基于改進EEMD算法的橋梁結構響應信號模態分解研究
2019-10-19 03:13:08陳永高鐘振宇
振動與沖擊 2019年10期
陳永高,鐘振宇,2
(1.浙江工業職業技術學院,浙江 紹興 312000;2.浙江大學 建筑工程學院,杭州 310058)
隨著實際橋梁結構的不斷運營,其自身會發生一定的損傷。目前,常在橋梁結構上配置一套健康監測系統[1],通過布置在結構上的傳感器采集其振動響應信號,再通過分析響應信號來掌握結構是否處于正常的運營狀態。但在實際工程中,由于橋梁結構所處的外界環境一般較為復雜,以致健康監測系統會受到各種干擾因素的影響,導致采集的響應信號中含有一定的噪聲[2]。基于此,需對響應信號進行降噪處理,以便最大化地消除噪聲帶來的影響。
就信號的降噪處理算法而言,國內外有很多降噪算法,大體上可將這些降噪算法[3]歸為三類:時域法、頻域法和時頻域法。時域降噪法是指:直接對實測信號進行數學運算,而無需考慮該實測信號是否存在一定的規律性。頻域降噪方法是指:先將實測信號從時域信號轉換到頻域信號,再依據信號與噪聲之間存在的頻譜差異性來去除噪聲,進而保留有用信號頻譜,最后再將該頻譜還原為時域信號。時頻分析方法是指:將實測信號分別展開到時域和頻域兩個空間上,以分析實測信號的時域特征和頻域特征。
本文將首先分析橋梁響應信號的基本特征[4],以選取最佳的降噪算法,其次針對該算法存在的弊端提出解決算法,最后將改進算法運用于信號分解,對比分析所得結果以驗證算法的可行性。
1 信號分解算法的篩選
在對橋梁響應信號進行降噪處理之前需了解其存在的基本特征,以便能選擇最佳的降噪算法。其基本特征包括:①Huang等[5]指出的非線性;②非平穩性[6]—在時域和頻域上均會隨著時間的推移而發生一定的變化,即信號的可預測性較差;③時變性—橋梁結構自身的特性會發生變化;④低頻性—主要是指橋梁結構自身的固有頻率較低,以致其響應信號對應的頻率值也低。
根據橋梁響應信號的基本特征,并結合現有的三大類降噪算法,可知時頻分析方法能夠更加有效地分析橋梁響應信號的時頻特性。目前,時頻分析法中常用的有小波(包)類和經驗模態分解(Empirical Mode Decomposition,EMD),其中小波(包)方法存在小波基和分解尺度的選擇問題,EMD是一種自適應分解方法,但其依然存在端點效應和模態混疊。針對EMD的弊端,Wu等[7]提出了集成經驗模式分解(Ensemble Empirical Mode Decomposition,EEMD)。但隨著該降噪算法的普及,其缺陷也逐漸凸顯,雖然已有不少學者對其進行了改進,但模態混疊現象依然存在,同時有效IMF分量篩選需人為參與。基于此,本文針對這兩方面的問題提出了相應的解決算法,以便能更好地對橋梁響應信號進行降噪處理。
