基于相關(guān)濾波和離散度分析的幀同步識別
2019-09-06 07:49:40雷迎科
探測與控制學(xué)報(bào) 2019年4期
關(guān)鍵詞:方法
邵 堃,雷迎科
(國防科技大學(xué)電子對抗學(xué)院, 安徽 合肥 230037)
0 引言
從利用傳統(tǒng)的短波、超短波電臺實(shí)現(xiàn)戰(zhàn)場實(shí)時(shí)通信到數(shù)據(jù)鏈技術(shù)在武器裝備上的應(yīng)用,軍事通信技術(shù)正在飛速地發(fā)展。軍事通信技術(shù)不斷結(jié)合發(fā)展現(xiàn)代通信技術(shù)與戰(zhàn)術(shù)理論,目的是保證戰(zhàn)場的通信并進(jìn)行信息實(shí)時(shí)的傳輸與反饋。軍事通信信號是以幀為單位進(jìn)行發(fā)送和接收的,幀內(nèi)除了有內(nèi)容可變的字段外還存在一些位置、內(nèi)容固定不變的固定字段。如文獻(xiàn)[1—3]所述,若收發(fā)雙方已知幀格式,可以通過比對處理對接收到的數(shù)據(jù)準(zhǔn)確分組,完成信息的傳送。作為非合作方,面對未知的幀結(jié)構(gòu),對偵察截獲到的數(shù)字序列進(jìn)行準(zhǔn)確的幀切分和幀同步的識別是對協(xié)議識別的第一步。因此,國內(nèi)外許多學(xué)者開展了對幀同步識別[4-13]的研究。
李歆昊等人提出一種基于多重分形譜的幀同步字盲識別方法[5]。該方法利用同步段與信息段的有偏性識別幀同步,但在同步碼是偽隨機(jī)性序列的情況下,該方法的識別性能明顯下降。文獻(xiàn)[6]提出一種累積濾波算法,該算法利用幀頭碼字的強(qiáng)相關(guān)性,能夠有效地檢測出幀頭部分的長度和起始位置,但該算法的識別性能受閾值選擇的制約。王和洲等人提出一種比特流切割算法[7],盡管該算法適用于完全未知的協(xié)議類型,但其一定程度地犧牲了空間上和時(shí)間上的復(fù)雜度。文獻(xiàn)[8]提出一種基于偏三階相關(guān)函數(shù)峰值特性的識別方法來識別幀同步碼序列,雖然該方法對樣本數(shù)據(jù)量要求較低,但其只適用于同步碼序列是m序列的情況。文獻(xiàn)[10]提出了對編碼加擾序列的幀同步識別方法,該方法結(jié)合擾碼重建技術(shù)先實(shí)現(xiàn)粗同步,再進(jìn)行解擾實(shí)現(xiàn)精同步位置識別,并將算法推廣到含噪聲情況,但該方法受限于編碼方式和參數(shù)的影響。文獻(xiàn)[11]提出的模糊匹配方法是將同步碼的碼型作為先驗(yàn)信息進(jìn)行匹配,只對碼型確定的同步碼識別率較高,對同步碼碼型不確定、碼長不確定的數(shù)字信號識別率明顯降低。利用濾波算法[11-13]尋找同步碼起始位置的過程中涉及到門限最優(yōu)選擇,可能導(dǎo)致算法達(dá)不到最優(yōu)性能,且多數(shù)算法未考慮關(guān)鍵字段與同步碼直接連接的情況。目前的幀同步識別方法普遍存在兩個(gè)問題:一是對于判決門限的選擇沒有一個(gè)具體的準(zhǔn)則,門限普適性不高;二是基于相關(guān)的幀同步碼識別方法無法準(zhǔn)確識別與固定字段連接在一起的幀同步碼。本文針對上述問題,提出了基于相關(guān)濾波和離散度分析的幀同步識別方法。
1 幀同步識別基礎(chǔ)
1.1 幀結(jié)構(gòu)
