卷積神經網絡在復雜核素識別中的應用*
2019-09-26 03:06:06胡浩行張江梅王坤朋馮興華
傳感器與微系統 2019年10期
胡浩行, 張江梅,2, 王坤朋, 馮興華
(1.西南科技大學 信息工程學院,四川 綿陽 621010;2.西南科技大學 核廢物與環境安全國防重點學科實驗室,四川 綿陽 621010)
0 引 言
基于伽馬能譜分析的核素識別方法已經在科學研究、環境監測、公共安全等諸多領域得到廣泛的應用[1]。目前核素識別方法主要分為基于全能峰的分析方法[2]以及基于統計學理論的全譜分析方法[3]。前者全能峰位置、面積及半高寬等信息對能譜進行特征提取,繼而在標準核素庫中依次檢索每個峰所匹配的所有可能核素從而確定核素種類;后者利用測量譜的每道數據結合特定核素庫完成解譜工作[3]。目前這兩類方法應用比較多,主要有基于人工神經網絡[4]、貝葉斯理論[5],但研究人員難以準確區分重疊峰及消除“假峰”的影響、特征選取依賴經驗知識,人工特征工程具有很大的盲目性和不確定性[3~5]。與依靠先驗知識、人工構造特征并提取的傳統模式分類方法不同,深度學習卷積神經網絡(convolution neural network,CNN)[6]能夠自適應地、隱式提取針對原始數據深層次的特征描述,其獨有的局部感受野和權值共享機制能夠大大降低模型結構的復雜,提取方式更加靈活,無需人工干涉[7]。
鑒于以上分析,提出一種基于CNN的核素識別方法。和傳統核素識別方法進行對比識別實驗,驗證所提方法的可行性和有效性。
1 CNN模型描述
CNN在多層卷積神經網絡中,卷積層和下采樣層交替組合成網絡的隱藏層。卷積層作為特征提取層,通過卷積運算對原始信號進行特征增強,在提取特征的同時由于卷積層的構造原理降低了噪聲。卷積過程[8]可以表示為
(1)
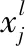
