基于深度學習特征提取和WOA-SVM狀態識別的軸承故障診斷
2019-10-19 01:41:14趙春華胡恒星陳保家張毅娜肖嘉偉
振動與沖擊 2019年10期
趙春華,胡恒星,陳保家,張毅娜,肖嘉偉
(1.三峽大學 水電機械設備設計與維護湖北省重點實驗室,湖北 宜昌 443002;2.三峽大學 機械與動力學院,湖北 宜昌 443002)
滾動軸承作為旋轉機械的重要組成部分,在現代工業生產中占據著重要地位。對滾動軸承進行實時準確的狀態監測和故障診斷,不僅能夠保證旋轉機械的性能和穩定性,而且還能延長機械的使用壽命。傳統故障診斷可歸納為特征提取和狀態分類兩個步驟。傳統特征提取方法需要依賴大量信號處理技術和人為主觀判斷,其中包括頻域統計分析、倒頻譜分析、小波變換和經驗模式分解等[1-2];而狀態分類可由K-近鄰算法、SVM(Support Vector Machine)、樸素貝葉斯等[3-6]機器學習算法來實現,這些機器學習方法大多數都是監督學習,需要大量的數據標簽,而在實際監測環境中獲得的數據大部分是無標簽數據,這就給軸承的故障診斷帶來了復雜性,同時傳統機器學習模型分類面臨維數災難、過擬合等問題,其淺層模型難以表征信號樣本與健康狀況之間復雜的映射關系,且缺少必要的泛化能力[7-8]。
近年來,由于神經網絡可以通過隱含層自適應提取到數據的高維特征,所以已經廣泛應用到機械故障診斷領域。同時,2006年Hinton等[9]通過逐層貪婪訓練法解決了深度神經網絡難訓練、易陷入局部最優解的問題,使得深度學習得到迅速的發展。李巍華等[10]利用深度信念網絡對軸承振動原始信號進行處理,取得了較高的軸承故障分類識別率,避免了特征提取與選擇的復雜性,增強了識別過程的智能性。朱煜奇等[11]通過棧式降噪自編碼網絡成功的挖掘高維深層的軸承故障特征,驗證了該方法對故障的識別能力和泛化能力。溫江濤等[12]利用變換域的壓縮采集和堆疊稀疏自編碼網絡對軸承故障信號進行自適應特征提取及診斷,實現了智能、準確的分類。這些非監督式的深度神經網絡可以擺脫對大量標簽的依賴,同時降低特征提取的復雜性,提高了分類準確率。
針對上述問題,本文提出一種深度學習自適應提取故障頻域特征和時域統計特征相融合,并通過WOA-SVM(Whale Optimization Algorithm-SVM)進行狀態識別的模型。該模型優勢在于:①通過建立深度網絡模型,利用逐層貪婪編碼的方法實現低維簡單特征到高維復雜特征的數據挖掘過程,擺脫了人為提取樣本特征的復雜過程,實現了軸承故障診斷的智能化;②深度學習提取故障頻域特征與人工提取時域特征相融合,提高了故障診斷的準確率和可靠性;③通過實驗臺數據分析對比GA-SVM和PSO-SVM模型識別方法,結果表明,WOA-SVM具有更高的狀態識別率以及更快的計算速度。
