基于殘差網絡的學生課堂行為識別
2019-08-20 07:26:30蔣沁沂張譯文譚思琪楊耀祖
現代計算機 2019年20期
蔣沁沂,張譯文,譚思琪,楊耀祖
(四川農業大學理學院,雅安625000)
0 引言
課堂是學生學習知識、接受教育的重要場所。隨著社會技術的不斷發展,教育改革的不斷深入,對課堂教學質量進行信息化、智能化分析的要求越來越急迫。用信息化手段對課堂中學生的行為進行實時的觀測、處理和分析,不僅可以提醒學生注意規范自己在課堂上的行為,幫助教師管理課堂,也可以反映出課堂氛圍好壞,幫助教師改進教學方式。
目前專門研究學生課堂行為識別的論文較少。周鵬霄等人[1]通過人臉檢測、輪廓檢測、主體動作幅度檢測得到數據集,將貝葉斯因果網作為判定主體行為特征的推理模型對課堂教學行為進行識別。黨冬利[2]則通過提取動作的Zernike 矩特征、光流特征、全局運動方向特征并結合樸素貝葉斯分類器[3]來對動作進行描述和判斷。張鴻宇[4]通過對人體骨骼向量進行特征提取,再用SVM 分類器[5]對動作向量進行分類和識別。上述方法主要運用的是傳統的機器學習方法,需要大量的人工操作步驟并且準確率較低。廖鵬等人[6]通過攝像頭采集學生課堂行為,并通過背景差分提取目標區域輸入VGG 網絡[7],成功識別了睡覺、玩手機、正常三種課堂行為。該研究通過將深度學習技術運用在課堂教學的圖像識別上,為課堂行為識別的研究提供了新的思路和方法,但是其識別學生數量較少,識別學生在課堂中的動作也較為簡單并且準確率仍然較低。
近年來,深度卷積神經網絡飛速發展,AlexNet[8]、VGGNet[7]、GoogLeNet[9]等深度神經網絡模型相繼被提出。但是,當網絡層數不斷加深,深度神經網絡在訓練過程中的梯度爆炸或梯度消失問題會變得越來越明顯。為了解決這種問題,何愷明等人提出了深度殘差網絡ResNet[10]。該網絡很重要的特征之一就是加入了殘差模塊,通過在卷積層之間加入Shortcut 結構,成功地緩解了當網絡層數過深時帶來的網絡退化問題。
為了能識別更多學生在課堂中表現出來的行為,同時提高識別的準確率,本文將深度殘差網絡用于課堂行為識別。通過實地采集大量學生課堂行為的圖片,搭建課堂行為識別數據集,并根據殘差模塊的特點,搭建出適用于該數據集的深度殘差網絡,為識別學生課堂行為提供了新的技術方法。
1 殘差結構