下采樣層[6]利用局部相關性的原理對上層輸出進行子抽樣操作,在減少數據維度的同時保留有用信息,并采用池化技術來保證特征的有效性[6]
(2)
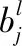
樣本圖像經過多層卷積和下采樣交替操作后得到數據特征,將這些特征通過全連接層作為分類器的輸入進行分類識別。整個網絡的參數使用誤差反向傳播(back propagation,BP)算法[9]通過最小化分類誤差來優化,前向傳播訓練網絡,反向傳播修改網絡權值等參數。圖1所示為參數優化示意。
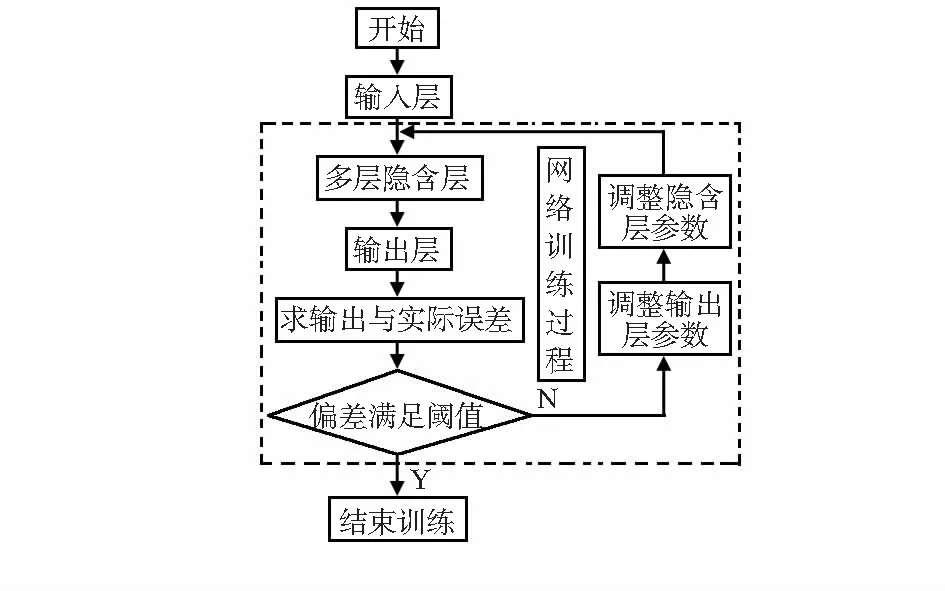
圖1 參數優化示意
2 基于CNN的核素識別算法
2.1 核素識別流程
基于CNN的核素識別方法步驟如下:1)對核素能譜數據進行預處理,將一維能譜信號轉換為二維能譜矩陣,并劃分訓練集和測試集;2)設計核素識別卷積神經網絡模型,使用訓練集對網絡進行訓練;3)使用測試集在訓練好的核素識別分類系統上進行分類測試,得出識別結果。
2.2 核素數據預處理
針對傳統方法探索核素信號峰的特征信息未能涉及到整體能譜的空間信息,以及卷積神經網絡輸入數據格式的需要,本文使用了一種數據轉換方式[3],即將一維能譜信號轉換為二維能譜矩陣,轉換方法如圖2所示。圖2介紹了核素數據轉換的具體實現過程,提供了探索核素信號二維空間特征的新途徑,無需任何預先設定的參數,可以極大地降低專家經驗的影響。
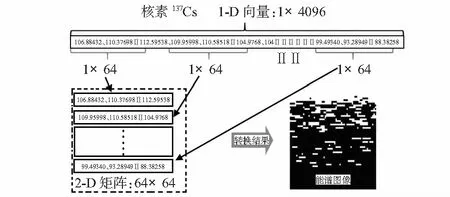
圖2 轉換方法
結合伽馬能譜的特點,將其變換為2維能譜灰度圖像。在所使用的核素數據中,一維能譜信號是長度為4 096的向量,則轉換圖像的大小設置為64×64。圖3給出了部分核素的信號轉換結果,可看出不同核素圖像具有明顯的差異。
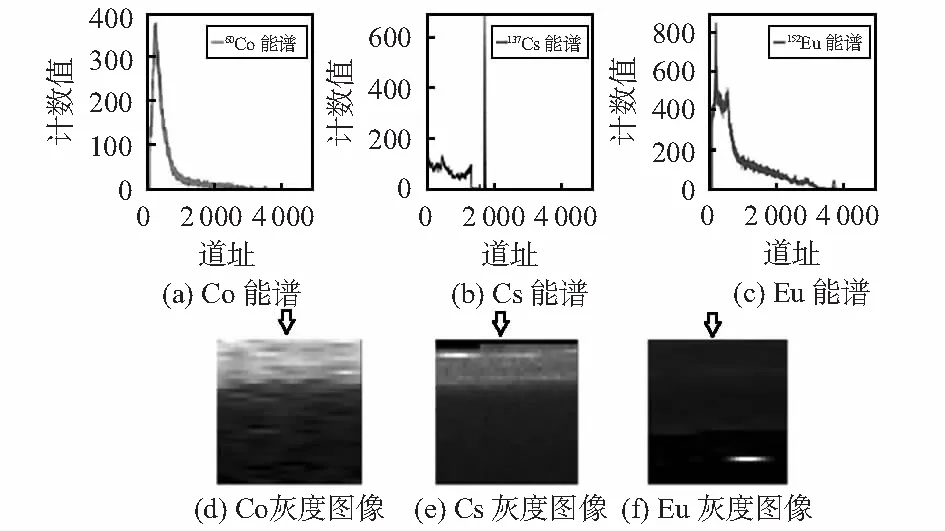