1 基于深度學習的特征提取
Hinton等提出的深度學習理論用于構建深度神經網絡(Deep Neural Network,DNN),可以通過組合低層特征形成更加抽象的高層特征表示,從而發現數據的分布式特征表達,與淺層神經網絡相比,深度神經網絡具有更加優異的表達能力。針對加速度傳感器采集到的機械故障信號,本文提出基于堆疊降噪自編碼方法實現對故障信號的自適應提取。該方法通過非監督式貪婪訓練法達到逐層初始化的目的,以解決深度神經網絡難以訓練的問題,再利用監督式BP算法進行微調,使DNN具有特征學習能力和判別能力。
1.1 基本自編碼網絡
基本自編碼器是三層的非監督神經網絡,分為編碼網絡與解碼網絡兩個部分,如圖1所示。自編碼器的輸入層和輸出層維數相同,自編碼器的本質是學習一個相等函數,即網絡的輸入和重構后的輸出相等,故編碼矢量成為了輸入數據的一種特征表示,即實現非線性特征降維,這種相等函數的表示缺點是當測試樣本和訓練樣本相差較大,即不符合同一分布時,效果不好,而降噪自編碼器在這方面的處理有所進步[13]。
1.2 降噪自編碼網絡
降噪自編碼器(Denoising Autoencoder,DAE)結構如圖2所示。編碼網絡將以一定概率將輸入層節點的值置為0,從而得到含有噪聲的樣本數據,然后對樣本進行編碼;解碼網絡再根據受到噪聲干擾的數據中估計出未受噪聲干擾樣本的原始形式,從而使DAE從含噪樣本中學習到更具魯棒性的特征,降低DAE對微小隨機擾動的敏感性。DAE的原理與人的感知機理類似,比如人眼看物體時,如果物體某一小部分被遮住了,人依然能夠將其識別出來;另外,多模態信息輸入人體時(比如聲音,圖像等),少了其中某些模態的信息有時影響不大[14]。因此降噪自編碼器可有效減少機械工況變化與環境噪聲等隨機因素對提取的狀況信息的影響,使特征表達的更具有魯棒性[15]。
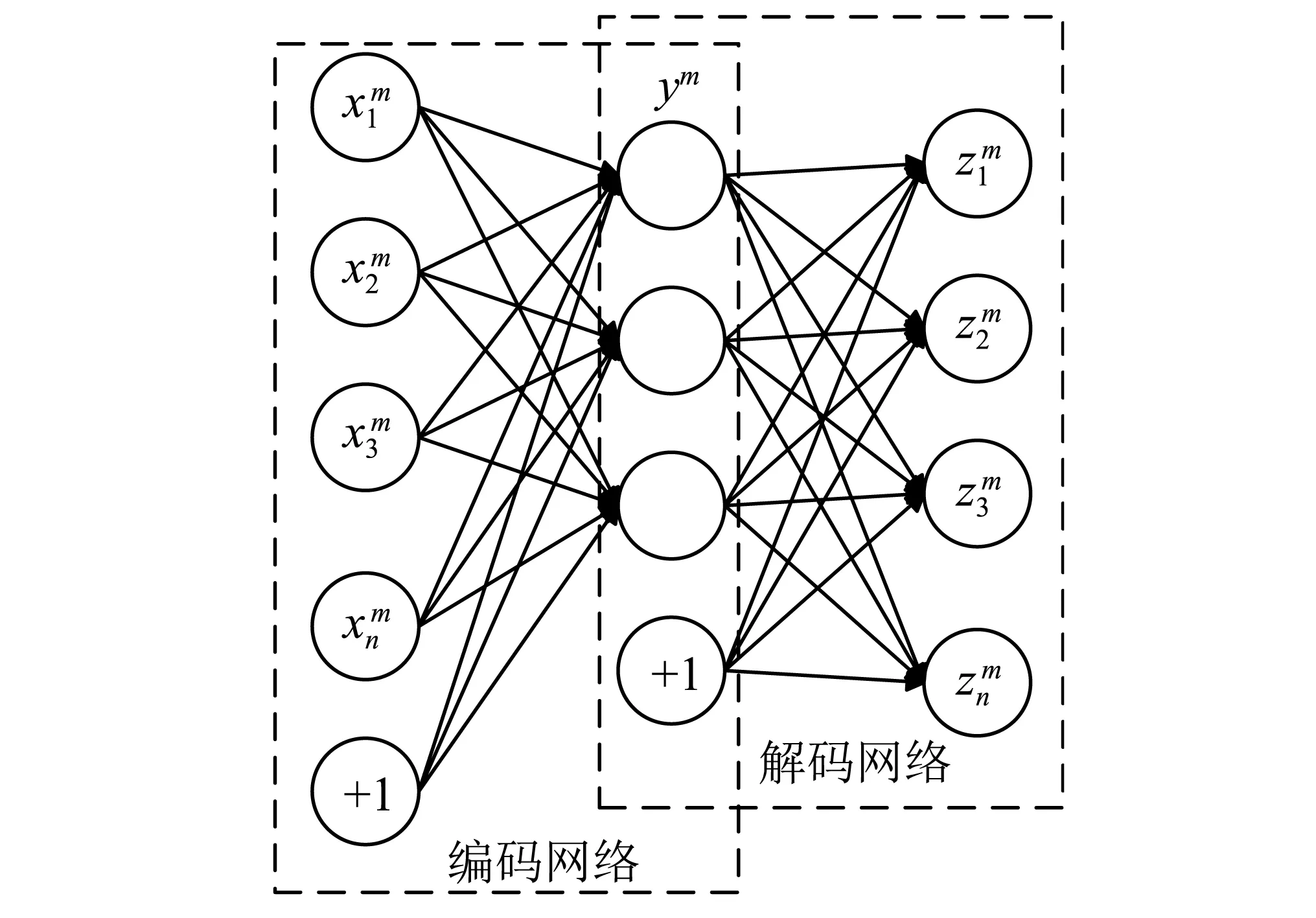
圖1 基本自編碼網絡Fig.1 Basic auto-encoder network
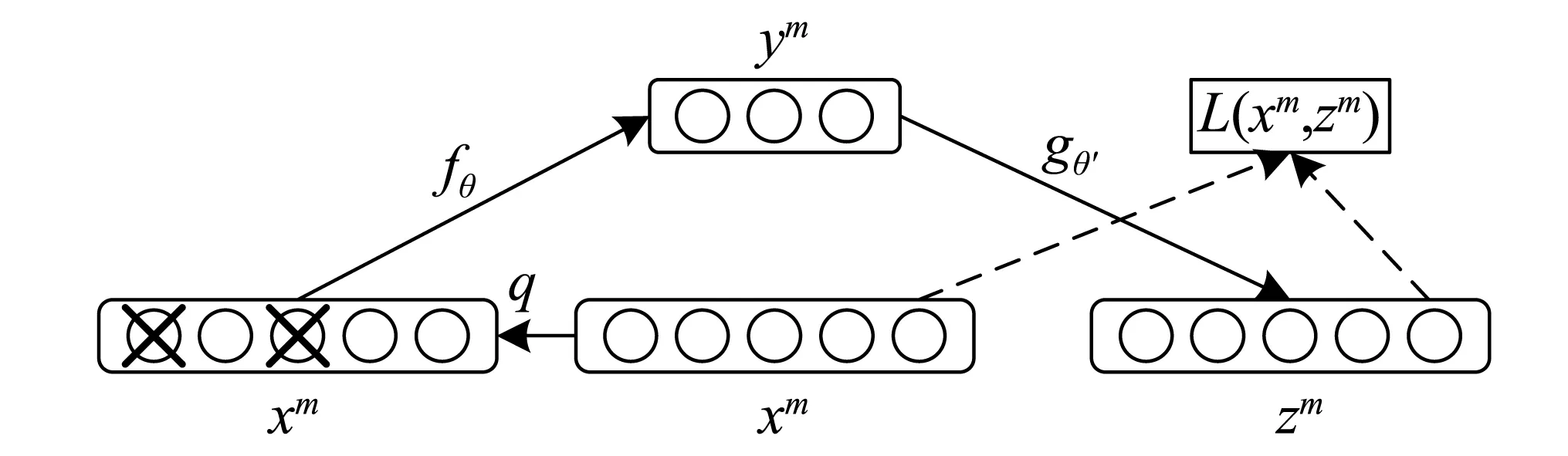
圖2 降噪自動編碼器原理圖Fig.2 Schematic diagram of denoising auto-encoder
假設降噪自編碼網絡的輸入層為{x1,…,xm,…,xM},式中上標表示第m個樣本,總共有M個訓練樣本。輸出層為{z1,…,zm,…,zM}。網絡結構的損失函數為
(1)
編碼網絡階段,輸入信號為前一個自編碼結構的編碼層的值(第一層網絡結構的輸入層為原始輸入信號。其數學表達式為
