基于梯度提升樹算法的夏玉米葉面積指數反演
2019-06-04 01:11:00張宏鳴韓文霆劉全中宋榮杰侯貴河
農業機械學報 2019年5期
張宏鳴 劉 雯 韓文霆 劉全中 宋榮杰 侯貴河
(1.西北農林科技大學信息工程學院, 陜西楊凌 712100; 2.西北農林科技大學機械與電子工程學院, 陜西楊凌 712100)
0 引言
葉面積指數(Leaf area index,LAI)是生態系統能量流動中極其重要的植被特征[1]。在LAI定義的不斷發展中,為了既可以適用針葉植被又可以適用闊葉植被,最終被定義為單位地表面積上綠葉表面積總和的一半[2]。傳統獲取LAI的方法主要依靠人工實地測量[3],不僅浪費人力,而且對作物破壞性極大。隨著遙感技術的不斷發展,獲取LAI的方法開始轉向于遙感反演[4-6]。目前,遙感數據主要來源于衛星和無人機,但衛星遙感屬于高空遙感技術,在獲取遙感圖像過程中易受到大氣因素的干擾[7]。且衛星遙感的研究區域面積適合在公頃以上,如果進行小范圍的區域研究,其分辨率受到一定的限制。因此,近年來產生了利用無人機搭載多光譜或高光譜相機的方式采集遙感圖像,該技術彌補了衛星遙感的不足,提高了圖像的地面分辨率,可快速準確獲得作物葉面積指數,為農情信息監測提供了有效手段[8-9]。
中國作為農業大國,玉米是不可或缺的農作物。長期以來,我國在作物的葉面積指數反演方面進行了相關研究[10]。早期在進行LAI反演時都選擇用單一植被指數作為輸入變量[11-12],但單一的植被指數存在不同程度飽和性[13],對于LAI的反演受到了一定的限制。之后的研究中發現,紅波段和近紅外波段的反射率與作物葉片的特征不僅最為密切相關且有別于其他地物[14],可組合出多種的植被指數,因而是當前用于LAI反演的常用波段[15]。為了可以融合多種與LAI相關性較強的植被指數及其他相關數據,衍生出了機器學習的方法。機器學習就單因子訓練模型進行了改進,利用多種相關因子的非線性擬合來構建較為精確的模型,使得驗證集與實際值之間的預測誤差最小,泛化能力最強[16]。
謝巧云等[17]利用高光譜數據進行作物LAI遙感反演,結果表明,非線性支持向量機模型最適宜用于研究區域冬小麥LAI反演;王麗愛等[18]將支持向量回歸和反向傳播神經網絡算法作為比較模型,證明隨機森林模型具有強學習能力和預測能力;張春蘭等[19]基于無人高光譜模型研究了4個生育期小麥的LAI,發現隨機森林模型LAI的反演精度較高,且適用性較強;HOUBORG等[20]發現,利用機器學習的方法,可有效分析和利用數量大、維度高的觀測數據。以上研究成果表明,機器學習中的回歸模型廣泛應用于作物遙感反演,且取得了較好的研究成果[21-22]。但回歸模型都存在小樣本數據出現過擬合的問題,且無法判斷輸入因子中的主要貢獻因子。梯度提升樹算法(GBDT)可以解決以上問題,該算法通過每一棵樹學習之前所有樹的殘差和結果,一步步迭代構建弱學習器,糾正原模型誤差,有效提高了預測精度[23],可作為反演夏玉米LAI的有效方法。
