過程的指標[15,36]。前者包括代碼行數(line of code,LOC)、McCabe 著色圖法、軟件科學法、功能點法、Chidamber 與Kemerer 提出的度量集(簡稱CK 度量集)、Abreu 提出的度量集(metrics for object-oriented design,MOOD)和Bansiya等提出的度量集(quality model for object-oriented design,QMOOD)等經典的基于代碼的度量指標[36]。后者包括有關代碼修改特征的度量、有關模塊間依賴性的度量、有關開發時間/開發人員/開發方法的度量,以及有關項目團隊組織架構的度量等。
面對如此眾多的度量指標,如何進行篩選是構建高質量軟件缺陷預測模型的第一個關鍵。如果不加篩選地采用全部度量指標,會造成三方面的問題。(1)收集全部度量指標需要花費大量的人力和物力,代價太大,有時也是做不到的;(2)部分度量指標間存在冗余,會增加構建缺陷預測模型的時間;(3)部分度量指標與缺陷不相關,會降低缺陷預測模型的性能。
目前,研究者已經對度量指標存在冗余達成統一共識。例如Emam 等[37]在一個電信軟件系統上發現6 個OO(object-oriented)度量與LOC 都是高度相關的,分別是WMC(weighted methods per class)、CBO(coupling between object classes)、RFC(response for classes)、LCOM(lack of cohesion of methods)、NPAVG(average number of parameters per method)和NMA(number of methods added)。Zhou等[38]分析了6個Java 開源系統(Eclipse 2.0、Equinox 3.4、JDT core 3.4、Lucene 2.4.0、Mylyn 3.1 和PDE UI 3.4.1),發現LOC、NMIMP(number of methods implemented in a class)、NumPara(number of parameters in the methods implemented in a class)、NM(number of methods)、NAIMP(number of attributes implemented in a class)、NA(number of attributes)和Stmts(number of statements)等類規模與大部分OO度量存在強相關。
因為度量指標間存在冗余[39-43],Gao 等[40]指出移除85%的度量指標可能會提高預測效果,Shivaji等[41]發現在大部分情況下最多只需要使用10%的度量指標,因此對其進行篩選是非常必要的。Xu 等[42]將度量指標篩選方法細分為5種。(1)過濾式排序法,例如Khoshgoftaar 等[43]比較了包括信息增益法IG(information gain)、卡方法CS(Chi-squared)和信噪比SNR(signal to noise ratio)在內的7種度量指標選擇方法,結果表明IG和SNR更有效。(2)過濾式子集選擇法,例如,楊曉杏[44]提出了一種改進的最小冗余、最大相關度量元分析方法來篩選度量指標,并發現度量指標和個數的選擇很大程度上依賴于數據集。(3)包裹式子集選擇法[45-49],例如,Liu 等[45]提出了3 種代價敏感的度量指標選擇方法,即CSVS(cost-sensitive variance score)、CSLS(cost-sensitive Laplacian score)和CSCS(cost-sensitive constraint score)。Laradji等[46]提出了一種集成方法選擇度量指標。