循環神經網絡在語音識別模型中的訓練加速方法
2019-01-24 08:26:44馮詩影韓文廷遲孟賢
小型微型計算機系統 2018年12期
馮詩影,韓文廷,金 旭,遲孟賢,安 虹
(中國科學技術大學 計算機科學與技術學院,合肥 230027)
1 引 言
作為對傳統神經網絡的一種改進,循環神經網絡(RNN)引入反饋機制,在解決如自然語言處理等序列問題方面取得了巨大的成功,例如語音識別[1],語言模型[2],以及機器翻譯[3]等.伴隨問題更加復雜,以及對訓練精度要求不斷提高,模型中神經網絡層數不斷增多,規模越來越大.如今,大多數神經網絡使用GPU或FPGA等加速卡進行訓練.然而,隨著神經網絡規模的不斷擴大,片上有限的存儲空間逐漸成為訓練大規模模型的瓶頸.目前已有許多工作用于加速神經網絡訓練,例如cuDNN——NVIDIA專用深度學習加速庫[4],或分布式機器學習技術[5],但是如果沒有有效利用計算資源,加速器的最佳性能同樣不能被最大化發掘.
本文提出了一種基于循環神經網絡的語音識別(ASR)模型加速訓練方法.首先,從訓練集中獲取序列長度分布,根據可利用內存空間確定存儲的不同大小模型數,并對每批次訓練樣本進行補零對齊.其次,平衡存儲空間與訓練時間,通過高效利用顯存,達到在相同存儲空間下一次訓練更多樣本,充分利用計算資源,提升計算效率.實驗表明,該方法有效地提升了訓練速度,且保證無精度損失.
2 相關工作
2.1 循環神經網絡
循環神經網絡(RNN)基于傳統神經網絡,在隱藏層之間增加了反饋連接.由于其反饋機制,RNN具有記憶過去狀態的能力,因此在處理具有時間相關性的序列數據中有良好表現.一個簡單的循環神經網絡如圖1所示.
xt是時刻t的輸入(input),通常是具有特征維度的向量.st是時刻t的隱藏狀態(hidden state),它由輸入xt和前一隱藏狀態st-1計算得到.ot為時刻t的輸出,它是表示所有類別的概率向量.U,V和W分別是從輸入,前一隱藏狀態到下一隱藏狀態,隱藏狀態到輸出的連接的權重矩陣.請注意,對于每一時刻,循環神經網絡共享權重.網絡輸出計算公式如下所示.為激活函數,如sigmoid或tanh.Softmax是一種應用于多分類問題的算法.
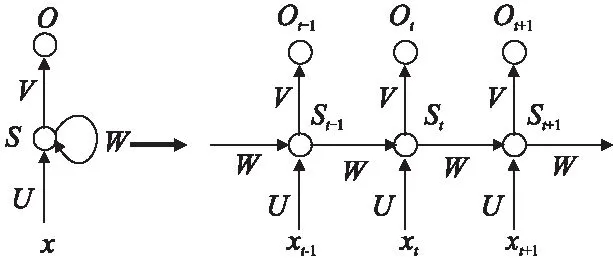
圖1 循環神經網絡Fig.1 Recurrent neural network
st=σ(Uxt+Wst-1)
(1)
ot=Softmax(Vst)
(2)
理論上,RNN能夠在任意長的網絡間傳遞信息,但是當涉及長時任務時,如對包含1000幀語音數據進行解碼,其反饋能力會大大降低.為了增強記憶能力,長短時記憶模型(Long Short-term Memory,LSTM)[6]和門控循環單元(Gated Recurrent Unit,GRU)[7]網絡應運而生,兩種改進的循環神經網絡結構添加門控機制,增強存儲信息的能力,并成功地避免了梯度消失問題[8].目前,基于循環神經網絡的大多數模型均使用LSTM[9]或GRU[10]進行構建.
如今,自動語音識別(ASR)模型使用RNN(LSTM或GRU)作為基本單元,通過對當前訓練幀引入反饋機制,極大提高了訓練的精確率.與其他神經網絡相同,有效地增加模型層數將會獲得更高的準確性,但同時將需要更多的計算時間和存儲空間.