本文以2018年內蒙古自治區鄂爾多斯市達拉特旗實驗基地為研究區域,采集夏玉米無人機多光譜影像,提取關鍵生育期V3~R5(出苗期至初入蠟熟期)的8種植被指數,實測LAI及玉米株高。將株高和8種植被指數作為輸入變量,LAI作為輸出變量輸入SVM算法、RF算法、GBDT算法3個模型中訓練學習,以驗證GBDT算法反演模型在夏玉米LAI反演中的適用性。
1 材料與方法
1.1 研究區概況
實驗基地(40°25′46.99″ N, 109°36′35.68″ E)位于內蒙古自治區鄂爾多斯市達拉特旗昭君鎮,屬于典型的溫帶大陸性氣候,干旱多大風,主要糧食作物為小麥和玉米。實驗區所種作物為夏玉米,屬于春播中晚熟型,一年一熟。播種時間為2018年5月中旬,收割時間為9月。選取株高為60 cm,葉片寬度約兩指寬(3 cm左右)時進行田間玉米LAI實驗。由于當地的降水量無法滿足玉米生長期內的需水量,主要的供水方式為噴灌機灌水。據此,將研究區中的④區利用噴灌機作水分脅迫,使之除大氣降水外,額外供水量少于其余區域。研究區無人機影像如圖1所示,實驗區域面積約為1.13 hm2,以噴灌機為中心,分為5個扇形區域,每個扇形區域內劃分3個4 m×4 m的實驗樣方,即研究區總計15個小樣方。
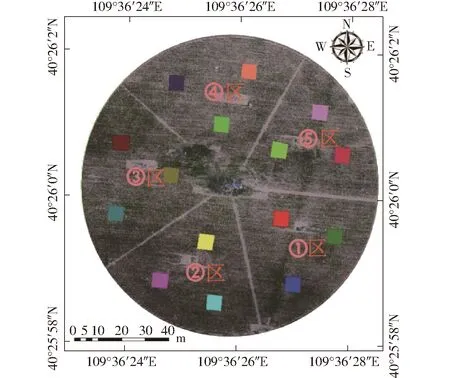
圖1 研究區無人機影像和分區示意圖Fig.1 UAV image and partition map of study area
1.2 數據的獲取與處理
田間夏玉米LAI的測量使用LAI-2200C型植物冠層儀進行。數據于2018年6月26日開始采集,2018年8月25日結束,共9次實驗,期間覆蓋夏玉米的V3(出苗期)、V6(拔節期)、VT(抽雄期)、R1(吐絲期)、R3(乳熟期)、R5(初入蠟熟期)6個關鍵生育期。前8次實驗數據用于建立模型,最后1次實驗數據用于模型預測及驗證。LAI采集方式采用ABBBB,即測量時,取4次冠下B值,一次冠上A值。由于玉米屬于行栽作物,測量方式通常采用對角線法:B值取樣點位于兩壟之間均勻分布,A值取樣點避免陽光直射,位于冠層上方。每個小樣方重復采集4組數據,取均值。考慮正午時分陽光強烈,測量時需配備遮光帽,以減少視野遮蓋帽周圍的反射光對數值的影響。夏玉米的株高在測量LAI時一同測量同一樣方對角線的點,在對角線3點的區域內每一點測量5組數據,取均值。
遙感圖像數據采集為六翼無人機RedEdge五波段搭載多光譜相機,相機焦距為5.5 mm,視場角為47.2°,圖像分辨率為1 280像素×960像素。相機配備了光強傳感器和兩個3 m×3 m的灰板。光強傳感器可對無人機航拍過程中外界光線的變化對光譜影像造成的影響進行校正,而灰板由于具有固定的反射率,可對航拍影像進行反射率的校正,從而生成反射率影像圖,進行植被指數的提取。