陳翔等[48]提出了一種基于多目標優化算法NSGA-II(non-dominated sorting genetic algorithm-II)的軟件缺陷預測指標選擇方法MOFES(multi-objective optimization feature selection),分別將最小化指標子集規模和最大化AUC(area under the ROC curve)作為兩個優化目標,在Promise 和ReLink 數據集上的實驗結果表明MOFES方法在大部分情況下可以篩選出更小規模的指標子集,并獲得更好的缺陷預測性能。Turabieh等[49]提出了一種分層循環神經網絡(recurrent neural network)方法選擇度量指標,隨機迭代選擇二元遺傳算法(binary genetic algorithm)、二元粒子群優化(particle swarm optimization)和二元蟻群優化(ant colony optimization)對度量指標進行提取,在19 個Promise 數據集上進行了實驗。(4)基于聚類的方法,例如,劉望舒等[50]提出了一種基于聚類分析的度量指標選擇方法FECAR(feature clustering and feature ranking),首先將具有冗余關系的度量指標聚于簇中,然后對每一個簇中的度量指標按照它們與缺陷的相關性降序排列,最后從每一個簇中選取指定數量的度量指標。在Eclipse和NASA數據集上的實驗結果表明集成少數度量指標的缺陷預測模型的性能優于集成所有度量指標的。Xu等[51]也提出了一種基于聚類分析的特征選擇方法MICHAC(maximal information coefficient with hierarchical agglomerative clustering),該方法采用最大信息系數對候選指標進行排名,進而過濾掉不相關的特征;然后采用層次凝聚法對指標進行聚類,只保留每組中的一個指標,去除冗余指標。(5)基于抽取的方法,例如,朱朝陽等[52]提出了基于主成分分析的軟件度量指標選擇方法。
上述度量指標篩選方法雖然考慮了度量指標間的相關性,考慮了度量指標與軟件缺陷間的相關性,也考慮了類規模與軟件缺陷間的相關性,但卻忽略了類規模對度量指標與軟件缺陷間關聯的混和效應,即度量指標與軟件缺陷之間的相關是真相關,還是由于類規模的原因引起的偽相關。
在類規模的混和效應分析方面,Emam等[37]在一個電信軟件系統上對WMC、DIT(depth of inheritance tree)、CBO、RFC、LCOM、NPAVG 和NMA 等7 個OO度量進行了LOC 的混和效應分析,研究結果表明:LOC對WMC、CBO、RFC和NMA的軟件缺陷預測能力具有強的混和效應。Zhou 等[38]在6 個Java 開源軟件系統上對55 個OO 度量進行了7 個類規模(LOC、NMIMP、NumPara、NM、NAIMP、NA和Stmts)的混和效應分析。研究結果表明:類規模對OO度量的混和效應廣泛存在,并且大多數過高地評估了OO度量的軟件缺陷預測能力,并提出了一種基于線性回歸的混和效應剔除方法。
此外,盧紅敏等[53]在102 個Java 開源軟件系統上檢查7 個類規模(LOC、NMIMP、NumPara、NM、NAIMP、NA和Stmts)對55個OO度量的易變性預測是否存在混和效應。隨機效應元分析結果表明:類規模對大多數的OO度量具有混和效應,甚至在許多情況下會導致虛假相關。
吳方君[54]在Eclipse的兩個版本2.0和2.1上檢測了3個類規模(LOC、NMIMP和NumPara)對55個OO度量的易變性預測是否存在混和效應。實驗結果表明:在軟件易變性預測中類規模對大部分OO度量存在混和效應,個別不存在混和效應。
3.2 軟件度量指標篩選面臨的問題
雖然類規模的混和效應分析工作為軟件度量指標篩選開啟了一個新窗口,但是縱觀先前的工作發現:或者只分析了少量的軟件系統,最多也只分析了6 個軟件系統;或者只分析了開源系統,得出的結論能不能推廣到其他更多的系統中尚存疑問。為此,非常有必要在大量學術界、開源界和產業界軟件系統的基礎上甄別OO 度量與軟件缺陷間相關性的真偽,幫助人們正確認識OO度量和軟件缺陷之間的關系,是否有必要將類規模作為混和變量考慮進來。
