基于源文件可疑度的軟件缺陷定位方法研究
2019-04-11 01:44:08陸皖麟
兵器裝備工程學報 2019年3期
陸皖麟,王 梟,馮 超,武 劍
(1.中國人民解放軍66133部隊, 北京 100043; 2.中國人民解放軍66135部隊, 北京 100043)
軟件是由不同功能模塊組成的系統集合,其中包含了大量源文件。當源文件中包含缺陷時,軟件系統的部分功能將會發生損壞或導致整個軟件系統癱瘓[1]。為對軟件質量加以保證,規避其中潛藏風險,缺陷定位成為必不可少的關鍵步驟[2]。
本文將缺陷定位理論和缺陷預測方法相結合,提出了新的可疑度概念及其計算方法,將缺陷定位到源文件。主要從關聯層—源文件和待定位缺陷的相關性,預測層—源文件的易錯程度兩個層次對每個源文件進行度量,度量結果定義為源文件的可疑度,可疑度越高,作為缺陷修復對象的可能性越大。
1 源文件可疑度定位方法框架
通過軟件缺陷數據分析和缺陷定位相關理論[3],構建出基于源文件可疑度的缺陷定位方法框架,如圖1所示。其主要過程分為兩個層,關聯層首先依據缺陷數據的不同特征屬性分析待定位缺陷和歷史缺陷之間的相似關系,引入歷史缺陷數據的修復信息對待定位缺陷數據和源文件進行相關性分析,并用相關度來度量源文件和待定位缺陷的相關性大小。預測層分析源文件的內在屬性,例如代碼規模,函數圈復雜度,環路復雜度,文件修改次數等[4],源代碼的不同度量元數據隱含著一定規律的缺陷信息,利用度量元數據構建的預測模型可以預測源文件包含相關缺陷的傾向性,即源文件的易錯程度。
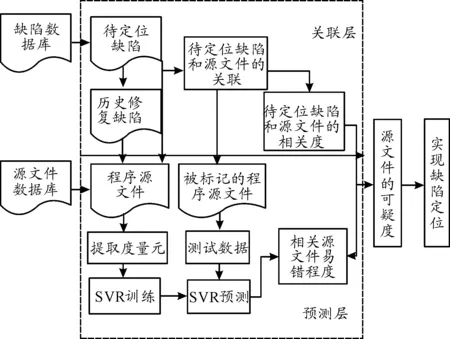
圖1 基于源文件可疑度定位的方法流程
通過相關度和易錯程度獲得源文件的可疑度,定義可疑度計算公式表示為
Score=(1-a)Score1+aScore2
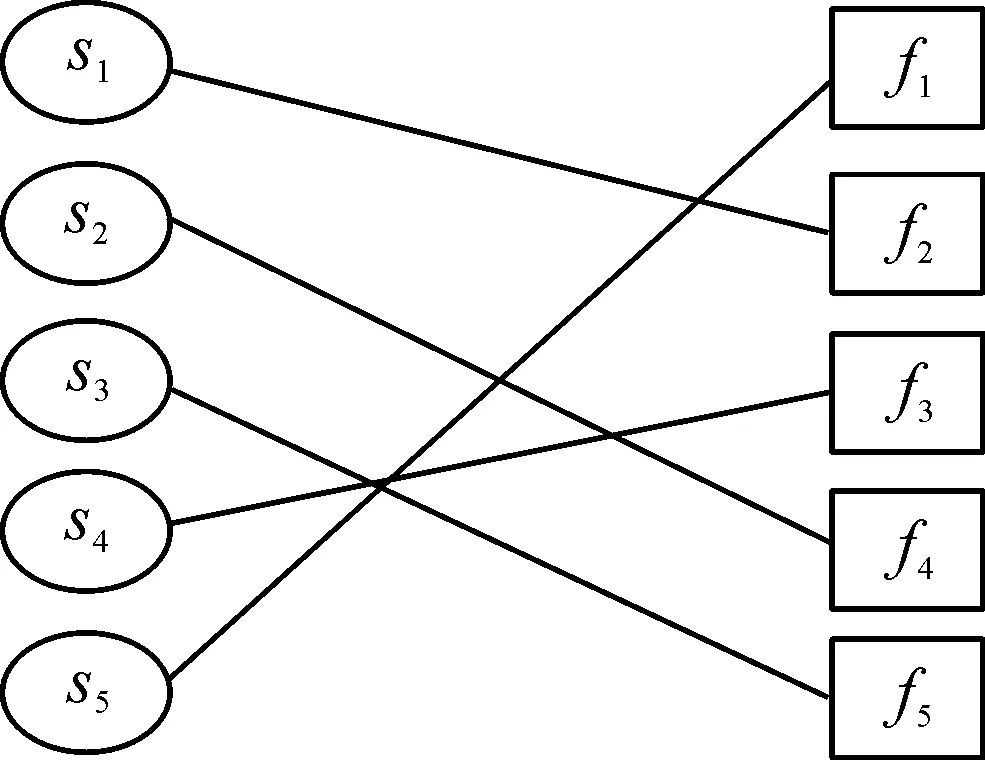
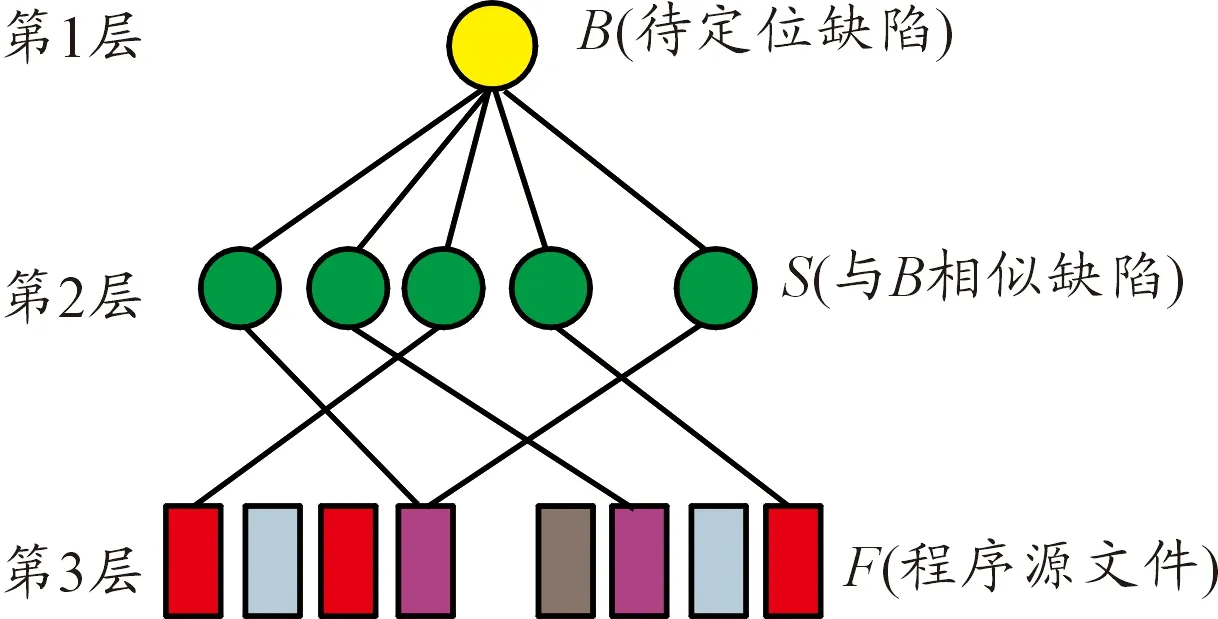
