基于視覺的行人引領移動機器人導航方法研究
2019-07-11 04:59:44曹志強喻俊志
導航定位與授時 2019年4期
龐 磊,曹志強,喻俊志
(中國科學院自動化研究所 復雜系統管理與控制國家重點實驗室,北京 100190)
0 引言
移動機器人通過跟隨一個領航員以實現導航是一種便捷的導航方式。近年來,移動機器人的行人引領導航在多種應用場景中被廣泛使用,例如老人看護機器人[1]、智能輪椅[2]、載貨機器人[3]等。
在機器人的行人引領導航中,實時地定位目標是順利實現導航的核心問題。近年來,已經有很多研究者通過多種類型的傳感器實現移動機器人的行人引領導航,其中包括超聲波傳感器[4]、單線激光雷達[5]、射頻識別(Radio Frequency Identifica-tion,RFID)[6]、RGB-D相機[7]、雙目相機[8]等。由于基于視覺的方法可以利用更豐富的顏色、紋理等信息,所以相對于基于超聲波[4]和單線激光[9]等測距傳感器的方法,基于視覺的方法在領航員定位以及在多人環境中分辨領航人員方面具有更大的潛力。
在基于視覺的行人定位和跟蹤方法中,使用RGB-D相機并利用骨架跟蹤框架[10]是一種常見的行人跟隨方案,但受限于RGB-D相機適用的工作場景,該類方案更適合用于室內環境中。另外,基于視覺跟蹤器的方法是一種流行的方法[6,8,11],視覺跟蹤器一般通過在線學習和更新目標的外貌特征來定位目標,這類方法容易受環境或者目標的劇烈變化影響而失效,且一般不具備處理遮擋的能力和重新初始化的能力。
對于處理行人遮擋問題,一些學者提出了使用分塊跟蹤和匹配的方法[12-13],此類方法對于處理部分遮擋的情況比較可行,但仍然取決于分部特征和匹配策略的魯棒性。利用RGB-D相機或者雙目立體相機提供的深度信息檢測和處理遮擋也是一種常用的方法,但此類方法容易受深度圖精度的影響[14]。此外,在有多個行人干擾或遮擋的場景中辨認領航員也是一個比較困難的問題,一些學者利用人體特征區分領航員與干擾行人,例如身高、衣服顏色、行走步態等[15-16]。
為了解決行人引領導航中的領航員定位問題,本文使用一個卡爾曼濾波器跟蹤領航員的位置和尺度,并利用基于深度神經網絡的行人檢測器檢測行人。同時,提出了2個指標關聯檢測結果和卡爾曼濾波器預測結果,將關聯的檢測結果用于更新卡爾曼濾波器。另外,還創新性地引入了一個使用大規模行人重識別數據集訓練的孿生神經網絡用于在多個行人中辨認領航員。最后,通過視頻實驗及機器人實驗證明了所提方法的有效性。
1 行人引領導航問題描述
為了使一個移動機器人跟隨指定的領航員,機器人需要實時獲取領航員與機器人之間的相對角度和距離。如圖1所示,一個雙目立體相機被安裝在移動機器人的超前方向,并且設置機器人的坐標與雙目相機左攝像頭的坐標一致,記為OXCYCZC。坐標系統OXCYCZC的原點O為雙目相機左相機的光心,其中ZC軸沿左相機的光軸方向,XC軸為機器人水平向左方向。

圖1 移動機器人行人引領導航系統示意圖Fig.1 Schematic diagram of the leader-guided system for mobile robots
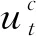
(1)
其中,Rh和Θ分別為左相機在水平方向的分辨率和視場角,分別為1080和72°。然后,在對應于左相機的深度圖像上,基于Bt包圍框估計領航員與機器人之間的距離dt。
(2)
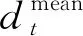
2 基于視覺的領航員定位方法模塊
