基于Prolog的列控工程數據驗證方法
2019-08-02 03:20:24譚冠華徐田華王海峰呂繼東
鐵道學報 2019年6期
譚冠華,徐田華,王海峰,張 路,呂繼東
(1. 北京交通大學軌道交通控制與安全國家重點實驗室,北京 100044;2. 北京交通大學軌道交通運行控制系統國家工程研究中心,北京 100044)
列控工程數據[1](以下簡稱列控數據)是列車移動授權、軌道電路編碼化、應答器報文編制等功能的基礎數據,是列車運行控制系統各功能實現的底層數據,保證其正確性是列車運行控制系統安全運行的根本保障。為保證列車運行控制系統安全運行,需要對列控數據進行正確性驗證。
傳統數據驗證方式是人工校驗。人工校驗存在如下缺點:一是數據類型多、數量大,任務周期短,校驗工作難度大;二是環境優化、勘測誤差修正、線路修改等都需要對數據進行修改,整個線路生產周期存在頻繁變更,人工校驗任務繁重;三是人工審核存在人為因素帶來的審核失誤、遺漏問題。可見,探索一種高可靠、高準確性的驗證方法,對于列車運行控制系統具有重要的現實意義。
列控數據驗證存在3個方面的問題:一是列控數據的處理方法,根據鐵總運〔2014〕246號文件[2]規定,包含數據表格16個,數據屬性繁多,單表數據之間以及多表數據之間存在關聯關系,期望建立數據的標準化格式,合理處理數據關系。二是列控數據的規則提取,鐵路技術標準、規范是以文本語言進行描述,在文義理解上易存在差異,也沒有明確指出數據間的關聯關系,僅能檢查工程數據的格式、類型等錯誤,對虛假數據巧合、數據間邏輯關聯關系方面,存在安全隱患,數據驗證的充分性和完備性不足。如何發現數據之間的隱含關系,提取出充分、完備的驗證規則,是數據驗證的難點之一。三是對于數據規則進行驗證模型構建,實現快速、高效、正確的自動化驗證。
對于軌道交通領域,已有部分學者探索了一些數據驗證方法。文獻[3]把需要驗證的鐵路系統數據利用B-language 把數據需求進行形式化建模,并利用OVADO 對模型進行測試;文獻[4]利用Atelier B 對鐵路數據進行驗證;文獻[5]通過對聯鎖數據建立各類形式化模型進行數據驗證。上述驗證方法的核心是B-Method,其理論基礎是數據集合和數據映射,在數據表示和數據處理上能力較弱,因此對于大數據集,其驗證過程中易存在狀態爆炸問題。文獻[6]提出了基于XML的XSLT,對列車運行控制系統數據進行驗證,其驗證方法是建立標準、規范化的數據約束,驗證數據是否滿足這些約束條件。文獻[7]提出了基于規則的數據驗證方法,但其驗證規則主要是數值驗證規則,對于大量的文本數據無法進行驗證。
針對列控數據存儲結構,本文提出基于XML的數據標準化格式。該存儲結構,可蘊含數據之間的關聯關系,易于數據交互。多表文件到單一文件的統一,易于實現數據修改,解決列控數據頻繁變更問題。針對列控數據驗證,本文提出一種基于Prolog的列控數據驗證方法。Prolog是一種主要運用于自然語言、人工智能等領域[8]的邏輯編程語言,建立在邏輯學基礎上,具有高效的自然語言描述方式,可以簡潔方便地描述驗證規則。其強大的遞歸能力和關系數據庫原理上的推理機制,提高了數據驗證的效率。同時,Prolog也是一種形式化表達,具有嚴謹的表示方式,可確保數據驗證的準確性。本文綜合考慮數據驗證各類問題,對武廣線的工程數據進行驗證結果分析。
1 背景知識
1.1 列控工程數據
列控工程數據是列車運行控制系統各設備的參數化實現的數據依據,主要包括:車站信息表、線路坡度表、線路里程斷鏈明細表、道岔信息表等。圖1是列控工程數據表結構。
