Spark平臺下綜合屬性權重離群點挖掘算法研究*
2019-09-03 07:22:58劉建華
計算機與數字工程 2019年8期
關鍵詞:檢測
馬 晶 劉建華
(1.西安郵電大學 西安 710061)(2.西安郵電大學信息中心 西安 710121)
1 引言
現有的入侵檢測系統存在許多不足[1],當前面臨的主要問題:IDS主動防御能力不足、高速網絡環境的性能差[2]。將數據挖掘中離群點檢測方法運用到入侵檢測中可一定程度改善現狀。離群點檢測是用來確定小部分數據對象與剩余的大部分數據明顯不同或者不一致的問題[3]。離群點檢測除了可應用在入侵檢測系統中外,也被廣泛應用于醫療處理、信用卡詐騙、保險詐騙和內幕交易[4]、工業損毀檢測、圖像處理、傳感器/視頻網絡監視[5]。
目前,很多離群點挖掘算法被應用于入侵檢測,其中基于K-means、DBSCAN的離群點挖掘算法中聚類個數k、閾值的選取和基于Apriori的離群點挖掘算法k頻繁項集的選取直接影響到離群點的產生,需要經過大量的實驗找出合適的k值和閾值;傳統的LOF算法[6]未能考慮數據對象屬性的權重問題;主觀賦權法在根據屬性本身含義確定權重方面具有優勢,但客觀性較差;而客觀賦權法在不考慮屬性實際含義的情況下,確定權重具有優勢,但不能體現決策者對不同屬性的重視程度,有時會出現確定的權重與屬性的實際重要程度相悖的情況;文獻[7]提出基于的HLOF算法只考慮屬性的客觀權值,未考慮其主觀權值,不能有效地挖掘出離群點。
然而,隨著網絡數據的爆炸式增長,使用一個CPU節點來進行計算,很難勝任對這些海量數據的分析任務。當今行之有效的解決方案則是在云計算的分布式方法的幫助下增強計算資源的能力,利用通過網絡連接的多個節點來共同承擔對計算資源需求量較高的復雜計算[2]。目前Hadoop和Spark是兩個主流的分布式平臺,相比 MapReduce[8],Spark速度快,開發簡單,并且能同時兼顧批處理和實時數據分析[9],其中Spark streaming是Spark計算框架中來做實時流處理的模塊。因為入侵檢測系統的實時性要求,所以,選擇Spark平臺來做算法的并行化。目前在國內外,已經有很多公司在實際生產環境中廣泛使用Spark,比如國外的谷歌、亞馬遜,易貝、雅虎等公司和國內的淘寶、百度、華為、優酷、土豆等公司[10]。因此,本文提出綜合權重離群點挖掘(Comprehensive attribute weight outliermining,CAWOM)算法,并將其在Spark云計算平臺對其并行化來解決以上問題。