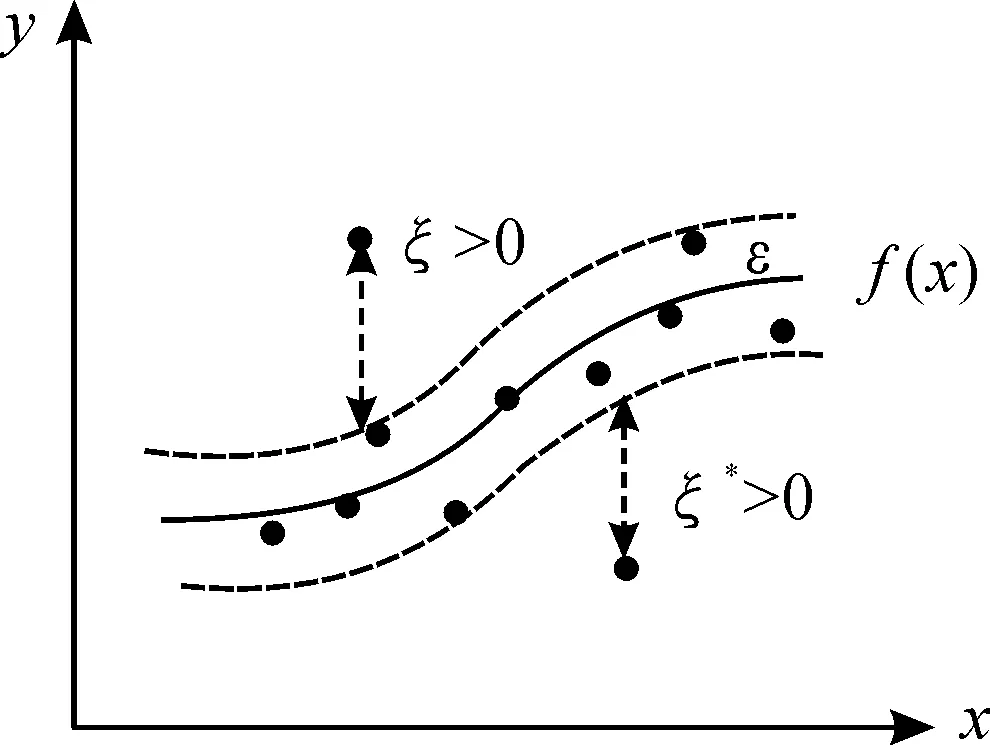
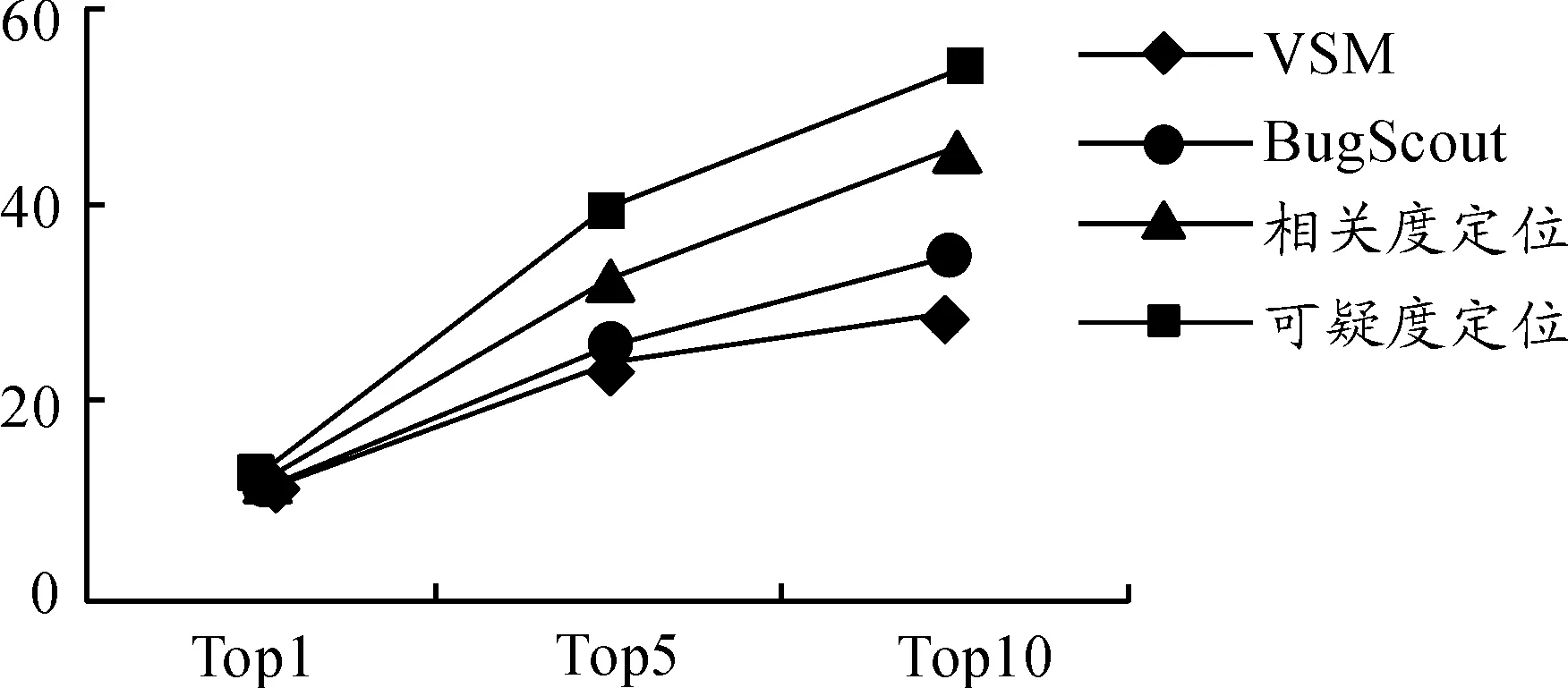
其中:Score1表示源文件和待定位缺陷的相關度,Score2表示源文件的易錯程度,參數a用來調整相關度和易錯程度在可疑度定位過程中的權重,0 關聯層分析的目的是標記與待定位缺陷相關的源文件,并分析待定位缺陷和源文件之間的相關度[5]。主要分為3步:缺陷數據的相似度分析、歷史缺陷和源文件的關聯分析、待定位缺陷與源文件的相關度分析,過程如圖2所示。 圖2 關聯層分析過程 根據軟件缺陷數據的特點,首先從缺陷記錄信息中提取能夠表征缺陷數據的特征屬性,依據向量空間模型思想將缺陷特征屬性抽象化處理,并建立缺陷數據的數學矩陣模型;其次,結合樣本之間的相似系數和距離系數構建改進后的模糊相似矩陣,通過傳遞閉包運算得到模糊等價矩陣;最后利用模糊等價矩陣獲取待定位缺陷數據和歷史修復缺陷的相似度。該方法能夠同時對大規模的缺陷數據進行處理,主要分為5個步驟: 1) 特征屬性提取及抽象化編碼。通過對軟件缺陷數據的分析,共提取10種特征屬性用于缺陷之間的相似度分析[6],具體內容如表1所示。 表1 軟件缺陷數據的特征屬性 抽象化編碼具體規范:如果屬性f取離散化的數值,且0<|f|<∞,則把屬性取值編碼為“1”,“2”,…;如果屬性f取連續的數值,且0<|f|<∞,則把屬性取值編碼為“1”,“2”,…;如果屬性f值缺失(即缺陷i或j缺少屬性f的度量值),則xif=xjf=0。根據上述抽象化編碼規范,得其編碼方式如表2所示。 表2 缺陷數據的抽象編碼 當存在n個缺陷數據時,全部進行抽象化編碼后可映射為n個缺陷特征向量,進一步表示為一個多維矩陣模型,矩陣的每個行向量表示一個缺陷數據,每個列向量表示缺陷數據的一個特征屬性,元素xij表示第i個缺陷數據的第j個特征屬性的編碼值,其數學形式表示為 (1) 2) 數據規范化處理。