一種P2P 分布式文件共享方式的實現與優化
2019-08-20 07:27:16劉睿任曉慧于波
現代計算機 2019年20期
劉睿,任曉慧,于波
(聊城大學計算機學院,聊城252000)
0 引言
當代社會步入一個高速發展的時代,科技發達、信息流通,人們之間的交流越來越密切,信息資源也成為國家發展、社會進步的重要戰略資源,信息的傳播與分享成為創造效率的必要條件。文件作為互聯網信息傳輸常用載體之一,其分發傳輸在內容分發網絡、P2P 網絡等方面都有比較成熟的研究和應用成果。而在日常教學及工作中,經常需要將規模小的信息以文件的方式快速分發出去,距離近(如位于同一局域網中的辦公室之間或者教室、機房內),如何提高工作效率以及辦公質量是本文所設計文件共享方式的初衷。目前也有許多學者進行過相關的研究,文獻[1]中研究實現了一種基于Python 語言的分布式文件共享系統,本文同樣采用Python 語言編程,實現了分布式文件共享的功能,并在其基礎上進行了優化設計:通過寫入數據庫表的形式,實現對分享條目的動態修改和對無效信息的及時清除,減少數據冗余;通過利用系統的體系監控機制,實現針對常見系統平臺(包括Windows 及Linux等)的動態監控。最終可實現:加入網絡環境中的每一個成員,都成為信息的發布者和分享者,快速分發,提高工作效率。
在日常的辦公及學習時,常見的文件共享方式一般有以下幾種[1]:通過現代商業辦公體系和一些即時通訊工具進行傳輸;建立FTP 協議的服務器進行文件共享;通過郵箱發送郵件的形式;使用存儲設備拷貝共享等。這些傳輸方式類型多樣,各有利弊,但共同點是都借用了第三方工具,獲取效率有所影響。本文設計實現的分布式文件共享方式特點為:實時查看,實時下載,方便快捷。該共享方式將網絡中內部成員需要傳遞的文件信息加入到共享系統中來,要想獲得這些信息,其他客戶端只需以網頁的形式使用關鍵字搜索即可快速實現。
1 設計思路介紹
1.1 相關概念
Peer-to-Peer(簡稱P2P,即對等方式技術)[2-3],是小型局域網常用的組網方式。其可以定義為:網絡的參與者共享他們所擁有的一部分硬件資源,這些共享資源通過網絡提供服務和內容,能被其他對等節點(Peer)直接訪問而無需經過中間實體。在此網絡中的參與者既是資源、服務和內容的提供者,又是資源、服務和內容的獲取者。
本文所設計的P2P 文件共享方式屬于集中式P2P網絡共享方式[2]。Peer 同時具有Client 和Server 的特點,可以直接通信和文件傳輸[4]。
選擇使用Python 語言進行服務器端、客戶端程序設計,是因為Python 語言是一種語法簡潔優美、功能強大、應用領域廣泛,具有強大完備的第三方庫的一種可移植、可擴展、可嵌入的解釋型編程語言。Python 語言誕生于1990 年,由Guido van Rossum 設計并領導開發,目前是一種被廣泛使用的高級通用腳本編程語言[5-6]。它的特點是:語法簡潔、與平臺無關,有優異的可擴展性;Python 語言提供了豐富的內置類庫和函數庫,可以大量利用已有的內置或第三方代碼,能夠輕量級地完成各種任務,用于編寫各領域的應用程序。Python 語言相對簡潔、開發效率高、易于維護,目前已經成為眾多科研領域使用的科學計算工具[7],具有廣闊的應用空間。使用Python 語言進行設計,可充分享受其代碼簡潔,語義容易理解的優勢,缺點在于運行速度稍慢,代碼不能加密等,對于實用的小程序來講,此點可忽略。
1.2 系統功能介紹
本文系統的實現方式如下:在同一局域網或可以互相訪問的虛擬局域網中,用戶通過運行程序將PC 上用于分享的文件夾設置為共享,應用程序將主動掃描該文件夾下所有文件,生成文件樹并提交到管理系統中,使用超文本傳輸協議(HTTP)的形式進行共享和展示;對于文件搜索,由主機提供Web 程序,以網頁形式進行交互式操作。其他網絡用戶可在智能終端使用通用的搜索入口進行查詢,若能找到可根據需要進行下載使用。為方便說明,本文將所有使用本系統的電腦終端稱之為客戶端,負責承擔搜索任務的電腦終端稱為服務器端。服務器端承擔的搜索任務可以通過使用與客戶端相同的體系來實現。具體工作流程圖如圖1 所示。
