降低車道偏離預警系統誤報率方法研究*
2019-09-03 07:22:36妮山
計算機與數字工程 2019年8期
關鍵詞:模型
孟 妮山 巖
(1.陜西工業職業技術學院 咸陽 712000)(2.長安大學汽車學院 西安 710064)
1 引言
車道偏離預警系統(Lane Departure Warning System,LDWS)目的是幫助駕駛人使車輛保持在車道內行駛,在車輛偏離車道時發出警告。通常車道偏離預警系統通過圖像識別技術采集車道線位置,通過識別車輛與車道線的距離關系判斷車輛是否發生偏離。車道偏離預警系統對于預防因為駕駛人分心或疲勞引起的無意識車道偏離具有良好的效果。但是許多駕駛人在換道過程中不開啟轉向信號燈,這導致車道偏離預警系統無法有效地區分駕駛人換道和無意識車道偏離行為,進而導致車道偏離系統在車輛換道時產生誤報。誤報率偏高會對駕駛人的正常行駛構成干擾,進而迫使駕駛人關閉車道偏離預警系統。
因為駕駛人換道過程中不開啟轉向燈現象普遍,國內外針對換道識別進行了大量研究,其中具有代表性的有:C.Jeol等利用車輛橫向運動和頭部姿態數據建立了基于稀疏貝葉斯方法換道識別系統[1]。Oliver等通過在換道模型中加入駕駛人眼動數據改善了模型換道識別效果[2]。Kuge等利用方向盤轉角向量值、方向盤轉動角速度和方向盤轉矩作為輸入,建立了基于隱馬爾科夫理論的換道意圖識別模型[3]。吉林大學侯海晶基于隱馬爾科夫理論建立了高速公路上不同類型駕駛人的換道意圖識別模型[4]。清華大學王玉海根據駕駛人的換擋行為特征對駕駛人換道行為進行識別[5]。Doshi等利用車輛運動狀態、駕駛人眼動參數和周圍車輛運動參數,建立了基于相關向量機的駕駛人換道預測模型[6]。
當前的研究只是集中于辨識車道變換與車道保持,將駕駛人無意識車道偏離簡單地劃分到車道保持當中去,但是駕駛人無意識車道偏離與換道具有較大的相似性,容易被誤識別為換道行為[7]。為此本文基于支持向量機理論著重研究駕駛人無意識車道偏離與換道行為的辨識。
2 模型建立
2.1 SVM理論
支持向量機(Support Vector Machine,SVM)是常用的模式分類方法。SVM的主要目的是通過尋找一個分類超平面作為模型的決策曲面,使得不同類別之間的隔離邊緣距離最大化[8]。支持向量機屬于通過特征空間里區域特性來分割不同類別的判別式模型。
SVM模型中最常見的是二分類SVM模型,本文也是采用二分類SVM模型區分駕駛人無意識車道偏離與換道行為。其具體計算過程如下。
1)建立已知訓練集:

其中xi表示特征向量,yi表示分類標簽,本文中換道標簽為0,無意識車道變換標簽為1。
2)選擇合適的核函數K和適當參數C用來求解最優化問題:
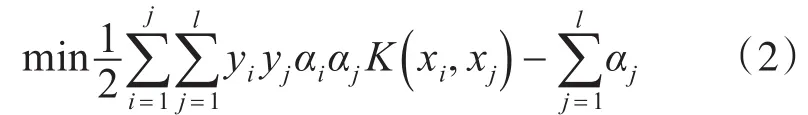


4)決策函數的構建:

2.2 表征參數獲取
本文通過實車試驗分別采集了車輛在換道和無意識車道偏離狀態下的運動數據,考慮到實驗過程中具有一定風險性,本文選取在試驗場內完成實車試驗。相關研究表明分心是造成駕駛人無意識車道偏離的主要因素之一,在駕駛人正常駕駛過程中,通過讓駕駛人處于分心狀態來使駕駛人出現無意識車道偏離的現象。本文中共選取了12名駕駛人。其中駕駛人的平均年齡為35歲,平均駕齡為5年,健康狀態良好。為保證實驗結果的客觀性,事前并沒有告知駕駛人實驗目的。
通過在試驗車輛上安裝方向盤傳感器、車道線識別系統、GPS和陀螺儀等。可以采集車輛行駛過程中的方向盤轉角、方向盤轉動角速度、方向盤轉動力矩、車速、橫向位移、橫擺角速度和橫向速度等參數。參考相關研究成果以及結合自身研究特點,選擇方向盤轉角、橫向速度、橫向距離作為模型的辨識參數[9]。
1)方向盤轉角θ:方向盤轉角能夠直接體現駕駛人對于車輛運動方向的控制意圖,在車輛換道過程中方向盤轉角會表現出明顯的波動變化。但是在車輛經過彎道時,無意識車道偏離與換道的方向盤轉角變化類似,僅依靠方向盤轉角難以區分兩者區別。
2)橫向距離d:本文中橫向距離表示車輛距離車道中心線的距離,橫向距離可以直接體現車輛在道路中的橫向位置變化。
3)橫向速度v:橫向速度能夠表現車輛的橫向變化趨勢,車輛在換道時其橫向速度普遍高于無意識車道偏移。
2.3 擴展卡爾曼濾波
傳感器在實際測量過程中會受到環境等因素的影響而在數據中夾雜有隨機噪聲,同時在數據采集過程中受到傳感器精度的影響產生數據不連續的現象。為了最大限度地消除隨機噪聲并使數據連續化,本文采用了擴展卡爾曼濾波器對獲取的數據進行濾波。傳統的卡爾曼濾波器利用線性高斯模型對目標狀態做最優估計,但這僅僅局限于線性問題或者近似線性問題的非線性問題[10]。車輛的車道偏離識別與相應的方向盤轉角、橫向速度、橫向距離參數是一種復雜的非線性映射關系,為了能夠精確地估計目標狀態,必須建立合適的非線性濾波器算法。
對于復雜的非線性問題,擴展卡爾曼濾波器采用線性變換將問題轉化成近似線性濾波器的問題。擴展卡爾曼濾波器的原理是圍繞濾波值對非線性函數展開成泰勒級數,通過去除二階以上項可以得到線性化模型,利用卡爾曼濾波器完成對數據的濾波處理。通過Matlab軟件中的卡爾曼濾波工具箱對方向盤轉角、橫向速度、橫向距離進行擴展卡爾曼濾波處理結果如圖1、圖2和圖3所示。

圖1 方向盤轉角濾波結果

圖2 橫向速度濾波結果

圖3 橫向距離濾波結果
2.4 歸一化處理
方向盤轉角的變換范圍通常在-60°~60°之間,橫向位移的變換范圍在-200cm~200cm之間,橫向速度的變化范圍在-6m/s~6m/s之間。方向盤轉角、橫向速度、橫向距離的單位不同,其變化范圍也不同,橫向位移的變換范圍明顯大于方向盤轉角和橫向速度[11]。若是不作處理直接輸入到SVM模型當中,橫向位移的變化趨勢就會一定程度的掩蓋方向盤轉角和橫向速度的變化趨勢。因此在建立模型前需要對輸入數據進行歸一化處理。將所有的數據都轉化到[0,1]范圍之內,歸一化處理公式如下:

其中,xmin表示數據當中最小值,xmax表示數據當中最大值。
方向盤轉角原始數據:7.438,7.438,7.438,7.438,7.438,5.95,5.95,5.95,5.95,8.925,8.925,7.438,7.438,7.438。
方向盤轉角歸一化后數據:0.5,0.5,0.5,0.5,0.5,0,0,0,0,1,1,0.5,0.5,0.5。
橫向距離原始數據:-1.445,-1.511,-1.578,-1.632,-1.691,-1.696,-1.624,-1.553,-1.444,-1.337,-1.299,-1.316,-1.379,-1.463,-1.539。
橫向距離歸一化后數據:0.632,0.465,0.297,0.161,0.012,0,0.181,0.360,0.634,0.904,1,0.957,0.798,0.586,0.395。
橫向速度原始數據:-0.541,-0.629,-0.551,-0.432,-0.272, 0.053,-0.461, 0.527, 0.521,0.447,0.064,-0.832,-1.071,-0.783,-0.630。
橫向速度歸一化后數據:0.331,0.276,0.325,0.399,0.5,0.703,0.381,1,0.996,0.949,0.71,0.149,0,0.18,0.275。
2.5 K均值聚類
本文中傳感器采集方向盤轉角、橫向速度、橫向距離參數數據的采樣頻率為10Hz,在1s中就會產生30個數據值,但是這些數據當中信息大部分是重疊的,直接輸入模型會增加模型的計算量,同時大量重疊信息有可能會導致模型出現過擬合現象。為了提高數據質量,選擇具有代表性的數據同時去除冗余數據,選擇K均值聚類法對輸入數據進行優化。
首先選取k個數據點作為初始聚類點,計算剩余數據點與初始聚類點之間的距離,將它們分配到最近的聚類當中。之后不斷進行迭代,每次對聚類的數據點求平均值,計算新的聚類中心。重新計算數據點與聚類中心的距離,若數據點距新聚類中心的距離小于上次聚類的距離,就將該數據點移至新的聚類當中。這個過程反復進行直到滿足收斂條件為止。
選取了換道時1s之內的數據為例進行K均值聚類,其中具體數據如表1所示。
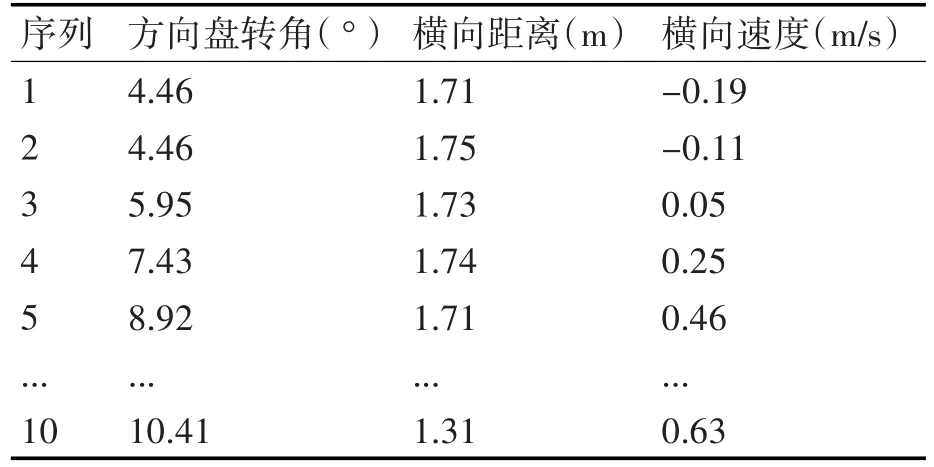
表1 輸入表征參數數據
利用K均值聚類法將方向盤轉角、橫向速度、橫向距離參數數據分為三類。因為輸入的表征參數都是按照一定規律漸變的,在選取初始聚類中心時分別選取了序列為3、6和9的數據作為初始聚類中心,如表2所示。

表2 初始聚類中心
利用Matlab軟件中kmeans函數對數據進行K均值聚類后得到的新聚類中心如表3所示。

表3 最終聚類中心
將最終的聚類中心作為輸入樣本。通過對原始數據進行精簡,在去除冗余信息的同時保留了關鍵信息。
3 模型訓練與測試
從試驗數據中挑選出換道和無意識車道偏離樣本數據共738組,其中換道包括417組數據,占總樣本的56.5%。無意識車道偏離包括321組數據,占總樣本的43.5%。從417組換道樣本中隨機挑選了367組樣本用于SVM模型訓練,剩余500組換道樣本用于測試。同樣從321組無意識車道偏離樣本中隨機選取271組樣本用于SVM模型訓練,剩余50組換道樣本用于測試。
3.1 最優時間窗口選取
時間窗口的大小控制著輸入SVM模型中的信息量的多少,輸入信息量太少,模型不能夠做出有效的識別。輸入信息量太多,可能會同時輸入不同運動狀態的信息也會影響模型識別準確率。時間窗口的選取對于SVM模型的識別準確率與識別效率有重要的影響。對采集到的417組換道樣本的換道時間進行統計可知,換道時間大部分集中于3s~14s之間,平均換道時間為7s。對321組無意識車道偏離樣本的持續時間進行統計可知,無意識車道偏離的持續時間主要集中于2s~7s之間,平均無意識車道偏離持續時間為4.7s。為了能夠有效地識別無意識車道偏離,時間窗口長度就需要小于平均無意識車道偏離持續時間,這樣才能保證模型能夠有效快速地識別大部分的無意識車道偏離行為[12]。因此選擇時間窗口寬度在0.5s~5.0s范圍之內,以0.5s為時間間隔,分別計算了不同時間窗口下模型的識別準確率。

