連續音素的改進深信度網絡的識別算法?
2019-04-02 08:47:58陰法明
應用聲學 2019年1期
關鍵詞:模型
陰法明 趙 焱 趙 力
(1南京信息職業技術學院通信學院 南京 210023)
(2東南大學信息科學工程學院 南京 210096)
0 引言
音素識別指的是對給定的語音特征向量,估計語音標簽序列的過程,在諸多語音識別系統中具有廣泛的應用[1?2],如關鍵字識別、語言分類、說話人識別等。有效的音素識別是提高語音識別的關鍵。
目前語音識別系統常用隱馬爾科夫模型(Hidden Markov models,HMM)來處理語音中的時域變量,用高斯混合模型(Gaussian mixture models,GMM)來確定每一個HMM狀態是如何對應于一幀輸入語音參數[3]。但是這種方法還存在一些缺點:在模擬數據空間中非線性樣本時,其統計無效。例如對球面上的點集進行建模時,GMM就需要使用大量的對角高斯或協方差高斯[4]。此外這種方法的語音是通過調制動態系統中相對較少的參數產生的,這意味著它真實的底層結構是用了一組低維數據來表示一幀包含了上百參數的語音。所以如果能充分挖掘幀中的信息,就有可能找到一種比GMM更好的方法來進行語音建模。
為克服上述缺點,有學者提出將深度神經網絡應用于聲學建模中,用深信度網絡(Deep belief network,DBN)/隱馬爾科夫模型(DBN/HMM)結構來提高最終的識別率[5?6]。Google與YouTube的相關實驗也表明DBN/HMM在語音識別效果上要遠遠優于傳統的GMM/HMM[4]。而DBN是通過將多個受限玻爾茲曼機(Restricted Boltzmann machine,RBM)堆疊而成,所以RBM的訓練成為整個結構的關鍵。Hinton[7]在2010年提出了對比散度(Contrastive divergence,CD)用來訓練RBM,之后又出現了持續對比散度(Persistent contrastive divergence,PCD)[8]。但是這兩種方法都是對單條馬爾可夫鏈進行采樣,且在初始化數據上也較為粗糙,導致其在計算模型期望時存在較大誤差。
為此本文在并行回火(Parallel tempering,PT)算法的基礎上,根據來自多條吉布斯鏈樣本的狀態能量,進行等能量劃分,構建多個能量環,提高相鄰溫度鏈之間的交換率,進而優化RBM的訓練,并將訓練好的RBM堆疊成DBN進行音素識別。在TIMIT語料庫上,由改進的并行回火算法所獲得的識別率明顯高于對比散度類算法。
1 受限玻爾茲曼機