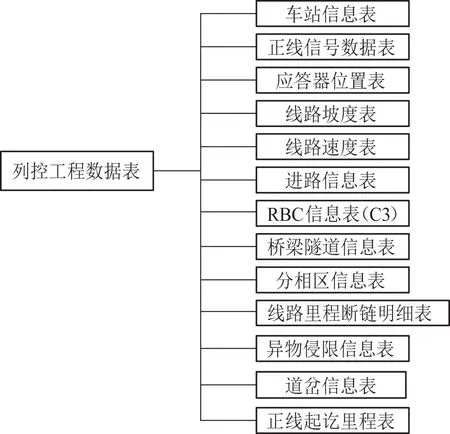
圖1 列控工程數據表結構
列控數據以表格形式存儲,各表定義了不同的數據屬性。例如:線路坡度表包含線別、坡度、長度、終點里程;正線信號數據表包含列車正向運行和反向運行的區間,站內正線部分的信號點與軌道區段信息。圖2給出正線信號數據表表格樣式。
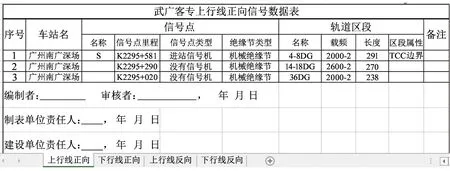
圖2 正線信號數據表
1.2 XML
XML[9]是一種可擴展標記語言,其設計宗旨是用于存儲與傳輸數據,可以根據自身需求定義各種數據類型,表示各類源數據。
XML與SQLServer、DB2等數據庫在應用和功能上不同,數據庫是一種數據存儲和管理的工具,通過sql語句實現數據庫的增刪改查等功能,而XML主要用于存儲自定義的數據,易于被各種編程語言開發的應用程序快速讀寫,通常作為應用程序的配置文件。XML與其他數據表現形式相比,具有以下優勢:
(1)自定義標記,具有極大的可擴展性;
(2)定義數據結構層次;
(3)篩選希望獲取的那部分數據;
(4)國際化語言,實現真正的數據交互。
除上述優勢外,XML相對于其他存儲格式,還有與之相關的兩種約束技術——DTD和Schema,它們可以預先定義XML文檔的數據結構和屬性約束,保證XML文件填寫的正確性。
2 列控數據處理和驗證
2.1 工程數據XML表示
工程數據表是以表格形式對數據進行存儲,表與表之間不是獨立存在的,而是整體表述一段完整的線路信息。該儲存方式存在缺點如下:
(1)表格多,不同應用所需數據不同,數據交互后,可能丟失數據;
(2)數據之間存在屬性關聯,數據變更影響多個數據,不利于數據修改;
(3)表格單獨表示,不能體現表間關系和屬性關系。
對于列控系統數據,統一標準的數據描述方式是許多學者的研究重點。當建立統一標準的數據描述方式后,列控系統各設備之間不再需要轉換接口函數,可以提高工程效率。對于不同鐵路部門和設備生產產家,可以實現數據共享,軟件互通,擴大數據交流。Railml[10]就是一種歐洲提出的統一的鐵路應用系統數據存儲格式,隨著鐵路系統各大公司和研究機構的不斷加入,Railml討論會議的不斷召開,Railml也開始得到了完善和使用。
針對列控工程數據表,本文提出基于XML的數據存儲標準化格式。通過XML數據存儲結構,可以把所有工程數據表統一在一個文件進行表述,可以避免數據的重復表示,消除數據冗余,也可防止表格丟失,保障數據完備性,同時XML文件是可自定義的結構化文件,表示表格之間、數據之間以及表格與數據間的包含關系和關聯關系。
通過對Railml和文獻[11]的研究,結合列控工程數據表的數據結構分析,列控數據的XML結構如圖3所示。圖3表示的是數據層次結構,每個結構還包含內部細致結構和具體屬性表示,本文不做具體說明,圖4是軌道分段拓撲結構XML數據示例。
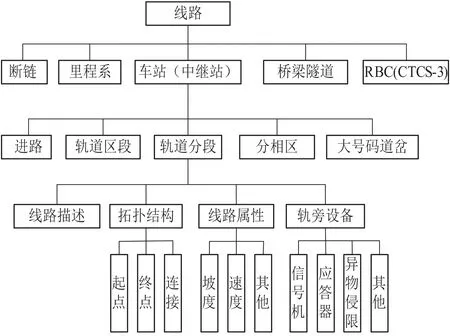
圖3 列控數據結構

圖4 軌道分段拓撲結構XML
2.2 驗證流程
圖5為列控數據驗證流程,首先實現列控工程數據表到XML列控標準數據的轉換;根據原始數據與XML數據定義,結合數據規范、領域知識以及數據挖掘技術提取驗證規則;利用Prolog語言將數據描述為事實,規則描述為知識,建立驗證模型,最后利用XSB工具對事實進行驗證,根據數據錯誤文檔修正數據。
