基于ALCIF描述邏輯的Web頁面聚類
2019-06-01 05:54:30富豪鄧立國
現代計算機 2019年12期
富豪,鄧立國
(沈陽師范大學數學與系統科學學院,沈陽 110034)
在Web 頁面聚類過程中為了能有效處理標簽內容以及標簽內容之間的聯系,選用ALCIF 描述邏輯表示方法來對Web 頁面信息進行抽取與存儲,并對抽取到的知識內容進行約減,從而實現對Web 文檔的降維,以此節約聚類時間。最后用實驗證明這種知識表示方法對于Web 頁面聚類的有效性。
Web 頁面聚類;ALCIF 描述邏輯;K-means
0 引言
國外描述邏輯的發展由描述邏輯工作組進行推進,最近兩年從描述邏輯工作組的特邀報告及其所展示的成果來看,描述邏輯的重點始終在本體研究和語義網上面。總的來看描述邏輯的大部分研究還處在理論方面,Renata Wassermann 博士使用描述邏輯在OWL上進行實踐,拉近了描述邏輯理論和實踐的距離。國內對于描述邏輯的研究有申宇銘教授的文獻[8],提出了???模型關系并給出表達定理,提高了描述邏輯的表達能力。除此之外張富博士在文獻[9]中實現了一個原型工具,能夠自動將XML 轉化成本體,然后利用這些本體進行XML 知識的推理。
隨著十幾年來互聯網的快速發展,網頁數量也開始激增,根據我國最新的《41 次中國互聯網絡發展狀況統計報告》來看,我國的網站數量已經達到了533 萬個[1],如何快速又準確地返回搜索結果給搜索引擎帶來不小挑戰。
描述邏輯是知識表示語言的一種統稱,具體有多種形式,其中ALC 是最基本也是最簡單的描述邏輯形式。ALC 有很多的變型,包括,ALCF、ALCN、ALCIF、ALCIQ 等,其具體推理復雜性可參考文獻[2]。另外SROIQ、??、DL-Lite 等也屬于描述邏輯,其中W3C 所推薦的OWL2 的直接語義是根據SROIQ 擴展而來。目前由于本體語言(Ontology Language)的發展和Web本體語言(OWL)的廣泛使用,描述邏輯及其各種推理算法也得以快速發展和廣泛使用。本文根據Web 頁面數據的半結構化特點采用ALCIF 描述邏輯對數據知識進行表示。
Web 頁面內容雖然包含多種多樣的數據,如聲音、文字、視頻等,但是具有一定的標簽結構,標簽里面含有結構信息,而且兩個對應的段落標簽之間含有文本內容信息,傳統的聚類技術大多采用抽取標簽里的數據信息進行聚類,例如DOM 解析樹的方法和SAX 方法都忽略了段落標簽里面的文本內容信息,在這種方法下進行文檔相似度度量顯然存在一定問題。本文提出的基于ALCIF 描述邏輯的Web 頁面信息表示方法能夠全面考慮HTML 標簽結構信息和文檔內容信息,對于保留各項細節方面有很大優勢。
本文提出的基于描述邏輯的Web 頁面聚類方式,在保證速度的同時,由于使用了描述邏輯使得聚類結果也更加準確,同時聚類結果的可解釋性也得到提高。
1 描述邏輯
1.1 描述邏輯概念及應用
描述邏輯是基于概念的知識表示方法,是一階謂詞邏輯的一個可判定子集,與一階謂詞相比,描述邏輯可讀性更好[3]。Attributive Language with Complements(簡稱ALC)是基本的描述邏輯,本文采用的ALCIF 描述邏輯在ALC 的基礎上增加了角色反(Role Inverse)和功能角色(Functionality Role)。
描述邏輯廣泛應用于知識表示、語義網(Semantic Web)、推理機以及人工智能等領域。
1.2 ALCIF描述邏輯知識庫
為了便于知識表示和理解,以及考慮到XML 在Web 中扮演的關鍵角色,采用XML Schema 表示方法對Web 頁面進行結構和內容表示。這一過程所使用的描述邏輯定理如下:
(1)(?-)I={<x,y >|<y,x > ∈ ?I} (角色反)
(2)(C?D)I=CI∩DI(交)
(3)(C?D)I=CI∪DI(并)
(4)(?C)I=ΔICI(否)
(5)(??.C)I={a|?b.<a,b >∈?I并且b∈CI} (存在限定)
(6)(??.C)I={a|?a.<a,b >∈?I并且b∈CI} (全稱限定)
描述邏輯為概念和角色的結合,兩者由構造子經簡單的概念和角色來構造復雜的概念和角色,概念對應于邏輯中的一元謂詞,角色對應于二元謂詞,構造子決定語言的表達能力,表達能力越強,相應對的構造子越復雜。在描述邏輯中,每個句子對應一個邏輯表達式。
