半自動構建扶貧領域知識圖譜工具的研究*
2019-09-03 07:22:46云紅艷張秀華
計算機與數(shù)字工程 2019年8期
胡 歡 云紅艷 賀 英 張秀華
(1.青島大學計算機科學技術學院 青島 266071)(2.青島大學電子信息學院 青島 266071)
1 引言
進入21世紀,隨著互聯(lián)網的蓬勃發(fā)展以及知識的爆炸式增長,搜索引擎被廣泛使用。但面對互聯(lián)網上不斷增加的海量信息,僅包含網頁和網頁之間鏈接的傳統(tǒng)文檔萬維網已經不能滿足人們迅速獲取所需信息的需求[1]。人們期望以更加智能的方式組織互聯(lián)網上的資源,期望可以更加快速、準確、智能地獲取到自己需要的信息。為了滿足這種需求,知識圖譜應運而生[2]。當然,知識圖譜并非是一個全新的領域,早在2006年,萬維網之父Berners-Lee就提出了鏈接數(shù)據的思想,人們可以將開放鏈接數(shù)據(linked open data)項目中去,通過將不同資源以URL來標識,來實現(xiàn)數(shù)據的無縫互聯(lián)和知識融合。
2 研究問題
近些年,學者在各個角度對扶貧領域做了研究。如從文化扶貧視角、金融扶貧視角、游扶貧視角、精準扶貧視角等對扶貧領域的研究成果進行了梳理。但是,上述研究的內容都是從比較單一的角度對文獻回顧[3]。知識圖譜能夠有效地組織多源數(shù)據源,將其內部隱含的單層乃至多層關系,通過目前較為流行的圖數(shù)據庫,展現(xiàn)在網頁端。使知識更加凝聚,內容更加明顯,有利于整合資源、查看資源、獲取資源。本文基于重慶的貧困數(shù)據源,構建一套半自動化生成知識圖譜以及查詢知識圖譜的工具。
由于手工構建知識圖譜的不便和自動構建圖譜的不可實現(xiàn)性。本文基于重慶貧困數(shù)據源,構建一套半自動化生成知識圖譜以及查詢知識圖譜的工具。完成的功能包括導入數(shù)據、語義映射、查看圖譜。導入數(shù)據功能模塊解析關系數(shù)據庫中的數(shù)據源轉化為csv文件,且自動生成圖數(shù)據庫Neo4j中生成圖節(jié)點的LOAD語句。語義映射功能模塊通過語義映射算法,得到關系數(shù)據庫中表與表之間存在的關系,用于自動生成在圖數(shù)據庫Neo4j中生成關系節(jié)點的MATCH語句。查看圖譜功能模塊中,首先,將存儲在Neo4j中的關系圖用Echarts組件顯示在前端界面;其次,用戶輸入關系或人物關鍵字,通過Echarts組件將計算封裝的數(shù)據顯示成對應的知識圖譜。
3 結構及框架設計
3.1 總體結構設計
系統(tǒng)的整體框架(如圖1所示)遵循三層架構的設計思想,從下到上依次為數(shù)據層、業(yè)務層、表現(xiàn)層,按照“強內聚,弱耦合”的思想將業(yè)務領域進行劃分。數(shù)據層主要將關系數(shù)據庫中數(shù)據源,自動生成LOAD語句導入圖數(shù)據庫Neo4j中;獲取關系數(shù)據庫中的表名以及字段名,解析構建的OWL文件,自動生成MATCH語句導入圖數(shù)據庫Neo4j中,為上層的業(yè)務邏輯提供數(shù)據來源。業(yè)務層是連接表現(xiàn)層與數(shù)據查詢層的橋梁,它主要是面向功能服務的,根據業(yè)務的需求進行數(shù)據的封裝、處理和分析等。表現(xiàn)層主要是面向用戶提供可視化的界面,負責收集用戶的請求數(shù)據和對系統(tǒng)的返回數(shù)據進行前端渲染。

