基于DCNN的井下行人監(jiān)測(cè)方法研究*
2019-09-03 07:23:10張應(yīng)團(tuán)鄭嘉祺
計(jì)算機(jī)與數(shù)字工程 2019年8期
張應(yīng)團(tuán) 李 濤 鄭嘉祺
(西安郵電大學(xué)計(jì)算機(jī)學(xué)院 西安 710061)
1 引言
行人檢測(cè)是一種能夠通過輸入圖片或視頻幀來判斷其是否存在行人,并將行人的位置信息表現(xiàn)出來的技術(shù),它在智能視頻監(jiān)控領(lǐng)域、車輛輔助駕駛領(lǐng)域以及人體行文分析領(lǐng)域中的第一步[1]。傳統(tǒng)目標(biāo)檢測(cè)的方法一般“三步走”:第一,在被檢測(cè)的圖像上劃分出一些候選的區(qū)域。第二,對(duì)這些區(qū)域進(jìn)行特征提取。第三,使用已經(jīng)訓(xùn)練好的分類器模型進(jìn)行分類[2]。利用傳統(tǒng)的目標(biāo)檢測(cè)方法設(shè)計(jì)一個(gè)能夠適應(yīng)目標(biāo)的形態(tài)多樣性、光照變化多樣性、背景多樣性等影響的特征并不是那么容易,但是分類好壞的決定性因素就在于特征的提取。傳統(tǒng)目標(biāo)檢測(cè)方法中常用的特征有尺度不變特征變換(Scale-invariant feature transform,SIFT)[3]、方向梯度直方圖(Histogram ofOriented Gradient,HOG)[4]。常用的分類器主要有SVM、Adaboost等。近幾年在圖像識(shí)別和視頻監(jiān)控領(lǐng)域中,深度學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò)大顯身手。深度學(xué)習(xí)是近十年來人工智能領(lǐng)域取得的最重要的突破之一[5],它在語音識(shí)別、自然語言處理、計(jì)算機(jī)視覺、圖像處理與視頻分析、多媒體等諸多領(lǐng)域都取得了巨大的成功[6]。
圖像分類方面,2012年ImageNet大規(guī)模視覺識(shí)別挑戰(zhàn)賽(ILSVRC,ImageNet Large Scale Visual Recognition Competition)上,由Geoffrey Hinton教授和他的學(xué)生Krizhevsky首次提出使用卷積神經(jīng)網(wǎng)絡(luò)來處理ILSVRC分類任務(wù),將Top-5 error降低到了15.3%,而使用傳統(tǒng)方法的第二名top-5 error高達(dá)26.2%[7],卷積神經(jīng)網(wǎng)絡(luò)第一次在圖像處理中展現(xiàn)了其強(qiáng)大的實(shí)力。