4 測評數據資源庫
4.1 測評數據資源庫的研究現狀
目前測評數據資源庫可劃分為三大類:(1)公共專業數據資源庫,如NASA(https://github.com/klainfo/NASADefectDataset)、Promise(http://promise.site.uottawa.ca/SERepository/datasets-page.html)、Softlab(https://github.com/klainfo/DefectData)和NETGENE(https://hg.st.cs.uni-saarland.de/projects/cg_data_sets/repository)。(2)公共非專業數據資源庫,如Harvard 數據資源庫(https://dataverse.harvard.edu/)。(3)個人專業數據資源庫,有部分學者在版本控制系統,如CVS(concurrent versions system)、Git(Georgia Institute of Technology)、SVN(subversion),以及缺陷追蹤系統,如Bugzilla(bug-tracking system)、JIRA、Mantis、Trac,和開發人員的相關往來郵件等的基礎上自行組建個人專業數據資源庫,如Zimmermann數據集(https://www.st.cs.uni-saarland.de/softevo/bug-data/eclipse/)、AEEEM數據集(http://bug.inf.usi.ch/)和ReLink 數據集[55]。Jing 等[56]和陳翔等[20]分別從數據來源、度量指標等方面對比分析了部分測評數據集。
此外,由于在軟件系統中缺陷服從帕累托(Pareto)原則[3],即20%的模塊包含了80%的缺陷,真正含有缺陷的模塊是少數,因此會出現類不平衡問題。國內外學者針對不平衡分類問題相繼提出了各種解決方案,大體上可以分為:數據預處理層面的重采樣方法和劃分方法,特征層面的特征選擇方法,分類算法層面的分類器集成、代價敏感方法和單類學習方法。有關不平衡數據分類更詳細的總結煩請參考文獻[57-59]。
4.2 測評數據資源庫面臨的問題
目前測評數據資源庫主要存在三方面的問題。(1)測評數據資源庫較少,在此基礎上得出的實驗結論具有一定的偏頗性,是否具有通用性,值得進一步檢驗。(2)部分測評數據集是從開源項目收集的,而開源軟件的開發方式與產業界商業軟件的開發方式存在著比較大的差異,前者一般由多人分布式開發,后者由多人集中式開發。在開源軟件數據上構建的缺陷預測模型在產業界的實用性比較差,甚至不如隨機猜想,是否與測評數據有關,值得進一步驗證。(3)大部分數據資源庫描述了模塊的缺陷傾向性,或者缺陷的數量,只有少數刻畫了缺陷的嚴重等級,無法滿足軟件產業界的需求。有了缺陷的嚴重等級數據,項目經理就可以將有限的人力和物力資源合理、高效地分配在真正需要審查/測試的軟件模塊上。
5 缺陷預測模型的構建
5.1 缺陷預測模型構建的研究現狀
缺陷預測模型的構建方法隨著預測目標的不同而各異。
5.1.1 缺陷傾向性預測模型的構建
當預測目標是缺陷傾向性時,經常采用分類法。最初是經驗預測階段,研究人員在軟件規模和軟件復雜度的基礎上憑經驗預測軟件缺陷;后來逐漸進入到智能預測階段,Malhotra[14]指出機器學習方法是使用頻率最高的。典型的缺陷預測模型構建方法如邏輯斯蒂回歸分析(logistic regression,LR)、樸素貝葉斯(na?ve Bayes,NB)、決策樹(decision tree,DT)、人工神經網絡(artificial neural network,ANN)、隨機森林(random forest,RF)、泊松回歸(Poisson regression,PR)、負二項回歸(negative binomial regression,NBR)和支持向量機(support vector machine,SVM)等。
