以全基因組關聯分析大數據為基礎的孟德爾隨機化方法探索出生體重與兒童肥胖的關聯
2019-06-04 07:23:18梁穎娜黃宇婷李立新
中國循證兒科雜志 2019年2期
梁穎娜 黃宇婷 李立新
傳統流行病學研究認為兒童肥胖是成年后發生心血管疾病(CVD)、糖尿病和某些癌癥等的危險因素,且這些疾病的風險隨著兒童BMI的升高而升高[3]。但由于其固有的混雜或偏倚,是否能夠真正反映出生體重與兒童肥胖之間存在因果關聯仍不明確,營養與飲食、體力活動等偏倚在傳統的觀察性研究設計中往往難以控制,且不能被實驗研究所證實。
孟德爾隨機化(MR) 研究通過引入計量經濟學中工具變量的概念,MR研究利用遺傳變異作為社會或行為因素的替代指標,對給定的暴露和結局做出因果關系的判斷。MR研究過程基于以下假設(圖1):①基因工具變量單核苷酸多態性(SNP)與暴露因素相關,此過程一般以GWAS研究為依據,選擇合適的SNP作為工具變量;②基因工具變量的形成可看作隨機分配的過程,與混雜因素相關獨立;③工具變量只能過通過暴露因素作用于結局。在MR研究中,基因與結局的效應關系不會受到出生后社會環境和行為因素等常見的混雜因素和反向因果關聯的影響或歪曲,對于暴露因素的因果推斷具有獨特的優點。全基因組關聯分析 (GWAS)的成熟發展,為MR研究的開展奠定了基礎,亦為研究復雜疾病的發生發展機制打開了新的大門[8]。
1 方法
1.1 研究設計 本研究采用MR研究方法,以基因工具變量探討出生體重與兒童肥胖的因果關聯。以早期生長遺傳學聯盟(EGG)公開發表的基因數據為參考依據,篩選出與出生體重的關聯有統計學意義的SNP作為工具變量[10-11],借助篩選出的SNP, 通過不同的MR方法來判斷出生體重與兒童肥胖的因果關聯[12-14]。
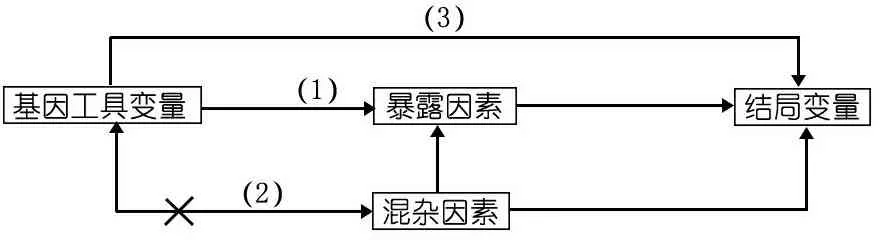
圖1 孟德爾隨機化應用模型示意圖
1.2 GWAS相關數據的來源和獲取 EGG能夠提供全基因組薈萃分析的摘要數據,包括相關染色體、基因組位置、效應等位基因及基因頻率、標準誤和P值等,超過200萬種已經通過質量控制的數據信息。本研究使用的GWAS結局變量的數據來自2012年Bradfield等[10]發表的關于新生兒肥胖與成人肥胖之間的遺傳性分析,新生兒體重的相關數據來自2016年Horikoshi等[11]發表的關于新生兒體重的文獻。數據獲取時間為2018年10月20日。
