基于鼠腦海馬位置細胞與Q學習面向目標導航
2019-04-24 06:12:02何洪軍
生物信息學 2019年1期
方 略,何洪軍
(中國電子科技集團公司第二十一研究所,上海 200030)
1971年Dostrovsky和O’Keefe在位于鼠腦海馬結構區域中發現了一種具有空間特異性放電特征的神經元細胞-位置細胞[1]。該細胞是鼠腦海馬結構中的主要神經元,當大鼠自由運動到環境中的某一特定位置時,相應位置細胞會發生最大化放電活動,將位置細胞發生最大化放電活動所對應區域稱為該位置細胞的“位置野”。人類大腦中同樣發現了類似于大鼠位置細胞特性的細胞存在[2-3]。隨著對位置細胞進一步生理學研究發現,位置細胞放電活動在大鼠面向空間目標導航發揮著關鍵作用,該細胞放電活動受環境因素影響。因此,研究外部環境對位置細胞放電活動影響,并將其和嚙齒類動物空間導航聯系起來具有重要意義。
1 模型生理學依據
位置細胞被發現以來,許多學者對該細胞進行了相關研究,由此提出了大量的位置細胞模型,主要包括有基于高斯函數的位置細胞模型[4],基于競爭學習位置細胞模型[5],基于獨立成分分析位置細胞模型[6],基于自組織映射位置細胞模型[7]和基于卡爾曼濾波位置細胞模型[8]等。然而,以上所提到的模型并沒有將外部線索(如視覺、嗅覺等)對位置細胞放電活動影響考慮在內。因為生理學實驗研究發現將視覺線索移除后,位置細胞放電活動會發生強烈變化,位置細胞位置野變得不穩定,這就暗示了視覺線索對于位置細胞位置野的形成和位置野的穩定性具有重要影響[9]。在缺乏視覺線索的情況下,許多研究學者認為路徑積分作為一種額外的機制使得大鼠能夠在空間環境中自由導航[10]。然而,Save等人的實驗表明當大鼠處于黑暗環境中進行自由導航時,單一的路徑積分不足以維持位置細胞位置野的穩定性[11]。如果沒有額外的視覺線索,隨著大鼠自由探索環境,路徑積分會導致大鼠在方向和距離上產生很大的累積誤差。因此,這就需要通過來自于外部環境中具有穩定位置信息(視覺線索)的參考物來校正從而減小誤差[12]。
