基于圖優化的Kinect三維視覺里程計設計
2019-03-05 08:14:20張兆博伍新華
傳感器與微系統 2019年3期
張兆博, 伍新華, 劉 剛
(武漢理工大學 計算機學院,湖北 武漢430000)
0 引 言
里程計作為同步定位和地圖構建(simultaneous localization and mapping,SLAM)[1,2]的關鍵部分,近年來逐漸成為機器人領域的熱點研究問題,而SLAM更被認為是實現移動機器人自主化的核心技術。視覺里程計(visual odometer)一詞源于Nister D等人[3]在2004年的一篇里程碑式的文獻,旨在通過分析視覺信息,來獲取運動的軌跡信息,是通過視覺傳感器作為機器人“雙眼”的基礎。
視覺里程計根據計算運動軌跡所使用的數據傳感器類型,可以分為單目里程計、雙目里程計、以及RGB—D里程計。2010年下半年,微軟推出了可以直接獲取景深信息的RGB—D相機Kinect,再加上其大眾化的價格,深受眾學者的喜愛。
早期Bailey T等人[4]使用擴展卡爾曼濾波算法來求視覺里程計。文獻[5~7]介紹了利用濾波求解視覺里程計的典型方法。這類算法對于運動時間較短的小場景可以取得較好的結果,但大規模場景的里程計會隨著誤差的累積產生較大的偏差。
Martinez Henry P等人[8]在2012年最先提出使用RGB—D相機求解視覺里程計,并提出一種TORO算法用來對相機位姿進行優化。該類算法雖起步較晚,但卻在近年來取得了不俗的成果[9~11]。Nikolas Engel Hard等人[12]在2012年實現了一種手持RGB-D里程計系統并進行了改進。Engel J等人[13]在2014年提出的LSD—SLAM中首次引入“關鍵幀”的概念,即通過選取有代表性的幀來求解視覺里程計。Mur-Artal R等人[14]在2015首次將優化的過程運行在線程上,提高了系統的性能。
本文使用Kinect作為視覺傳感器,進行視覺里程計的計算。本文在Henry算法的基礎上,充分結合Kinect相機易于獲取深度圖像這一特點,提出一種新的基于深度圖像匹配的關鍵幀選取算法,通過在關鍵幀上構建帶環圖模型,對視覺里程計結果進行局部和全局優化。實驗結果表明,相比較Henry P等人的方法,本文方法在減小里程計相對誤差上效果顯著,這對以視覺里程計為基礎,重建三維場景的應用中具有重要的作用[15,16]。
1 基于深度圖像的關鍵幀選取
Kinect攝像機的幀率一般在30 Hz左右,計算每一幀的視覺里程計是不可取的。因為當幀與幀之間距離過近時,相當于沒有移動;過遠時,則無法進行計算。因此,只用當攝像機的運動在一定范圍內時,計算才有意義,這樣的幀定義為“關鍵幀”。本文根據Kinect攝像機易于獲取深度信息這一特點,利用光流法匹配幀間位姿,利用閾值來篩選關鍵幀。
假設3維空間中一點X=[x,y,z,1]T,在時刻t與時刻t+1之間的剛體運動為
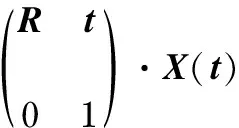
(1)
式中R3×3為3個自由度的旋轉矩陣,t3×3為3維平移向量。變換矩陣T可以表示為
(2)
式中T為圖像幀之間的位置變換,T又稱為幀間位姿;[ωx,ωy,ωz]為相對于x,y,z軸的旋轉;[tx,ty,tz]為相對于x,y,z軸的平移。連續的變換矩陣T即視覺里程計。根據透視投影,x(t+1)于t+1時刻在深度圖像上的投影點為
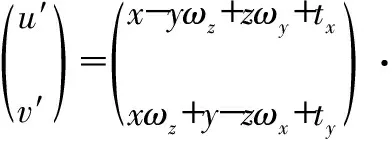
(3)
式中fL為攝像機的焦距。求得投影點x(t+1)相對于μ=[ωx,ωy,ωz,tx,ty,tz]的導數矩陣Fμ,即