在數據獲取和分析過程中,借助MR-base平臺,得以在不直接獲取數據的前提下進行MR研究。MR-base平臺(http://www.mrbase.org)是由布里斯托大學醫學研究理事會(MRC)下屬綜合流行病學部門開發的關于MR數據庫和分析的計算機程序和在線平臺[15]。MR-base平臺可以使MR研究過程實現自動化,減少人為錯誤的風險,使得研究結果更為可靠。
1.3 篩選出生體重相關的SNP 參考文獻[16],設置篩選參數為P<5×10-8、連鎖不平衡r2<0.1,篩選出與出生體重達到基因組顯著性相關的SNP,將其作為工具變量代替臨床風險暴露因素出生體重。
1.4 兒童肥胖的定義 參考文獻[17],兒童肥胖定義為0~18歲按不同性別年齡別BMI≥P95[17]。
1.5 數據分析 ①通過將SNP-出生體重關聯與SNP-兒童肥胖關聯回歸,計算SNP比率估計的IVW均值[12]。②使用加權中值方法估計影響效應,計算出所有被選擇的SNP的比率估計的加權經驗分布函數[13]。加權中值方法允許效應較強的SNP對因果估計作出更多的貢獻,在較少SNP成為有效的工具時也能減少因果效應估計的偏倚。③進行MR-Egger分析[14]。該方法假設水平多變性與SNP暴露效應無關(即Inside假設),允許在所有SNP的回歸和不平衡的水平多變性中有1個非零的截距。MR-Egger回歸是SNP-兒童肥胖風險與SNP-出生體重效應估計的加權線性回歸。MR-Egger能夠在所有SNP都是無效的工具時提供有效的因果效果評估。所有結果以OR及其95%CI表示,P<0.05為差異有統計學意義。為了實現統計分析結果的可視化,直觀展示每個SNP的統計效應,利用MR-base平臺數據分析功能繪制SNP相關的出生體重與兒童肥胖風險的森林圖及散點圖。
2 結果
2.1 出生體重相關的SNP篩選結果 本研究中新生兒體重的相關數據來自文獻[11],包含有26 836名新生兒體重數據[11]。