新一代人工智能技術驅動下的新藥研發
2019-07-04 02:51:52蒲小平
中國藥理學通報 2019年7期
吳 昊,林 銘,孫 懿,趙 欣,蒲小平
(北京大學藥學院分子與細胞藥理學系,北京 100191)
新藥研發是一項復雜的工程,具有高風險、高投入、周期長的特點。利用傳統方式開發新藥的費用已接近25億美元,而且每9年會增加1倍,不僅如此,傳統開發新藥的方式漫長而且效率低下,近九成的藥物在Ⅰ期臨床階段就會被淘汰[1]。因此,國內外藥品公司都積極地將人工智能(artificial intelligence, AI)技術應用于新藥研發(Tab 1),以提高研發效率,即能在早期通過計算生物學和生物信息學等手段,篩選除去無活性藥物,并形成新的藥物開發模式。所以,本文將圍繞以“統計學習”為特征的新一代AI技術驅動下的新藥研發,探究AI技術對傳統新藥研發模式的顛覆性改變。
1 AI技術在整合表型篩選中的應用
一般來說,傳統新藥研發的起點是利用分子生物學結合生物信息學相關數據,分析確定疾病治療的有效靶點,再圍繞靶點逐步尋找活性藥物。在開發過程中,一般利用虛擬篩選(virtual screening,VS)、高通量篩選(high throughput screening,HTS)和高內涵篩選(high content screening,HCS)[2]等。其中,確定疾病靶點以及靶點相關基因和蛋白的過程耗時耗力,嚴重影響新藥研發進程。與傳統新藥研發相比,AI技術具有明顯的優勢,能利用大數據樣本表型篩選的方法,加快復雜疾病新藥研發的速度和效率。
1.1 表型篩選及其優勢表型篩選是在疾病靶點不明確,而且發病機制不清楚的條件下,基于生物體表型改變來進行藥物篩選。相對于傳統體內和器官/組織表型篩選,結合了AI技術的現代表型篩選適用于更復雜的病理生理過程,并且能在細胞水平利用表型改變來篩選新的化合物[3]。一般來說,先導化合物篩選過程中,常用到3種類型細胞表型篩選方法,分別是細胞活力測定、細胞信號通路分析和疾病相關表型分析。此外,細胞表型篩選還會用于細胞自噬、凋亡、細胞分泌、細胞運動、細胞核易位、骨架重排等[4]。
AI篩選平臺和高敏感檢測系統的發展,更推進了表型分析小型化和大型樣品庫的快速篩選[5]。Berg Health公司Narain等[6]通過將轉移性前列腺癌PC-3細胞系暴露于模擬的腫瘤微環境中(氧氣不足、低pH和營養不足),分別在培養24、48 h后,吸取15 mL條件培養基進行蛋白質組學分析,再使用AI貝葉斯神經網絡推斷方法分析蛋白質組數據,生成每個特定因子的獨特概率模型,再根據功能變量子網的Burt約束度量得分進行排名,找到潛在的前列腺癌生物標志物Filamin-A和Filamin-B等,并在前列腺癌患者血樣中得到驗證。
在過去的20年里,藥物靶點篩選一直是新藥研發的主流,而到近十年,AI技術的崛起,使得基于表型篩選的方法回到人們的視線,又重新成為藥物篩選和先導化合物發現的趨勢(Fig 1)[5],像白血病治療的溴結構域抑制劑篩選[7]、丙型肝炎病毒NS5A抑制劑開發[8]等。這一改變主要是因為AI技術在藥物研發方面具有的優勢,使人們進一步意識到基于靶點篩選方法的缺陷,即對于多數靶點不明確、發病機制多樣的復雜疾病,其局限性較大。此外,再利用批準藥物的表型篩選方法,還能明顯減少潛在藥物的臨床前開發時間和成本[9]。新藥研發的模式也因此從單一的分子靶點篩選向整合表型篩選轉變[10]。不過,表型篩選并不能有效確定藥物作用機制和靶點,因此不能完全覆蓋靶點篩選的功能,這是目前表型篩選未能被藥企普遍接受的主要原因。