圖3 部分核素轉換結果
2.3 核素識別CNN框架搭建
傳統方法對一維能譜信號進行特征提取,主要是特征峰的提取。而該方法在核素數據預處理和LeNet—5[7]經典網絡的基礎之上,利用CNN核素識別模型對能譜圖像直接進行特征提取和分類識別。如圖4所示為基于卷積神經網絡的核素識別總體架構。
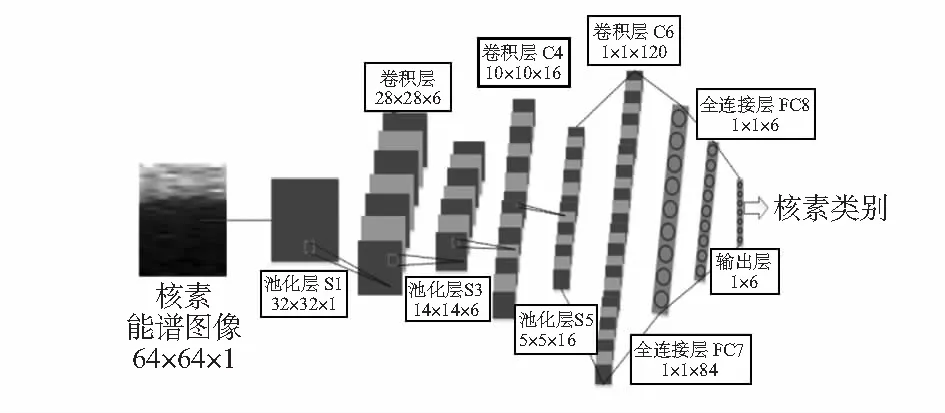
圖4 核素識別CNN結構
如圖4所示,核素識別CNN模型的輸入大小為64×64的灰度圖,構建了3個池化層和3個卷積層、2個全連接層以及最后的1個Softmax層。各層的具體參數如表1所示。
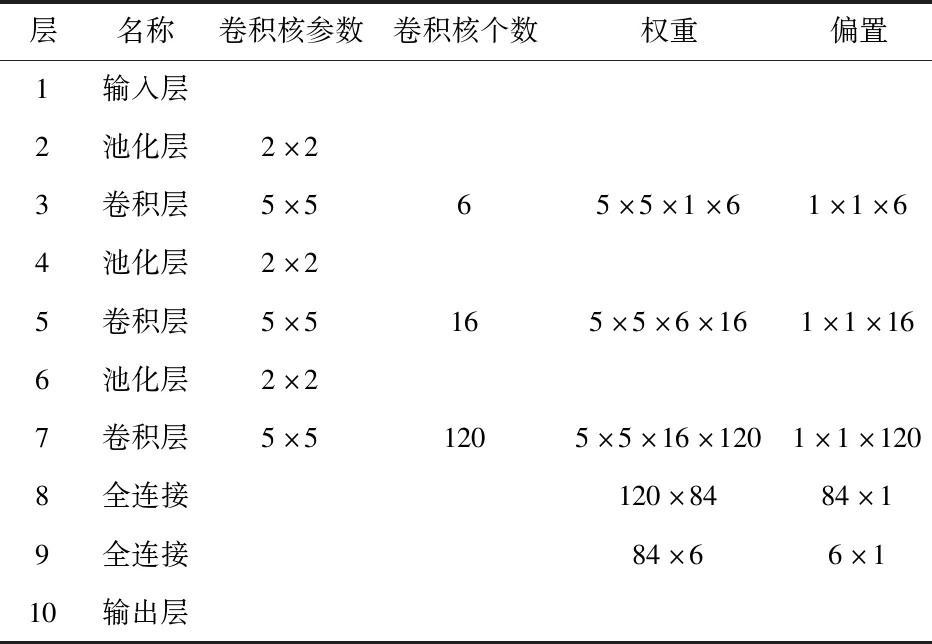
表1 模型各層參數
CNN的時間復雜度,即模型的運算次數,決定了模型的訓練和預測時間。卷積網絡層時間復雜度[10]一般形式為
(3)
式中n為網絡輸入n×n的矩陣邊長,l為當前卷積層的序號,d為卷積網絡所具有的層數,kl為第層的濾波器的個數,kl-1也被稱為第l層的輸入通道的數量,m為每個卷積核輸出特征圖的邊長,s為每個卷積核的邊長。CNN整體的時間復雜度是所有卷積層的時間復雜度累加。由此得出,所提出的核素識別卷積神經網絡模型的時間復雜度為O(n2)。
3 結果與分析
進行了無噪聲情況下和含噪聲情況下仿真數據實驗。使用由歐洲粒子物理研究所(CERN)針對高能物理實驗開發的Geant 4蒙特卡羅模擬軟件包,按照核素產生各種γ射線的能量分支比生成了137Cs,60Co,152Eu三種放射源以及部分混合放射源樣本數據共6類,分別為152Eu,137Cs,60Co,60Co+137Cs,60Co +152Eu,137Cs+152Eu。
3.1 無噪聲仿真數據實驗
