文本解析技術及其在法律實踐中的應用*
2019-05-06 07:54:06邱昭繼
中國法律評論 2019年2期
邱昭繼
內容提要:文本解析技術的突破與IBM的“沃森”和“辯論者”程序的研發團隊的努力密不可分。“沃森”基于文本的信息提取技術展現了不同凡響的問答本領,“辯論者”已經學會了論證挖掘。深度問答、信息提取和論證挖掘這些技術用更一般性的術語講就是文本解析。人工智能與法律研究者和技術專家將文本解析與法律推理和法律論證的計算模型整合在一起,創建了一些新的法律應用程序。這些法律應用程序不僅僅是將法律人的處理過程計算機化和標準流程化,更是創造性地處理了一些法律人過去無法完成的任務。文本解析技術的迅速發展將深刻地改變法律實踐、法律職業、法律教育和法學研究。
引言
2011年2月,由戴維·費魯奇(David Ferrucci)領導的IBM研發團隊開發的認知計算系統“沃森”(Watson)參加了美國著名智力問答競賽電視節目“危險邊緣!”(Jeopardy!)。該節目以一種獨特的問答形式進行:它以答案形式提供各種線索,參賽者以問題的形式做出簡短回答。問題設置非常廣泛,參賽者需具備歷史、文學、藝術、流行文化、科技、地理、政治、體育等多方面知識,還需要理解隱語、反諷等表述方式。“沃森”在節目中表現神勇,一舉擊敗了連勝紀錄保持者肯·詹寧斯(Ken Jennings)和最高獎金得主布拉德·魯特爾(Brad Rutter)。這是IBM歷史上繼“深藍”計算機于1997年打敗國際象棋衛冕世界冠軍加里·卡斯帕羅夫(Gary Kasparov)后,又一次成功地挑戰人類。“沃森”在節目中能夠回答微妙、復雜、語義雙關的問題,這開啟了認知計算的新紀元,也標志著人工智能寒冬的終結。1Dr. John E. Kelly III:《認知計算和我們的未來——人類和機器如何鍛造認知新時代》,載 IBM商業價值研究院:《認知計算與人工智能》,東方出版社2016年版,第7頁。2014年春季,IBM研究院總監約翰·凱利三世在米爾肯研究所年度會議上演示了“辯論者”(Debater)程序。“辯論者”是IBM公司研發出來的新的人工智能項目,它使用“沃森”程序的一些文本處理技術來執行論證挖掘。
文本解析技術的突破與IBM的“沃森”和“辯論者”程序的研發團隊的努力密不可分。“沃森”基于文本的信息提取技術展現了不同凡響的問答本領,“辯論者”已經學會了論證挖掘。深度問答、信息提取和論證挖掘這些技術用更一般性的術語講就是文本解析。“文本解析也稱為文本挖掘,是從文本數據中獲得高質量和可操作信息和見解所遵循的方法和過程。這涉及使用自然語言處理、信息檢索和機器學習從語法上把非結構化文本數據解析成更結構化的形式,并從這些數據中提取出對終端用戶有幫助的模式和洞見。”2[印度]迪潘簡·撒卡爾:《Python文本分析》,閆龍川、高德荃、李君婷譯,機械工業出版社2018年版,第35頁。該書的譯者將“text analytics”翻譯成“文本分析”,我將這個概念翻譯成“文本解析”。當被解析的文本是法律時,人們將其稱之為法律文本解析。3Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, p. 5.法律文本解析(legal text analytics)又稱之為法律文本挖掘(legal text mining),是指“使用語言的統計的和機器學習的技術自動發現法律文本數據檔案中的知識”。4Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, p. 397.法律文本解析簡稱為法律解析。深度問答、信息提取和論證挖掘成為了法律文本解析的核心技術。
“沃森”和“辯論者”程序雖然不會進行法律推理和法律論證,但它們為法律推理和論證的計算模型提供了文本解析技術。兩位有遠見的作者呼吁法律界認真對待“沃森”技術對未來法律實踐的影響。他們指出,“沃森”是應用于法律的最重要的技術,“沃森”改變了人們對于法律知識結構的理解,降低了法律成本,促進了法律信息和數據的組織管理,給年輕律師提供了更多的出人頭地的機會,給法律教學帶來了全新的挑戰,讓法學與工程學科的交叉融合提供了可能性,等等。5Paul Lippe and Daniel Martin Katz, "10 predictions about how IBM's Watson will impact the legal profession", October 2, 2014, 載http://www.abajournal.com/legalrebels/article/10_predictions_about_how_ibms_watson_will_impact,2018年10月8日訪問。法律文本解析是人工智能時代廣泛應用于法律實踐的一項新技術。本文試圖對法律文本解析及其在法律實踐中的應用問題做一番初步的探討。本文將逐一闡述深度問答、信息提取和論證挖掘技術及其在法律實踐中的應用情況。
*本文是國家社會科學基金項目“司法裁判過程中的人工智能應用研究”(項目編輯18BFX008)階段性成果。
**邱昭繼,西北政法大學教授,法學理論教研室主任。
一、深度問答技術及其在法律中的應用
深度問答技術是IBM“沃森”的核心技術。“沃森”是基于自然語言處理、機器學習和高級數據解析的高級問答系統。2011年2月,在美國電視節目“危險邊緣!”游戲中,“沃森”“在回答問題時能夠搜索其巨大的資料庫,并判斷預估答案的可信度,當對答案有充分把握時,搶先于人類按動了搶答器”,6[美]約翰·E. 凱利、史蒂夫·哈姆:《機器智能》,馬雋譯,中信出版社2016年版,第3—4頁。從而一戰成名。