2.1 行人檢測器
目標檢測器可以在不具備幀間運動信息的情況下在每一幀圖像上檢測出多種類別的多個目標。近年來,基于深度神經網絡的端到端檢測器可以在圖形處理器(Graphics Processing Unit,GPU)的加速下快速準確地檢測多種類別的物體。對于基于視覺的移動機器人行人引領導航方法,需要在圖像中實時定位目標,而基于行人數據訓練的行人檢測器可以提供行人包圍框,為實現領航員提供了非常有用的信息。
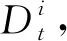
2.2 卡爾曼濾波器
行人檢測器雖然能夠在每一幀圖像中獲取多個行人的位置,但是無法獲得行人之間的身份信息,即無法在多個行人之間辨認出指定的領航員。因此,本文引入了一個卡爾曼濾波器FK預測目標位置和尺度,并通過對比FK的預測結果和檢測器結果在多幀之間持續定位領航員;同時,使用FK可以減少由于檢測器漏檢造成的不利影響。卡爾曼濾波器的狀態被定義為
S=(x,y,a,r,Δx,Δy,Δa,Δr)T
(3)
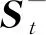
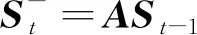
(4)
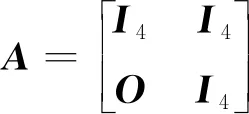
此外,為了使FK保持對領航員的跟蹤,確認為是領航員的行人檢測器結果DA被用作測量值zt利用,式(4)更新FK狀態。
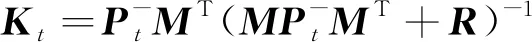
(5)
其中,M=I4是測量矩陣,K是卡爾曼增益,R是測量噪聲的協方差矩陣,zt是由DA計算得到的四維測量向量 (x,y,a,r)。在機器人行人跟隨過程中,更新后的FK狀態被用于計算領航員包圍框Bt,并基于更新后的Bt計算目標的距離;然而,當沒有檢測結果被確認為與Bt關聯時,則以FK的預測狀態計算目標的位置。
2.3 基于孿生神經網絡的行人重識別模塊
行人重識別是一種廣泛應用于視覺監控領域的技術,旨在多個無重疊且不同視角的攝像機中辨別出同一行人。該技術對于機器人行人跟隨過程中,需要配合行人檢測器重新定位或搜索出領航員是非常有效的。本文中使用一個基于大規模行人重識別數據集訓練的孿生網絡[18]來提取行人特征,通過提取的特征對領航員外貌進行抽象表達。該網絡同時結合了驗證模型(verification model)和識別模型(identification model)的優點,同時使用兩種損失函數訓練模型,有效提高了特征表達的魯棒性。
本文以孿生網絡輸出的4096維全連接層特征作為對領航員的特征表達(fc描述子),并設立一個包含N個fc描述子且每隔50幀更新一次的目標特征庫GI={f1,f2,…,fN}。在需要驗證行人身份信息時,通過提取待驗證行人的fc描述子,記為fI,并計算其與GI中每一個描述子的余弦相似度的均值作為評估候選者為領航員的可能性SI,即
(6)
3 基于視覺的行人跟隨方法
為了完成移動機器人行人跟隨,本文使用了基于視覺的行人檢測器、卡爾曼濾波器以及一個基于孿生神經網絡的行人重識別模塊在行人跟隨任務中持續定位目標。利用2個指標,通過3個模塊之間的配合,實現了對領航員的持續定位。圖2所示為3個模塊之間的關系示意圖。
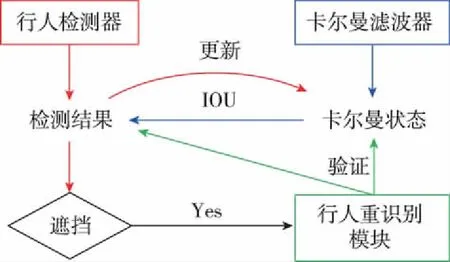
圖2 模塊關系示意圖Fig.2 Schematic diagram of the relationship between the proposed modules
(7)