2 CAWOM算法
CAWOM算法首先根據層次分析法和均方差賦權法計算出數據對象屬性的綜合權重,得到數據的屬性加權距離,進而求出數據對象的偏離系數和數據集的平均偏離系數,然后對二者進行比較,最終找出離群點。
做如下規定,數據集D={X1,X2,X3,…,Xm}表示m個待檢測的數據,其中每個對象Xi由k個屬性構成,可表示為 Xi=(Xi1,Xi2,Xi3,…,Xik),每個對象 Xi各個屬性的綜合權重為(CW1,CW2,CW3,…,CWk)。
2.1 綜合權重
為了能夠兼顧每個獨立網絡環境的特殊性,使用綜合權值法來對屬性賦權。利用AHP和均方差法計算出各屬性的主觀權值和客觀權值,然后采用“乘法”集成法構造綜合權值,進而能夠綜合、全面地考慮屬性對離群系數的影響。
AHP計算屬性主觀權重:層次分析模型見圖1,其中,屬性權重為目標層,n種攻擊方式為準則層,k個屬性為方案層,通過各層次單排序權向量計算層次總排序,得出各個屬性的權值。具體步驟:根據準則層中各個攻擊方式的發生頻率構造判斷(成對比較)矩陣A,然后計算A的最大特征值λmax1及其相對應的歸一化特征向量ω(2),λmax用來計算A的一致性指標(n為準則層因素個數);將準則層中的n個因素作為方案層各個屬性的對比標準,構造n個k×k成對比較矩陣B,計算每個矩陣的最大特征值λi及其歸一化特征向量ωi,得 出 其 層 次 單 排 序 權 向 量 ω(3),,比較矩陣的一致性的判斷與準則層相同;根據層次單排序計算層次總排序,得出 k個屬性的權值。
均方差法計算屬性客觀權重:計算各個屬性集(X1i,X2i,X3i,…,Xmi),0<i≤k的標準差si,屬性的客觀權重公式:
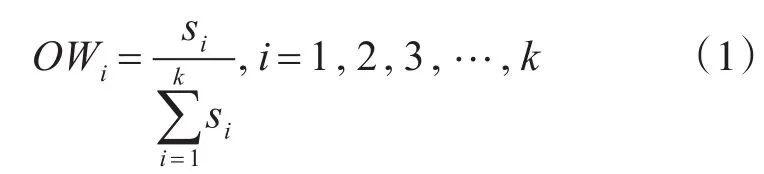
采用“乘法”集成法構造屬性的綜合權值。綜合權值公式:
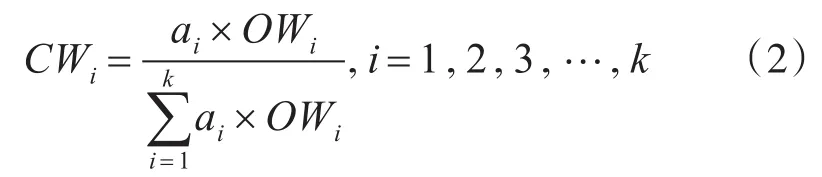
2.2 偏離系數
根據屬性的綜合權值構造數據對象Xp,Xq的加權屬性距離公式為
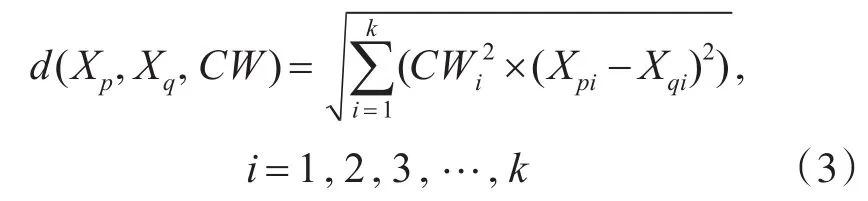
數據對象Xp的加權屬性距離公式:

偏離系數(Outlier Factor,OF),OF(Xi)計算公式:

平均偏離系數AOF(D)計算公式:

2.3 算法執行過程
根據綜合權重公式,得到各個屬性的綜合權值,然后計算數據集D中每個數據對象Xi的偏離系數OF(Xi)和平均偏離系數AOF(D),若OF(Xi)>AOF(D),則Xi為數據集D的離群數據,即離群點。具體算法如下:
輸入:對象集D={X1,X2,X3,…,Xm}為待挖掘的數據集,屬性重要程度參數()。
輸出:對象集中的離群點。
算法過程如下:
根據AHP算法確定每個屬性的主觀權重ai;
根據式(1)計算屬性的客觀權重OWi;
根據式(2)計算綜合權重CWi;
根據式(4)計算每個對象的加權屬性距離N d(Xi,CW);
根據式(5)計算每個對象的偏離系數OF(Xi);
根據式(6)計算數據集D的平均偏離系數AOF(D),將OF(Xi)>AOF(D)的對象作為離群點輸出。
3 Spark Stream ing
Spark是一套開源的、基于內存的,可運行在分布式集群上的并行計算框架[11~12]。Spark的一切都基于Spark的輸入—RDD。RDD可由外部文件存儲系統HDFS、HBase等中的數據集創建。Spark平臺擴展了5個主要的函數庫,Spark SQL、Spark Streaming、MLlib、GraphX和SparkR。
Spark Streaming[13]屬于核心 Spark API的擴展,支持實時數據流的可擴展、高吞吐、容錯的流處理。DStream(離散數據流)是Spark Streaming的基本抽象,由一組時間序列上連續的RDD來表示,可看作一個RDDS序列。Spark Streaming是將實時數據流根據固定的時間間隔劃分成DStream存儲在RDDs中,然后從DStream的轉換操作生成對RDDs的轉換操作,執行產生的中間結果可以存儲在內存中以進行迭代操作。圖2是基于DStream實現的Spark Streaming模型。
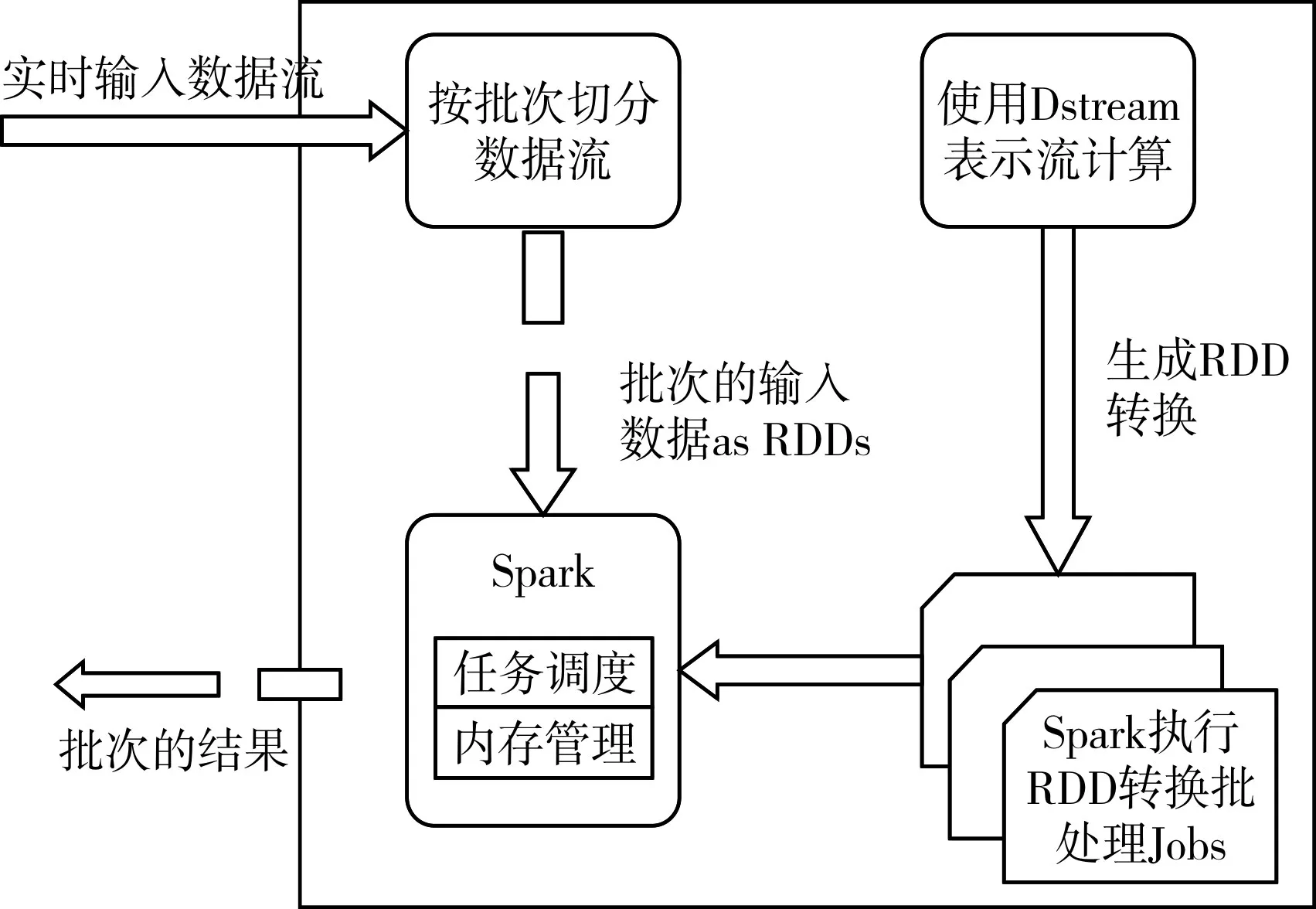
圖2 基于DStream實現的Spark Streaming模型
4 Spark平臺并行化CAWOM算法
4.1 S-CAWOM算法
S-CAWOM算法是CAWOM算法在Spark平臺的實現。算法首先將數據按照1s的時間間隔分配到各個子節點,在各個子節點上根據CAWOM算法計算對象的離群系數OF(Xi)及數據集Di的平均離群系數AOF(Di);將各個子節點的離群點匯總,比較 OF(Xi)與數據集D的平均偏離系數AOF(D)(AOF(D)為各個子節點的AOF(Di)的平均值),找出離群點。圖3是Spark平臺下算法的并行化流程圖。