Hall 等[12]總結了2000—2010 年發表的208 篇文獻,指出LR和NB是最優的;陳翔等[20]統計了2016年7月以前發表的56篇文獻,指出LR、NB、DT、SVM和RF 使用頻率最高,同時指出分類方法中參數取值的不同會影響預測性能;Tantithamthavorn 等[60]也分析了分類方法中不同的參數取值對預測性能的影響,建議把這種影響納入考慮范圍。
Jiang等[61]提出了一種半監督的軟件缺陷預測方法ROCUS(random committee with under-sampling),該方法利用半監督學習來解決標記樣本數量少的問題,利用欠抽樣方法解決數據不均衡問題,并在8 個NASA數據集上進行了實證。
王鐵建等[62]提出了一種基于核字典學習的軟件缺陷預測方法,該方法利用核方法將數據映射到一個高維空間,之后采用核字典基選擇策略學習得到核字典,最后預測模塊的缺陷傾向性,并在NASA 數據集上進行了實證。
楊杰等[63]提出了基于Boosting 的代價敏感軟件缺陷預測方法,該方法用隨機屬性子集選擇法降低Boosting重抽樣過程中的維度災難,為漏報和誤報增加不同的代價敏感因子,并在NASA數據集上進行了實證。
傅藝綺等[64]提出了基于組合機器學習的軟件缺陷預測,該方法將LR、DT、NB和ANN等幾種算法的預測結果作為新的度量指標加入數據集,之后運用Stacking集成學習方法再次預測缺陷,在Eclipse數據集的實證驗證了其有效性。
雖然軟件缺陷預測方法大多是基于機器學習的,但是也有研究人員從復雜網絡[65-67]、多目標優化[68-75]和深度學習[76-80]等方面入手。
(1)基于復雜網絡的軟件缺陷預測方法比較少。例如,Wu[65]通過UML(unified modeling language)類圖將軟件系統映射為有向復雜網絡,之后研究了軟件網絡復雜性度量與典型的OO度量之間的關系,指出雖然兩者不顯著相關,但是前者從不同側面對OO度量起到一個較好的補充;雖然軟件網絡復雜性度量對軟件缺陷預測方面有提高作用,但提高的程度不顯著。劉慶山[66]通過函數間的調用關系將軟件系統映射為有向復雜網絡,之后采用網絡度量指標數據對缺陷進行預測,并指出網絡度量是有效的。Ma等[67]在軟件網絡度量指標的基礎上進行缺陷預測,并指出網絡度量在不同的系統上表現差異比較大,并在6 個Firefox 版本、5 個Eclipse 版本、9 個開源系統(JEdit、Ant、Camel、Ivy、Poi、Lucene、Xalan、Xerces 和Tomcat)的28個版本上進行了實證。
(2)基于多目標優化的軟件缺陷預測方法也較少。Khoshgoftaar 等[68]提出了一種以誤分代價最小化、決策樹復雜度最小化和可用資源最優為目標的缺陷預測方法;Carvalho等[69]提出了一種以高缺陷檢測率和低誤報率為目標的粒子群優化方法MOPSO(multi-objective particle swarm optimization);楊曉杏[44]提出了一種結合代碼敏感SVM和多目標優化策略的非支配排序遺傳算法NSGA-II-based SVM 來對缺陷模塊序列進行排序,其中高缺陷檢測率和低資源浪費率是兩個優化目標,并在17個Promise數據集上驗證了其高效性;Canfora 等[70]提出了一種以高缺陷檢測率和LOC 最小化為目標的缺陷預測方法MODEP(multi-objective defect predictor);Shukla 等[71]提出了一種以誤分代價最小化/召回率最大化為目標,或者可用資源最優/召回率最大化為目標的缺陷預測方法;Ryu 等[72]提出了一種以高缺陷檢測率、低誤報率和高整體性能為多目標的樸素貝葉斯缺陷預測方法;Chen 等[73]在NSGA-II 的基礎上提出了一種以高缺陷檢測率和低資源使用率為多目標的缺陷預測方法。