缺陷數據的相似度分析過程中,缺陷集合X={x1,x2,…,xn}表示的是包含10個特征屬性的所有n個缺陷對象。為了消除缺陷屬性編碼值數量級或單位的差別,需要對抽象化的缺陷數據進行規范處理,將每一特征屬性的編碼值規范到[0,1],消除不同量綱帶來的影響,進一步提升缺陷數據相似度分析方法的效果。筆者采用平移極差變換的方法將缺陷數據規范化處理,如式(2): (2) 3) 模糊相似矩陣的構建。對于缺陷數據的非空集合X(x1,x2…,xn),為計算集合X中缺陷xi和缺陷xj之間的模糊相似關系,定義X和X之間的模糊關系R滿足R∈f(X×X),為X和X的直積,即X×X={(xi,xj)|xi∈X,xj∈X}。其中,R(xi,xj)表示元素xi和元素xj之間的相似度,且滿足R(xi,xj)→[0,1]。則集合X中缺陷之間的模糊關系可表示為m×n的模糊相似矩陣: (3) 簡記為R=(rij)n×n,矩陣中rij=R(xi,xj)表示X中缺陷i和缺陷j之間的相似關系。 通過規范化后的缺陷數據建立上述模糊相似矩陣,考慮10種缺陷數據特征屬性對距離貼近程度和相關關系程度的影響不同,采用距離系數描述缺陷屬性之間的距離貼近程度,相似系數描述缺陷屬性之間的相關關系程度。因此將相關系數和距離系數結合共同構建缺陷數據之間的模糊相似矩陣R= (rij)n×n,進一步提高相似度分析結果的準確性。 相似系數的計算公式為 (4) 距離系數計算公式為 (5) 最終相似度計算公式為 rij=δ1sij+δ2dij (6) 其中,i,j=0,…,n,sij和dij分別表示缺陷數據xi和xj的相似系數和距離系數,δ1,δ2表示相似系數和距離系數各占比重,其中δ1+δ2=1,筆者將相似系數和距離系數賦予相同的比重,即δ1=δ2=0.5,由此可以構造出模糊相似矩陣R= (rij)n×n。 如果模糊相似矩陣R= (rij)n×n滿足自反性、對稱性、傳遞性,則rij能夠準確表示缺陷i和缺陷j之間的相似度,通過模糊相似矩陣R= (rij)n×n的構建方法分析,其滿足自反性和對稱性,但是不滿足傳遞性,所以需進行下一步模糊等價矩陣的構建。 