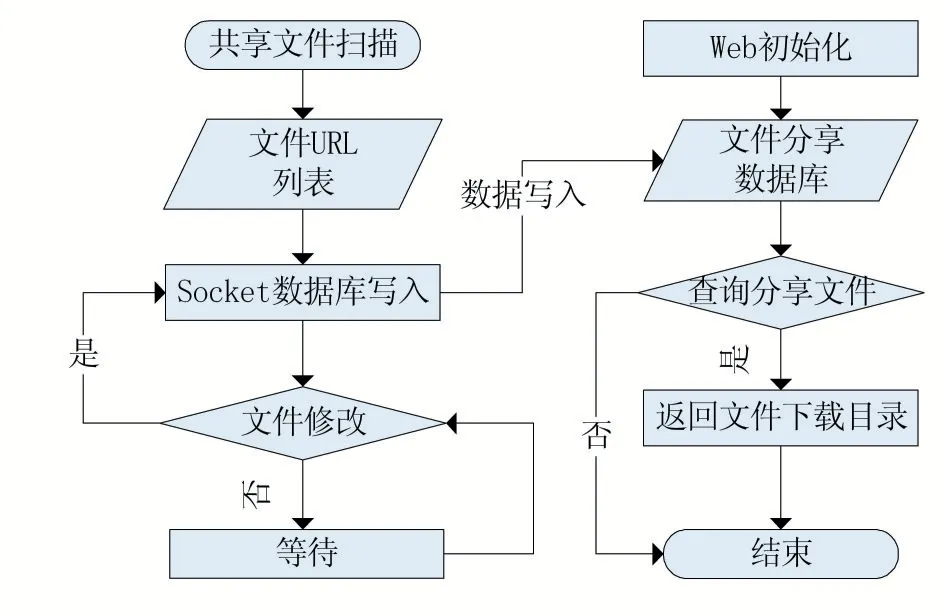
圖1 總體流程圖
2 系統主要功能實現
本文系統功能的實現,分為客戶端、服務器端兩部分分別設計。
根據客戶端實現的功能,采用模塊化及逐層封裝思想,將文件操作,數據庫操作及網絡操作逐層封裝,具體分為以下幾個類進行功能實現:FileTools 文件操作類、DbTools 數據庫操作類、Monitor 文件改動監控類、ClionHttp 服務類、Config 配置文件。作為與文獻[1]的比較,本文著重改進的地方在于DbTools 數據庫操作類與Monitor 文件改動監控類兩部分的設計,下面對每個功能類的實現技術點進行說明。
2.1 FileTools文件操作類
按照系統設計,客戶端需有能力獲取用戶設置為共享文件夾下的所有文件及路徑,故在文件操作類FileTools 中實現獲取所有文件的方法,通過逐層遞歸遍歷實現所有文件的記錄,并同時記錄下文件所在具體位置。
for num in range(len(filelist)):
returndirstr +=creatfile.getfilelist(filepath + '/' + filelist[num])
if os.path.isdir(filepath+'/'+filelist[num]):
else:
returnfilestr+=filepath+'/'+filelist[num]+' '
returnstr+=returnfilestr+returndirstr
為了使文件的路徑信息轉換為對HTTP 服務的有效URL 路徑,故在文件操作類中集成URL 轉換方法,實現由共享文件夾的相對位置轉化為Web 服務的有效路由信息:
list = list.replace(path, "http://" + str(ip)+ ':' + str(PORT)).spli(t' ')
通過Python 標準庫中字符串替換方法,高效生成HTTP 服務分享連接。同時為實現獲取客戶端IP 功能,使用UDP 報文頭抓取方法,該方法相比使用標準庫GETIP()等內置功能的實現方法,更能高效地在客戶機用于兩個及以上IP 地址時,自動判別內網IP,實現IP 定位功能。
2.2 DbTools數據庫操作類
針對客戶端所需的數據庫操縱能力,在比較多種實現技術后,使用對象關系映射技術(Object-Relational Mapping,ORM)[8],作為將本體(Ontology)文件存儲到關系型數據庫中的一種可借鑒的方法。通過在數據庫和代碼業務應用層中間加入數據持久化層,避免直接對數據庫進行操作,避免如SQL 注入等常見的Web 攻擊方式,并且通過對數據域的對象化,可以方便的進行面向對象的數據元操作。將SQL 語句中的關系型聯系轉化為源類對象之間的交互。
在具體的Python 語言中,類似的ORM 框架有很多種[8][9],如SQLObject、Storm、Peewee 等。針對客戶端的特點,選取Peewee 的Python ORM 框架,簡單小巧,且容易學習。
由于客戶端向服務器端提交數據,故設計數據庫表如下:
time 提交時間
ip 提交內網IP name 文件名稱
filename http 分享連接
使用Peewee 建立數據表模型:
class ip_file_url(BaseModel):
time=CharField()
ip=CharField()
name=CharField()
filename=CharField(max_length=500)