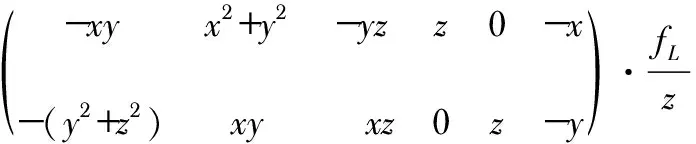
(4)
以上導數可反映像素點根據Fμ在深度圖像上的位置變化。點X在時刻t的深度值為d,根據LK方法,存在
d(F(x,μ),t+1)=d(x,t)
(5)
即在一定的范圍內對于三維空間點X在相鄰時刻的深度值恒定。求解μ,即是找到一個μ使得最小二乘誤差最小,即
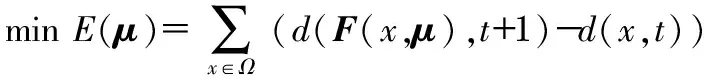
(6)
式中Ω為t時刻的模板區域,只有在Ω內部的像素點才考慮運動估計。因為深度圖像保存了場景的景深信息,可以通過簡單的二值化分離出背景,非背景區域即為Ω模板區域。
假設運動為μ+Δμ,則誤差為
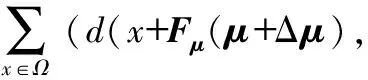
t+1)-d(x,t))
(7)
根據泰勒展開式
(8)
計算μ是一個迭代過程。在每次迭代中計算運動增量Δμ。然后,模板根據運動增量Δμ進行變換,變換結果用于下一次迭代。當Δμ收斂后迭代過程結束,μ通過一系列Δμ變換組合得到。μ經過矩陣變換得到幀間位姿T。
對于運動矩陣μ=[ωx,ωy,ωz,tx,ty,tz],數值Lμ表示運動的大小,Lμ如下
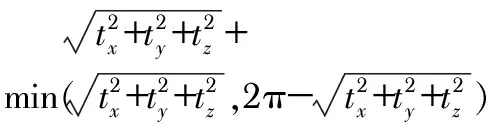
(9)
利用閾值法對Lμ進行定義
(10)
式中 過小表示兩圖像幀間距很近,沒有必要都進行保留;過大則表示兩幀間距很遠,缺乏關聯性;適中則能保證兩幀的間隔性與關聯性,并且新的圖像幀會被加入到關鍵幀序列中去。其中k1和k2的取值通過實驗獲得,閾值法的好處在于可以靈活地調整閾值來保證結果的正確性,針對一些復雜多變的環境是非常有效的。
2 基于圖的里程計優化
計算視覺里程計實質是計算幀序列的幀間位姿序列,Tij表示第i幀與第j幀的位姿變換。引入圖G={V,E}構建優化模型,E為頂點表示相機的位姿
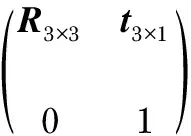
(11)
式中V為邊表示頂點間的變換或約束
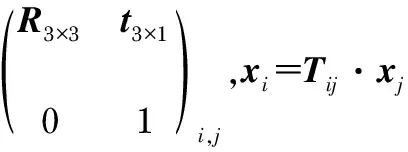
(12)
未進行優化的視覺里程計的圖結構如圖1所示。

圖1 不帶路標的圖結構
本文在上述鏈式結構的基礎上,通過上文的關鍵幀算法,在局部添加局部回環以及隨機回環,進而構造不含路標頂點的因子圖。具體流程如下:
1)初始化關鍵幀的序列F,并將第一幀f0放入F。
2)對于新來的一幀fnew,利用關鍵幀提取算法計算F中最后一幀與fnew的幀間位姿T,并估計該T的大小Lμ。有以下幾種可能:
a.過小,說明離前一個關鍵幀很近,丟棄該幀;
b.過大,說明運動太大,可能是距離太遠或計算錯誤,同樣丟棄該幀;
c.適中,運動估計正確,同時又離上一個關鍵幀有一定距離,則把fnew作為新的關鍵幀,進入回環檢測程序。
3)局部回環檢測:匹配fnew與F末尾n1個關鍵幀。匹配成功時,在圖里新增一條約束邊。
4)隨機回環:隨機在F里取n2個幀,與fnew進行匹配。匹配成功時,在圖里新增一條邊。一般取n2=2n1,這樣取值的好處在于盡可能多地讓新幀與前面的幀建立約束邊,同時保證不會因為某一幀的丟失導致圖鏈的斷裂。
5)將fnew放入F末尾。若有新的數據,則回步驟(2);若無,則圖構造完成。取n1=3,n2=6時圖的結構如圖2所示。
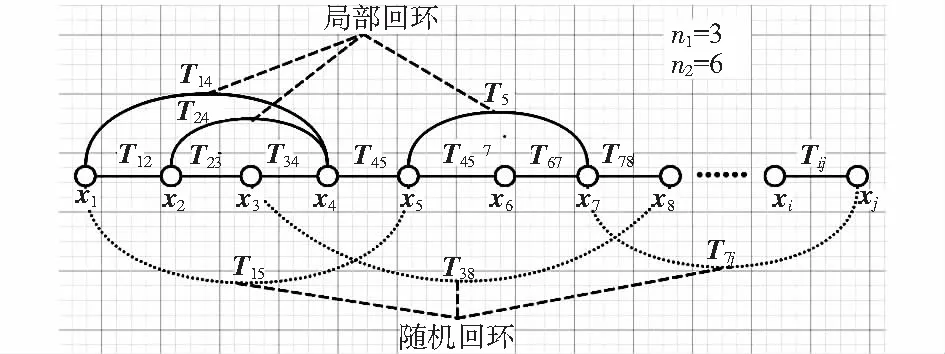
圖2 本文算法構造的圖結構
當圖結構是存在回環的非鏈狀結構時,由于邊Tij中存在誤差,使得所有邊給出的數據不一致,此時,優化一個不一致性誤差