研究發現,當大鼠在某一空間環境中自由探索該環境空間時,鼠腦海馬結構中的各位置細胞會在各自對應的空間位置處發生最大化放點活動,即在各位置處產生相對應的“位置野”[13]。大鼠對空間環境自由探索完成后,在大鼠腦內形成了其對所處空間環境的認知地圖,該認知地圖是各位置細胞“位置野”聯合表征得到的。認知地圖表征空間環境,研究發現單憑該認知地圖并不能夠使大鼠來正確的預測其下一時刻的運動方向,即不能夠完成面向空間環境某一目標導航的任務。隨著研究不斷深入,研究者發現大腦控制中心內側前額葉皮層(Medial prefrontal cortex, mPFC)與海馬之間的動態聯系是大鼠正確預測其下一刻運動方向的關鍵所在[14-15]。大腦前額葉皮層中最主要的神經細胞是運動神經元,該神經元與大鼠的空間運動息息相關[16-17]。鼠腦海馬中最主要的神經元細胞是位置細胞。大腦腹側被蓋區 (Ventral tegmental area, VTA)里主要存在的神經元細胞是多巴胺能神經元(Dopaminergic neurons)[18-19],該神經元細胞與獎勵預測誤差信號相關。它能夠將接收到的信息傳輸至伏隔核 (Nucleus accumbens, NA)。研究發現大鼠腦海馬中的信息主要傳輸至伏隔核,伏隔核和前額葉皮層之間的信息傳遞方式是雙向纖維投射[20]。即伏隔核從海馬接收空間環境信息,從大腦腹側被蓋區接收獎勵預測誤差信息,通過與前額葉皮層相互作用來正確預測大鼠下一時刻的運動方向。 