混合改進的花朵授粉算法*
2019-09-26 03:06:00陶志勇崔新新
傳感器與微系統 2019年10期
陶志勇, 崔新新
(遼寧工程技術大學 電子與信息工程學院,遼寧 葫蘆島 125100)
0 引 言
花朵授粉優化算法[1](flower pollination algorithm,FPA)是由Yang X S等人在2012年提出的一種模擬自然界中花粉授粉過程的群優化算法,由于該算法不需要知道待優化函數的具體形式、易實現、參數少、易調節等特點,引起了很多學者的研究興趣,并廣泛應用于自然科學研究領域。然而該算法和粒子群算法[2]、蟻群算法[3]、遺傳算法[4]等類似,都存在早熟收斂,容易陷入局部最優,收斂精度低,迭代次數多等問題。文獻[5]提出一種基于引力搜索機制的花朵授粉算法,采用花朵個體間的萬有引力和算法本身的萊維飛行共同實現個體位置的更新,使花朵受萊維飛行和萬有引力的雙重影響;文獻[6]通過定義種群多樣性及差異性指標,定性分析了花朵授粉算法在多模函數優化中的尋優缺點,利用Nelder-Mead單純形搜索技術對花朵局部授粉進行重構,提出一種新的花朵授粉尋優架構;Wang R等人[7]提出了一種逐維度計算的FPA算法,通過逐維度更新算子,保留各算子各維度的最優信息;王玉鑫等人[8]將差分進化和變異策略與花朵授粉算法結合,提高種群多樣性,從而提高算法的尋優能力。肖輝輝等人[9]將模擬退火算法與花朵授粉算法相結合,提高了算法的全局尋優和跳出局部最優的能力。
以上文獻在一定程度上提高了FPA算法的尋優能力,但大多是通過與其他智能算法進行混合的方式以提升FPA算法的性能[10~13],但這樣增加了算法的復雜性,破壞了FPA算法簡單易實現的特點。
本文在不增加算法復雜度的前提下,針對FPA算法速度和精度不足的問題,將均勻初始化、正態分布縮放因子、擾動進化和邊界變異引入花朵授粉算法中,提出利用共軛梯度法改進的花朵授粉算法,并通過7種標準測試函數仿真實驗測試HFPA算法的性能 。
1 花朵授粉算法
花朵授粉算法是一種模擬自然界開花植物授粉過程的群智能優化算法。自然界的授粉過程非常復雜,很難通過算法完全真實地模擬花粉授粉的各個細節,且實用價值不高。為了使該算法更為高效,FPA對花朵授粉過程進行簡化。在FPA中,假設每朵花為優化問題的一個解,并且每朵花都是通過轉換概率p進行異花授粉操作,或以概率 1-p進行自花授粉操作繁衍后代。異花授粉通過一些昆蟲或鳥類進行,此類授粉的范圍較大,在優化理論中可以視為全局搜索;自花授粉主要是在自然作用下兩朵花之間進行小范圍授粉,此類授粉的范圍較小,在優化理論中可以視為局部搜索。
