基于店鋪特征和用戶需求的廣告轉化率預測
2019-09-10 07:22:44孫玥楊國為何鎏
青島大學學報(工程技術版) 2019年3期
關鍵詞:用戶需求
孫玥 楊國為 何鎏
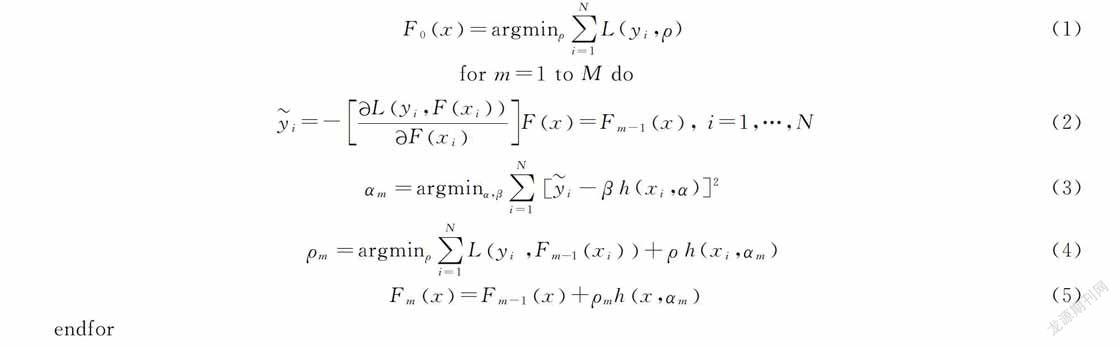

摘要: 針對現(xiàn)有搜索廣告轉化率預測模型和分類模型未考慮店鋪特征和用戶需求,為了更好的預測廣告的轉化率,本文基于店鋪特征和用戶需求對廣告轉化率進行預測。以阿里搜索廣告為研究對象,提出基于店鋪特征和用戶需求的數(shù)據(jù)預分析的特征處理方式,對特征進行預分析,即對用戶和店鋪的相關特征進行初次預測處理,分別求出轉化率,以此作為新特征。XGBoost算法泛化性能高,損失函數(shù)同時用到一階導和二階導,可以加快優(yōu)化速度,所以運用該算法構建基于店鋪特征和用戶需求的阿里搜索廣告轉化率預測模型和轉化率分類模型。通過對比預測結果在對數(shù)似然損失(Logarith mic loss, Logless)的指標,該預測模型的正確預測率和正確分類率顯著提升。本文使用的特征處理方式能夠充分挖掘商品信息,能夠更好的實現(xiàn)廣告轉化率的預測,有利于提高廣告的競爭力。
關鍵詞: 搜索廣告; 預分析; XGBoost; 轉化率; 店鋪特征; 用戶需求
中圖分類號: TP181? 文獻標識碼: A
1 相關理論與證明
1.1 特征工程概念
特征工程是機器學習領域至關重要的概念,一般認為是為機器學習應用而設計特征集的相關工作。對于基于特征的機器學習方法,特征集的選擇決定了算法迭代到最優(yōu)情況的極值,特征體系設計的優(yōu)劣決定了整個模型的性能[6]。因此,如何利用已有的歷史數(shù)據(jù)抽取有效的、與預估任務高度關聯(lián)的特征是接下來要考慮的首要問題。特征設計的好壞直接影響預測模型預測效果的極限,對模型的時空復雜度及收斂速度都有較大影響。特征工程通過一系列必要的工程活動,將所有信息使用更加高效的編碼方式表示,獲取更好的訓練數(shù)據(jù)。在對信息進行特征處理時,要保證信息損失較少,原始數(shù)據(jù)中包含的規(guī)律依然保留。此外,新的編碼方式應盡量減少原始數(shù)據(jù)中不確定性因素的影響[78]。
1.2 特征工程常用方法
對特征工程的數(shù)據(jù)處理一般包括3種方式。在進行特征構建時,分別對不同類型的數(shù)據(jù)進行處理,獲得預測模型需要的特征。
1.2.1 數(shù)值型數(shù)據(jù)
1) 標準化處理:對于數(shù)值型的特征,特征取值范圍較大,數(shù)據(jù)分布也很分散,導致方差很大,因此在進行處理時,需要將其標準化為正態(tài)函數(shù),均值為0,方差為1,但處理前需要提前考慮是否需要進行這項處理[9]。