(3)基于深度學習的軟件缺陷預測方法也比較少。例如,甘露等[78]通過疊加多層限制玻爾茲曼機(restricted Boltzmann machine,RBM)對度量指標進行集成,在此基礎上進行深度學習,之后提出了基于深度信念網(deep belief networks,DBN)的軟件缺陷預測模型DBNSDPM(deep belief network software defect prediction model),并在5個NASA 數據集上進行了實證,實驗結果表明缺陷預測準確性有顯著提高。針對特征冗余和高維性,周末等[79]提出了一種基于深度自編碼網絡的軟件缺陷預測方法,并在6 個NASA、Promise 和NETGENE 數據集上進行了實證。針對特征冗余和數據不均衡性,徐海濤等[80]提出了一種結合稀疏自編碼神經網絡(sparse autoencoder neural networks)和過采樣技術SMOTE 的軟件缺陷預測方法,并在NASA數據集上進行了實證。
針對分類任務的缺陷預測時,有少數研究者考慮缺陷嚴重等級。Zhou等[81]將缺陷嚴重等級劃分為高低。Singh等[82]將其劃分為高中低。Tian等[83]將其劃分為Trival、Minor、Major、Ctritical 和Blocker。Zhang等[13]將 其 劃 分 為Trivial、Minor、Normal、Critical 和Blocker。Chen等[84]通過模塊間的依賴關系將軟件系統映射為有向復雜網絡,之后在軟件網絡度量指標的基礎上進行高危缺陷預測,其中高危缺陷是指嚴重等級是Major、Critical 或Blocker,指出基于網絡度量指標的高危缺陷預測性能可以與基于代碼度量指標的高危缺陷預測性能相媲美,并在Firefox、Eclipse、Ant 和Hbase 上進行了實證。喻維[85]采用主動學習和半監督學習相結合的方法預測缺陷的嚴重程度。
5.1.2 缺陷數量/分布密度預測模型的構建
當預測目標是缺陷的數量或分布密度時,通常采用多元線性回歸分析MLR(multiple linear regression)[1,6,86-89],例如Akiyama[1]提出了Akiyama 模型,用于刻畫LOC與缺陷數量之間的關系;Gao等[6]比較了以NBR 和PR 為代表的8 種廣義線性回歸模型的性能。此外,也有研究人員從其他方面入手解決上述問題。例如,Livshits 等[86]開發了一個缺陷檢測工具DynaMine,利用關聯規則挖掘那些因為未配對使用某些程序構造(如方法調用等)而造成的缺陷,并在Eclipse 和JEdit 上進行了驗證;Nguyen 等[87]基于模塊間的相似性來預測缺陷的數量,K個近鄰模塊所含的缺陷數量的均值就是模塊所含缺陷數量的預測值;簡藝恒等[88]依據缺陷模塊和無缺陷模塊的比例,借助SMOTE多次過采樣得到多個數據集,之后利用回歸分析得到多個軟件缺陷數量預測模型,將上述多個模型的預測值的均值作為最終的預測值。
5.1.3 缺陷模塊排序模型的構建
當預測目標是缺陷模塊排序時,一般采用分類法和回歸分析技術,例如采用最小二乘法或最大似然法預測的多元線性回歸、RF、以NBR 為代表的廣義線性回歸和SVM等,也有研究人員從聚類、排序學習(learning to rank,LTR)方面入手解決該問題。
楊明[90]提出了一種基于聚類的缺陷模塊排序預測方法LSDB(largest-cluster started distance based),該方法在代碼級度量數據的基礎上,首先利用Kmeans 或者X-means 等算法對模塊進行聚類,然后進行簇間排序,最后進行簇內模塊排序。進行簇間排序時,作者將包含模塊最多的簇排在第一位,計算剩余簇的中心點到第一個簇的中心點的歐式距離,按照距離升序排列。進行簇內模塊排序時,計算模塊與該簇中心點的歐式距離,按照距離升序排列。LSDB 方法預測出來的缺陷模塊序列是按照缺陷概率升序排列的。