相機的波段信息以及灰板的反射率如表1所示。實驗時晴朗無云,平均氣溫28.6℃,平均相對濕度61.96%,平均風速1.12 m/s,微風。時間在11:30—14:30。多光譜無人機飛行高度為70 m,飛行方向為南北方向,航向、旁向重疊度分別為80%和70%。將每次實驗按照固定航線拍攝的多張圖像,以日期為索引導入到瑞士Pix4D公司的Pix4D mapper軟件中,以實時動態(Real time kinematic,RTK)測量的方法獲取地面像控點,導入小圖對應的POS數據,在軟件中進行初始化處理,幾何校正,構建三維模型,提取紋理以及構造地物特征,最終生成高清正射多光譜影像。由于拼接預處理后的原始圖像包含除研究區域以外很大的區域,為了更加突顯遙感影像的作物特征,需在ENVI軟件中裁剪處理。根據可見光影像中的樣方對應裁剪出多光譜影像的15塊實測區域,每一塊實測區域一一對應實驗樣地的每一小樣方。取裁剪后每一小樣方的對角線3點,生成這3點對應的各項植被指數,最終以均值來確定每個小樣方的植被指數。
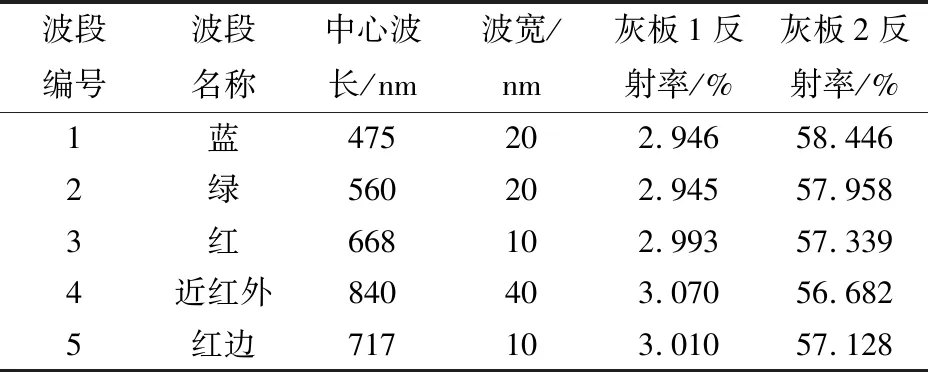
表1 RedEdge多光譜相機參數及灰板對其中心波長的反射率Tab.1 Multispectral camera parameters and reflectivity of gray plate to its center wavelength
由于正午時分和黃昏時分葉片的蜷縮程度受溫度影響會有一定的區別,且在不同的時間段接收的光譜信息也有很大的差異,因此多光譜影像數據和地面數據采集需在同一天的同一時間段。
1.3 植被指數的提取
植被對于不同波段入射光子的吸收作用和散射作用不同,形成了特殊的光譜響應特征。由于植被和農作物在紅光波段強吸收和在近紅外波段強反射的特性,大量的研究證明這兩個波段與作物覆蓋度和LAI具有很好的相關關系[24]。因此本文借鑒前人研究,選擇紅光、綠光和近紅外波段組合出與LAI相關性較強的8種植被指數進行LAI反演,各計算公式[25-26]見表2。

表2 植被指數計算公式Tab.2 Formulas of vegetation index
注:RNir、RRed、RGreen分別為灰板對RedEdge相機近紅外、紅波段、綠波段的平均反射率。
1.4 模型構建
1.4.1支持向量機
支持向量機(Support vector machine,SVM)中的支持向量回歸(Support vector regression,SVR)是早期機器學習中常用的回歸模型。SVR就是尋找一個最優的回歸平面,讓集合中所有的數據到這個回歸平面的距離最近[13]。本文選擇了SVM中優化的LIBSVM庫進行夏玉米的LAI預測。LIBSVM[27]具有操作簡單、快速有效和可處理高維空間數據等特點,常用來做分類和回歸。支持向量回歸與傳統的回歸模型相比,優點是此算法可容忍基于模型的輸出f(x)與真實的輸出y之間有ε的偏差,也就是當|f(x)-y|>ε時才計算損失。但SVM算法對非線性問題沒有通用的解決方案,難以找到合適的核函數。