2 模態混疊現象的避免
2.1 模態混疊現象
模態混疊現象是指本征模態函數(Intrinsic Mode Functions,IMF)間存在相近的特征時間尺度;該現象的存在會導致后續的時頻分布混淆[8]。究其主要原因如下:
(1)信號內部含有噪聲,導致極值點的分布發生了變化;
(2)信號內部含有一定的高頻的、間斷性的弱信號;
(3)信號的組成分量比較接近,即組合分量對應的頻率值比較接近。
導致該現象發生的根本原因是模態分解不滿足全局正交性,只有保證信號在模態分解的過程中始終保證所得結果間滿足正交性。鑒于此,可通過引入多元統計學中的“解相關算法”[9],同時為了進一步避免模態混疊現象可引入“譜系聚類”[10]。
2.2 解相關算法
解相關算法的基本原理是通過計算向量x和向量y之間的相關程度Cxy,并通過相關程度的大小來辨識兩向量之間是否滿足正交性。相關程度的計算式為
Cxy=E{(x-ηx)(y-ηy)}=E{xy}-E{x}E{y}
ηx=E{x}
ηy=E{y}
(1)
當Cxy=0時,表明向量x和向量y并不相關,由于不相關和正交具有等價性,所以兩向量x和滿足y正交性。
當Cxy≠0時,表明兩向量不滿足正交性,此時則需要根據Cxy的數值大小來判定是否需要進行“解相關處理”。肖瑛等的研究中指出,當Cxy∈[0.1,1]時則應利用式(2)將相關部分ry(n)從x(n)中剔除,以得到與y(n)不相關的部分。
v(n)=x(n)-ry(n)
(2)
算法流程如下:
步驟1 信號EMD分解
EMD處理待分解信號x(t),僅需分解得到前兩個IMF分量IMFi(i=1,2);
步驟2 求解IMF1分量
求解IMF1和IMF2間的相關程度,計算式如下
(3)
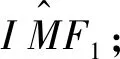
(2)當r12∈[0,0.1]時,表明所得IMF1為所求第一個IMF分量;
步驟3 剩余IMF分量求解
根據步驟2的算法流程依次求得剩余的所有IMF分量。
2.3 譜系聚類算法的運用
為進一步保證所得IMF分量中任意兩個分量間不存在模態混疊現象。鑒于此,可引入“譜系聚類”來解決這一問題,以下將詳細介紹如何在信號分解過程中嵌入該算法。
為了將譜系聚類與EEMD分解算法進行有效結合,應先分析EEMD分解算法的基本流程,流程圖見圖1。根據圖1可知:
(1)IMFj的求解是直接對IMFij(i=1,2,…,n)求平均,雖然解相關處理能夠保證同一列的相鄰兩分量間不存在模態混疊,卻難以保證同一行的N個IMFij(i=1,2,…,N)間不發生混疊現象;
(2)同一列的n-1個IMFij(j=1,2,…,n-1)也可能發生混疊現象。
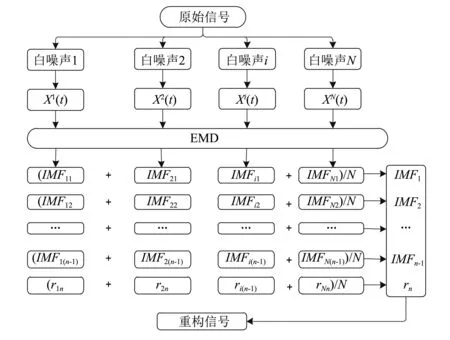
圖1 EEMD流程圖Fig.1 Flow-chart of EEMD
將譜系聚類算法嵌入到分解過程中,思路如下:
(1)為保證圖1中同一列的n-1個IMFij(j=1,2,…,n-1)間不存在混疊現象,可在每次信號EMD分解完之后利用譜系聚類辨識所得IMF分量,當分量間存在混疊現象時,則需要重新計算該組分量,直到所得分量間不存在混疊現象;
(2)在對同一行的N個IMFij(i=1,2,…,N)進行求平均值之前,可通過譜系聚類算法辨識這些IMF分量間是否存在混疊現象。假如當IMFn1和IMFn2發生混疊時,需重新對信號添加N次白噪聲進行模態分解。
以下將詳細介紹譜系聚類算法的具體實現步驟:
步驟1 求解分量間的歐式距離
鑒于“歐式距離”能夠描述二維和三維空間中點點之間的實際距離,所以本文采用譜系聚類中的歐式距離定義向量xi和向量xj之間的距離d(xi,xj),該距離滿足如下條件:
(1)d(xi,xj)≥0,且d(xi,xj)=0?xi=xj
(2)d(xi,xj)=d(xj,xi)
(3)d(xi,xj)≤d(xi,xk)+d(xk,xj)
(4)
基于上述原理,可利用式(5)計算IMFi和IMFj之間的歐式距離dij
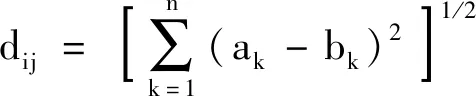
(5)
步驟2 模態混疊現象的辨識
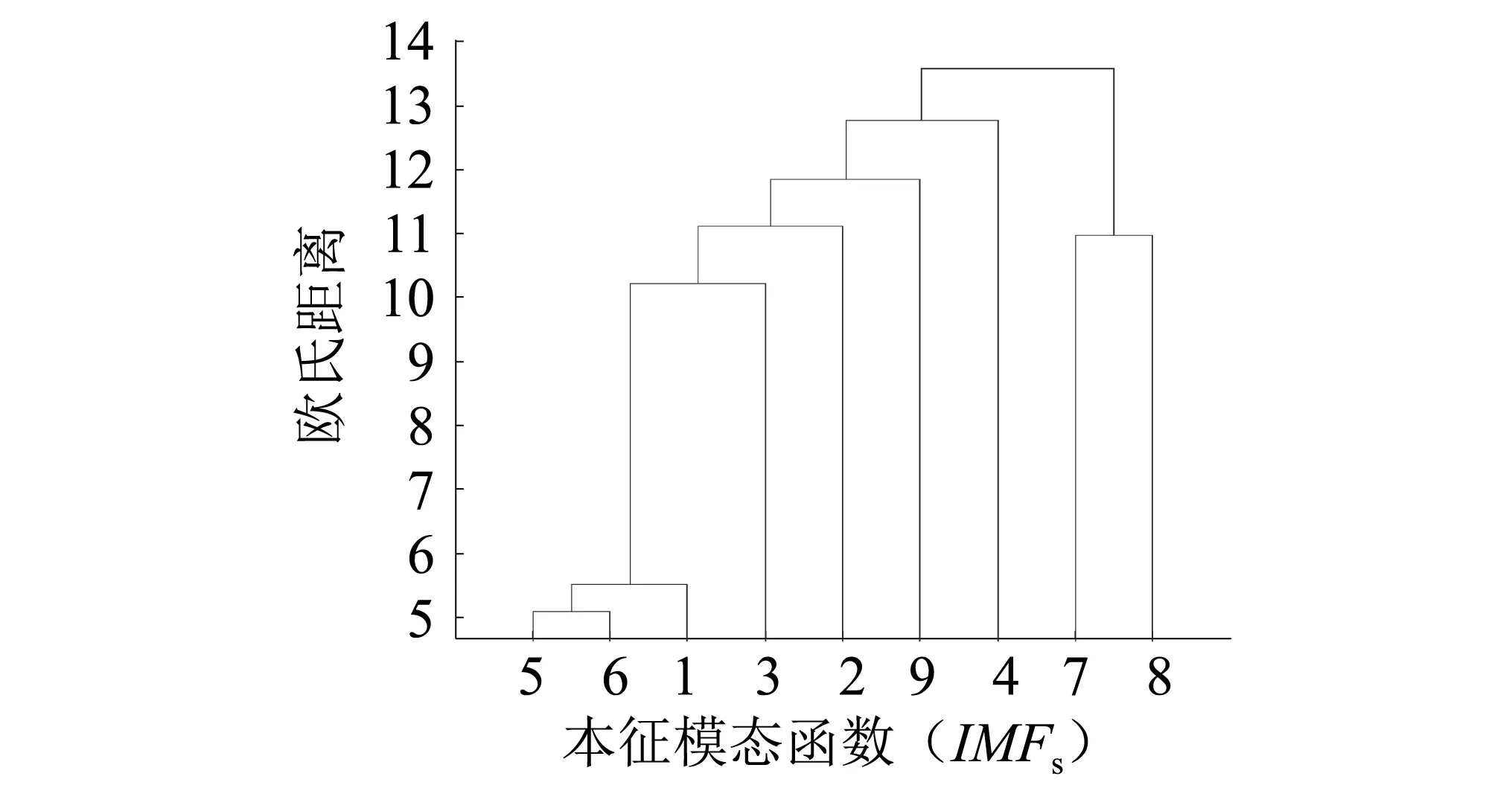
基于步驟1可計算出任意兩IMF分量間的歐式距離,并繪制歐式距離圖,見圖2。辨識兩分量間是否存在模態混疊需確定聚類的閥值Nn。通過多次試驗,提出可利用式(6)計算該閥值。
Nn=(dmax-dmin)×0.6
dmax=max(dij)
dmin=min(dij)
(6)

圖2 歐式距離圖Fig.2 Euclidean distance chart
步驟3 譜系聚類算法的嵌入
分解過程中引入“解相關算法”和“譜系聚類算法”,流程圖如圖3所示。
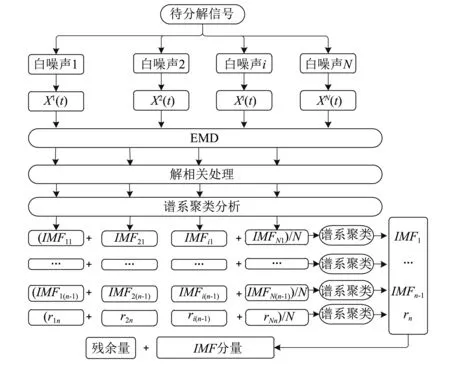
圖3 改進EEMD流程圖Fig.3 Flow-chart of improved EEMD
3 智能化篩選有效IMF分量