2.2 相關加速算法
與卷積神經網絡(Convolution Neural Network,CNN)[11]和全連接網絡(Fully Connected Network,FCN)[12]相比,循環神經網絡不僅包含垂直方向上的深度信息,還包含水平方向的時間信息.當涉及序列學習任務時,對于長度不同的輸入序列,使用RNN進行訓練時,模型的水平方向長度將會變化.通常,神經網絡以批處理(batch)方式進行訓練,以達到更高計算效率[13].當同時訓練多個序列時,較短的序列將在末尾填零補齊,從而使同一組訓練數據具有相同長度.顯然,填補零將帶來額外計算開銷,同時每一批不同長度的序列將使用不同大小的模型進行訓練.由于存儲限制,應該考慮如何選取合適的模型數量及大小進行存儲.
截斷反向傳播時間(Back-propagation Through Time,BPTT)是一種將輸入樣本進行分段訓練的方法,能夠有效減少訓練模型大小[14],但截斷將會導致梯度信息丟失并影響性能[15].同時,對于訓練較大模型,陳天奇小組提出了一種減少內存消耗的系統化方法,已被證明在卷積神經網絡和固定長度的循環神經網絡模型訓練中有效[16].谷歌提出了一種前后向折中計算的方式來訓練循環神經網絡[17],解決了內存緊張時大規模模型訓練的問題.這兩個方法均在理論上以犧牲計算時間在有限存儲下進行訓練,未表現出加速性能.
本文提出一種更合理的方法來訓練語音模型中的循環神經網絡,通過對序列的合理組織以及高效的存儲使用,來提升對輸入序列的長度有顯著變化的模型訓練速度.
3 序列分組
序列分組(sequence bucketing)思想是指將輸入序列按批(batch)訓練大小進行劃分,并放入對應組中,每個特定大小的組稱為桶(bucket).序列分組有兩個考慮因素:(a)應保留訓練數據的隨機性.(b)對于訓練序列,分組應該是最佳的.序列分組主要分為三個步驟(見圖2).
1)給定具有可用內存的塊大小,將數據集拆分成具有索引的多個塊;獲取數據時,隨機從磁盤中取出一個塊到內存;
2)對所選塊中的序列進行排序,并按批訓練大小進行分組;再次對其編號進行隨機化;
3)訓練時取出一組樣本,選擇合適大小的桶對其進行處理,并使用對應大小模型進行訓練.

圖2 序列分組過程Fig.2 Process of sequence bucketing
該方法第一步一次將一整塊數據放入內存中,減少硬盤訪問次數來提高數據訪問速度.此步由多線程生產者消費者模式進行操作,掩蓋讀取時間開銷.第二步對該塊序列排序,具有相似長度的序列將位于同一訓練批次中.通過隨機化,前兩步保證了輸入數據的訓練隨機性.第三步,批訓練數據被置入合適大小的桶中,該桶為長度大于當前批次最長序列中最小的桶.顯然,由于沒有額外的計算,具有相同長度的序列的桶大小將達到最佳性能.直接利用已存儲的模型將會減少模型構造時間,但由于參數,網絡結構等設置,一個模型將占用200MB空間;對于最長序列長度為1000的數據集,若對每一步長的模型均進行存儲,將占用近200GB的空間,這將給內存帶來巨大的負擔.如果動態構建模型,當計算與構建模型時間不能重疊時,整體訓練時間也將大大增加.
此時考慮存儲特定大小及數量的桶.桶的數量取決于內存大小和最長的序列長度.在可存儲范圍內,不同尺寸的模型將被保存和重復使用.本文提出兩種設置桶大小的方法.
設L為最長的序列長度,N是桶的數量; Bm是第m個桶的大小,Bm和Bm+1之間的步長為Sm+1.注意對于任一步長,Sm>0,桶大小按升序排列.此時桶的大小表示為:
(3)
通常,簡單采用固定步長可以滿足基本訓練需求,此時桶的大小如公式所示:
(4)
固定步長適用于序列長度均勻分布的數據集.但是,大部分數據集并不符合均勻分布.圖3顯示了一個語音識別數據集的序列長度的概率密度分布.可以看到,大多數序列傾向于在一定范圍內分布,并且較短的序列比更長的序列分布更加密集.因此,具有較大尺寸的桶利用率較低,而在數據集的密集分布范圍內桶的利用率更高.