殘差網絡是一種深層次卷積神經網絡。對于卷積神經網絡而言,加深網絡層數可以增強其擬合能力。但隨著網絡層數的加深,卷積神經網絡會變得非常難以訓練,當網絡層數超過某個值后,網絡的識別能力反而會呈現下降趨勢[11]。在梯度反向傳播的過程中,由于網絡層數過深,靠近輸出層的網絡參數會很快收斂,而靠近輸入層的參數則收斂得很慢。為了避免當網絡層數過深引起的識別準確率下降的問題,殘差網絡引入了殘差單元,即通過在卷積層之間加入Shortcut 結構,這種結構使網絡要訓練的目標函數變為了減去輸入函數后的殘差,該結構如圖1 所示。設f(x)為原始網絡輸出,在引入Shortcut 結構后實際輸出設為h(x),有h(x)=f(x)+x,即實際輸出為原始輸出與原始輸入相加,從而將網絡對f(x)的擬合轉變為對h(x)的擬合。這種結構沒有增加新的參數與額外的計算量,同時也解決了網絡反向傳播過程中梯度彌散的問題。
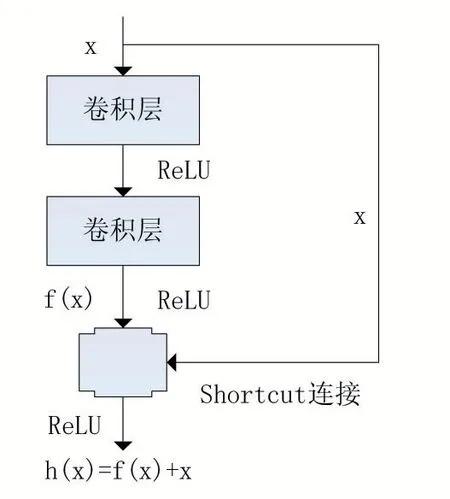
圖1 殘差單元
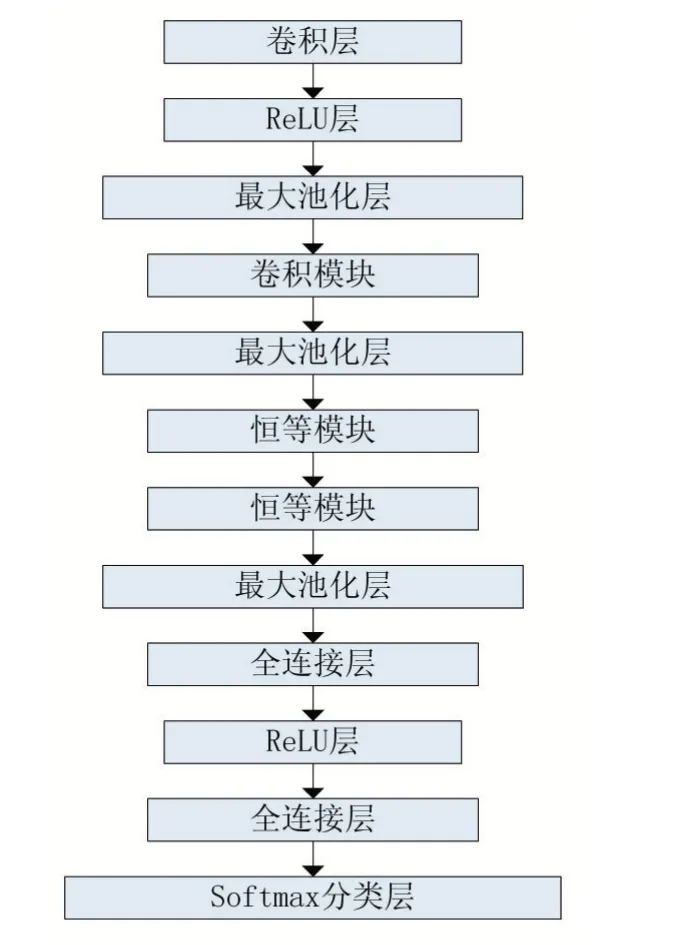
圖2 殘差網絡結構圖
2 深度殘差網絡的結構
本文用于識別學生課堂行為的深度殘差網絡的結構如圖2 所示。包括1 個卷積層、2 個ReLU 層、3 個池化層、1 個卷積模塊、2 個恒等模塊、2 個全連接層以及最后的分類層,該網絡中卷積層的填充方式均為“same”。輸入圖像首先經過卷積層,該卷積層含有64個大小為2×2 卷積核,操作步長為2,由ReLU 激活函數激活從而進行初步特征提取,之后經過一個卷積模塊、兩個恒等模塊進行深度特征提取,再用兩個大小不同的全連接層依次進行特征降維,后一個全連接層的輸出神經元個數為6,分別對應學生在課堂中表現出來的6 種行為,最后通過分類層輸出分類結果。
恒等模塊的結構如圖3 所示,卷積模塊的網絡結構如圖4 所示。
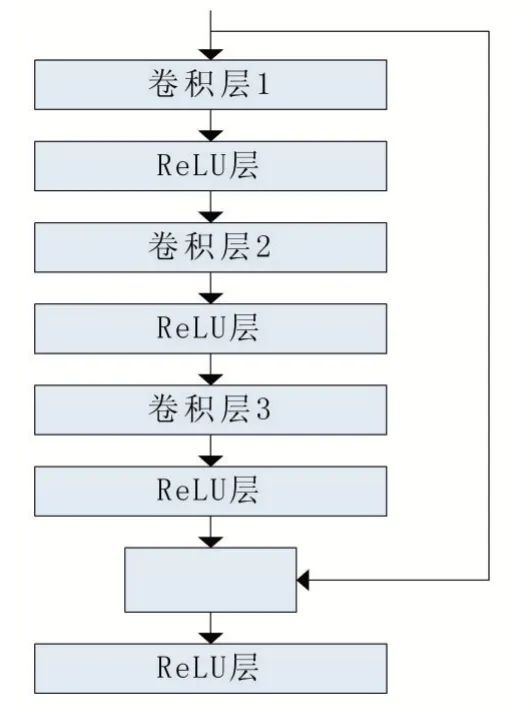
圖3 恒等模塊
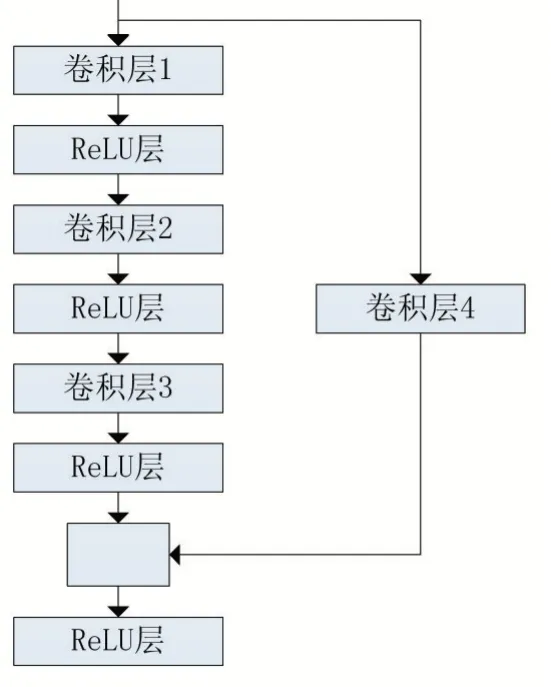
圖4 卷積模塊
恒等模塊包括3 個卷積層、3 個ReLU 層和一個Shortcut 連接操作。其中,卷積層1 含有64 個大小為1×1 卷積核,操作步長為1;卷積層2 含有64 個大小為3×3 卷積核,操作步長為1;卷積層3 含有256 個大小為1×1 卷積核,操作步長為1。Shortcut 連接操作用于將恒等模塊的輸入與經過三次卷積操作后的輸出相加,該操作體現了殘差網絡的基本思想。
卷積模塊包括4 個卷積層、3 個ReLU 層和一個Shortcut 連接操作。其中,卷積層1 含有64 個大小為1×1 卷積核,操作步長為2;卷積層2 含有64 個大小為3×3 卷積核,操作步長為1;卷積層3 含有256 個大小為1×1 卷積核,操作步長為1;卷積層4 含有256 個大小為1×1 卷積核,操作步長為2。相比于恒等模塊,其在Shortcut 連接操作之前先對網絡輸入x 先進行了一次卷積操作。
3 數據庫搭建與網絡訓練