1.4.2隨機森林
隨機森林(Random forest,RF)是決策樹的集成算法,通過對大量分類樹的匯總以提高模型的預測精度,是取代神經網絡等傳統機器學習方法的新算法。隨機森林算法中包含多個決策樹來降低過擬合風險[28],思想是Bagging算法和隨機特征選取[20]。隨機森林通過對訓練樣本重新采樣的方法得到不同的訓練樣本集;在新的訓練樣本集上分別進行訓練學習,由于每個學習器相互獨立,所以此類方法更容易并行;最后合并每一個學習器的結果,從而得到最終的學習結果。隨機森林的一個缺點是在噪聲較大的分類或者回歸問題中容易過擬合。
1.4.3梯度提升樹
梯度提升樹(Gradient boosting decision tree,GBDT)是集成學習中重要的一種算法,是基于Booting算法的一種改進[29-30]。Booting算法的工作原理是在初始訓練集樣本上給每個訓練樣本賦予相同的權值,在每一次訓練之后對于出錯的樣本進行增加錯分點的權值,在經過多次迭代后,生成相應的多個基學習器,之后對于這些基學習器進行組合,最終通過加權或投票得到模型。而梯度提升樹回歸與分類算法的區別是輸入的訓練數據是殘差,即將上一次的預測結果帶入殘差中求出本輪的訓練數據,而不是損失函數的梯度[22]。
梯度提升樹具有可靈活處理各種數據、預測準確率高、使用健壯的損失函數和對異常值具有很強的魯棒性等優點,可有效進行回歸預測。GBDT回歸算法如下:
(1)輸入訓練樣本
D={(x1,y1),(x2,y2),…,(xm,ym)}
(2)初始化弱學習器
式中L——損失函數
c——樣本y的均值
(3)計算負梯度
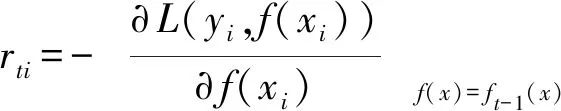
式中T——最大迭代次數
(4)利用(xi,rti)擬合一棵分類回歸樹(Classification and regression tree,CART)中的回歸樹,從而得到第t棵回歸樹,其對應的葉子節點區域Rtj(j=1,2,…,J),J為回歸樹t的葉子節點的個數。
(5)計算最佳擬合值
(6)更新強學習器
(7)得到強學習器表達式
(8)輸出為強學習器。
梯度提升樹算法中,所產生的樹是回歸樹而不是分類樹,GBDT的樹會累加之前所有樹的結果,這種累加的實現只能用CART回歸樹實現。
1.5 模型評價
以決定系數(R2)和均方根誤差(RMSE)來進行模型精度的評價。
為保證模型的有效性和穩定性,本文基于實驗分區來劃分不重復的訓練集和驗證集,將樣本3次分組,重復放入模型訓練學習。樣本組1的訓練集為區域①、②、④,驗證集為區域③和⑤;樣本組2的訓練集為區域②、③、⑤,驗證集為區域①和④;樣本組3的訓練集為區域①、③、⑤,驗證集為區域②和④。
2 結果與分析
2.1 植被指數相關性分析