其中,取得最大交-并面積比IOUmax且滿足如下條件的候選人被認為是領航員。
IOUmax=max(IOUi)≥TIOU
(8)
這里TIOU的值設定為0.3。
在無行人干擾的情況下,依據空間位置的連續性判斷檢測結果之間的關聯性是一種安全的策略;然而,當領航員周圍出現干擾行人甚至出現遮擋情況時,需要借助更多的信息以更好地判斷檢測結果的身份信息。因此,移動機器人需要判斷領航員周圍干擾的存在情況,并且在確認干擾存在的情況下,使用行人重識別模塊來增強檢測結果在多幀之間關聯的可靠性。
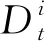
SI≥TI
(9)
4 實驗驗證
4.1 室外場景視頻實驗
本實驗及機器人實驗的視頻使用一個ZED雙目立體相機采集,該相機可以同時輸出RGB圖像和深度圖像。此視頻實驗為校園場景的室外環境,該實驗包括行人姿態變化、光照變化、行人干擾等諸多挑戰。為了更好地說明所提方法的有效性及優越性,此節進行了所提方法與行人引領導航中常用的TLD[19]的比較。該實驗的結果如圖3所示,由此可見,目標在行走較長距離后仍然能準確定位目標。如圖3中第300幀和第330幀圖像所示,當目標穿越光線條件復雜的走廊時,所提方法仍然能夠準確定位領航員。而對比方法TLD[19]從第151幀后便無法再次準確地檢測和跟蹤目標,如圖3中第350幀所示,其檢測到錯誤的目標。

圖3 視頻驗證實驗的實驗結果,其中藍色包圍框為手工標注 的真值,黃色包圍框為行人檢測器結果,紅色包圍框為所提方法 輸出的領航員位置,品紅色的包圍框為對比方法TLD[19]的Fig.3 Results of the video experiment. The blue bounding boxes are the locations of the manually labeled ground truth, the yellow bounding boxes are results of the proposed pedestrian detector, and the red bounding boxes are results of the proposed approach, the magenta bounding boxes are the results of the TLD[19]
此外,此實驗中包括2次行人干擾情況。其一,如圖3第188幀和第210幀圖像所示的場景中,所提方法在第188幀檢測到周圍存在行人干擾,并啟動行人重識別模塊,該過程中關聯檢測結果和卡爾曼濾波器預測結果需要同時考慮式(8) 和式(9)。其中行人重識別模塊輸出的分數SI如圖4所示,該過程中所提方法能一直跟蹤領航員位置,且行人重識別模塊驗證DA的身份信息時均滿足條件式(9),故卡爾曼濾波器可以及時被更新并輸出準確的領航員位置。
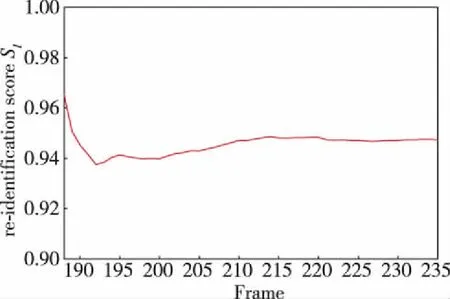
圖4 行人重識別分數SI曲線(188~235幀)Fig.4 Curve of re-identification scores SI (frames 188~235)
由圖3中第404~444幀圖像所示,另外一次行人干擾出現,此過程中行人重識別模塊輸出的分數SI如圖5所示,由SI可知所提方法仍然能夠準確定位目標。因此,在目標姿態連續變化后,所提方法仍然可以準確確認領航員的身份信息,證明了本文所提的行人重識別模塊及設計的目標特征庫GI是有效的。
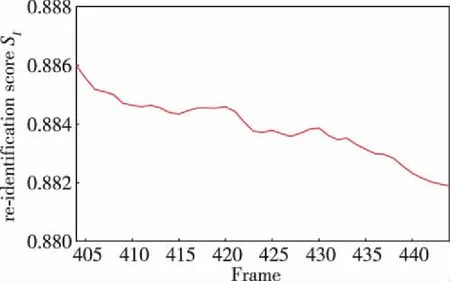