(2)
解碼網絡階段,將重構出沒有添加噪聲前的原始輸入信號,其數學表達式為
zm=gθ′(ym)=sg(W′ym+d)
(3)
式中:ym為編碼層輸出值;sg為解碼網絡的響應函數;θ′為解碼網絡的參數集合,且θ′={W′,d};W′,d分別為解碼網絡的連接權值和偏置參數。
由上述過程可知,降噪自編碼器屬于非監督學習,不需要任何標簽,依靠最小化輸出層與輸入層信號間的重構誤差,得到編碼層的降維特征。
為了防止結構過擬合增強特征的聚類能力和判別能力,在降噪自編碼器的損失函數中加入稀疏性懲罰項,即得到稀疏降噪自編碼器,其損失函數數學表達式為
(4)
式中:λ為懲罰因子,控制網絡的稀疏程度。
稀疏自編碼網絡有著天然的聚類性質,能夠充分發揮數據所含有的信息,去掉冗余的數據信息,最大化利用數據,使得高層網絡層能夠表達原始數據本質特征,并且具有很強的判別能力。
1.3 堆疊降噪自編碼器預訓練與微調
降噪自編碼器的淺層網絡結構函數表達能力有限。為了增強網絡的表達能力,多個DAE依次堆疊構成深度網絡結構,即堆疊降噪自編碼器(Stacked Denoising Autoencoder,SDAE)[16],如圖3所示。由于DAE各層滿足歸一化要求,因此將上一個DAE的編碼層作為下一個DAE的輸入,以此類推,通過逐層貪婪訓練得到自適應非監督提取的特征,但是逐層最優并不能確保堆疊后分類器整體最優。為了確保堆疊后整體最優,此時需要帶有標簽的樣本數據,采用BP算法進行監督式訓練,實現微調。對每一層預先分別訓練,可以避免傳統深度結構容易陷入局部極小值的問題[17]。相較于傳統的神經網絡隨機初始化權重,深度學習網絡的初始參數是通過無監督學習得到,更接近于全局最優值。
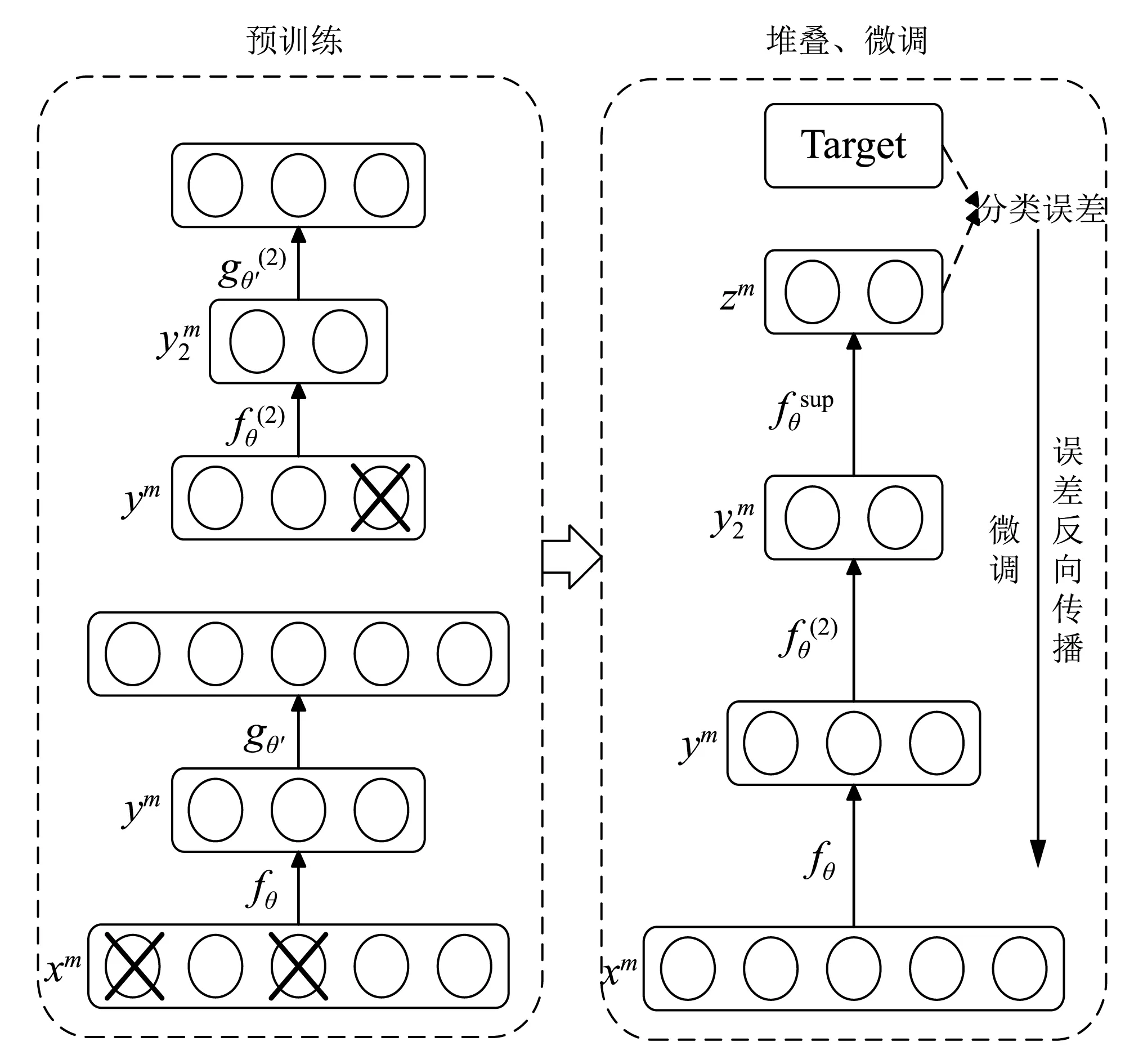
圖3 堆疊降噪自編碼器預訓練與微調示意圖Fig.3 Pre-training and fine-tuning of the stacked denoising auto-encoder
2 WOA-SVM原理
2.1 WOA算法介紹
Mirjalili等[18]于2016年提出了鯨魚優化算法(WOA),該算法對鯨魚的“螺旋氣泡網”策略、收縮包圍、螺旋式位置更新和隨機捕獵機制不斷逼近獵物的狩獵過程進行數學模擬,其具有調節參數少、全局收斂性強、收斂速度快等特點。WOA數學模型包括環繞式包圍捕食、泡泡網攻擊獵物和隨機搜索捕食3個階段。
2.1.1 環繞式包圍捕食
座頭鯨在尋找獵物時,能夠識別它們的位置并將其包圍。具體數學模型為
D=|CX*-X(t)|
(5)
X(t+1)=X*(t)-AgD
(6)