2) 歸一化處理:將數(shù)據(jù)大小調(diào)整到0~1之間,進行歸一化處理后,不僅能夠提高收斂速度,減少運算時間,而且能夠提升模型精度。所以本文對廣告商品的銷量等級、價格等級、被收藏次數(shù)等級、被展示次數(shù)等級這些特征進行歸一化處理。
3) 離散化處理:將連續(xù)值轉化成非線性數(shù)據(jù)。廣告商品的品牌編號是一個long類型,將其按照1 000以上,10到1 000和10以下進行離散化處理。
1.2.2 類別型數(shù)據(jù)
類別型一般是文本信息,使用數(shù)據(jù)時采用OneHot編碼處理。OneHot編碼方法是使用N位狀態(tài)寄存器對N個狀態(tài)進行編碼,每個狀態(tài)都有獨立的寄存器位,并且在任意時候只有一位有效[1011]。在對頁面展示編號廣告商品的類目進行處理時,采用OneHot編碼處理。
1.2.3 時間型數(shù)據(jù)
時間型數(shù)據(jù)特征可被看作兩部分,當為連續(xù)值時,用來統(tǒng)計持續(xù)時間和時間間隔等[1213];當為離散值時,可以提取小時和星期,w和h就是提取出來的小時和星期。
2 基于XGBoost算法的轉化率預測模型和分類模型的構建過程XGBoost是大規(guī)模并行Boosted tree工具,比常見的工具包快10倍以上,Boosted tree最基本的組成部分叫做回歸樹(Regression tree),也叫CART,它會把輸入根據(jù)輸入的屬性分配到每個葉子節(jié)點,且每個葉子節(jié)點上面都會對應一個實數(shù)分數(shù)[1415]。該算法可通過分布方式建立模型,在不斷更新迭代中選擇梯度下降的方向來保證預測結果最優(yōu),其算法流程如下[16]
本文使用XGBoost算法在CPU計算機上并行Boosted tree,提升Boosted tree的預測精度[17],調(diào)用train_test_split函數(shù),隨機將實驗數(shù)據(jù)劃分為訓練集和測試集,其中實驗數(shù)據(jù)都是242維,用來訓練模型。
3 系統(tǒng)實現(xiàn)
3.1 實驗數(shù)據(jù)
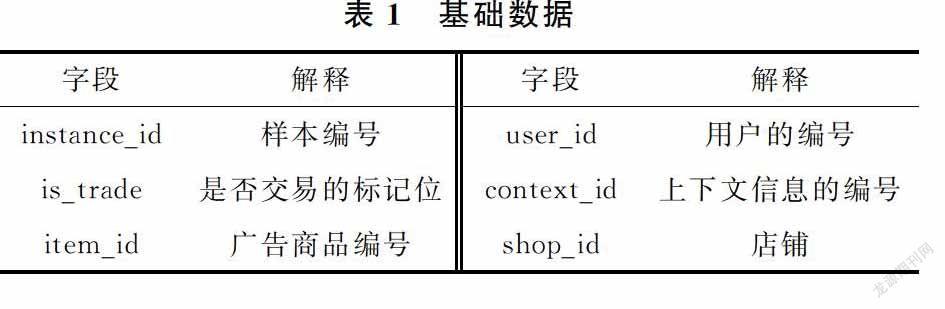
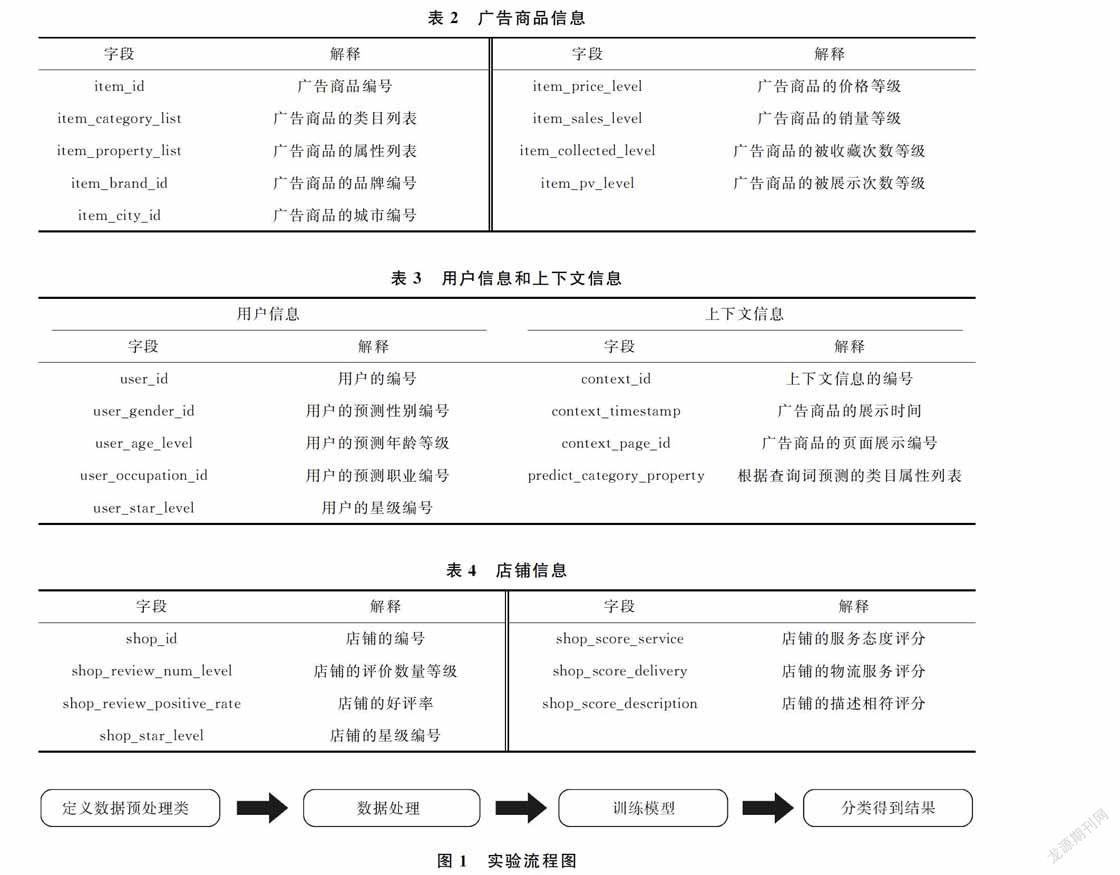
為保證實驗結果的準確性,實驗使用的數(shù)據(jù)來自阿里媽媽國際廣告算法大賽,本次使用的數(shù)據(jù)包括基礎數(shù)據(jù)、廣告商品信息、用戶信息、上下文信息和店鋪信息5類。基礎數(shù)據(jù)表如表1所示,提供了搜索廣告最基本的信息以及“是否交易”的標記;廣告商品信息、用戶信息、上下文信息和店鋪信息等4類數(shù)據(jù)如表2~表4所示,提供了
3.2 實驗數(shù)據(jù)特征處理
采集到的廣告數(shù)據(jù)由于相關性程度低等因素導致包含不實用數(shù)據(jù),為了使數(shù)據(jù)分析或數(shù)據(jù)預測工作具有科學性和可靠性,不能直接使用這些“臟數(shù)據(jù)”。因此,首先需要對采集到的原始數(shù)據(jù)進行特征提取[18]。
