基于聚類分析的中美航空事故調查報告中安全建議的研究
2019-04-11 08:58:48孫文龍
海外文摘·藝術 2019年1期
孫文龍
(中國民航大學飛行技術學院,天津 300300)
0 引言
隨著我國民航事業的快速發展,民航飛機的安全性也越來越高,并且以其快捷、舒適的優勢逐漸成為人們出行最受歡迎的交通工具之一。但一些不安全事件、事故征候還是時有發生,特別是航空事故還是無法徹底避免,在航空事故發生后必須要進行事故調查,民航事故調查的目的是為了防止事故/事件的再次發生,為了達到這一目的,事故調查方在調查的過程中和最終調查報告發布時都會針對調查過程中發現的安全系統的缺陷發布各種安全建議。
聚類分析是數據挖掘和機器學習中常見的技術,在學術和工業領域被大量使用,因此本研究運用聚類技術對這些安全建議進行處理,充分發揮計算機強大的計算能力,利用聚類技術實現安全建議文本數據的自動分類,能夠給民航事故調查員提供思路以及各單位人員在安全管理中作為參考依據,最終提高中國民航的安全水平。
1 研究方法
文本挖掘主要涉及到數據挖掘、自然語言的處理、模式識別、信息檢索等技術。本研究中利用的文本聚類分析方法是文本挖掘技術的一種,在數據挖掘方面特別是在對大數據的分析與處理方面應用廣泛,是一個非常有效的數據處理分析方法。聚類分析有以下特點:
(1)聚類是在對數據沒有深入了解的情況下,通過聚類算法自動把數據集劃分為多個類別,每一個類別稱為簇。
(2)聚類的目標是:在同一個類別中的數據相似度比較高,而在不同類別中的數據相似度比較低。聚類和分類不同,它是一個無監督學習的過程。
(3)聚類分析是一個逐步試探的過程,它根據數據集本身的特點進行自動的分類,與事先設定好的分類規則無關。
安全建議是文本的一種,因此本研究運用文本聚類的方法對中美航空事故調查報告中的安全建議進行文本聚類的處理,最終實現安全建議的自動分類。
安全建議的文本聚類處理流程圖如圖1所示。
在對安全建議文本集進行文本聚類的過程中,從“中英文分詞”到“特征權重表示”階段處理是通過編寫Python語言代碼來實現;“聚類算法的選擇”以及“聚類結果的輸出”階段是借助于MATLAB工具來實現。
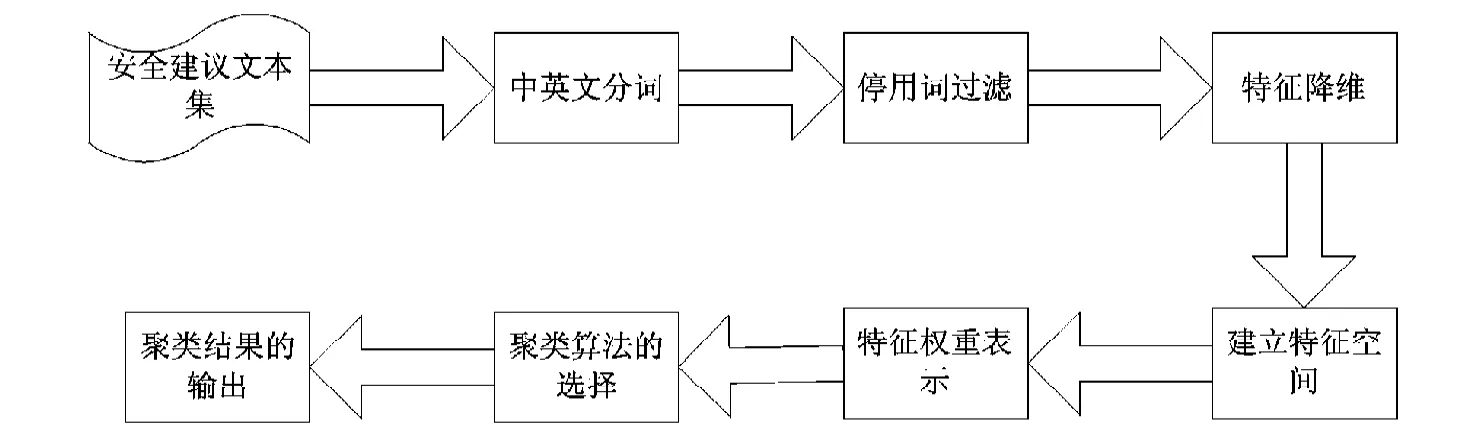
圖1 文本聚類過程

表1 部分中英文安全建議特征詞
2 數據來源
本研究收集了中國民航在2017年發布的事故/事故征候/不安全事件調查報告130份,在這些報告中共發布了安全建議319條;美國NTSB在2013-2017年發布的航空類安全建議302條,針對這兩組數據進行了分析。
3 研究過程
3.1 中英文分詞
分詞指的是將一些漢字序列或者是英文的句子切分成一個個單獨的詞,然后把這些詞與機器詞典中的詞條進行匹配,如果在詞典中能夠找到上面切分出的單個詞,說明匹配成功(識別出一個詞)。對于本研究來說,分詞結束以后,每一條安全建議就被切分成了多個詞組的形式。
3.2 停用詞過濾以及特征降維
由表1可知,分詞結束后也產生了很多無意義的詞,比如中文的像“的”、“后”、等等,英文的像“of”、“to”等等,把類似這種無意義的詞歸結為停用詞,因此為了提高最終聚類結果的準確性有必要把這些停用詞過濾掉,這時本研究引入了中英文的停用詞表,其中包括中文的停用詞3832個,英文的停用詞891個。
通過以上的分詞以及停用詞過濾,把最終得到的詞稱為安全建議的特征詞,Python運行后最終得到了1740個中文特征詞,1638個英文特征詞。部分特征詞如表1所示。
3.3 建立特征空間
建立安全建議文本的特征空間是進行安全建議文本聚類分析的重要組成部分,本研究采用的是應用最廣泛的向量空間模型。向量空間模型的原理是把一組文檔的集合表示成向量空間中的多個向量,在本研究中也就是把每條安全建議用一個向量來表示,每個特征詞對應一個坐標軸,將每個安全建議特征詞的權重大小作為對應每個坐標軸上的值,假設用Weight來表示權重的大小,有N個特征詞,則某一條安全建議d對應的向量為:
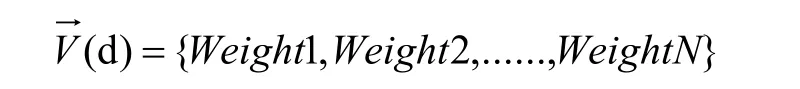
WeightN