4) 模糊等價矩陣的構建。為了使rij能夠如實反映缺陷i和缺陷j之間的相似關系,需要對模糊相似矩陣進行改造,即構建模糊等價矩陣T。筆者采用求傳遞閉包t(R)的經典算法—平方法計算模糊等價矩陣。 平方法的主要過程是將模糊相似矩陣R不斷自乘[7],當自乘過程首次出現Rk·Rk=Rk時,所得到的傳遞閉包Rk即為模糊等價矩陣T。因為模糊等價矩陣滿足自反性,對稱性和傳遞性,所以模糊等價矩陣T中的元素tij能夠準確表示缺陷i和缺陷j之間的相似度,根據模糊等價矩陣T中能夠得到任一缺陷和其他缺陷的相似度。 5) 截矩陣的構建。給定任意α∈[0,1]的閾值,對于X和X之間的模糊關系T,截集Tα表示為Tα={(xi,xj)∈X×X|tij≥α}。對于二元組(xi,xj)∈Tα,表示缺陷xi和缺陷xj滿足閾值α水平的相似關系。 定義:設給定模糊等價矩陣T=(tij)n×n,對任意α∈[0,1],記 Tα=(αtij)n×n (7) 其中: (8) 則稱Tα=(αtij)n×n為T的α截矩陣。 模糊等價矩陣的α截矩陣是一個布爾矩陣,通過缺陷數據集合建立模糊等價矩陣T之后,就能夠依據截矩陣將某行或某列為1的對象劃歸到一類。 假設,缺陷數據1,2,3之間的模糊等價矩陣為 設置閾值α=0.5,則T的α截矩陣為 為確定與缺陷2相似的缺陷,只需提取Tα中的第2行或第2列中為1的元素,其中,t23或t32為1表示與缺陷2和缺陷3滿足閾值水平的相似關系。 設置不同的α閾值,缺陷之間的相似關系提取結果也不同。在α從0~1的變化過程中,模糊等價矩陣T的α截矩陣也會隨之改變,α越大提取的缺陷之間的相似度也越高。 歷史缺陷信息不僅包含缺陷的各種特征屬性,還包括缺陷修復的源文件位置信息等,根據其修復信息可以追溯每個缺陷所變更的程序源文件,歷史修復缺陷和源文件的相關性分析就是建立歷史缺陷及其修復的源文件的鏈接關系。 