針對如何篩選有效IMF分量,已有不少學者對其進行了深入的研究。
(1)林麗等[11]通過計算各IMF分量與原始信號之間的相關系數來選取有效分量,該算法的缺點在于,由于原始信號內部一般含有噪聲,導致求解出的相關系數不具代表性;
(2)張雪等[12]通過計算各IMF分量含有的信息熵來對IMF分量進行區分,該方法的缺陷在于難以定義高頻成分與低頻成分的分界點;
(3)陳仁祥等[13]通過計算各IMF分量自身的能量密度和平均周期來篩選有效分量;該方法的缺陷在于,信號內部噪聲的大小會在一定程度上影響能量密度的計算,以致最終篩選的有效IMF分量并不可信。
上述作者在篩選有效IMF分量時僅利用了一種算法,以致篩選的結果可能會存在偏差。鑒于此,可采用數學建模中的“線性加權算法”以相關程度、信息熵、能量密度以及平均周期為因子構建新的篩選指標。
3.1 相關程度的計算
考慮到原始信號x(t)和IMFi(i=1,2,…,n)均為矢量,所以采用夾角余弦來定義彼此之間的相似性度量Ri,計算式為
(7)
式中:m為單個矢量的序列長度值。
3.2 信息熵的計算
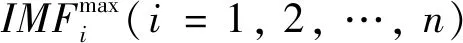
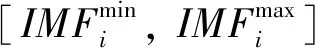
(3)確定原始信號的總采樣點數N以及IMFi(t)落在第i個區間的個數為mi,計算IMFi(t)落在第i個區間的概率P=mi/N,再利用式(8)求解IMFi(i=1,2,…,n)對應的信息熵XSi。
(8)
3.3 能量密度和平均周期的計算
(1)定義IMFi對應的能量密度為Ei,平均周期為Ti,兩者的乘積為ETi,計算式為
(9)
式中:l為原始信號總測點數;Fi為IMFi對應的振幅值;Ji為IMFi對應的極值點個數。
(2)計算能量系數Xi
(10)
①Xi越大,則該IMFi為高頻成分的幾率越大,反之亦然;
②當Xi>2Xi-1時,即IMFi能量系數相比IMFi-1成倍的增加,此時便認定IMFk(k=1,2,…,i-1)為高頻分量。
3.4 線性加權算法的運用
為了實現有效IMF分量的智能化篩選,引入了數學建模中的“線性加權算法”,該算法并不是第一次被運用到橋梁結構相關計算中。周勇軍等[14]用來計算沖擊系數;趙紹東[15]用來進行橋梁評估。本文將利用其篩選有效IMF分量,步驟如下:
步驟1 為了避免因量綱的不同帶來的影響,在對IMFi對應的Ri,XSi以及Xi進行線性加權之前,對XSi和Xi分別進行歸一化處理
(11)
步驟2 鑒于三項指標具有相同的重要性,將各項指標對應的權重值均取為1/3,利用式(12)構建新指標-有效系數YXi