在戰(zhàn)場環(huán)境下,通信方為了實(shí)現(xiàn)通信的隱蔽性和防截獲性[14],需要完成信息的間斷傳輸,為了確保收發(fā)端順利傳輸信息,發(fā)送方會選擇將數(shù)據(jù)打包成幀后進(jìn)行傳輸,即發(fā)送端在每幀的開始插入一段特殊的碼組作為同步序列。根據(jù)協(xié)議類型的不同,同步序列長度不定碼型不定,同步序列部分用于幀同步,信息部分用來承載來自高層的傳輸塊數(shù)據(jù),幀封裝的一般格式如圖1所示。

圖1 幀封裝一般格式
Fig.1 Frame encapsulation general format
1.2 比特流數(shù)據(jù)的特點(diǎn)
圖2表示具有集中插入式幀結(jié)構(gòu)的比特流數(shù)據(jù)。對幀同步進(jìn)行識別時(shí),不僅要考慮到幀結(jié)構(gòu)還要考慮到比特流數(shù)據(jù)的特點(diǎn):
1) “01”性。比特流數(shù)據(jù)中包含的元素具有二元性,非0即1。
2) 無界性。對于非合作方來說,對不加處理的數(shù)據(jù)無法區(qū)分幀起始點(diǎn)和結(jié)束點(diǎn),比特流數(shù)據(jù)的無界性如圖3所示。
3) 關(guān)聯(lián)性。通信方以幀為單位進(jìn)行數(shù)據(jù)傳輸。每段比特流數(shù)據(jù)承載著不同的內(nèi)容。通信方為了保證信息的實(shí)時(shí)傳輸和表達(dá)準(zhǔn)確性和效率,各數(shù)據(jù)幀之間的同步序列等關(guān)鍵字段存在著一定的關(guān)聯(lián)性。
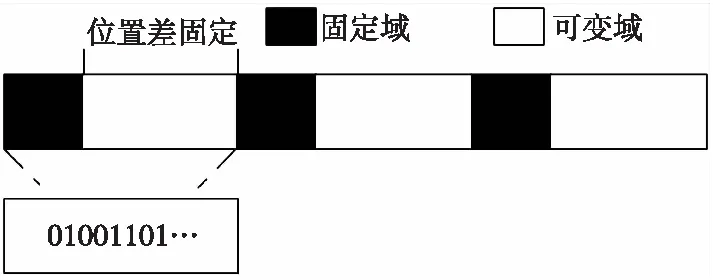
圖2 集中插入式幀同步比特流數(shù)據(jù)特點(diǎn)Fig.2 Centralized insertion frame synchronization bitstream data characteristics

圖3 無界性示意圖Fig.3 Schematic diagram of unbounded property
1.3 同步碼的相關(guān)性
為了接收機(jī)可以通過相關(guān)濾波的方式準(zhǔn)確識別同步碼,要求同步碼具有很強(qiáng)的自相關(guān)性,因此,不論是較短的巴克碼還是較長的偽隨機(jī)序列的自相關(guān)特性曲線都具有尖銳的單峰。
設(shè)一組n位的幀同步碼組為x=(x1,x2,…,xn),其相關(guān)性[15]可由式(1)表示:
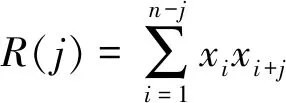
(1)
同步碼的相關(guān)函數(shù)滿足式(2)關(guān)系:
R(0)?R(j)
(2)
即同步字段具有自相關(guān)性強(qiáng)而互相關(guān)性差(在零附近分布)的特點(diǎn),由于信息段經(jīng)過信道編碼后,序列被偽隨機(jī)化,所以信息段的自相關(guān)與互相關(guān)的差異要小于同步字段。
1.4 相關(guān)濾波
相關(guān)濾波[11]是信號處理領(lǐng)域一項(xiàng)重要的技術(shù),它可以利用信號的相關(guān)性對時(shí)移信號進(jìn)行處理,從而抑制和防止干擾、提高信噪比。
1.5 離散度分析
離散度分析法是統(tǒng)計(jì)學(xué)一項(xiàng)重要的方法,主要用來測度一組數(shù)據(jù)的分散程度。分散程度反映了一組數(shù)據(jù)遠(yuǎn)離其中心值的程度。對于一組數(shù)據(jù)變動趨勢的分析,要從集中趨勢和分散程度兩個(gè)方面進(jìn)行說明。
2 幀同步識別方法