表4 不同時間窗口下SVM識別率
由表4可知,SVM總體識別準確率是隨著時間窗口的增加先增加后減小的,其中SVM模型對于換道識別的準確率要普遍高于對于無意識車道偏離的識別率。在時間窗口為3.5s時,總體識別率達到最高為83%。但是當前SVM的識別準確率難以滿足LDWS系統的要求。
3.2 粒子群優化算法
粒子群優化算法(PSO)是一種群體智能優化算法。PSO算法受到生物種群行為的啟發并將其運用到尋找最優化的問題上。PSO算法當中每一個粒子代表了SVM模型中一組可能最優參數。選擇SVM模型的誤差值作為適應度函數,每一個粒子的適應度值由適應度函數決定,粒子適應度的大小決定了該粒子品質的優劣。粒子的速度表示了粒子在PSO算法當中的移動距離和方向。速度跟隨其自身以及周圍粒子的經驗進行動態調整[13]。通過速度、位置和適應度指標來表示粒子特征。粒子在參數空間運動過程中,利用群體極值Gbest和個體極值Pbest不斷更新粒子位置,群體極值表示所有粒子尋找到適應度最優的坐標,個體極值表示個體搜尋過程中得到的適應度最優的坐標[14]。粒子位置每變更一次,對于適應度、群體極值和個體極值都需要重新更新[15]。最終獲取空間內的SVM最優化參數。其中PSO算法優化SVM模型的流程如圖4所示。
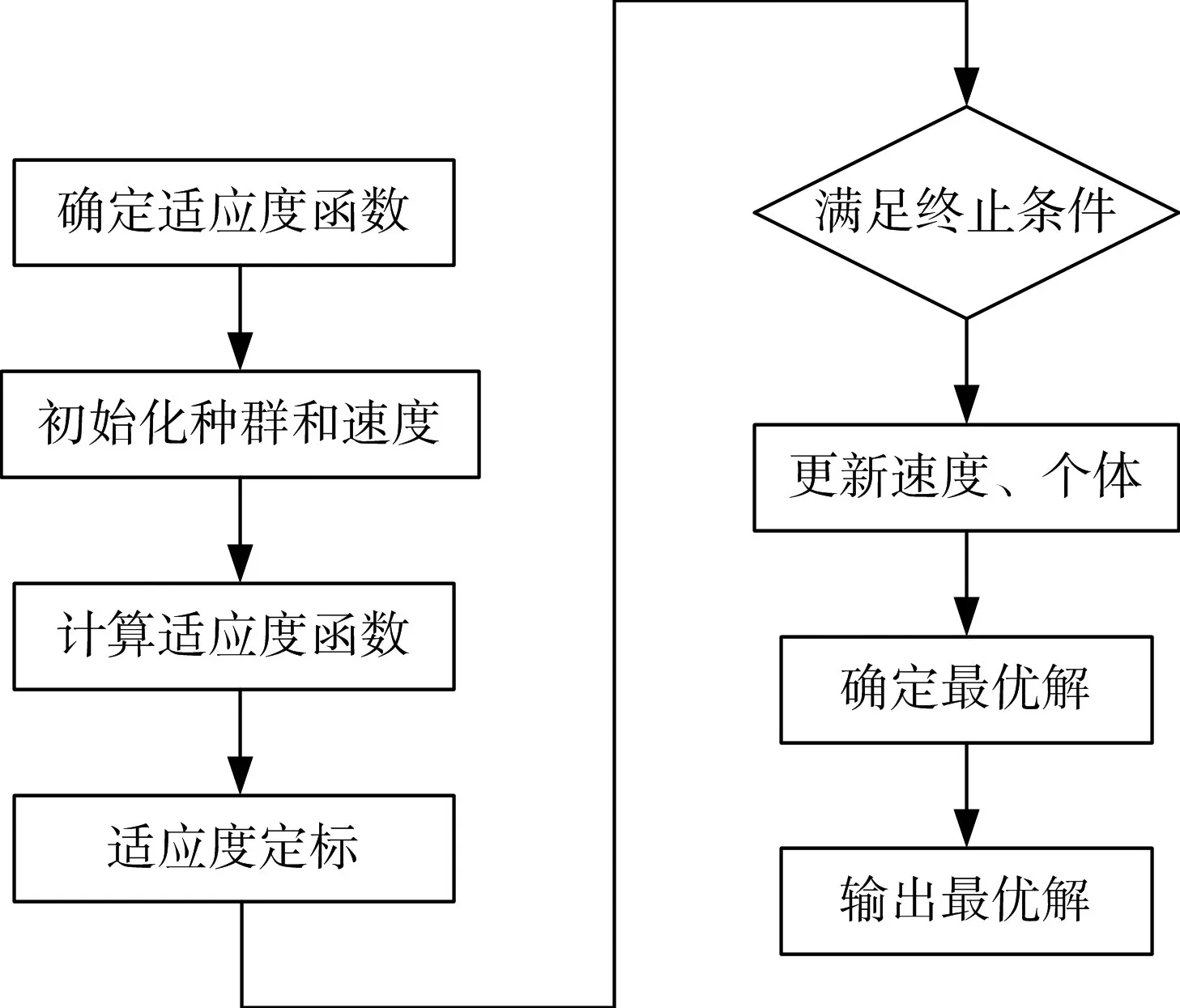