3.2.1 用戶信息處理
用戶自然屬性特征來源與用戶的注冊信息,主要根據(jù)所給的數(shù)據(jù)進行轉化率求解,即在所有給定的數(shù)據(jù)及標簽的情況下,分別求出不同性別及不同年齡等級產(chǎn)生購買行為的轉化率,從而產(chǎn)生新的使用特征。
3.2.2 廣告商品的信息處理
對于廣告商品的屬性列表,由于其屬性有分類,所以需要計算其各屬性的數(shù)量及權重和。商品類目列表經(jīng)過計算,其第1列完全相同,所以只選后兩個,并把其分為兩個特征分別計入,為后面編碼做準備。廣告商品編號、廣告商品的品牌編號、廣告商品的城市編號分別計數(shù),求其轉化率。
3.2.3 上下文信息處理
用戶是否購買商品與時間存在一定聯(lián)系,如雙十一購物節(jié)、春節(jié)、圣誕節(jié)、情人節(jié)等都會使用戶產(chǎn)生購買行為,因此商品的展示時間也是一個重要屬性。根據(jù)所給的原始數(shù)據(jù),先將時間轉化為正常格式,同時增加周屬性來增加新的特征。對于商品的預測類目屬性,由于其存在缺失值,可以統(tǒng)計類目屬性的個數(shù)、最大值及其總和。
3.2.4 OneHot Encoding處理
在很多機器學習任務中,特征有的是連續(xù)值,有的是分類值。如果將特征用數(shù)字表示,效率會很高。但是在轉化為數(shù)字表示后,數(shù)據(jù)不能直接用在分類器中。為了解決上述問題,可行的方法是采用獨熱編碼(OneHot Encoding),又稱1位有效編碼。其方法是使用N位狀態(tài)寄存器對N個狀態(tài)進行編碼,每個狀態(tài)都有其獨立的寄存器位,并且在任意時候,其中只有一位有效[19
20]。所以對'item_sales_level','item_price_level','item_collected_level','item_pv_level','context_page_id','w','h','item_category1','item_category2'進行編碼處理。
3.2.5 基于店鋪特征和用戶需求的預分析特征處理
為解決傳統(tǒng)特征處理的弊端,本研究加入創(chuàng)新點,為對shop和user的相關數(shù)據(jù)進行預分析的特征處理,分別通過XGBoost后產(chǎn)生兩列新的特征,即不同店鋪和不同用戶的轉化率,其分別為predicted_shop_score和predicted_user_score。
用戶數(shù)據(jù)的轉化與否與用戶的意愿密切相關,所以對用戶相關的特征處理非常重要。首先對每個用戶的相關特征進行組合,然后通過XGBoost對組合后的數(shù)據(jù)求轉化率,進而重新生成一維特征,即每個用戶的轉化率predicted_user_score。