Fig 1 Development of drug screening methods Black wireframe indicates phenotypic screening

Tab 1 Selected collaborations in AI-drug discovery space
1.2 基于細胞圖像組學的表型篩選細胞圖像組學是指利用AI技術,將模擬疾病的細胞模型圖像進行形態學分析,建立疾病的細胞表型數據庫,并確定疾病的指紋特征。而基于細胞圖像組學的表型篩選則是將指紋特征和大量化合物測定的生物學活性相結合,構建特征-活性網絡,再根據特定化合物的細胞特征信息,來確定其生物學活性并進行篩選[11]。與基于靶點藥物篩選缺乏細胞學信息相比,基于細胞表型圖像藥物篩選可以提供更多的生物學信息,通過相互作用蛋白所處的細胞環境和信號網絡相關信息,并能保留高通量篩選能力[12]。美國猶他州Recursion Pharmaceuticals(遞歸醫藥)利用HTS經過大量的分析開發后,決定采用6種熒光染料進行染色,包括Hoechst 33342(DNA)、伴刀豆球蛋白A/Alexa Fluor 488結合物(內質網)、SYTO 14綠色熒光核酸染色(核仁,細胞質RNA)、鬼筆環肽/Alexa Fluor 568結合物(肌動蛋白)、小麥胚芽凝集素/Alexa Fluor 555結合物(高爾基體,質膜)和Mito Tracker深紅(線粒體),在5個通道成像,并能在單個顯微鏡中區別以上8種細胞成分或區室,再借助開源軟件CellProfiler提取每個細胞的1 000多個形態特征,從形態學上反映細胞的表型信息,再對上百種罕見病的幾萬張細胞圖片進行特征分析,從而找到罕見病的指紋特征(Fig 2)[13]。之后,結合自動化生化指標檢測,實現大規模并行化的高通量藥物篩選。目前,該公司已經確定了幾十種罕見疾病有前景的候選化合物,例如,治療2型神經纖維瘤病(neurofibromatosis type 2,NF2)的mTOR受體抑制劑AZD2014和VEGF c-KIT激酶抑制劑PTC99等[14],還與賽諾菲(Sanofi)集團建立合作關系,以評價開發過程和臨床前測試中獲得成功的化合物。此外,Cell Image LibraryTM在線有各種細胞圖像、視頻和動畫以及藥物處理后的細胞形態學數據,有利于其他團隊使用該技術進行采集、分析和比較細胞圖像,免費提供數據庫,實現資源共享。
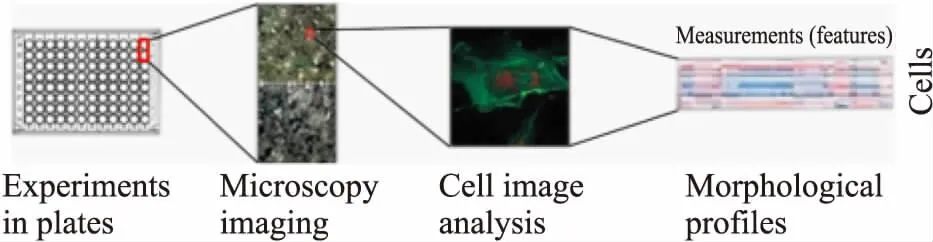
Fig 2 Morphological analysis based on cell phenotype images
基于細胞圖像組學的表型篩選雖然滿足了大量化合物快速篩選以及活性測定的需求,但仍未解決無法有效確定藥物作用機制和靶點的問題,因此,該技術目前還只是被AI技術團隊使用。
2 小樣本學習在新藥研發中的應用
從小樣本中學習和概括的能力是人類智慧的標志[15]。道格拉斯·霍夫斯塔特(Douglas Hofstadter)曾指出,只有全面的AI技術才具備人類處理文字的靈活性,而小樣本的學習能力正是其中重要的一環[16]。AI技術已經在大數據樣本中獲得成功(Tab 1),尤其是深度學習(deep learning),通過搭建多個神經網絡,實現對大量標記樣本的學習,而且樣本越大,診斷精準度越高。所以,AI技術實現對小樣本學習(one/few/low-shot learning),可以推動AI向小樣本學習模式的發展,有利于在缺乏大樣本的疾病中進行新藥研發,并降低成本。