大鼠面向目標的導航任務神經生理學依據是海馬位置細胞與伏隔核神經元之間與獎勵信號相關的突觸調節, 伏隔核進一步將信息投射至大鼠前額葉皮層來實現大鼠正確預測下一時刻運動方向。大腦前額葉皮層中主要是運動神經元。海馬中主要是位置細胞。基于此,利用位置細胞、運動神經元構建一種前饋神經網絡模型,采用Q學習算法來實現大鼠面向目標導航任務。
2 方 法
2.1 視覺線索感官輸入
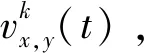
(1)
其中k表示的是四個不同顏色所標記的墻面,t表示的是時間。
考慮到實際因素,在視覺感知信息輸入中添加一定的噪聲信號,假定大鼠在空間環境中自由跑動時對于長距離估計會產生一定的誤差。由公式(2)描述:
(2)
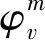

圖1 實驗環境Fig.1 Experimental environment
本文中,構建了一個由輸入層、位置細胞、運動神經元(動作細胞)和輸出層所組成的前饋神經網絡模型來實現大鼠面向目標導航任務,前饋神經網絡模型如圖2所示。
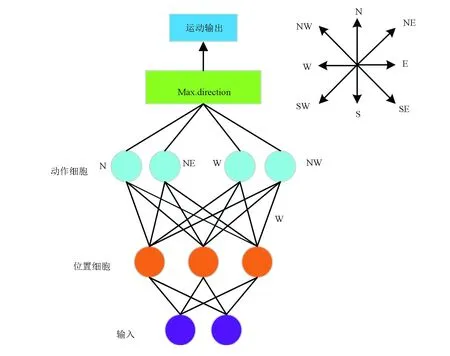
圖2 前饋神經網絡模型Fig.2 Feed-forward neural network model
2.2 位置細胞模型

(3)
其中,u是服從[0,1]之間均勻分布的隨機值,v=0.5和σ=0.2。位置細胞放電率見公式(4),隨機初始化權值,針對某一特定視覺輸入信息通過競爭學習會激活位置細胞。
第i個位置細胞放電率由高斯函數表征[21],由公式(4)來描述:
(4)