式中:t為當前迭代次數;X*為當前獲得的獵物位置向量;X為鯨魚位置向量;A和C為系數向量,其定義為
A=2agr-a
(7)
C=2gr
(8)
式中:a為收斂因子,隨迭代次數增加從2線性減小到0,表達式為a=2-2t/M,其中M為最大迭代次數;r為[0,1]之間的隨機向量。
2.1.2 泡泡網攻擊獵物
為了建立鯨魚的泡泡網攻擊行為的數學模型,設計了兩種方法來模擬這種行為,數學模型如下:
(1)收縮包圍圈機制(Shrinking Encircling Mechanism,SEM),實現該行為只需要減少式(8)中的a,需要注意的是A隨著a的減小而縮小。
(2)螺旋式位置更新(Spiral Updating Position,SUP),座頭鯨以螺旋運動方式不斷接近獵物,其螺旋運動的數學模型為
X(t+1)=D′geblgcos(2πl)+X*(t)
(9)
式中:D′=|X*(t)-X(t)|為第i條鯨魚和獵物的距離;b用于定義螺旋形狀的常數;l為[-1,1]的隨機數。
但要注意,鯨魚沿著螺旋形狀運動時,同時在收縮包圍圈,為了模擬這種同步行為,Mirjalili等假設選擇收縮包圍圈機制或螺旋位置更新概率均為50%。數學模型為
(10)
式中:p為[0,1]上的隨機數。
2.1.3 隨機搜索捕食
座頭鯨可以隨機更新個體位置捕食獵物。鯨魚根據相互之間的位置進行隨機搜索,具體過程為
D=|CgXrand-X|
(11)
X(t+1)=Xrand-AgD
(12)
式中:Xrand為從當前群體中隨機選擇的個體位置向量。
2.2 WOA-SVM參數優化
WOA-SVM尋優過程為:首先,在搜索空間中隨機產生N個鯨魚個體組成初始種群;接著在進化過程中,群體根據當前最優鯨魚個體或隨機選取一個鯨魚個體更新各自的位置;然后,根據隨機產生的數p決定鯨魚個體進行螺旋或包圍運動;最后,循環迭代至WOA算法滿足終止條件。流程圖如圖4所示。通過WOA對SVM進行參數尋優,可以避免傳統人工反復試錯的過程,結合WOA算法的調節參數少、結構簡單、收斂速度快等特點,實現對SVM的懲罰因子c和核參數g的快速尋優,來提高WOA-SVM狀態識別的正確率。試驗中,以交叉驗證意義下支持向量機的平均分類準確率作為適應度函數,評價鯨群中每個個體的適應度,適應度較高的成員被保留,試圖找到搜索空間內的最佳適應度所對應的c和g。同時,針對懲罰因子c過大會導致過擬合現象的發生,也會使分類器的泛化能力降低,對WOA-SVM作出改進
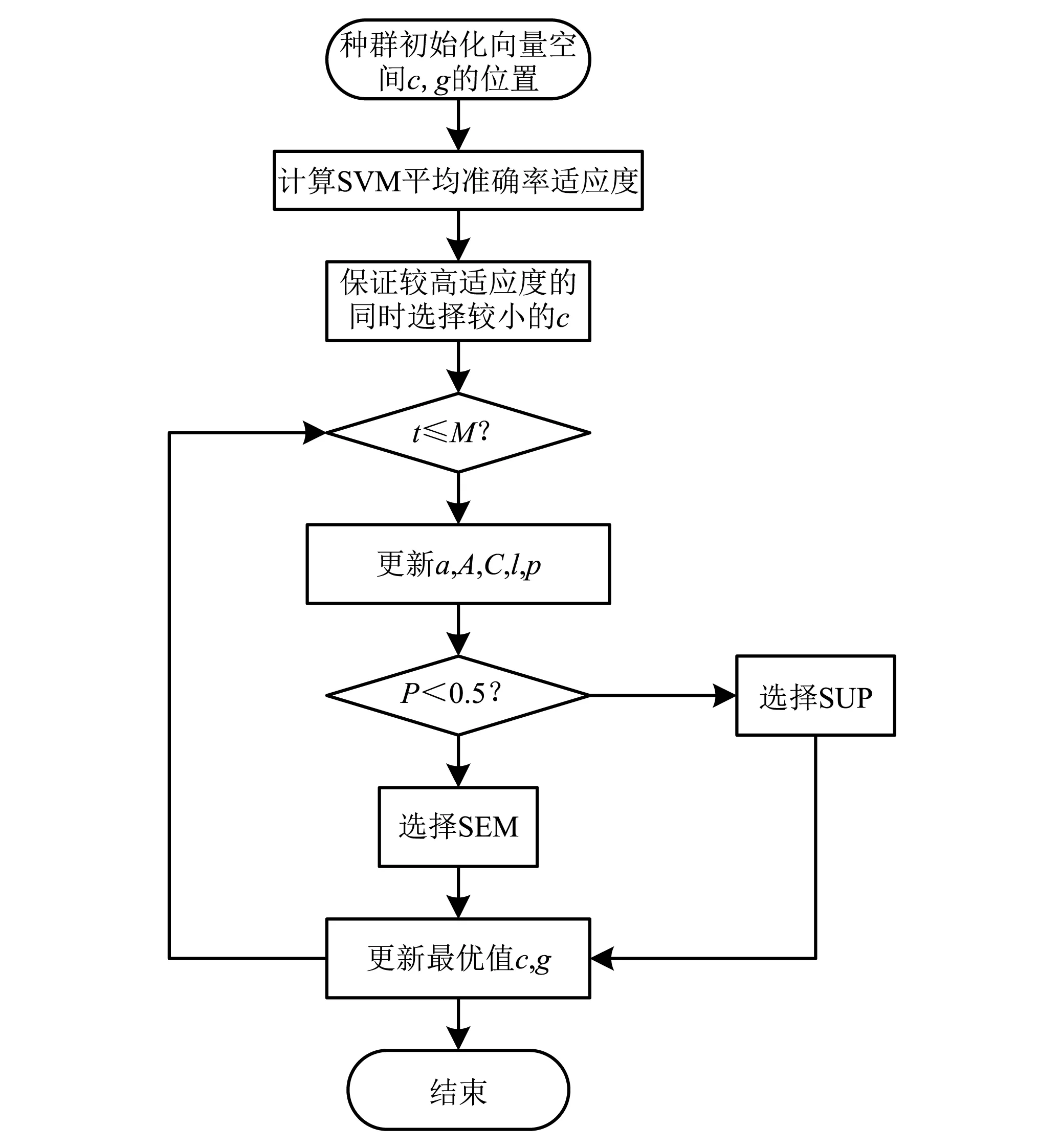
圖4 WOA-SVM算法流程圖Fig.4 WOA-SVM algorithm flow chart