圖1 系統(tǒng)設計框架
系統(tǒng)整體采用B/S結構,后端采用Spring Boot框架構建微服務,提供RESTful接口。前端采用HTML5和Echarts相關技術構建可視化界面,數(shù)據庫采用Neo4j圖數(shù)據庫和MySQL關系數(shù)據庫。數(shù)據層主要采用Spring Data模塊操作Neo4j圖數(shù)據庫,javaCSV API或SQL語句操作MYSQL關系數(shù)據庫,自動生成LOAD語句導入Neo4j圖數(shù)據庫,jena API解析OWL文件在與關系數(shù)據庫創(chuàng)建關系,自動生成MATCH語句導入Neo4j圖數(shù)據庫中。業(yè)務層主要進行的是數(shù)據的處理,通過調用數(shù)據層對返回的數(shù)據進一步封裝,完成數(shù)據的統(tǒng)計分析和格式規(guī)范。根據需要完成的相關功能進行業(yè)務邏輯的編寫,并將封裝后的數(shù)據傳遞給表現(xiàn)層,數(shù)據交換格式采用JSON。表現(xiàn)層將接收到數(shù)據傳遞給前端進行渲染,利用Echarts組件和HTML5實現(xiàn)查看圖譜、圖譜檢索功能。
3.2 功能設計框架
本文設計了半自動化生成知識圖譜工具,其功能設計框架(如圖2所示)該圖譜系統(tǒng)主要包含三個功能模塊:導入數(shù)據、語義映射、查看圖譜。
第一個模塊是導入數(shù)據。首先,將關系數(shù)據庫的數(shù)據庫表轉為csv文件,在用文件上傳函數(shù)接口上傳到Neo4j中的import文件夾中。其次,自動生成導入圖數(shù)據庫Neo4j生成圖節(jié)點的LOAD語句。最后,在將生成的LOAD語句導入Neo4j圖數(shù)據庫,生成圖節(jié)點。
第二個模塊是語義映射。首先,對MySQL關系數(shù)據庫進行解析,獲取數(shù)據庫表名和字段名。其后,解析構建扶貧領域的OWL文件,利用Jena API解析構建的本體文件,獲取其類名以及類與類之間的關系屬性。再者,人工確定多張數(shù)據庫表名,在勾選與其對應的本體中的類名,再通過語義映射算法,映射出結果,其為選中的數(shù)據庫表之間存在的關系。然后,自動生成導入圖數(shù)據庫Neo4j生成關系節(jié)點的MATCH語句。最后,在將生成的MATCH語句導入Neo4j圖數(shù)據庫,生成關系節(jié)點。

圖2 功能設計框架
第三個模塊是查看圖譜。針對本工具知識圖譜的可視化方面,采用ECharts組件可以實現(xiàn)力導向布局圖,描述知識圖譜中幫扶人與貧困戶之間的關聯(lián)情況。在圖譜檢索中,實現(xiàn)按人物查詢、按關系查詢。如幫扶人與貧困戶之間關系查詢。首先,發(fā)送查詢請求;解析請求參數(shù)。其次,調用數(shù)據查詢層,發(fā)送最短路徑請求給圖數(shù)據庫。然后,Neo4j圖數(shù)據庫返回數(shù)據,計算并封裝數(shù)據。最后,Echarts組件進行渲染。
4 功能實現(xiàn)介紹
4.1 導入數(shù)據
Neo4j是由Neo Technology開發(fā)的開源圖數(shù)據庫,它是當前主流的圖數(shù)據庫之一,具有高性能、高可抗性、可擴展、支持事務等特點。知識圖譜本質是一個圖結構,其表現(xiàn)形式主要分為兩種:RDF圖和屬性圖[4~8]。RDF圖是W 3C官方推薦的語義表示的模型,是用來描述資源以及其關系的三元組的集合,是語義網技術棧中的基石。屬性圖是由節(jié)點、關系和屬性三要素構成的圖譜,通過這三個元素可以完成任何描述。針對數(shù)據間關系的復雜性和動態(tài)變化等問題,考慮到后期知識圖譜的擴展和維護,本文采用Neo4j圖數(shù)據庫對知識圖譜進行持久化存儲。Neo4j圖數(shù)據庫具有強性能、易擴展、支持事務、后臺可視化等特點,能夠有效地組織、存儲和更新動態(tài)數(shù)據及其關聯(lián),并提供給高效的遍歷算法支持多層復雜查詢,在知識存儲和知識表現(xiàn)方面具有重要作用。
實現(xiàn)導入數(shù)據功能。首些,需要將重慶扶貧數(shù)據源生成csv文件。本文中,提供兩套方法。第一種方法通過javaCSV API(如表1所示)。