2014年,來自Facebook的科學(xué)家Ross B.Girshick使用Region Proposal加上CNN(Convolutional Neural Network)代替?zhèn)鹘y(tǒng)目標(biāo)檢測(cè)使用的滑動(dòng)窗口加手工設(shè)計(jì)特征,設(shè)計(jì)了R-CNN(Region-Convolutional Neural Network)框架,使得目標(biāo)檢測(cè)取得巨大突破。R-CNN在PASCAL VOC2007上的檢測(cè)結(jié)果從DPM HSC的34.3%直接提升到了 66%mAP(mean Average Precision)[8]。2015年何凱明等在Spatial Pyramid Pooling in Deep ConvolutionalNetworks for VisualRecognition論文中提出了SPP-NET[9],它優(yōu)化了R-CNN的檢測(cè)流程,大大提高了R-CNN的速度。Ross B.Girshick教授又提出了Fast R-CNN,它在SPP-NET的基礎(chǔ)上加入了多任務(wù)損失函數(shù),在訓(xùn)練過程中直接使用softmax代替SVM分類,提高了訓(xùn)練和測(cè)試的速度和便捷性[10]。基于回歸的目標(biāo)檢測(cè)算法代表是YOLO目標(biāo)檢測(cè)系統(tǒng)。
2 YOLO目標(biāo)檢測(cè)系統(tǒng)
YOLO方法是在2016年CVPR(IEEE Conference on Computer Vision and Pattern Recognition,IEEE國(guó)際計(jì)算機(jī)視覺與模式識(shí)別會(huì)議)上提出的一種目標(biāo)檢測(cè)方法。YOLO系統(tǒng)的理論基礎(chǔ)就是卷積神經(jīng)網(wǎng)絡(luò)。其最大的不同就是它將物體檢測(cè)的框架設(shè)計(jì)成了一個(gè)回歸問題,YOLO系統(tǒng)將目標(biāo)檢測(cè)所需要的各個(gè)部分全部放入到了一個(gè)神經(jīng)網(wǎng)絡(luò)當(dāng)中,神經(jīng)網(wǎng)絡(luò)使用整幅圖像的特征去預(yù)測(cè)每一個(gè)范圍框的參數(shù),同時(shí)也能夠預(yù)測(cè)整個(gè)圖片里包含的所有目標(biāo)種類的范圍框。也就是說只需要使系統(tǒng)“看”一次圖像,就能夠得出目標(biāo)的種類以及它所在圖片的位置,因此這個(gè)方法才取名YOLO(You Only Look Once)[11]。YOLO系統(tǒng)的設(shè)計(jì)能夠讓訓(xùn)練成為端對(duì)端的并且速度非常快,同時(shí)又能夠滿足較高的平均檢準(zhǔn)率(mean Average Precision,mAP)。