(12)
YXi的取值大小問題,尚未有學者對其進行研究。僅有少量學者對類似系數進行定義。林旭澤等[16]選取0.9為有效分量的閥值;陳仁祥等[17]認為相關系數大于0.7時即可。綜合上述分析,本文將有效系數的閥值取為0.8。最后對所有的有效IMF分量進行重組得到重構信號x′(t)。
4 有效IMF分量的驗證
就所得有效IMF分量是否具有可靠性,還需進一步的驗證。現階段,常用的驗證指標包括信噪比(Signal to Noise Ratio,SNR),用于表示信號與噪聲能量大小的關系;標準誤差(Standard Error,SE),用于表示重構信號與原始信號在數據方面的差異性,該值越小代表重構信號的去噪效果越好;相關系數(Correlation Coefficient,R ),一般用于描述重構信號與原始信號在形狀方面的差異性。各指標的計算公式為
(13)
5 仿真信號試驗驗證
仿真信號采用正弦信號、余弦信號以及噪聲組成。其中正弦信號對應的頻率為1 Hz和5 Hz;余弦信號的頻率為2 Hz;噪聲對應的均值為0,方差為1,且含噪水平約為15%。模擬信號的時間曲線方程為
x(t)=8sin(10πt+2π/3)+5cos(4πt+π/3)+
1.5sin(2πt)+15rand
信號持續時間為10 s,采樣頻率為100 Hz,即采樣點數為1 000。疊加信號及各信號對應的時程曲線見圖4。

圖4 信號時程曲線圖Fig.4 Time-step curves of signal
5.1 模態混疊處理效果
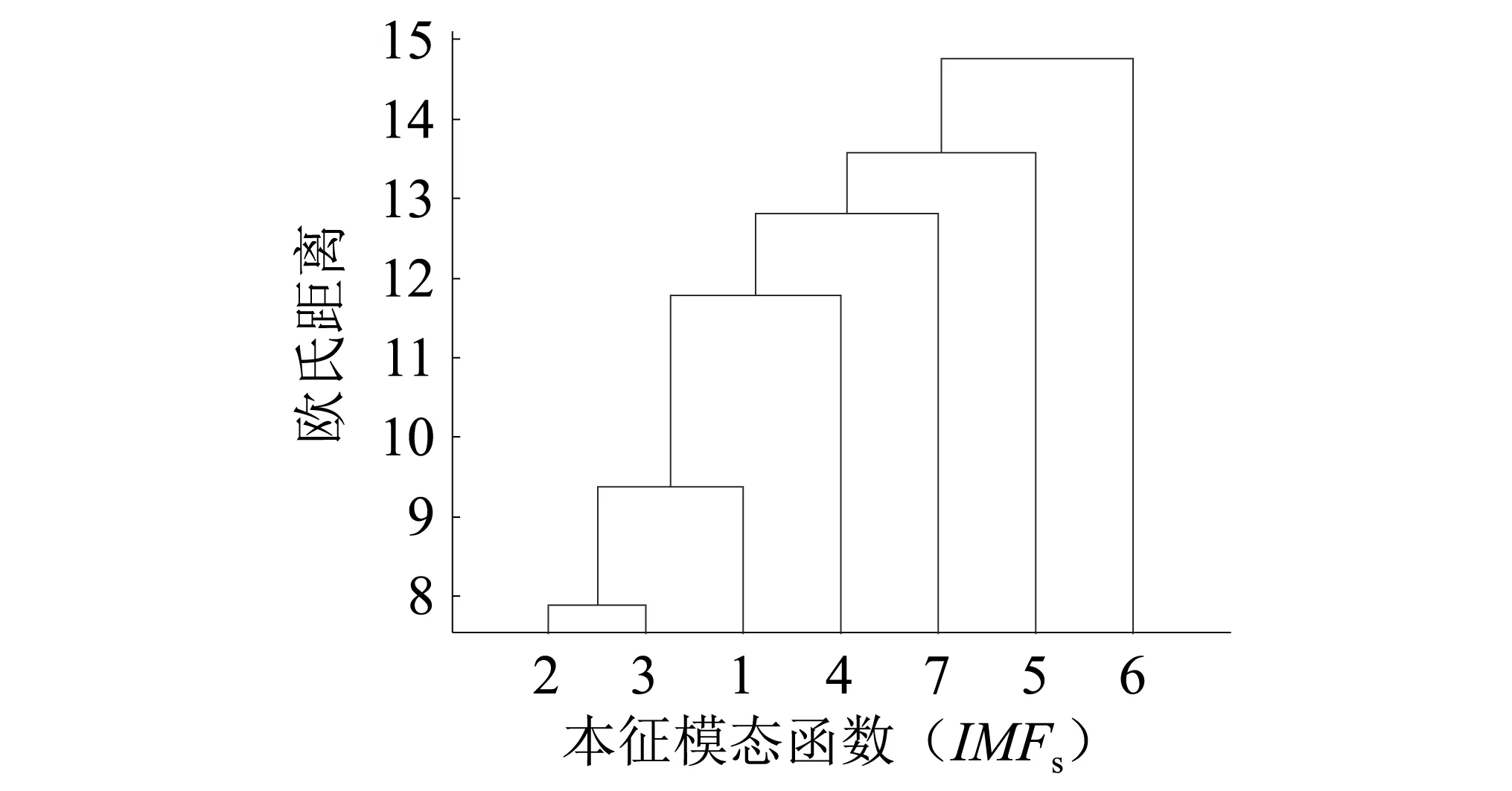
分別運用改進EEMD算法與EEMD算法對仿真信號進行模態分解,圖5是為各IMF分量時程圖;圖6為歐式距離圖。對比分析圖6可得如下結論:
(1)根據式(6)求EEMD和改進EEMD對應的聚類閥值分別為5.4和4.5;
(2)EEMD分解結果中IMF5和IMF6間發生了混疊現象,即兩分量間含有一定的相似信息;改進EEMD分解結果中,各IMF分量均獨立,無模態混疊現象發生。

圖5 模態分解結果Fig.5 Modal decomposition results
(a)歐式距離圖(EEMD)
(b)歐式距離圖(改進EEMD)
圖6 歐式距離圖
Fig.6 Euclidean distance chart
5.2 相關程度的計算
為驗證所提算法分解得到的IMF分量與原始信號中的疊加信號更為接近,求得兩分解算法所得各分量與仿真信號中各疊加信號間的相關系數,結果見表1和表2。可得結論:
(1)僅根據相關系數選擇有效分量,則EEMD僅能篩選出IMF2,該分量僅能反映疊加信號中的5 Hz;
(2)改進EEMD分解結果中僅IMF3為有效IMF分量,該分量僅能代表疊加信號中的5 Hz信號。
可見僅利用相關系數進行有效IMF分量的篩選,則可能會遺漏部分有效IMF分量。

表1 相關系數表(EEMD)Tab.1 Table of the correlation coefficient(EEMD)
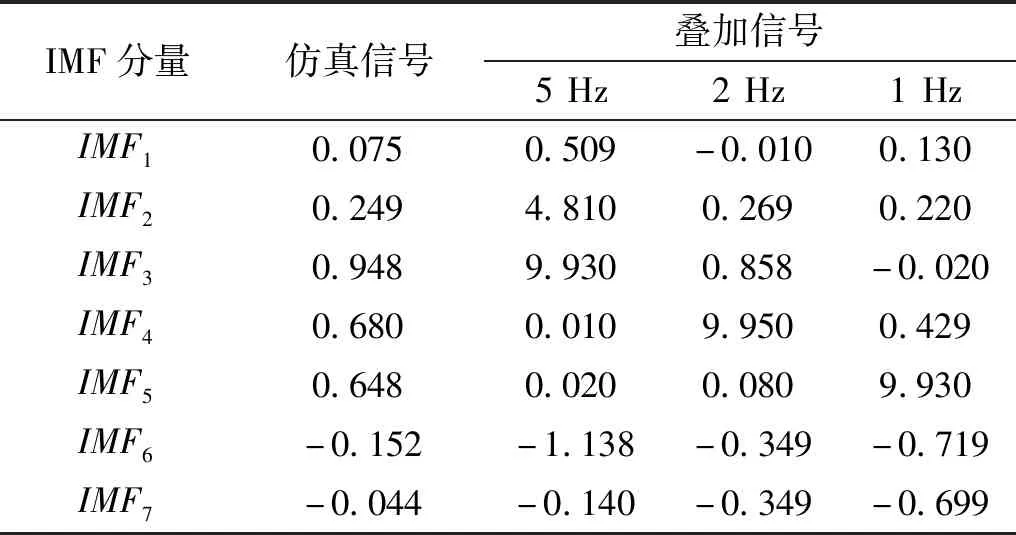
表2 相關系數表(改進EEMD)Tab.2 Table of the correlation coefficient (improved EEMD)
5.3 有效IMF分量的智能化辨識
求解出兩種分解算法所得IMF分量對應的相關系數、信息熵以及能量系數,并基于3.4節所提算法計算用于篩選有效IMF分量的有效系數,結果見表3和表4。分析表中數據可知:
(1)EEMD分解結果中的有效IMF分量分別是IMF2,IMF4和IMF5;
(2)改進EEMD分解結果中的有效IMF分量分別是IMF3,IMF4和IMF5;
(3)本文算法能有效避免人為參與有效IMF分量的篩選,且結果具有可靠性。
利用式(13)分別計算兩種分解算法所得重構信號對應的信噪比、相關系數以及均方誤差,結果見表5。

表3 有效系數(改進EEMD)Tab.3 Effective coefficient (improved EEMD)

表4 有效系數(EEMD)Tab.4 Effective coefficient (EEMD)
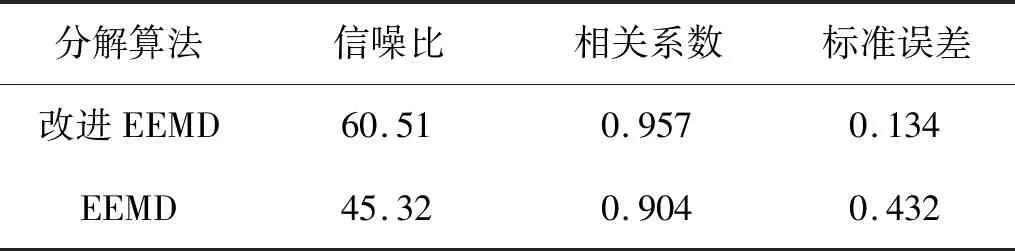
表5 去噪效果評價指標Tab.5 Evaluation of noise removal results
根據表5可知,本文算法得到的重構信號,其內部的有效信號所占比重更大;與原始信號更接近。
6 斜拉橋響應信號驗證
為驗證所提算法能運用于實際橋梁結構信號,以下將分別利用兩種分解算法對環境激勵下的橋梁結構響應信號進行模態分解,并對比分析所得結果。該橋梁為雙塔索面斜拉橋,跨徑布置為(2×100+300+1 088+300+2×100)m,主梁上共布置14個豎向加速度傳感器,見圖7所示。采樣頻率為20 Hz,圖8是1號傳感器于白天12點左右采集的加速度響應信號對應的時程圖,采樣點數為4 000,即采樣時間為200 s。

圖7 加速度傳感器布置圖Fig.7 Acceleration sensor arrangement