隨后趙東曉[91]也提出了四種基于聚類的缺陷模塊排序預測方法,基本框架與楊明方法[90]一樣,不同之處在于簇間排序和簇內模塊排序方法,不僅根據軟件缺陷服從Pareto 原則[3],而且還參考軟件模塊包含缺陷的概率與其規模成反比[4]來設定排序方法。第一種方法MSSB(minimum-size-cluster started size based)進行簇間排序和簇內模塊排序時均按照LOC升序排序。第二種方法SSDB(smallest-cluster started distance based)進行簇間排序時,將包含模塊最少的簇排在第一位,剩余簇的中心點到第一個簇的中心點的歐式距離升序排列;對于簇內模塊排序時,按照模塊與該簇中心點的歐式距離升序排列。第三種方法SSSB(smallest-cluster started size based)進行簇間排序時,按照簇包含的模塊數量升序排列;對于簇內模塊排序時,按照模塊的LOC 升序排列。第四種方法SSDSB(smallest-cluster started distance and size based)進行簇間排序時,將包含模塊最少的簇排在第一位,按照剩余簇的中心點到第一個簇的中心點的歐式距離升序排列;對于簇內模塊排序時,按照模塊的LOC升序排列。四種方法預測出來的缺陷模塊序列均是按照缺陷概率降序排列的。
田青青[92]提出了一種多次迭代的、基于反饋的圖像檢索框架的半監督協同缺陷模塊序列排序方法SSADP:首先將未標記缺陷傾向性的模塊按照LOC升序排列;然后選擇排在前面的2%模塊手工標記上缺陷傾向性類標簽,作為初始的訓練數據集;最后訓練分類器,并預測剩余模塊的缺陷傾向性,根據預測值降序排列軟件模塊,返回給用戶。
近年來,越來越多的研究者借助于多目標優化和機器學習中的排序學習[93]來解決缺陷模塊排序預測問題。楊曉杏等[44,94]在線性模型的基礎上提出了一種軟件缺陷模塊排序預測方法,該方法以FPA(faultpercentile-average)為優化目標,利用組合差分進化(composite differential evolution,CoDE)算法[95]來獲得參數,并在6 個Zimmermann 數據集和5 個開源系統(Eclipse JDT core、Eclipse PDE UI、Equinox framework、Mylyn 和Apache Lucene)的數據集上驗證了其有效性。隨后,Priya 等[96]引入玻爾茲曼機來增強排序學習的能力。Nguyen 等[87]將經典的排序學習算法RankSVM 和RankBoost 應用于缺陷模塊排序預測中,并在5 個開源系統(Eclipse JDT Core 3.4、Eclipse PDE UI 3.4.1、Mylyn 3.1、Equinox framework 3.4 和Apache Lucene 2.4.0)的數據集上驗證了其有效性。You 等[97]在多元線性回歸分析的基礎上提出了一種軟件缺陷模塊排序預測方法ROCPDP(rankingoriented approach to cross-project defect prediction),利用梯度下降法來獲得參數,并在5 個AEEEM 數據集和34個Promise數據集上驗證了其有效性。
5.2 缺陷預測模型構建面臨的問題
學者們從不同角度、采用不同方法和技術,針對不同的軟件缺陷預測問題展開了深入、細致的研究和應用,取得了豐碩的成果,為后續研究和應用奠定了扎實的基礎。雖然在缺陷管理領域考慮嚴重程度和優先級的工作開展得比較多[98-99],但是在缺陷預測領域考察缺陷嚴重程度研究相對少[9,81-85],兩者的區別在于前者已經通過代碼審查/測試等途徑知道了缺陷的存在,只不過嚴重程度的標識可能由于提交者初步確定時存在一些錯誤,需要進行修正;而后者是不知道哪些模塊存在缺陷,需要通過預測為項目經理和軟件工程師合理分配物力、人力資源在真正需要審查/測試的模塊上提供指導和幫助。針對分類任務的缺陷預測,只有少數學者考慮了缺陷嚴重等級[9,81-85];針對排序任務的缺陷預測,只有You等[97]將缺陷嚴重等級納入考慮。軟件產業界中的真實情況是軟件不僅包含缺陷,而且缺陷還有等級之分。如缺陷追蹤系統Bugzilla 和Eclipse 工程師不僅將缺陷劃分成Blocker(系統崩潰)、Critical(部分主要功能缺失,影響系統使用)、Major(部分功能缺失,不影響系統使用)、Normal(部分功能存在缺陷)、Minor(系統功能齊全,但存在瑕疵)、Trivial(小問題)、Enhancement(需要完善)等7個等級,而且還設置了優先級Priority指標,從最高優先級P1到最低優先級P5。