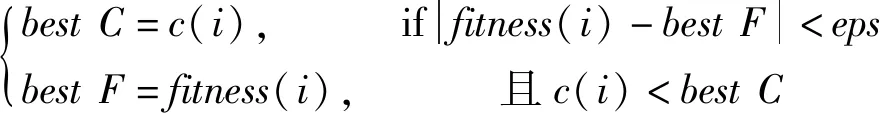
(13)
式中:bestC為當前鯨群最佳懲罰因子c;bestF為當前鯨群最佳適應度;c(i)和fitness(i)分別為第i個鯨魚的懲罰因子c與適應度;eps=0.1為允許降低適應度的閥值;這樣就可以在保證得到較高的適應度時,獲得較小的懲罰因子c。
3 基于深度學習特征提取和WOA-SVM狀態識別的軸承故障診斷
3.1 模 型
基于深度學習特征提取和WOA-SVM狀態識別分類模型可以實現設備故障診斷,如圖5所示。振動信號一般作為軸承故障的分析對象,可以選擇時域分析,也可以選擇頻域分析,試驗表明,頻域信號更加適合作為分類器輸入。相較于傳統機器學習,堆疊稀疏降噪自編碼網絡可以處理高維特征,最大限度保留了樣本信息,通過多個稀疏降噪自編碼疊加,可以有效的提取到輸入樣本的高維特征,再將高維特征輸入WOA-SVM實現軸承的故障診斷。綜上,構建以軸承振動信號頻譜序列為輸入,堆疊稀疏降噪自動編碼器提取高維特征,以WOA-SVM作為故障分類器,可以實現基于深度學習特征提取和WOA-SVM狀態識別的軸承故障診斷。

圖5 基于深度學習特征提取和WOA-SVM狀態識別分類模型Fig.5 Classification model based on deep learning feature extraction and WOA-SVM state recognition
3.2 試驗與驗證
為了驗證深度學習神經網路在故障特征提取中的效果,在自制滾動軸承試驗臺上進行故障模擬試驗,試驗裝置如圖6所示,本試驗臺可以模擬滾動軸承多種故障,如裂紋、腐蝕、剝落等。

圖6 滾動軸承系統試驗臺Fig.6 Rolling bearing system test bench
利用該試驗臺模擬了滾動軸承的10種健康狀況,如表1所示。試驗分3種不同轉速(500 r/min,800 r/min和1 200 r/min)與兩種不同載荷(無載荷與加載)下進行。試驗中,采樣頻率20 480 Hz,采樣時間持續16 s,根據最低轉速500 r/min,軸承轉動一圈,傳感器約采集2 457個數據點,選取樣本長度為2 400作為一個樣本。綜上,隊原始振動信號隨機不重疊可以采集大約7 440個樣本,每一種故障狀態的樣本個數均為744,即每種故障狀態在單一工況下有124個樣本,考慮到算法優化時間成本,只隨機選取3 720個樣本集,其中3 300個樣本作為訓練集,剩余的420個樣本作為測試集。
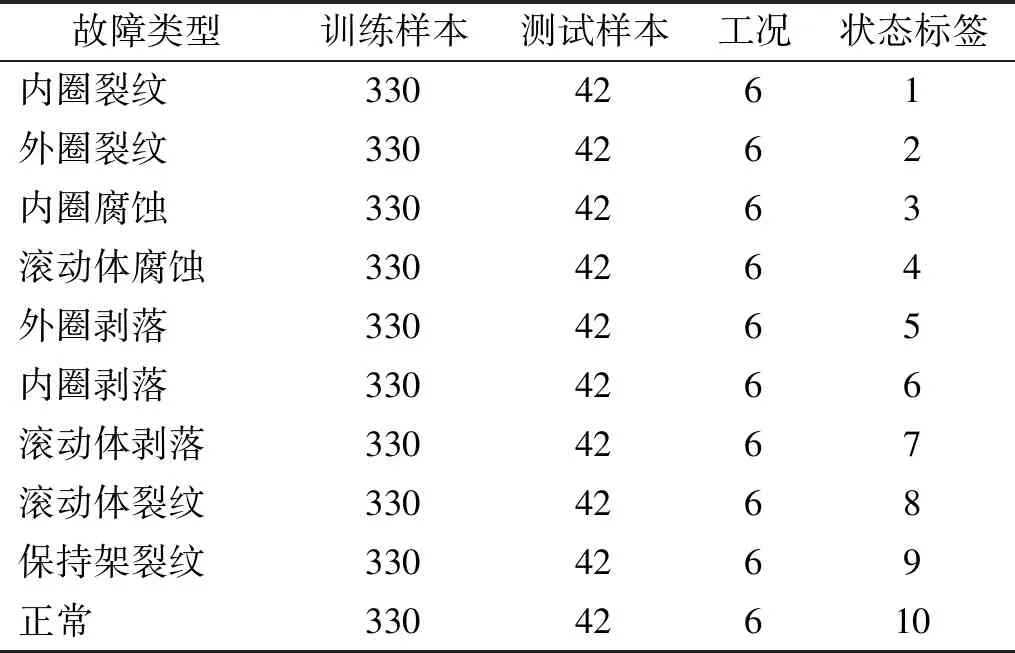
表1 滾動軸承試驗的10種健康狀況Tab.1 10 health conditions of the rolling bearing experiment
