基于HBase的海量冠字號碼多維索引研究?
2019-03-01 02:52:16張重陽
計算機與數字工程 2019年1期
張 藝 張重陽
(南京理工大學計算機科學與工程學院 南京 210094)
1 引言
人民幣冠字號碼管理指的是對錢幣的身份編號(冠字號碼)進行記錄、存儲和分析。冠字號碼的查詢能助推貨幣政策的貫徹落實和實施,使銀行與客戶責任清晰,有效抑制洗錢、行賄、偷稅等違法行為,及時發現問題鈔票,為執法機關提供服務[1]。冠字號碼在錢幣的流通過程中扮演著非常重要的角色。在經濟飛速發展的今天,銀行業每天都會產生數量巨大的冠字號碼信息,這對傳統的人民幣冠字號管理模式形成了很大的壓力與挑戰。目前各大銀行冠字號碼數據需要集中到總行管理,支持至少三個月的全行數據。
冠字號碼數據是一種海量流數據,具有體量大、多維度、更新速度快等特點。由于現在銀行業的發展,海量的冠字號碼數據會隨著時間序列連續產生。具有良好擴展性的HBase分布式數據庫適合存儲海量的冠字號碼數據。但是由于HBase的設計特點,在數據的插入與查詢實時性方面還有待提高,其原因為
1)實時數據插入效率問題。在HBase中,region是數據存儲的基本單位。而面對海量時序數據時,如果某個時間段內數據特別大,數據則會按字典序依次插入某個region中,當這個region達到預設的閾值時,會觸發split操作。而大量的split操作對數據插入效率影響很大。
2)多維數據查詢效率問題。HBase采用的是鍵值對模型,對主鍵有著良好的查詢效率。但是在多維度冠字號碼的實際查詢中,往往會根據在一定時間間隔內去查詢某些條件,這種多維范圍查詢需要scan表中多個區域,消耗的代價很大。
為了解決這一問題,本文結合分布式數據庫HBase與具體的冠字號碼數據提出了一種基于時間序列的多維索引結構MT-index(Multi-dimensional index based on Time)。
2 相關工作
近年來,云計算技術的得到了學術界與工業界的廣泛關注。而NoSql作為云平臺中的分布式數據庫也應用于越來越多的地方,這也推動了云數據管理索引技術[2]的發展。文獻[3]最早提出了在云平臺中使用索引技術,提出了一種在云環境中具有兩層索引的計算框架。文獻[4]提出了一種在主存建立列數據索引的方法。現主要的研究分為二級索引技術與全局局部索引結合的二層索引方式。
二級索引是一種常用的索引技術,主要應用于鍵值存儲的云數據數據庫系統中,如HBase。目前基于二級索引的方案主要有ITHBase、IHBase以及CCIndex[5]。其中,ITHBase與IHBase是開源的實現方案,其原理是索引表存放索引列與原表的鍵值信息,查詢時先通過索引表得到鍵值再根據鍵值去原表查詢數據。然而查詢索引表時得到的鍵值是大量隨機的,去原表查詢時也需要通過大量隨機查詢才能得出查詢結果。為此,ZOU等提出了互補聚簇式索引,稱為CCIndex,CCIndex的方法是把數據的詳細信息也放在索引表中,減少了大量的隨機查詢,減少了查詢時間,但是會造成索引表空間的增大。CCIndex還給出了一種查詢優化機制以支持多維查詢。二級索引實現簡單,維護代價較低,但是多維查詢效率低而且空間冗余大。
文獻[6]中提出了一種動態多維索引框架,先通過八叉樹對云空間進行索引,再使用跳表隨機訪問層次化的八叉樹索引,實現了多維查詢,范圍查詢,動態索引縮放等。文獻[7]提出了多種云索引方案,分別為CAN組織所有節點,R-樹索引節點內數據;集中式R-樹索引全局,KD-樹索引節點;Chord覆蓋網絡并使用MX-CIF索引本地。文獻[8]提出了一種MapReduce框架下高維數據近似查詢方法。使用MapReduce任務并行處理的優勢將整個數據集均勻的劃分到集群中的各個計算節點,基于劃分的方法構建分布式雙層索引。但該方法針對的數據集比較穩定,沒有考慮索引的更新。