圖3 并行算法流程圖
S-CAWOM算法的執行過程:
1)集群從分布式文件系統HDFS上讀取數據,以1秒為時間間隔,生成DStream;
2)通過flatMap()方法將數據格式化為向量;
3)通過map()方法將根據CAWOM算法計算出每個節點的OF(Xi)與之前節點向量連接組成新的向量;
4)通過reduce()方法計算各個集群的離群系數 AOFi,然后通過filter()、union()方法得出初始離群點集O';
5)通過reduce()方法得到平均離群系數AOF,然后通過filter()方法得出離群點集O。
4.2 算法偽代碼
Input:存放數據對象集地址HDFS_path,Spark集群地址master_address,屬性重要程度值向量P(pi),0<i≤k,其中k為屬性維數。

5 實驗結果與分析
5.1 實驗環境
在2臺主機上安裝Red Hat Linux7.2操作系統,在每臺主機上分別創建3臺虛擬機。將主機1作為Master節點,主機2和其余6個虛擬機作為Slave節點,每個節點的配置信息均為Internet Core i7 2.7GHz CPU,2GB內存,50GB硬盤。采用CDH平臺集成搭建Spark集群。
實驗數據采用KDD CUP99數據集,主要包含DoS、Probe、U2R和R2L 4種攻擊。數據集為CVS格式,大小約為708MB,包含490萬個連接,每個連接占一行,包含38個屬性特征[14]。其中的類別型特征屬性采用One-hot編碼處理,Protocal-type的處理如表1,其余的類別型屬性參考Protocal-type的處理。對于連續型屬性參考文獻[15]中的Imp-Chi2算法處理。

表1 Protecal-type處理表
5.2 實驗方法及結果分析
在計算主觀權重時,選取KDD CUP99 10%數據集中的攻擊比例作為AHP模型準則層的參考。在spark平臺將存儲在分布式文件系統HDFS上的數據集按照S-CAWOM算法進行離群檢測,找出其離群點集,算法進行性能評價時,選取檢測率、誤檢率和算法執行時間3個性能指標與文獻[16]中的ACPO、EOS算法進行比較,表2為檢測性能對比表。

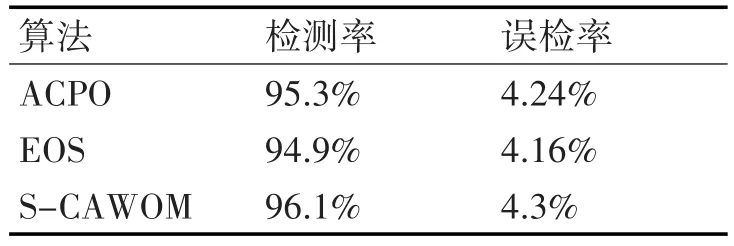
表2 檢測率對比表
由表2可以看出,S-CAWOM算法的檢測效率高于ACPO和EOS算法,但誤檢率稍高于ACPO和EOS算法。
為了驗證算法的執行效率,在KDD CUP99數據集抽取10000、20000、50000、100000條鏈接進行驗證,比較三種算法的算法運行時間。圖4為三種算法分別在10000、20000、50000、100000條鏈接的運行時間折線圖。
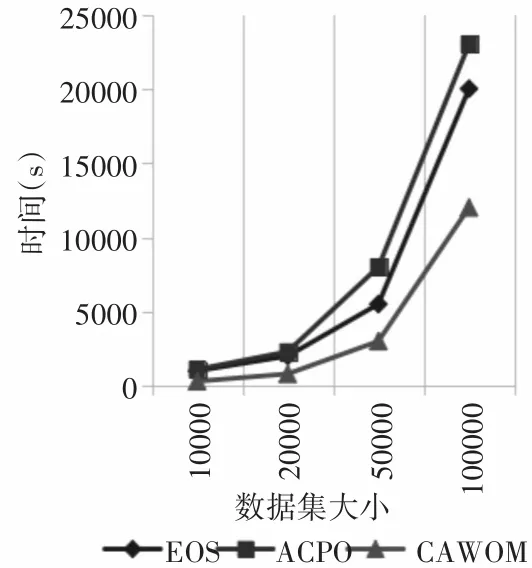
圖4 算法運行時間
根據圖4可發現,在當數據集在變化時,S-CAWOM算法的運行時間都是最少的。從整個趨勢來看,當數據集較小時,各算法的運行時間相差較小,當數據集逐漸增大時,各算法執行時間增長較快,效率減小。
6 結語
本文研究Spark平臺下綜合屬性權重離群點挖掘的問題,由于很多研究都未考慮屬性的綜合權重,只是從客觀屬性單方面進行研究,使得離群點的檢測效率不高。本文在Spark Streaming框架的基礎上,提出了綜合屬性權重離群點挖掘算法S-CAWOM。實驗證明,該算法的執行效率高,檢測性能良好。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