YOLO系統(tǒng)的網(wǎng)絡(luò)包含卷積層和全連接層。卷積層負(fù)責(zé)提取圖像的特征,全連接層負(fù)責(zé)輸出范圍框的中心點(diǎn)坐標(biāo)及長(zhǎng)寬和檢測(cè)概率。YOLO的網(wǎng)絡(luò)結(jié)構(gòu)借鑒了GoogLeNet的圖像分類模型,去掉了GoogLeNet中起始模型(Inception Module)里的預(yù)先層(Previous Layer)[12],只簡(jiǎn)單地在3*3卷積層后面接了一個(gè)1*1的卷積層來降低特征空間。整個(gè)網(wǎng)絡(luò)結(jié)構(gòu)包含24個(gè)卷積層和2個(gè)全連接層。
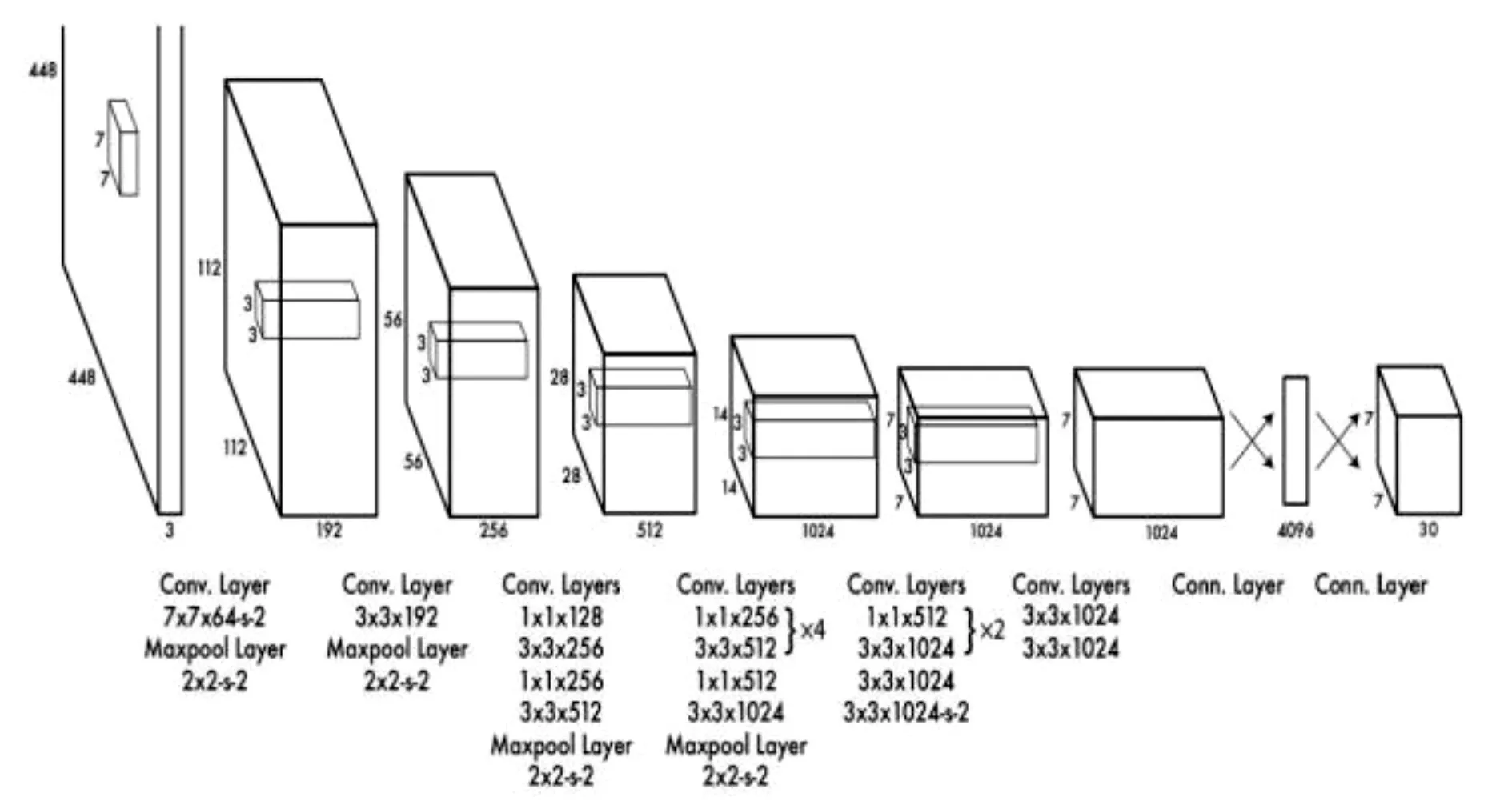
圖1 YOLO基本網(wǎng)絡(luò)結(jié)構(gòu)示意圖
YOLO的最大優(yōu)勢(shì)是它的檢測(cè)速度非常快,這受益于將檢測(cè)問題轉(zhuǎn)換為了回歸問題,所以它不需要太復(fù)雜的結(jié)構(gòu)。以上述結(jié)構(gòu)為例,在Titan X GPU上檢測(cè)的檢測(cè)速率能夠達(dá)到45幀每秒。
目前最快最好的檢測(cè)方法FastR-CNN比較容易誤將圖像中的背景區(qū)域檢測(cè)成物體,因?yàn)樗鼨z測(cè)的范圍比較小。YOLO的背景誤差要比Fast R-CNN小一半多。雖然YOLO在檢測(cè)的速度上已經(jīng)非常快了,但是在檢測(cè)精度上仍然落后于目前最好的檢測(cè)系統(tǒng)。因?yàn)槠鋸?qiáng)烈的空間約束,導(dǎo)致YOLO在對(duì)小目標(biāo)和多重目標(biāo)上的檢測(cè)精度還不夠好。
3 YOLO的改進(jìn)及測(cè)試
雖然新版本的YOLO性能表現(xiàn)良好,其檢測(cè)速度和精度都有了提升,然而在井下的環(huán)境中,光照環(huán)境差、背景單調(diào)、檢測(cè)目標(biāo)較為單一、且監(jiān)控視頻數(shù)據(jù)為單通道、圖片噪聲比較大,如果直接使用YOLO檢測(cè)系統(tǒng)來對(duì)井下環(huán)境的目標(biāo)進(jìn)行檢測(cè),會(huì)導(dǎo)致精確度不高,而且檢測(cè)效果非常差,如圖2,使用原YOLO系統(tǒng)無法檢測(cè)出井下環(huán)境中的人。

圖2 使用原YOLO系統(tǒng)的檢測(cè)結(jié)果
3.1 改進(jìn)的思想
礦井下的環(huán)境與自然光場(chǎng)景下有著極大的不同,所以訓(xùn)練集必須要符合井下的環(huán)境要求。局限于YOLO的缺陷,其檢測(cè)小目標(biāo)和多重目標(biāo)的效果較差,針對(duì)這一點(diǎn),調(diào)整其網(wǎng)絡(luò)結(jié)構(gòu)來改進(jìn)最后網(wǎng)絡(luò)的檢測(cè)結(jié)果。所以本文對(duì)YOLO的改進(jìn)主要包含兩個(gè)方面,一是選擇新數(shù)據(jù)集重新訓(xùn)練模型,二是改進(jìn)其網(wǎng)絡(luò)結(jié)構(gòu)。