(一)IBM沃森的深度問答
為了在“危險邊緣!”游戲中獲勝,IBM組建了一支由二十多位科學家組成的核心研發團隊,這些科學家是自然語言處理、信息檢索、知識表示、自動推理、機器學習和高性能計算等領域的頂尖專家。他們經過五年多時間的研究和開發,實現了技術的突破。“沃森”是作為一個問答計算系統創建的。研發者為“沃森”創造了一種叫做深度問答的學習能力系統。深度問答技術包括問題解析和分類、問題分解、自動源獲取與評價、實體和關系檢測、邏輯形式生成、知識表達和推斷等內容。“沃森”將機器學習提升到了一個新高度。對于每一個問題,“沃森”學習如何從數據庫的數百萬個文本中提取問題的候選答案,學習使其能夠識別該類問題的答案的各種證據,學習與文本相連的各種證據的可信度。研發者“訓練沃森識別各類信息,如名人、地點和關系,同時也解析語言。之后,他們又設計了一套統計方法,用來學習不同語境中詞語的使用情況。這種技術組合使“沃森”從數據中學習,而不是僅僅按照指示工作。從某種意義上說,“沃森”將學習人類的學習方式,接觸大量的事情并從中得出推論并習得經驗”。7同上注,第36—37頁。深度問答架構將自動問答問題視為大規模平行假設生成和評價任務。深度問答的結果不僅僅是提問與回答,而且是一個執行不同診斷的系統。這個系統基于各種數據收集、分析和評估每個結果的置信水平。通過問題、主題、案例或一組相關問題,深度問答在輸入語言中找到重要的概念及其關系,構建用戶信息需求的表示,然后通過搜索生成許多可能的回應。對于每個可能的回應,它產生獨立和競爭的線索,這些線索從結構化和非結構化數據中收集、評估和組合不同類型的證據。它可以提供排序的回應列表,每個回應都與證據配置文件相關聯,該證據配置文件描述了深度問答內部算法是如何對支持證據進行加權的。8參見IBM“沃森”研究團隊關于深度問答架構的描述,載https://researcher.watson.ibm.com/researcher/view_group_subpage.php?id=2159,2018年10月3日訪問。深度問答軟件架構是根據非結構化信息管理架構(Unstructured Information Management Architecture,UIMA)標準建立的。UIMA是一個用于問答系統的開源阿帕奇(Apache)框架,在這個架構中文本注釋器被組織到文本處理管道,將語義分配給文本區域。
通過自然語言處理和各種結構化和非結構化數據源組合,“沃森”擁有理解復雜上下文的能力。它可以“讀”文本、“看”圖像、“聽”自然語言,它解讀那些信息,提取信息并對信息進行標記和注釋,同時伴有推論和推理過程,提供候選答案并對它們成為一個正確答案的可能性進行評估和排名。其實,“沃森”并不真正“知道”答案。“沃森”也會犯錯。在第一天的比賽將結束時,“危險邊緣!”游戲的終局節目是“美國城市,分值400美元”。答案是“它最大的機場以第二次世界大戰的英雄命名;它第二大的機場以第二次世界大戰的一場戰役命名。”沃森給出的答案是“多倫多是什么?????”,正確的答案是“芝加哥是什么?”芝加哥的第一大機場是以“二戰”英雄海軍王牌少校指揮官愛德華·亨利·布奇·奧黑爾(Edward Henry “Butch” O’ Hare)的名字命名的,第二大機場中途機場(Midway Airport)是以“二戰”著名的太平洋海戰命名的。稍有常識的人都知道多倫多是加拿大城市,不是美國城市。“沃森”困惑于這個問題的原因有很多,在美國確實有一些叫多倫多的城市,比如伊利諾伊州的多倫多、印第安納州的多倫多,并且加拿大的多倫多藍鳥隊的確參加美國棒球聯盟的比賽。結果,“沃森”的置信水平非常低,只有14%,正如5個問號所示,它對答案沒有信心。然而,“沃森”能夠從錯誤中學習,通過大規模機器學習,“沃森”能從訓練和運用中不斷改善。9參見Dr. John E. Kelly III:《認知計算和我們的未來——人類和機器如何鍛造認知新時代》,載 IBM商業價值研究院:《認知計算與人工智能》,東方出版社2016年版,第9—10頁。
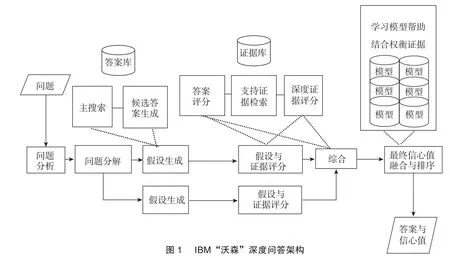
圖1 IBM“沃森”深度問答架構
(二)深度問答技術在法律中的應用
“沃森”和“辯論者”程序雖然不會進行法律推理和法律論證,但它們為法律推理和論證的計算模型提供了文本解析技術。IBM試圖將“沃森”的深度問答技術應用于法律領域。“沃森”的基本任務是回答問題。法律問答可以讓法律知識更容易獲得。IBM的總法律顧問羅伯特·韋伯(Robert Weber)指出,深度問答技術能在幾毫秒內解析數億頁內容并挖掘它們以獲取事實和結論。雖然深度問答技術不會取代律師,但它讓律師如虎添翼。這項技術將在兩個方面派上用場:收集事實和建構法律論證時識別觀點。這項技術甚至可以在法庭上近乎實時地發揮作用。如果證人說某些似乎不可信的內容,律師現場就能檢查其準確性。10參見Robert C. Weber, "Why 'Watson' matters to lawyers", The National Law Journal, Feb. 18, 2011, https://www.law.com/nation allawjournal/almID/1202481662966/,2018年8月25日訪問。