圖4 PSO算法優化SVM模型流程圖
SVM模型參數經過PSO算法優化后,計算出了SVM算法在不同時間窗口下對于換道和無意識車道偏離的識別準確率。
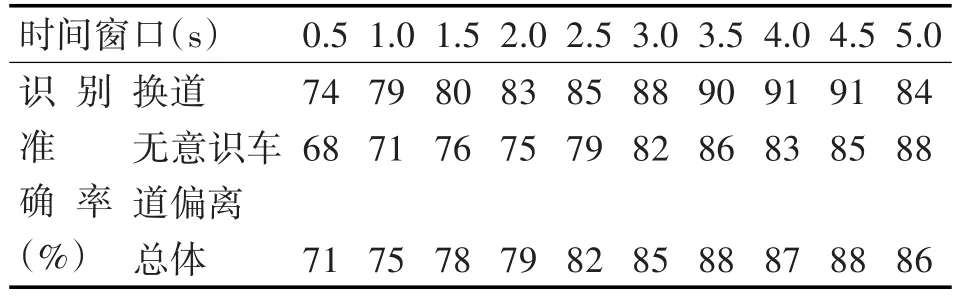
表5 優化后不同時間窗口下SVM識別率
由表5可知,經過粒子群優化算法優化后,SVM模型的識別準確率有明顯的提升。在時間窗口為3.5s時,SVM模型具有最高的識別準確率88%,其中換道識別準確率為90%,無意識車道偏離的識別準確率為86%,能夠滿足LDWS系統的要求。
4 結語
因為車道偏離系統會混淆無意識車道偏離與換道行為,對換道行為進行有效識別可以降低車道偏離預警系統的誤報率。本文通過實車試驗分別采集了駕駛人在換道和無意識車道偏離時的方向盤轉角、橫向位移和橫向速度等數據。并通過擴展卡爾曼濾波、歸一化和K均值聚類方對數據進行預處理。建立了基于支持向量機的車道偏離識別模型。為了進一步提高支持向量機對于車道偏離的識別準確率,采用粒子群算法對支持向量機參數進行優化。在時間窗口為3.5s時,支持向量機的總體識別率可以達到88%,降低了車道偏離預警系統的誤報率,減少了因為系統誤報對駕駛人造成的干擾。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