2016年12月YOLO在其官網(wǎng)上發(fā)布了新版本YOLOv2[13],在新版本中對(duì)原有的YOLO系統(tǒng)進(jìn)行了許多改進(jìn)。所以本文的改進(jìn)是基于新版本的YOLO系統(tǒng)的。
3.1.1 數(shù)據(jù)集的選擇
數(shù)據(jù)集選擇井下的監(jiān)控視頻轉(zhuǎn)換生成的圖片集。真實(shí)生產(chǎn)環(huán)境的圖片可以減小由于網(wǎng)絡(luò)泛化能力對(duì)檢測(cè)結(jié)果帶來的影響。這樣訓(xùn)練出的神經(jīng)網(wǎng)絡(luò)模型在應(yīng)用時(shí)能夠直接作為實(shí)際應(yīng)用的模型,不用再做更多的調(diào)整。
3.1.2 網(wǎng)絡(luò)結(jié)構(gòu)上的改進(jìn)
YOLO對(duì)于臨近物體的檢測(cè)效果不好,對(duì)于圖片細(xì)節(jié)上的處理還有待于提高,調(diào)整其網(wǎng)絡(luò)結(jié)構(gòu),能夠使其更好的保存網(wǎng)絡(luò)的細(xì)節(jié)特征。
在深度神經(jīng)網(wǎng)絡(luò)中,網(wǎng)絡(luò)的層數(shù)越深,其提取的特征就越抽象,圖像的語義信息就越清晰。所以如果能夠結(jié)合來自深層的語義信息和來自淺層的表征信息作為網(wǎng)絡(luò)的最后輸出,在理論上就能夠提升原YOLO網(wǎng)絡(luò)中對(duì)于細(xì)節(jié)上的處理。
原YOLO系統(tǒng)的網(wǎng)絡(luò)結(jié)構(gòu)共包含22個(gè)卷積層,通過大量的實(shí)驗(yàn)發(fā)現(xiàn),提取第8層卷積層的特征與輸出結(jié)合效果最好。在此基礎(chǔ)上,根據(jù)如上的改進(jìn)思想,本文提出了二種改進(jìn)方案:
方案一:先卷積后下采樣,考慮到卷積后生成的特征圖經(jīng)過采樣會(huì)丟掉一部分原有的信息,因此交換卷積層和下采樣層的順序,即在原YOLO網(wǎng)絡(luò)結(jié)構(gòu)中的第8個(gè)卷積層后的下采樣層后再添加一個(gè)下采樣層,然后再接一個(gè)卷積層,這時(shí)的卷積后的輸出特征圖大小直接就為13*13,再與網(wǎng)絡(luò)最后的輸出相加作為整個(gè)系統(tǒng)最后的輸出。方案一的網(wǎng)絡(luò)結(jié)構(gòu)如圖3所示。
方案二:考慮到采樣對(duì)于特征圖信息的損失,在此方案中,仍然在第8層卷積層后的下采樣層添加一個(gè)卷積核大小為1*1,數(shù)量為30的卷積層,不再添加下采樣層,這時(shí)此卷積層的輸出特征圖大小為26*26。然后將原網(wǎng)絡(luò)的輸出特征圖大小由13*13調(diào)整為26*26與新添加層的輸出匹配,最后將這兩層的結(jié)果相加作為整個(gè)檢測(cè)系統(tǒng)的輸出。本文中將大小為13*13的特征圖調(diào)整為26*26所采用的方法為反卷積的方法[21]。方案二的網(wǎng)絡(luò)結(jié)構(gòu)如圖4所示。