表1 生成csv文件主要方法
第二種方法通過SQL語句生成CSV文件,如使用如下SQL語句將家庭表(jiating)生成csv文件。
SELECT*FROM(SELECT‘表頭名’union all select*from jiating)jiatingINTOOUTFILE‘D:\cypher\import\jiating.csv’FIELDSTERMINATED BY‘,’OPTIONALLY ENCLOSED BY‘"’ LINES TERMINATED BY‘ ’.)
其次,將生成的csv文件上傳到Neo4j的import文件夾中。采用Apache開源的common-fileupload.jar和common-io.jar實現(xiàn)多文件上傳,上傳文件用到的主要方法(如表2所示)。

表2 上傳csv文件主要方法
自動生成LOAD語句的核心代碼如(LOADCSVWITHEADERSROM “file:///pkh_helpperson.csv”AS row CREATE(n:HelpPerson)SET n=row)。最后,將生成的LOAD語句導入圖數(shù)據庫Neo4j中。
4.2 語義映射
實現(xiàn)語義映射功能。首先,需要解析MySQL關系數(shù)據庫中的數(shù)據庫表名以及字段名。Java操作Mysql的驅動主要為ODBC和JDBC,本文所采用的是JDBC驅動。由工具的環(huán)境是基于SpringBoot微服務,可在程序包中的pom.xm l文件中配置mysql-connector-java,配置版本為5.1.6。配置好驅動,利用 SQL 查詢語句:(stmt.executeQuery(“se-lect*from”+“”+tableName);stm t.executeQuery(“select*from”+“ ”+tableName))解析據庫的表名以及字段名。其次,解析構建的本體。本體作為領域概念模型的建模工具,形式化的描述領域內的概念及概念之間的關系,是領域知識共同理解的基礎,是知識圖譜中重要的組成部分。使用本體對數(shù)據集進行描述,可以解決知識圖譜構建過程中數(shù)據集成遇到的語義異構問題。在本文中,我們將以本體扶貧數(shù)據源為基礎,描述本體構建的相關過程。本體描述語言可以清晰地對領域內概念與概念間的關系進行規(guī)范的描述,具備以下特點:明確的語法、豐富的表達能力、對推理的支持、便捷表述。目前主流的本體語言包括XML、RDF(S)、OWL等。
對本文要研究的領域概念進行抽取,主要抽取出類、對象屬性、數(shù)據屬性。結合領域中概念與概念之間的關系,本文抽取的部分三元組如{幫扶人幫扶項目 貧困戶}、{貧困戶家庭信息家庭成員}。確定了概念與概念之間的關系之后,利用Python第三方庫pygraph繪制出扶貧本體的RDF圖(如圖3所示)。其中類與類之間的對象屬性用實心箭頭的實線標識,類的數(shù)據屬性使用實心箭頭的虛線標識。

圖3 扶貧領域本體
本文構建的OWL文件類有Helper、PoorHouseholds、GovHelp、Family;對 象 屬 性 有 has_helper、has_govhelp、has_family。由于本體文件中的類與對象屬性為語義映射的輸入,則需要對本體文件作進一步的解析。本文采用Jena API,主要方法(如表3所示)。

表3 jena解析本體主要用到的方法
解析出了數(shù)據庫中的表名、字段名以及本體中的類名以及類與類之間的關系屬性。如算法1所示,人工確定多張數(shù)據庫表名,在勾選與其對應的本體中的類名。再將對應的數(shù)據通過AJAX傳入后臺。由于類與類之間存在著確定的關系。依次判斷,若存在相關類,則將解析出來的對象屬性傳遞給結果集,作為數(shù)據庫表與表之間的關系。若不存相關類,需要人工自定義選中表的關系。
算法1語義映射