其中,σf=0.07表示的是位置細胞位置野寬度。前饋神經網絡模型中權重值調整依據勝者為王機制。即針對某一特定視覺輸入信息,獲勝的位置細胞神經元χt與該特定視覺輸入信息之間權重值會進行相應調整,其余權重值不變。基于競爭學習獲勝的位置細胞神經元χt用公式(5)來描述:
(5)
獲勝神經元權重值按照公式(6)改變:
(6)
其中,0<α<<1代表的是學習效率因子。
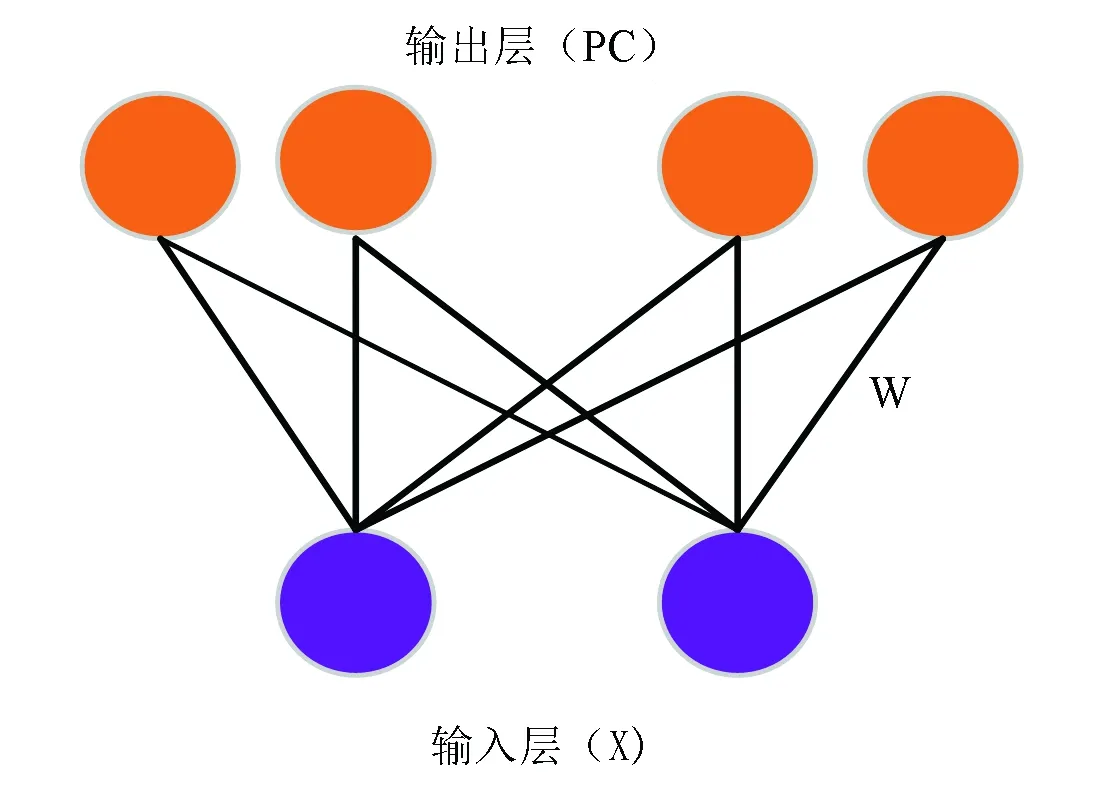
圖3 位置細胞模型Fig.3 Model of place cells
2.3 目標導航任務
某一特定視覺輸入信息通過競爭學習算法激活某些位置細胞神經元,激活位置細胞神經元與運動神經元通過Q學習算法可以得到大鼠下一時刻的運動方向。 大鼠在空間環境中不斷學習直至能找到任一起始位置到目標位置之間導航的最短路徑為止,大鼠空間導航示意如圖4所示。使用如圖1所示的實驗環境,該實驗環境的四面墻被不同顏色(黑色、紫色、紅色和藍色)所標記。大鼠運動的起始位置如圖4中藍色圓點標記所示。目標點位置如圖4中紅色正方形所示。當大鼠剛進入到實驗環境中時,它是在隨機探索環境的過程中找到目標位置(如圖4中黑色虛線所示)。當大鼠經過長時間的學習后,就能夠快速實現起始位置到目標位置的最短路徑導航。
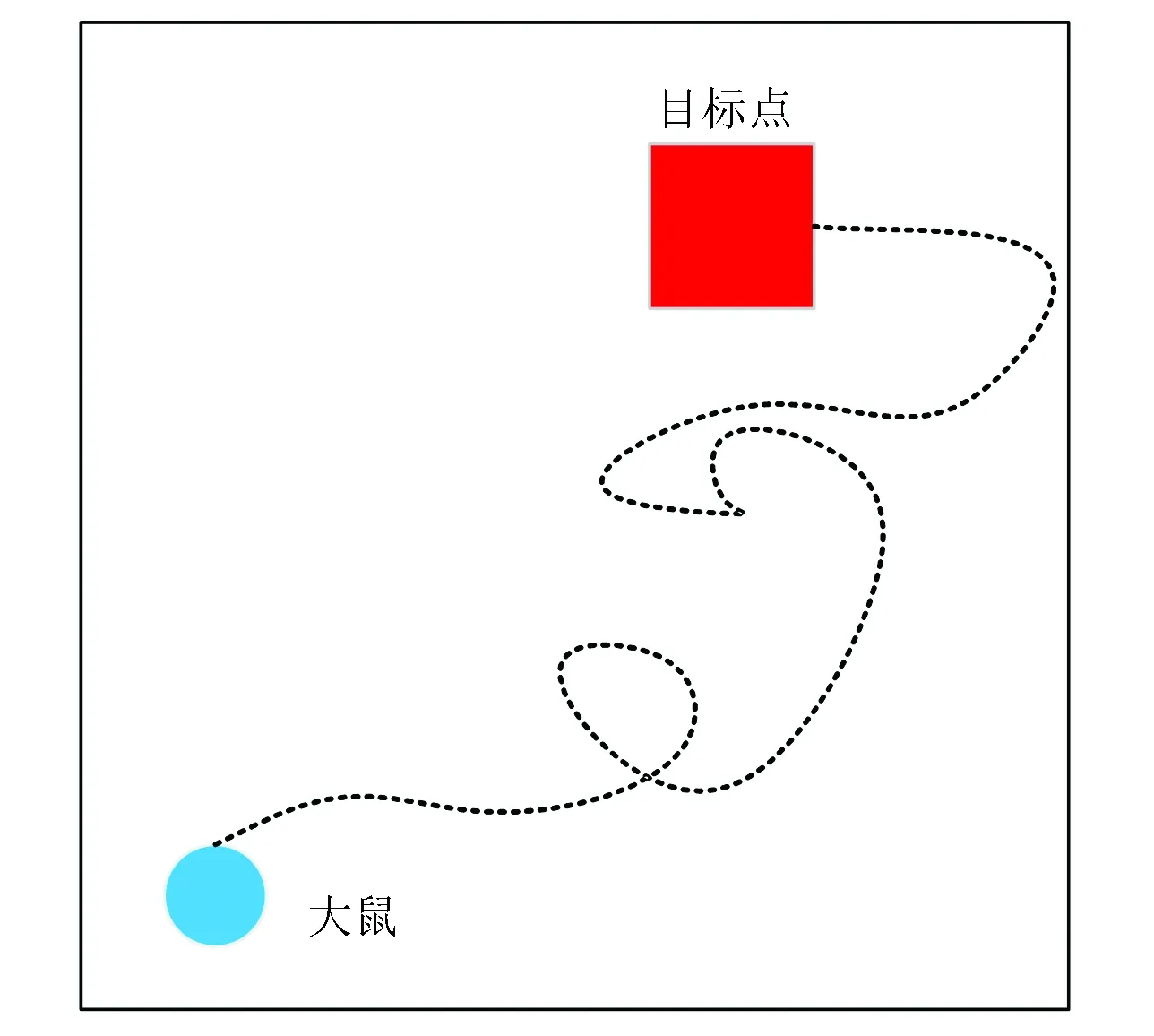
圖4 大鼠空間導航示意圖Fig.4 Schematic diagram of spatial navigation in rat’s brain
注:彩圖見電子版:http://swxxx.alljournals.cn/ch/index.aspx.(2019年第1期).