圖3 語音識別數據集長度概率分布Fig.3 Probability distribution of sequence length for the speech recognition dataset
在這種情況下,根據數據集的分布設置變化步長的桶大小會取得更好的性能.取其概率分布函數F(x),桶大小可以設置為:
(5)
對于語音識別的數據集,概率分布函數類似平方根函數.與均勻步長相比,桶的大小變化較大,這可能對長序列有更差的影響.為平衡性能,最終選取如下公式對桶大小進行設置,即相鄰兩桶之間步長呈遞增形式:
(6)
(7)
圖4給出了取8個桶時,選擇固定步長和變化步長方法下,每個桶覆蓋數據集中不同長度序列范圍的示例.最上為改進后的變化步長,中間為依靠概率分布所取步長,最下為固定步長.如圖所示,序列長度較短范圍內,選取變化步長時桶的數量明顯多于固定步長,且改進后的變化步長方法在較長序列范圍部分,桶的數量較原方法增多,從而使位于語音數據集中不同長度的序列均有大小合適的桶可供選擇.

圖4 不同步長設置下桶覆蓋數據區域分布Fig.4 Buckets with different step setting
除此之外,批訓練數據的形狀被重新排列,以桶大小作為第一維度(如圖2中的步驟3所示).通過此種排列,處于不同序列但在同時刻的輸入數據將位于連續向量中,從而在計算過程中能夠連續訪存,獲得較高訪存性能.
4 高效利用顯存
在循環神經網絡中,由于水平方向實際為按時間順序循環展開,因此每個單元結構相同,其輸出不僅作下一層輸入,還將傳遞給后一單元.隨著序列長度和批樣本數增加,模型逐漸變大,有限存儲空間將無法存儲模型,或僅可以在一次訓練中訓練幾個序列,導致計算效率極低.因此,需要考慮在計算時間和存儲空間之間進行平衡,從而提升訓練性能.
為了解循環神經網絡模型占用內存大小,需要深入了解其單元結構.以LSTM作為對象進行分析,LSTM網絡與標準RNN相同,但隱藏層中的單元被更復雜的單元替代.在該單元內,細胞(cell)是LSTM的關鍵部分,它保存當前單元的狀態信息; 輸入門(input gate)、輸出門(output gate)和遺忘門(forget gate),決定是否應將信息添加到單元中或從單元中移除.
LSTM核心公式如下.it,ft,ot表示輸入門,遺忘門和輸出門,輸入數據xt,隱藏狀態ht,單元狀態ct分別為向量形式.Wmn表示從單元n到單元m的連接權重矩陣,大小為m×n.bi,bf,bo,bt分別為三個門和變換部分的偏置權重,為向量形式.t表示時刻t.σ為激活函數,g是單元和隱藏層的輸出激活函數.
it=σ(Wixxt+Wihht-1+bi)
(8)
ft=σ(Wfxxt+Wfhht-1+bf)
(9)
ct=ftct-1+itg(Wcxxt+Wchht-1)
(10)
ot=σ(Woxxt+Wohht-1+bo)
(11)
ht=otg(ct)
(12)
從方程式可以看出,LSTM計算過程比基本RNN更加復雜,更多變量需要存儲.圖5顯示了一個LSTM單元的計算過程.在圖中,點狀網格表示一個LSTM單元,其內部的每個方塊表示中間結果或最終結果.

圖5 LSTM單元結構圖Fig.5 LSTM unit
首先,前一隱藏狀態ht-1和輸入xt通過全連接層被轉換成四個矩陣.后續操作——矩陣加法,激活和矩陣點乘均基于這四個矩陣進行計算.假設批樣本大小為B,一層中的神經元數量和輸入維度均為H,則一個塊中的內存使用總大小為2(19BH).例如,對于批量大小為8,隱藏大小為2048的浮點數據類型,一個單元占用2.5MB,那么對于步長(step)為1000的3層模型,除其他如softmax層外,已經需要7.5GB顯存.反向傳播過程使用鏈式法則來遞歸地計算每層參數梯度,中間結果將被再次使用進行誤差計算.此時保存所有輸出及中間結果,調整模型深度或一次訓練更多樣本將被顯存限制.