3.1 搭建課堂行為識別數據庫
對深度神經網絡的訓練需要大量已標記的訓練數據,由于網絡上沒有公開的課堂行為識別數據,故本文通過實地收集數據構建了一套專門的課堂行為識別數據集。
視頻通過安裝在教室中的攝像設備采集,分辨率為2560×1536。收集包括上課、睡覺、玩手機、做筆記、東張西望、看書等學生在課堂中出現頻率較高的6 個動作。在視頻收集好后,首先對視頻進行均勻幀采樣,將視頻轉換成圖像,再將圖像裁剪成含有單個學生的圖片并重塑成128×128 的分辨率大小,對每個圖像里的學生課堂行為進行標記后,總共得到1020 張帶有標簽的課堂行為圖片。通過鏡像對稱的數據增強方式對原始數據集進行擴充,最終得到包含2040 張圖片的課堂行為識別數據集。數據集中的部分圖片如圖5 所示,其中每個行為的圖片數量都相同。隨機抽取其中的1560 張圖片作為訓練集,剩下的480 張圖片作為測試集。

圖5 課堂行為識別數據集圖片示例
3.2 訓練殘差網絡
本文實驗在開源深度學習框架TensorFlow 上進行,搭載平臺為Anaconda3。實驗所用CPU 為Intel Core i5-8300H,主頻為2.30GHz,可睿頻至3.96GHz,內存為8GB,操作系統為Windows 操作系統,顯卡為GTX 1050Ti,顯存4G。
卷積神經網絡擁有強大的擬合能力,能夠學習從輸入到輸出的復雜映射關系。即使不知道從輸入到輸出的精確數學表達式,卷積神經網絡也能通過對從輸入到輸出之間的特定模式的學習,較為準確地建立兩者間的映射關系。對卷積神經網絡的訓練一般采用監督訓練的方法。其訓練過程主要分為兩個階段,即前向傳播階段和反向傳播階段。
在前向傳播階段中,為了提高模型準確率,同時使網絡迅速收斂,本文先將訓練集隨機打亂,再結合機器情況在每一次迭代過程中選擇固定數量的小批量圖片作為網絡輸入。輸入經過構造好的網絡架構逐層向前傳播,最后通過Softmax 分類層輸出對每個行為的識別概率。
在反向傳播階段,首先以交叉熵作為損失函數計算出誤差值,然后通過Adam 優化器[12]使誤差反向傳播,更新網絡權重,逐步使得損失函數接近最優值,以優化整個網絡。
另外,本文在對標簽類別進行編碼時采用One-hot編碼方式,網絡學習率為0.001,在全連接層使用Dropout 技術[8],即每次訓練時使神經元隨機失活,從而緩解網絡過擬合,達到正則化效果。
4 實驗結果分析
實驗對比了帶有殘差單元的深度殘差網絡(ResNet)和不帶殘差單元的深度卷積神經網絡(DCNN)在課堂行為識別數據集下的表現情況。其中不帶殘差單元的深度神經網絡是指將原殘差網絡中的Shortcut 連接去掉以后,由其余部分組成的神經網絡。