阿什利想象了一個“法律危險邊緣!”游戲。主持人透露類別是“體育法”。答案是“美國棒球聯盟球隊在經濟罷工期間不能合法雇用替補球員”。“沃森”搶答道:“多倫多藍鳥隊是什么?”主持人宣布:“答案正確!多倫多藍鳥隊在經濟罷工期間不能雇傭替補工人。”“沃森”回答這個問題的方式不同于法律人。法律人首先想到的是美國棒球聯盟球隊所在國家和州的勞動法規定,看看這些法律規定是否禁止球隊在經濟罷工期間雇用替補球員。然而,“沃森”不知道多倫多的位置或所屬國家也能正確地回答問題。“沃森”是依賴語料庫中的信息提取答案。根據1995年《福德姆國際法期刊》發表的《多倫多藍鳥隊的替補球員?——在加拿大安大略省替補工人法與美國替補工人法之間取得恰當的平衡》一文,美國的國家勞動關系法案允許美國的棒球隊在球員罷工期間雇用替補球員,而多倫多藍鳥隊受加拿大安大略省勞動法的約束,根據安大略省的勞動關系法案,多倫多藍鳥隊在球員罷工期間不能雇傭替補球員。11Jordan Lippner, "Replacement players for the Toronto Blue Jays? Striking the appropriate balance between replacement worker law in Ontario, Canada, and the United States", Fordham International Law Journal, 1995 (38), pp.2026-2029.只要“沃森”的語料庫中包含這篇文章,稍加訓練的“沃森”就可以學會將其識別為與此類問題相關的信息,從中提取相關答案,并評估其對答案正確性的置信水平。“沃森”很可能無法解釋它所提取的答案。解釋答案需要人們理解與法律選擇和法律主題相關的規則和概念,而“沃森”不掌握這些知識也不可能使用這些知識。經過適當訓練的“沃森”可以學習識別相關問答對的證據類型,包括語義線索,如“合法雇用”“替代工人”“經濟罷工”等概念和關系。在評估答案的置信水平時,“沃森”能夠學習根據這些證據給予答案多大的權重。12參見Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017,pp. 17-18。
“沃森”的深度問答技術被廣泛應用于法律市場。法律問答讓法律知識的獲取變得更容易。“法律上匝道”(Legal OnRamp)是一個使用IBM“沃森”解析合同的應用程序。公司的合同信息推動了大多數業務運營:收入確認、薪酬、服務和產品交付、風險評估、大量研發和知識產權資產創造。當重大的公司活動或交易發生時,公司都會聘請法律顧問審查合同。公司法律顧問希望能夠輕松回答以下問題:哪些合同包括特定約定?哪些合同包括諸如對間接損失的免責聲明?包含在合同正文而不是附錄中的特定類型的約定針對的是哪些合同?使用普通的信息檢索工具無法輕松可靠地回答此類問題。“法律上匝道”將合同提供給IBM“沃森”和其他機器學習工具,以自動回答法律問題并加快人工審查流程。由于“法律上匝道”直接與公司合作,因此它可以獲得比任何律師事務所更多的合同。在回答問題時,“沃森”分解問題,從合同文本語料庫中搜索候選答案,并根據每個候選答案解決問題的信心對候選答案進行排序。13Ibid., p. 27。
加拿大多倫多大學的學生團隊創建的“羅斯”(Ross)是運用深度問答技術研發出來的法律應用程序,被稱為法律領域的“沃森”。“羅斯”于2015年1月參加了IBM的“沃森”挑戰競賽并獲得了第二名的好成績。“羅斯”利用“沃森”提供的自然語言和認知計算平臺的優勢,以開發者云為基礎向客戶提供法律問答服務。他們給“羅斯”取了一個有趣的綽號——“遇見超級聰明的律師羅斯”。“羅斯”幾乎模仿人類閱讀過程,識別文本中的模式,并提供有關文檔片段的語境化答案。“羅斯”接受以簡明英語提出的問題,并根據制定法、判例法和其他法律淵源提供答案。比如,你問“羅斯”:“破產公司還能開展業務嗎?”“羅斯”就會提供了一個帶有引文的答案,并向你提供一些與該主題相關的讀物。“羅斯”的演示視頻列出了該程序可以處理的示例問題,包括:(1)加拿大公司需要保留哪些公司記錄?(2)加拿大公司的董事可以加入一類股票的國家資本賬戶嗎?(3)員工可以開展競爭業務嗎?(4)如果員工沒有達到銷售目標并且無法完成他們的工作要領,他們可以在不事先通知的情況下被解聘嗎?14Brian Jackson, "Meet Ross, the Watson-Powered 'Super Intelligent' Attorney". https://www.itbusiness.ca/news/meetross-the-watson-powered-super-intelligent-attorney/53376,2018年9月12日訪問。在回答最后一個問題時,“羅斯”屏幕引用了加拿大的雷吉娜訴阿瑟斯案(Regina v.Arthurs,1967)以及該案的摘錄和文本。“羅斯”對這個答案給出的置信水平為94%。“羅斯”總結道:如果一名員工犯了嚴重的不當行為,習慣性疏忽職守,無能,或與其職責不符,或者對雇主的業務造成損害,或者如果他有在實質上對雇主的命令故意不服從,法律承認雇主有權立即解雇不盡責的雇員。“羅斯”建議額外閱讀關于“正當理由終止”的制定法、判例法、法律備忘錄和其他淵源中的讀物。“羅斯”具有從用戶反饋中學習的能力。例如,“羅斯”在雷吉娜訴阿瑟斯案這個答案后跟著一個詢問,如果答案是準確的,請用戶按豎起的大拇指,如果答案是不準確的,請用戶按朝下的大拇指。15Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, pp. 351-352.反饋旨在告知“羅斯”這個答案的準確率,這也為“羅斯”更新答案提供信息。