2 混合改進的花朵授粉算法
2.1 均勻種群初始化
為了使初始種群相對均勻的分布在搜索空間中,同時保持種群的多樣性,采用隨機均勻種群初始化,如式(1)所示
Xi=bL+(i-1)(bU-bL)/n+rand(1,d)
(1)
式中Xi為種群的第i個個體,bL為優化問題的下界,bU為優化問題的上界,n為種群規模,rand(1,d)為d維的隨機數。
2.2 正態分布縮放因子
原始FPA算法采用Levy飛行進行全局搜索,Levy飛行屬于隨機游走的一種,其特征是小步長的移動很多,但有小概率進行較大步長的移動。理論上Levy飛行能夠幫助算法脫離局部最優,但由于轉換概率p的限制,花朵授粉算法進行的全局搜索較少,這就大概率導致Levy飛行是以較小步長進行局部運動,反而使算法不易脫離局部最優。
本文算法采用式(2)進行全局搜索
(2)
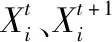
2.3 變異策略
花朵授粉算法的局部搜索策略為
(3)
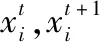
在差分進化算法中,常用的變異策略有兩種:
DE/rand/1:
(4)
DE/best/1:
(5)
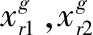
Zheng W等人[14]對差分進化算法進行研究后,提出了一種新的變異策略
(6)
式(6)中,以全局最優解作為基向量,算子本身參與變異,能夠更好地平衡變異的隨機性和方向性,既能加快收斂速度,又能減慢算法陷入局部最優的速度。
僅采用單一的差分進化仍有可能導致算法陷入局部最優。為了增強算法跳出局部最優的能力,HFPA算法在使用新的變異策略的基礎上,算子有較小概率發生變異,使算法跳出局部最優
(7)
最終的局部尋優表達式為
ifrand>pl
else
(8)
2.4 邊界變異
在原FPA算法中,對越界算子的處理是將越界的維度的值改為所超越的邊界
(9)
為了解決粒子群算法易在邊界上陷入局部最優的缺陷,引入了邊界變異思想,使得種群多樣性得到提升,從而提高了算法的搜索能力。
本文將邊界變異思想引入到花朵授粉算法中,對算法中的越界個體依照式(10)進行邊界變異:
(10)