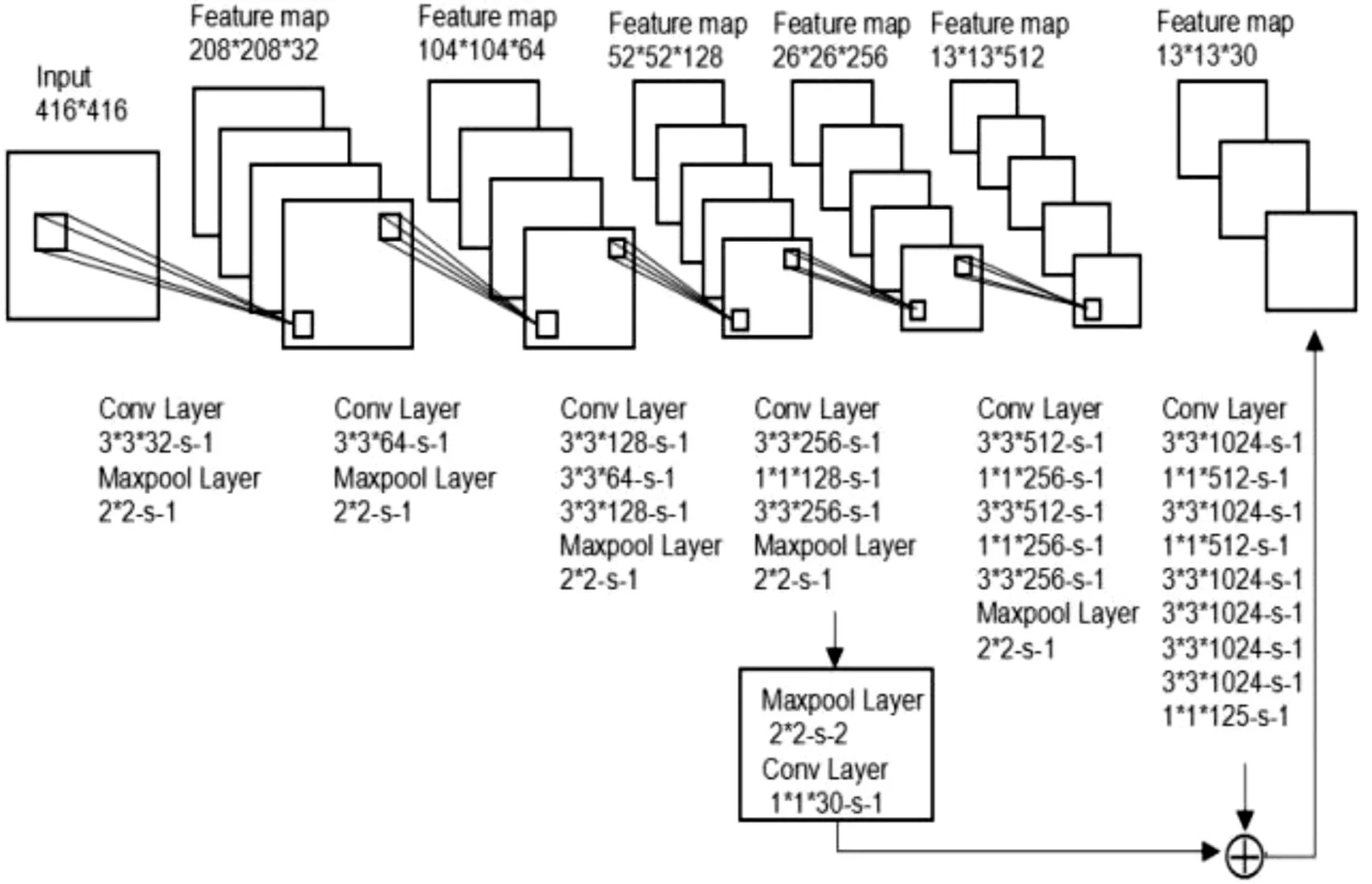
圖3 方案一的網(wǎng)絡(luò)結(jié)構(gòu)

圖4 方案二的網(wǎng)絡(luò)結(jié)構(gòu)
其中Deconv Layer為反卷積層[14],目的是擴(kuò)大特征圖的大小。
3.2 網(wǎng)絡(luò)的訓(xùn)練
為了對(duì)比兩種網(wǎng)絡(luò)結(jié)構(gòu)與原網(wǎng)絡(luò)結(jié)構(gòu)的結(jié)果,在訓(xùn)練中兩個(gè)方案與原網(wǎng)絡(luò)除網(wǎng)絡(luò)結(jié)構(gòu)和訓(xùn)練次數(shù)外,訓(xùn)練過程以及其他訓(xùn)練相關(guān)參數(shù)的設(shè)定都是相同的。
3.2.1 網(wǎng)絡(luò)的預(yù)訓(xùn)練
本文所采用的預(yù)訓(xùn)練模型與原YOLO系統(tǒng)的預(yù)訓(xùn)練模型一致,都是在ImageNet上經(jīng)過20萬次訓(xùn)練的模型。
3.2.2 訓(xùn)練數(shù)據(jù)集處理
訓(xùn)練集采用正通煤礦副井底進(jìn)車側(cè)的監(jiān)控視頻,經(jīng)過轉(zhuǎn)換篩選共生成數(shù)據(jù)集11605張圖片。網(wǎng)絡(luò)的輸入是靜態(tài)二維的圖片信息,攝像頭采集到的視頻需要預(yù)先處理成格式化的圖片,以符合網(wǎng)絡(luò)輸入端的需求。
首先對(duì)攝像頭采集到的原始圖片進(jìn)行預(yù)處理,對(duì)其進(jìn)行統(tǒng)一縮放到416*416像素,縮放之后對(duì)人體輪廓信息損失不大,但有效地減小了網(wǎng)絡(luò)的計(jì)算量,然后每張圖片都利用LabelImg工具進(jìn)行人工標(biāo)注,標(biāo)注后每張圖片會(huì)生成對(duì)應(yīng)xm l文件,深度網(wǎng)絡(luò)需要的數(shù)據(jù)量非常巨大,于是使用Data Augmentation[15]技術(shù)對(duì)圖片進(jìn)行了擴(kuò)增。
數(shù)據(jù)集的構(gòu)成采用VOC數(shù)據(jù)集分割的基本思想,將全部數(shù)據(jù)集的百分之五十設(shè)定為驗(yàn)證集,剩下百分之五十中的一半設(shè)定為訓(xùn)練集,另一半設(shè)定為測(cè)試集。所以最終的數(shù)據(jù)集分為驗(yàn)證集共5800張圖片,測(cè)試集共2900張圖片,訓(xùn)練集共2900張圖片。
3.2.3 損失函數(shù)的設(shè)計(jì)