基于前人對于作物LAI反演進展的研究,分析光譜特征信息發現作物LAI對于紅光參數與近紅外參數較為敏感,為后期的植被指數的選擇提供了方向。本文對3組樣本中8種植被指數和株高與LAI進行相關性分析,結果如表3所示, LAI與8種植被指數和株高在P<0.01水平呈極顯著相關,訓練集相關系數均不小于0.660,驗證集相關系數均不小于0.668。NDVI、OSAVI、RDVI、RVI、SAVI、EVI2、MASVI、TVI與LAI在總樣本中相關系數平均為0.777、0.765、0.751、0.769、0.747、0.743、0.744、0.715(P<0.01),因此可選擇此8種植被指數作為構建LAI反演模型的變量。而本實驗中新加入的實測株高在P<0.01水平下與LAI的相關系數均值也達到了0.769,說明株高與夏玉米的葉面積指數有著較強的相關性,可以選擇與8種植被指數一同作為SVM、RF和GBDT模型的輸入變量,進行夏玉米LAI的預測研究。
2.2 夏玉米LAI反演模型的構建
由于實地采集的樣本相對較少,因此選取3個區夏玉米生長關鍵生育期的9次實驗數據進行反演模型的訓練,8種植被指數和同期的株高共9個因子一同作為訓練模型的輸入變量,夏玉米LAI作為輸出變量,分別使用SVM算法、RF算法和GBDT算法來構建夏玉米LAI反演模型。SVM算法模型用LIBSVM庫來實現,核函數選擇徑向基,其余參數根據網格搜索法來確定最優參數;RF算法模型根據多次實驗,確定決策樹的數量為100,節點分割變量為3;而本文構建GBDT算法模型,用Python語言編寫回歸程序,根據輸入樣本組的不同,防止出現過擬合現象,需多次實驗確定每組訓練集的子模型數目(n_estimators)、損失函數(loss)、樹的最大深度(max_depth)等參數。
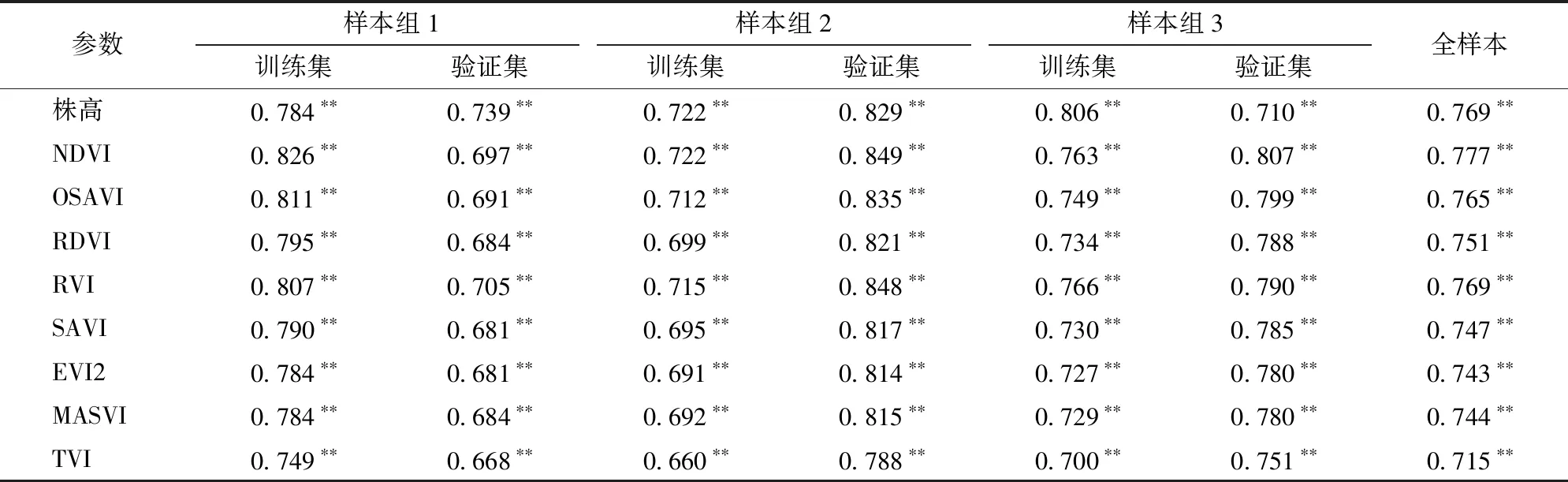
表3 植被指數與LAI相關性分析結果Tab.3 Correlation analysis result of LAI and vegetation index
注:** 表示在P<0.01水平上極顯著相關。
以樣本組2為例說明參數選擇過程:調參前,樣本組2由于選擇的樹深和子模型數目等過大引起過擬合(圖2a)。調參時,選擇最小絕對偏差(lad)為損失函數,n_estimators為500,max_depth為4,步長(learning_rate)為0.01,葉節點最小樣本(min_samples_leaf)為6,作為樣本組2的模型參數(圖2b)。由圖2可以看出,在提升迭代次數(Boosting iterations)為500時,訓練集偏差和驗證集偏差(Deviance)分別最小,500為最優的提升迭代次數,過大或過小都會造成預測精度的降低。
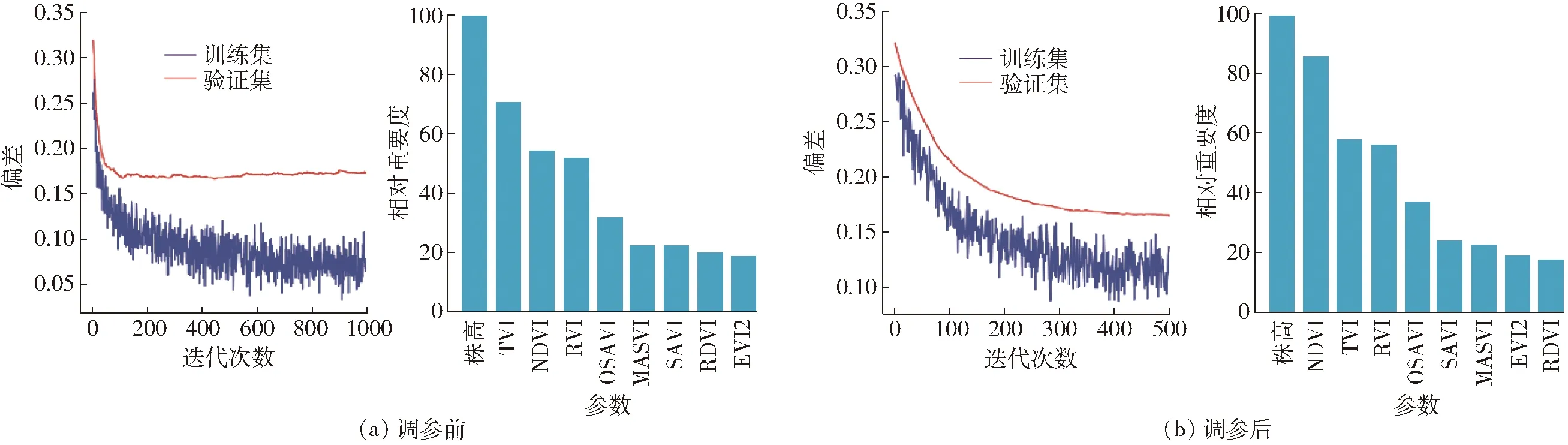
圖2 樣本組2調參對比Fig.2 Contradistinction of parameter adjustment for sample group 2