店鋪優(yōu)劣對廣告商品轉化率有重大影響,對于同一商品,不同店鋪的轉化率不同,店鋪的評價數(shù)量、好評率、星級、服務態(tài)度、物流服務、描述相符等特征都會影響轉化率,而店鋪轉化率又與廣告商品的轉化率密切相關,所以研究店鋪的相關特征對搜索廣告轉化率有重大影響。首先對每個店鋪的相關特征進行組合,然后通過XGBoost對組合后的數(shù)據(jù)求出轉化率,進而重新生成一維特征,即每個店鋪的轉化率predicted_shop_score。對于得到的兩維新特征predicted_shop_score和predicted_user_score,與其他特征一樣,作為最終需要的特征進行訓練。
4 實驗評價與討論
4.1 分類預測評估指標
本文采用對數(shù)似然損失(logarithmic loss, Logloss)對模型進行評價。對數(shù)損失通過懲罰錯誤的分類,實現(xiàn)對分類器準確率的量化。最小化對數(shù)損失基本等價于最大化分類器的準確度,為了計算對數(shù)損失,分類器必須提供對輸入所屬類別的概率值,不只是最可能的類別。對數(shù)損失的計算公式為
4.2 實驗評價
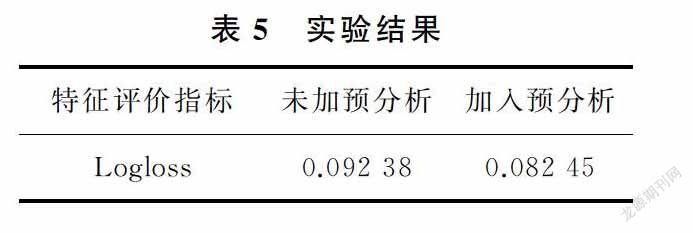
運行Python程序,通過模型將測試集的樣本進行分類,求解其轉化率,用于求Logloss的pi,進而求解Logloss值。實驗結果如表5所示。由表5可以看出,在沒有加入初次預測項數(shù)據(jù)時,logloss較高;在加入初次預測后,logloss明顯下降。因此,基于店鋪特征和用戶需求預分析的特征處理方式是可用的。
5 結束語
本文提出基于店鋪特征和用戶需求預分析的特征處理方式,對轉化率進行正確分類及預測。通過實驗研究廣告轉化率的預測問題,訓練數(shù)據(jù)特征的選擇對于模型的預測性能影響重大。廣告轉化率預測中,數(shù)據(jù)特征包含基礎數(shù)據(jù)、廣告商品信息、用戶信息、上下文信息和店鋪信息。這些特征組合得越好,模型性能就越好,模型的準確率就越高。本文提出的模型更好地降低了Logloss值,預測廣告的轉化率更準確,實現(xiàn)了廣告商的最大利益。如何從特征學習的角度預估稀疏廣告的轉化率,同時進行不同模型融合方面的機理性研究是下一步的研究重點。
參考文獻:
[1] Graepel T, Candela J Q, Borchert T, et al. Webscale Bayesian clickthrough rate prediction for sponsored search advertising in Microsoft's bing search engine[C]∥International Conference on International Conference on Machine Learning. Haifa, Israel: DBLP, 2010: 1320.