“羅斯”具有四個方面的優勢:(1)設計高度直觀,易于使用,羅斯可以無縫地引入律師的工作流程;(2)通過尖端的人工智能技術,律師能夠更智能、更快速、更流暢地工作;(3)通過大幅減少研究和流程準備所需的勞動時間來提高效率;(4)通過加快工作流程和提高效率,人們能夠將時間和金錢花在高價值的咨詢任務和復雜的法律事務上,從而提高盈利能力。16https://rossintelligence.com/,2018年9月15日訪問。北美律師事務所按小時收費,平均每小時收取400美元的勞務報酬。由于北美律師收費高昂,許多法律文書工作外包給了印度等其他國家,這些國家的勞動力成本低,他們的律師收費低、服務質量也有保證。“羅斯”問世后法律行業將發生巨大的變化。律師事務所可以將許多工作交給“羅斯”去完成。“羅斯”大大地降低了法律服務的成本,也極大地提高了律師的效率、準確率和盈利能力。根據“羅斯”官網的統計,“羅斯”相比基于“布爾”的搜索節省了30.3%的時間,相比基于自然語言的搜索節省了22.3%的時間,讓每位律師增加了13,067美元的年收入。17同上注。
二、從法律文本中自動提取信息
人工智能長期以來尋求從文本中識別和提取語義要素,如概念及其關系。計算機程序從法律文本中提取語義信息,并用它幫助人類解決法律問題。“信息提取是計算機從人類語言書寫的文檔中提取可識別的信息的行為。”18[美]Douglas Downing,Michael Covington, Melody Covington, Catherine Anne Barrett, Sharon Covington編:《巴朗行業詞典—計算機與網絡》,清華大學出版社2015年版,“信息提取”詞條。典型的信息提取系統的內部工作過程主要包括五個步驟:(1)用一組信息模式描述感興趣的信息;(2)對文本進行“適度的”詞法、句法及語義分析,并作各種文本標引;(3)使用模式匹配方法識別指定的信息;(4)進行上下文關聯、指代、引用等分析和推理,確定信息的最終形式;(5)輸出結果,例如生成一個關系數據庫或給出自然語句陳述等。19參見孫斌:《信息提取技術概述》(上),載《術語標準化與信息技術》2002年第3期。信息提取是從非結構化的機器可讀文檔中自動提取結構化信息的任務。自動提取信息是法律文本解析技術的一個重要特征。在法律專家系統中,專業知識體現在人類專家用于解決此類問題的規則中,這些規則通常由工程師在知識獲取過程中手動構建。而在認知計算中,知識體現在文本語料庫中,計算機程序從中提取候選解決方案或解決方案元素,并根據它們與問題的相關性對解決方案進行排序。計算機程序用于評估相關性的知識主要不是手動獲取,而是通過使用機器學習從特定領域的數據集中提取模式而自動獲取。20參見Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, p. 13。從法律文本中自動提取信息的技術包括:幫助法律信息檢索系統考慮意義,將機器學習應用于法律文本以及從法律法規和法律判決中自動提取語義信息等方面。21參見Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, pp. 31-32。
(一)用機器學習從案例語料庫中提取信息
機器學習是一種自動化分析模型構建的數據分析方法,它是人工智能的一個分支。機器學習算法可以從數據中學習、識別文本特征模式、總結模型中的模式并做出決策。根據學習方式的不同,機器學習分為監督學習、無監督學習和半監督學習。機器學習為從法律文本中提取信息提供了關鍵的技術支持。將機器學習應用于法律文本分為兩個步驟。第一步是收集和處理原始數據,即自然語言法律文本的語料庫。第二步是使用一些語言處理來轉換原始文本數據,以標記、規范和注釋文本,然后法律文檔被表示為特征向量。法律文本中機器學習的目標是對文檔進行分類或進行預測。在涉及法律案件的機器學習語境中,目標可能是通過句子在法律意見中發揮的功能對句子進行分類,例如,分為“法律決定或法律裁決”的句子或“基于證據的發現”的句子。在成文法條款的機器學習語境中,目標可能是按行政法、私法、環境法或刑法等主題對條款進行分類。22Ibid., pp. 236-237。
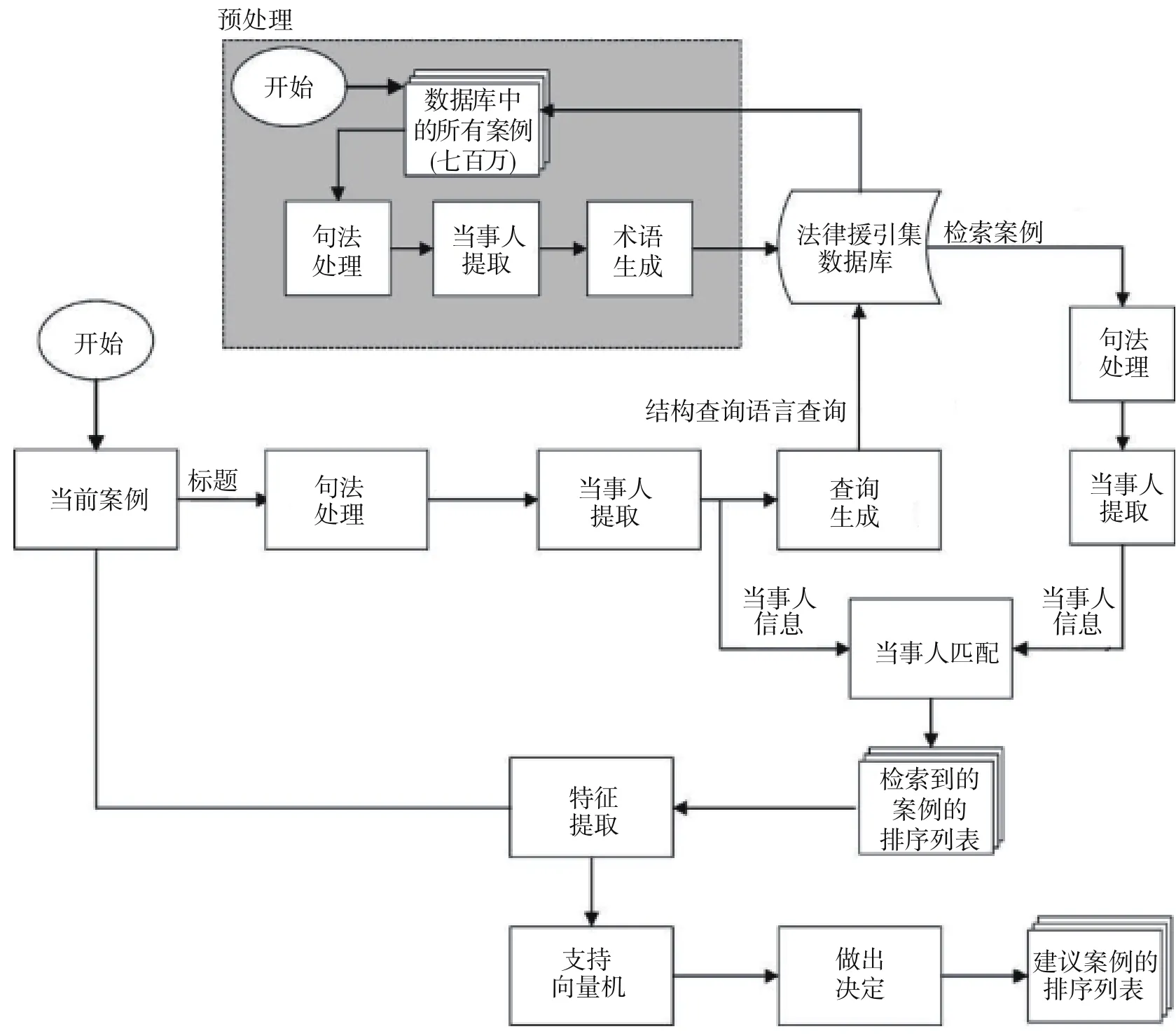
圖2 先前案例檢索系統的處理模塊
“萬律歷史項目”(Westlaw History Project)是用機器學習從法律案件語料庫中提取有用信息的典型系統。該系統“從法院意見中提取信息,并用這些信息建議新案件應當鏈接的先前案例”。23Peter Jackson, Khalid Al-Kofahi, Alex Tyrrell, and Arun Vachher,"Information extraction from case law and retrieval of prior cases", 150Artificial Intelligence 1-2 (2003), p. 240.先前案例檢索識別當前案件中的歷史語言影響的案例。所有案例都應以上訴鏈接(appellate chains)的形式與法律援引集數據庫連接在一起。“歷史項目”系統把來自文本語料庫的信息提取、基于提取的信息的候選案例的信息檢索以及基于機器學習的關于候選案例的判斷結合在一起。如圖2所示,先前案例檢索系統的處理模塊包括三個主要的組件:信息提取、信息檢索和做出決定。信息提取組件處理法院意見及其首部,提取當事人姓名、法院、日期、案卷號和歷史語言;信息檢索組件生成查詢,并把它們提交到法律援引數據集以檢索先前案例的候選案例;決定做出組件采用機器學習算法決定哪個候選案例是當前案件的真正先例。24Ibid., pp.274-276.