本文提出基于相關(guān)濾波和離散度分析的幀同步識別方法,該方法從幀結(jié)構(gòu)、比特流數(shù)據(jù)特點(diǎn)和同步碼相關(guān)性出發(fā),通過相關(guān)濾波和離散度分析對幀同步進(jìn)行識別,該方法包括幀長識別、關(guān)鍵字段識別和同步碼識別三個(gè)部分,流程圖如圖4所示。

圖4 基于相關(guān)濾波和離散度分析的幀同步識別方法流程圖Fig.4 Flow chart of frame synchronization recognition based on relativity filter and dispersion analysis
2.1 基于相關(guān)濾波的幀長識別
2.1.1 填充矩陣的構(gòu)造
設(shè)接收到的數(shù)字序列為y,同步序列m表示為(a1,a2,a3,…,am),其余幀頭、控制協(xié)議、消息體、校驗(yàn)等部分設(shè)為q,表示為(am+1,am+2,am+3,…,aL),其中a∈{0,1},幀長L=Lm+Lq。作為非合作方在接收數(shù)字序列時(shí),會因較差的信道環(huán)境和前期濾波解調(diào)等步驟的偏差使得數(shù)字序列的某些位置出現(xiàn)誤碼。根據(jù)集中插入式幀同步之間的相關(guān)性,將數(shù)字序列y按長度n分組,排列成m行n列的填充矩陣H。

(3)
通過公式(3)可以濾除多余數(shù)據(jù)對幀長識別的影響。當(dāng)n=L時(shí),填充矩陣H的排列方式即為圖5所示,數(shù)據(jù)幀中的同步字段將會出現(xiàn)在填充矩陣每行的相同位置。
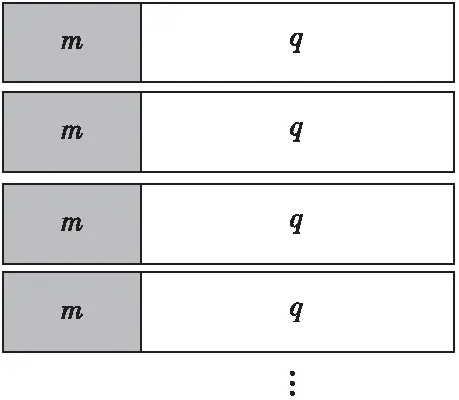
圖5 等長幀理想接收模型Fig.5 Constant length frame reception model
2.1.2 加權(quán)相關(guān)值的計(jì)算
(4)
對填充矩陣H的每列求均值。
(5)
根據(jù)幀數(shù)據(jù)的“01”性改寫c(i)。
ifc(i)>0.5
b(i)=1-c(i);
else
b(i)=c(i);
end

r(i)=f(b(i))(i=1,…,n)
(6)
最后計(jì)算填充矩陣的加權(quán)相關(guān)值:
(7)
輸出v(n),當(dāng)v(n)≥Wh時(shí)的第一個(gè)n值為幀長L,其中Wh為門限值。
加權(quán)相關(guān)值算法的優(yōu)點(diǎn):從分類的角度,加權(quán)相關(guān)值可以有效地將不同長度的n按相關(guān)程度區(qū)分開。考慮存在誤碼的情況,通過兩次均值計(jì)算,使得算法具有較高的容錯(cuò)性。
加權(quán)相關(guān)值算法的不足:加權(quán)相關(guān)值算法只能根據(jù)經(jīng)驗(yàn)對門限Wh選擇,極有可能造成漏檢和誤檢。因此,為了提高識別效率,降低對門限Wh精度的要求,在保證一定的識別率的前提下,根據(jù)加權(quán)相關(guān)值之間的關(guān)系,提出一種基于三次濾波的幀長識別算法。
2.1.3 三次濾波算法基礎(chǔ)
對幀結(jié)構(gòu)的分析可知,關(guān)鍵字段之間存在位置差固定的關(guān)聯(lián)規(guī)則。由式(7)可知,加權(quán)相關(guān)值v滿足下列性質(zhì):
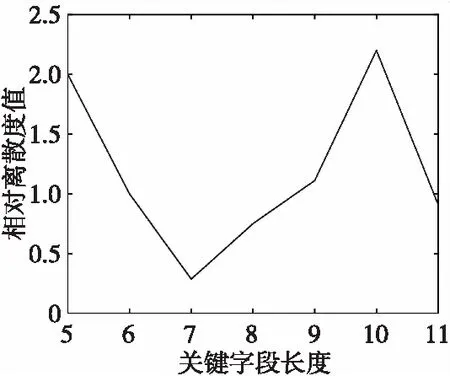
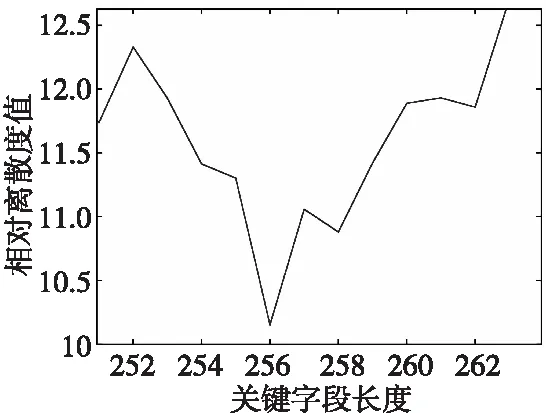
