基于機器學習的個人信用借貸風控模型構建
2019-05-24 07:36:48譚天翔李達陳俊林
求知導刊 2019年6期
譚天翔 李達 陳俊林
摘 要:近年來,隨著網絡個人貸款在中國蓬勃發展,一些平臺出現提現困難、經偵介入、跑路等問題,究其原因主要是平臺對風險的控制不過關。文章對國內網絡借貸行業的貸款風險數據(來源:拍拍貸官網)進行選擇分析,基于機器學習技術提出個人借貸風控模型的構建方案,為投資人提供關鍵的決策思路。
關鍵詞:xgboost;SVM;邏輯回歸模型
中圖分類號:F832.4
文章編號:2095-624X(2019)06-0014-03
一、概述
本文的研究目標是根據用戶歷史行為數據來預測用戶在未來6個月內是否會逾期還款的概率。該問題可以轉換成二分類問題,從數據表中構建特征,評估指標為AUC,其本質是排序優化問題,所以本文在模型頂層融合也使用基于排序優化的rank_avg融合方法。
本文首先從數據清洗開始,介紹我們對缺失值的多維度處理、對離群點的剔除方法以及對字符、空格等的處理;其次進行特征工程,包括對地理信息特征構建、組合特征構建和數據表的特征提取等;再次進行特征選擇,本文采用xgboost,其訓練過程即對特征重要性排序過程;最后一部分是模型設計與分析,采用了工業界廣泛應用的邏輯回歸模型,并基于Large-scale SVM的方法在本課題上的應用,取得了較好的效果。
二、數據清洗
1.缺失值的處理
在個人信貸問題中,用戶所提供自身信息的數量對其在信貸體系中的信用等級有著至關重要的作用,所提供的信息越詳細則越容易通過審核得到貸款。我們以此為切入點來分析和處理原始數據中的缺失值。
首先,以行為單位統計各樣本的屬性缺失值個數。按照缺失屬性的個數由小到大排序,繪制散點圖并分析得出,訓練集和測試集中的各樣本缺失屬性的個數的分布情況基本一致。同時在訓練集數據中,序號在80000附近的少量樣本的缺失屬性個數非常多,可視為離群點刪除。其次,以列為單位統計各個屬性缺失值個數,并計算相應的缺失率,分析其中兩列缺失率達到97%,且這兩種屬性沒有有效的信息,故可直接刪除。而缺失率達到63%的三種屬性為分類型數據,可以用-1來代替缺失值,從而等價于表示“是否缺失”的新類別。除去前五種缺失率較高的屬性,其余屬性的缺失率都比較低,因此可用中值代替。補全數據后最終達到了可以研究的目的。最后,缺失值的個數也可以作為一項衡量用戶信息詳細程度的重要指標。
2.常變量的剔除
題目提供的數據中數值型特征有190個,我們可以計算每個特征的標準差后,將所得結果按照從大到小排序,從而刪除標準差最小,即變化較小的特征。
3.離群點的剔除
樣本空間中有一些樣本點與其他的特征或一般行為不相符,這些點便可稱為離群點。由于離群點的不同特征可能是多種因素造成的,在上文中我們就已通過分析處理缺失值的個數來篩選少量離群點。
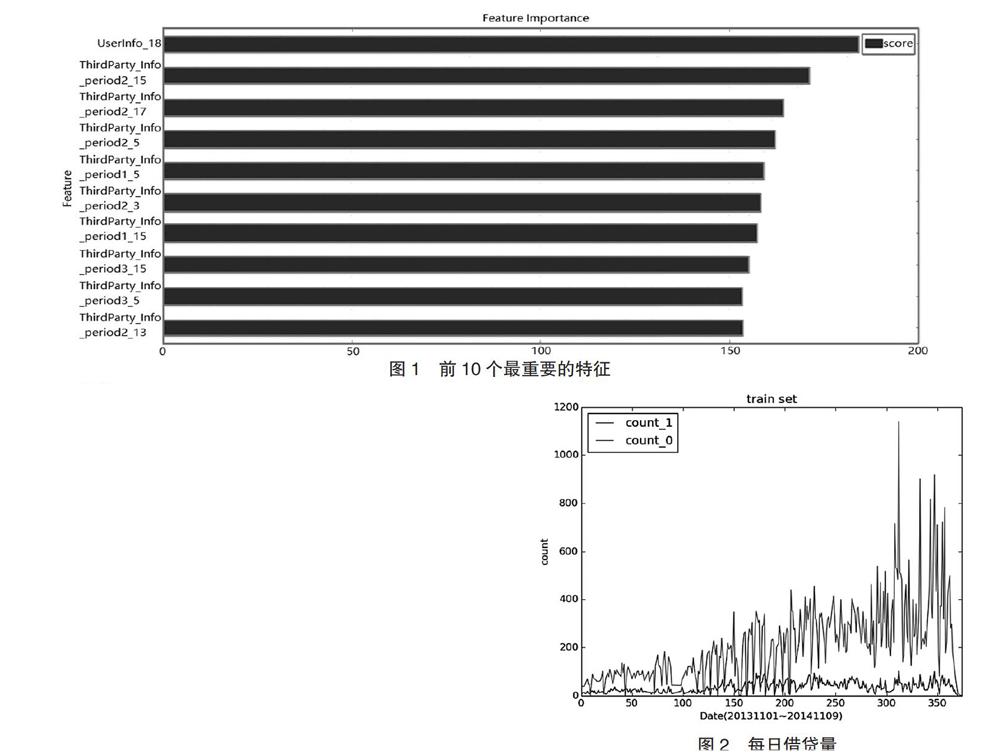