表示在安全建議d中第N個特征詞的權重大小。這樣安全建議之間的相似度計算就轉變為N維向量之間的相似度計算。對于本研究來說,Python運行后得到的中文安全建議N的取值為1740,英文的為1638。3.4 特征權重表示
在權重大小的計算方面,本研究采用的是詞頻-反文檔頻率(TF-IDF)算法。
對于在某一文檔d
里的詞語t
來說,t
的詞頻可表示為:
n
是詞語t
在文檔d
中的所出現的次數大小,分母是在文件d
中所有的詞語所出現的次數之和。IDF衡量的是某一個詞在整個文本集中的重要程度。IDF的公式表示如下:
D
|是文本集中所有文檔的總數,分母是其中包含詞語t
的所有文檔的數目。本研究通過計算某個安全建議特征詞的tf*idf來作為該特征詞的權重。最終得到了中英文安全建議的權重矩陣。3.5 聚類算法的選擇
本研究采用的是k-means聚類算法。在完成對安全建議數據的結構化轉換之后,需要根據每條安全建議間的相似度進行聚類。在k-means聚類算法中,對于每條安全建議間的距離運算過程,本研究采用的是“歐式距離”和“余弦距離”。
歐氏距離是應用最常見的距離度量,它衡量的是向量空間中各個點之間的絕對距離(直線距離)。公式如下:
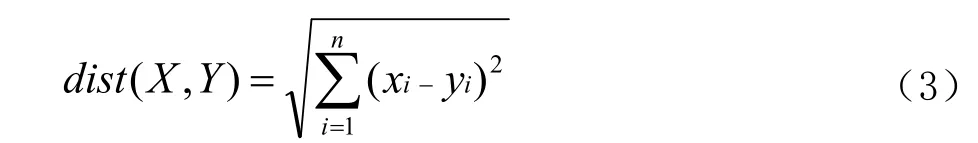
X
、Y
分別指某一個文檔,x
、y
分別是對應文檔中某個特征詞的權重大小,n
是特征詞的個數。余弦距離用向量空間中兩個向量夾角的余弦值作為衡量兩個個體間差異的大小。相比距離度量,余弦相似度更加注重兩個向量在方向上的差異,而非距離或長度上。公式如下:

X
、Y
分別指某一條安全建議,x
、y
分別是對應安全建議中某個特征詞的權重大小,n
是特征詞的個數。3.6 聚類結果的輸出
本研究把Python處理得到的中英文權重矩陣分別導入MATLAB軟件,調用其中的聚類處理模塊,分別選擇“歐式距離”和“余弦相似度”進行聚類。由于k-means算法需要事先設定k的大小,因此本研究設置初始簇個數分別為3、4、5,探究不同的k值對聚類結果的影響,然后根據聚類的結果統計每一個聚集中的中英文安全建議數目
通過分析得出:“余弦距離”在對中美安全建議的處理方面效果更好,主要基于以下評價標準:
(1)類簇的數量是否合理:用“余弦距離”對安全建議進行聚類,每一類中的數量分布相對“歐氏距離”更加均衡。
(2)類簇的可解釋程度高低方面:通過對以上不同類別中的安全建議內容進行分別閱讀認知,發現用“余弦距離”處理得到的結果中,每一類中的安全建議相對“歐氏距離”更像一個整體,相似度更高一些,可解釋程度也更高。
一般以類中數量適中,類簇可解釋程度較高作為聚類效果較好的標志。
4 結語
在研究過程中,得出以下結論:(1)由于安全建議中也存在較多的民航專業詞匯,如果單獨用jieba詞庫進行分詞會產生較多有歧義的詞,因此如果在jieba詞庫里面再加入民航專業詞匯,這樣最終的分詞效果會更好;(2)中美航空事故調查報告中的安全建議作為短文本的一種,每條安全建議大約都是幾十個詞最多也就一百個詞左右,并且安全建議的數量相對較多,中美安全建議的總詞數都分別達到了兩萬多字,經過文本的預處理過程最終篩選出的特征詞分別高達一千多個,與每條安全建議詞的數量相差巨大,這樣會導致權重表格比較稀疏,最終會影響聚類的效果;(3)歐氏距離衡量的是空間各點的絕對距離,跟各個點所在的位置坐標直接相關;而余弦距離衡量的是空間向量的夾角,更加體現在方向上的差異,而對絕對的數值不敏感。因此造成了聚類結果的差異。
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
學生天地(2020年32期)2020-06-09 02:57:54
制造技術與機床(2019年10期)2019-10-26 02:48:08
人大建設(2018年9期)2018-11-18 21:59:16
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2017年5期)2017-08-15 00:53:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
浙江人大(2014年4期)2014-03-20 16:20:16
語文知識(2014年1期)2014-02-28 21:59:13