GBDT算法模型訓練結束后,會出現所使用輸入變量的相對重要度(Relative importance),便于理解哪些因素對于預測結果有關鍵影響力。同樣也可以判別出幾種由紅、近紅外波段組合出的與LAI強相關的相似植被指數中,對于夏玉米LAI反演結果的影響力強弱。由圖3可知,3組樣本中株高在相對重要度中比例占據第一,是影響模型精度的主要因素;而MASVI在3組樣本中相對重要度比例相對比較低,即MASVI對LAI反演模型的影響力較弱;綜合3組的變量重要性分析,株高對于LAI反演模型的結果貢獻較大,MASVI對于LAI反演模型的結果貢獻較小。
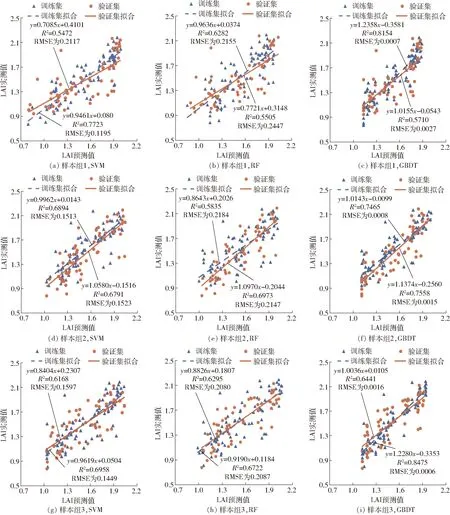
圖4 夏玉米LAI實測值與預測值關系Fig.4 Relationship graphs of measured and predicted summer maize LAI
2.3 夏玉米LAI反演模型比較分析
先將3組訓練集分別以3種算法進行訓練,不斷進行調參和多次迭代訓練,得到優化的模型;進而分別將3組樣本組中獨立于訓練集的驗證集,作為訓練模型的最后驗證;最后將訓練集和驗證集模型預測得到的LAI與實地測量的LAI分別進行散點圖分析,擬合成線性的回歸線(圖4)。
由圖4可知,GBDT算法對于連續值的預測效果較SVM算法和RF算法好。GBDT算法在每一樣本組中都體現出強大的學習能力,訓練集的決定系數R2分別為0.815 4、0.746 5、0.847 5,對應的RMSE為0.000 7、0.000 8、0.000 6;驗證集的決定系數R2分別是0.571 0、0.755 8、0.644 1,對應的RMSE為0.002 7、0.001 5、0.001 6。
2.4 夏玉米LAI空間分布
依據GBDT算法對3個樣本組反演結果的分析,選取效果最佳的樣本組2模型作為反演模型,對8月23日的數據進行研究區內夏玉米LAI反演,該研究區的夏玉米LAI空間分布如圖5所示。
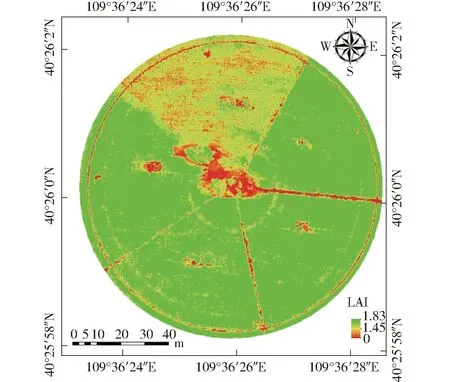
圖5 研究區夏玉米LAI空間分布圖Fig.5 Spatial distribution map of summer maize in study area
由圖5可知,8月23日的夏玉米LAI在①、②、③、⑤區主要集中在1.8左右,④區的LAI在1.4左右。與8月23日的實測LAI相比較,總研究區域實測均值為1.851 4,實測最大值為2.190 0,實測最小值為1.315 8。5個區域實測均值分別為2.092 6、1.795 8、2.087 0、1.406 9、1.888 1。由以上數據可知LAI反演數據與實測數據基本相符。整體上①、②、③、⑤區LAI較高,這是因為①、②、③、⑤區噴灌正常,玉米長勢均勻;研究區④夏玉米LAI較低,主要是因為④區進行了一定的水分脅迫,導致夏玉米生長較其余4個區緩慢,區域內作物稀疏;綜上,基于GBDT算法模型反演的LAI與研究區的LAI空間分布相對一致,進一步證明了該模型的合理性和可靠性。