實驗過程中對各類放射源數據設置相同大小的格式,模擬無噪聲環境,仿真大量如表2所示的實驗核素數據并劃分訓練集和測試集。使用所提方法對數據進行預處理和核素識別,并與典型的核素能譜對稱零面積[2]尋峰方法γz和基于奇異值分解(SVD+SVM)[3]方法進行比較。實驗結果如下表2所示。
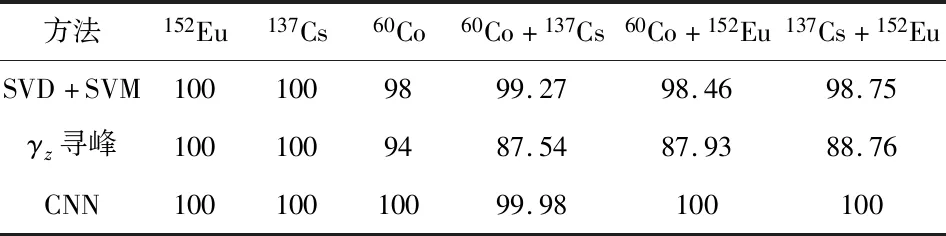
表2 無噪聲情況核素識別結果準確率 %
表2結果表明基于CNN的識別方法具有良好的識別性能,能夠同時識別出多種單一及混合核素;當識別模型被訓練完成之后,測試時只需將待測樣本輸入到模型當中即能得出判定結果,相比較傳統方法仍需對待測樣本進行手工提取特征、分類器識別的過程,其識別速率遠遠高于傳統尋峰方法和基于奇異值分解識別方法。
3.2 含噪仿真數據實驗
在標準核素數據中模擬添加了不同程度的高斯白噪聲,得到與無噪聲環境下同等量級的核素樣本數據集,并使用三種方法測試不同噪聲情況影響下生成的能譜數據,得到如圖5所示的三種方法識別率對比圖。
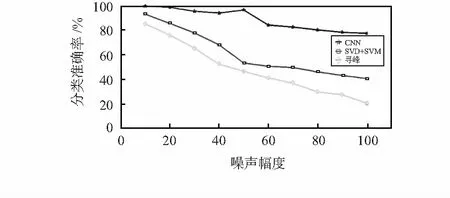
圖5 不同噪聲情況下三種方法的準確度
從圖5中可以看出,隨著數據所含噪聲幅度的增大,三種方法識別率均出現了一定程度的下降,前兩種方法準確率在噪聲幅度10~50期間呈現大幅度的下降,而基于CNN的識別方法準確率雖有下降,但趨勢不大,依舊能夠在90 %上下波動;隨著噪聲幅度的不斷增加,三者之間的差異更加明顯,前兩種方法分類準確率已經降到20 %左右,而CNN方法卻能穩定在80 %附近,結果表明,所提方法在多核素識別的同時和前兩種方法相比具有更強的適應性和抗干擾性。
4 結 論
通過不同噪聲環境下仿真數據實驗,和傳統核素識別方法相比,可以發現該方法避免了手工提取特征、構建并訓練分類器的過程,能夠同時快速識別出多種單一及混合核素,具有較高的識別率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