(13)

(14)
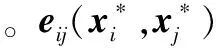
(15)
式中Jij為誤差函數eij(x*)在x*附近的雅克比矩陣。將式(15)代入式(14)的某一項并展開
F(x*+Δx)=C+2bΔx+ΔxTHΔx
(16)
H=∑Hij為Hession矩陣的累加。為使式(16)最小,使其一階導數等于0,得
HΔx=-b
(17)
至此,將優化問題進一步轉化為線性方程組求解問題。
求解的過程通過高斯—牛頓迭代法完成。首先將關鍵幀匹配求得的每一幀的位姿向量[ωx,ωy,ωz,tx,ty,tz]作為圖中每個頂點x的初始值x*,求得的Δx疊加x*作為新的初始值,重復執行該過程直到x*收斂,此時x*為優化后的結果。
3 實驗與結果分析
為了對算法進行評估,本文利用Computer Vision Group提供的RGB-D數據集進行試驗,該數據集主要包含2個部分:Kinect視頻序列和真實的里程計。
3.1 算法性能評估
算法性能主要包含2方面:算法的精度和算法的實時性。算法的精度由求得的視覺里程計與真實里程計的誤差決定,算法的實時性由單幀里程計平均用時決定。圖3給出了視覺里程計在2維空間的投影結果。
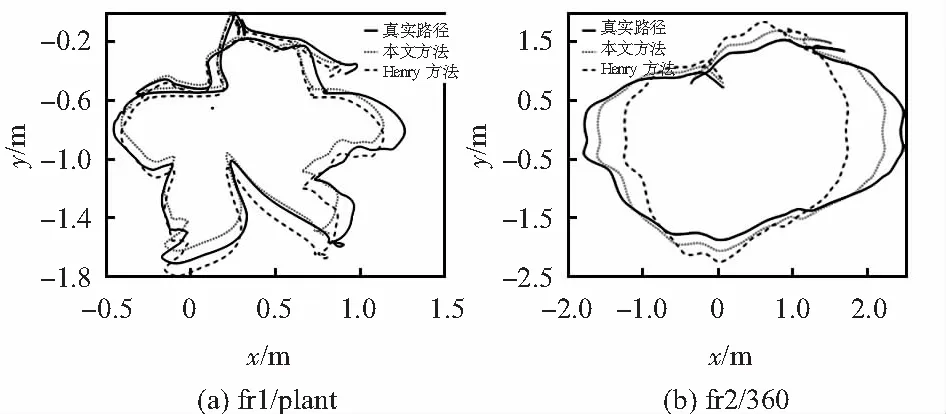
圖3 不同算法估計相機運動2D軌跡
圖4(a)為不同算法在具體標準誤差上的比較,絕對軌跡誤差 (absolute trajectory error,ATE)用來衡量算法估計軌跡與真實軌跡的誤差;相對姿態誤差 (relative pose error,RPE)用來衡量位姿之間存在的誤差積累程度。圖4(b)為不同算法在耗費時間上的比較。可以看出,相比較傳統算法,本文算法在不影響實時性的前提下,在絕對軌跡誤差和相對姿態誤差上,取得了較為顯著的提高。
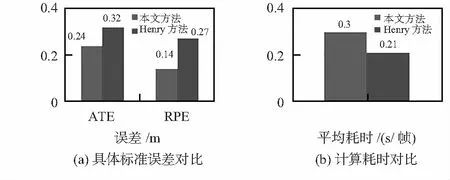
圖4 性能對比
3.2 三維點云圖
為進一步驗證算法性能,以求得的視覺里程計為基礎,實現三維場景的重構,通過點云圖呈現。當然由于Kinect相機拍攝距離的局限性,對于過遠的場景,由于無法得到其圖像,所以沒辦法進行拼接還原。如圖5所示。

圖5 數據集的三維點云模型
3.3 真實室內環境實驗
為了進一步通過實驗檢驗算法,通過手持Kinect,在室內緩慢繞行1周,收集室內場景信息。Kinect的幀率為30 Hz,分辨率大小640×480,共收集1 800幀RGB-D圖像,最終選取了230個關鍵幀。由于當物體離Kinect較遠時,測量的深度信息可能不準確,設定只保留7 m以內的點。點云0.05 m,最小距離k1設為0.8,k2設為2,相鄰檢測幀數n1設為4,隨機檢測幀數n2設為8。實驗建立的室內三維場景如圖6所示。左圖為整體效果,右圖是對局部區域放大后的顯示效果,從該圖中可以看出,對于拐角、轉彎等易于產生較大誤差的地方,本文算法都實現了較好的優化。

圖6 真實室內環境的三維點云模型
4 結束語
Kinect相機因其能夠提供深度信息的優勢在計算機視覺領域具有廣闊的應用前景。本文以Kinect為傳感器,實現基于圖優化的視覺里程計設計。該方法充分利用了Kinect易于獲得深度信息的特點,提出了一種新的基于深度圖像的關鍵幀選取算法,并通過在關鍵幀添加局部和隨機回環構建圖,在圖上用非線性最小二乘方法實現視覺里程計的優化。實驗結果表明:運用本文方法,在不影響實時性的同時,有效減小了誤差,得到了更為精確的視覺里程計結果。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