將采集到的樣本經過快速傅里葉變換為頻譜序列并歸一化,以1 200維的頻譜序列作為輸入堆疊降噪自編碼網絡。本文中DNN設置為5層,網絡結構為1 200-450-150-50-10,神經元激活函數為sigmoid函數,輸入樣本去噪率為0.5,輸入層神經元個數由樣本長度決定,輸出層由標簽類別決定。預訓練和微調階段,將模型迭代次數設定為50。將經微調后得到的降維數據輸入WOA-SVM中進行分類。其中:采用徑向基核函數和5折交叉驗證,并以交叉驗證意義下支持向量機分類正確率作為適應度函數。WOA算法參數設置和待優化參數范圍如表2所示。
3.3 結果分析
為了驗證深度學習神經網絡能夠自適應提取頻譜中的有效故障特征,試驗中人工提取了14個常用的時域統計特征[19]輸入WOA-SVM,與深度學習神經網絡自適應提取的故障頻譜特征做對比。尋優參數最優值和交叉驗證下平均分類正確率和測試集正確率的結果如表3所示,得到的適應度曲線如圖7、圖8所示。

表2 WOA參數設置和待優化參數范圍Tab.2 WOA parameter setting and range of parameters to be optimized
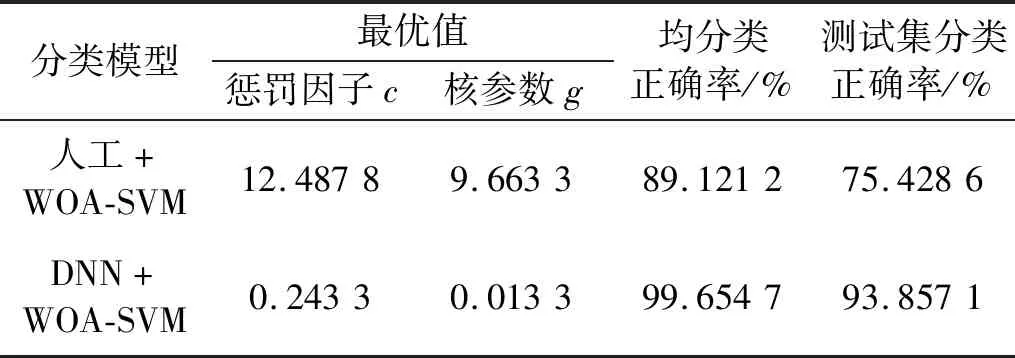
表3 尋優參數最優值及分類正確率Tab.3 The optimal value and classification accuracy of the optimized parameters
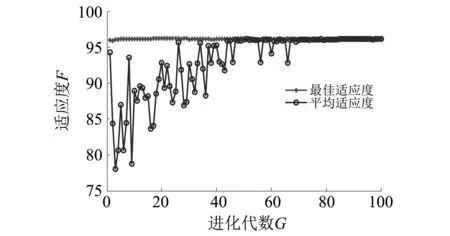
圖7 WOA-SVM對人工提取的時域統計特征分類的適應度曲線Fig.7 Fitness curves of time domain statistical feature classification based on WOA-SVM

圖8 WOA-SVM對深度神經網絡自適應提取頻域特征的分類適應度曲線Fig.8 Fitness curves of the classification of frequency domain feature which is selected by the DNN based on WOA-SVM
由表3可知,深度學習神經網絡自適應提取特征,其測試集在WOA-SVM上分類正確率為93.857 1%。說明深度學習神經網絡能夠有效的提取故障特征。但人工方法提取的頻域狀態特征,其測試集在WOA-SVM上分類正確率只有75.428 6%,分析原因,可能是特征表達性不強,懲罰因子c過大,模型訓練存在過擬合現象,導致測試集上分類正確率有所下降。