文獻[9]提出的A-Tree索引是云環境下適合點查詢與范圍查詢的分布式多維數據索引,A-Tree通過R-Tree實現索引,但R-Tree的缺點是有很多“重復覆蓋”的區域,為此通過Bloom過濾器來選擇查詢區域。但是由于Bloom過濾器的局限性,當數據量越大時出現誤判的概率也越大。文獻[10]提出了一種基于改進四叉樹的空間劃分方法,再使用Hilbert曲線進行局部多維索引。這種索引方法高效的實現了多維查詢,但構建效率復雜。而如KR+-索引[11]、HQ-Tree[12]、DQuadtree[13]這些多維索引框架都基于經典的空間數據索引,缺點是空間冗余較大。
3 MT-index
對于使用HBase存儲實時流數據,如果當某個時間段數據量過大時很容易出現數據熱點問題,為了減少數據熱點的影響,一般的解決方式是為其建立索引,使得數據不會只集中存儲在分布式集群中的某個節點內,而是分散的存入每個節點中。但是在插入數據的同時構建索引,對于數據插入的實時性也有一定的影響。因此,為了解決這一問題,MT-index將索引層劃分為全局的粗粒度索引與本地的細粒度索引,數據在插入的時候先按粗粒度索引方式進入預先的分區中并只對粗粒度索引進行維護,等待數據入庫后再進行細粒度索引的建立。這樣的方式在一定程度上緩解了插入實時性的問題。同時,HBase采用Key-Value的形式進行存儲,這種模式只提供了鍵值的快速查詢,對于非鍵值的查詢操作只能使用scan操作,其效率在海量冠字號系統中是不能接受的。現實中冠字號碼數據的查詢往往是涉及多個查詢條件,比如查詢某段時間內某人辦理的業務涉及的冠字號碼等,如果是按照HBase提供的過濾器進行查詢,則查詢過程消耗太大。為此,在粗粒度索引中使用時間序列與空間曲線結合的方式對數據進行劃分并將多維查詢條件降為一維,減少索引元所占空間,使用較少的存儲空間實現了高效的多維查詢。
3.1 整體框架
整體框架如圖1所示,整個系統由數據導入模塊、HBase分布式數據庫模塊、索引模塊以及查詢模塊構成。數據導入模塊負責將銀行網點隨時產生的數據導入到云存儲空間的HBase中;HBase分布式數據庫模塊負責將導入的數據按鍵值對的形式存入HBase表中,產生的數據包括交易流水、交易內編碼、冠字號碼、時間、操作代碼、銀行網點編號、機器號、卡號等字段。同時,HBase也負責存儲索引模塊導入的索引表;索引模塊負責構建與維護索引數據,先通過時間序列與空間曲線對數據分區后進行粗粒度的全局索引,當數據存入對應的region之后,再采用二級索引的策略構建本地索引;查詢模塊根據查詢條件先去查詢粗粒度的全局索引,確定數據所在的region,再根據本地的細粒度索引查詢出具體數據。

圖1 系統整體框架
3.2 索引的設計與實現
3.2.1 索引結構
索引結構如圖2所示,索引包括了粗粒度索引以及region中細粒度的二層索引。
1)索引的第一層使用B+樹將時間序列轉為索引。由于隨著時間變化會不斷的有冠字號碼數據更新進入系統,所以在本文中,將時間分為若干個時間段{[T0,T1],[T1,T2],…,[Ti-1,Ti]},這些時間段沒有重疊,相加之后為系統需要的時間量。時間段會不斷的后移,在規定范圍之外的時間段就將其從索引中刪除。使用B+樹索引時間序列,每個葉子節點指向對應下層空間曲線所表示的區域。
2)使用Z曲線[14]對多維數據進行降維并且分區。Z曲線是一種通過隔行掃描二進制數字的比特到一個字符串來實現降維,并將產生的Z區域按升序填充到線性曲線中。空間Z曲線通過降維后分區,將源數據分為連續的Z空間,每個Z空間都對應著曲線上的一個Z值。在冠字號碼數據中,對卡號與銀行網點代碼、冠字號碼這三維構建多維索引,其意義是查詢某段時間內,某個用戶在某個網點取出或者存入的某張錢幣。在查詢時,可以將查詢條件完整輸入也可以輸入個別條件。