根據軟件缺陷服從Pareto[3],而且模塊包含缺陷的概率與其規模成反比[4]的原則,在此舉了一個比較符合軟件產業界真實情況的例子。如表2 所示,3 個模塊包含了不同嚴重程度、數量不等的缺陷。表3給出了3個模塊在不同情況下的排列順序。
表3 中,當進行缺陷模塊排序預測時,在考慮代碼審查/測試工作量的情況下,3 個模塊的審查/測試順序是C、A、B。簡而言之,按照C、A、B 的順序對3個模塊進行代碼審查/測試最符合軟件產業界的真實情況。因為致命的缺陷會導致系統崩潰,嚴重的缺陷使系統主要功能喪失,這兩種類型的缺陷是一定要修改的,不管缺陷所在模塊的規模大小;一般缺陷使系統部分功能無效,這種類型的缺陷也是需要修改的,但是需要考慮缺陷所在模塊的規模大小;提示只是警告,這種類型的缺陷可以在人力和物力資源充足的條件下修改。從成本收益的角度來講,模塊C、A、B的排序是最好的。
6 缺陷預測模型的評價
6.1 缺陷預測模型評價的研究現狀
目前,模型評價標準可劃分為針對分類預測能力的評價標準和基于代碼審查/軟件測試工作量感知的評價標準。評價分類預測能力的標準比較多,如準確率(accuracy)、查準率(precision)、召回率(recall)、F值、G-Mean(geometric mean of precision and recall)、AUC 和MCC(Matthews correlation coefficient),它們的值越大越好;I型錯誤率和II型錯誤率,它們的值越小越好。上述指標的使用需要滿足一個前提條件,即項目經理和軟件工程師有充足的人力和物力資源可以審查/測試所有的代碼模塊,但是在軟件產業界卻是不現實的,為此研究者們提出了基于代碼審查/軟件測試工作量感知的評價標準,如基于代碼行的Alberg 圖(也稱為累積提升圖(cumulative lift chart,CLC))[8]、平均缺陷百分比FPA[11]和成本收益曲線下面積(area under the cost-effectiveness curve,AUCEC)[100]及PofB20指標[101],它們的值越大越好。特別地,CLC和FPA線性相關[44,94],且FPA更簡單、更易理解。
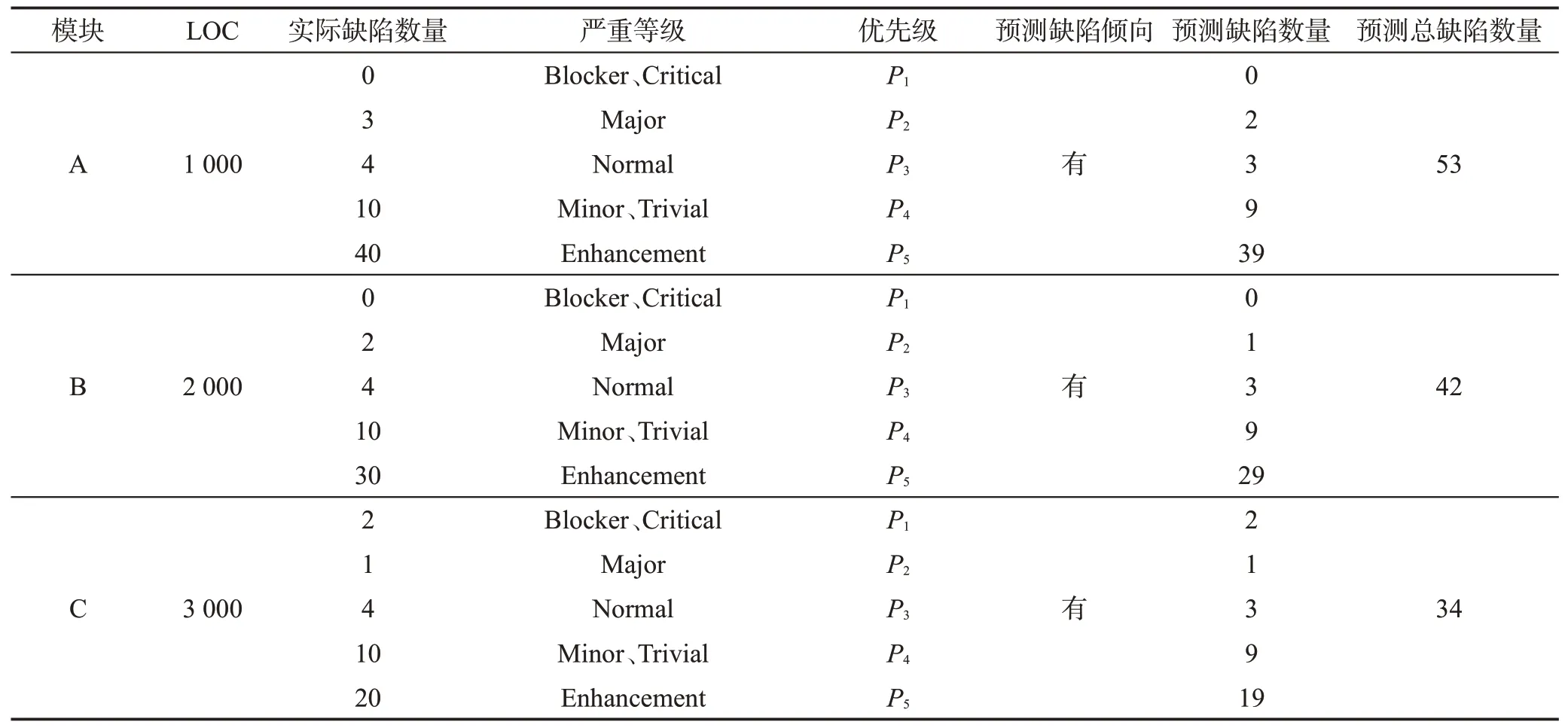
Table 2 Example表2 示例

Table 3 Sequence表3 排列順序
6.2 缺陷預測模型評價面臨的問題
雖然基于代碼審查/軟件測試工作量感知的評價標準更符合軟件產業界的現實狀況,但是它們只評價了缺陷傾向性,而沒有評價缺陷的嚴重等級。
7 研究展望
在國內外眾多學者和軟件開發人員的努力之下,基于軟件度量的靜態缺陷預測取得了斐然的成績,但仍存在一些問題有待于進一步地研究和探討,特別是:
(1)針對排序任務的軟件缺陷預測進行度量指標篩選的工作欠缺。在軟件度量指標篩選方面,研究者已經對度量指標存在冗余達成統一共識,因此有必要對其進行篩選。雖然已經存在若干度量指標篩選方法,但大部分是針對分類任務的軟件缺陷預測開展了度量指標的篩選,針對排序任務的度量指標篩選比較少。度量指標在不同任務的軟件缺陷預測時性能可能有所差異,可能會存在某些度量指標在分類任務時性能良好,但是排序任務時性能差的情況,因此有必要針對排序任務的軟件缺陷預測進行度量指標的篩選,深度學習中的自編碼網絡可能是個不錯的選擇。
(2)未將缺陷嚴重等級納入全面考慮。①已有的大部分測評數據資源庫記載了模塊的缺陷傾向性,或者缺陷的數量,只有少數記載了缺陷的嚴重等級,無法滿足軟件產業界的需求。②大部分軟件缺陷預測只考慮了有無缺陷,較少考慮缺陷嚴重等級,這不符合產業界追求成本收益的目標。③雖然有若干軟件缺陷預測模型的評價標準,但它們只評價了缺陷傾向性,而沒有評價缺陷的嚴重等級,不符合軟件產業界的現實狀況。