標題匹配可以有效地減少候選先例的數量,并幫助候選先例的排序。但標題信息不足以確保好的結果。特征提取和表示模塊從法院意見、案卷號、法院和歷史語言中提取額外的信息。為了最佳地表示每個案例以達到機器學習的目的,每個候選案例用八個特征表示為特征向量。八個特征包括:(1)標題相似性特征,衡量當前案件的標題與候選先例標題的相似性;(2)歷史語言特征,這是一個二進制標志,如果自然語言組件直接從當前案件報告中提取歷史語言,則該特征賦值為“1”;(3)案卷號匹配特征,這是一個二進制特征,當且僅當當前案件和候選先例被分配了相同的案卷號,則該特征賦值為“1”;(4)檢查上訴特征,根據在法院層級中法院之間的關系估計一個法院成為當前法院的先前法院的概率;(5)先前案例的概率特征,估計當前案件實際上具有一個先前案例的概率;(6)引用案例特征,這是一個二進制標志,當且僅當檢索的先前候選案例在當前案件中被引時,這個特征賦值為“1”;(7)標題權重特征,估計當前案件標題中包含的信息;(8)AP1搜索特征,這是一個二進制標志,當且僅當先前案例的候選案例通過一個查詢檢索到并且這個查詢是從當前案件的“上訴行”生成時,該特征賦值為“1”。25Ibid., pp.282-283.歷史項目團隊為了完成任務,采用監督學習并使用支持向量機作為機器學習算法。機器學習算法可以根據文本中的證據區分事實和法律討論,并學會識別和區分法律案件段落的事實和討論。
(二)從法律法規文本中自動提取信息
法律是指引和協調人的行為的社會規范。從普通公民到政府官員和法律職業人士都需要理解法律法規文本,了解法律規范的要求并按法律的要求行為。人工智能與法律研究長期以來致力于從電子化的法律法規文本中自動提取有關規范要求的信息。從法律法規文本中提取的信息可以用于自動法律推理和法律論證。自動提取信息技術可以通過各種方式支持認知計算。
從法律法規中提取的信息主要包括如下類型:(1)法律規范的功能類型,如禁止性法律規范、命令性法律規范和授權性法律規范;(2)與功能相關的特征,一些法律規范的功能類型將更具體的信息作為要素或參數,如義務或責任的承擔者和受益人;(3)法律規范的邏輯構成,法律規范在邏輯上由“前提條件”、“行為模式”和“法律后果”三部分構成;(4)法律規范所屬的部門法類型,如刑法、民法、行政法、環境法或勞動與社會保障法;(5)出現在法律詞庫或本體中的規章概念,如“歐盟合同”、“少數群體保護”和“漁業管理”。從法律法規文本中自動提取功能信息對于概念信息檢索非常有用。
為了從法律法規文本中提取功能信息,意大利的人工智能與法律研究者設計了自動化方法。這種方法包括四個主要的模塊:(1)交叉引用解析器,旨在檢測交叉引用和建構相關的統一命名;(2)結構解析器,旨在自動化遺留內容的可擴展標記語言的網上規范轉換;(3)條款自動分類器,根據條款的模式自動將段落分類為條款類型;(4)條款論證提取器,旨在自動提取條款論證。條款自動分類器能夠自動檢測立法文本中包含的條款類型。它主要由文本分類算法構成。條款自動分類器的輸入是法律條款的文本段落,輸出是從一組候選類別中選擇的預測類型或條款類別。26E.Francesconi and A.Passerini, "Automatic classification of provisions in legislative texts", Artificial Intelligence and Law,2007 (15), pp. 6-7.條款論證提取器的輸入是文本段落和預測類型,輸出的是條款的功能信息和特征。下面舉一例說明條款論證提取器的輸入和輸出。27Ibid., p.3.
輸入:《意大利個人數據保護法典》第7條第1款規定:“打算處理屬于本法案適用范圍的個人數據的控制人必須通知其擔保人。”
類型:義務
輸出:系統提取功能信息:
特征:
接收者:“控制人”
行為:“注意”
對應方:“擔保人”
被提取的功能信息可以作為元數據應用于語義標記中的條款。一旦此類信息納入制定法條款的本體索引,人類用戶就可以搜索所有分配“控制人”向“擔保人”通知的義務的條款。研究者將機器學習和知識工程方法以互補的方式應用于法律條款。機器學習提取了更多抽象的功能類型,如“義務”。知識工程規則提取了更具體的角色扮演者,如被賦予義務的“控制人”。機器學習和知識工程方法各有優劣。機器學習方法手動注釋訓練實例,自動使用機器學習算法來生成區別于實例訓練集的特征。這種方法更靈活,更少領域依賴,并且需要較少的專業知識,但需要足夠大的手動注釋訓練實例集。知識工程方法為每種類型的條款確定清晰的易于觀察的模式,并手動構建規則以識別新文本中的模式并提取相關信息。這種方法不要求手動注釋的訓練數據,但需要手動創建的專家分類規則來捕獲與每類條款相關聯的標準短語。28參見Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, pp. 263-266。
三、論證挖掘技術及其在法律中的應用
論證挖掘(argument mining)是以語料庫為基礎的話語分析的新發展,包括自動識別話語的論證結構,例如前提、結論和每個論證的論證型式,以及文檔中論證與子論證以及論證與反駁的關系。論證挖掘的成功要求自然語言技術、語義學、語用學、話語理論、人工智能、論證理論和論證的計算模型等學科提供的跨學科方法,還需要不同領域的不同類型的來源創建和注釋高質量的論證語料庫。29ACL-AMW, "3d Workshop on Argument Mining at the Association of Computational Linguistics" (ACL 2016). http://argmining2016.arg.tech/,2018年9月22日訪問。
(一)IBM的“辯論者”