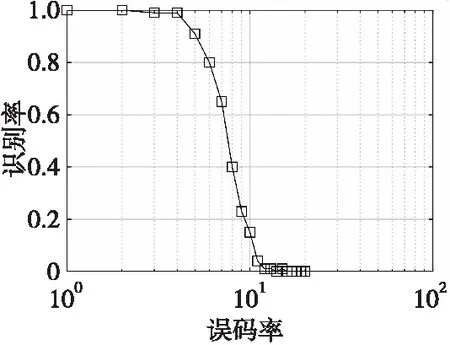
2) 當(dāng)n 2.1.4 三次濾波算法的步驟 1) 第一次濾波:選取一個(gè)相對較小的門限W,將填充矩陣的列數(shù)從小到大變化,得出三個(gè)大于等于門限W的v(n),按照其原有的順序組成步徑為3的判斷矩陣,如式(8): (8) 2) 第二次濾波:判斷n1、n2、n3是否同時(shí)滿足下列關(guān)系: ①Δl=n2-n1=n3-n2; ②n2可以被Δl整除。 3) 第三次濾波:判斷加權(quán)相關(guān)值是否滿足下列關(guān)系: v(n1) 經(jīng)過三次濾波后,Δl即是幀長值。若上述二、三次濾波有一次不滿足,則給W重新賦值W=max{v(n1),v(n2),v(n3)},繼續(xù)上述循環(huán)直到滿足條件或超時(shí)退出。 2.1.5 幀長識別算法性能分析 當(dāng)門限W取適當(dāng)?shù)闹凳沟门袛嗑仃嘝中包含v(kL)(k∈N+)時(shí),在無誤碼的情況下,幀長識別率為100%;當(dāng)門限值W使得判斷矩陣P中不包含加權(quán)相關(guān)值v(kL)(k∈N+)時(shí),經(jīng)過之后的兩次濾波重新修正了門限值,濾除弱相關(guān)性的序列,繼續(xù)循環(huán)識別幀長。 經(jīng)過濾波處理可以對初始門限值進(jìn)行修正,降低了對門限選擇的要求。 關(guān)鍵字段是指在信息傳輸過程中具有特殊作用的字段,如同步字段和對時(shí)隙類型、脈沖形式、航跡號、密鑰號進(jìn)行標(biāo)識的字段。多數(shù)關(guān)鍵字段在幀內(nèi)的位置、內(nèi)容固定不變,但傳輸消息經(jīng)過了編碼、交織、擴(kuò)頻以及信息加密處理等,使得消息中的關(guān)鍵字段被分散,有的可能直接與同步字段連接,本節(jié)中的關(guān)鍵字段是指包含同步字段在內(nèi)的位置、內(nèi)容固定的字段,工作流程如下: 1) 根據(jù)求得的幀長值L重新構(gòu)造填充矩陣。 (9) 2) 求填充矩陣每列的相關(guān)值,進(jìn)一步構(gòu)造相關(guān)矩陣。將相關(guān)值與門限比較進(jìn)行判決,統(tǒng)計(jì)滿足條件的列。 3) 統(tǒng)計(jì)所有連續(xù)滿足條件的列,得到關(guān)鍵字段的識別結(jié)果,其中最長的一段關(guān)鍵字段X有可能是幀同步碼。 經(jīng)過2.2節(jié)的計(jì)算可初步確定接收序列中同步碼的位置,但是所提取的關(guān)鍵字段X中可能既包括同步碼也存在一些固定字段。為了確定基于相關(guān)值法提取的關(guān)鍵字段中是否包括固定字段,并進(jìn)一步將同步碼與固定字段準(zhǔn)確分割開,提出一種基于離散度分析的幀同步碼識別方法。 通過離散度分析法可以得到各組數(shù)據(jù)遠(yuǎn)離中心值的程度。根據(jù)同步碼的自相關(guān)函數(shù)值等于同步碼長,互相關(guān)函數(shù)值始終在0值附近小范圍內(nèi)波動的特性,對關(guān)鍵字段的相關(guān)函數(shù)進(jìn)行離散度分析,可以識別序列中的幀同步碼。 在該處分析中,數(shù)字序列的值用±1,將關(guān)鍵字段X帶入式(1)求得相關(guān)函數(shù)R(j),對相關(guān)函數(shù)進(jìn)行離散度分析: (10) 式(10)中,σ表示關(guān)鍵字段互相關(guān)函數(shù)值相對0值的波動程度。