通過分析后向計算過程中的導數公式[18],必須存儲的中間結果是經過激活函數后的輸出,其他梯度可通過該值進行求取.以這種方式,一個單元所需的保存結果的空間為7BH,矩陣參數大小為4H2+H.假設模型共L層,時間步長為N,網絡中的參數在單元中共享,則訓練時前后向計算所需內存成本的總大小為:
mem=2(7LNBH+4H2+H)
(13)
為減小單個樣本存儲空間,提升訓練規模,此時考慮數據丟棄方法(data drop),即在前向計算中,丟棄中間結果,只保存最終輸出,在反向傳播階段,丟棄的中間結果通過對最近的記錄狀態重新進行前向計算獲得.該方法非常適用于循環神經網絡,因為RNN中的每個單元成為一段,輸出的隱藏狀態作為記錄狀態,單元內的中間結果可以通過記錄的隱藏狀態重新計算.
僅保存每個單元的隱藏狀態和單元狀態時,為前向計算過程中需要計算的中間結果分配一個臨時空間;在后向過程中,再次使用該空間來重新計算中間結果以獲得誤差值,從而節省原需要保存全部單元而占據的存儲空間.單層RNN算法描述如下:
輸入:訓練樣本序列X,長度為N
輸出:本層輸出S及梯度G
顯存分配:
(1)中間結果temp
(2)輸入X[N],輸出 S[N],梯度G[N]
Step1.前向計算
For k=1 to N do
S[k]←rnn[k].forward(X[k],S[k-1],temp)
End for
Step2.后向計算
For k=N to 1 do
rnn[k].forward(X[k],S[k-1],temp)
G[k]←rnn[k].backward(G[k+1],temp)
End for
只存儲每個塊的隱藏狀態和單元狀態,參數和臨時空間時,同樣大小的訓練模型的內存成本為:
mem=2(2LNBH+4H2+H)
(14)
與等式(13)相比,一個單元內所需的空間理論上將縮小至原空間大小的30%,并且模型包含單元越多,內存節省的將會越多.通過這種方式,在一次訓練過程中,相同內存將可用來訓練更多樣本.盡管反向傳播階段的計算成本增加,但由于批處理規模增大,GPU硬件計算單元得到充分利用,計算效率提高,即同一時間并行計算的數據增多,從而為提升整體訓練速度提供可能.
5 實 驗
5.1 實驗設置
實驗針對語音識別模型進行評估,使用具有隱層大小為2048的3層LSTM模型,并且基于低秩方法[19],每個單元的輸出維數減少到512以降低計算規模.輸入數據集最長序列長度設置為2000,每幀向量輸入維度為40維;輸出損失函數使用Softmax,最終類別為8991類.
數據集來源于Switchboard Corpus,使用的訓練樣本包含332,576個序列.實驗基于MXNet框架[20].此次試驗基于NVIDIA Tesla M40,該GPU具有12GB顯存.優化效果評測主要針對單GPU,當使用多GPU進行數據并行加速時,其速度基本與單卡速度成線性關系.
實驗目標為如何在限定條件下在單GPU上獲得最佳性能,主要基于三個因素的評估:不同的模型數量,不同步長的選擇方式以及高效利用顯存方法.首先對序列分組方法進行實驗,然后使用數據丟棄方法查看實際內存減少比例,最終通過組合兩種方法來測試基于相同內存下訓練不同樣本大小的計算性能.
5.2 序列分組加速結果
該部分實驗設置批訓練樣本數設置為8,分別選取{1,2,4,8,16,32 }作為桶的數量.桶的數量為1時,代表所有序列都將在具有固定大小的單個模型中進行訓練.同時,實驗比較了分別使用固定步長(公式(4))和變化步長(公式(7))效果.