將提取特征的表達性對診斷效果的影響進行深入的分析。對樣本進行聚類并投影到貢獻率前三的特征向量三維空間中,可以直觀的了解特征對樣本的表達能力。如圖9、圖10所示。可知人工方法對樣本特征的提取,其中同類樣本能實現一定程度的聚集,但不同故障類型下的樣本重疊部分較多。相比之下深度學習神經網絡自適應提取的故障頻譜特征,能夠明顯地區分不同故障模式下的樣本,分類效果更好。
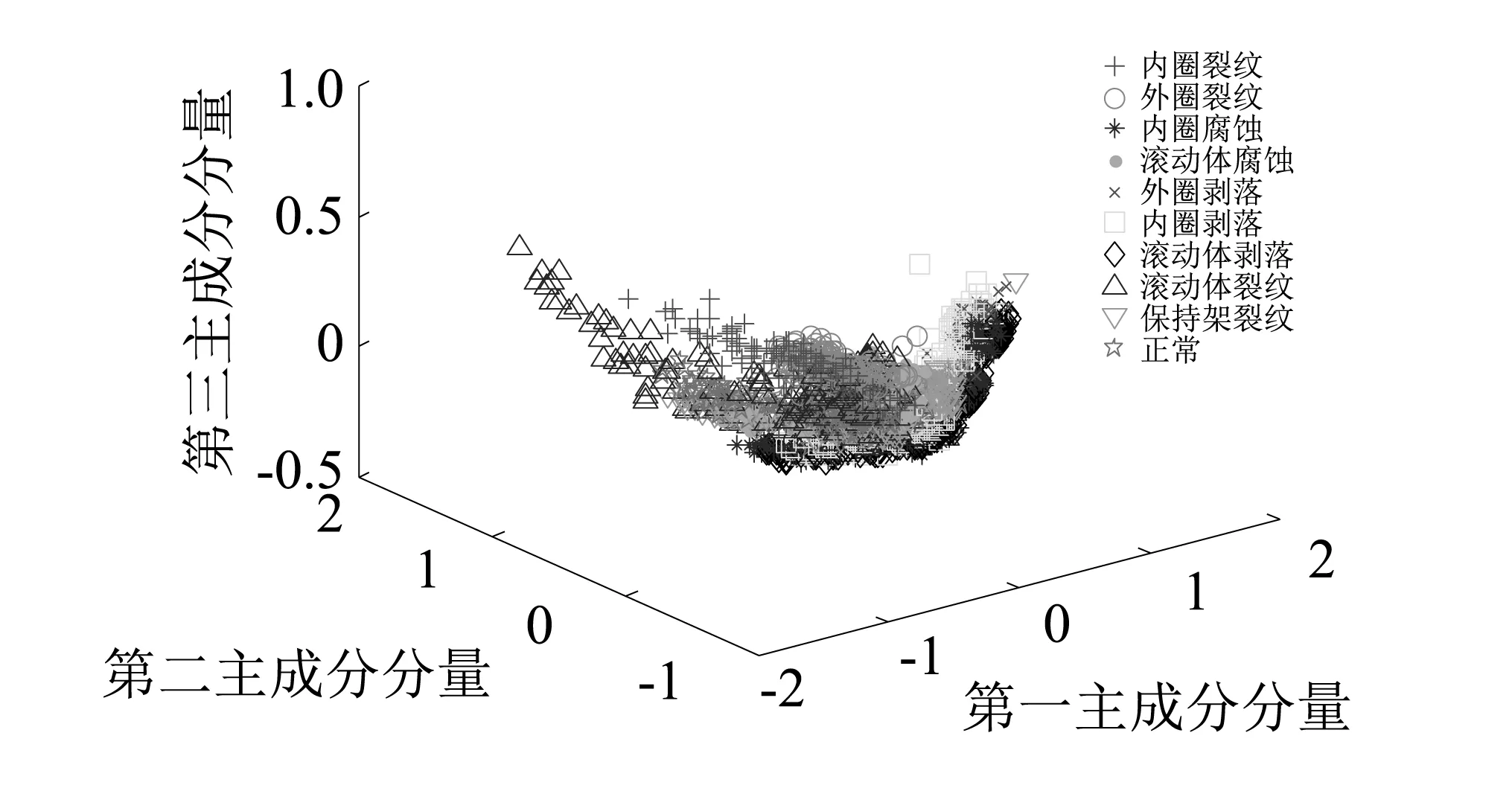
圖9 人工方法提取的時域統計特征的主成分散點圖Fig.9 Main scatter points diagram of the time domain statistical features extracted by the artificial method
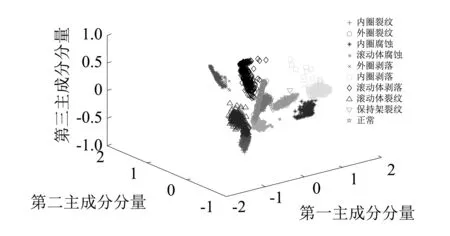
圖10 深度神經網絡自適應提取的頻域特征的主成分散點圖Fig.10 Main scatter points diagram of frequency domain feature extracted by the DNN
以上結果表明,深度學習神經網絡能夠有效提取表達性強的故障特征,擺脫了人工提取頻域特征過程的復雜性,實現了診斷過程的智能化,并一定程度上提高了故障分類的正確率。而人工提取特征從高維特征向低維空間投影的過程中損失了大量有用的特征信息,導致某些相似狀態下可分性差,影響診斷結果。
4 方法對比
為了驗證增加人工提取故障時域特征能夠提高WOA-SVM分類器的診斷正確率的可行性和有效性,將文中人工提取的故障時域特征與深度學習提取故障頻域特征相結合成的聯合特征輸入WOA-SVM分類器中,并與SDAE和深度置信網絡(Deep Belief Network,DBN)診斷能力作比較,試驗重復進行10次以減少隨機擾動,對比結果如圖11所示。可以看出,提出方法的平均診斷準確率為96.64%要高于直接用SDAE診斷的平均診斷準確率90.89%和DBN的平均診斷準確率81.71%,證明增加時域統計特征后,能提高分類器對故障的分類準確率。
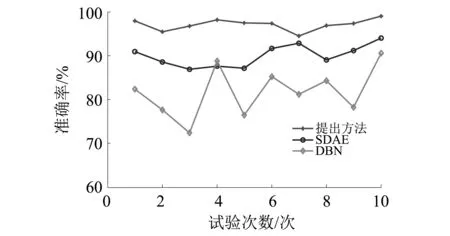
圖11 10次試驗中的診斷準確率Fig.11 Diagnostic accuracy in the 10 tests
為了驗證WOA-SVM具有更快的收斂速度,和更高的準確率,將其與GA-SVM和PSO-SVM作比較,把深度學習神經網絡自適應提取的故障特征分別輸入WOA-SVM,GA-SVM和PSO-SVM中進行故障分類。WOA算法參數設置同表2所示,GA和PSO算法基本參數和待優化參數范圍如表4所示。得到的適應度曲線如圖12、圖13所示。