針對客戶端具體功能要求,實現了對數據庫的增、刪功能。通過調用FILETOOLS 模塊獲得文件的名稱和HTTP 分享路徑,轉換成具體的數據庫條目,并調用Peewee 中的insert_many()方法,插入到服務器端數據表中。針對共享目錄下文件修改或文件增加、刪除問題,統一使用數據表刪除方法,刪除掉本IP 提交的所有信息,并將新的文件共享項目表提交到服務器數據庫中。通過這種方法,來實現對共享條目的動態修改和對無效信息的及時清除,減少數據冗余。
2.3 Monitor文件改動監控類
在文件分布式分揀存儲系統中,最重要的是實現文件信息的動態更新。因為在實際使用中,用戶可能會對文件進行不定時的更新,為了保證數據的實時性及在整個文件分享系統中的可靠性,就需要實現對特定文件夾的實時監控。當用戶對分享文件夾中的文件進行操作時,系統要及時更新系統數據庫中文件樹,來保證數據完整性。在開發中為了保證跨平臺及兼容性,通過封裝系統信號量監控機制,來實現對不同平臺(包括Windows、Linux、Mac OS 等)的文件操作的實時監控。
具體而言,使用Python 編程,通過對watchdog 模塊的擴展來實現,用來監控指定目錄/文件的變化:
watchdog.events.FileCreatedEvent()
文件被創建時觸發該事件
watchdog.events.DirCreatedEvent()
目錄被創建時觸發該事件
watchdog.events.FileDeletedEvent()
文件被刪除時觸發該事件
watchdog.events.DirDeletedEvent()
目錄被刪除時觸發該事件
watchdog.events.FileModifiedEvent()
文件被修改時觸發該事件(修改文件內容、修改文件inode 信息如權限和訪問時間,都會觸發該事件)
watchdog.events.DirModifiedEvent()
目錄被修改時觸發該事件
通過對watchdog 事件處理類的重構及繼承,來實現針對文件共享目錄的實時監控,每當有文件操作發生在設定的共享目錄時,系統就能根據具體的文件操作類型,實時掃描文件修改,并通過FileTools 及Db-Tools 實時同步到服務器端數據庫中。
2.4 ClionHttp服務類
因為客戶端要根據需求,使用HTTP 服務分享客戶端文件,又要降低對系統的負荷,減小對CPU 及磁盤I/O 影響,故使用Python 標準庫中自帶的http.server模塊,實現了一個小型、符合預期的HTTP 服務程序。
WEBDIR=path
PORT=config.http_prot
os.chdir(WEBDIR)
Handler=SimpleHTTPRequestHandler
with socketserver.TCPServer(('', PORT), Handler)as httpd:
print("serving at port",PORT)
httpd.serve_forever()
通過os.chdir()方法,將當前路徑切換到設定的共享文件目錄上,來實現HTTP 服務的高效運行。
2.5 Config文件
通過創建Config 文件,將一些需要根據情境來更改的屬性綁定到一起,減少修改代碼的復雜性,當用戶在自行部署時,可以統一地在Config 文件中修改具體參數,如數據庫賬號信息、開放端口信息等,避免對代碼的文正行的修改和破壞[10]。
2.6 服務器端
服務器端需要給用戶提供一個完善的UI 交互界面,滿足用戶的可視化操作要求,結合本系統的應用需求,決定使用Web Server 形式提供給用戶類似搜索引擎的文件查詢界面。針對本項目,建立了一個名為server 的Django App 應用。
建立數據層
class files(models.Model):