[2] 宋益多. 基于用戶特征的搜索廣告點擊率預測研究[D]. 哈爾濱: 哈爾濱工程大學, 2015.
[3] Stankevich M, Isakov V, Devyatkin D, et al. Feature engineering for depression detection in social media[C]∥International Conference on Pattern Recognition Applications and Methods. Angers, France: IEEE, 2018: 426431.
[4] 余仕敏. 基于遞歸神經(jīng)網(wǎng)絡的廣告點擊率預估[D]. 杭州: 浙江理工大學, 2016.
[5] 曹璨. 基于特征抽取和分步回歸算法的資金流入流出預測模型[D]. 合肥: 中國科學技術大學, 2017.
[6] Thenmozhi D, Mirunalini P, Aravindan C. Feature engineering and characterization of classifiers for consumer health information search[M]. Springer, Germany: Text Processing, 2018.
[7] 張凱姣. 基于Python機器學習的可視化麻紗質(zhì)量預測系統(tǒng)[D]. 長寧: 東華大學, 2017.
[8] 司向輝. 個性化廣告點擊率預測的研究和實現(xiàn)[D]. 北京: 北京郵電大學, 2013.
[9] Chen J H, Li X Y, Zhao Z Q, et al. A CTR prediction method based on feature engineering and online learning[C]∥International Symposium on Communications and Information Technologies. Cairns, QLD,Australia: IEEE, 2017.
[10] 劉懷軍, 車萬翔, 劉挺. 中文語義角色標注的特征工程[J]. 中文信息學報, 2007, 21(1): 7984.
[11] 王兵. 一種基于邏輯回歸模型的搜索廣告點擊率預估方法的研究[D]. 杭州: 浙江大學, 2013.
[12] 周永. 基于特征學習的廣告點擊率預估技術研究[D]. 哈爾濱: 哈爾濱工程大學, 2014.
[13] 胡平伍. 移動廣告點擊率預測方法的研究與實現(xiàn)[D]. 南京: 東南大學, 2017.
[14] 葉倩怡. 基于Xgboost方法的實體零售業(yè)銷售額預測研究[D]. 南昌: 南昌大學, 2016.
[15] 蘭曉然, 張灝, 李明, 等. 基于數(shù)據(jù)挖掘的手機用戶換機行為預測研究[J]. 數(shù)學的實踐與認識, 2017, 47(16): 7180.
[16] 賈文慧, 孫林子, 景英川. 基于XGBoost模型的股骨頸骨折手術預后質(zhì)量評分預測[J]. 太原理工大學學報, 2018, 49(1): 174178.
[17] 樊鵬. 基于優(yōu)化的xgboosTLMT模型的供應商信用評價研究[D]. 廣州: 廣東工業(yè)大學, 2016.
[18] 劉懷軍, 車萬翔, 劉挺. 中文語義角色標注的特征工程[J]. 中文信息學報, 2007, 21(1): 7984.
[19] 匡俊, 唐衛(wèi)紅, 陳雷慧, 等. 基于特征工程的視頻點擊率預測算法[J]. 華東師范大學學報: 自然科學版, 2018(3): 7787.
[20] 嚴嶺. 展示廣告中點擊率預估問題研究[D]. 上海: 上海交通大學, 2015.
猜你喜歡
中國新通信(2016年21期)2017-01-06 11:51:42
青年時代(2016年20期)2016-12-08 17:50:05
新聞愛好者(2016年10期)2016-11-18 15:20:33
中國市場(2016年34期)2016-10-15 04:02:07
科教導刊·電子版(2016年11期)2016-06-03 21:29:45
今傳媒(2016年5期)2016-06-01 23:47:05
今傳媒(2016年5期)2016-06-01 00:17:22
電腦知識與技術(2016年8期)2016-05-19 13:45:35
商(2016年9期)2016-04-15 09:47:56
求知導刊(2016年6期)2016-04-06 00:54:00