定義(缺陷修復位置關系圖):把缺陷和源文件抽象化在圖中用各個節點表示,位置關系G=(S,F)表示缺陷和源文件的位置關系,其中S代表所有缺陷數據,F代表程序源文件。如圖3所示,缺陷s1所修改的源文件為f2,缺陷s2所修改的源文件為f4,連接線表示缺陷和源文件之間的鏈接關系。 圖3 缺陷修復位置關系 當一個待定位缺陷B提交時,首先需要對其相似的歷史修復缺陷和歷史缺陷所變更的源文件進行分析,然后構造一個3層異構圖,如圖4所示。第1層的節點表示待定位缺陷B;第2層表示歷史修復缺陷中與待定位缺陷B相似的歷史修復的缺陷數據集S,其相似程度依據閾值大小進行設置;第3層表示歷史修復缺陷所變更的程序源文件集合F,通過對歷史缺陷數據的修復信息進行查詢,建立歷史修復缺陷數據和源文件的鏈接關系,表示這些源文件對第2層的歷史缺陷數據產生影響。 圖4 待定位B缺陷和源文件的關聯關系 因此,待定位缺陷和程序源文件的相關度分析過程中,首先需要對待定位缺陷和歷史修復缺陷進行相似度分析,建立第1層和第2層的關聯;然后根據歷史修復缺陷所變更的源文件信息建立第2層和第3層的關聯;最后得到第1層待定位缺陷和第3層程序源文件的相關度。其中,待定位缺陷和程序源文件的相關度Score1的計算公式如下: 其中,Similarity(B,Si)表示待定位缺陷B和歷史修復缺陷Si的相似度;m表示所有與程序源文件Fi相關聯的缺陷Si的數量;n表示Si相關的源文件個數。 預測層分析是通過缺陷預測方法對關聯層標記的源文件進行易錯程度分析的過程。將缺陷密度[8]作為源文件易錯程度的度量,首先選取對缺陷密度影響較大的度量元構建源文件缺陷密度預測模型,然后對源文件的缺陷密度進行預測,獲得源文件易錯程度的度量。主要思路是將源文件的度量元作為預測過程的輸入,將源文件的缺陷密度作為預測過程的輸出,通過相應的預測方法建立度量元和缺陷密度之間的關系,用于下一步的預測,如圖5所示。 