本文中使用Q學習算法對大鼠空間導航進行研究。該算法應用在如圖5所示的兩層前饋神經網絡模型中,位置細胞作為兩層前饋神經網絡的輸入層,分別與8個運動神經元連接(該8個運動神經元分別代表8個不同方向(北(N),東北(NE),東(E),東南(SE),南(S),西南(SE),西(W),西北(NW))。通過Q學習算法計算得到以上8個方向的Q值,Q值最大的方向就是大鼠下一時刻的運動方向。大鼠向正西和正東的運動由公式(7)和(8)來描述:
Δx=±(Δs+c·ψx)
(7)
Δy=c·ψy
(8)
其中,Δs=500 表示的是大鼠步幅大小,ψx和ψy是服從[-1,1]均勻分布的隨機值,c=100表示的是噪聲幅值。負號代表大鼠向正西運動,正號代表大鼠向正東運動。同樣的,大鼠在西南和東北方向的運動由公式(9)和(10)來描述:
(9)
(10)
當大鼠隨機探索空間環境的過程中運動到某一位置時計算所得Q值是0時,大鼠在當前位置下一時刻的運動方向是不確定,它在當前位置保持方向不變的概率為1-pk,在當前位置選擇一個新方向運動的概率為pk=0.25。當計算的Q值不為0時,大鼠的下一時刻的運動方向由Q值來確定的。

圖5 由輸入層(位置細胞)、運動神經元構建的前饋網絡模型示意圖Fig.5 Feed-forward network model of the input layer (place cells) and motor neurons
位置細胞到動作細胞學習機制是Q學習算法。簡便起見,將t時刻第i個位置細胞放電率由公式(11)來描述:
(11)
其中,i=1,…,Q,Q=500表示的是神經網絡模型中位置細胞總數。
由公式(12)來定義動作值函數:
(12)
其中,Γi,a表示的是第i個位置細胞與運動神經元a之間的連接權重值。根據Reynolds所提及的使用平均Q學習規則[22]。即按照公式(13)更新t時刻真正產生動作at的權值Γi,at。
Γi,at=Γi,at+β(δmaxaA(rt+1,at+1)+Rt+1-Γi,at)Ψi(rt)