time=models.CharField(max_length=100)
ip=models.CharField(max_length=100)
name=models.CharField(max_length=500)
filename=models.CharField(max_length=500)
class Meta:
db_table='ip_file_url'
來定義數據操縱的表結構,為后續數據操作實現類定義。
定義兩個方法Headhtml(),Inquire()來完成系統操作。Headhtml()來完成用戶訪問本系統時,返回查詢首頁面的功能,當用戶在窗口中輸入要查詢的文件名稱時,通過post 方式提交到后臺,而Inquire()方法用來接受用戶的查詢參數,并使用models 中定義的數據表進行對數據庫的查詢操作。
class MyFormView(View):
form_class=MyForm
template_name='result.html'
def post(self,request,*args,**kwargs):
form=self.form_class(request.POST)
if form.is_valid():
form=files.objects.filter(name_iexact=names)
return render(request, self.template_name, {'form':form})
當在數據庫中查詢到具體條目時,主動渲染到result 模板中,并返回給用戶。
針對網絡安全問題,尤其是在表單提交時的跨域攻擊問題,特地在網頁模板中添加{%csrf_token%}標簽,使用{%csrf_token%}生成一個input 框在form 表單中提交,每次post 請求提交有需要Django 生成的csrftoken 值,來防范跨域攻擊問題。
3 系統實現
在同一局域網中的多臺辦公電腦上進行了系統測試,其中一臺電腦啟動服務器端服務。圖2 和圖3 分別顯示在客戶端電腦進行文件搜索及找到相關文件后的畫面,可以看到本文系統的實現效果如圖2。
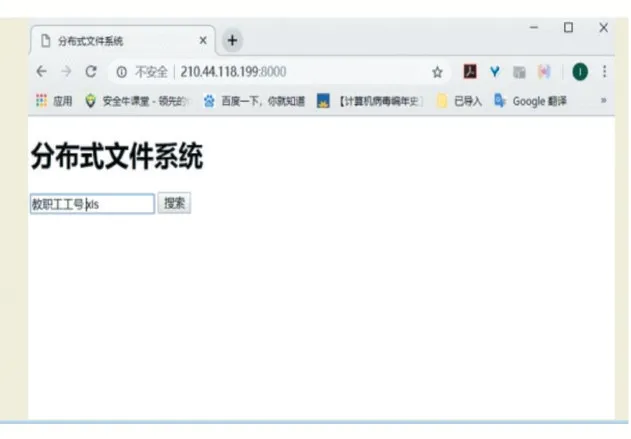
圖2 文件搜索
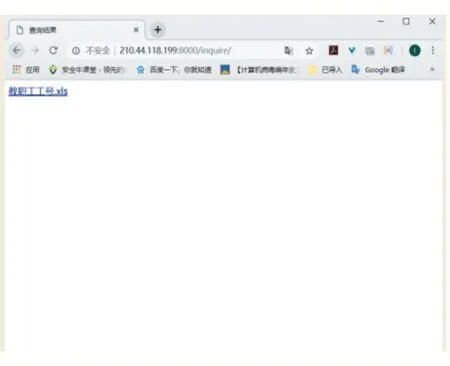
圖3 文件下載
4 結語
本文使用Python 語言編程,實現了整個分布式文件共享系統的功能,優化設計的地方主要有:通過寫入數據庫表的形式,實現對分享條目的動態修改和對無效信息的及時清除,減少數據冗余,保證信息的準確性。使用系統監控機制,實現針對常見系統平臺的動態監控,使得該共享方式適用于各種系統平臺。用戶只需要運行客戶端程序,隨時都可以加入到文件共享的隊伍中,其他的網絡用戶通過搜索,即可獲取相應的文件。該方式實現簡單有效,可滿足于各種辦公、教學環境使用,是一種可推廣的文件共享方式。
算法過程簡潔明了,易于理解。系統實現部分給出了較直觀的圖,顯示了系統運行時的共享文件搜索及文件下載界面。關于系統安全[11]及文件搜索過程中模糊查詢、內容查詢等細化方面的工作,可作為下一步的研究方向。
猜你喜歡
中華詩詞(2022年6期)2022-12-31 06:41:24
中國科技論壇(2017年7期)2017-07-25 08:49:53
財經(2017年2期)2017-03-10 14:35:35
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
財經(2016年15期)2016-06-03 07:38:02
商用汽車(2016年4期)2016-05-09 01:23:12
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
創業家(2015年5期)2015-02-27 07:53:25