受限玻爾茲曼機(RBM)是一種特殊的馬爾科夫隨機域,一個RBM包含一個由隨機的隱層單元構成的隱層和一個由隨機的可見單元構成的顯層,其中隱層一般為伯努利分布,顯層一般是高斯分布或伯努利分布[9]。RBM可以表示成雙向圖,只有不同層之間的單元才會存在邊,同層單元之間都不會有邊連接,即層間全連接,層內無連接。
RBM是一種基于能量的模型,其可見矢量v和隱層矢量h的聯合配置能量由公式(1)給出。
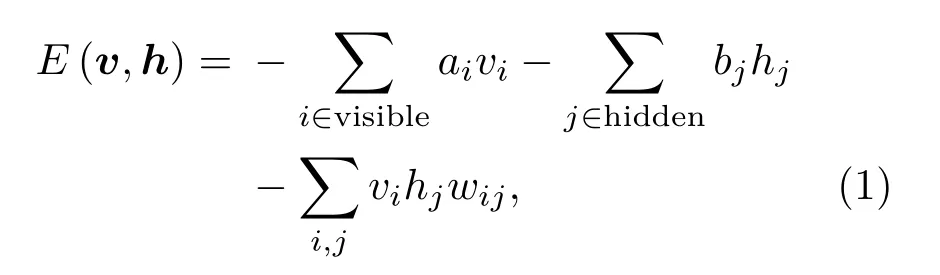
其中,vi是可見單元的二值狀態,hj是隱層單元的二值狀態,ai和bj分別是可見單元i和隱層單元j的偏置值,wij是鏈接權值。通過E可以定義可見單元和隱層單元狀態的聯合分布概率:
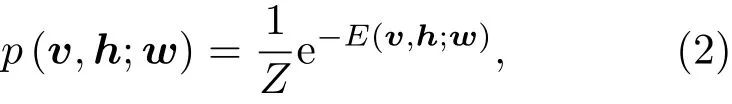

因為RBM層內無連接,所以隱層單元之間是獨立的,所以可見矢量v的概率是對隱層單元的求和。RBM中的權值更新算法依據梯度下降法[7]:
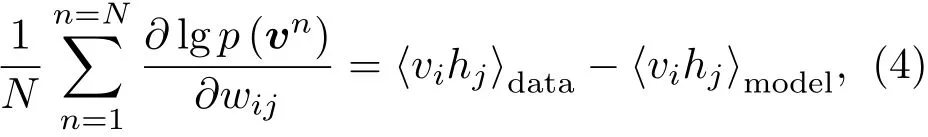
式(4)表示由輸入數據所確定的期望?vihj?data與模型獲取的期望?vihj?model之間的差異。最終,可以得到RBM的權值每次更新的大小為
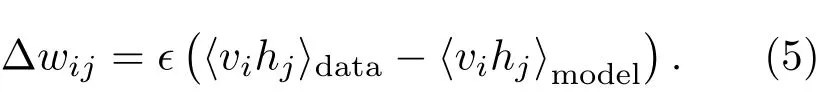
2 改進的RBM的訓練算法
對于RBM而言,由于隱層單元之間沒有連接,無偏樣本?vihj?data是很容易得到的,而且條件分布,給定一個可見矢量v,隱層單元hj的狀態為1的概率為
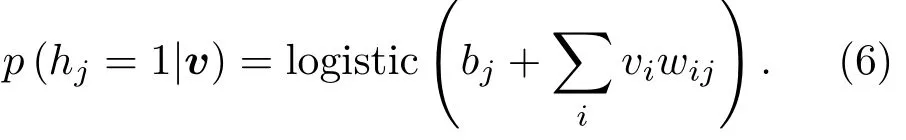
同理可得給定一個隱層矢量h,可見單元vi的狀態為1的概率為
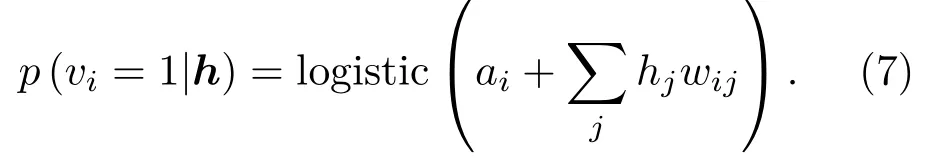
無偏樣本?vihj?model的獲得是很困難的。傳統算法采用對比散度來近似計算該模型的期望,步驟總結如下:(1)初始化可見矢量v0;(2)采樣h0:p(h|v0);(3)采樣v1:p(v|h0);(4)采樣h1:p(h|v1);如此交替進行采樣來訓練RBM。由此可知,該算法的復雜度是指數級增加的。
為解決RBM的訓練效率問題,目前提出了對比散度(CD)、持續對比散度(PCD)和并行回火(PT)等方法[10]。對比散度是訓練RBM的標準方法,它通過訓練數據來初始化吉布斯鏈,然后交替執行CD-1算法,所以實際上它并沒有依據模型分布來計算對數概率的梯度[7]。持續對比散度是通過對一條持續馬爾科夫鏈進行吉布斯采樣來計算模型梯度,其初始吉布斯的狀態來源于前一次的更新參數,而不是訓練數據[8]。這兩種方法都僅使用單一的馬爾科夫鏈來計算?vihj?model,這會引起訓練退化。尤其是對含有多個峰值的目標分布,這種使用對比散度或持續對比散度的吉布斯采樣會容易陷入局部最優。