但是σ只反映了除自相關(guān)值外的相關(guān)函數(shù)的波動程度,是數(shù)值的絕對量,無法反映相關(guān)函數(shù)的整體離散情況,因此引入相對離散度值: (11) 依次減小關(guān)鍵字段X的長度,求出對應(yīng)的相對離散度值,若n等于序列X長度時(shí)μn最小,則說明關(guān)鍵字段X即為同步碼,若不然,則當(dāng)μn取最小值時(shí)對應(yīng)的n值是同步碼的長度。 為防止噪聲對識別結(jié)果產(chǎn)生的影響,在一定范圍內(nèi)取多個(gè)m值,重復(fù)上述過程,統(tǒng)計(jì)每個(gè)n值對應(yīng)的多個(gè)相對離散度值,并對其取平均: (12) 實(shí)驗(yàn)一 巴克碼識別 圖6中橫坐標(biāo)填充矩陣列數(shù)即為數(shù)字序列中幀的長度值,圖中在橫坐標(biāo)等于51處加權(quán)相關(guān)值出現(xiàn)第一個(gè)峰值,之后的峰值對應(yīng)的幀長值是實(shí)際幀長的倍數(shù),這是由基于相關(guān)的幀長識別算法決定的,該算法正是利用相鄰峰值間的幀長度差固定的原則求出幀長。圖7中橫坐標(biāo)對應(yīng)一幀數(shù)據(jù)中的各比特位,縱坐標(biāo)表示填充矩陣每列的相關(guān)值,其中相關(guān)值大于門限的位置是關(guān)鍵字段,即1~11 bit。圖8給出了同步碼的識別結(jié)果,圖中在7 bit位置相對離散度值出現(xiàn)最小值,代表1~7 bit是同步碼,實(shí)驗(yàn)數(shù)據(jù)識別結(jié)果與題設(shè)完全吻合。 實(shí)驗(yàn)二 偽隨機(jī)序列識別 實(shí)驗(yàn)參數(shù):幀同步碼是256 bit的偽隨機(jī)序列;同步碼后有42 bit固定字段;幀內(nèi)隨機(jī)插入不等長的固定字段;幀長為1 500 bit;接收序列含有50幀數(shù)據(jù)。 圖6 幀長識別結(jié)果Fig.6 Frame length recognition results 圖7 關(guān)鍵字段識別結(jié)果Fig.7 Frequent sequence recognition results 圖8 同步碼識別結(jié)果Fig.8 Synchronization code recognition results 為了驗(yàn)證基于相關(guān)濾波和離散度分析的幀同步盲識別方法的普適性,選擇幀長較長、同步碼是偽隨機(jī)序列、幀結(jié)構(gòu)復(fù)雜的數(shù)字序列作為實(shí)驗(yàn)對象。圖9給出了幀長識別的結(jié)果。圖10給出了幀內(nèi)關(guān)鍵字段的識別結(jié)果,圖中相關(guān)值等于1的位置即為幀內(nèi)位置和內(nèi)容固定的關(guān)鍵字段。圖11和圖12給出了幀同碼的識別結(jié)果,在256 bit處相對離散度值出現(xiàn)最小值。該方法可以識別出幀長、關(guān)鍵字段、同步碼,實(shí)驗(yàn)結(jié)果與題設(shè)數(shù)據(jù)完全吻合,證明該方法能夠?qū)崿F(xiàn)對幀同步的盲識別。 