圖5 缺陷定位的預測層分析框架 為保證源文件缺陷密度預測的準確性,需對缺陷密度和度量元進行相關性分析,選擇對缺陷密度影響較大的度量元作為預測模型的輸入。采用Spearman秩相關系數的分析方法,用來計算度量元和缺陷密度之間的相關系數。 給定度量元和缺陷密度的n組源文件數據,可表示為X(x1,x2,…,xn)和Y(y1,y2,…,yn)。其中,xi表示第i個源文件的度量元的值,yi表示第i個源文件的缺陷密度。首先將和中數據進行組對,即(x1,y1),(x2,y2),…,(xn,yn)。然后將xi和yi分別按照數值大小進行排列,獲得和各自所占名次(即秩),記作Ri和Si。由此可以得到數據組(x1,y1),(x2,y2),…,(xn,yn)的n對秩,即(R1,S1),(R2,S2),…,(Rn,Sn)。利用Spearman等級相關系數衡量度量元X和缺陷密度Y之間的相關程度,可表示為 (9) 標準的相關系數和相關關系的評價指標如表3所示,選取滿足相關系數閾值的源文件度量元,構建源文件的缺陷密度預測模型。 支持向量機(Support Vector Machine,SVM)在小樣本、非線性和高維度空間的模式識別中具有獨特優勢[9-10],通過支持向量回歸(Support Vector Regression,SVR)構建源文件缺陷密度預測模型。 表3 相關關系評價指標 源文件缺陷密度預測就是給定數據樣本集合{(x1,y1),…,(xi,yi),…,(xl,yl)},其中,xi表示源文件的度量元向量,yi表示源文件缺陷密度,xi∈Rn,yi∈R,i=1,2,…,l。在Rn上尋找f(x)=w·x+b來擬合,使集合點與超平面的誤差較小,定義正則化的誤差函數: 假設允許模型的預測值與真實值有一定的偏差ε,則在模型中定義一個損失函數,用于調和預測值和實際值的誤差,這種類型的函數就是ε不敏感損失函數。 ε不敏感損失函數定義為 Lε=|yi-f(xi)|ε=max{0,|yi-f(xi)|-ε} 利用定義的ε不敏感損失函數忽略一定范圍內的誤差,當樣本點位于兩條虛線內的管道時,認為該點沒有損失,兩條虛線構成的管道為ε-管道。