網(wǎng)絡(luò)中最后一層的輸出負(fù)責(zé)預(yù)測(cè)目標(biāo)種類的概率和范圍框的坐標(biāo)和長(zhǎng)寬。首先對(duì)范圍框的長(zhǎng)寬與圖片的長(zhǎng)寬進(jìn)行歸一化處理,使得范圍框的長(zhǎng)寬取值在0~1之間。同樣將范圍框中的坐標(biāo)通過柵格的偏移也歸一化到了0~1之間。最后一層的激活函數(shù)選擇了線性激活函數(shù),其他層使用弱矯正函數(shù)作為激活函數(shù)(式(1))。最后使用誤差平方和的方式來優(yōu)化輸出的結(jié)果。
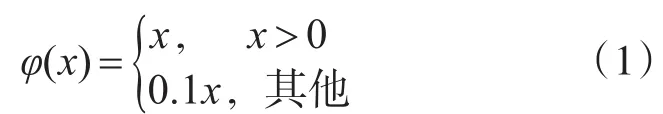
選擇誤差平方和的原因是它簡(jiǎn)單,但是用它無法達(dá)到最佳的檢測(cè)效果,因?yàn)榘逊秶虻奈恢谜`差和類別誤差放到一起優(yōu)化本身就是不合理的。而且將圖片劃分為n*n的柵格后,有些柵格里不包含任何的目標(biāo),這些置信度為0的柵格的梯度更新的范圍會(huì)非常大,這樣就會(huì)以壓倒性的優(yōu)勢(shì)覆蓋掉包含物體的柵格梯度的更新,這就會(huì)導(dǎo)致模型非常不穩(wěn)定,而且有極大可能造成網(wǎng)絡(luò)的發(fā)散。

圖5 大小范圍框敏感性曲線圖

從上式可以看出,只有當(dāng)柵格里存在待檢測(cè)目標(biāo)時(shí),才會(huì)對(duì)分類錯(cuò)誤進(jìn)行懲罰,也只有當(dāng)某個(gè)范圍框?qū)δ硞€(gè)物體檢測(cè)負(fù)責(zé)的時(shí)候,才會(huì)對(duì)范圍框的位置參數(shù)進(jìn)行懲罰。
3.2.4 其他訓(xùn)練參數(shù)的設(shè)定
1)訓(xùn)練次數(shù)的設(shè)定
原網(wǎng)絡(luò)訓(xùn)練了45000次,每次訓(xùn)練8張圖片(batch size=8)。考慮到改進(jìn)后網(wǎng)絡(luò)結(jié)構(gòu)相比于原來更加復(fù)雜,所以方案一訓(xùn)練了50000次,方案二訓(xùn)練了60000次。
2)學(xué)習(xí)率的設(shè)定
學(xué)習(xí)率是負(fù)梯度的權(quán)重。在訓(xùn)練中,學(xué)習(xí)率在開始時(shí)會(huì)選擇一個(gè)較小的值,因?yàn)槿魪妮^大的學(xué)習(xí)率開始,通常會(huì)因?yàn)槠鋷淼牟环€(wěn)定的梯度導(dǎo)致模型發(fā)散。
3)動(dòng)量(momentum)的設(shè)定
動(dòng)量是上一次更新值的權(quán)重,它能夠使得網(wǎng)絡(luò)的權(quán)值更新更加平緩,使得學(xué)習(xí)過程更為穩(wěn)定、迅速。動(dòng)量設(shè)定為0.9。
3.3 測(cè)試網(wǎng)絡(luò)結(jié)果及對(duì)比分析