圖8 加速度響應信號時程圖Fig.8 Time-distance chart of acceleration response signal
以前1 000個測點對應的響應信號為研究對象,分別運用所提算法和EEMD對其進行模態分解,結果見圖9。圖10為兩分解結果各IMF分量對應的歐式距離圖,根據圖10可知,EEMD分解所得IMF分量間有模態混疊現象,其中IMF1與IMF2間發生了混疊現象,同時IMF4與IMF5間也發生了混疊現象。
對兩種分解算法所得IMF分量進行有效IMF分量的智能化篩選,并重構信號,圖11為兩重構信號對應的Hilbert-Huang譜圖。圖中瞬時頻率顏色的深淺與該頻率成分能量大小相關,能量越大顏色越深。根據該圖可知,相比EEMD所得結果,本文算法得到的有效IMF分量對應各階頻率的能量更高,即本文算法能更好地保留原始信號中的有效成分。

圖9 模態分解結果Fig.9 Modal decomposition results
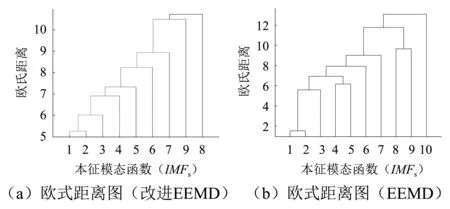
圖10 歐式距離圖Fig.10 Euclidean distance chart
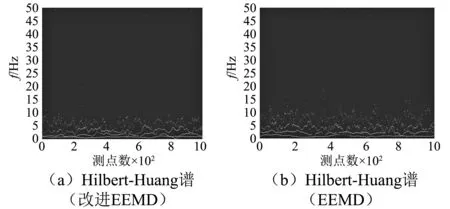
圖11 Hilbert-Huang譜Fig.11 Hilbert-Huang spectrum
7 結 論
針對EEMD算法存在的弊端,本文提出了相應的改進算法,并將所提算法運用于仿真信號和實測橋梁振動信號,結果表明:
(1)為避免模態混疊現象的產生,可在信號分解過程中引入“解相關處理”和“譜系聚類”來有效地保證所得IMF分量間滿足全局正交性。
(2)為實現有效IMF分量的篩選,可以利用能量密度、平均周期、相關程度以及信息熵為因子,并結合多元統計學中的“線性加權算法”來構建新的篩選指標,結果表明所提篩選算法具有可靠性。
(3)本文算法不僅能運用于仿真信號,還能運用于實際橋梁響應信號中,且分解效果較現有EEMD算法而言更好。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
湖南教育·A版(2019年4期)2019-05-10 03:31:44
小學生學習指導(低年級)(2019年4期)2019-04-22 03:28:24
電子制作(2018年11期)2018-08-04 03:25:42
山東工業技術(2016年15期)2016-12-01 05:31:04
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