圖5 行人重識別分數SI曲線(404~444幀)Fig.5 Curve of re-identification scores SI (frames 404~444)
此實驗采用手工逐張標注的方式獲得目標行人的包圍框真值,并計算了所提方法和TLD在此次實驗中的精確度,其中包括2個指標:精確度曲線和成功率曲線,如圖6所示。精確度曲線計算跟蹤算法估計的目標包圍框的中心點與人工標注的目標包圍框的中心點之間的距離小于給定閾值的視頻幀的百分比。成功率曲線通過計算跟蹤算法估計的目標包圍框與人工標注的目標包圍框的交面積與并面積的比值在某個重疊率閾值范圍內的視頻幀的百分比。
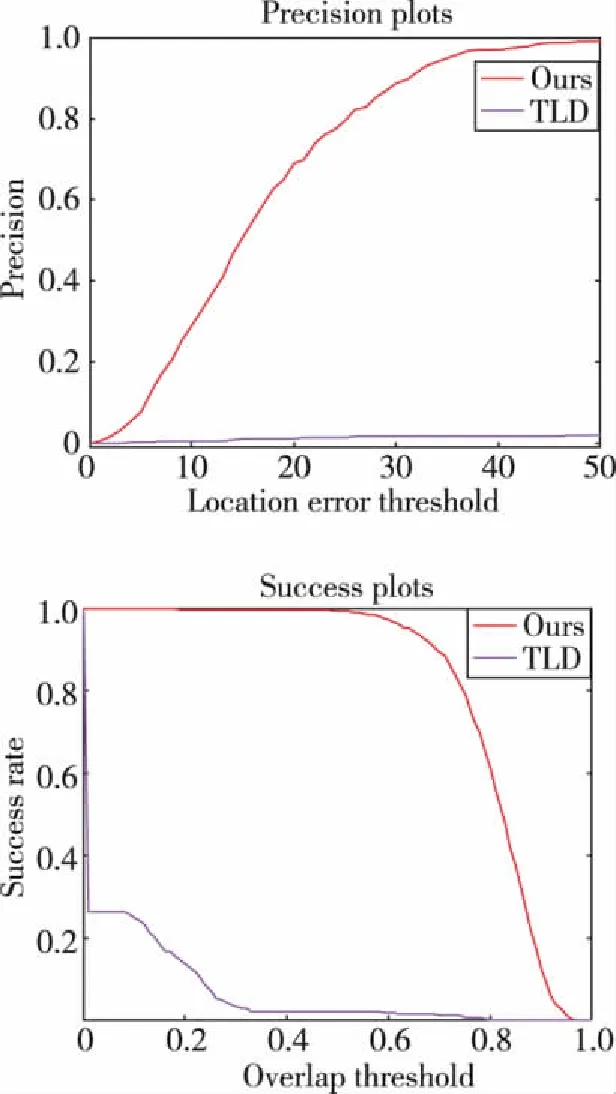
圖6 所提方法和TLD[19]在視頻驗證實驗中的 精度和成功率評價Fig.6 Precision and success evaluation in the verification experiment of the proposed approach and TLD[19]
4.2 機器人實驗
為了驗證所提方法能夠在機器人上有效定位目標,在EAI 輪式機器人上進行了行人引領導航實驗,其中實驗場景如圖7所示。實驗中移動機器人根據所提算法提供的Bt,通過式 (1) 計算目標與機器人之間的夾角,并根據Bt在深度圖像上利用式 (2) 估計領航員于機器人之間的距離信息dt。基于領航員與機器人之間的方向夾角和距離信息,控制機器人的速度和方向使機器人跟隨領航員,并保持一定的距離范圍,從而實現行人引領導航。需要指出的是,由于本文所提方式使用了基于深度神經網絡的檢測器SSD以及孿生神經網絡,為了保證在機器人上運行的實時性,需要使用配備有GPU的計算單元,因此本文所提方法運行時的功耗相對較高。

圖7 機器人實驗示意圖Fig.7 Schematic diagram of the experiment on the mobile robot
5 結論和展望
本文提出了一種結合基于深度神經網絡的行人檢測器、卡爾曼濾波器及基于行人重識別數據集訓練的孿生神經網絡的行人定位方法。該方法創新性地引入了視頻監控領域的行人重識別技術,用于在多個干擾行人之間辨認領航員,實驗證明了行人重識別模塊和其他模塊配合能夠有效地定位目標并處理行人干擾問題。基于此方法并利用雙目相機提供的RGB和深度圖像能夠實時獲取行人引領導航所需的領航員方向和距離信息。另外,本文通過視頻實驗及機器人實驗證明了所提方法的有效性。
在未來工作中,將繼續改進行人定位方法,提高機器人行人引領導航的穩定性。同時,為了提高在機器人引領導航過程中的安全性,將關注能與行人定位方法配合使用的避障算法和局部路徑規劃算法。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
北京航空航天大學學報(2022年6期)2022-07-02 01:59:12
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
北京航空航天大學學報(2017年9期)2017-12-18 07:12:25
制造技術與機床(2017年3期)2017-06-23 08:11:21
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
電源技術(2016年9期)2016-02-27 09:05:39
電源技術(2015年1期)2015-08-22 11:16:28
中國海洋大學學報(自然科學版)(2014年8期)2014-02-28 12:21:31