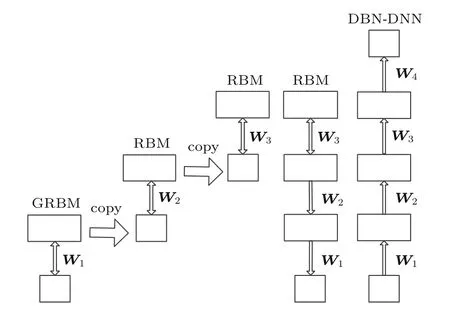
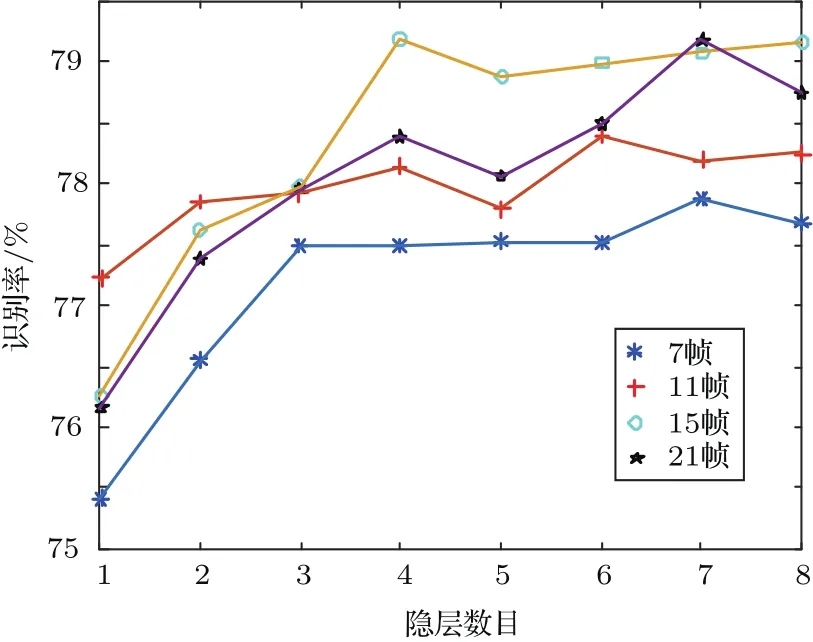
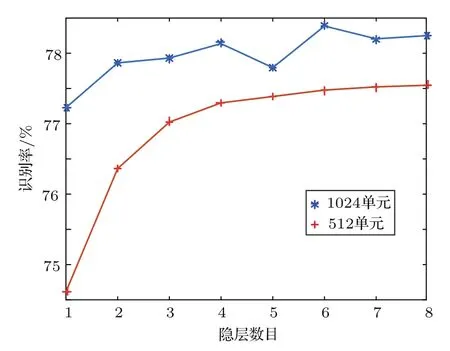
“回火”作為一種通用策略,它通過從1/t<1的模型中采樣來實現不同峰值之間的快速混合。本文使用并行回火采樣對RBM訓練(RBM-PT),并行回火引入了增補吉布斯鏈,它能夠從漸進平滑的原始分布中采樣[11?12]。RBM-PT在訓練過程中,每個溫度對應一條吉布斯鏈并使用并行回火的方法采樣。每條吉布斯鏈對應一個不同的溫度ti,ti滿足1=t1< ··· 根據式(2),在不同的溫度下,并行回火RBM聯合概率為 通過將式(1)的RBM參數θRBM={W,a,b}中的顯層單元與隱層單元之間的連接權重W乘以溫度β,整個模型的參數變為θRBM?PT={βW,a,b},對于偏置值a和b并沒有改變。此時,并行回火算法可與受限波爾茲曼機結合,改善訓練效率。公式(8)中的參數t指“溫度”,該參數反映了基于能量模型的統計物理起源。當溫度趨于0時,1/t則趨于無窮,此時的基于能量的模型是確定性的。反之,基于能量的模型成了均勻分布。 并行回火蒙特卡羅算法包括兩個階段: (1)Metropolis-Hastings采樣[13]階段:根據已有的采樣值計算當前溫度的下一個采樣點,基本采樣計算公式為 (2)交換:并行回火RBM模型的交換條件如下: 其中,tγ與tγ?1是兩個相鄰的溫度,E(vγ,hγ)與E(vγ?1,hγ?1)是其對應的隱層期望。如果滿足該條件,就把相鄰的溫度鏈下的采樣點交換,否則不交換。為了提高這種交換率,本文提出了如下改進方法:由公式(10)可得,當溫度固定時,交換率取決于兩個狀態能量之差,且差值越小交換的可能就越大。本文根據所有鏈的狀態能量,將狀態空間分為幾個等能量集合,促使當前狀態向等能量集中的其他狀態轉移。具體算法如下: 首先引入d+1個能量水平: 理論上H1應小于最小能量,但在本文中H1被設為最小能量,而Hd等于最大能量值。因為這樣也能包含模型中的所有狀態能量。H2,···,Hd?1通過均分(Hd?H1)獲得。 其次根據這d+1個能量水平,要將N個馬爾可夫鏈劃分為多個能量環,每個能量環Dj定義如下: 接著在能量環內執行交換,而是否交換的依據類似于公式(10),不同的是此處的能量差應為同一能量環內的兩條鏈的能量差。實際中交換的次序是從高溫向低溫執行的。此外由于在訓練時RBM的參數是動態改變的,所以這些狀態能量也是動態的,實際操作中我們只要在訓練RBM前設定好能量環的數量d即可。 