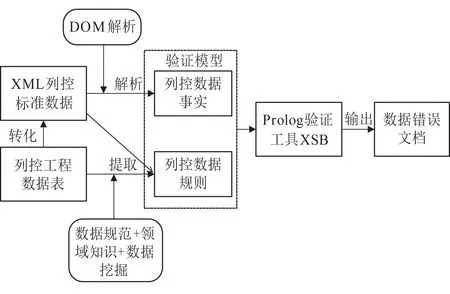
圖5 列控數據驗證流程
3 數據規則提取
列控數據驗證的基礎是數據的內容和特點,其目的是提高數據的正確性,其驗證目標就是數據包含的各類規則。規則來源分為三類:一是鐵總運下達的各類文件,例如《列控數據管理暫行辦法》[2]、《CTCS-2級列控系統應答器應用原則》[12]等;二是領域專業知識,鐵路信號基礎、車站信號控制等;三是通過數據挖掘方式,發現數據隱含規則。
3.1 值域規則
根據圖3可知,列控數據包含各類數據對象,不同數據對象還包含大量數據屬性。每個數據對象在真實世界有其物理意義,各項數據屬性也必須滿足其值域規則,即格式需求與取值需求。
(1)數據類型
不同數據屬性,代表實際含義不同,數據類型也存在差異性,列控數據主要包含的數據類型有:整型、浮點型、字符串、布爾類型、枚舉類型。
(2)格式需求
列控數據是列控基礎數據,應用于各類設備配置數據、軟件開發等。為滿足數據通用性,其數據格式具有嚴格的要求。例如:各項設備名稱基本都有其命名規范;公里標格式‘K×××+×××’;數值根據方向分奇數與偶數。
(3)值精度
值精度狹義上是考慮浮點型數據的小數位數,但其廣義上還包括數據單位,數據值必須與其單位匹配。例如坡度單位‰;公里標單位m;速度單位km/h。
(4)值范圍
值范圍即數據的取值范圍,由數據類型與數據的物理意義確定。例如速度非負,并有其最大值;布爾取值只能0和1;對于連續性數據,根據箱型圖分析方法確定上界與下界。
表1從總體上簡單概括值域規則具體內容。

表1 值域規則
3.2 邏輯規則
值域規則是對數據自身要求,滿足的是格式與值域。邏輯規則是表述各表各屬性間的邏輯關系。下文對部分數據進行定義形式并表述蘊含邏輯規則。
定義1軌道分段數據定義為
定義2線路斷鏈數據定義為
規則1斷鏈長度由斷鏈起點里程和終點里程確定。即
Dlength= |Dend-Dbegin|
(1)
規則2軌道分段長度由其起點、終點里程以及是否包含斷鏈決定。
當?Dk∈D,Dk?Ti
Tlength,i= |Tend,i-Tbegin,i|
(2)
當?Dk∈D,Dk∈Ti
Tlength,i= |Tend,i-Tbegin,i|±Dlength,k
(3)
式中:D為斷鏈集合;Dk為D的一個元素。
定義3坡度數據定義為
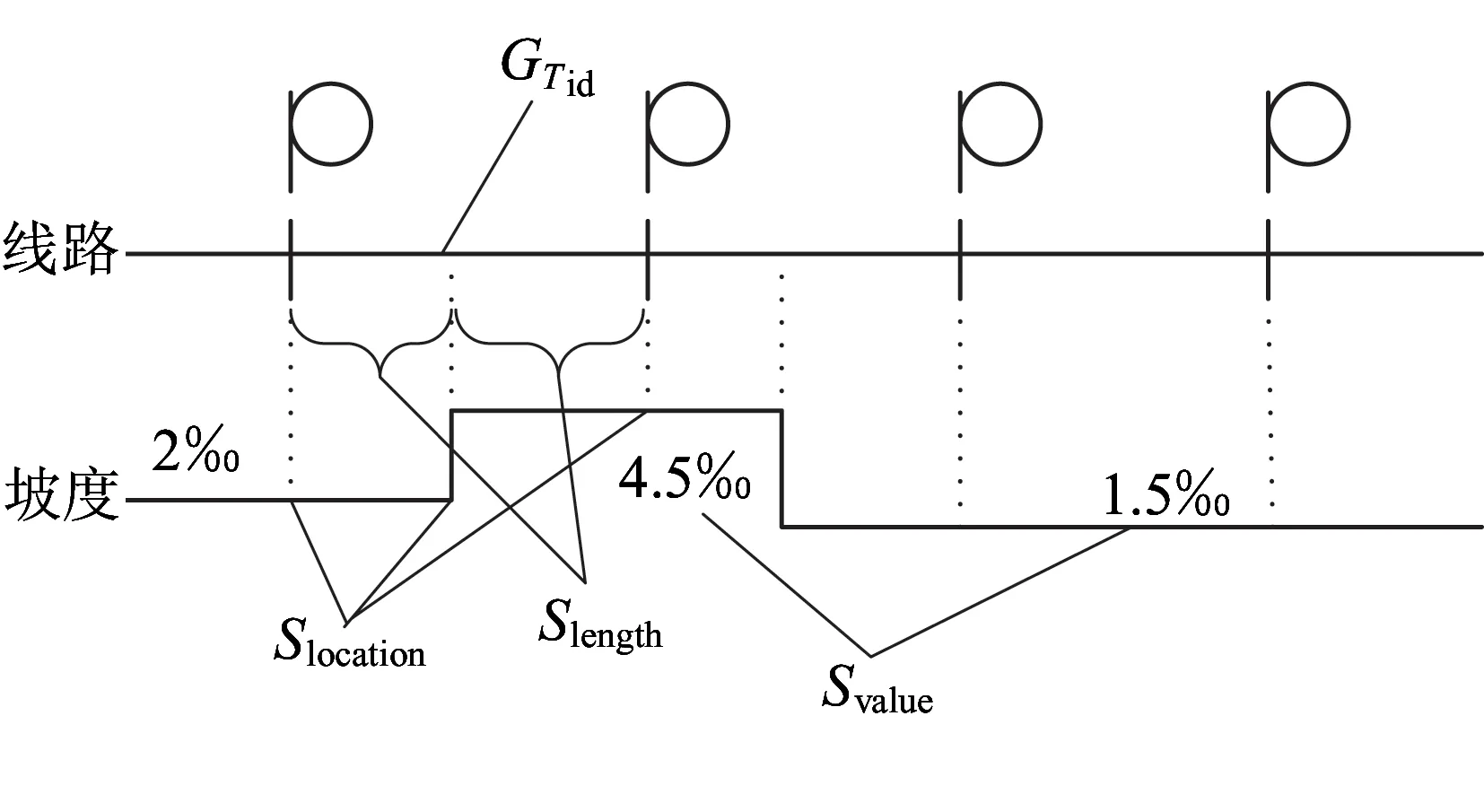
圖6 坡度映射圖
規則3坡度長度與坡度點公里標一一對應,斷鏈表示未給出,即
Slength,1=Slocation,1-Tbegin,id
(4)
Slength,i=Slocation,i-Slocation,i-1i≥2
(5)
規則4線路的坡度分段描述了各個軌道分段的坡度信息,所屬軌道分段相同的坡度的長度之和等于軌道區段長度。即
(6)
定義4信號機數據定義
規則5信號機位置必然有絕緣節,則信號機位置也是軌道分段分界點,即
SIlocation=Tbegin,id∨SIlocation=Tend,id
(7)
定義5應答器信息分組存儲,數據定義為
規則6應答器組內間距標準為5 m,即
Blocation,i-Blocation,i-1=5
(8)
規則7根據應答器布置規范,不同類型的應答器,與信號機之間的安裝距離為固定集合,用集合M表示,即
|Blocation,i-Slocation,i|∈M
(9)
定義6軌道分段連接關系定義為
規則8存在連接關系,則軌道分段不是同一段,且連接點公里標相同,即
當?