式中xi(t,r)為第t次迭代中,第i個算子的第r維。越界個體變異后,可以使個體不在聚集在邊界處,提高算法的全局搜索能力。
2.5 算法流程
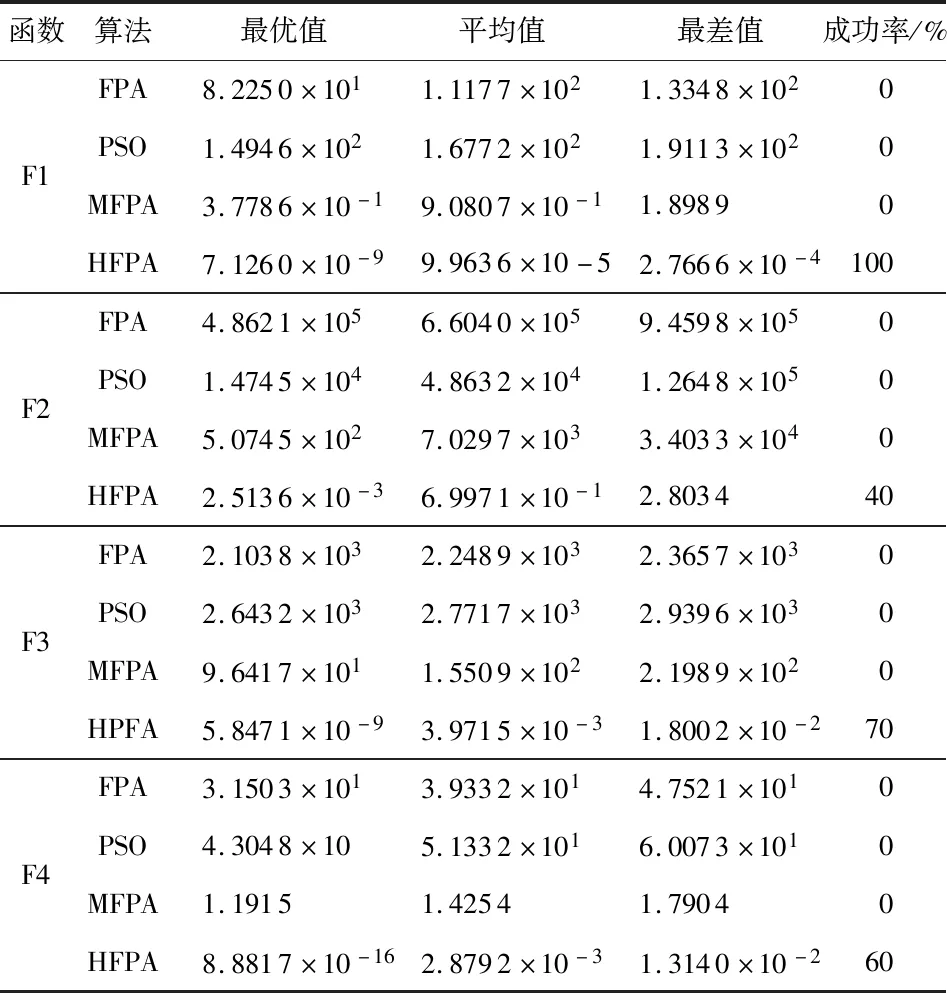
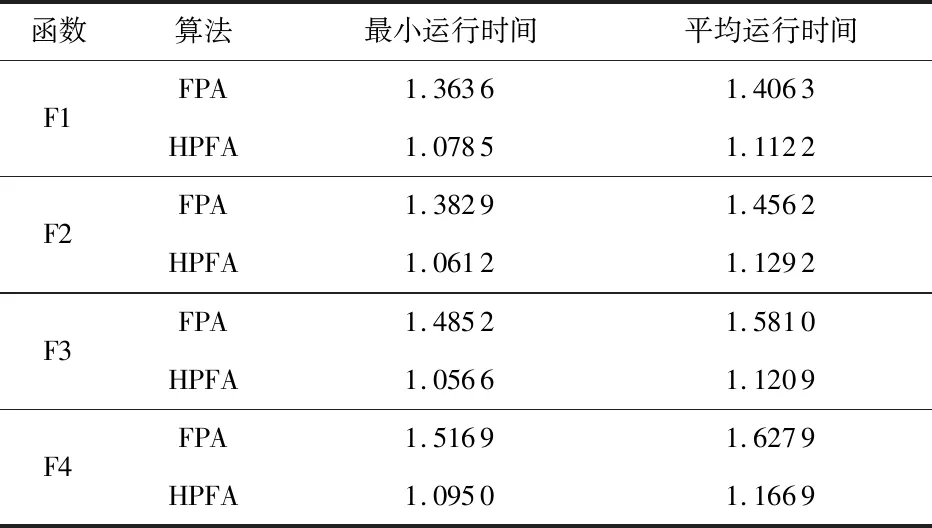
a.初始化算法的參數,迭代次數N(或迭代停止精度),種群數量n,轉換概率p,變異概率pl;b.均勻初始化種群,并計算各個個體的適應度值;c.若p>rand,按照式(2)對更新解,進行全局尋優;d.若p 本文選擇具有代表性的4個函數來驗證HFPA算法的有效性和優越性,包括單峰、多峰函數,并將測試結果與FPA算法,粒子群算法(PSO)等算法那進行比較。測試函數選取CEC2013 benchmark[15]測試函數的一部分: 其中,f1,f2,f3為單峰函數,f4~f7為多峰函數,一般用來驗證算法逃離局部極值的能力。 此實驗各算法種群數均為20,迭代次數為1500,維度為30。每種算法對每個測試函數運行100次,對比各算法的最優值、平均值就、最差值及尋優成功率。若算法所得最優值與理論最優值相差小于0.001,則認為尋優成功。實驗結果如表1所示。其中FPA算法的參數為:p=0.8,n=20;HFPA算法的參數為:p=0.8,n=20,pl=0.1;MFPA的參數為p=0.8,n=20,w=0.618;PSO算法參數為:c1=1.496 2,c2=1.496 2,w=0.729 8。實驗結果如表1所示。 從表1可以看出,HFPA算法對各個函數求解的最優值都遠小于FPA和PSO算法。較同為FPA改進算法的MFPA算法相比,HFPA解的精度有1~16個數量級的提升,同時解得最優解的成功率和穩定性有很大提高,對7種測試函數的求解均達到了100 %的尋優成功率。圖1是其中四種算法在測試函數F1~F4的收斂曲線,其中橫坐標代表迭代次數,縱坐標表示測試函數的適應度值。 表1 HFPA在低維的性能分析 圖1 測試函數收斂曲線 從圖1可以看出,HFPA 算法不易陷入局部最優,且能在算法迭代初期快速收斂,有效提高了迭代速度和精度。 實驗中各算法種群數均為20,迭代次數為1500,維度為100。每種算法對每個測試函數運行100次,對比各算法的實際最優值、平均值就、最差值,如果理論最優值與實際獲得的最優值誤差小于0.001,認為尋優成功。實驗結果如表2所示。 