最后經過多次循環采樣、交換,最終將t1=1溫度下的采樣值用于RBM預訓練模型參數θ,并采用并行回火獲取的目標采樣值可使RBM訓練獲得較好的應用效果。 在訓練好一個RBM后,其隱層單元狀態可以作為訓練下一個RBM的數據,所以該RBM能夠學習到第一個RBM隱層單元之間的依賴性。這一過程可以一直重復下去,直到產生所需要的非線性特征檢測器的層數,層數越多統計數據結構也就越復雜。將多個RBM堆疊起來就能產生一個多層生成模型——深信度網絡(DBN)。雖然單個RBM是間接模型,但由它產生的DBN是一個混合生成模型。DBN的最上面2層是無向鏈接,其他層是自頂向下的有向鏈接。獲得DBN之后,在其頂層之上,再增加一個softmax輸出層,輸出每種音素對應的概率值。此時的網絡稱為DBN-DNN,如圖1所示。 圖1 利用RBM堆疊產生用于音素識別的DBNFig.1 Stacking up RBMs to form DBN for phoneme recognition RBM的預訓練僅僅為了使得DBN獲得一個較好的初始權重,避免訓練時陷入局部最優[14]。為了使得DBN能更好地應用于音素識別,還需要針對目標輸出進行監督訓練。其輸出目標為語音內的中間幀所對應的HMM狀態。訓練的損失函數為交叉熵,通過方向傳播算法獲得網絡的最終權值。 本文實驗在TIMIT語料庫上進行,選擇462個說話人的3296個語句為訓練集,選擇TIMIT的核心測試集(24個說話人的192個語句)作為測試集。語音信號使用Hamming窗處理,幀長25 ms,幀移10 ms,預加重系數為0.97。聲學特征參數使用13階梅爾頻率倒譜系數(Mel-frequency cepstrum coefficients,MFCC),以及其一階、二階差分系數,最終使得每幀語音含有39維特征參數。RBM的訓練使用8條吉布斯鏈。預訓練時的學習率為0.001。監督學習中的學習率為0.0001,以Adam為優化器。 圖2 輸入幀數變化時的音素識別性能Fig.2 The phoneme recognition performance when the input frames numbers change 圖2 給出了隱層單元數為1024時,隱層數與幀數對識別結果的影響。從圖2中可以看出,隨著隱層數量和輸入幀數的增加,識別性能有明顯改善。其中隱層數量的增加提高了網絡對非線性函數的擬合能力,而幀數的增加則代表了輸入上下文信息量的增加。當DNN的隱層數為4、輸入幀數為15時,取得了最佳識別性能。說明隱層數量的增加并不會無限度地提高識別率,因為隨著層數的增加,會導致梯度消失等問題[15]。同樣輸入信息的增加也不會無限度地改善系統性能,一方面是因為時間跨度較大的兩幀語音數據之間的相關性較小,甚至有可能從一個音素所在時間蔓延到另一個音素時間,導致識別率下降;另一方面是當網絡參數確定后,DNN對于這些特征的區分能力是有限的。