論證挖掘技術的發展與IBM“沃森”的兄弟項目“辯論者”(Debater)緊密地聯系在一起。“辯論者”是IBM公司研發出來的新的人工智能項目,它使用“沃森”程序的一些文本處理技術來執行論證挖掘。“辯論者”不僅能從文本中提取信息,還能“理解”信息并運用它們進行推理。2014年春季,IBM研究院總監約翰·凱利三世在米爾肯研究所年度會議上演示了“辯論者”程序。演示的辯論主題為“向未成年人出售暴力視頻游戲應該被禁止”。“辯論者”的任務是檢測相關主張并返回對正方主張和反方主張的預測。“辯論者”以近乎完美的英語回應道:“掃描了400萬篇維基百科文章,返回10篇最相關的文章,掃描了這10篇文章中的3000個句子,檢測到包含候選主張的句子,確定了候選主張的邊界,評估候選主張是支持正方還是反方,構建了一個具有最高主張預測的演示演講,然后準備提交!”“辯論者”能夠自動地從維基百科中提取信息,消化所提取的信息,并運用這些信息進行推理,然后用自然語言呈現它的論證。“辯論者”在視頻中的輸出是聽覺的,可以用視覺術語呈現其輸出的文本。圖3頂部框包含論辯的命題。與實線相連的主張支持該命題,與虛線相連的主張攻擊該命題。從輸入主題到輸出論證的時間是3—5分鐘。值得注意的是,“辯論者”并不真正理解所提取內容,它只是在數據上運行算法并進行概率分析以得出結論。30George Dvorsky, "IBM's Watson Can Now Debate Its Opponents", 2014年5月5日, https://io9.gizmodo.com/ibms-wats on-can-now-debate-its-opponents-1571837847,2018年9月23日訪問。
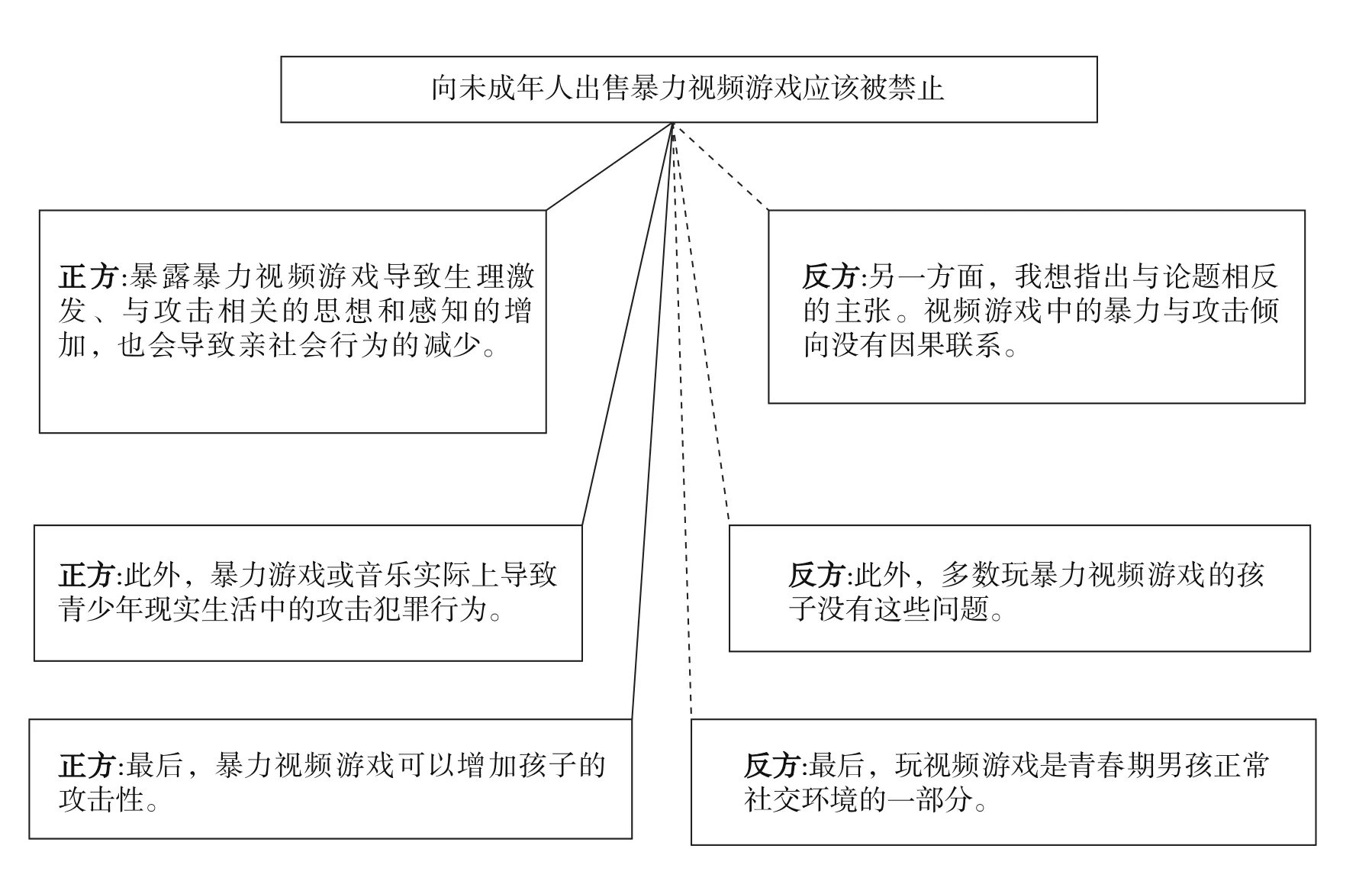
圖3 IBM“辯論者”針對暴力視頻游戲主題輸出的論證 31
2018年6月18日,“辯論者”程序在舊金山IBM辦公室舉辦的辯論賽中擊敗了人類頂尖辯手。它的對手是以色列國際辯論協會主席丹·扎菲爾(Dan Zafrir)和2016年以色列國家辯論冠軍諾亞·奧瓦迪亞(Noa Ovadia)。這次辯論賽共分兩場,以現場觀眾的感受判斷輸贏。兩場辯論賽的題目分別是“我們是否應該資助太空探索”和“我們是否應該更多地使用遠程醫療”。“辯論者”程序皆為正方。給定一個辯題后,“辯論者”程序迅速搜索其龐大的語料庫,尋找最相關的證據,然后挑選最有說服力、多樣性的論點,并安排論點來構建一個具有完整說服力的敘述,以此來支持或反對論點。32參見Lee:《人工智能如何參與辯論》,載《電腦報》2018年6月25日。
IBM“辯論者”團隊開發了一種手動注釋訓練集的方法,以便機器學習可以從文本中提取信息。“辯論者”檢測上下文的主張,直接支持或辯駁特定主題的一般性陳述,還檢測依賴上下文的證據,在給定主題的語境中支持依賴上下文的主張的文本片段。在給定主題和相關文章的情況下,句子組件選擇200個最佳句子,邊界組件在每個句子中界定候選主張,排名組件根據句子和邊界分數選擇50個最佳候選主張。“辯論者”使用機器學習完成句子選擇、邊界設置和候選主張排名這三個步驟。“辯論者”的機器學習取決于人類注釋者執行高質量的訓練文檔集注釋的能力。注釋者被要求將文本片段標記為依賴上下文的主張。“辯論者”團隊開發了一種系統的方法來組織人工注釋工作以最大化可靠性。33參見Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, pp. 306-307。
論證挖掘技術已被用于法律文本解析。論證挖掘技術自動地識別案例文本中最終可用的與論證相關的信息,并隨之產生法律實踐中智能技術的新典范:基于論證相關信息的可靠的概念法律信息檢索,也稱為論證檢索。34Ibid., p. 12。論證挖掘支持律師從法律文本中提取信息建構回答手頭問題的論證。論證簡單地說,就是舉出理由以支持某種主張或判斷。35參見顏厥安:《法與實踐理性》,中國政法大學出版社2003年版,第88頁。有關法律主張、判斷、決定或裁判的證明或辯護就是法律論證。論證挖掘就是要識別和提取法律文本中與法律論證有關的信息。與法律論證相關的信息包括:法律論證的命題、前提或結論,連接前提與結論的論證型式和論證規則,陳述法律規則的句子,陳述案件事實的句子,影響論證強度的信息等。
(二)從案例文本中提取與論證相關的信息
使用機器學習、自然語言處理和提取規則從案例文本中提取與論證相關信息的項目有很多,比如莫查萊斯和莫恩斯研發的系統、智能索引學習(Smart Index Learner,SMILE)項目和法律領域的非結構化信息管理架構(Legal UIMA,LUIMA)系統。莫查萊斯和莫恩斯研發的系統在法律論證挖掘方面做出了開拓性的貢獻,它確定了在論證中起作用的句子,應用機器學習將句子劃分為命題、前提或結論。智能索引學習是基于問題的預測程序的自然語言界面,它充當問題的自然語言描述和預測案例結果的計算模型之間的橋梁。智能索引學習項目致力于識別和提取實質性法律因素和事實模式,它們加強或削弱一方的法律主張。非結構化信息管理架構是用于問答系統的開源阿帕奇架構,IBM“沃森”的技術就是建立在UIMA基礎上的。36參見Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, p. 287。LUIMA是應用于法律領域的以UIMA為基礎的類型系統。它聚焦于概念、關系和提及,以識別司法裁判中句子的論證功能。LUIMA系統是一種非常成熟的法律文本解析技術,因而本文主要介紹LUIMA系統提取與論證相關的信息的方法。
LUIMA采用基于規則的注釋器和機器學習注釋器用語義信息注釋案例文檔。句子分割是注釋案例文檔的第一步。句子分割是將案例文本語料庫分解成句子的過程。任何文本語料庫都是文本的集合,其中每一段落都包含多個句子。執行句子分割有多種技術,基本技術包括在句子之間尋找特定的分隔符,例如句號(.)、換行符( )或者分號(;)。37參見[印度]迪潘簡·撒卡爾:《Python文本分析》,閆龍川、高德荃、李君婷譯,機械工業出版社2018年版,第80頁。LUIMA注釋還標記了一些預設信息,包括事實和語言概念以及與受規制領域相關的提及。LUIMA注釋在案例文本中標識此類預設信息為:(1)術語,例如疫苗術語,疾病術語,因果關系術語。(2)提及,例如疫苗提及,其中包括疫苗首字母縮寫與疫苗術語[“麻腮風(MMR)疫苗”],疫苗接種事件提及,因果關系提及。(3)規范化,疫苗提及的規范化,疾病提及的規范化,即句子中提到的疫苗或疾病的規范名稱。38參見Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, p. 302。基于規則的注釋器根據提及和子句類型自動注釋句子。如果一個句子包括提及原告、必須關系的術語(比如,證明),那就把這個句子注釋為“法律標準表述”(Legal Standard Formulation)。在“根據該標準,請求人必須證明疫苗接種更可能是受到傷害的原因”這個句子中,包括“請求人”術語和“證明”術語,因而把這個句子注釋為表示法律標準的句子。