搭建Caffe深度學(xué)習(xí)框架并配置好所有訓(xùn)練參數(shù)后,開始網(wǎng)絡(luò)的訓(xùn)練。本文所使用的GPU型號(hào)為GTX980ti,平均每個(gè)模型的訓(xùn)練時(shí)間約為32h。訓(xùn)練完成后,對(duì)每個(gè)模型進(jìn)行測(cè)試,得到其mAP值,然后根據(jù)mAP值來做模型的效果對(duì)比。
本文以VOC2007計(jì)算mAP為標(biāo)準(zhǔn),當(dāng)范圍框與真實(shí)值的IOU達(dá)到0.5以上,就認(rèn)為是已經(jīng)檢測(cè)出結(jié)果。表1為原YOLO與二種方案的mAP值對(duì)比。

表1 mAP值對(duì)比
由表1可看出,原YOLO在訓(xùn)練到35000次左右開始收斂,最大的mAP值能夠達(dá)到0.818167。方案一的性能明顯比原YOLO好,其mAP值最高達(dá)到了0.906555,說明方案一的改進(jìn)是有效的。方案二的mAP值最高,達(dá)到0.908375,方案二在精度上是所有方案里最高的。
雖然精度上方案二最高,但是通過FPS對(duì)比可以發(fā)現(xiàn),原YOLO的FPS能夠達(dá)到50.2,由于方案二在原來的基礎(chǔ)上添加了一層網(wǎng)絡(luò),其FPS能夠達(dá)到40.0,比原來的速度稍低,而方案二的網(wǎng)絡(luò)最為復(fù)雜,并且其中加入了反卷積,所以它的FPS只有6.2左右,這樣的速度是無法滿足實(shí)時(shí)檢測(cè)的。
通過以上分析,在滿足實(shí)時(shí)檢測(cè)速度的前提下,本文選擇了方案一中mAP值最高的模型(訓(xùn)練了47500次后的模型)作為整個(gè)井下行人檢測(cè)系統(tǒng)的最終神經(jīng)網(wǎng)絡(luò)模型。圖6、圖7為此模型與原YOLO訓(xùn)練次數(shù)為35000次在單張圖片上的檢測(cè)效果對(duì)比。

圖6 原YOLO測(cè)試結(jié)果

圖7 方案二測(cè)試結(jié)果
4 結(jié)語
本文通過結(jié)合煤礦企業(yè)井下行人檢測(cè)的需求與深度學(xué)習(xí)網(wǎng)絡(luò)的優(yōu)勢(shì),提出了一種采用深度卷積神經(jīng)網(wǎng)絡(luò)YOLO方法。本文對(duì)YOLO的網(wǎng)絡(luò)結(jié)構(gòu)和損失函數(shù)進(jìn)行了改進(jìn),雖然其檢測(cè)速度很快,但是其精度可以再提升。在后續(xù)的工作當(dāng)中,應(yīng)該將重點(diǎn)放在不損失速度的條件下,通過不斷的設(shè)計(jì)和實(shí)驗(yàn)新模型,使得其精度能夠進(jìn)一步提升。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