但在本節中,我們在題目提供的數據上訓練xgboost,用得到的xgb模型來評價各個特征的重要性,對其進行由大到小的排序得到前10個最重要的特征,如圖1所示。然后分別計算每個樣本的這10個特征的缺失值個數。如若缺失值個數大于10個,則將其視為離群點。這些離群點缺失了前10個特征上的取值,給訓練模型增加了很多麻煩,不便于處理,故需要刪除。
4.其他處理
將數據表中其他數據進行相應處理,如英文字符統一為小寫;數據包含了空格字符,是同一種取值,如“中國 電信”與“中國電信”,刪除空格字符;含有“長沙市”“長沙”等情況,其意義相同,故統一刪除“市”這個字符。
三、特征處理
1.地理信息處理
針對地理位置信息(類別變量),我們想到的處理方法是利用獨熱編碼(one-hot encoding),然而如此會產生較高維的稀疏特征,阻礙模型學習的效率和有效性,對此我們先對數據進行篩選。
數據中包含了六個字段的用戶地理信息,當中的兩個字段為省份,另外四個為城市信息。我們計算各省份和城市的違約率,違約率最大的幾個地區分別為吉林、天津、山東、湖北、湖南以及四川,由此,我們設立6個二維特征,分別為:“是否為吉林省”“是否為天津市”“是否為山東省”等,取其值為0或1。即對其地理信息進行了獨熱編碼處理,保留其中判別性特征。之后,由于城市信息建立二值特征產生的稀疏特征維度較高,分析難度較高。因此我們對獨熱編碼處理后的高維稀疏特征進行xgb模型訓練,根據輸出的特征重要性篩選出二值特征。
根據城市等級合并。因類別特征取值個數太多,對其獨熱編碼處理后所得稀疏特征維度較高,我們還使用了與上面不同的合并變量方法。
城市特征向量化。統計城市特征中城市數,并取對數,之后等值離散化到6~10個區間內。
地理信息差異特征。地理信息中有4列為城市。因此我們設置城市差異特征,如diff_12表示1、2列的城市是否一致。
2.成交時間特征
依日期來統計訓練集中每日借貸成交量,正負樣本分別計算,得到如下的曲線圖2,橫坐標是日期(20131101至20141109),縱坐標是每日借貸量。count_1曲線是違約樣本每日數量(為了體現對比,將量擴大一倍),coun_o曲線對應未違約數量。
由圖中可以看到拍拍貸業務量總體呈增長趨勢,而違約量前期有緩慢增長,之后基本趨于平穩,總體上違約率為平穩甚至下降趨勢。在300~350對應的日期區間內,有一些借貸量非常大的情況出現,其中可能隱藏著我們尚未挖掘出來的某些信息。
3.特征組合
訓練完成xgboost后可以輸出特征重要性,我們發現第三方數據特征“ThirdParty_Info_Period_XX”的feature score較高(見圖1),即判別性比較高,于是用這部分特征構建了組合特征:將特征相除得到6000多個特征,之后使用xgboost對其單獨進行模型訓練,得到特征重要性排序,取其中前450個特征線下cv能達到0.73以上的AUC值。將其添加到初始體系中,線下cv的AUC值從0.777提高到0.7833。另外,也組合了乘法特征(取對數):log(x*y),篩選出其中的240多維,加入初始體系中,單模型cv又提高到了0.785左右。
4.其他特征