由表5可知,在交叉驗證下的平均分類正確率3種算法均能達到99.9%以上,而在測試集上WOA-SVM方法分類正確率略高于GA-SVM和PSO-SVM,并且WOA-SVM的尋優時間明顯快于GA-SVM和PSO-SVM。
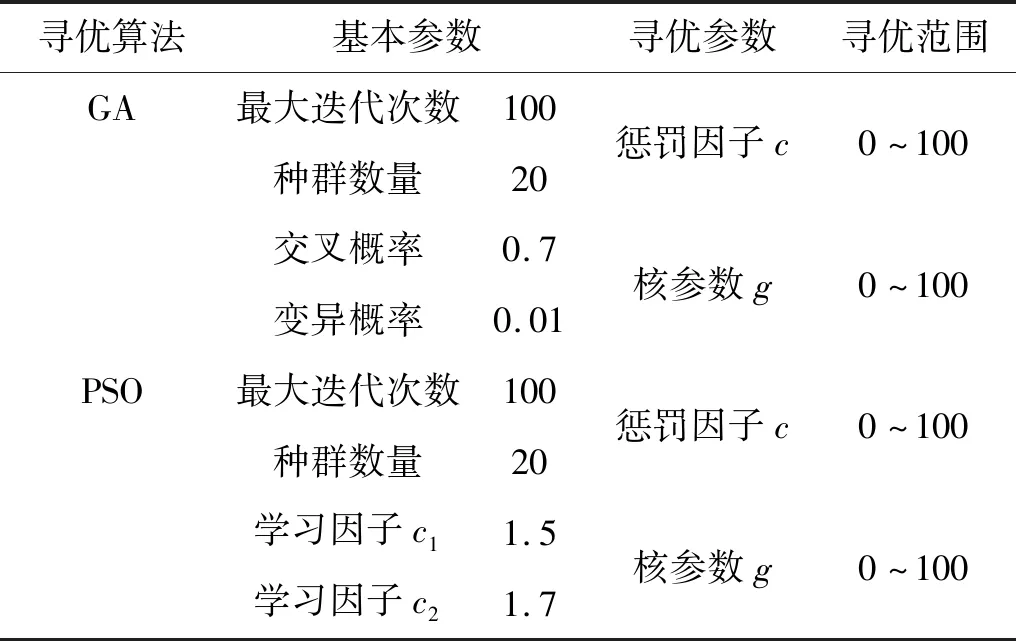
表4 GA和PSO基本參數設置和待優化參數范圍Tab.4 Basic parameter settings of GA and PSO and the range of parameters to be optimized
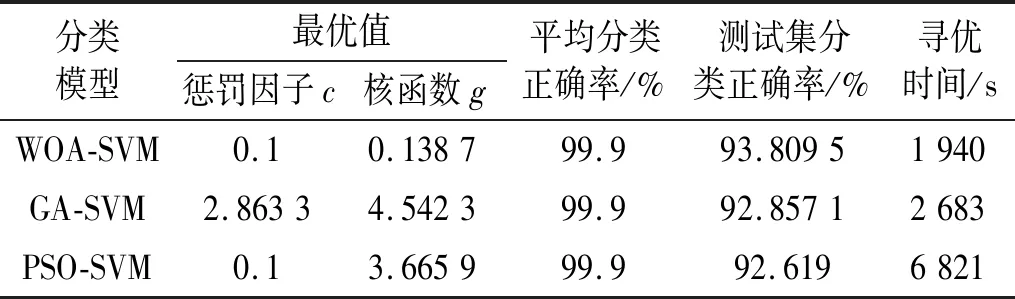
表5 3種優化算法結果對照表Tab.5 Comparison table of results of three optimization algorithms
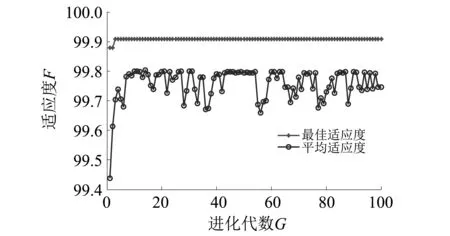
圖12 GA-SVM對深度神經網絡自適應提取頻域特征的分類適應度曲線Fig.12 Fitness curves of the classification of frequency domain feature which is selected by the DNN based on GA-SVM
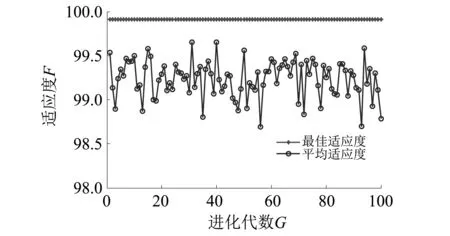
圖13 PSO-SVM對深度神經網絡自適應提取頻域特征的分類適應度曲線Fig.13 Fitness curves of the classification of frequency domain feature which is selected by the DNN based on PSO-SVM
5 結 論
(1)提出了一種基于深度學習特征提取和WOA-SVM狀態識別的故障診斷方法,通過DNN網絡對原始數據進行非線性降維能獲得有效的頻譜特征,擺脫了對大量信號處理知識和診斷工程經驗的依賴。用WOA-SVM做故障分類器取得較高的故障診斷精度。
(2)比較直接通過SDAE與DBN進行故障診斷的方法,提出的方法在滾動軸承故障診斷上取得較高正確率,證明了該方法的有效性。
(3)WOA算法具有調節參數少,收斂速度快,尋優精度高等優點,WOA-SVM較GA-SVM與PSO-SVM節省了大量優化時間,并在一定程度上提高了故障分類正確率。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