LUIMA注釋案例文檔的另一種技術是機器學習。機器學習將案例文檔的句子分為三類:法律規則句子,基于證據發現的句子,不屬于這兩類句子的句子(標記為“非注釋”句子)。出于機器學習的目的,句子文本被表示為特征向量。每個特征向量的值是這個特征在文本中沿著特征維度的量。量可以是“0”,表示文檔不具有該特征,或“1”表示它具有該特征。比如,在“羅珀訴衛生與公眾服務部部長”一案中,“在本案的證詞中,萊西博士進一步解釋了他的觀點,即破傷風疫苗接種可能導致請求人羅珀女士的胃輕癱”被注釋為證據句子,而不是基于證據發現的句子,因為它報告的不是法官做出的結論,而是專家證人萊西博士做出的結論。因此,機器學習注釋器將這個句子表示為“非注釋”句子。
LUIMA然后根據注釋過的信息執行論證檢索,即識別和提取與論證有關的信息。論證檢索幫助人類用戶建構支持一種主張的可行論證或反擊對手的最佳論證。論證挖掘技術使法律推理和法律論證的計算模型能夠直接處理法律數字文檔,幫助人們預測和證成法律結果。在疫苗傷害賠償的案例中,請求人必須證明疫苗接種更可能是受到傷害的原因。只有在疫苗接種導致傷害的情況下,請求人才能獲得賠償。因而必須確定疫苗接種與傷害之間存在因果關系。請求人必須通過優勢證據確定:(1)疫苗類型與傷害類型之間有著“醫學理論上的因果關系”;(2)特定疫苗接種與特定傷害之間存在“因果關系的邏輯順序”;(3)疫苗接種和傷害之間存在“近似時間關系”。法律論證的計算模型將適用的制定法和規章要求表示為“規則樹”,即權威性規則條件以及法律判決中的推理鏈,將證據斷言與特殊法官對這些規則條件的事實發現聯系起來。39Ibid., p. 161。
四、結語:法律文本解析對未來法治的影響
深度問答、信息提取和論證挖掘這些文本解析技術為法律實踐帶來了革命性的變化。IBM“沃森”、“辯論者”和UIMA等為這種變革種下了革命的種子。人工智能與法律研究者和技術專家將法律文本解析與計算模型整合在一起,創建了一些新的法律應用程序。這些法律應用程序能完成許多傳統上只能由人完成的智能任務。法律應用程序在定制商品化法律服務中發揮重要作用。它能用法律文本推理,使實踐系統能夠根據人類用戶的特定問題定制其輸出。“法律應用程序不僅會以適合人類用戶特定問題的方式選擇、預訂、突出和匯總信息,還會探索信息并以前所未有的新方式與數據互動。”40Kevin D. Ashley, Artificial Intelligence and Legal Analytics: New Tools for Law Practice in the Digital Age, Cambridge University Press, 2017, p. 13.法律文本解析技術產生時間較短,但在不到十年的時間里卻涌現了六十余種成熟的法律應用程序。41Jonathan Marciano, "Automating the Law: A Landscape of AISolutions", Jun 10, 2017, 載https://www.topbots.com/automatingthe-law-a-landscape-of-legal-a-i-solutions/,2018年10月4日訪問。代表性的法律應用程序包括美國的法律集中營(LegalZoom)、法律機器(Lex Machina)、法律機器人(Legal Robot)、拉威爾(Ravel)、既判力(Judicata)和法律過濾器(Legal sifter)、加拿大的織布解析(Loom Analytics)、英國的法律智能支持助理機器法律人(Robot Lawyer LISA)、以色列的LawGeex和愛爾蘭的布賴特旗(Brightflag)等。這些新興的法律應用程序不僅僅是將法律人的處理過程計算機化和標準流程化,而是創造性地處理一些法律人過去無法完成的任務。
法律文本解析或許是這個時候最重要的技術,它的迅速發展將深刻改變法律實踐、法律職業、法律教育和法學研究。薩斯坎德(Susskind)指出,許多信息技術是顛覆性的,這些技術不支持或兼容傳統的工作方式,它們將徹底挑戰和改變傳統習慣。對法律行業也是如此,這些無處不在、急速增長的信息技術會顛覆和改造律師和法院的運作方式。42[英]理查德·薩斯坎德:《法律人的明天會怎樣?》,何廣越譯,北京大學出版社2015年版,第23頁。數百年來,訴訟律師運用法律方法分析案件的事實構成,總結案件的爭議焦點,尋找適用于手頭案件的法律法規或判例,推理將事實涵攝于法律之下,最后提出訴訟策略并做出法律預測。法律文本解析顛覆了律師的工作方式,它將法律工作分解為不同的任務并逐項以盡可能高效的方式完成。訴訟律師的工作可以分解為文件審閱、法律研究、項目管理、訴訟支持、電子披露、策略、戰術、談判和法庭辯論等任務。這九項任務中除了策略、戰術和法庭辯論,其他的重復性事務性的工作任務都可以用不同方式分包出去。43同上注,第41—42頁。這些分包出去的工作都可以由法律應用程序而非法律人完成。法律文本解析挖掘案件文件和卷宗中的數據,然后匯總這些數據,從中發現一些有用的洞見,包括法官、律師、法院、律師事務所和當事人的各種信息。訴訟律師使用法律文本解析來揭示過去訴訟中的趨勢和模式,然后根據這些趨勢和模式制定手頭案件的訴訟策略并預測法律結果。44Owen Byrd, "Legal Analytics vs. Legal Research: What's the Difference?" June 12, 2017,載https://www.lawtechnolog ytoday.org/2017/06/legal-analytics-vs-legal-research/,2018年8月21日訪問。法官運用智能審判系統實現對起訴狀、答辯狀、庭審筆錄等案件卷宗信息的智能解析和信息提取,提取各類卷宗材料文書所需的核心信息,然后自動生成判決、裁定等法律文書。法律文本解析技術在法律實踐中的廣泛應用將極大地節省律師和法官處理案件的時間,過去他們花上數周完成的工作現在幾分鐘就能完成。