id1≠id2∧Tbegin,id1=Tend,id2
(10)
定義7軌道區段定義
規則9軌道區段因可能包含道岔,所以其可能包含多個軌道分段,各個分段之間必然存在連接關系,即
?LTi,LTi+1∈LTid??
(11)
3.3 關聯規則
在列控數據規則提取過程中,值域規則和邏輯規則都是側重數據屬性的約束關系,這些約束關系的來源是數據規范和領域專家知識。本文期望擴展規則來源,能在鐵路線路大量的數據中,發現數據與數據之間的隱含關系。針對上述問題,本文選取數據挖掘的方式提取數據中隱含的關聯規則。
數據挖掘[13]是以大量數據為基礎,通過各種數據處理辦法發現可用規律的技術。根據列控數據的實際情況分析,本文的數據挖掘方式采用的是關聯分析。關聯分析是數據挖掘的主要研究方法之一,期望從列控數據中發現它們之間的相關性,而這些相關性并沒有在列控數據中直接體現。
常用的關聯規則算法有Apriori算法、FP-Growth算法、灰色關聯分析法。由于列控數據與大數據相比較,其數據量相對較少,因此本文采用的是Apriori算法。Apriori算法的核心思想是通過逐層的迭代,找到數據中最大的頻繁項集,再根據最小支持度與最小置信度,從頻繁項集中找到滿足要求的強關聯規則。下文對Apriori算法進行基本簡介。
項集是事務中項的集合,如果項集中存在I個項,則成為I項集,如果I項集的支持度大于或等于設定的最小支持度,則稱I項集為I頻繁項集。其中最小支持度是用于表示事務頻繁出現的一個閾值,大于該閾值的項集才具有統計意義。強關聯規則是從頻繁項集中找到的大于或等于最小置信度的關聯規則,其中最小置信度是強關聯規則發生的最低可靠性。
支持度:項集X、Y在所有事務中同時發生的概率。
支持度(X?Y)=P(XY)
置信度:項集X發生后,項集Y也發生的概率。
置信度(X?Y)=P(Y|X)
Apriori算法的實現分為兩個步驟。
步驟1先找到所有的1-頻繁項集,再通過逐層迭代,依次找到所有的2-頻繁項集、3-頻繁項集,直至找到最大的I-頻繁項集為止。
步驟2由頻繁項集生成關聯規則。關聯規則表述為X?Y,X稱為前件,Y稱為后件。該過程依次生成所有1-后件(后件只有一項)強關聯規則,然后生成2-后件關聯規則,以此類推生成所有強關聯規則。
本文以武廣線正線信號數據表的上行正向數據為例,描述關聯規則挖掘過程。第一步是確認數據對象并獲取數據,表2為部分正線信號數據樣例。

表2 武廣線正線信號數據
數據獲取是數據挖掘第一步,第二步是數據預處理,該步驟需要完成數據清理、屬性規約和屬性變換。數據清理的作用是清除數據中的無效數據和錯誤數據。本文的數據來源是廣鐵集團,表格數據基本正確,清理過程通過值域規則進行審查。通過對表2進行屬性規約,刪除不相關屬性:序號、車站名、信號點里程。表3為屬性規約數據。