深度殘差網絡和深度卷積神經網絡的最終準確率如圖6 所示。從圖中可以看到,深度殘差網絡與深度卷積神經網絡相比,泛化準確率較高,前者的泛化準確率為89.46%,而后者為91.91%,說明在加入了殘差結構后,網絡能取得更好的性能。其中,深度殘差網絡識別準確率迭代更新細節如圖7 所示。
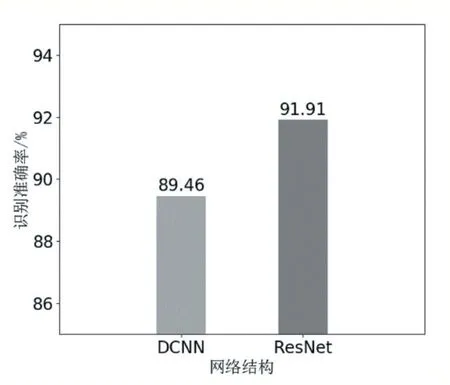
圖6 不同網絡結構識別準確率對比
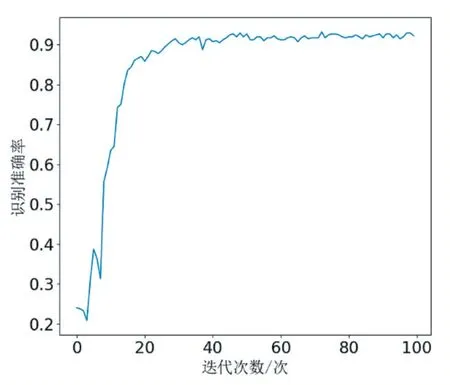
圖7 深度殘差網絡訓練迭代圖
深度殘差網絡識別出的各個行為的準確率如表1所示,其中睡覺和看書分別達到了97.06%、94.12%的較高識別準確率,而玩手機、做筆記、上課、東張西望的識別準確率分別為92.65%、89.71%、91.18%、86.76%。東張西望和上課的識別準確率都相對較低,經分析可能是由于學生分散坐在教室的各個位置,上課時其頭部會有一定的偏向,導致在數據集中,學生上課的行為與東張西望的行為有一定的相似度,從而致使網絡誤識別,降低了其識別準確率。

表1 深度殘差網絡識別各個行為的準確率
5 結語
傳統的機器學習方法識別課堂行為需要復雜的操作對圖像進行特征提取,并且其分類準確率較低。相比于傳統方法,卷積神經網絡能自動提取圖像特征,根據從輸入當輸出的端到端訓練完成網絡的訓練,使網絡具有識別課堂行為的能力,在提升了準確率的同時降低了操作復雜度。然而,隨著網絡層數增加,對網絡的訓練會變得更加困難,甚至帶來網絡性能退化的問題。本文將殘差結構引入卷積神經網絡,提出了一種適用于課堂行為識別的深度殘差網絡模型,實驗結果證明了該網絡相比于深度卷積神經網絡在性能上有更好的表現,但仍存在需要進一步研究的地方。首先,本文中收集的課堂行為數據還不夠豐富,識別的行為還不夠多,研究成果到實際應用還存在一定的距離。其次,網絡在識別具有細微差異的行為時準確率還有待提高。對于這些問題,將在后續的研究中做進一步探討和解決。
猜你喜歡
美食(2022年2期)2022-04-19 12:56:24
少兒美術·書法版(2021年10期)2021-10-20 06:14:10
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
甘肅教育(2020年12期)2020-04-13 06:24:48
十幾歲(2020年4期)2020-02-02 06:00:22
十幾歲(2020年13期)2020-02-02 02:08:44
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
小天使·一年級語數英綜合(2018年9期)2018-10-16 06:30:16