我們將剩余類別特征均做獨熱編碼處理,提取了用戶修改信息特征,比如:修改次數,修改時間到成交時間的間隔,各信息修改次數等特征。我們提取了用戶登錄信息特征,如時間天數,平均登錄間隔以及各操作代碼的次數等。對初始特征中190維數值型特征按數值從小到大進行排序,得到排序特征。排序特征對異常數據有更強的抗變換性,使模型更加穩定,降低過度擬合的風險。
四、特征選擇
在特征工程部分,我們構建了一系列位置信息相關的特征、組合特征、成交時間特征、排序特征、類別稀疏特征等,所有特征加起來將近1500維,這么多維特征可能會導致維數災難,需要做降維處理,此處通過特征選擇來降低特征維度。特征選擇的方法很多:最大信息系數(MIC)、正則化方法(L1,L2)、基于模型的特征排序方法。比較高效的是最后一種,即基于學習模型的特征排序方法,這種方法有一個好處:模型學習的過程和特征選擇的過程是同時進行的,因此我們采用這種方法基于xgboost來做特征選擇,xgboost模型訓練完成后可以輸出特征的重要性,據此我們可以保留前N個特征,從而達到特征選擇的目的。
五、模型設計
本次研究所收集到的數據共有9萬個,將此數據分為三個集合,分別為訓練數據(訓練集)、測試數據(測試集)和驗證數據(驗證集合)。其中訓練集8萬數據,測試集1萬數據,驗證集1萬數據。其中7萬的訓練集用于模型的調參,本次實驗主要采用7折交叉驗證進行調參,而驗證數據主要是為了方便進行線上模擬實驗,在得到單個的模型結果后,可在驗證數據的基礎上做進一步的模型融合。
1.logistic回歸
logistic回歸即邏輯回歸,它與多重線性回歸實際上有很多相同之處,最大的區別就在于他們的因變量不同,其他的基本差不多。最為常用的就是因變量二分類的logistic回歸,這就為本次實驗的模型選取提供了可選擇性。
首先,對原始特征和構建的多維特征進行添加和形式的變換。其次,就本次實驗來說,關鍵在于動態地根據交叉驗證的反饋來處理特征,這個基本思想貫穿整個建模的過程。對于xgboost模型訓練后輸出的重要性與特征進行單因素分析和數值特征的離散化,對于連續性變量在分析過程中常常需要采用OCDD離散化方法進行離散化后變成等級特征然后進行獨熱編碼。為了提高模型的表達能力,如果單純用線性模型來對問題進行刻畫會有失準確性,因此構建并加入上文中描述的組合特征,特征組合正好可以加入非線性表達,以此來增強模型的表達準確性。最后,在高維特征上進行模型的訓練,單模型驗證集得到的AUC為0.772左右。
2.xgboost
xgboost的全稱是extreme Gradient Boosting(極端梯度提升),它能夠自動利用CPU的多線程進行并行,同時在算法上加以改進提高精度,有著出眾的效率與較高的預測準確度,值得我們在GBDT(Gradient Boosting Decision Tree:梯度提升決策樹)的基礎上對其進一步探索學習。
之前的原始特征和構建的特征共有1439維特征,在此基礎上訓練xgboost,單模型線下交叉驗證的ACU值為0.7833左右。我們又對模型做進一步改進。在之前模型得到的參數基礎上,讓參數在小范圍內隨機波動,并對特征進行隨機抽樣。例如,之前模型的子樣品參數取值為0.75,而得到的新模型的子樣品參數在0.7~0.8隨機取值;原模型所用到的特征為1439維,而新模型則在隨機抽樣部分進行訓練。經過改進,線下模擬的ACU值達到了0.787。