由表3數據可知,屬性中的信號點名稱和軌道區段名稱為文本數據,命名上差異較大,而長度為數值數據,離散度較大,都需要通過屬性變換,構造相關屬性。信號點名稱用信號機類型與方向集成為新屬性A,其中A1表示上行進站信號機、A2表示上行出站信號機、A3表示上行通過信號機、A4表示上行進路信號機、A5~A8為上述對應的下行信號機、A9表示空、A10表示分割點。軌道區段名稱根據其屬于區間還是站內劃分,分別用D1、D2表示。長度屬性為離散化數值,采用分段的劃分方式,例如F1取值[0,199]、F2取值[200,399]。其他屬性為枚舉類型,不需要特殊區分,表4為屬性變換后的數據。
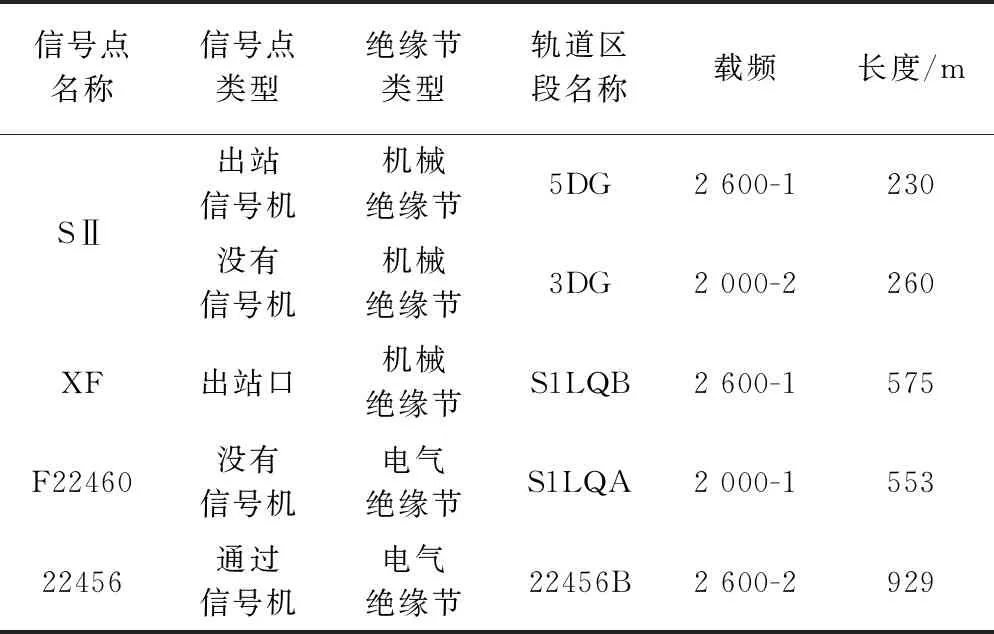
表3 屬性規約數據
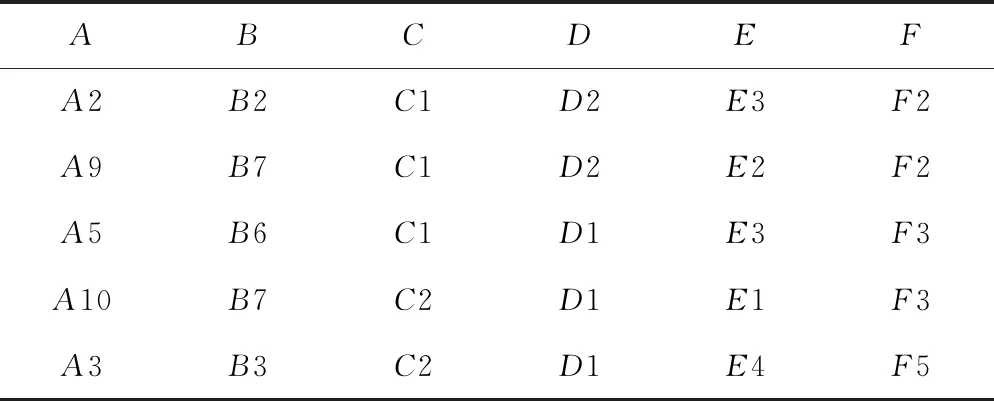
表4 屬性變換數據
通過數據獲取、數據預處理,將最小支持度設為8%,最小置信度設為95%,通過Apriori算法處理所有武廣線上行正向數據后,挖掘出438條強關聯規則。因強關聯規則僅表示滿足支持度和置信度要求,還需要分析規則有效性以及審核是否符合實際意義,同時需要通過多條線路關聯規則對比后提取有效規則。表5是部分關聯規則示例。
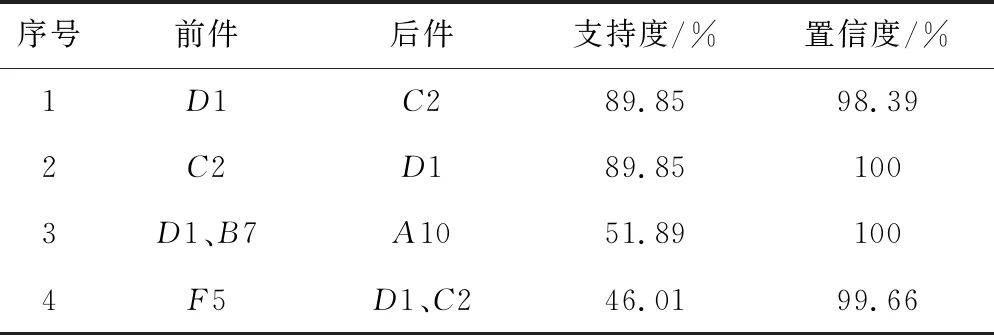
表5 關聯規則
4 驗證模型
為了實現自動檢查列控數據的正確性,需要對數據進行規則的一致性表示。本文使用Prolog邏輯語言建立邏輯編程框架,即驗證模型。驗證模型的目的就是搜索違反規則一致性的數據反例。Prolog建立的驗證模型是基于一階謂詞的形式化表述,本文主要包含以下三類謂詞:
(1)表述輸入數據文件事實的謂詞,即將列控數據轉換為Prolog可識別的邏輯定義;
(2)表述數據規則的謂詞,即值域規則、邏輯規則、關聯規則;
(3)表述搜索數據反例的謂詞,即搜索錯誤數據。
4.1 Prolog程序結構
Prolog語言程序結構有三類,分別是事實、規則和詢問[14]。
事實是對事務定義的客觀存在,具有恒為真的含義。事實中的關系稱為謂詞。例如Line(1-5DG,900),該事實描述軌道區段名稱為1-5DG,長度為900,謂詞是Line。
規則是事實自身或事實與事實之間可滿足的基本關系,是邏輯判斷的主要依據。規則由規則頭和規則體組成,其中用符號“:—”連接,用”.”結束。規則的一般描述形式如下:
p:—p1,p2,p3,…,pn.