3 討論
LAI反映的是葉片的疏密程度,隨著作物的生長,高度不斷增長,葉片的疏密程度按照稀疏-稠密-稀疏變化,高度表現出對于LAI的顯著影響。本文經過輸入變量相關性分析和輸出結果相對重要度分析兩方面佐證了株高對LAI具有極顯著關系,將遙感數據(植被指數)與實測數據(株高)相結合一同進行LAI的反演,可得到較好的反演效果。因此,LAI反演中不應只局限于遙感圖像提取的植被指數,還可考慮其他對于LAI有影響的因子。
機器學習算法與作物遙感反演密切相關,一個回歸能力很強的機器學習算法模型,可以融合眾多因子(多種植被指數和株高)共同反演LAI,大幅度提高結果的精度。本文將GBDT算法應用到農作物鄰域,反演夏玉米LAI。基于模型穩定性的考慮,分為3組樣本重復訓練,以8種植被指數和株高構建GBDT算法反演模型,并與SVM算法和RF算法R2、RMSE相比較,結果表明GBDT算法構建的模型兩項指標均高于SVM算法的模型,同樣也較同出一派的RF算法構建的模型性能有了進一步的提升。在后期的研究中可以將GBDT算法應用到玉米葉綠素、玉米生物量等作物相關參數的反演,以擴大精準農業技術支持的范圍。
GBDT算法的優勢在于將若干個弱學習器組合成強學習器,結果是多棵回歸樹的累加之和。由此算法構建的模型可以靈活處理各種數據,不論是本文中的LAI連續值,還是后續研究中作物冠層溫度的離散值;在小樣本的回歸問題中,GBDT算法可通過設置不同的損失函數以及在相對較少的調參時間下,提高反演精度。GBDT算法不僅減少了SVR模型因選擇核函數和其他參數造成的時間復雜度的浪費,而且也解決了RF算法對待各輸入因子是同一權值,無法判斷其中每一因子的貢獻率的問題。因此,GBDT算法在回歸問題中有很強的應用價值。但還需要注意兩點:①利用GBDT算法進一步判斷了在紅波段和近紅外波段組成的幾種相似植被指數的不同影響度,突出了算法的優勢,但在精度方面的后續研究中還有進一步提升空間。②GBDT算法中的基學習器之間存在依賴關系,一般難以進行并行計算。本文尚未考慮各個基學習器之間的并行操作,在今后的研究中應著重考慮如何實現部分的并行操作,進一步提高反演模型的效率。
4 結束語
將機器學習中梯度提升樹應用到夏玉米的LAI反演中,并與機器學習中的支持向量機和隨機森林算法進行了對比。該算法構建的模型與無人機多光譜圖像相結合,具有較好的反演效果,為實現大面積、無損夏玉米LAI反演和遙感監測作物長勢提供了技術支持。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
核科學與工程(2015年4期)2015-09-26 11:59:03
電測與儀表(2015年5期)2015-04-09 11:30:52