Web 頁面也稱為HTML 頁面,其包含內容豐富,因此具有一定復雜性。為了將HTML 的結構和內容都保留下來,在數據抽取的時候使用了XML 格式文件的XSD(XML Schema Definition)文件定義思想。通過XSD 這一結構來組織HTML 頁面內容。一個.xsd 文件截圖如圖1 所示。
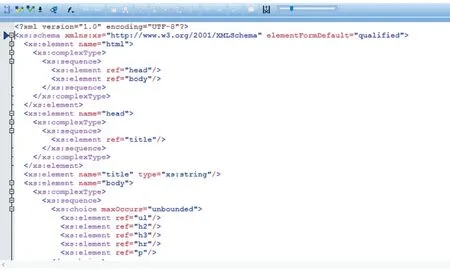
圖1 XML Schema代碼片段截圖
使用描述邏輯進行推理所基于的知識庫里包含兩種子庫,一種是TBox,包含了HTML 的各種術語即標簽名稱,另一種是ABox,所包含HTML 的具體屬性斷言。知識庫表示為К=<TBox,ABox>。TBox 是一個有限集合,TBox 通過概念描述的定義構造,里面包含術語知識TBox 通常由具有有限個包含關系的數學結構集合表示。
代碼1:HTML 的TBox。

將圖1中的HTML代碼與所對應的ABox 模型里面包含的是擴展知識是這樣的,這種擴展知識通常也稱作斷言知識如代碼2:一個HTML 的ABox 模型S'(與代碼1 對應)。
知識庫К被表示為ABox 集合(代碼2)和TBox 集合(代碼1)兩種形式,需要注意的是這里的ABox 和TBox 集合里面的元素未被全部列舉出。
2 基于知識庫模型的數據抽取
HTML 標簽知識庫通過ABox 模型S'建立,并在描述邏輯知識庫中存儲了模式表示的實例,現在就可以使用描述邏輯推理來對XML 模式表示進行推斷。下面將HTML 對應到知識庫過程進行正確性驗證,如圖2 所示。在這一過程中知識庫被不斷擴展,以適應XML Schema 帶來的數據增量式拓展。
使用Python 工具對HTML 數據內容進行抽取,抽取的內容包含頁面名稱、標簽名稱還有其它標簽里的文本內容,如title 標簽、字號標簽里的內容以及段落標簽p 里的全部內容,尤其段落標簽p 可能包含了大段的文本內容。再用描述邏輯知識庫對大段的文本內容進行縮減形成若干個屬性,通過XML Schema 將標簽數據聯系起來。
根據HTML 文件知識庫的表示方法,將HTML 文檔內容按照ABox 進行組織。組織后的HTML 文檔中P 標簽里面的文本內容由TBox 驗證其中的包含關系將文本內容進行縮減。然后將抽取文本保存在文本文件中。將文本內容映射到知識庫中時,得到一個文檔的特征概念集合T={t1,t2,t3,…,tn},經過TBox 包含關系處理后得到的是一個簡化的概念集合T’,這一過程會極大地降低文本數據維度。在第4 部分直接對這些HTML 文件進行相似度計算。
在HTML 網頁中title 標簽和某些文本內容相互聯系,可能是和文件內的,也可能和其他文件有所關聯,嘗試著使用描述邏輯找出其中的關系。例如大學里Jon Damon Reese 教授的個人主頁,嘗試找出里面J D Reese 教課的課程名,然后有哪些學生選了J D Reese的課,從而建立一種關聯關系并在聚類中考慮到這種關系。
3 文檔向量與相似度計算
在第3 部分進行了HTML 文檔內容提取,并將抽取的數據內容保存在知識庫中。通過特征項與知識庫進行匹配化簡,得到一個新的向量T’{t1,t2,t3,…,tm}(m≤n)。
傳統的VSM 模型將文本空間看做一個有一組正交詞條表示對的向量空間,其中每個文本表示的規范化特征向量V(d)=(t1,w1(d);t2,w2(d);…tn,wn(d)),tn為詞條項,wn(d)是tn在d 中的權重。TF-IDF 是一種常用的詞條權重確定方法。這里不考慮同一文件中詞出現的先后順序和頻率,即要求同一ti不重復出現,這時可以把t1,t2,…,tn看作一個具有n 維的坐標系,將權重wn(d)看作坐標值,這樣一個文檔就被表示為一個n 維的坐標向量。V(d)=(w1,w2,…,wn)稱作文本d 的向量空間模型。其中每個詞條的權重計算如下:
其中D 是HTML 文檔集,d 表示任意一個HTML文檔,t 為一個文檔中的詞,tf(d,t)為詞t 在文檔d 中出現的頻率,|D|為文檔集的總數,tf(t)為詞t 在HTML 文檔集中出現的次數,那么tfidf(d,t)就表示詞t 在文檔d中的權重。