從表2可以得知,HFPA,在300維測試函數下,除F7函數外,都能達到都能夠達到70 %以上的收斂率,而FPA算法大部分情況下無法收斂。HFPA 與 FPA、PSO、MFPA 相比,對于函數 ,HFPA 的最優值、平均值、最差值和尋優成功率均好于其他 3 種算法。這說明從尋優精度、收斂速度和魯棒性上,HFPA相較原算法有較大幅度的提高。 實驗中各算法種群數均為20,最大迭代次數為3000,維度為30。每種算法對每個測試函數運行100次,對比各算法達到10-3精度所需的最少迭代次數,平均迭代次數和最大迭代次數。 表2 HFPA在高維的性能分析 表3 HFPA在固定精度下的性能分析 從表3可以看出,對于4個測試函數,HFPA算法均能在1000次迭代內達到目標精度,且無論是最小收斂代數還是平均收斂代數均優于原算法,與其他花朵授粉改進算法相比,迭代次數明顯降低。說明HFPA有效提高了FPA算法的收斂速度。 針對4種測試函數,維度30,算法種群數均為20,迭代次數1500次。每個算法運行10次,比較FPA算法和HFPA算法的最小運行時間和平均運行時間。實驗結果如表4所示。 表4 HFPA運行速度分析 s 從表4可以看出,HFPA的在相同迭代次數下的運行時間在各測試函數下相比FPA算法均有降低。說明HFPA的時間復雜度低于原FPA算法,結合HFPA達到目標精度所需迭代次數較少的特點,使得算法收斂到目標精度所需的時間相比FPA算法大大縮短。 仿真實驗結果表明:HFPA算法在收斂速度和精度,運行速度相比原FPA算法有較大提升。HFPA算法在低維下尋優精度較原FPA算法有5~20個數量級的提升,高維下有3~9個數量級的提升,達到相同精度所需的迭代次數大大減少,單次運行時間的比FPA算法有0.4~0.5s的降低,證明本文算法具有一定的可行性。今后準備將花朵授粉算法與其他領域結合,將算法應用于實際當中。3 仿真實驗與結果分析
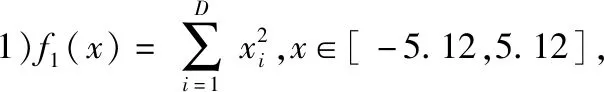
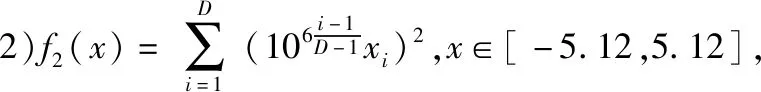
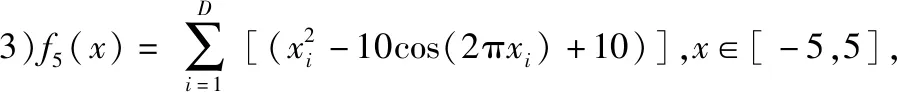

3.1 低維下的性能分析
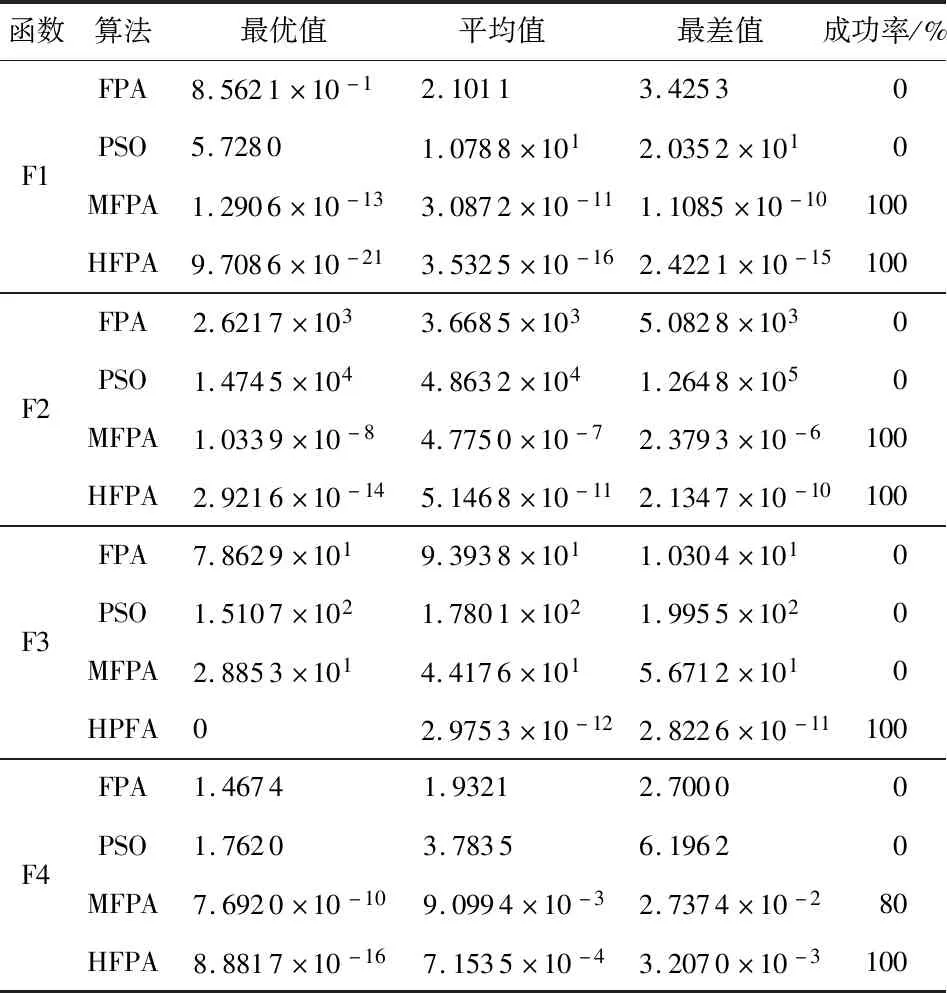
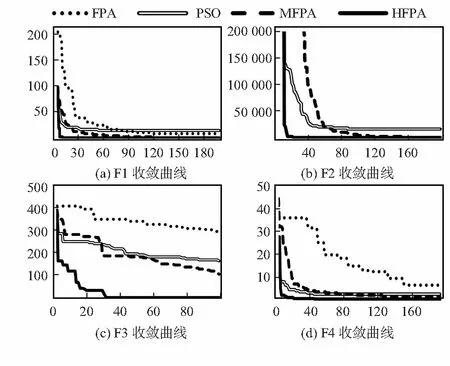
3.2 高維下的性能分析
3.3 固定精度下的性能分析

3.4 運行速度分析
4 結 論