以P<5×10-8、連鎖不平衡r2<0.1為篩選參數共篩選到33個SNP,分別為rs2131354、rs13266210、rs10818797、rs2306547、rs72833480、rs17034876、rs12543725、rs2497304、rs35261542、rs6016377、rs134594、rs900399、rs1415701、rs11720108、rs740746、rs2946179、rs1819436、rs854037、rs753381、rs72480273、rs113086489、rs10872678、rs1351394、rs10935733、rs4144829、rs7575873、rs798498、rs3780573、rs1411424、rs2473248、rs7998537、rs11765649和rs7964361。
2.2 出生體重對兒童肥胖的影響效應 共納入5 530例肥胖兒童和8 318名正常兒童。IVW分析:OR=1.79,95%CI:1.29~2.47,P=4.24×10-4;加權中值法:OR=1.30,95%CI:0.81~2.08,P=0.27);MR-Egger法:OR=1.73,95%CI:0.58~5.20,P=0.36)。
森林圖(圖2)顯示,IVW方法分析時兒童肥胖的遺傳易感性與出生體重水平有關。rs7964361、rs11765649、rs3780573和rs1351394的分析均表明出生體重與兒童肥胖的關聯有統計學意義。
與出生體重相關的SNP及其兒童肥胖風險的散點圖見圖3,根據直線斜率判斷,IVW法、MR-Egger法和加權中值法的因果關聯估計相近。
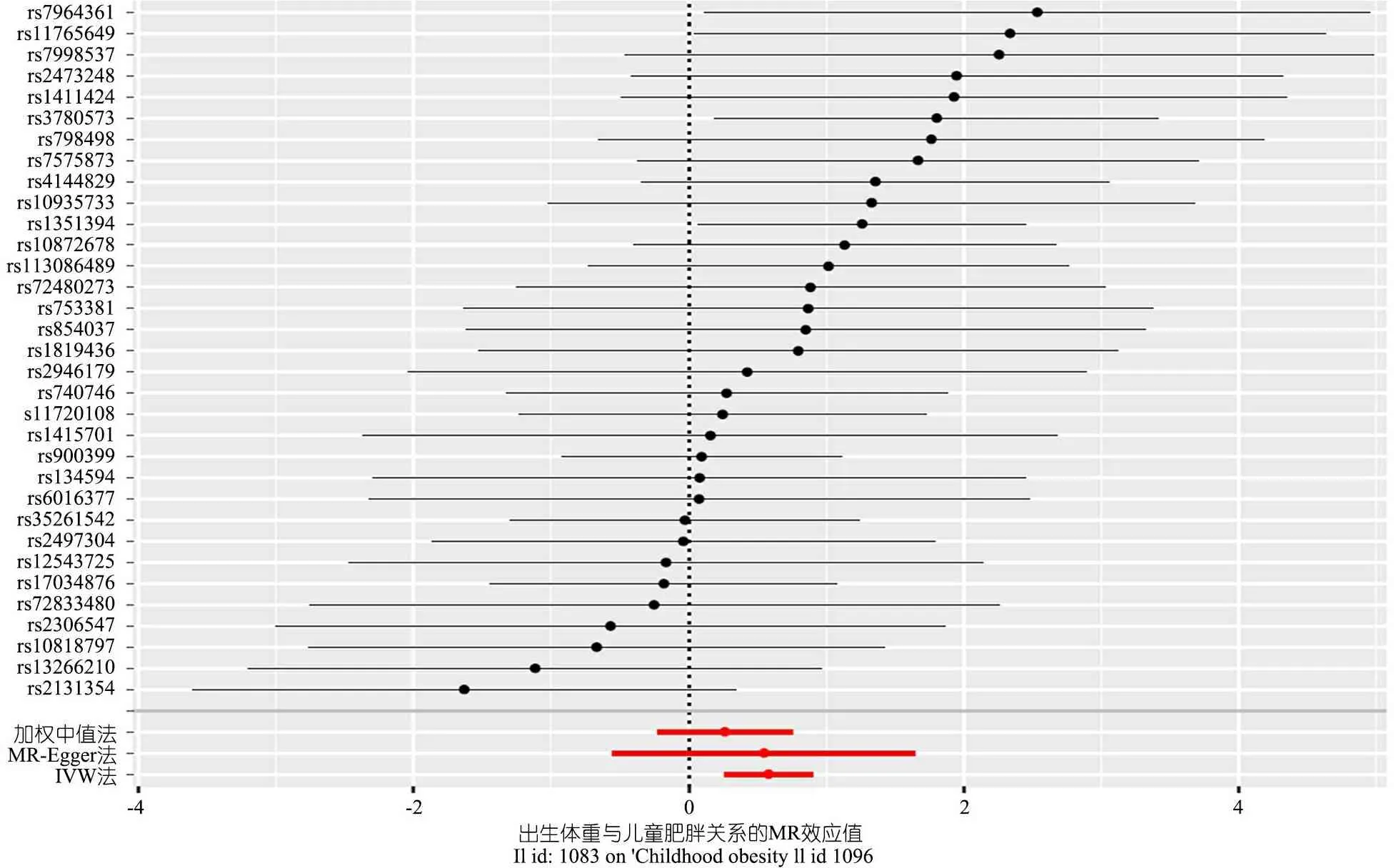
圖2 SNPs與出生體重及新生兒肥胖風險的森林圖
注 黑點代表出生體重中標準差(SD)增加的兒童肥胖對數OR,OR是使用每個SNP作為單獨工具變量產生的。紅點顯示不同的MR方法對所有SNP組合的因果估計。水平線段為95%CI
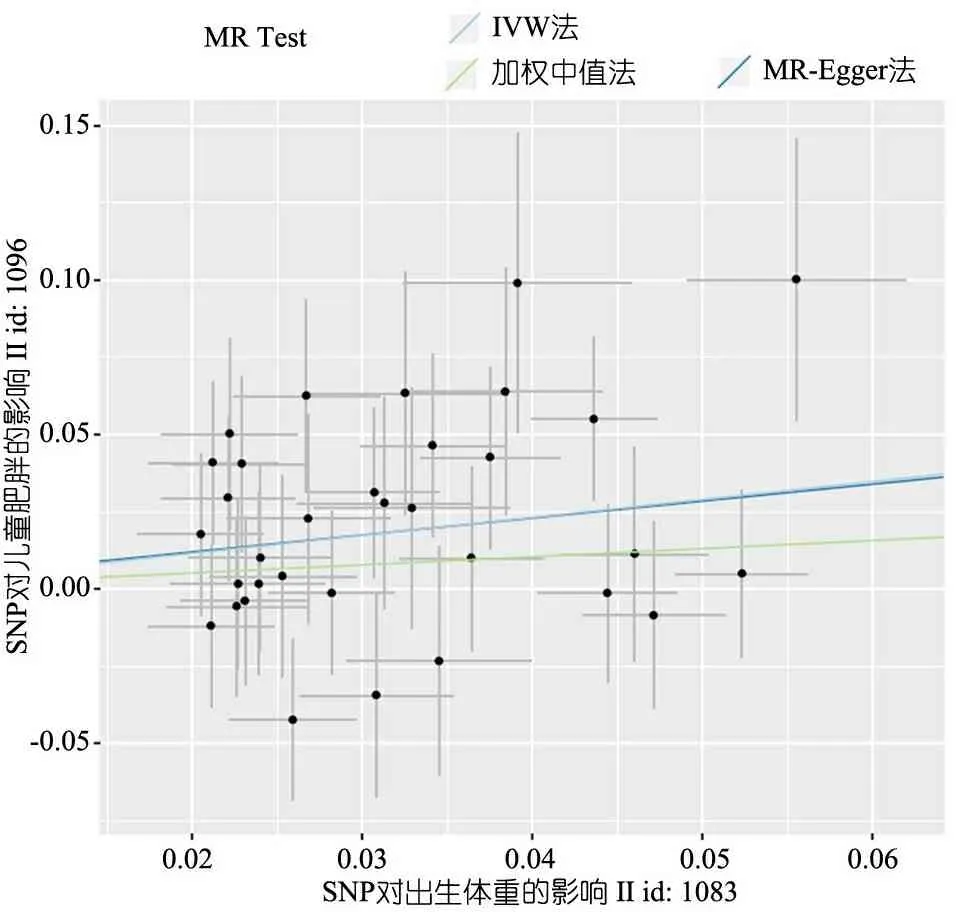
圖3 SNPs與出生體重及新生兒肥胖風險的關聯及合并效應
注 X軸(SD單位)代表SNP對出生體重的影響,Y軸(log OR)表示SNP對兒童肥胖的影響。每個黑點代表單獨的SNP,線段表示95%CI。3條直線的斜率對應于3種MR方法的因果估計,淺藍線為IVW法,深藍線為MR-Egger法,綠線為加權中值法
3 討論