3)region中數據的本地索引。本文中在數據插入HBase表中并且維護完上兩層索引之后,會構建本地索引,本地索引類似開源框架IHbase,其目的是通過查詢條件定位到某一個區域后,通過二級索引的方式能快速地查詢出數據,避免掃描操作。由于這層索引是細粒度的,相對于上一層構建消耗較大,因此選擇在當前時間序列結束后再對前一個時間段的數據構建本地索引。
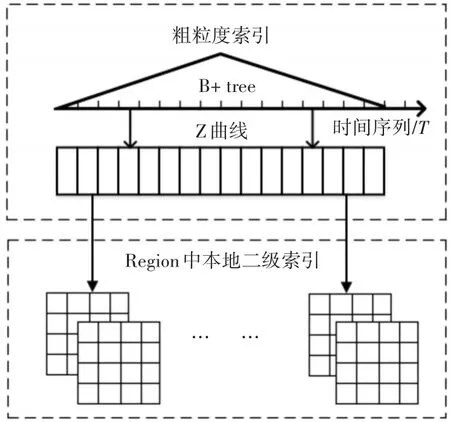
圖2 索引結構
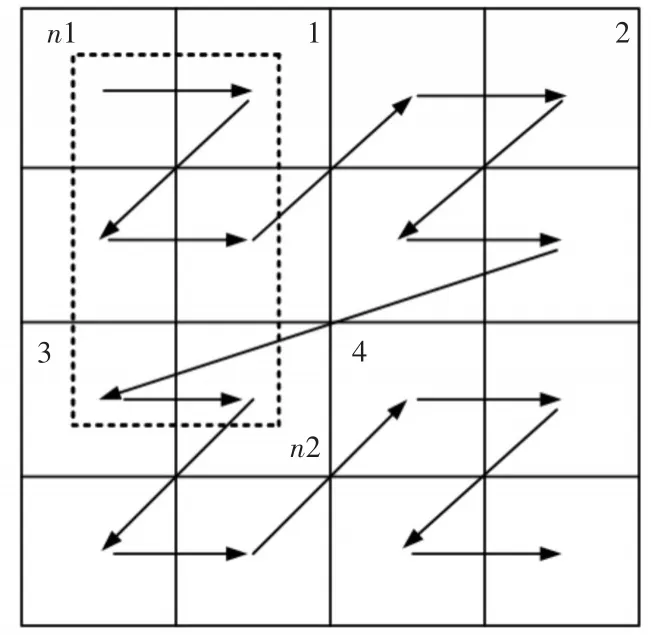
圖3 二維Z曲線中范圍查詢
3.2.2 數據分區
HBase中基本的存儲單位是region,每個region都有其對應的regionServer維護。本文的索引方式是時間序列與空間曲線相結合的方式,若直接按照這兩點設計RowKey,可能會造成熱點數據問題,數據會不斷地寫入同一個region中,當數據量超過了region的閾值便會調用split方法,數據量增長很快的同時split操作的次數也會很多,對于插入性能影響很大。在region中startKey和endKey是兩個非常重要的元素,決定了這個region中RowKey的范圍。所以在本文中采用了隨機散列與預分區結合的方法來確定startKey與endKey。因為HBase中RowKey不能重復,所以在系統中使用時間序列與交易內編碼結合的方式生成RowKey。1)先預測并隨機產生未來一段時間序列內會生成的RowKey,使用MD5的方式轉為hash在轉為bytes,并將這個值拼接在原RowKey之前,升序后放在一個集合之中。2)根據預分區region的個數,對整個集合分割,產生對應的splitKey。產生的splitKey即可作為region的起始與結束位置。3)使用HBaseAdmin中的createTable方法指定預分區。這樣可以避免熱數據插入問題以及大量的region的分裂操作,提高效率。當預分區的時間序列結束前,系統會產生下一階段預分區的結果作為下個階段存儲數據的region。
3.3 索引效率分析
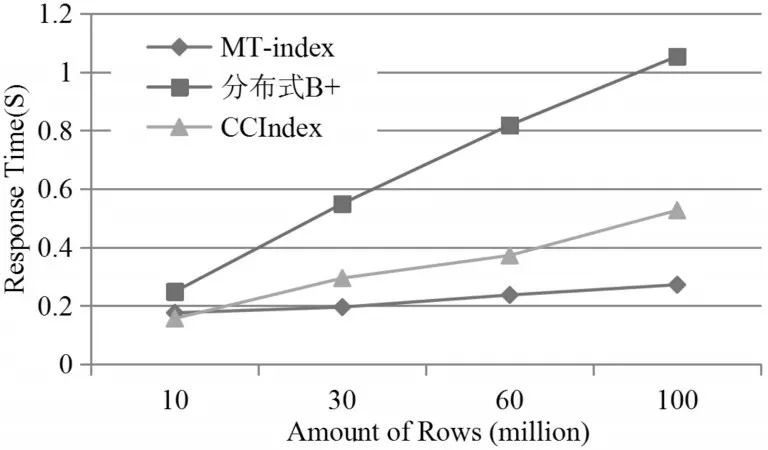
MT-index多維索引是一種以空間換取時間效率的方式,通過全局的粗粒度索引與本地的細粒度索引結合的方式提高數據插入以及多維查詢效率。本文使用這種方式的目的在于實現高效的多維查詢,現分析MT-index在多維查詢方面的效率。多維查詢分為多維點查詢和多維范圍查詢,在多維點查詢時,通過查詢條件的計算,能確切得到數據在空間曲線的某個對應區域,查詢的范圍為一個區域,不存在效率的問題。而在多維范圍查詢時,所涉及到的Z區域較多,可能會造成無關區域的搜索問題。如圖3所示,在一個二維空間中,查詢范圍為(n1,n2),那么需要查詢的區域應該是虛線框中的范圍,對應的Z區域應為1,3兩個區域,但在空間曲線上,則會按序查詢1,2,3三個區域,這就造成了無關區域的搜索,對效率產生了影響。為此,將B+樹與Z曲線結合,如圖4所示。可見,基于時間序列B+樹中非葉子節點是個三元組 由上面的分析可以得出,粗粒度的全局索引能快速地定位到數據所在的空間區域,盡量減少了無關區域的查詢。但是如果查詢所給的范圍很大,最終會有很多個區域需要查詢,由于在數據處理中已經進行了預分區處理,每個region中數據量不會有很大偏差,則每個空間Z區域也不會有很大偏差,符合并發執行的條件,因此使用MapReduce[15]進行并發搜索,提高多維范圍搜索效率。同時,在每個region中,會為其中的數據建立二級索引,即將查詢條件作為鍵值,本文中采用用戶卡號,該層索引實現比較簡單,具體操作為在本地的二級索引表中按條件過濾出對應源數據的主鍵,目的是避免全區域的scan操作。 