2.1 遷移學習和半監督學習對于某些情況,比如確定個體沙門氏菌血清型[17]等,研究者只能夠獲取單個或幾個樣本,有時還是未知樣本。為了實現小樣本學習,AI技術常會用到遷移學習(transfer learning)以及半監督學習(semi-supervised learning)等。遷移學習指先在樣本源領域(source domain)訓練,再把整合的知識遷移到目標領域(target domain),從而將已知的樣本信息與小樣本目標信息進行聯系。研究者往往將遷移學習和深度學習結合,形成深度遷移學習(deep transfer learning)。美國芝加哥大學Huynh等[18]先從小樣本乳腺癌圖像數據庫中找到每個圖像中病灶的感興趣區域(region of interest,ROI),并進行截圖標記(良性或惡性)作為目標集,再通過非醫學任務預訓練的卷積神經網絡,從該小樣本醫學圖像集中提取腫瘤信息,再借助支持向量機分類器進行特征分類,之后利用接收器操作特征分析和交叉驗證進行模型評估,最終很好地完成了對乳腺癌的準確診斷,并發現潛在的藥物作用靶點。此外,遷移學習還可用于阿爾茨海默病、前列腺癌等的準確診斷。所以,遷移學習有利于小樣本信息分析,能夠推動精準醫學中AI技術的發展。
而半監督學習通過標記的小樣本信息和未標記的大樣本信息進行訓練和分類,從而完成小樣本學習。Chen等[19]通過基于網絡的拉普拉斯正則化最小二乘協同藥物組合預測(network-based Laplacian regularized least square synergistic drug combination prediction,NLLSS)算法,整合少量已知的協同抗真菌藥物組合和大量未知的抗真菌藥物組合,并根據發揮協同作用的藥物具有相似的性質,同時借助藥物-靶點相互作用和藥物化學結構來檢測藥物相似性,從而預測潛在的協同藥物組合,結果證明,NLLSS可以有效識別潛在的協同藥物組合,探索藥物的新適應癥,并有助于協同藥物組合的潛在分子機制研究。加拿大Hao等[20]則通過間接闡明陽性無標記學習(positive unlabeled learning for splicing elucidation,PULSE)算法,利用剪接、進化、調節性、蛋白質組學、結構功能等5個維度,共計48個預測特征的小樣本蛋白質異形體(protein isoforms)數據集和大量未標記的蛋白質異形體數據集,進行半監督學習,首次成功預測約32%的“外顯子跳躍”選擇性剪接事件會產生穩定的蛋白質,并獲得了大量推測的和未表征的蛋白質,再對預測的活性蛋白質異形體進行結構分析,包括剪接掉PK酶結構域261~271片段的BRSK2蛋白質異形體、剪接掉WD40結構域431~496片段的多聚體調節因子1蛋白質異形體等,找到疾病特異的蛋白質異形體(disease-specific protein isoforms),有助于疾病預測和靶點研究。
2.2 基于高維小樣本數據的靶點篩選高維數據是多變量數據,使用更多變量來描述樣本,而不增加要分析的樣本數量,而且變量的數量往往超過了樣本的數量。例如,同時測量所有已知基因的表達(大于20 000),但研究中受試者血樣可能只有幾百個[21]。如何方便有效地實現高維數據可視化,一直都是國內外科研機構關注的問題。而AI技術通過深度自動編碼器的反向傳播,實現了高維數據的非線性降維,并能保留全局特征[22],因此,可以幫助人們分析并整合疾病高維數據和遺傳信息,以便更好地找到對藥物篩選有價值的作用靶點。