p1,…,pn均為命題,符號”,”表示合取(∧并且)的意思。規則的語義是:如果“p1∧p2∧…∧pn”為真,則p為真。
Prolog系統是一種數據庫或知識庫系統,事實和規則就是庫里面的知識,通過詢問的方式,向系統詢問一些問題,就是系統求解的目標。對于本文而言,事實表示存在哪些列控數據,規則表示數據應符合的驗證規則,詢問就是遍歷數據是否滿足所有規則,并尋找反例。
4.2 數據事實
給定一個完整的XML格式的列控數據文件,需要根據其中的XML元素定義成可識別的數據事實,下文對部分列控數據進行事實表示。
軌道分段及其連接、坡度、信號機、應答器、橋梁等事實表示如下:
t_section(Tid,Tbegin,Tend,Tlength,Tdir).
connection(Tid1,type1,Tid2,type2).
slope(Tid,Slength,Slocation,Svalue).
signal(SIid,SIname,SItype,SIlocation,sIpointType,SIJYJType).
balise(Bid,Bname,Blocation,Bfunction,Bstation).
baliseGroup(ArrayBid).
bridge(BRname,BRdir,BRloc_start,BRloc_end,BRlength).
line(Lid,Lname,Lfrequent,LTid).
belong(Tid,SIid|Bid)。
上述謂詞包含數據主要參數,部分參數未給出。其中謂詞baliseGroup描述應答器組關系;ArrayBid是應答器編號數組;belong謂詞用于描述兩個對象間從屬關系,其中參數是對象編號,不僅可表示軌道分段與信號機從屬關系,整個XML文件層次結構從屬關系,都可用該謂詞表示,其余謂詞可參見本文3.2節。
值域規則中,部分數據的值范圍具有明確規則,該部分數據值域可用枚舉的形式來表示所有取值范圍。例如線路方向只有上行、下行,絕緣節只分為電氣絕緣節、機械絕緣節,相關事實表示如下:
dir([up,down]).
frequent([2 600-1,2 600-2,2 000-1,2 000-2]).
jyj_type([electrical, mechanical]).
balise_type([active,passive]).
4.3 規則模型
數據事實是根據列控數據的實際情況,定義了相應的格式后,將列控數據轉化為對應的事實表示。通過將上述的各類規則轉換為Prolog的邏輯規則,構建數據驗證的規則模型,規則模型搭建的越完整,驗證準確性越高。規則模型主要分為以下4個子模型。
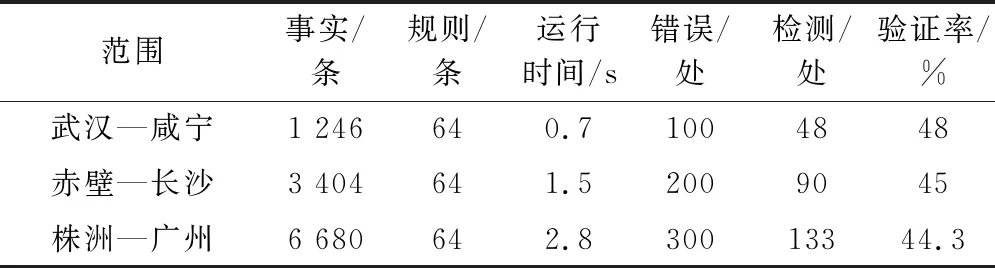
4.3.1 值域規則子模型
值域規則子模型是對列控數據各對象值域規則的集成,是對數據格式和取值的約束。
對于數據類型,Prolog有內部定義的類型謂詞,例如integer(A),string(A),real(A)。其余嚴格的數據格式約束,需要自定義相關規則謂詞。
信號機事實中包含信號機類型,也包含其位置絕緣節類型,驗證這些類型是否在值域范圍的規則表示如下:
rule_1(A):—signal(A,B,C,D,E,F)∧
signal_type(type1)∧insulation_joint(type2)∧
member(C,type1)∧member(C,type2).