(13)
其中,β=0.7表示的是學習率,δ=0.7表示的是折減系數,R表示的是獎勵。將獎勵函數Rt由函數(14)來描述:
(14)
3 實驗結果
實驗過程是大鼠剛進入到實驗環境中時,它是在隨機探索環境的過程中找到目標位置。當大鼠經過長時間的學習后,就能夠快速實現起始位置到目標位置的最優路徑導航,實驗結果如圖6、圖7、圖8和表1所示。本次實驗中大鼠一共進行了40輪實驗。圖6是前20輪實驗結果示意圖,圖7是后20輪實驗結果示意圖。由圖6和圖7可以很直觀的看出在前8輪實驗中大鼠由于剛進入到一個比較陌生的環境中,它只能隨機的去探索目標位置,其運動軌跡是隨機的,當它經過一段的時間學習后對其所處空間環境有了學習認知,便能夠從第9輪實驗開始找到從起始位置到目標位置的最優路徑。圖8是40輪實驗過程中每輪實驗大鼠到達目標位置所需步數示意圖,由該圖也能很直觀的看出從第9輪實驗開始大鼠能夠找到從起始位置到目標位置的最優路徑。表1是大鼠基于Q學習面向目標導航迭代次數與到達目標位置所需步數對應關系表。由該表能夠直觀的看出前8輪實驗中由于大鼠隨機探索環境,此時它到達目標位置所走步數是隨機的沒有規律可循的,當經過一段時間學習后,它到達目標位置的步數是基本穩定的,由表1可知從第9輪實驗開始,大鼠到達目標位置所走步數大約為20步。
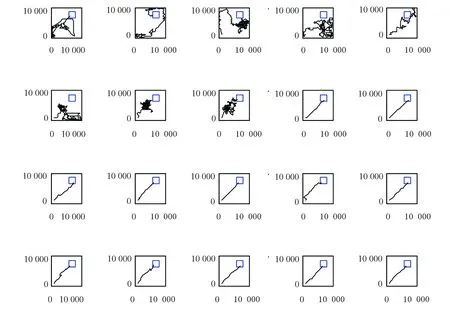
圖6 大鼠前20次運行軌跡Fig. 6 Trajectories of the rat’s paths from the first 20 runs
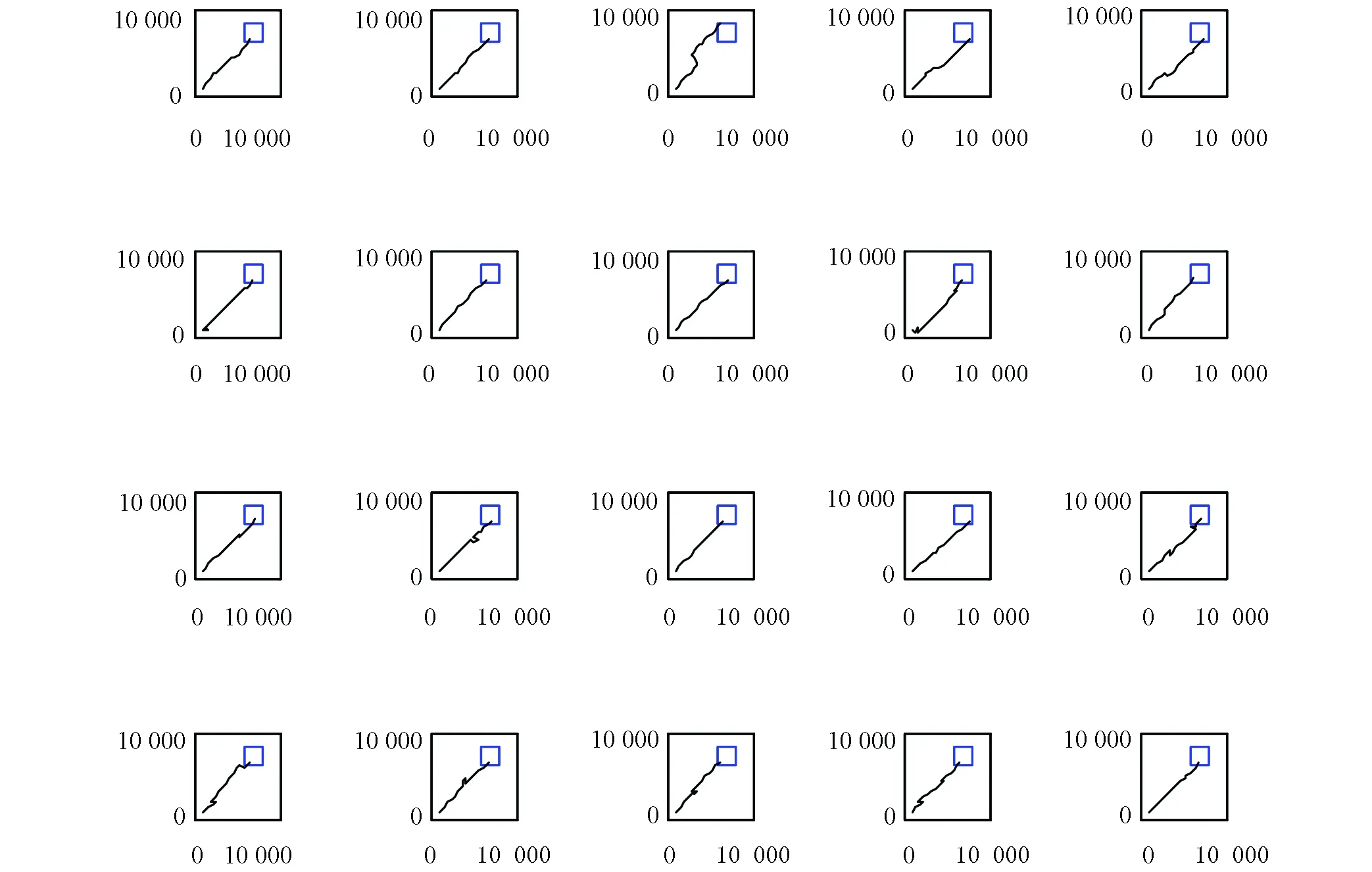