法律職業也將因法律文本解析技術的應用而發生翻天覆地的改變。如果法律應用程序能夠完成許多以前只能由法律職業者完成的工作,那么部分法律職業者將要失業。2013年9月,牛津大學的卡爾·弗瑞(Carl Frey)和邁克爾·奧斯本(Michael Osborne)發表了《就業的未來》研究報告,調查各項工作在未來二十年被計算機取代的可能性。根據他們研發的算法估計,到2033年,法律秘書有98%的概率會失業,律師助理的概率為94%,行政法官和聽證官的概率為64%,書記員的概率為41%,法官和地方法官的概率為40%。45Carl Benedikt Frey and Michael A. Osborne, "The Future of Employment: How Susceptible Are Jobs to Computerisation?",17 September 2013, pp. 62-71. https://www.oxfordmartin.ox.ac.uk/downloads/academic/The_Future_of_Employment.pdf,2019年1月5日訪問。又見[以色列]尤瓦爾·赫拉利:《未來簡史》,林俊宏譯,中信出版社2017年版,第293頁。當然,淘汰傳統的法律的工作的同時也會產生一些新的法律工作。根據薩斯坎德的總結,法律人的新工作包括法律知識工程師、法律技術專家、跨學科法律人才、法律流程分析師、法律項目管理師、在線糾紛解決師、法律管理咨詢師和法律風險管理師。例如,法律知識工程師負責研發法律標準和流程,在計算機系統中組織和表達法律知識。法律技術專家是同時具備法律和系統工程及信息技術管理兩個領域的訓練和經驗的專業人士。46[英]理查德·薩斯坎德:《法律人的明天會怎樣?》,何廣越譯,北京大學出版社2015年版,第129—131頁。這些新的法律職業人士從事的工作迥異于傳統法律職業者所做的事情。
法律文本解析技術將改變法律教育的內容和教學方式。多年來,如何利用技術去講授法律一直是一個法學界不關注的問題,現在漠視技術發展的時代將要終結。技術讓法學教育變得更有效更實際提供了可能性。現如今,同步遠程學習模式、非同步遠程學習模式、大規模開放式網絡課程、翻轉課堂、在線教學、在線協作等創新技術已經廣泛地應用于法學院的法律教育。47[美]米歇爾·皮斯托:《法學院與技術——我們現在何處并將駛向何方》,周亞玲譯,邱昭繼校,載王翰主編:《法學教育研究》第15卷,法律出版社2016年版,第259—272頁。IBM“沃森”為法律教育開辟了新的可能性。法學院擅長的蘇格拉底教學法將受到嚴重的挑戰,老師在《合同法》課程中提出的各種問題都可以交由法律應用程序回答,在線課程將逐漸取代面授課程。法律人工作方式的改變對法律教育提出了新的要求。傳統的法律教育以培養專業基礎扎實、熟練掌握法律職業技能的法律人才為目標,未來的法律教育應根據法律實踐的變化做出相應的調整。根據理查德·格拉納特(Richard Granat)和馬克·勞里森(Marc Lauritsen)的調查,美國有10所法學院非常重視法律文本解析技術,開設了多門相關課程或成立了相關的研究中心。比如,密歇根州立大學法學院建立了一個再造法律實驗室,開設了電子發現、創業律師、法律信息工程與技術、法律解析、訴訟、數據、理論、實踐、過程、律師定量分析和21世紀的法律實踐等法律實踐技術方面的課程。薩福克大學法學院建立了法律實踐技術與創新研究所。法學院提供智能機器時代的律師培訓、流程改進和法律項目管理、法律文件自動化和21世紀律師和決策支持系統的調查等課程。48Richard Granat and Marc Lauritsen, "Teaching the technology of practice: the 10 top schools", Law Practice Magazine,2014: (4) ,載www.americanbar.org/publications/law_practice_magazine/2014/july-august/teachingthe-technology-of-practicethe-10-top-schools.html. 2018年10月3日訪問。
法律文本解析技術將導致法學研究產生相應的變化,它將促使法學與理工科的交叉融合。法學與哲學、社會學、政治學、人類學、經濟學等哲學社會科學的緊密聯系人們已經很熟悉了,而法律文本解析技術將法學與統計學、信息科學、計算機科學和腦科學等學科緊密地聯系在一起。著名法學家霍姆斯早在120年前就預言:“對于法律的理性研究而言,研究歷史文本的人或許是現在的主人,而未來的主人則屬于研究統計學之人和經濟學專家。”49[美]霍姆斯:《法律的道路》,載[美]霍姆斯:《法律的生命在于經驗——霍姆斯法學文集》,明輝譯,清華大學出版社2007年版,第221頁。法律的經濟學研究早在20世紀70年代就異軍突起,成為法學界的顯學。人們沒有想到的是,統計學會成為法學研究的主導學科。人工智能時代,統計學的重要性越發凸顯,人工智能法學的研究越來越需要統計學的支持。
法律文本解析技術方興未艾,這是我國法治發展的重大戰略機遇。法律文本解析技術在法律信息搜索、法律咨詢、法律解釋、證據收集、案例分析、法律文件閱讀與分析、法律推理和法律論證等方面大有用武之地。它的應用是我國智慧法院、智慧檢察院、智慧律所、智慧公安和人工智能法學院建設的重要抓手。
猜你喜歡
法律方法(2021年3期)2021-03-16 05:57:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
山東青年(2016年1期)2016-02-28 14:25:30
小學教學參考(2015年20期)2016-01-15 08:44:38
中國衛生(2015年1期)2015-11-16 01:05:56
中外會展(2014年4期)2014-11-27 07:46:46
浙江人大(2014年5期)2014-03-20 16:20:27
語文知識(2014年1期)2014-02-28 21:59:13