圖6 基于不同桶數量時速度對比Fig.6 Speed of different bucket number
最終速度性能如圖6所示.使用多個桶明顯提高具有不同長度序列的訓練性能;在變化步長的方式下,與只基于單一模型的訓練相比,當桶的數量為32時,加速比達到4.2倍.比較固定步長和變化步長的結果,后者在相同條件下較前者有大約1.1倍加速比.后續實驗中,均采用變化步長方法進行速度對比.
5.3 高效利用顯存加速結果
實驗首先對優化前后顯存的實際使用情況進行驗證.模型的展開步長設置為2000.優化前后方法均調用基于相同計算函數編寫的內核,優化前內核保存中間結果,優化后內核在前向計算中丟棄中間結果,在后向計算時重新計算.由于cuDNN中的RNN函數只能應用于固定長度模型,對于變長模型無法使用,因此并沒有將其用作對比目標.
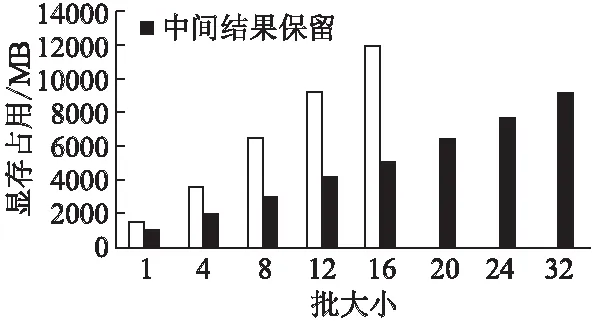
圖7 優化前后顯存大小對比Fig.7 Memory usage comparison
圖7顯示了內存使用情況.批樣本大小從1開始,考慮到CUDA內核的線程組織,批樣本大小均設置為4的倍數.從實驗中可以清楚地看出,使用優化顯存方法減少內存使用,并且隨著批樣本數增加,計算性能隨之提升.在單GPU上的12GB內存中,優化前模型能夠訓練的最大批樣本大小為16,而優化后批訓練樣本數達到32.
其次,基于相同的桶數量,步長及顯存優化方法,不同批樣本大小下的訓練速度對比如表1所示,速度單位為每秒訓練序列數.隨著批樣本數增加,訓練速度趨于線性加速,即批訓練樣本數增大,訓練性能隨之提高.

表1 不同批樣本數下速度對比實驗數據表Table 1 Speed comparison with different batch size
最后,實驗基于相同顯存下,對使用優化顯存方法前后的性能進行對比.實驗選取批樣本大小分別為8,20和12,32兩組實驗進行對比.圖8顯示了兩組實驗基于不同數量桶下的速度.兩組實驗均從優化顯存方法中獲得了性能提升:第一組實驗平均得到1.82倍的加速,第二組實驗的加速為1.73倍.該結果表明,盡管數據丟棄方法在后向計算中需要更多的時間,但由于增大了批訓練樣本數,硬件計算利用效率得以提升,從而提高了整體訓練速度.

圖8 相同顯存下優化前后速度對比Fig.8 Speed comparison with same memory
基于完整的一次訓練,當完成一個訓練周期(批樣本大小為8時需要10,343個epoch;批樣本大小為32時需要41,375個epoch),未使用優化顯存方法前,原模型一次只能訓練8個樣本,在單GPU上需要48小時;使用優化方法后,一次訓練樣本數達到32,單GPU只需19小時,使用4GPU進行數據并行訓練時間縮短至5小時.
6 結 論
本文提出了一種有效的方法來加速基于變長輸入序列的循環神經網絡的訓練速度.通過高效的序列分組和顯存優化方法,循環神經網絡模型訓練速度得到顯著提升.
實驗主要基于語音識別模型進行評估,在相同的顯存下,基于NVIDIA Tesla M40 GPU實現了1.7倍的加速.實驗證明,該方法對于較長序列的循環神經網絡效果更好.此外,隨著每批訓練樣本數的增加,可以提高學習率來加速收斂.下一步工作將考慮在顯存和計算之間進行更準確的量化分析,以及在其他模型上使用該方法進行加速,期望達到更優的訓練性能.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