圖7 大鼠后20次運行軌跡Fig. 7 Trajectories of the rat’s paths from the last 20 runs
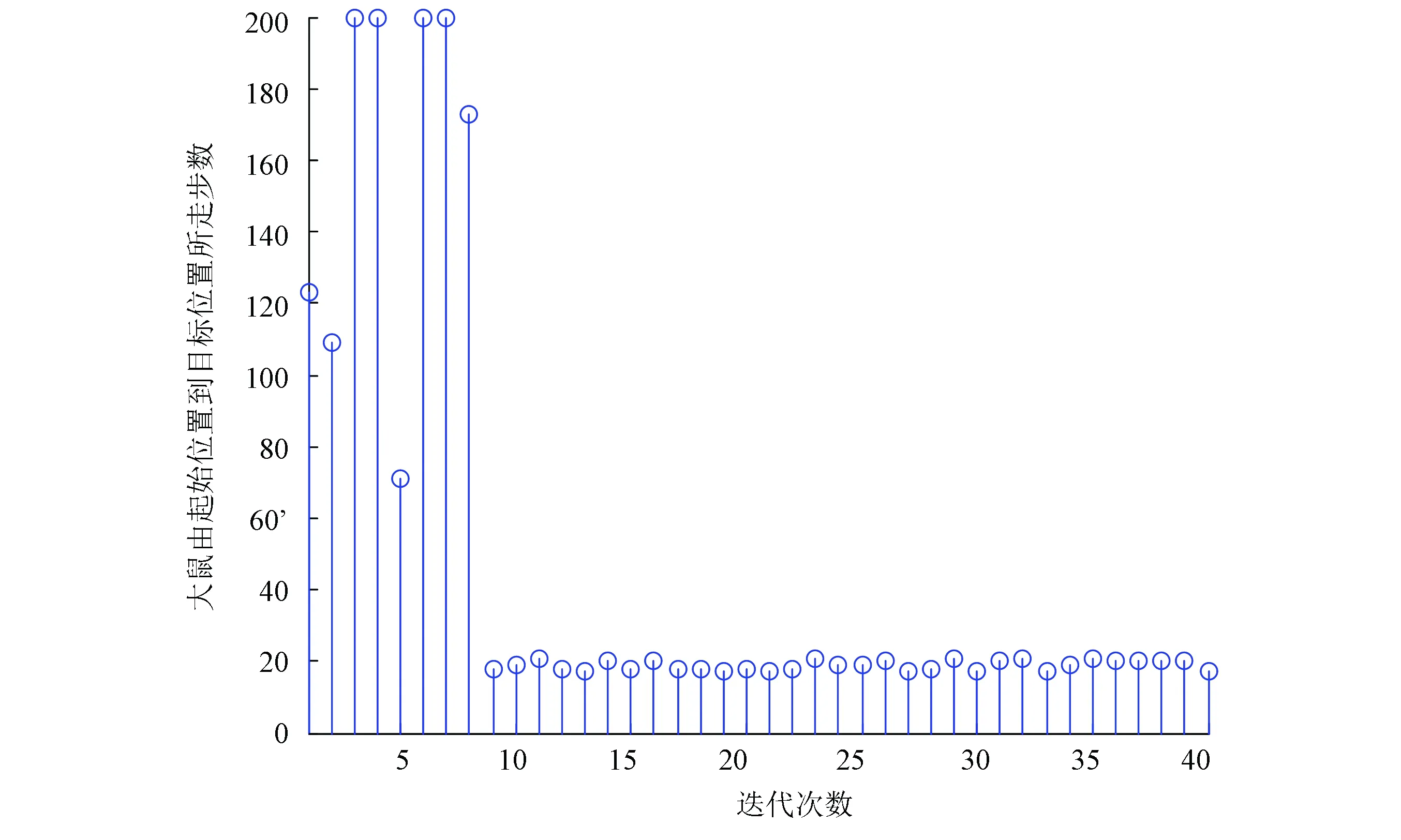
圖8 大鼠到達目標位置所需步數示意圖Fig. 8 The number of steps needed to reach the target position for the rat
4 結 論
強化學習算法主要是應用于解決學習類任務當中,針對仿生學上又主要分為兩類,一類是用于鼠腦海馬仿生導航中[23-26],另一類是仿生機器人在某一特定空間環境中通過強化學習來認知所處空間環境,進而與環境交互執行相關動作[27-30]。本研究充分表明了基于位置細胞、運動神經元來構建一種前饋神經網絡模型,采用Q學習算法能夠快速實現大鼠面向目標導航任務。

表1 大鼠基于Q學習面向目標導航迭代次數與到達目標位置所需步數對應關系Table 1 Corelation between the number of iterations of the good-oriented navigation based on Q learning and the number of steps needed to reach the target position
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2020年6期)2020-02-01 06:28:50
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中國生殖健康(2019年11期)2019-01-07 01:28:02
光學精密工程(2016年6期)2016-11-07 09:07:19