圖9 幀長識別結(jié)果Fig.9 Frame length recognition results 圖10 關(guān)鍵字段識別結(jié)果Fig.10 Frequent sequence recognition results 圖11 同步碼識別結(jié)果1Fig.11 Synchronization code recognition results 圖12 同步碼識別結(jié)果2Fig.12 Synchronization code recognition results 實(shí)驗(yàn)三 不同誤碼率下的識別率實(shí)驗(yàn) 為了檢驗(yàn)本文方法的識別性能,在不同誤碼率條件下進(jìn)行蒙特卡洛實(shí)驗(yàn)。 圖13 幀長識別率Fig.13 Frame length recognition rate 圖14 同步碼長識別率Fig.14 Synchronous code long recognition rate 圖15 同步碼起始位識別率Fig.15 Synchronous code start bit recognition rate 誤碼率Pe 00.010.020.030.040.050.060.070.080.090.1幀長識別率1.001.001.001.001.001.001.001.001.001.000.99同步碼長識別率1.001.001.000.990.990.910.800.650.400.230.15同步起始位識別率1.001.001.001.000.981.000.950.880.770.700.56 從表1可知,在誤碼率為6%以內(nèi),該方法對數(shù)字序列的幀長、同步碼長、同步起始位的識別率達(dá)到80%以上,有較高的識別率。 本文提出了基于相關(guān)濾波和離散度分析的幀同步識別方法。該方法以集中插入式同步碼作為研究對象,首先通過構(gòu)造填充矩陣初步消除了數(shù)據(jù)冗余對識別算法的影響;然后通過三次相關(guān)濾波自適應(yīng)地改變門限值,完成幀長的識別,解決了幀同步識別算法中門限選擇難度大的問題;之后利用相關(guān)值識別關(guān)鍵字段,初步確定同步碼的位置;最后通過離散度分析方法,準(zhǔn)確地將同步碼與固定字段分割開。其中利用相關(guān)濾波修正門限值的方法和利用離散度分析精確識別同步碼的方法是由本文首次提出。通過對巴克碼和偽隨機(jī)序列作為同步碼的數(shù)字序列的仿真實(shí)驗(yàn)表明,該方法能有效識別幀長、關(guān)鍵字段和同步碼,并且在誤碼率為6%以內(nèi)仍能達(dá)到較高的識別率。2.2 關(guān)鍵字段識別
2.3 基于離散度分析的幀同步碼識別
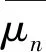
3 實(shí)驗(yàn)仿真
3.1 無誤碼的情況





3.2 有誤碼的情況
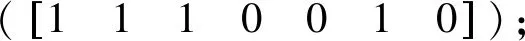



4 結(jié)論
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04河北畫報(bào)(2021年2期)2021-05-25 02:07:46中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04兒童繪本(2020年5期)2020-04-07 17:46:30兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14Coco薇(2016年2期)2016-03-22 02:42:52山東青年(2016年1期)2016-02-28 14:25:23Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年7期)2015-08-11 15:03:12小雪花·成長指南(2015年4期)2015-05-19 14:47:56