處于虛線上的樣本決定了ε-管道的位置,這部分樣本稱為“支持向量”,如圖6所示。 圖6 非線性回歸函數的不敏感帶 回歸問題則等價于最優化問題: 在上述模型中,需要事先確定損失函數中的參數ε,筆者基于上述原理構建出ν-SVR的缺陷密度預測模型,將ε的值自動最小化,并使用非負常數ν控制支持向量的數目。另外選擇合適的核函數K(xi,xj),把上述回歸問題轉化為最優化問題: (10) 對偶問題為 (11) 其中,ν和C為常數。最終建立的SVR預測模型為 (12) 為了體現本文缺陷定位方法的通用性,選用Eclipse平臺的開源項目AspectJ中的缺陷數據。該項目中有完整的缺陷數據庫和歷史變更記錄,并具有不同數量的缺陷和源代碼文件。將AspectJ項目中的缺陷數據作為歷史缺陷,并從中選取2002年7月至2006年10月的286個缺陷數據作為待定位缺陷,其中的源文件共有6 485個。 實驗提取286個缺陷數據,將每個缺陷數據進行抽象化編碼。通過關聯分析和預測分析,獲取每個缺陷數據所對應的源文件可疑度排序,完成每個缺陷的定位工作。最后通過分析驗證上述缺陷數據實際所修復的源文件位置,對定位結果的準確性進行評估。 為評估本文缺陷定位方法的效果,依據現階段普遍采用的TopN(TopN Rank)、MRR(Measurement Result Recording) 、MAP(Mean Average Precision)3項評估指標對該方法的實驗結果進行對比。實驗對比4種缺陷定位方法,方法1采用VSM定位方法[11];方法2采用BugScout定位方法[12];方法3為本文缺陷定位方法中僅采用待定位缺陷和源文件的相關度(a=0),相似度閾值為0.55時的定位結果。方法4為本文基于源文件可疑度(a=0.2),核函數為徑向基函數(RBF)的定位結果,上述4種方法的定位結果如表4所示。 