由于需要匹配知識庫,從而判斷包含關系,進而縮減一個文檔的維度。因此會得到一個新的權重計算公式:

其中nwi為概念c 在表示文檔di時的權重,twk為匹配知識庫前根據TF-IDF 計算得到的權重,其中r 為:

通過新的權重計算公式可以得到一個文本的語義表示模型,每一個HTML 文本可以表示成V(d)=(nw1,nw2,…,nwn),若存在包含關系則V(d)=(nw1,nw2,…,nwm)。
向量計算公式參數設置如下:
tfidf_vectorizer = TfidfVectorizer(max_df=0.7,max_features=200000,
min_df=0.1,stop_words='english',
use_idf=True,tokenizer=tokenize_and_stem,ngram_range=(1,3))
4 K-means算法
使用傳統的K-means 算法需要先確定聚類點的數目,雖然不符合聚類的不確定性特點,而且K-means 算法初始簇中心點的選擇具有較大隨機性,但是由于K-means 算法的易用性以及可在大數據級上應用而被廣泛接受。K-means 算法的隨機性可能導致最終的聚類結果不穩定,兩次運行結果存在差異,針對這一點指定同一個聚類初始簇中心即可完美解決。王勇等在聚類之前對數據進行分層以此來獲得聚類數量的上限,快速確定聚類范圍解決了K-means 聚類算法無法確定最佳聚類數目的問題[5]。邵倫等通過將樣本數據映射多維網格中,然后將樣本數最多的網格作為聚類過程中的初始網格然后進行K-means 聚類,這種方法很大程度上解決了容易陷入最優解的問題[6]。本文則選用K-means++算法在初始簇聚類中心點的選擇上給與了優化。
4.1 算法的基本思路
K-means++算法在簇中心點的初始化過程中的基本原則是各個簇中心點間的相互距離盡可能遠,這樣能在一定程度上解決聚類過程中隨機初始各個簇中心點所帶來的弊端。算法首先隨機選取一個數據(n=1)點作為第一個聚類初始點,其次選取距離前n 個數據點較遠的數據點為第n+1 個初始簇中心點,計算樣本與聚類中心點距離為[7]:

4.2 算法流程
輸入:數據集T,簇數量K。
輸出:劃分為k 個簇的數據集T。
算法過程描述:
(1)從T 中隨機選擇一個數據點作為第一個簇中心點;
(2)選擇樣本與簇中心點距離較遠的點作為下一個簇中心點;
(3)重復(2)直到K 個簇初始中心點都被確定;
(4)使用K-means 算法計算調整簇中心點的位置;
(5)輸出具有K 個簇的數據集T。
5 實驗環境及結果
實驗硬件條件是處理器是英特爾酷睿i5-4200U,硬盤用的東芝5400 轉的500G 機械硬盤,內存為海力士4+8G 的DDR3L,內存頻率為1600MHZ。軟件上使用Python 3.6 版本,數據集采用的是WebKB。
聚類之前使用Tidy 對數據集進行了規范化處理,提取XML 的XSD,然后根據謂詞邏輯中包含思想用Gensim 的Word2Vec 訓練詞向量,對標簽關系進行學習,形成特定的模型。之后使用算法結合得到的模型對WebKB 數據集進行聚類,聚類時也能更好地解釋Web 頁面聚類結果,當K=8 時聚類結果如圖3 所示。
圖3 Python實驗截圖
6 結語
本文提出的在Web 頁面聚類中使用ALCIF 描述邏輯的方法對HTML 標簽結構關系進行聯系,根據TBox 文本知識表示方法可以降低HTML 的數據維度,通過實驗證明將描述邏輯用于Web 文檔的知識表示從而精簡文檔構造語義聯系并發現其中的關聯關系是合理且有效的。未來的工作是考慮將運算規則引入到描述邏輯關系中,使得P 標簽內的大量文本一些復雜的邏輯能夠進行約減,從而幫助Web 數據降低維度,節省聚類時間。
猜你喜歡
文萃報·周五版(2025年2期)2025-02-14 00:00:00
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
保健醫苑(2022年1期)2022-08-30 08:39:14
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
語文知識(2014年1期)2014-02-28 21:59:13
電腦愛好者(2011年11期)2011-06-22 08:20:18