由于研究樣本的復雜性,小樣本數據往往以高維數據形式被獲取。目前,基于高維小樣本數據的疾病靶點篩選方法還在逐步完善當中。中國科學院陳洛南團隊將高維小樣本動態網絡生物標志物應用于流感病毒感染和癌癥轉移的數據集,來準確識別疾病的臨界狀態,以進行個體化疾病診斷,并能分析疾病進展的分子機制。此外,還能識別許多非線性生物過程的臨界狀態,如細胞分化和細胞增殖等,這有助于找到潛在的藥物靶點[23-24]。加拿大Chao等[25]則通過動態基因組信息,借助于微陣列雜交(microarray hybridization,MH)和MAS5算法,找到選定血樣集中穩定的探針組,再對挑選出的探針組進行評估和優化,從而利用單個外周血液樣品找到多種疾病的生物標志物,包括精神疾病、骨關節炎、心血管疾病、胃腸道疾病、腫瘤等,從而獲得每個患者的多種疾病患病風險,為組織活檢提供了替代方案,也便于不同疾病的診斷和預后,以及藥物潛在靶點的篩選。
總之,隨著小樣本學習的發展,基于高維小樣本數據的新藥研發會使AI技術變得更加全面、成熟。
3 AlphaGo Zero在新藥研發中的應用
2018年,AI技術出現重大突破,英國雜志Nature發表重磅文章,指出AlphaGo Zero只使用單一的深度強化學習(deep reinforcement learning)算法和蒙特卡羅樹搜索(Monte Carlo tree search, MCTS)[26],從空白狀態學起,無人工監督,利用自我對弈模型來不斷迭代,進而找到全局最優解。其中,自我對弈模式可以類似地理解為近似策略迭代方案,由MCTS來進行策略評估和策略優化。AlphaGo Zero已經擊敗了AlphaGo及其升級版AlphaGo Fan、AlphaGo Lee等,而且只使用1臺機器和4個張量處理單元(tensor processing unit,TPU),非常節省資源[27]。AlphaGo Zero的成功,表明深度強化學習算法在沒有大量先驗知識的情況下,能很好地完成復雜任務,突破了現有AI技術需要樣本訓練集的局限性。
最近,德國Segler等[28]通過深度學習神經網絡和MCTS,利用Reaxys化學數據庫學習已知的大約1 240萬個單步化學反應,再反復訓練進行算法優化,使其可以預測單步可用的化學反應。再結合指導搜索的擴展策略網絡和過濾網絡,預先選擇目標化合物的最優合成路線,大幅提高了化合物合成效率。該算法被稱作“化學界的AlphaGo”,具有劃時代意義。而AlphaGo Zero比AlphaGo學習能力更強,所以,AlphaGo Zero理論上具備更強的處理復雜問題的能力,將會進一步推動新藥研發的快速發展。
4 展望
AI技術通過高維數據分析結果來生成假設,改變了新藥研發“先假設再驗證”的傳統模式,此外,AI技術可以利用小樣本學習,進一步推動精準醫學和個體化醫療的發展。而AlphaGo Zero的成功表明機器無需幫助就可能超越人類,為AI技術帶來重大突破,但AlphaGo Zero的成功經驗能否拓展到新藥研發,還需要進一步探索和研究。目前,世界上還沒有AI技術研發的新藥被批準上市,然而,Berg Health公司的候選藥物BPM 31510和BPM 31543均進入臨床研究階段,而BPM 31510預計會在2020年獲得FDA批準[29]。最近,美國國防高級研究計劃局(Defense Advanced Research Projects Agency,DARPA)開展的“AI Next”項目,使機器具備理解和推理能力,為人類開啟第3次AI浪潮[30],預計會為新藥研發策略帶來又一次革命性轉變。