得出語義映射[15~16]結果,組織生成導入圖數(shù)據庫Neo4j生成關系節(jié)點的MATCH語句(如MATCH(b:BasicInfo),(g:GovHelp),(b1:BangFuXiangMu)WHERE b.id= g.huzhu_id AND g.xiangmumingcheng=b1.xiangmumingchengCREATE (b1) [:BangFuXiangMu{fuchinianfen:g.fuchinianfen,jiansheneirong:g.jiansheneirong}]->(b))。 最 后 ,將MATCH語句導入圖數(shù)據庫Neo4j生成關系節(jié)點。
4.3 查看圖譜
實現(xiàn)查看圖譜功能。主要是采用Echarts控件來實現(xiàn)圖譜的查看與檢索。ECharts是百度開源的純JavaScript圖表庫。目前,百度的ECharts項目已經進入國際頂級開源社區(qū)Apache孵化器,ECharts具有豐富的可視化圖表類型和深度交互能力的開源可視化庫,配置便捷并且支持靈活的定制功能,具備高達千萬級數(shù)據的可視化能力[9~14]。Echarts控件生成圖譜流程大致如表4所示。
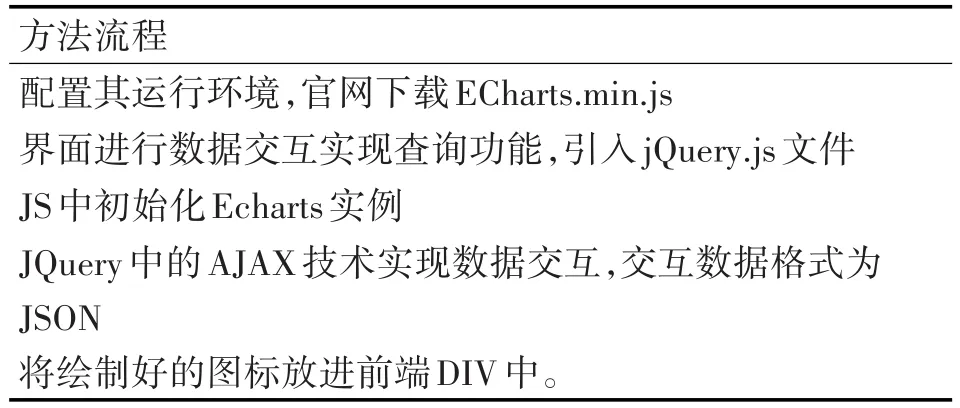
表4 Echarts控件生成圖譜流程
圖譜檢索中,按關系查詢,用戶通過輸入框指定需要查詢的兩個人名稱,如果存在關系,則展示兩個人之間存在的最短路徑關系圖譜,通過不同顏色的節(jié)點標識不同的實體類型,通過邊的文字顯示與方向標識不同的關系類型。如果不存在關系,則顯示兩個孤立的節(jié)點。幫扶人與貧困戶之間關系圖譜的查詢過程如圖4所示。

圖4 關系圖譜的查詢過程
用戶指定需要查詢的兩個人名并向服務端發(fā)起請求,服務端的業(yè)務邏輯層接收參數(shù)后進行校驗和解析,校驗通過后調用數(shù)據查詢層的方法傳入實參。利用Neo4j圖數(shù)據庫最短路徑函數(shù)shortestPath()對兩法人之間的路徑進行查詢并返回結果集。針對結果集解析和加工。封裝成特定格式的JSON數(shù)據傳遞給ECharts組件進行渲染,最終以圖譜方式展現(xiàn)。
5 結語
本文基于重慶的貧困數(shù)據源,構建一套半自動化生成知識圖譜以及查詢知識圖譜的工具。首先,將存儲在關系數(shù)據庫中的結構化數(shù)據構建出扶貧領域本體,以及將結構化數(shù)據通過半自動化工具導入圖數(shù)據庫Neo4j中生成圖節(jié)點。再者,本文提出語義映射算法,將解析的OWL文件中類與對象屬性與查詢的結構化數(shù)據表名之間映射出關系,再通過半自動化工具導入圖數(shù)據庫Neo4j生成關系節(jié)點。最后,用戶可輸入人物或關系關鍵字,通過Echart組件,將存儲在Neo4j圖數(shù)據庫中的數(shù)據展現(xiàn)在用戶界面,實現(xiàn)查看圖譜和圖譜檢索功能。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