(3)隨著云計算技術的發展,互聯網軟件開發出現了一些新的范式,如微服務架構軟件[102]、無服務架構軟件等。微服務架構是Amazon、eBay和Netflix等公司建立的一種軟件體系設計模式,將復雜系統拆分成多個獨立的小系統,具有敏捷開發、持續交付、持續集成等特點;無服務架構是微服務架構的一種表現形式,將代碼放到谷歌Cloud Functions、微軟Azure Functions、亞馬遜AWS Lambda 等平臺上,由平臺來處理與服務器相關的具體細節問題,具有運行維護簡單、開發效率高等特點。這些互聯網軟件開發的新模式隨之帶來了一些新問題和新挑戰,例如一個復雜系統可能由多個采用不同的程序設計語言來編碼的獨立小系統組成,它們的基于代碼的度量數據存在較大差異;由于代碼存放在平臺上,因此通過日志來定位缺陷就比較困難。諸此種種導致傳統的軟件缺陷預測的技術和經驗不適用,即時缺陷預測可能是個不錯的處理辦法。
(4)近年來,如何解決缺陷預測在產業界實際軟件開發中所面臨的各種問題,提升軟件缺陷預測的實用性和經濟性,為管理人員分配有限的人力和物力資源提供指導,以便在付出最小代價的前提條件下,審查/測試出盡可能嚴重、盡可能多的軟件缺陷,進一步把軟件缺陷預測從學術界推向產業界,這是目前亟待解決的問題。
雖然產業界的項目經理和軟件工程師已經意識到軟件缺陷預測在改善系統質量方面起著重要作用,迫切希望將其運用到軟件工程實踐活動中,也已有研究人員在微軟[16]、谷歌[17]和思科[18]等軟件產業界的知名公司進行了軟件缺陷預測的實踐,但是卻發現它們實用性比較差,甚至不如隨機猜想,與學術界開展的如火如荼的軟件缺陷預測理論研究形成了鮮明對比。原因在于:①在產業界,軟件開發成本是有限的,不能把所有的人力和物力資源全部投入到代碼審查/軟件測試中。②在整個軟件生命期中,發現和修正缺陷占用了50%~75%的費用[2],如何把發現和修正缺陷的費用盡量降低,這是產業界所關心的。③真正含有缺陷的模塊是少數,軟件缺陷服從帕累托(Pareto)原則[3],即20%的模塊包含了80%的缺陷。④項目經理和軟件工程師不僅關心系統中是否含有缺陷和缺陷的數量,更關心缺陷的嚴重程度。事實上,缺陷嚴重程度不僅有等級之分,它們造成的后果也是不同的:致命的缺陷會導致系統崩潰,嚴重的缺陷使系統主要功能喪失,一般缺陷使系統部分功能無效。缺陷嚴重等級影響了代碼審查/軟件測試工作,致命(blocker)缺陷和嚴重(critical)缺陷是一定要修改的,一般(normal)缺陷是需要考慮缺陷所在模塊的規模大小來加以修改的,提示(enhancement)類型的缺陷可以在人力和物力資源充足的條件下修改。⑤學術界構建的軟件缺陷預測模型大部分是基于開源項目數據,而開源軟件的開發方式與產業界商業軟件的開發方式存在著比較大的差異,前者一般由多人分布式開發,后者由多人集中式開發,在前者上構建的缺陷預測模型在后者的實用性比較差,甚至不如隨機猜想。已有的軟件缺陷預測方法和技術側重于缺陷的預測能力,未將產業界的實際情況加以深入考察。因此如何將有限的人力和物力資源合理、高效地分配在真正需要審查/測試的軟件模塊上是非常值得研究和非常經濟實用的,缺陷排序預測可能是個有效的措施。
(5)軟件缺陷預測研究工作的再現性和可復制性至關重要,只有可再現性和可復制的工作才有可能運用到軟件工程實踐活動中去;然而,現有研究工作的再現性和可復制性卻比較差。Mahmood等[103]選取208 項高引用的軟件缺陷預測研究工作進行再現性和可復制性實驗,發現只有13 項(6%)是可復制的,而且有1項的結果與原始結果不一致。下一步的研究工作需要注重可再現性和可復制性。
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
兒童故事畫報(2019年5期)2019-05-26 14:26:14
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