如圖2中15幀語音與21幀語音所對應的識別率曲線圖所示。 圖3給出了輸入幀數固定為11幀,隱層單元數對識別結果的影響。從圖3中可以看出,當隱層數固定時,增加隱層單元數可以提高音素識別性能。當隱層單元數較少時,通過增加隱層數量能有效提高識別性能,但當隱層數過多時,這種改善效果就顯得非常有限。這表明隱層單元數在一定程度上決定了網絡最終的識別率。實際中,過多的隱層單元數和隱層數會帶來龐大的時間開銷,而帶來的性能改善卻是有限的,所以往往需要折中考慮參數配置。 圖3 隱層單元數不同時的音素識別性能Fig.3 Phoneme recognition performance with different number of hidden layer nodes 上文中簡述了各種不同RBM的訓練方法及各自的特點,本實驗給出在隱層單元數為1024、輸入幀數為11幀時,不同訓練算法的識別率對比結果。從圖4中可以看出,并行回火類算法的識別性能明顯優于對比散度類算法。主要原因在于對比散度與持續對比散度僅使用一條馬爾可夫鏈進行梯度估算,而并行回火類算法則依據從原始分布中采樣出的多條吉布斯鏈對公式(4)進行計算,其精確度更高。而本文所提的方法的識別率比對比散度算法提高約4.5%,比原始的并行回火算法識別率高1%左右,因為通過等能量劃分后,相鄰溫度下的狀態交換率提高了,進而提高了最終的識別率。由此說明在沒有增加計算量的情況下,本文對并行回火算法的改進在音素識別應用上是有效的。 圖4 不同訓練算法的音素識別性能Fig.4Phoneme recognition performance of different training algorithms 本文首先研究分析了RBM的學習原理,在并行回火算法的基礎之上,根據模型分布所得的樣本能量,進行等能量劃分,以提高相鄰溫度鏈之間的交換率,進而提高模型期望的計算精度,訓練出較好的RBM。然后將RBM組成DBN應用于音素識別中,實驗表明,由該方法訓練所得的RBM可以有效提高最終識別率。

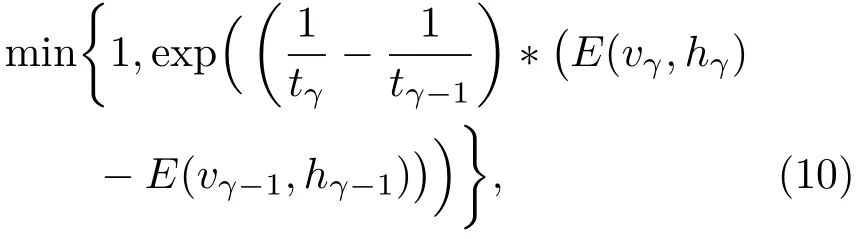
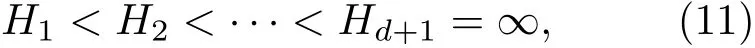
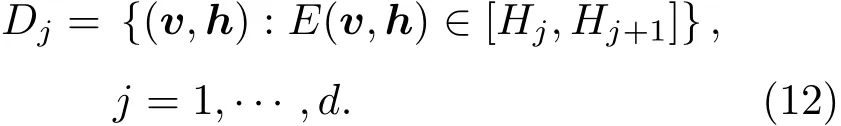
3 基于RBM的深信度網絡
4 實驗結果分析
4.1 實驗配置
4.2 參數性能分析實驗
4.3 不同訓練算法的對比實驗

5 結論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