表4 不同方法的缺陷定位結果 本文針對TOP1,TOP5,TOP10的準確率對上述4種方法進行對比分析,對比結果如圖7所示。 圖7 開源項目AspectJ中不同缺陷定位方法結果 通過圖7對比結果可知,基于可疑度的缺陷定位方法總體效果較好。TOPN表示可疑度排序的前N個源文件中包含需要修復的源文件的準確率,從TOP1的角度分析,四種方法的定位效果基本相似,因為定位問題本身的復雜性,相對來說TOP1的準確性仍處在較低的水平,本文定位方法的優勢并未得到突顯。從TOP5和TOP10的角度分析,方法4相比于方法1和方法2具有較為明顯的優勢,其中方法1和方法2的定位過程是從信息檢索的角度出發,檢索缺陷報告和源文件中代碼的文本相似度,但是一般情況下缺陷報告采用自然語言描述,源文件采用程序語言描述,因為源文件和缺陷報告的語言空間不同,所以對定位效果有一定影響,容易產生不理想的結果。 方法3所得的源文件可疑度排序列表,雖然能夠定位到程序源文件,但是忽略了缺陷修復的行為規律和源代碼自身代碼質量。方法4既考慮了源文件和待定位缺陷之間的相關度,又考慮了源文件的內在結構和歷史修復信息即對源文件易錯程度的預測。上述實驗表明:采用本文方法對缺陷進行定位能夠取得較好的效果。2 關聯層分析
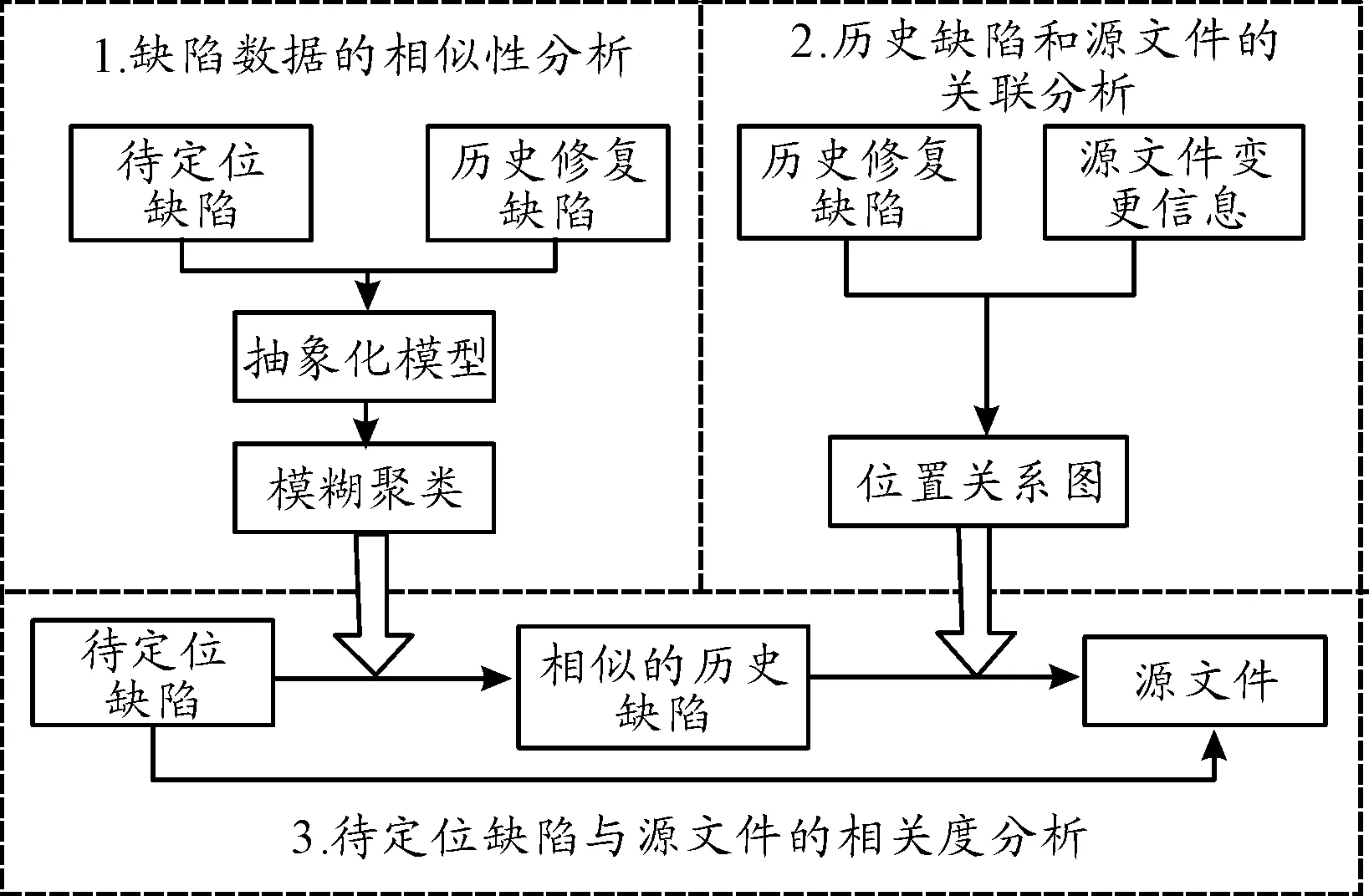
2.1 缺陷數據的相似度分析


2.2 歷史缺陷和源文件的關聯
2.3 待定位缺陷和源文件的相關度分析
3 預測層分析

3.1 源文件度量元的選擇
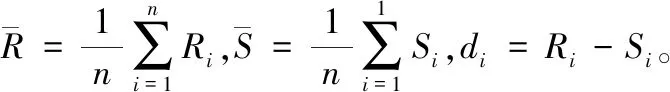
3.2 預測模型構建

4 實驗及分析
4.1 實驗設計
4.2 結果分析

猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
兒童故事畫報(2019年5期)2019-05-26 14:26:14
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