3.大規模數據的SVM嘗試
SVM即支持向量機,它是在分類與回歸分析中分析數據的監督式學習模型與相關的學習算法。但是,SVM存在的問題就是不能處理大規模的數據,本次實驗我們收集了8萬的數據,對于SVM來說數據規模過大,因為當處理大規模的數據時它受到訓練時間和實驗硬件設施的限制。因此,要解決數據過大而造成的時間過長問題,具體的做法就是采用工作集方法、訓練集分解方法、增量學習方法等。實驗中我們訓練了30個SVM,在此中采用Bootstrap抽樣產生子集。這種方法實質上減小了計算復雜度。假設原始數據有n,則原方法訓練的復雜度是O(n2),將數據集n分為p份,則每一份數據量為n/p,每一份訓練一個子SVM,復雜度為O((n/p)2),全部相加,則復雜度減小了p倍。在此種方法上得到的AUC為0.77左右,在一定程度上減少了訓練時間。
4.模型融合
我們實現模型融合的基本框架,基于3個方案的融合。
方案1:bagging xboost,通過參數擾動生成不同30個xgb模型,對同一數據集進行訓練產生結果,采用均值融合產生M1結果。
方案2:Large-Scale SVM,通過shuffle將數據集劃分為30子數據集,根據復雜度分析,這個方式的時間復雜度進一步降低,對30個svm結果輸出取平均產生M2結果。
方案3:單模型,根據線下CV驗證,調試2個不同版本的最優單模型,S_XGB_1, S_XGB_1分別為陳天奇版本的xgboost和graphlab版本的模型,生成不同的單模型結果。
模型融合的關鍵在于模型差異性。框架中體現出模型差異性主要是3個部分:不同模型、相同模型不同參數和訓練數據集不同。因此每次在ensemble之前需要參考下各個模型的相關性,可以采用person系數評價等。
最上層的融合方式可以采用均值融合,rank均值融合等簡單方式,最終我們選用的是線下效果最好的1/rank加權融合(按score降序)。
六、結語
根據本文研究,通過數據預處理—特征處理—模型選擇—模型融合這樣一個過程,我們實現算法和方案的有效建立。其實模型與數據是相輔相成的,只有更加了解數據才能更好地使用模型。投資人根據本文提供的模型,結合實際數據,可以更好地對用戶借貸行為進行預測。
參考文獻:
[1]趙花.基于組合模型的用戶是否二次貸款預測應用研究[D].上海:上海師范大學,2018.
[2]王磊.社交數據驅動的P2P借貸風險評估模型[D].杭州:浙江大學,2017.
[3]李洋,鄭志勇.量化投資:以MATLAB為工具[M].北京:電子工業出版社,2015.
[4]卓金武,周英.量化投資:MATLAB數據挖掘技術與實踐[M].北京:電子工業出版社,2017.
基金項目:湖南商學院2017年度大學生研究性學習和創新性實驗計劃項目。
作者簡介:譚天翔(1997—),男,湖南岳陽人,湖南商學院數學與應用數學專業1501級學生。