本研究以出生體重相關的SNP為工具變量,代替臨床風險暴露因素出生體重,通過MR方法分析了出生體重及兒童肥胖發生風險的關系,共篩選到33個與出生體重相關的SNP,其中4個SNP表明出生體重與兒童肥胖有顯著的因果關聯。出生體重高的人群發生兒童肥胖的風險較高,每增加1個升高出生體重含量的等位基因,兒童肥胖的發生風險增加79%(OR=1.79)。
以往有多項傳統流行病學研究報道了出生體重和兒童肥胖之間的關系,多數都顯示出生體重與兒童肥胖風險之間存在顯著的正相關。丹麥1項基于人群的隊列研究表明,出生體重≥4.0 kg與3.0~3.5 kg相比,6~13歲時兒童發生肥胖的風險增加[18]。1項中國的隊列研究發現,出生體重>3 500 g較3 000~3 249 g,3~6歲時超重的比例升高[19]。含26個國家、66項研究的Meta分析表明,與正常出生體重(2 500~4 000 g)相比,高出生體重(>4 000 g)與兒童超重的可能性正相關(OR=1.66; 95%CI:1.55~1.77)[20]。另1項來自中國的研究調查了出生體重與3~6歲兒童肥胖風險之間的關系,當出生體重≥3 000 g時,兒童期超重和肥胖的OR值顯著增加[21]。然而,上述研究的結果能否真正反映出生體重與兒童肥胖之間存在因果關聯,仍不明確,流行病學研究中固有的偏倚也可能導致這種結果。
近年來,隨著MR研究的發展,對于兒童肥胖的危險因素有了進一步認識。Richmond等[22]通過研究4 296名11歲兒童的BMI、活動水平和相關基因型數據,發現兒童肥胖與身體鍛煉存在雙向的因果關系, 肥胖的增加導致兒童體力活動的減少,較低的體力活動也導致肥胖的增加;Eric等[9]整合4 000多個父母及其后代組成的隊列的相關遺傳數據,通過MR分析進行因果推斷,發現孕婦高血糖可能是后代兒童肥胖的重要危險因素;Censin等[23]通過EEG數據庫篩選了與兒童肥胖相關的SNP,并探究其與1型糖尿病的關聯。但目前尚無有關出生體重與兒童肥胖的MR研究的文獻發表。