圖4 B+樹與Z曲線結合結構圖 本實驗平臺由Hadoop-2.7.3集群組成,搭建于4個節點之上,每個節點上搭建了14.04的64位Ubuntu系統,每個節點CPU為Inter(R)Core(TM)i5,3.20Hz,內存為4G。Hadoop集群中有一個主節點與三個從屬節點,分別提供管理與存儲功能。使用的數據庫為HBase-1.2.3,在HBase環境中有HMaster與HRegionServer兩個角色。本實驗中將HMaster部署在主節點,其余節點作為從屬節點。實驗數據采用冠字號碼記錄信息,記錄信息包括交易流水、冠字號碼、時間、銀行網點號、網點機器號、卡號。HBase表中數據格式如表1所示。數據通過仿真生成,模仿了100個網點三個月生成的業務量。每筆業務都有其對應的冠字號碼集,截取100萬,300萬,600萬,1000萬數據進行插入實驗以及1000萬,3000萬,6000萬,10000萬數據量進行查詢實驗。插入實驗的數據是直接調用HBase中的API而查詢實驗的數據則是使用HBase提供的Bulk-Load方式批量導入。在實驗中,使用MT-index與CCIndex以及分布式B+樹進行比較。 在該實驗中,分別對三種索引結構進行四組不同數據量的數據插入,統計對于插入一定數量的流數據,系統需要消耗的時間。由實驗結果(圖5)表明,對于數據插入方面,三種索引結構的時間都是隨著數據量的增加呈現線性增長。當數據量較小的情況下,MT-index消耗的時間要略大于CCIndex以及分布式B+樹,其原因為MT-index需要計算空間曲線Z值以及計算預分區,這些時間消耗在總時間中所占比重較大。而當數據量變大后,MT-index的插入時間則小于CCIndex與分布式B+樹。實驗結果表明,MT-index在大量的流數據情況下,具有較好的數據插入性能。其原因在于對于多維索引,分布式B+樹會根據多個屬性建立多個索引表,同樣CCIndex的索引冗余很大,構建需要較多的時間。而MT-index則采用了Z曲線將多維降為一維,只需要構建一個索引表,且采用粗細粒度索引分離的方式,所以數據插入的性能更高。 圖5 數據插入耗時 數據查詢實驗中,采用4組數據進行查詢實驗。分別從源數據中獲取100份范圍查詢數據,在MapReduce框架進行連續實驗,記錄完成時間,再取平均值作為該索引在該數據量下的查詢響應時間。實驗結果如圖6所示。相對于分布式B+樹與CCIndex,MT-index的查詢響應時間更短。當數據數據較小的時候,三種索引方式的查詢效率差不多,而當數據量不斷增大,MT-index在查詢效率方面的優勢是很明顯的。而且,查詢響應時間受數據規模的影響較小。其原因是在MT-index這種索引模式下,最終要查詢的區域隨著數據量的增長變化并不大。所以MT-index具有高效的查詢效率。 圖6 查詢響應時間 本文基于HBase提出了一種冠字號碼數據的多維索引模型,為海量冠字號碼數據的存儲與查詢提供了方案。實驗表明,該方法具有較好的插入、查詢效率,易于實現,受數據規模影響不大,能夠適用于數據規模不斷增長的實時冠字號碼數據查詢系統。本文的工作重點在于對索引的構建,目的是提高實時數據插入與查詢的性能。對于解決海量冠字號碼問題具有重要的參考價值和實用意義。
4 實驗論證
4.1 實驗環境
4.2 數據插入實驗

4.3 數據查詢實驗
5 結語
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
甘肅教育(2020年14期)2020-09-11 07:57:42
中學生數理化(高中版.高考數學)(2020年5期)2020-06-02 09:19:08
商周刊(2017年9期)2017-08-22 02:57:49
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國衛生(2014年11期)2014-11-12 13:11:32