根據信號機事實表示可知,C、F分別是編號為A的信號機的類型和位置絕緣節類型;member(C,type)是確認C是否是集合type的一個元素。
應答器名稱在應答器相關規范中有嚴格要求,其名稱的首字母必須為“B”,規則表示如下:
rule_2(A):—balise(A,B,C,D,E)∧name(B,X)∧X=[X1|_]∧X1=66.
根據應答器事實表示可知,B表示應答器名稱,name(B,X)是內部謂詞,實現字符串轉換對應ASCⅡ碼數組,66是字符‘B’的ASCⅡ碼。
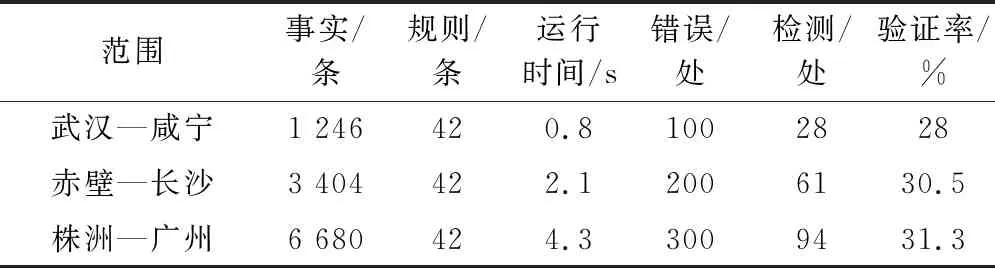
4.3.2 邏輯規則子模型
根據規則1可知,斷鏈的長度由起點里程和終點里程決定,即長度等于起點里程與終點里程之差,驗證規則表示如下:
rule_3(A):—chain(A,B,C,D,E,F)∧D=|B-C|.
根據規則2可知軌道分段的長度不僅與起點里程、終點里程相關,還需要檢測是否存在斷鏈。該規則需要定義以下多條規則構建其完整性。
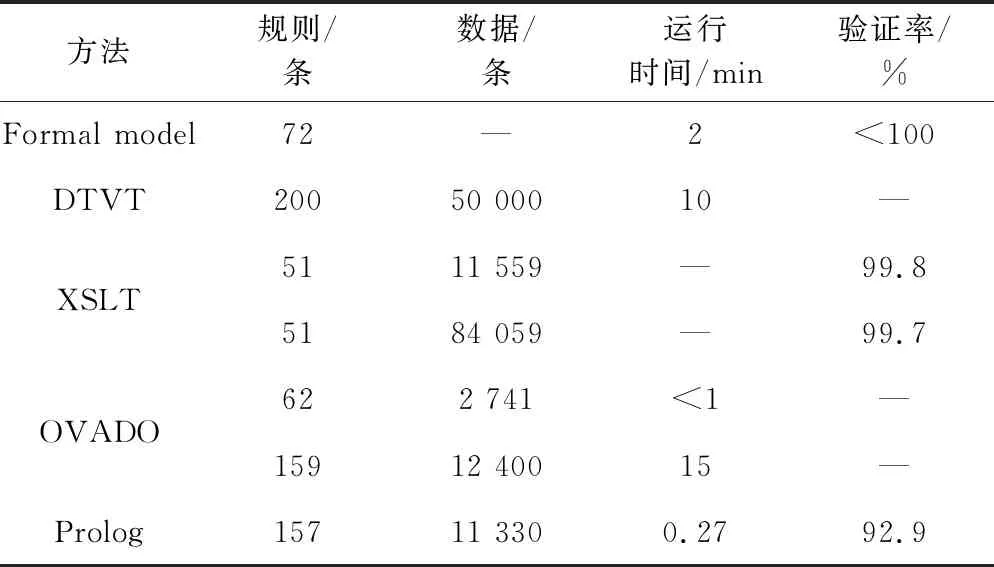
rule_containChain(A,Length,type):—t_section(A,B,C,D,E)∧chain(X,Y,Z,Length,type,U)∧E=U∧((B rule_t_sectionLength(A):—t_section(A,B,C,D,E)∧rule_containChain(A,L,T)∧((D=|C-B|-L∧T=‘S’)∨(D=|C-B|+L∧T=‘L’)). rule_ t_sectionLength (A):— t_section(A,B,C,D,E)∧D=|B-C|. 其中謂詞rule_containChain表示編號為A的軌道分段是否包含斷鏈,并取得斷鏈長度和類型。rule_ T_sectionLength有兩條,分別存在斷鏈和不存在斷鏈,謂詞名稱相同,兩條規則是或邏輯關系。 根據規則6可知,應答器組內應答器布置位置相差5 m,其驗證規則表示如下: rule_distanceBalise(A):—baliseGroup(A)∧length(A)>1∧?Ai,Ai+1∈A∧balise(Ai,B1,C1,D1,E1)∧balise(Ai+1,B1,C1,D1,E1)∧|C1-C2|=5. 信號機和應答器與軌道分段有映射關系,即信號機的位置與軌道分段的起點或終點對應,應答器位置在所屬軌道分段范圍內,驗證規則表示如下: rule_signal To t_section(A):—signal(A,B,C,D,E,F)∧t_section(a,b,c,d,e)∧belong(a,A)∧(D=b∨D=c). between(D,X,Y):—D≤max(X,Y)∧D≥min(X,Y). rule_balise To t_section(A):—balise(A,B,C,D,E)∧t_section(a,X,Y,d,e)∧belong(a,A)∧between(D,X,Y). 4.3.3 關聯規則子模型 根據數據挖掘關聯規則的方法,提取出了大量關聯規則,根據關聯規則建立關聯規則子模型。 對于關聯規則“C1—>D1”,其實際意義是對于每條線路數據,信號點絕緣節類型是電氣絕緣節,所屬軌道區段分類是區間,表示如下: rule_C1—>D1(A):—signal(A,B,C,D,E,F)∧belong(a,A)∧t_section(a,b,c,d,e)∧(F=‘ electrical’—>isRegion(a)). 其中electrical表示電氣絕緣節,謂詞isRegion判斷T_section(A)是否是區間軌道。 對于關聯規則“D1、B7->A10”,其實際意義表示區間軌道對應信號點類型沒有信號機,則信號點名稱屬于合成新屬性A6,表示如下: rule_D1B7->A10:—(isRegion(a)∧belong(a,A)∧signal(A,B,C,D,E,F))->(newAttribute(A,New),New=‘A6’). 