本研究分別使用IVW法、加權中值法和MR-Egger法分析了出生體重與兒童肥胖的關聯。IVW法分析顯示,出生體重與兒童肥胖具有較強的相關性(OR=1.79,95%CI:1.29~2.47,P<0.001),但其他兩種方法分析均發現差異無統計學意義(P>0.05)。這3種方法均為MR研究的常用方法,每種方法在因果效應估計的一致性和檢驗效能各有優劣及無法驗證的假設條件[24],發現因果效應的效能亦有所差別。IVW法發現因果效應的效能高于加權中值法和MR-Egger分析,但由于IVW法所依賴的假設條件較強,致使其進行因果效應估計的I類錯誤率及得到因果效應的估計值的偏倚都有所增加。MR-Egger法受Inside假設的影響較大,當滿足其假設時,因果效應估計的I類錯誤率和基因多效性效應的偏倚都能得到很好的控制;一旦違背Inside假設,其檢驗效能受到很大的影響[25]。加權中值法相比其他兩種方法并無太大的特色,但在違背Inside假設時,如果無效的工具變量不是太多,其表現優于其他兩種方法[13]。這3種統計學方法各有優劣,且由于GWAS相關數據的限制,部分假設條件無法驗證(如Inside假設)。因此,本研究得到的因果關聯還需要進一步的證據支撐。
與其他研究相比,本研究的優勢在于:①MR設計可以防止傳統觀察性研究中因為固有的混雜因素導致的反向因果關系;②研究樣本較大,統計效應增加,效果估計相對更準確;本研究的局限性:①使用來自EGG研究的公共數據,納入的研究人群主要來自歐美國家,研究結論是否適用于中國人群,有待普遍性驗證;②無法直接獲得患兒所在研究隊列的數據,因此無法進行相關的亞組分析研究;③新生兒體重與兒童肥胖之間潛在的生物學機制仍未完全明確,通過MR方法僅能對其因果關系做出初步判斷。
猜你喜歡
核科學與工程(2021年4期)2022-01-12 06:30:26
當代陜西(2021年17期)2021-11-06 03:21:36
今日農業(2020年19期)2020-12-14 14:16:52
學苑創造·A版(2018年11期)2018-02-01 06:29:20
中學物理·高中(2016年12期)2017-04-22 11:53:03
讀者(2017年5期)2017-02-15 18:04:18
雜文選刊(2016年7期)2016-08-02 08:39:56
小天使·一年級語數英綜合(2016年6期)2016-05-14 12:21:05
當代修辭學(2011年2期)2011-01-23 06:39:12
小學生·新讀寫(2006年6期)2006-06-14 05:16:24