其中謂詞newAttribute為確定信號點名稱新屬性類型。 4.3.4 錯誤輸出子模型 上述3個子模型的目的是驗證數據事實是否滿足數據規則,其回答是yes或no,不能提示數據錯誤位置。錯誤輸出子模型就是對違反規則輸出錯誤信息,主要分為錯誤信息存入Prolog知識庫,以及輸出錯誤到錯誤信息TXT文件。 斷鏈信息中長度與起點里程和終點里程不匹配,則存儲對應錯誤信息,表示如下: error_Meg1(A):—not rule_3(A) ->assert(error(message)). 其中,assert謂詞是內部謂詞,邏輯判斷過程中添加新的事實,assert(error(message))就是將驗證過程中出現的錯誤信息以事實的方式進行存儲。 在驗證過程完成后,為便于直觀地查看驗證不通過的信息,方便修改錯誤數據,可將上述的error事實輸出,錯誤信息輸出模塊表示如下: save(FileName):—telling(Old), tell(FileName), listing(error), told, tell(Old). 為了驗證本文提出列控數據驗證方法的高效性和準確性,利用武廣客專正線列控數據進行實驗分析。線路跨度里程達1 000 km,數據記錄條數近9 000條。本文從中選取三段線路長度不同的數據作為驗證樣本,分別為武漢—咸寧、赤壁—長沙、株洲—廣州。表6~表8是根據上述建立驗證模型得到的驗證結果。 表6 值域子模型驗證結果 表7 邏輯子模型驗證結果 表8 關聯子模型驗證結果 根據表6~表8可以看出,隨著數據事實數量的增加,運行時間也在增加,但3個子模型運行總時間不超過20 s,三段鐵路線跨度已達950 km,相比較人工驗證按天數來計算驗證時間,該方法對于列控數據驗證具有明顯的高效性。 驗證方法最重要的評價指標是驗證率,即能驗證出錯誤數據的比例。針對本文驗證方法,數據錯誤添加的方式是:先確保已有列控數據的正確性,再由非驗證模型設計人員修改數據,并記錄修改內容,以便于核實驗證效果。根據驗證結果可知,3個子模型單獨驗證列控數據的驗證率都不高,但是,針對3個模型驗證結果進行統計,三段線路的整體模型驗證率可達92%、94%、92.6%,均超過了90%,可見該驗證方法對于列控數據驗證具有較高的準確性。 表9給出了本文方法與文獻[2-5]中的數據驗證方法性能,列控數據驗證方法不同,在規則單元以及數據單元定義會有差異,例如DTVT的數據單元是單元格,Prolog是數據分類的一行,所以數量級上不好比較,但可以發現本文方法在運行時間上有明顯優勢,驗證率上稍有缺陷。 表9 列控數據驗證方法性能 通過對遺漏的數據錯誤進行分析,發現未檢測的原因主要在于以下三點:(1)數據屬于孤立信息或者約束較少,例如RBC的號碼92570107被修改成91111111;(2)名稱信息完全屬于自然語言,只有基本規范,沒有明確限制,例如D1改成D111;(3)連續性數據只能約束異常數據,如坡度取值1.5‰被修改為1.4‰無法驗證。通過原因分析發現,不能檢測錯誤數據的原因不在于方法;導致以上類型數據無法進行驗證的根本原因在于列控數據定義的自身缺陷,缺少相關數據約束,所以本文提出的數據驗證方法具有可行性。 本文針對列控數據校核任務困難的問題,提出了基于Prolog的列控數據驗證方法。針對列控數據表格的多樣性、獨立性,期望建立基于XML的新型數據存儲格式。通過鐵路總公司數據規范、領域專家知識和數據挖掘三種方式,提取出數據驗證規則,用于驗證模型搭建,保障了驗證模型的完整性,提高了驗證模型的驗證準確性。以武漢—廣州線的列控工程數據為數據樣本,通過驗證測試與分析,說明了本文提出的列控數據驗證方法具有高效性和準確性。5 實驗分析

6 結束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
